

Selles postituses tahaksime jagada huvitavat viisi hajutatud süsteemi konfigureerimisega tegelemiseks.
Konfiguratsioon on esitatud otse Scala keeles tüübikindlal viisil. Rakenduse näidet kirjeldatakse üksikasjalikult. Arutatakse ettepaneku erinevaid aspekte, sealhulgas mõju üldisele arendusprotsessile.
()
Sissejuhatus
Tugevate hajutatud süsteemide loomine nõuab kõigis sõlmedes õige ja sidusa konfiguratsiooni kasutamist. Tüüpiline lahendus on kasutada tekstilist juurutuse kirjeldust (terraform, ansible või midagi sarnast) ja automaatselt genereeritud konfiguratsioonifaile (sageli iga sõlme/rolli jaoks pühendatud). Samuti sooviksime kasutada igas suhtlussõlmes samade versioonide samu protokolle (muidu tekiks kokkusobimatuse probleeme). JVM-i maailmas tähendab see, et vähemalt sõnumiteek peaks kõigis suhtlussõlmedes olema sama versiooniga.
Aga süsteemi testimine? Loomulikult peaks meil enne integratsioonitestide juurde asumist olema kõigi komponentide jaoks ühikutestid. Testitulemuste käitusajal ekstrapoleerimiseks peaksime tagama, et kõigi teekide versioonid oleksid nii käitus- kui ka testimiskeskkondades identsed.
Integratsioonitestide käitamisel on sageli palju lihtsam, kui kõigil sõlmedel on sama klassitee. Peame lihtsalt veenduma, et juurutamisel kasutatakse sama klassiteed. (Erinevates sõlmedes on võimalik kasutada erinevaid klassiteid, kuid seda konfiguratsiooni on keerulisem esitada ja õigesti juurutada.) Nii et asjade lihtsaks hoidmiseks käsitleme kõigis sõlmedes ainult identseid klassiteid.
Konfiguratsioon kipub arenema koos tarkvaraga. Tavaliselt kasutame erinevate tuvastamiseks versioone
tarkvara evolutsiooni etapid. Tundub mõistlik katta konfiguratsioon versioonihalduse alla ja tuvastada erinevad konfiguratsioonid teatud siltidega. Kui tootmises on ainult üks konfiguratsioon, võime kasutada identifikaatorina ühte versiooni. Mõnikord võib meil olla mitu tootmiskeskkonda. Ja iga keskkonna jaoks võib vaja minna eraldi konfiguratsiooniharu. Seega võidakse konfiguratsioonid märgistada haru ja versiooniga, et eri konfiguratsioone unikaalselt tuvastada. Iga haru silt ja versioon vastab iga sõlme hajutatud sõlmede, portide, väliste ressursside ja klassitee teegi versioonide ühele kombinatsioonile. Siin käsitleme ainult ühte haru ja tuvastame konfiguratsioonid kolmekomponendilise kümnendversiooni järgi (1.2.3), samamoodi nagu muud artefaktid.
Kaasaegsetes keskkondades konfiguratsioonifaile enam käsitsi ei muudeta. Tavaliselt genereerime
konfiguratsioonifailid juurutamise ajal ja pärast. Seega võiks küsida, miks me ikkagi kasutame konfiguratsioonifailide jaoks tekstivormingut? Mõistlik võimalus on paigutada konfiguratsioon kompileerimisüksusesse ja saada kasu kompileerimisaja konfiguratsiooni valideerimisest.
Selles postituses uurime ideed säilitada konfiguratsioon koostatud artefaktis.
Kompileeritav konfiguratsioon
Selles jaotises käsitleme staatilise konfiguratsiooni näidet. Kaks lihtsat teenust - kajateenus ja kajateenuse klient on seadistamisel ja juurutamisel. Seejärel luuakse kaks erinevat hajutatud süsteemi mõlema teenusega. Üks on mõeldud ühe sõlme konfigureerimiseks ja teine kahe sõlme konfigureerimiseks.
Tüüpiline hajutatud süsteem koosneb mõnest sõlmest. Sõlme saab tuvastada mõne tüübi abil:
sealed trait NodeId
case object Backend extends NodeId
case object Frontend extends NodeIdvõi lihtsalt
case class NodeId(hostName: String)või isegi
object Singleton
type NodeId = Singleton.typeNeed sõlmed täidavad erinevaid rolle, käitavad mõningaid teenuseid ja peaksid suutma suhelda teiste sõlmedega TCP/HTTP ühenduste kaudu.
