

2015. aasta Alexey Lesovskõi ettekande "Sügav kaevamine PostgreSQL sisestatistika" tõlgendus
Ettekande autori teadanne: Tahan märkida, et see ettekande kuupäev on novembris 2015 — on möödunud üle 4 aasta ja palju on juhtunud. Ettekandes käsitletud versioon 9.4 ei ole enam toetatud. Viimase 4 aasta jooksul on ilmunud 5 uut versiooni, kus on palju uuendusi, parandusi ja muudatusi, mis puudutavad statistikat, ning osa materjalist on aja jooksul vananenud ja ei ole enam asjakohane. Ülevaatamisel püüdsin märkida neid kohti, et mitte eksitada sind, lugeja. Ma ei hakanud neid kohti ümber kirjutama, sest neid on väga palju ja see tooks lõpuks välja hoopis teistsuguse ettekande.
PostgreSQL andmebaas on ulatuslik süsteem, mille erinevad alamsüsteemid mõjutavad otse andmebaasi jõudlust. Töö käigus kogutakse statistikat ja teavet komponentide toimimise kohta, mis võimaldab hinnata PostgreSQL efektiivsust ja võtta meetmeid jõudluse parandamiseks. Kuid, selle teabe hulk on suur ja see esitatakse üsna lihtsustatud vormis. Selle teabe töötlemine ja tõlgendamine on tihti keeruline ülesanne, ning "loomaaed" tööriistu ja utiliite võib isegi kogenud DBA jaoks segadusse ajada.


Tere päevast! Minu nimi on Aleksei. Nagu Ilya ütles, räägin ma PostgreSQL statistika kohta.

PostgreSQL aktiivsuse statistika. PostgreSQL-l on kaks statistikat. Aktiivsuse statistika, millest juttu tuleb. Ja planeerija statistika andmete jaotuse kohta. Räägin just PostgreSQL aktiivsuse statistikast, mis võimaldab meil teha järeldusi jõudluse kohta ja selle parandamise võimalustest.
Räägin, kuidas tõhusalt kasutada statistikat erinevate probleemide lahendamiseks, mis teil on või võivad tekkida.

Mida ma ettekandes ei käsitle? Ettekandes ei puuduta ma planeerija statistikat, kuna see on eraldi teema eraldi ettekandes, kuidas andmeid andmebaasis hoitakse ja kuidas päringute planeerija saab aru nende andmete kvaliteedist ja kvantitatiivsest iseloomust.
Ja ei tule ülevaateid tööriistadest, ma ei hakka ühte toodet teisega võrreldes. Reklaami ei tule. Jätame selle kõrvale.

Ma tahan teile näidata, et statistika kasutamine on kasulik. See on vajalik. Selle kasutamine ei ole hirmus. Meie jaoks on vajalik ainult tavaline SQL ja põhiteadmised SQL-i kohta.
Ja räägime, millist statistikat valida probleemide lahendamiseks.

Kui vaatame PostgreSQL-i ja käivitame operatsioonisüsteemis protsesside vaatamiseks käsu, siis näeme "mustas kastis". Me näeme mingeid protsesse, mis midagi teevad, ja me saame nende nimede järgi enam-vähem aru, mida nad seal teevad, millega nad tegelevad. Kuid tegelikult on see must kast, me ei näe sisse.
Saame vaadata protsessori koormust top, saame vaadata mälukasutust mõne süsteemiteenuse abil, kuid PostgreSQL sisse vaadata me ei saa. Selleks on meil vaja teisi tööriistu.
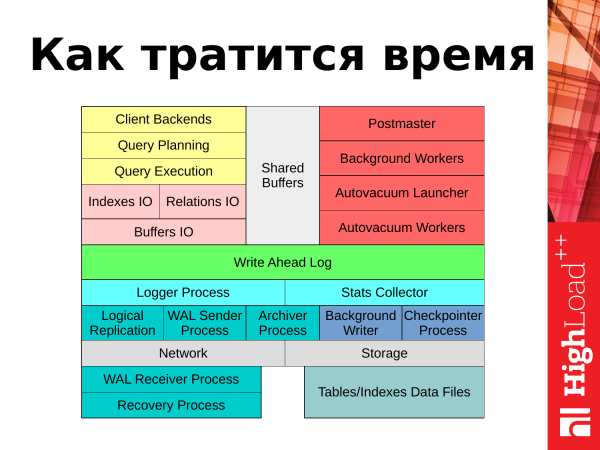
Ja edasi rääkides räägin, kuhu aeg läheb. Kui me kujutame PostgreSQL'i sellise skeemina, siis saame vastata, kuhu aeg kulub. See on kaks asja: kliendi rakenduste päringute töötlemine ja taustategevused, mida PostgreSQL täidab oma töövõime hoidmiseks.
Kui me vaatame vasakult ülemisest nurgast, saame jälgida, kuidas klientide päringud töödeldakse. Päring tuleb rakendusest ja edasise töö jaoks avatakse kliendi sessioon. Päring edastatakse planeerijale. Planeerija koostab päringu plaani. Saadetakse see täitmiseks edasi. Toimub mingisugune plokkide kaupa andmete sisestamine ja väljund, mis on seotud tabelite ja indeksitega. Vajalikud andmed loetakse ketastest mällu spetsiaalsesse ala "shared buffers". Päringu tulemused, kui need on uuendused või kustutamised, registreeritakse tehingute ajaloos WAL. Teatud statistiline teave jõuab logisse või statistika kogumise kollektorisse. Ja päringu tulemus antakse kinnituseks tagasi kliendile. Pärast seda saab klient kõik uuesti alustada uue päringuga.
Mis toimub meie taustategevuste ja taustaprotsessidega? Meil on mitu protsessi, mis tagavad süsteemi töökindluse ja hoiavad andmebaasi normaalses töörežiimis. Need protsessid kajastuvad ka aruandes: autovacuum, checkpointer, protsessid, mis on seotud replikeerimisega, taustakirjutaja. Käsitlen igaüht neist oma ettekande käigus.

