


SQL, mis võiks olla lihtsam? Igaüks meist oskab kirjutada lihtsa päringu – me trükime valima, loetleme vajalikud veerud, seejärel Rohkem kui, tabeli nimi, mõned tingimused kus ja ongi kõik – kasulikud andmed on meie taskus ja (peaaegu) olenemata sellest, milline andmebaasihaldussüsteem parasjagu kapoti all on (või äkki ). Seetõttu saab peaaegu iga andmeallikaga (nii relatsioonilise kui ka mitte) töötamist vaadelda tavalise koodi vaatenurgast (koos kõige sellega kaasnevaga - versioonikontroll, koodi ülevaade, staatiline analüüs, automaatsed testid ja kõik muu). Ja see ei puuduta ainult andmeid endid, skeeme ja migratsioone, vaid üldiselt kogu salvestusruumi eluiga. Selles artiklis räägime igapäevastest ülesannetest ja probleemidest erinevate andmebaasidega töötamisel "andmebaas kui kood" kontseptsiooni all.
Ja alustame kohe algusest Esimesed "SQL vs ORM" tüüpi lahingud märgati juba aastal .
Objekti-relatsiooniline kaardistamine
ORM-i pooldajad hindavad traditsiooniliselt arenduse kiirust ja lihtsust, sõltumatust andmebaasihaldussüsteemist ja puhast koodi. Paljude jaoks on andmebaasiga (ja sageli ka andmebaasiga endaga) töötamise kood...
tavaliselt näeb välja umbes selline…
@Entity
@Table(name = "stock", catalog = "maindb", uniqueConstraints = {
@UniqueConstraint(columnNames = "STOCK_NAME"),
@UniqueConstraint(columnNames = "STOCK_CODE") })
public class Stock implements java.io.Serializable {
@Id
@GeneratedValue(strategy = IDENTITY)
@Column(name = "STOCK_ID", unique = true, nullable = false)
public Integer getStockId() {
return this.stockId;
}
...Mudel on kaetud nutikate annotatsioonidega ja kusagil kulisside taga genereerib ja käivitab vapra ORM-i abil tohutult SQL-koodi. Muide, arendajad püüavad oma andmebaasist eraldada kilomeetrite kaupa abstraktsioone, mis viitab mingile... .
Teisel pool barrikaade märgivad puhta "käsitsi tehtud" SQL-i pooldajad võimet pigistada oma andmebaasihaldussüsteemist välja kõik mahlad ilma täiendavate kihtide ja abstraktsioonideta. Selle tulemusel tekivad "andmekesksed" projektid, kus andmebaasi haldavad spetsiaalselt koolitatud inimesed (ehk "basistid", e.n. "basoviki", e.n. "basemenshchiki" jne) ja arendajad peavad ainult valmisvaateid ja salvestatud protseduure "välja tõmbama", ilma detailidesse laskumata.
Mis siis, kui võtaksite parima mõlemast maailmast? Nagu seda tehakse imelises instrumendis, millel on elujaatav nimi. Toon oma vabas tõlkes paar rida üldisest kontseptsioonist ja saate sellega lähemalt tutvuda. .
Clojure on suurepärane keel andmeliideste (DSL) loomiseks, aga SQL on juba suurepärane DSL ja me ei vaja veel ühte. S-avaldised on suurepärased, aga need ei lisa siia midagi uut. Sulgud jäävad alles sulgude pärast. Ei nõustu? Seejärel oota, kuni andmebaasi abstraktsioon hakkab lekkima ja hakkad funktsiooniga võitlema. (raw-sql)
Mida siis teha? Jätame SQL-i tavaliseks SQL-iks – üks fail päringu kohta:
-- name: users-by-country
select *
from users
where country_code = :country_code... ja seejärel loe see fail läbi, muutes selle tavaliseks Clojure'i funktsiooniks:
(defqueries "some/where/users_by_country.sql"
{:connection db-spec})
;;; A function with the name `users-by-country` has been created.