TCP-ühenduse jaoks on vaja vähemalt pordi numbrit. Samuti tahame veenduda, et klient ja server räägivad samast protokollist. Sõlmedevahelise ühenduse modelleerimiseks deklareerime järgmise klassi:
case class TcpEndPoint[Protocol](node: NodeId, port: Port[Protocol])kus Port on lihtsalt Int lubatud vahemikus:
type PortNumber = Refined[Int, Closed[_0, W.`65535`.T]]Rafineeritud tüübid
nägema raamatukogu. Lühidalt, see võimaldab lisada kompileerimisaja piiranguid teistele tüüpidele. Sel juhul Int lubatud on ainult 16-bitised väärtused, mis võivad tähistada pordi numbrit. Selle konfiguratsioonimeetodi jaoks pole seda teeki vaja kasutada. Tundub, et see sobib lihtsalt väga hästi.
HTTP (REST) jaoks võime vajada ka teenuse teed:
type UrlPathPrefix = Refined[String, MatchesRegex[W.`"[a-zA-Z_0-9/]*"`.T]]
case class PortWithPrefix[Protocol](portNumber: PortNumber, pathPrefix: UrlPathPrefix)Fantoomtüüp
Protokolli tuvastamiseks kompileerimise ajal kasutame Scala funktsiooni tüübiargumendi deklareerimiseks Protocol mida klassis ei kasutata. See on nn fantoomtüüp. Käitusajal vajame harva protokolli identifikaatori eksemplari, seetõttu me seda ei salvesta. Koostamise ajal annab see fantoomtüüp täiendavat tüüpi turvalisust. Me ei saa vale protokolliga porti läbida.
Üks enim kasutatavaid protokolle on REST API koos Json-serialiseerimisega:
sealed trait JsonHttpRestProtocol[RequestMessage, ResponseMessage]kus RequestMessage on põhitüüp sõnumid, mida klient saab saata serverisse ja ResponseMessage on vastussõnum serverilt. Muidugi võime luua muid protokollikirjeldusi, mis täpsustavad sideprotokolli soovitud täpsusega.
Selle postituse jaoks kasutame protokolli lihtsamat versiooni:
sealed trait SimpleHttpGetRest[RequestMessage, ResponseMessage]Selles protokollis lisatakse päringusõnum URL-ile ja vastusesõnum tagastatakse tavalise stringina.
Teenuse konfiguratsiooni saab kirjeldada teenuse nime, portide kogumi ja mõne sõltuvusega. Kõigi nende elementide esitamiseks Scalas on mõned võimalused (näiteks HList, algebralised andmetüübid). Selle postituse jaoks kasutame koogi mustrit ja esindame kombineeritavaid tükke (mooduleid) tunnustena. (Selle kompileeritava konfiguratsiooni lähenemisviisi puhul ei ole koogi muster nõutav. See on vaid üks idee võimalik teostus.)
Sõltuvusi saab esitada, kasutades kooki mustrit teiste sõlmede lõpp-punktidena:
type EchoProtocol[A] = SimpleHttpGetRest[A, A]
trait EchoConfig[A] extends ServiceConfig {
def portNumber: PortNumber = 8081
def echoPort: PortWithPrefix[EchoProtocol[A]] = PortWithPrefix[EchoProtocol[A]](portNumber, "echo")
def echoService: HttpSimpleGetEndPoint[NodeId, EchoProtocol[A]] = providedSimpleService(echoPort)
}Echo teenus vajab ainult konfigureeritud porti. Ja me teatame, et see port toetab kajaprotokolli. Pange tähele, et me ei pea praegu konkreetset porti määrama, kuna tunnus võimaldab abstraktseid meetodeid deklareerida. Kui kasutame abstraktseid meetodeid, nõuab kompilaator konfiguratsioonieksemplaris rakendamist. Siin oleme pakkunud rakenduse (8081) ja seda kasutatakse vaikeväärtusena, kui jätame selle konkreetses konfiguratsioonis vahele.
Saame deklareerida sõltuvuse kajateenuse kliendi konfiguratsioonis:
trait EchoClientConfig[A] {
def testMessage: String = "test"
def pollInterval: FiniteDuration
def echoServiceDependency: HttpSimpleGetEndPoint[_, EchoProtocol[A]]
}Sõltuvusel on sama tüüp kui echoService. Eelkõige nõuab see sama protokolli. Seega võime olla kindlad, et kui ühendame need kaks sõltuvust, töötavad need õigesti.