Millised probleemid on statistika osas?
- Teavet on palju. PostgreSQL 9.4 pakub 109 meetrit statistikaandmete vaatamiseks. Siiski, kui andmebaasis on palju tabeleid, skeeme ja baase, tuleb kõik need meetrid korrutada vastava tabelite ja baaside arvuga. See tähendab, et teabe hulk kasvab veelgi. Ja selle sees on väga lihtne ära uppuda.
- Järgmine probleem on see, et statistika esitatakse loendureina. Kui me vaatame seda statistikat, näeme pidevalt kasvavaid loendureid. Ja kui ajavahemik alates statistika lähtestamisest on olnud väga pikk, näeme miljardilisi väärtusi. Need ei ütle meile midagi.
- Ajaloo puudumine. Kui teil on toimunud mingi tõrge, näiteks midagi kukkus 15-30 minutit tagasi, siis ei ole võimalik kasutada statistikat, et näha, mis toimus 15-30 minutit tagasi. See on probleem.
- PostgreSQLi sisseehitatud tööriistade puudumine on probleem. Tuuma arendajad ei paku mingit tööriista. Neil pole midagi sellist. Nad lihtsalt annavad statistika andmebaasi. Kasutage seda, esitage sellele päring, tehke, mida soovite.
- Kuna PostgreSQL-is ei ole sisseehitatud tööriista, on see põhjuseks teisele probleemile. Paljusid kolmanda osapoole tööriistu. Igal ettevõttel, kellel on rohkem-vähem oskuslikud töötajad, on oma programm. Ja lõpuks on kogukonnas palju tööriistu, mida saab statistika töötlemiseks kasutada. Ühes tööriistades on ühed võimalused, teistes aga teised, või on pakutud uusi funktsioone. Tekkib olukord, kus on vaja kasutada kahte, kolme või nelja tööriista, mis kattuvad omavahel ja pakuvad erinevaid funktsioone. See on väga ebameeldiv.

Mida sellest järeldada? On oluline osata statistikat otse võtta, et sõltuda mitte programmide töötlusest, või kuidagi ise neid programme parandada: lisada funktsioone, et saada enda kasu.
Ja on vajalikud põhilised SQL-teadmised. Et saada andmeid statistika kohta, tuleb koostada SQL päringud, st peate teadma, kuidas koostada select ja join.

Statistika pakub meile mitmeid asju. Need saab jagada kategooriatesse.
- Esimese kategooria alla kuuluvad sündmused, mis esinevad andmebaasis. See on, kui andmebaasi toimub mingi sündmus: päring, tabeli juurde pääsemine, automaatne tühjendamine, kommid, need kõik on sündmused. Vastavad sellele sündmusele loendurid suurenevad. Ja me saame neid sündmusi jälgida.
- Teine kategooria on objektide omadused, nagu tabelid ja andmebaasid. Neil on omadused. See on tabelite suurus. Saame jälgida tabelite suuruse kasvu, indeksite suurenemist. Saame vaadata muutusi dünaamikas.
- Ja kolmas kategooria on sündmusele kulutatud aeg. Päring on sündmus. Sellel on oma konkreetne kestuse mõõt. Siin see käivitus, seal see lõppes. Saame seda jälgida. Samuti jälgitakse diskilt lugemise või kirjutamise aega. Sellised asjad jälgitakse samuti.

Statistika allikad on esitatud järgmiselt:
- Jagatud mälus (shared buffers) on segment, kus hoitakse statistilisi andmeid, seal on ka need samad loendurid, mis pidevalt suurenevad, kui toimuvad mingid sündmused või tekivad teatud hetked andmebaasi töös.
- Need performance measurements beyond what your users and admins can access? PostgreSQL offers a suite of low-level metrics through SQL functions. By performing a select query using these functions, you can obtain specific metrics.
- However, working with these functions directly can be cumbersome. This is where views (VIEWs) come into play. They serve as virtual tables that provide statistics for specific subsystems or sets of events within the database.
- These built-in views (VIEWs) are the primary means for users to engage with statistical data. They are readily available by default with no additional setup required, allowing you to access and extract information immediately. Additionally, there are official contrib modules. You can install the postgresql-contrib package (for instance, postgresql94-contrib), load the necessary module in your configuration, set its parameters, restart PostgreSQL, and start using it. (Note. Depending on the distribution, in recent versions, the contrib package is included as part of the main package.).
- Ja on olemas mitteametlikud contrib. Need ei kuulu PostgreSQL standardsetesse pakettidesse. Need tuleb kas koos kompileerida või installida raamatukoguna. Valikud võivad olla väga erinevad, sõltuvalt sellest, mida selle mitteametliku contrib'i arendaja on välja mõelnud.