;;; Let's use it:
(users-by-country {:country_code "GB"})
;=> ({:name "Kris" :country_code "GB" ...} ...)Järgides põhimõtet "SQL eraldi, Clojure eraldi", saate:
- Süntaksilisi üllatusi pole. Sinu andmebaas (nagu iga teinegi) pole 100% SQL-iga ühilduv – aga Yesql-il pole sellest mingit huvi. Sa ei raiska kunagi aega SQL-iga samaväärse süntaksiga funktsioonide otsimisele. Sa ei pea kunagi funktsiooni juurde tagasi pöörduma. (raw-sql "mõned('funky'::SÜNTAKS)")).
- Parem redaktori tugi. Teie redaktoril on juba suurepärane SQL-i tugi. SQL-i SQL-ina salvestades saate seda lihtsalt kasutada.
- Käskude ühilduvus: teie andmebaasiadministraatorid saavad lugeda ja kirjutada teie Clojure'i projektis kasutatavat SQL-i.
- Lihtsam jõudluse häälestamine. Kas peate koostama plaani probleemse päringu jaoks? See pole probleem, kui teie päring on puhas SQL.
- Päringute taaskasutamine: lohista need samad SQL-failid teise projekti, sest see on lihtsalt tavaline SQL – lihtsalt jaga seda.
Minu arvates on idee väga lahe ja samal ajal väga lihtne, tänu millele on projekt palju populaarsust kogunud. paljudes keeltes. Ja me püüame rakendada sarnast filosoofiat, mis eraldab SQL-koodi kõigest muust, mis ulatub kaugemale ORM-ist.
IDE ja andmebaasi haldurid
Alustame lihtsa igapäevase ülesandega. Tihti peame andmebaasist otsima objekte, näiteks leidma skeemist tabeli ja uurima selle struktuuri (milliseid veerge, võtmeid, indekseid, piiranguid jne kasutatakse). Ja igalt graafiliselt IDE-lt või andmebaasihaldurilt ootame ennekõike just neid võimalusi. Et see oleks kiire ja te ei peaks poolt tundi ootama, kuni kuvatakse aken vajaliku teabega (eriti aeglase ühenduse korral kaugandmebaasiga), ning samal ajal, et saadud teave oleks värske ja asjakohane, mitte vahemällu salvestatud vana kraam. Pealegi, mida keerulisem ja suurem on andmebaas ja mida rohkem neid on, seda raskem on seda teha.
Aga tavaliselt viskan hiire kaugele ja kirjutan lihtsalt koodi. Oletame, et teil on vaja välja selgitada, millised tabelid (ja milliste omadustega) sisalduvad "HR" skeemis. Enamikus andmebaasihaldussüsteemides saab soovitud tulemuse saavutada sellise lihtsa päringuga information_schema abil:
select table_name
, ...
from information_schema.tables
where schema = 'HR'Andmebaasist oleneb selliste viitetabelite sisu iga andmebaasihaldussüsteemi võimalustest. Näiteks MySQL-i puhul saab samast viiteallikast hankida sellele andmebaasihaldussüsteemile omased tabeliparameetrid:
select table_name
, storage_engine -- Используемый "движок" ("MyISAM", "InnoDB" etc)
, row_format -- Формат строки ("Fixed", "Dynamic" etc)
, ...
from information_schema.tables
where schema = 'HR'Oracle ei tea information_schema't, aga tal on ja suuri probleeme pole:
select table_name
, pct_free -- Минимум свободного места в блоке данных (%)
, pct_used -- Минимум используемого места в блоке данных (%)
, last_analyzed -- Дата последнего сбора статистики
, ...
from all_tables
where owner = 'HR'ClickHouse pole erand:
select name
, engine -- Используемый "движок" ("MergeTree", "Dictionary" etc)
, ...
from system.tables
where database = 'HR'Midagi sarnast saab teha ka Cassandras (kus tabelite asemel on veeruperekonnad ja skeemide asemel võtmeruumid):
select columnfamily_name
, compaction_strategy_class -- Стратегия сборки мусора
, gc_grace_seconds -- Время жизни мусора
, ...
from system.schema_columnfamilies
where keyspace_name = 'HR'Enamiku teiste andmebaaside puhul saate samuti sarnaseid päringuid teha (isegi Mongol on üks olemas , mis sisaldab teavet kõigi süsteemis olevate kogude kohta).