Teenuste juurutamine
Teenus vajab käivitamiseks ja sujuvaks sulgemiseks funktsiooni. (Teenuse sulgemise võimalus on testimise jaoks ülioluline.) Jällegi on mõned võimalused sellise funktsiooni määramiseks antud konfiguratsiooni jaoks (näiteks võime kasutada tüübiklasse). Selle postituse jaoks kasutame taas koogimustrit. Saame esindada teenust kasutades cats.Resource mis juba pakub kahveldust ja ressursside vabastamist. Ressursi hankimiseks peaksime esitama konfiguratsiooni ja teatud käitusaja konteksti. Seega võib teenuse käivitamise funktsioon välja näha järgmine:
type ResourceReader[F[_], Config, A] = Reader[Config, Resource[F, A]]
trait ServiceImpl[F[_]] {
type Config
def resource(
implicit
resolver: AddressResolver[F],
timer: Timer[F],
contextShift: ContextShift[F],
ec: ExecutionContext,
applicative: Applicative[F]
): ResourceReader[F, Config, Unit]
}kus
Config— konfiguratsiooni tüüp, mida see teenuse käivitaja nõuabAddressResolver— käitusobjekt, millel on võimalus hankida teiste sõlmede tegelikke aadresse (üksikasjade saamiseks lugege edasi).
teised tüübid pärinevad cats:
F[_]- efekti tüüp (lihtsamal juhulF[A]võiks olla lihtsalt() => A. Selles postituses kasutamecats.IO.)Reader[A,B]— on enam-vähem funktsiooni sünonüümA => Bcats.Resource— omab omandamise ja vabastamise viiseTimer— võimaldab magada/aega mõõtaContextShift- analoogExecutionContextApplicative— kehtivate funktsioonide ümbris (peaaegu monaad) (võime selle lõpuks asendada millegi muuga)
Seda liidest kasutades saame rakendada mõningaid teenuseid. Näiteks teenus, mis ei tee midagi:
trait ZeroServiceImpl[F[_]] extends ServiceImpl[F] {
type Config <: Any
def resource(...): ResourceReader[F, Config, Unit] =
Reader(_ => Resource.pure[F, Unit](()))
}(Vt muude teenuste juurutamise jaoks — ,
ja .)
Sõlm on üks objekt, mis käitab mõnda teenust (ressursside ahela käivitamise lubab Cake Pattern):
object SingleNodeImpl extends ZeroServiceImpl[IO]
with EchoServiceService
with EchoClientService
with FiniteDurationLifecycleServiceImpl
{
type Config = EchoConfig[String] with EchoClientConfig[String] with FiniteDurationLifecycleConfig
}Pange tähele, et sõlmes määrame täpse konfiguratsioonitüübi, mida see sõlm vajab. Kompilaator ei lase meil ehitada ebapiisava tüübiga objekti (Cake), kuna iga teenusetunnus deklareerib piirangu Config tüüp. Samuti ei saa me sõlme käivitada ilma täielikku konfiguratsiooni esitamata.
Sõlme aadressi eraldusvõime
Ühenduse loomiseks vajame iga sõlme jaoks tõelist hostiaadressi. See võib olla teada hiljem kui konfiguratsiooni muud osad. Seetõttu vajame viisi sõlme ID ja selle tegeliku aadressi vahelise vastendamiseks. See kaardistamine on funktsioon:
case class NodeAddress[NodeId](host: Uri.Host)
trait AddressResolver[F[_]] {
def resolve[NodeId](nodeId: NodeId): F[NodeAddress[NodeId]]
}Sellise funktsiooni rakendamiseks on mitu võimalikku viisi.
- Kui me teame tegelikke aadresse enne juurutamist, sõlme hostide käivitamise ajal, saame genereerida Scala koodi tegelike aadressidega ja käivitada pärast seda ehitust (mis kontrollib kompileerimise aega ja käivitab seejärel integratsioonitestide komplekti). Sel juhul on meie kaardistamisfunktsioon staatiliselt tuntud ja seda saab lihtsustada näiteks a
Map[NodeId, NodeAddress]. - Mõnikord saame tegelikud aadressid alles hiljem, kui sõlm on tegelikult käivitatud, või meil pole veel käivitamata sõlmede aadresse. Sel juhul võib meil olla avastamisteenus, mis käivitatakse enne kõiki teisi sõlme ja iga sõlm võib selles teenuses oma aadressi reklaamida ja sõltuvusi tellida.