Sellel slaidil on esitatud kõik need vaated (VIEWd) ja osa funktsioone, mis on saadaval PostgreSQL 9.4-s. Nagu näeme, on neid palju. Ja üsna lihtne on segadusse minna, kui olete sellega esmakordselt kokku puutunud.
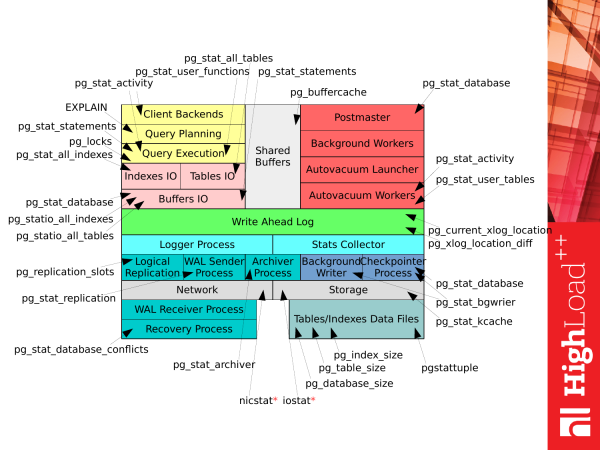
Kuid kui võtame eelneva pildi Kuidas kulub aeg PostgreSQL-i kasutamisel ja ühitame selle nimekirjaga, siis saame sellise pildi. Iga väli (VIEWd) või iga funktsioon, mida saame kasutada erinevatel eesmärkidel, et saada vastavat statistikat, kui meil on PostgreSQL töömas. Ja me saame juba mingit teavet alamhaldussüsteemi töö kohta.
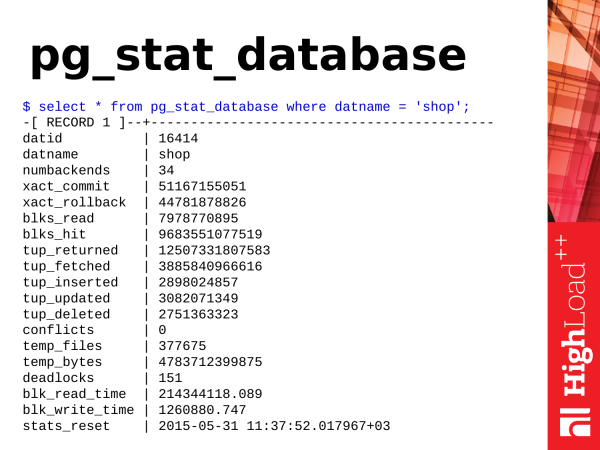
Esimene asi, mida vaatame, on pg_stat_database. Nagu näeme, on see väli. Seal on väga palju teavet. Kõige mitmekesisemat teavet. Ja see annab väga väärtuslikku teadmist selle kohta, mis meie andmebaasis toimub.
Mida kasulikku saame sealt võtta? Alustame kõige lihtsamatest asjadest.

select
sum(blks_hit)*100/sum(blks_hit+blks_read) as hit_ratio
from pg_stat_database;Esiteks, mida saame vaadata, on vahemälu hiti protsent. Vahemälu hiti protsent on kasulik mõõdik. See võimaldab hinnata, kui palju andmeid võetakse vahemälust (shared buffers) ja kui palju loetakse kettalt.
Selgelt on näha, et mida suurem on meie vahemälu hiti protsent, seda parem on see.. Me hindame seda mõõdikut protsendina. Ja näiteks, kui meil on vahemälu hiti protsent üle 90%, siis on see hea. Kui see langeb alla 90%, siis näitab see, et meil pole piisavalt mälu, et hoida kuuma andmete "pead" mälus. Ja et neid andmeid kasutada, peab PostgreSQL pöörduma ketta poole, mis on aeglasem kui andmete lugemine mälust. Siis tuleks juba mõelda mälu suurendamisele: kas suurendada shared buffersi või lisada rohkem füüsilist mälu (RAM).
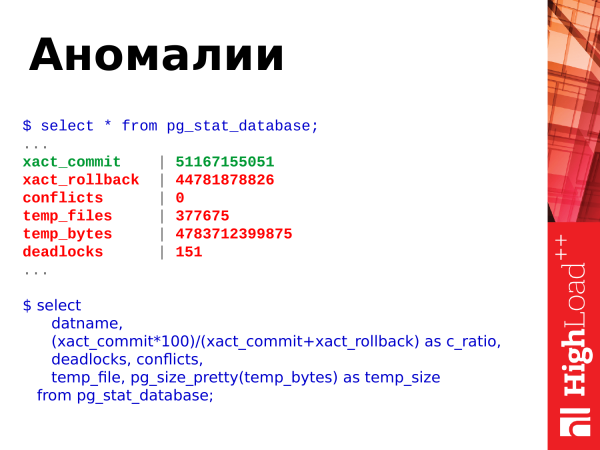
select
datname,
(xact_commit*100)/(xact_commit+xact_rollback) as c_ratio,
deadlocks, conflicts,
temp_file, pg_size_pretty(temp_bytes) as temp_size
from pg_stat_database;Mida veel saame sellest esitamisest võtta? Saame vaadata andmebaasis toimuvaid anomaaliaid. Mida siin näidatakse? Siin on commits, rollbacks, ajutiste failide loomine ja nende maht, deadlocks ja konfliktid.
Saame kasutada seda päringut. See SQL on üsna lihtne. Ja saame neid andmeid enda juures vaadata.
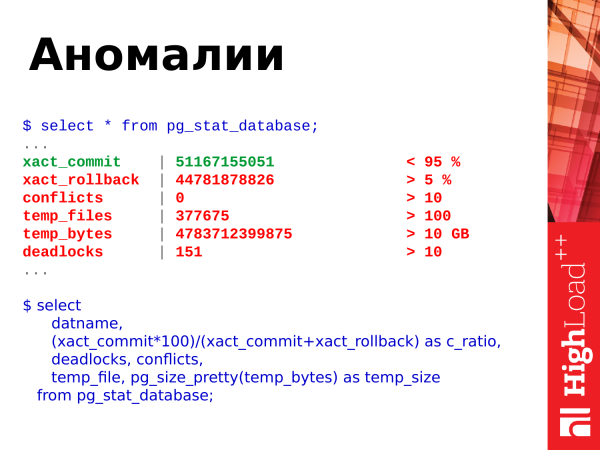
Siin on kohe piirväärtused. Me vaatame commits ja rollbacks suhet. Commits on eduka tehingu kinnitamine. Rollbacks on tagasivõtmine, st tehing tegi mingit tööd, koormas andmebaasi, tegi arvutusi, kuid siis toimus tõrge ja tehingu tulemused kõrvaldatakse. St. korrutusi, mis pidevalt suurenevad, on halb. Ja peaks neid vältima ning koodi parandama, et sellist ei juhtuks.
Konfliktid (conflicts) on seotud replikatsiooniga. Ja neid tuleks samuti vältida. Kui teil on mõni päring, mis töötab replikal ja tekivad konfliktid, tuleb need konfliktid lahendada, vaadata, mis toimub. Üksikasjad leiab logidest. Ja tuleb kõrvaldada konfliktolukordi, et rakenduse päringud töötaksid ilma vigadeta.
Deadlockid – see on samuti halb olukord. Kui päringud konkureerivad ressursside pärast, pöördub üks päring ühe ressursi poole ja võtab selle blokeeringu, teine päring pöördub teise ressursi poole ja võtab samuti blokeeringu, ning seejärel pöörduvad mõlemad päringud üksteise ressursside poole ja takerdusid ootama, kuni naaber blokeeringu vabastab. See on samuti probleemne olukord. Neid tuleb lahendada rakenduste ümberehitamise ja ressurssidele juurdepääsu serialiseerimise tasemel. Ja kui te näete, et teie deadlockid suurenevad pidevalt, tuleb uurida üksikasju logidest, analüüsida tekkinud olukordi ja otsida, mis on probleem.
Ajutised failid (temp_files) – see on samuti halb. Kui kasutaja päringul ei ole mälu, et paigutada operatiivseid ajutisi andmeid, loob ta faili kettale. Ja kõik operatsioonid, mida ta saaks teostada ajutises mälupuhvrisse, hakkab ta teostama juba kettal. See on aeglane. See suurendab päringu täitmise aega. Ja klient, kes saatis päringu PostgreSQL-ile, saab vastuse veidi hiljem. Kui kõik need operatsioonid teostatakse mälus, vastab Postgres palju kiiremini ja klient peab vähem ootama.
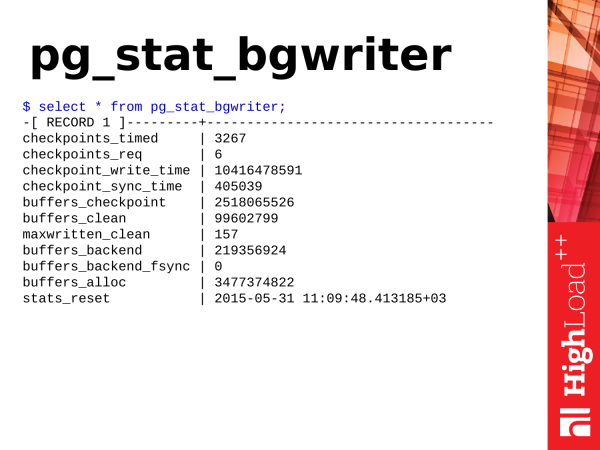
Pg_stat_bgwriter – see vaade kirjeldab kahe PostgreSQL taustasüsteemi tööd: see kontrollpunkt ja taustakirjutaja.