Muidugi saab seda meetodit kasutada teabe saamiseks mitte ainult tabelite, vaid üldiselt mis tahes objekti kohta. Perioodiliselt jagavad lahked inimesed sellist koodi erinevate andmebaaside jaoks, näiteks Habri artiklite sarjas "Funktsioonid PostgreSQL-i andmebaaside dokumenteerimiseks" (, , ). Muidugi pole kogu selle päringute mäe peas hoidmine ja pidev tippimine "nii väga" lõbus, seega on mul oma lemmik IDE/redaktoris eelnevalt ettevalmistatud komplekt koodijuppe sageli kasutatavate päringute jaoks ja jääb üle vaid objektide nimed malli tippida.
Seetõttu on see navigeerimis- ja objektide otsimise meetod palju paindlikum, säästab palju aega, võimaldab teil saada täpselt seda teavet ja sellisel kujul, nagu te seda praegu vajate (nagu näiteks postituses kirjeldatud). ).
Objektidega toimingud
Pärast vajalike objektide leidmist ja uurimist on aeg nendega midagi kasulikku ette võtta. Loomulikult ka sõrmi klaviatuurilt tõstmata.
Pole saladus, et tabeli kustutamine näeb peaaegu kõigis andmebaasides sama välja:
drop table hr.personsAga tabeli loomisega on asi juba huvitavam. Peaaegu iga andmebaasihaldussüsteem (sealhulgas paljud NoSQL-id) saab ühel või teisel kujul "tabelit luua" ja selle põhiosa ei erine isegi palju (nimi, veergude loend, andmetüübid), kuid muud detailid võivad dramaatiliselt erineda ja sõltuda konkreetse andmebaasihaldussüsteemi sisemisest struktuurist ja võimalustest. Minu lemmiknäide - Oracle'i dokumentatsioonis on "tabeli loomise" süntaksi jaoks ainult "paljad" BNF-id. Teistel andmebaasihaldussüsteemidel on tagasihoidlikumad võimalused, kuid igal neist on ka palju huvitavaid ja ainulaadseid funktsioone tabelite loomiseks (, , , ). On ebatõenäoline, et mõni teise IDE (eriti universaalse) graafiline "viisard" suudab kõiki neid võimalusi täielikult katta ja kui suudab, siis pole see nõrganärvilistele mõeldud. Samal ajal on õigesti ja õigeaegselt kirjutatud operaator loo tabel võimaldab teil neid kõiki hõlpsalt kasutada, muutes teie andmete salvestamise ja neile juurdepääsu usaldusväärseks, optimaalseks ja võimalikult mugavaks.
Samuti on paljudel andmebaasisüsteemidel oma spetsiifilised objektitüübid, mis teistes andmebaasisüsteemides saadaval pole. Lisaks saame toiminguid teha mitte ainult andmebaasiobjektidega, vaid ka andmebaasisüsteemiga endaga, näiteks protsessi "tappa", mälu vabastada, jälgimist lubada, lülituda kirjutuskaitstud režiimi ja palju muud.
Nüüd joonistame natuke
Üks levinumaid ülesandeid on andmebaasiobjektidega diagrammi loomine, objektide ja nendevaheliste seoste nägemine ilusal pildil. Seda saab teha peaaegu iga graafiline IDE, eraldi "käsurea" utiliidid, spetsiaalsed graafilised tööriistad ja modelleerijad. Need joonistavad teie eest midagi "nii hästi kui suudavad" ja saate seda protsessi vaid veidi mõjutada konfiguratsioonifaili mitme parameetri või liidese märkeruutude abil.