- Kui saame muuta
/etc/hosts, saame kasutada eelmääratletud hostinimesid (ntmy-project-main-nodejaecho-backend) ja seostage see nimi juurutamise ajal IP-aadressiga.
Selles postituses me neid juhtumeid üksikasjalikumalt ei käsitle. Tegelikult on meie mänguasja näites kõigil sõlmedel sama IP-aadress - 127.0.0.1.
Selles postituses käsitleme kahte hajutatud süsteemi paigutust:
- Ühe sõlme paigutus, kus kõik teenused on paigutatud ühele sõlmele.
- Kahe sõlme paigutus, kus teenus ja klient asuvad erinevates sõlmedes.
Konfiguratsioon a paigutus on järgmine:
Ühe sõlme konfiguratsioon
object SingleNodeConfig extends EchoConfig[String]
with EchoClientConfig[String] with FiniteDurationLifecycleConfig
{
case object Singleton // identifier of the single node
// configuration of server
type NodeId = Singleton.type
def nodeId = Singleton
/** Type safe service port specification. */
override def portNumber: PortNumber = 8088
// configuration of client
/** We'll use the service provided by the same host. */
def echoServiceDependency = echoService
override def testMessage: UrlPathElement = "hello"
def pollInterval: FiniteDuration = 1.second
// lifecycle controller configuration
def lifetime: FiniteDuration = 10500.milliseconds // additional 0.5 seconds so that there are 10 requests, not 9.
}Siin loome ühe konfiguratsiooni, mis laiendab nii serveri kui ka kliendi konfiguratsiooni. Samuti konfigureerime elutsükli kontrolleri, mis tavaliselt lõpetab kliendi ja serveri pärast seda lifetime intervall möödub.
Sama teenuse juurutuste ja konfiguratsioonide komplekti saab kasutada kahe eraldi sõlmega süsteemi paigutuse loomiseks. Peame lihtsalt looma vastavate teenustega:
Kahe sõlme konfiguratsioon
object NodeServerConfig extends EchoConfig[String] with SigTermLifecycleConfig
{
type NodeId = NodeIdImpl
def nodeId = NodeServer
override def portNumber: PortNumber = 8080
}
object NodeClientConfig extends EchoClientConfig[String] with FiniteDurationLifecycleConfig
{
// NB! dependency specification
def echoServiceDependency = NodeServerConfig.echoService
def pollInterval: FiniteDuration = 1.second
def lifetime: FiniteDuration = 10500.milliseconds // additional 0.5 seconds so that there are 10 request, not 9.
def testMessage: String = "dolly"
}Vaadake, kuidas me sõltuvust määrame. Mainime teise sõlme pakutavat teenust praeguse sõlme sõltuvusena. Sõltuvustüüpi kontrollitakse, kuna see sisaldab protokolli kirjeldavat fantoomtüüpi. Ja käitusajal on meil õige sõlme ID. See on kavandatud konfiguratsioonimeetodi üks olulisi aspekte. See annab meile võimaluse määrata port ainult üks kord ja veenduda, et viitame õigele pordile.
Kahe sõlme rakendamine
Selle konfiguratsiooni jaoks kasutame täpselt samu teenuste rakendusi. Ei mingeid muudatusi üldse. Loome aga kaks erinevat sõlmerakendust, mis sisaldavad erinevaid teenuseid:
object TwoJvmNodeServerImpl extends ZeroServiceImpl[IO] with EchoServiceService with SigIntLifecycleServiceImpl {
type Config = EchoConfig[String] with SigTermLifecycleConfig
}
object TwoJvmNodeClientImpl extends ZeroServiceImpl[IO] with EchoClientService with FiniteDurationLifecycleServiceImpl {
type Config = EchoClientConfig[String] with FiniteDurationLifecycleConfig
}Esimene sõlm rakendab serverit ja see vajab ainult serveripoolset konfiguratsiooni. Teine sõlm rakendab klienti ja vajab konfiguratsiooni teist osa. Mõlemad sõlmed nõuavad teatud eluea spetsifikatsiooni. Selle postiteenuse sõlmel on lõpmatu eluiga, mida saab kasutades lõpetada SIGTERM, samas kui kajaklient lõpeb pärast konfigureeritud piiratud kestust. Vaata üksikasjad.