Alustame kontrollpunktidest, st. kontrollpunktid. Mis on kontrollpunktid? Kontrollpunkt on positsioon tehingute logis, mis teatab, et kõik andmete muudatused, mis on logis registreeritud, on edukalt sünkroniseeritud andmetega kettal. Protsess võib sõltuvalt töökoormusest ja seadistustest olla pikk ning see seisneb suurel määral määrdunud lehtede sünkroniseerimises jagatud puhvrites kettal olevate andmefailidega. Miks on see vajalik? Kui PostgreSQL pöördus pidevalt kettale ja võttis sealt andmeid ning salvestaks andmeid igal korral, kui sealt andmeid võetakse, oleks see aeglane. Seetõttu on PostgreSQL-l mälu segment, mille suurus sõltub konfiguratsioonis olevatest parameetritest. Postgres salvestab sellesse mälu operatiivsed andmed hilisemaks töötlemiseks või nende esitlemiseks päringute järgi. Andmete muutmise päringute puhul toimub nende muutmine. Ja me saame kaks versiooni andmetest. Üks on meil mälus, teine kettal. Ja perioodiliselt on vajalik need andmed sünkroniseerida. Me peame mälus muudetud andmed sünkroniseerima kettale. Selleks on vajalikud kontrollpunktid.
Checkpoint läbib jagatud puhverid, märgib räpaste lehtedena, et need on vajalikud kontrollpunktiks. Siis käivitab see teise läbimise jagatud puhverites. Ja lehed, mis on märgitud kontrollpunktiks, sünkroniseeritakse juba. Niimoodi toimub andmete sünkroniseerimine ketas.
On kaks tüüpi kontrollpunkte. Üks kontrollpunkt toimub ajavahemiku järgi. See kontrollpunkt on kasulik ja hea – checkpoint_timed. Ja on nõudmisi alusel tehtavad kontrollpunktid – checkpoint required. Selline kontrollpunkt toimub, kui meil on väga suur andmete kirjutamine. Oleme kirjutanud väga palju tehingute logisid. Ja PostgreSQL peab seda kõike võimalikult kiiresti sünkroniseerima, et teha kontrollpunkt ja edasi elada.
Ja kui vaatasite statistikat pg_stat_bgwriter ja nägite, et teil on checkpoint_req palju rohkem kui checkpoint_timed, siis see on halb. Miks halb? See tähendab, et PostgreSQL on pidevas stressis, kui tal on vaja andmeid kettale kirjutada. Checkpoint on väljumise aeg vähem stressirohke ja toimub vastavalt sisemisele ajakavale ning on ajaliselt jaotatud. PostgreSQL-il on võimalus teha töötamise pausid, et mitte koormata kettasüsteemi. See on PostgreSQL jaoks kasulik. Samuti ei puutu tõrgeteta toimuvad päringud stressi, kui kettasüsteem on hõivatud.
Ja checkpointi reguleerimiseks on kolm parameetrit:
checkpoint_segments.checkpoint_timeout.checkpoint_completion_target.
Need võimaldavad reguleerida kontrollpunktide tööd. Kuid ma ei jää nende juurde. Nende mõju on juba eraldi teema.
Tähtis: Arutletav etapp 9.4 ei ole enam asjakohane. Kaasaegsetes PostgreSQL versioonides on parameeter checkpoint_segments asendatud parameetritega min_wal_size ja max_wal_size.