Kuid seda probleemi saab lahendada palju lihtsamalt, paindlikumalt ja elegantsemalt ning loomulikult koodi abil. Mis tahes keerukusega diagrammide koostamiseks on meil mitu spetsiaalset märgistuskeelt (DOT, GraphML jne) ja neile lisaks - terve hulk rakendusi (GraphViz, PlantUML, Mermaid), mis suudavad selliseid juhiseid lugeda ja visualiseerida erinevates vormingutes. Noh, ja me juba teame, kuidas saada teavet objektide ja nendevaheliste seoste kohta.
Siin on kiire näide sellest, kuidas see PlantUML-i kasutades välja võiks näha ja (vasakul on SQL-päring, mis genereerib PlantUML-i jaoks vajaliku käsu, ja paremal on tulemus):
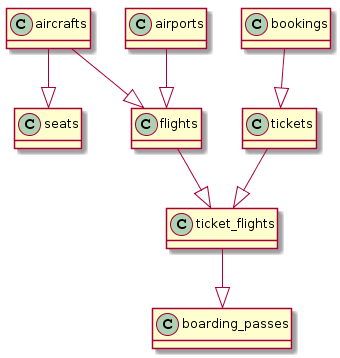
select '@startuml'||chr(10)||'hide methods'||chr(10)||'hide stereotypes' union all
select distinct ccu.table_name || ' --|> ' ||
tc.table_name as val
from table_constraints as tc
join key_column_usage as kcu
on tc.constraint_name = kcu.constraint_name
join constraint_column_usage as ccu
on ccu.constraint_name = tc.constraint_name
where tc.constraint_type = 'FOREIGN KEY'
and tc.table_name ~ '.*' union all
select '@enduml'Ja kui sa natuke proovid, siis selle põhjal võite saada midagi väga sarnast päris ER-diagrammile:
SQL-päring on veidi keerulisem
-- Шапка
select '@startuml
!define Table(name,desc) class name as "desc" << (T,#FFAAAA) >>
!define primary_key(x) <b>x</b>
!define unique(x) <color:green>x</color>
!define not_null(x) <u>x</u>
hide methods
hide stereotypes'
union all
-- Таблицы
select format('Table(%s, "%s n information about %s") {'||chr(10), table_name, table_name, table_name) ||
(select string_agg(column_name || ' ' || upper(udt_name), chr(10))
from information_schema.columns
where table_schema = 'public'
and table_name = t.table_name) || chr(10) || '}'
from information_schema.tables t
where table_schema = 'public'
union all
-- Связи между таблицами
select distinct ccu.table_name || ' "1" --> "0..N" ' || tc.table_name || format(' : "A %s may haven many %s"', ccu.table_name, tc.table_name)
from information_schema.table_constraints as tc
join information_schema.key_column_usage as kcu on tc.constraint_name = kcu.constraint_name
join information_schema.constraint_column_usage as ccu on ccu.constraint_name = tc.constraint_name
where tc.constraint_type = 'FOREIGN KEY'
and ccu.constraint_schema = 'public'
and tc.table_name ~ '.*'
union all
-- Подвал
select '@enduml'
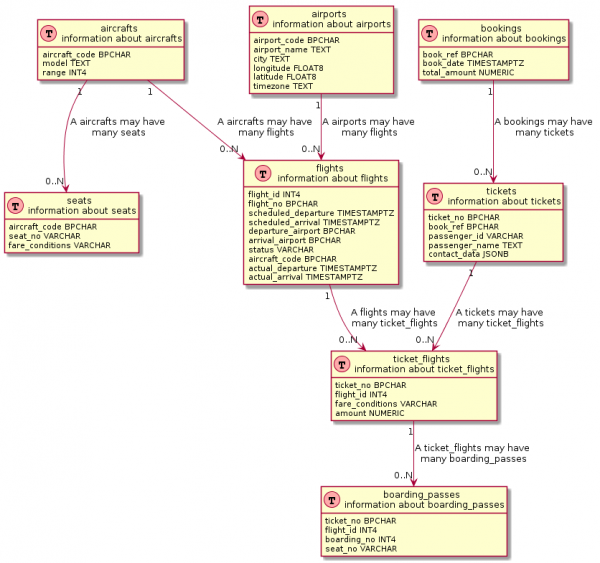
Kui lähemalt vaadata, siis paljud visualiseerimisvahendid kasutavad sarnaseid päringuid. Need päringud on aga tavaliselt sügavalt... , rääkimata nende mis tahes muutmisest.