Üldine arendusprotsess
Vaatame, kuidas see lähenemisviis muudab konfiguratsiooniga töötamise viisi.
Konfiguratsioon koodina kompileeritakse ja see loob artefakti. Tundub mõistlik eraldada konfiguratsiooniartefaktid muudest koodiartefaktidest. Sageli võib meil olla palju konfiguratsioone samal koodibaasil. Ja loomulikult võib meil olla erinevatest konfiguratsiooniharudest mitu versiooni. Konfiguratsioonis saame valida konkreetsed teekide versioonid ja see jääb konstantseks alati, kui seda konfiguratsiooni juurutame.
Konfiguratsioonimuudatusest saab koodimuutus. Seega peaks see olema hõlmatud sama kvaliteedi tagamise protsessiga:
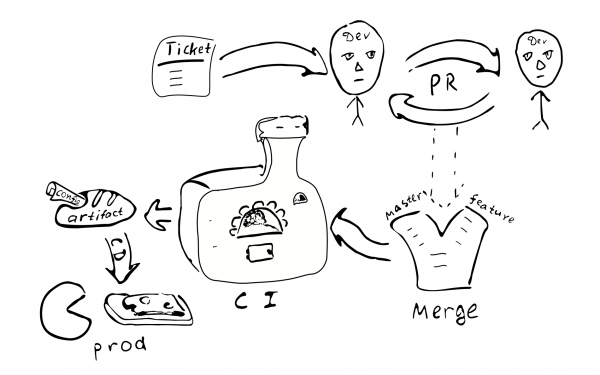
Pilet -> PR -> ülevaade -> ühendamine -> pidev integreerimine -> pidev kasutuselevõtt
Sellel lähenemisel on järgmised tagajärjed:
- Konfiguratsioon on konkreetse süsteemi eksemplari jaoks ühtne. Tundub, et sõlmede vahel ei saa kuidagi valesti ühendust luua.
- Konfiguratsiooni muutmine ainult ühes sõlmes pole lihtne. Tundub ebamõistlik sisse logida ja mõnda tekstifaili muuta. Seega muutub konfiguratsiooni triiv vähem võimalikuks.
- Väikseid konfiguratsioonimuudatusi pole lihtne teha.
- Enamik konfiguratsioonimuudatusi järgib sama arendusprotsessi ja see läbib mõne ülevaatuse.
Kas vajame tootmise seadistamiseks eraldi hoidlat? Tootmiskonfiguratsioon võib sisaldada tundlikku teavet, mida sooviksime hoida paljudele inimestele kättesaamatus kohas. Seega tasub hoida eraldi piiratud juurdepääsuga hoidlat, mis sisaldab tootmiskonfiguratsiooni. Võime konfiguratsiooni jagada kaheks osaks – üks, mis sisaldab tootmise kõige avatumaid parameetreid, ja teine, mis sisaldab konfiguratsiooni salajast osa. See võimaldaks enamikule arendajatest juurdepääsu enamikule parameetritele, piirates samas juurdepääsu tõeliselt tundlikele asjadele. Seda on lihtne saavutada parameetrite vaikeväärtustega vahepealsete tunnuste abil.
Variatsioonid
Vaatame pakutud lähenemisviisi plusse ja miinuseid võrreldes teiste konfiguratsioonihaldusmeetoditega.
Kõigepealt loetleme mõned alternatiivid pakutud konfiguratsiooni käsitlemise viiside erinevatele aspektidele:
- Tekstifail sihtmasinas.
- Tsentraliseeritud võtmeväärtuste salvestus (nt
etcd/zookeeper). - Alamprotsessi komponendid, mida saab ilma protsessi taaskäivitamata ümber konfigureerida/taaskäivitada.
- Konfiguratsioon väljaspool artefakti ja versioonikontrolli.
Tekstifail annab ad hoc paranduste osas mõningast paindlikkust. Süsteemi administraator saab sihtsõlme sisse logida, teha muudatusi ja lihtsalt teenuse taaskäivitada. Suuremate süsteemide jaoks ei pruugi see nii hea olla. Muudatusest ei jää jälgi. Muudatust ei vaata üle teine silmapaar. Võib olla raske välja selgitada, mis muutuse põhjustas. Seda ei ole testitud. Hajutatud süsteemi vaatenurgast võib administraator lihtsalt unustada mõne muu sõlme konfiguratsiooni värskendamise.