Järgmine alamvõrk on taustakirjutaja — taustakirjutaja. Mida ta teeb? Ta töötab pidevalt lõpmatus tsüklis. Skaneerib lehti ühiskasutatavatest puhkudest ning lehti, mis on määrdunud, mille ta leiab, kirjutab kettale tagasi. Nii aitab ta checkpointer'il vähendada töökoormust kontrollpunktide täitmise protsessis.
Mis see veel on kasulik? See tagab vajaduse puhaste lehtede järele jagatud puhverdes, kui need peaksid äkki olema vajalikud (suurtes kogustes ja kohe) andmete salvestamiseks. Oletame, et olukord on tekkinud, kus puhtaid lehti on vaja päringu täitmiseks ja need on juba jagatud puhvris. Postgres tagaosa lihtsalt võtab need ja kasutab, tal ei ole vaja ise midagi puhastada. Kuid kui selliseid lehti pole, siis backend peatab töötamise ning alustab lehtede otsingut, et need diskile kirjutada ja enda vajaduste jaoks võtta — see mõjutab negatiivselt hetkel käimasoleva päringu täitmise aega. Kui näete, et teil on parameeter maxwritten_clean suur, tähendab, et taustakirjutaja ei suuda oma tööd teha ja peab suurendama parameetreid bgwriter_lru_maxpages, et ta suudaks ühes tsüklis rohkem tööd ära teha, rohkem lehti puhastada.
Ja teine väga kasulik näitaja on buffers_backend_fsync. Backendid ei tee fsynci, sest see on aeglane. Nad edastavad fsynci kõrgemale IO stack’ile checkpointer’ile. Checkpointeril on oma järjekord, ta töötleb fsynci perioodiliselt ja sünkroniseerib mälus lehed failidega diskil. Kui checkpointer’il on suur järjekord ja see on täis, peab backend ise tegema fsync, mis aeglustab backend’i tööd., st. klient saab vastuse hiljem, kui võiks. Kui näete, et see väärtus on suurem kui null, siis on see juba probleem ja peate pöörama tähelepanu background writer’i seadetele ning hindama ka kettasüsteemi jõudlust.
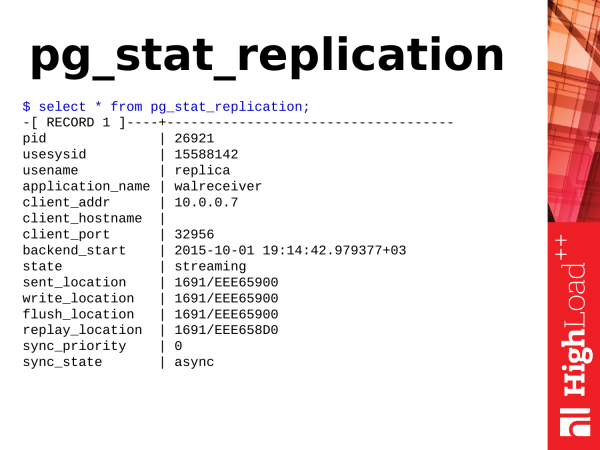
Tähtis: _Järgmine tekst kirjeldab statistilisi representatsioone, mis on seotud replikatsiooniga. Enamik vaateid ja funktsioonide nimesid on Postgres 10-s ümber nimetatud. Ümbernimetamine hõlmas xlog järgnevaga wal ja asukohta järgnevaga lsn funktsioonide/vaadete jne nimedes. Eriline näide on funktsioon pg_xlog_location_diff() , mis nimetati ümber pg_wal_lsn_diff()._
Siin on meil samuti palju asju. Kuid me vajame vaid punkte, mis on seotud location’iga.
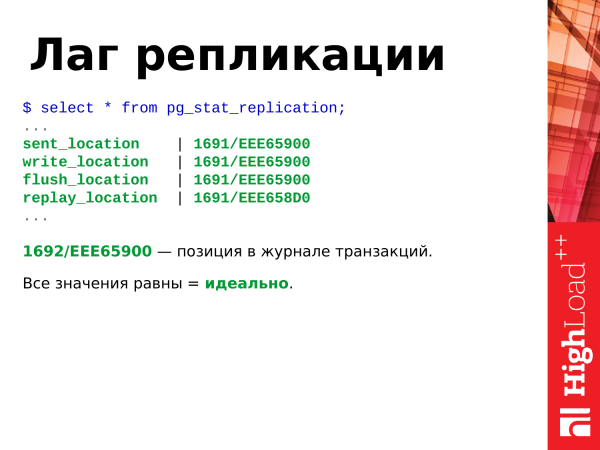
Kui me näeme, et kõik väärtused on võrdsed, on see ideaalne variant ja replikatsioon ei jää maestro taga.
See kuuekümnendaline positsioon on positsioon tehingute ajakirjas. See suureneb pidevalt, kui andmebaasis on mingit aktiivsust: lisamised, kustutamised jne.
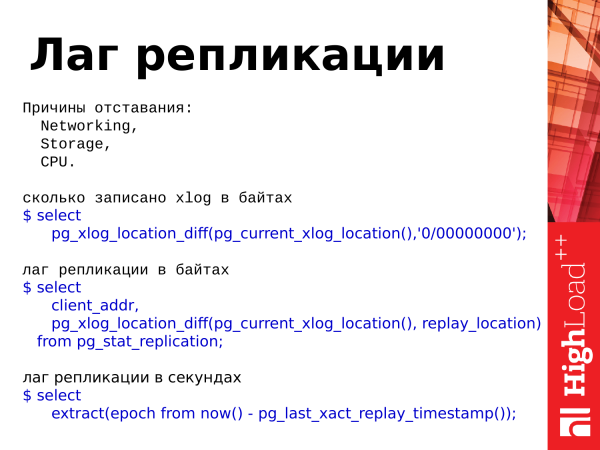
kui palju xlog on kirjutatud baitides
$ select
pg_xlog_location_diff(pg_current_xlog_location(),'0/00000000');
replicatsiooni viivitus baitides
$ select
client_addr,
pg_xlog_location_diff(pg_current_xlog_location(), replay_location)
fro pg_stat_replication;
replicatsiooni viivitus sekundites
$ select
extract(epoch from now() - pg_last_xact_replay_timestamp());Kui need asjad erinevad, siis tähendab see, et on mingisugune viivitus. Viivitus on replika viibimine peamise serveri ees, st andmed erinevad serverite vahel.
On kolm põhjust viibimise tekkimiseks:
- See on diskial süsteem, mis ei suuda kirjutada failide sünkroniseerimist.
- Need võivad olla võrguvead või võrgu koormus, kui andmed ei jõua replikasse õigel ajal ja ta ei suuda neid taastada.
- Ja protsessor. Protsessor – see on väga harv juhtum. Olen sellist näinud kaks või kolm korda, aga see võib ka juhtuda.
Ja siin on kolm päringut, mis võimaldavad meil kasutada statistikat. Saame hinnata, kui palju on meie tehingu žurnalis kirjutatud. On olemas selline funktsioon pg_xlog_location_diff ja saame hinnata replicatsiooni viivitust baitides ja sekundites. Seda jaoks kasutame samuti väärtust sellest vaatepunktist (VIEWs).
Märkus: _pg_xlog_locationdiff() funktsiooni asemel saab kasutada lahutamisoperaatorit ja lahutada ühe asukoha teisest. Mugav.
Aegluse, mis on sekundites, on üks hetk. Kui meistris ei toimu mingit aktiivsust, oli tehing umbes 15 minutit tagasi ja aktiivsust pole, ja kui me vaatame replikas seda aeglust, siis näeme 15-minutilist viivitust. Sellest tasub meeles pidada. Ja see võib tekitada segadust, kui olete seda viivitust vaadanud.
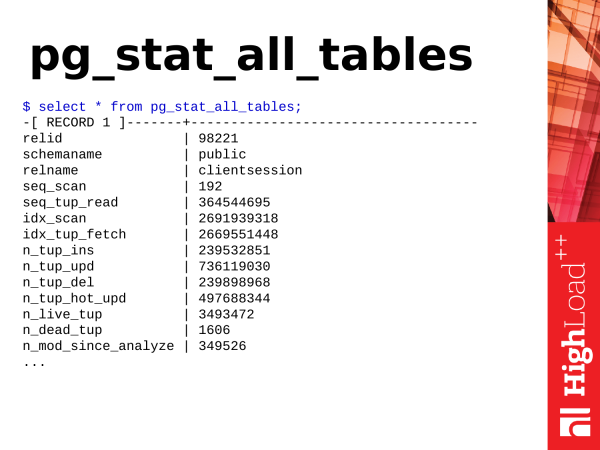
Pg_stat_all_tables – veel üks kasulik vaade. See näitab tabelite statistikat. Kui meie andmebaasis on tabeleid, millega toimub mingisugune aktiivsus, saame seda teavet selle vaate kaudu.