Mõõdikud ja jälgimine
Liigume edasi traditsiooniliselt keerulise teema juurde – andmebaasi jõudluse jälgimine. Meenutan lühikest tõsielulugu, mida mulle rääkis „üks mu sõber“. Teise projekti kallal elas teatud võimas andmebaasiadministraator ja vähesed arendajad tundsid teda isiklikult või nägid teda isegi silmast silma (vaatamata sellele, et ta töötas kuulujuttude kohaselt kuskil naabermajas). Tunnil „X“, kui ühe suure jaemüüja tootmissüsteem hakkas taas „halvasti“ käituma, saatis ta vaikselt Oracle Enterprise Manageri graafikute ekraanipilte, millel ta „arusaadavuse“ huvides punase markeriga kriitilised kohad hoolikalt esile tõstis (see pehmelt öeldes ei aidanud palju). Ja just selle „fotokaardi“ järgi pidimegi tegutsema. Samal ajal polnud kellelgi ligipääsu väärtuslikule (mõlemas tähenduses) Enterprise Managerile, kuna süsteem on keeruline ja kallis, äkki „komistavad arendajad millegi otsa ja lõhuvad kõik“. Seetõttu leidsid arendajad „empiiriliselt“ aeglustuste koha ja põhjuse ning andsid välja paranduse. Kui DBA ähvardav kiri lähitulevikus uuesti ei tulnud, siis hingasid kõik kergendatult ja naasid oma praeguste ülesannete juurde (kuni järgmise Kirjani).
Kuid jälgimisprotsess võib tunduda lõbusam ja sõbralikum ning mis kõige tähtsam - kõigile kättesaadavam ja läbipaistvam. Vähemalt selle põhiosa, lisaks peamistele jälgimissüsteemidele (mis on kindlasti kasulikud ja paljudel juhtudel asendamatud). Iga andmebaasihaldussüsteem on tasuta ja täiesti tasuta ning valmis jagama teavet oma praeguse oleku ja jõudluse kohta. Samas "verises" Oracle'i andmebaasis saab peaaegu igasugust jõudluse kohta teavet süsteemivaadetest, protsessidest ja seanssidest kuni puhvermälu olekuni (näiteks , jaotis "Jälgimine"). PostgreSQL-il on ka terve hulk süsteemivaateid , eriti need, mis on iga andmebaasiadministraatori igapäevaelus hädavajalikud, näiteks , , MySQL-il on selleks otstarbeks isegi eraldi skeem. Ja Mongos on see sisse ehitatud. koondab jõudlusandmed süsteemikogumikku .
Seega, relvastatuna mõne mõõdikute kogujaga (Telegraf, Metricbeat, Collectd), mis suudab täita kohandatud SQL-päringuid, nende mõõdikute salvestusruumiga (InfluxDB, Elasticsearch, Timescaledb) ja visualiseerijaga (Grafana, Kibana), saate üsna kerge ja paindliku jälgimissüsteemi, mis on tihedalt integreeritud teiste süsteemiüleste mõõdikutega (näiteks rakendusserverist, operatsioonisüsteemist jne). Nagu näiteks pgwatch2-s, mis kasutab InfluxDB + Grafana paketti ja süsteemivaadete päringute komplekti, mis võib olla ka .
Kogusummas
Ja see on vaid ligikaudne nimekiri sellest, mida saab meie andmebaasiga tavalise SQL-koodi abil teha. Olen kindel, et leiate veel palju rakendusi, kirjutage kommentaaridesse. Ja me arutame, kuidas (ja mis kõige tähtsam, miks) seda kõike automatiseerida ja järgmisel korral oma CI/CD-torustikku lisada.
Allikas: www.habr.com