(Btw, kui lõpuks on vaja hakata kasutama teksti konfiguratsioonifaile, peame lisama ainult parseri + validaatori, mis suudavad sama luua Config tüüp ja sellest piisaks tekstikonfiguratsioonide kasutamise alustamiseks. See näitab ka, et kompileerimisaja konfiguratsiooni keerukus on veidi väiksem kui tekstipõhiste konfiguratsioonide keerukus, kuna tekstipõhises versioonis vajame lisakoodi.)
Tsentraliseeritud võtmeväärtuste salvestus on hea mehhanism rakenduse metaparameetrite levitamiseks. Siin peame mõtlema, mida peame konfiguratsiooniväärtusteks ja mis on lihtsalt andmed. Antud funktsioon C => A => B nimetame tavaliselt harva muutuvaid väärtusi C "konfiguratsioon", samas kui andmeid muudetakse sageli A - lihtsalt sisestage andmed. Funktsiooni konfiguratsioon tuleks anda varem kui andmed A. Seda ideed arvestades võime öelda, et konfiguratsiooniandmete eristamiseks lihtsalt andmetest saab kasutada eeldatavat muutuste sagedust. Samuti pärinevad andmed tavaliselt ühest allikast (kasutaja) ja konfiguratsioon teisest allikast (administraator). Parameetritega tegelemine, mida saab pärast initsialiseerimisprotsessi muuta, suurendab rakenduse keerukust. Selliste parameetrite puhul peame käsitlema nende edastamismehhanismi, sõelumist ja valideerimist ning valede väärtuste käsitlemist. Seetõttu peaksime programmi keerukuse vähendamiseks vähendama parameetrite arvu, mis võivad käitusajal muutuda (või isegi kõrvaldada need täielikult).
Selle postituse vaatenurgast peaksime eristama staatilisi ja dünaamilisi parameetreid. Kui teenindusloogika nõuab mõne parameetri harva muutmist käitusajal, siis võime neid nimetada dünaamilisteks parameetriteks. Vastasel juhul on need staatilised ja neid saab kavandatud lähenemisviisi abil konfigureerida. Dünaamilise ümberkonfigureerimise jaoks võib vaja minna teisi lähenemisviise. Näiteks võib süsteemi osi taaskäivitada uute konfiguratsiooniparameetritega sarnaselt hajutatud süsteemi eraldi protsesside taaskäivitamisele.
(Minu tagasihoidlik arvamus on vältida käitusaja ümberseadistamist, kuna see muudab süsteemi keerukamaks.
Võib-olla oleks lihtsam protsesside taaskäivitamisel lihtsalt OS-i toele loota. Kuigi see ei pruugi alati võimalik olla.)
Üks staatilise konfiguratsiooni kasutamise oluline aspekt, mis mõnikord paneb inimesed (ilma muude põhjusteta) dünaamilist konfigureerimist kaaluma, on teenuse seisak konfiguratsiooni värskendamise ajal. Tõepoolest, kui peame staatilist konfiguratsiooni muutma, peame süsteemi taaskäivitama, et uued väärtused muutuksid tõhusaks. Nõuded seisakuajale on erinevate süsteemide puhul erinevad, seega ei pruugi see olla nii kriitiline. Kui see on kriitiline, peame süsteemi taaskäivitamist ette planeerima. Näiteks võiksime rakendada . Selle stsenaariumi korral käivitame iga kord, kui meil on vaja süsteemi taaskäivitada, paralleelselt süsteemi uue eksemplari, seejärel lülitame sellele ELB-i, laseme samal ajal vanal süsteemil olemasolevate ühenduste teenindamise lõpule viia.
Aga konfiguratsiooni hoidmine versioonistatud artefakti sees või väljaspool? Konfiguratsiooni hoidmine artefakti sees tähendab enamikul juhtudel, et see konfiguratsioon on läbinud sama kvaliteedi tagamise protsessi nagu teised artefaktid. Seega võib olla kindel, et konfiguratsioon on kvaliteetne ja usaldusväärne. Vastupidi, konfiguratsioon eraldi failis tähendab, et pole jälgi selle kohta, kes ja miks selles failis muudatusi tegi. Kas see on oluline? Usume, et enamiku tootmissüsteemide jaoks on parem stabiilne ja kvaliteetne konfiguratsioon.