select
relname,
pg_size_pretty(pg_relation_size(relname::regclass)) as size,
seq_scan, seq_tup_read,
seq_scan / seq_tup_read as seq_tup_avg
from pg_stat_user_tables
where seq_tup_read > 0 order by 3,4 desc limit 5;Esimene asi, mida me saame vaadata, on järjestikused skaneerimised tabelis. Number nende läbimiste järel ei pruugi olla halb ja ei tähenda tingimata, et peame midagi ette võtma.
Kuid on ka teine mõõdik – seq_tup_read. See on ridade arv, mis tagastatakse järjestikulise skaneerimise tulemusena. Kui keskmine number ületab 1 000, 10 000, 50 000, 100 000, siis on see näitaja, et võib-olla peate kuskil indeksi looma, et juurdepääsud oleksid indeksi kaudu, või on võimalik optimeerida päringuid, mis kasutavad selliseid järjestikulisi skaneerimisi, et seda vältida.
Lihtne näide – oletame, et päring, millel on suur OFFSET ja LIMIT, on kulukas. Näiteks skaneeritakse 100 000 rida tabelis ja seejärel võetakse 50 000 vajalikku rida, samas kui eelnevalt skaneeritud read jäetakse kõrvale. See on samuti halb olukord. Selliseid päringuid tuleb optimeerida. Siin on lihtne SQL-päring, mille abil saab seda vaadata ja mõõdetud numbreid hinnata.

select
relname,
pg_size_pretty(pg_total_relation_size(relname::regclass)) as
full_size,
pg_size_pretty(pg_relation_size(relname::regclass)) as
table_size,
pg_size_pretty(pg_total_relation_size(relname::regclass) -
pg_relation_size(relname::regclass)) as index_size
from pg_stat_user_tables
order by pg_total_relation_size(relname::regclass) desc limit 10;Tabelite suurusi saab samuti saada selle tabeli ja täiendavate funktsioonide abil. pg_total_relation_size(), pg_relation_size().
Tegelikult on olemas metakomandid. dt ja di, mida saab kasutada PSQL-is ning samuti vaadata tabelite ja indeksite suurusi.
Kuid funktsioonide kasutamine aitab meil näha tabelite suurusi, arvestades indekseid või ilma indekseid arvesse võtmata, ning teha juba mingeid hindamisi andmebaasi kasvu põhjal, st kuidas see meil kasvab, millise intensiivsusega, ning teha mingeid järeldusi suuruste optimeerimise osas.
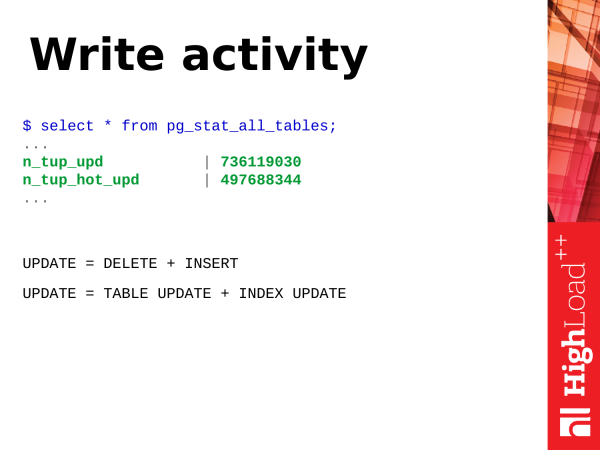
Kirjutamisaktiivsus. Mis on kirjutamine? Vaatame operatsiooni KUUDA – ridade värskendamise operatsiooni tabelis. Sisuliselt on update kaks operatsiooni (või isegi enam). See on uue versiooni sisestamine ja vana versiooni märgistus aegunuks. Hiljem tuleb autovakuum ja need vanad versioonid eemaldatakse, tähistades selle koha taaskasutamiseks sobivaks.
Lisaks ei tähenda update ainult tabeli värskendamist. See hõlmab ka indeksite värskendamist. Kui teie tabelil on palju indekseid, tuleb update käigus kõik indeksid, kus osaleb värskendatav väli, samuti värskendada. Nendes indeksites on samuti vanad versioonid, mida tuleb puhastada.

valige
s.relname,
pg_size_pretty(pg_relation_size(relid)),
coalesce(n_tup_ins,0) + 2 * coalesce(n_tup_upd,0) -
coalesce(n_tup_hot_upd,0) + coalesce(n_tup_del,0) AS total_writes,
(coalesce(n_tup_hot_upd,0)::float * 100 / (case when n_tup_upd > 0
then n_tup_upd else 1 end)::float)::numeric(10,2) AS hot_rate,
(select v[1] FROM regexp_matches(reloptions::text,E'fillfactor=(\d+)') as
r(v) limit 1) AS fillfactor
from pg_stat_all_tables s
join pg_class c ON c.oid=relid
order by total_writes desc limit 50;Ja oma olemuselt on UPDATE – see on keeruline operatsioon. Kuid neid saab kergendada. On kuumad värskendused. Need ilmusid PostgreSQL versioonis 8.3. Mis need on? See on kerge värskendus, mis ei põhjusta indeksite ümberstruktuurimist. See tähendab, et me värskendasime kirjet, kuid muutus ainult lehe kirje (mis kuulub tabelile), ja indeksid suunavad endiselt sellele samale kirjele lehe sees. Siin on pisut huvitav töölogika: kui tuleb vaakum, siis ta need ahelad kuumad uuendab ja kõik töötab jätkuvalt ilma indeksite uuendamiseta, ja see toimub väiksema ressursikulu arvelt.
Ja kui teil on n_tup_hot_upd suure hulga, siis see on väga hea. See tähendab, et kerged värskendused domineerivad ja see on meie ressursside jaoks odavam ja kõik on suurepärane.

ALTER TABLE table_name SET (fillfactor = 70);Kuidas suurendada kuumade värskendustehulka? Me saame kasutada fillfactor. See määrab reserveeritud vabade kohtade suuruse lehe täitmisel tabelis INSERT-ide abil. Kui tabelisse sisestatakse andmeid, täidavad need täielikult lehe, jättes sellele tühi koht. Seejärel eraldatakse uus leht. Andmed täidetakse uuesti. See on vaikekäitumine, fillfactor = 100%.
Saame seadistada fillfactori 70% peale. See tähendab, et kui sisestatakse andmeid, eraldatakse uus leht, kuid täidetakse vaid 70% lehe mahust. 30% jääb meile reserviks. Kui tuleb teha uuendus, toimub see tõenäoliselt samal lehel, ja uue versiooni rida paigutatakse samasse lehte. Sellega lihtsustatakse tabelite kirjutamist.

select c.relname,
current_setting('autovacuum_vacuum_threshold') as av_base_thresh,
current_setting('autovacuum_vacuum_scale_factor') as av_scale_factor,
(current_setting('autovacuum_vacuum_threshold')::int +
(current_setting('autovacuum_vacuum_scale_factor')::float * c.reltuples))
as av_thresh,
s.n_dead_tup
from pg_stat_user_tables s join pg_class c ON s.relname = c.relname
where s.n_dead_tup > (current_setting('autovacuum_vacuum_threshold')::int
+ (current_setting('autovacuum_vacuum_scale_factor')::float * c.reltuples));Autovakumi järjekord. Autovakum on alamsüsteem, mille statistika PostgreSQL-is on väga väike. Saame tabelites pg_stat_activity vaid näha, kui palju meil hetkel autovakume on. Kuid on väga keeruline mõista, kui palju tabeleid on tal järjekorras.
Märkus: _Alates PostgreSQL versioonist 10 on olukord autovakumi jälgimisel oluliselt paranenud — ilmus vaade pg_stat_progress, mis lihtsustab autovakumi jälgimise küsimust oluliselt.
Saame kasutada sellist lihtsustatud päringut. Ja saame vaadata, millal peaks vakum olema tehtud. Kuid kuidas ja millal peaks vakum käivituma? Need on vananenud stringiversioonid, millest ma varem rääkisin. Uuendus toimus, uus stringiversioon sisestati. Ilmus vananenud stringiversioon. Tabelis pg_stat_user_tables on selline parameeter n_dead_tup. See näitab "surmatud" stringide arvu. Ja niipea, kui surmatud stringide arv ületab kindla piiri, tuleb tabelisse autovakum.
Ja kuidas see piir arvutatakse? See on üsna konkreetne protsentuaalne suhe tabelis olevate stringide koguarvust. On olemas parameeter autovacuum_vacuum_scale_factor. See määrab protsendi suhte. Oletame, et 10 % + seal on täiendav baaspiirang 50 rida. Ja mis sellega juhtub? Kui meie surnud ridu on rohkem kui "10 % + 50" kõigist ridadest tabelis, siis paneme tabeli automaatse tühjendamise (autovacuum) peale.