Artefakti versioon võimaldab teada saada, millal see loodi, milliseid väärtusi see sisaldab, millised funktsioonid on lubatud/keelatud, kes vastutas iga konfiguratsioonimuudatuse tegemise eest. Konfiguratsiooni hoidmine artefakti sees võib nõuda pingutusi ja see on disaini valik.
Plussid Miinused
Siinkohal tahaksime välja tuua mõned pakutud lähenemisviisi eelised ja arutada mõningaid puudusi.
Eelised
Täieliku hajutatud süsteemi kompileeritava konfiguratsiooni omadused:
- Konfiguratsiooni staatiline kontroll. See annab kõrge kindlustunde, et konfiguratsioon on tüübipiiranguid arvestades õige.
- Rikkalik konfiguratsioonikeel. Tavaliselt piirduvad muud konfiguratsioonimeetodid maksimaalselt muutuva asendusega.
Scalat kasutades saab konfiguratsiooni paremaks muutmiseks kasutada laias valikus keelefunktsioone. Näiteks võime kasutada tunnuseid vaikeväärtuste pakkumiseks, objekte erineva ulatuse määramiseks, millele saame viidatavals on defineeritud ainult üks kord välissfääris (DRY). Võimalik on kasutada sõnasõnalisi jadasid või teatud klasside esinemisjuhte (Seq,MapJne). - DSL. Scalal on korralik tugi DSL-i kirjutajatele. Nende funktsioonide abil saab luua mugavama ja lõppkasutajasõbralikuma konfiguratsioonikeele, nii et lõplik konfiguratsioon on vähemalt domeeni kasutajatele loetav.
- Sõlmede terviklikkus ja sidusus. Üks kogu hajutatud süsteemi ühes kohas konfigureerimise eeliseid on see, et kõik väärtused määratletakse rangelt üks kord ja seejärel kasutatakse neid uuesti kõigis kohtades, kus neid vajame. Sisestage ka turvalise pordi deklaratsioonid, mis tagavad, et süsteemi sõlmed räägivad kõigis võimalikes õigetes konfiguratsioonides sama keelt. Sõlmede vahel on selged sõltuvused, mis muudab mõne teenuse pakkumise unustamise raskeks.
- Muudatuste kõrge kvaliteet. Üldine lähenemine konfiguratsioonimuutuste läbimisele tavapärase PR-protsessi kaudu kehtestab kõrged kvaliteedistandardid ka konfiguratsioonis.
- Samaaegsed konfiguratsioonimuudatused. Kui teeme konfiguratsioonis muudatusi, tagab automaatne juurutamine, et kõiki sõlme värskendatakse.
- Rakenduse lihtsustamine. Rakendus ei pea konfiguratsiooni sõeluma ja kinnitama ega käsitlema valesid konfiguratsiooniväärtusi. See lihtsustab üldist rakendust. (Teatud keerukus on konfiguratsioonis endas, kuid see on teadlik kompromiss ohutuse suunas.) Tavakonfiguratsiooni juurde naasmine on üsna lihtne – lihtsalt lisage puuduvad osad. Lihtsam on alustada kompileeritud konfiguratsiooniga ja lükata täiendavate osade juurutamine mõnele hilisemale ajale.
- Versioonitud konfiguratsioon. Kuna konfiguratsioonimuudatused järgivad sama arendusprotsessi, saame tulemuseks ainulaadse versiooniga artefakti. See võimaldab meil vajadusel konfiguratsiooni tagasi lülitada. Saame isegi juurutada konfiguratsiooni, mida kasutati aasta tagasi ja see töötab täpselt samamoodi. Stabiilne konfiguratsioon parandab hajutatud süsteemi prognoositavust ja töökindlust. Konfiguratsioon on kompileerimise ajal fikseeritud ja seda ei saa tootmissüsteemis kergesti rikkuda.
- Modulaarsus. Kavandatav raamistik on modulaarne ja mooduleid saab kombineerida mitmel viisil
toetada erinevaid konfiguratsioone (seadistusi/paigutusi). Eelkõige on võimalik kasutada väikesemahulist ühe sõlme paigutust ja suuremahulist mitme sõlme seadistust. On mõistlik kasutada mitut tootmispaigutust. - Testimine. Testimise eesmärgil võib rakendada näidisteenust ja kasutada seda sõltuvusena tüübikindlal viisil. Samaaegselt saab säilitada mõnda erinevat testimispaigutust, kus erinevad osad on asendatud pilkadega.
- Integratsiooni testimine. Mõnikord on hajutatud süsteemides integratsioonitestide käivitamine keeruline. Kasutades kirjeldatud lähenemisviisi tervikliku hajutatud süsteemi turvalise konfiguratsiooni tippimiseks, saame juhtida kõiki hajutatud osi ühes serveris juhitaval viisil. Olukorda on lihtne jäljendada
kui üks teenustest muutub kättesaamatuks.
Puudused
Koostatud konfiguratsiooni lähenemisviis erineb "tavalisest" konfiguratsioonist ja see ei pruugi vastata kõikidele vajadustele. Siin on mõned koostatud konfiguratsiooni puudused:
- Staatiline konfiguratsioon. See ei pruugi kõigi rakenduste jaoks sobida. Mõnel juhul on konfiguratsioon tootmises vaja kiiresti fikseerida, jättes kõrvale kõik ohutusmeetmed. See lähenemine muudab selle keerulisemaks. Kompileerimine ja ümberpaigutamine on vajalik pärast konfiguratsiooni muutmist. See on nii omadus kui ka koormus.
- Konfiguratsiooni genereerimine. Kui konfiguratsiooni genereerib mõni automatiseerimistööriist, nõuab see lähenemine hilisemat kompileerimist (mis võib omakorda ebaõnnestuda). Selle täiendava sammu integreerimine ehitussüsteemi võib nõuda täiendavaid jõupingutusi.
- Instrumendid. Tänapäeval on kasutusel palju tööriistu, mis põhinevad tekstipõhistel konfiguratsioonidel. Mõned neist
ei kehti konfiguratsiooni koostamisel. - Vaja on mõtteviisi muutust. Arendajad ja DevOps tunnevad tekstikonfiguratsioonifaile. Konfiguratsiooni koostamise idee võib neile tunduda kummaline.
- Enne kompileeritava konfiguratsiooni kasutuselevõttu on vajalik kvaliteetne tarkvara arendusprotsess.
Rakendatud näitel on mõned piirangud:
- Kui pakume lisakonfiguratsiooni, mida sõlme rakendamine ei nõua, ei aita kompilaator meil puuduvat rakendust tuvastada. Seda saab lahendada kasutades
HListvõi ADT-d (juhtumiklassid) sõlmede konfigureerimiseks tunnuste ja koogimustri asemel. - Peame konfiguratsioonifailis esitama mõne katlaplaadi: (
package,import,objectdeklaratsioonid;
override def's parameetrite jaoks, millel on vaikeväärtused). Seda võib osaliselt lahendada DSL-i abil. - Selles postituses me ei käsitle sarnaste sõlmede klastrite dünaamilist ümberkonfigureerimist.
Järeldus
Selles postituses oleme arutanud ideed esitada konfiguratsioon otse lähtekoodis tüübikindlal viisil. Seda lähenemisviisi saab kasutada paljudes rakendustes xml- ja muude tekstipõhiste konfiguratsioonide asendajana. Vaatamata sellele, et meie näidet on Scalas rakendatud, saab seda tõlkida ka teistesse kompileeritavatesse keeltesse (nt Kotlin, C#, Swift jne). Seda lähenemist võiks proovida mõnes uues projektis ja kui see hästi ei sobi, minna üle vanamoodsale.
Loomulikult nõuab kompileeritav konfiguratsioon kvaliteetset arendusprotsessi. Vastutasuks lubab see pakkuda sama kvaliteetset ja tugevat konfiguratsiooni.
Seda lähenemisviisi saab laiendada mitmel viisil:
- Makrosid saab kasutada konfiguratsiooni valideerimiseks ja äriloogika piirangute tõrgete korral kompileerimise ajal ebaõnnestuda.
- DSL-i saab rakendada konfiguratsiooni esitamiseks domeeni kasutajasõbralikul viisil.
- Dünaamiline ressursside haldamine koos automaatsete konfiguratsiooni kohandamisega. Näiteks kui kohandame klastri sõlmede arvu, võiksime soovida, et (1) sõlmed saaksid veidi muudetud konfiguratsiooni; (2) klastrihaldur uute sõlmede teabe saamiseks.
tänan
Tahaksin tänada Andrei Saksonovit, Pavel Popovit ja Anton Nehajevit inspireeriva tagasiside eest selle postituse mustandile, mis aitas mul seda selgemaks teha.
Allikas: www.habr.com