select c.relname,
current_setting('autovacuum_vacuum_threshold') as av_base_thresh,
current_setting('autovacuum_vacuum_scale_factor') as av_scale_factor,
(current_setting('autovacuum_vacuum_threshold')::int +
(current_setting('autovacuum_vacuum_scale_factor')::float * c.reltuples))
as av_thresh,
s.n_dead_tup
from pg_stat_user_tables s join pg_class c ON s.relname = c.relname
where s.n_dead_tup > (current_setting('autovacuum_vacuum_threshold')::int
+ (current_setting('autovacuum_vacuum_scale_factor')::float * c.reltuples));Kuid siin on üks moment. Baaspiirangud parameetritel av_base_thresh ja av_scale_factor võivad olla määratud individuaalselt. Seetõttu ei ole piirang globaalne, vaid individuaalne tabeli jaoks. Seega, et arvutada, peab kasutama nippe ja trikke. Ja kui teid huvitab, siis võite vaadata meie kolleegide kogemust Avitos (link slaidil ei ole enam kehtiv ja on tekstis uuendatud).
Nad kirjutasid , mis arvestab neid asju. Seal on kahe lehe pikkune tekst. Kuid see arvutab õigesti ja võimaldab üsna efektiivselt hinnata, kus meil tühjendamine tabelite jaoks on väga vajalik, ja kus on seda vähem.
Mida me sellega teha saame? Kui meil on pikk järjekord ja automaatne tühjendamine ei toimi, saame me suurendada tühjendamise töötajate arvu või lihtsalt teha tühjendamise agressiivsemaks, et see aktiveeruks varem, töötleks tabelit väikeste tükkidena. Ja seeläbi väheneb järjekord. — Peamine on jälgida ketaste koormust, kuna vaakum ei ole tasuta, kuigi SSD/NVMe seadmete tulekuga on probleem muutunud vähem nähtavaks.
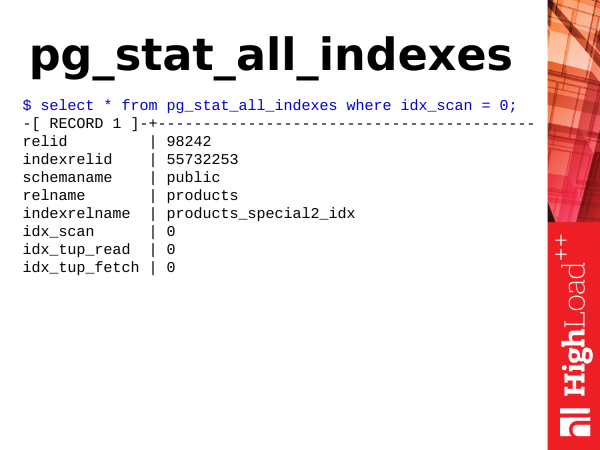
Pg_stat_all_indexes – see on statistika indeksite kohta. See on väike. Ja me saame selle põhjal teavet indeksite kasutamise kohta. Näiteks saame määrata, millised indeksid on meie jaoks üleliigsed.
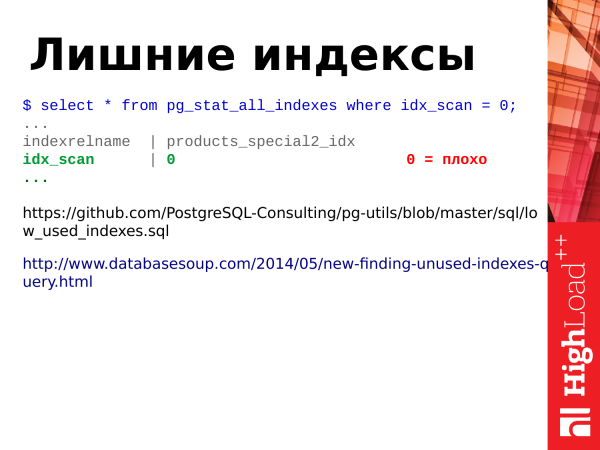
Kuidas ma juba mainisin, update – see ei ole ainult tabelite värskendamine, vaid ka indeksite värskendamine. Seega, kui meil on tabelis palju indekseid, siis tabeli ridade värskendamisel tuleb ka indekseeritud väljade indeksid värskendada, ja kui meil on kasutamata indeksid, mille kohta ei toimu indeksiskaneerimist, siis need on meie jaoks koormaks. Ja neist peab vabanema. Selle jaoks on meil vaja välja idx_scan. Vaata lihtsalt indeksiskaneerimiste arvu. Kui indeksitel on null skaneerimist suhteliselt pika statistika säilitamise perioodi jooksul (mitte vähem kui 2-3 nädalat), siis on tõenäoliselt tegemist halva indekssiga, millest peame vabanema.
Märkus: Klastri replikatsioonide puhul tühjade indeksite otsimisel tuleb kontrollida kõiki klastri sõlmi, kuna statistika ei ole globaalne ja kui indeksit ei kasutata peamise serveri peal, võib see olla kasutusel koopiates (kui neil on koormus).
Kaks linki:
Need on arenenumad päringute näited, kuidas leida tühje indekseid.
Teine link on üsna huvitav päring. Seal on väga keeruline loogika. Soovitan tutvuda.
Mis veel indeksite kohta rõhutada?
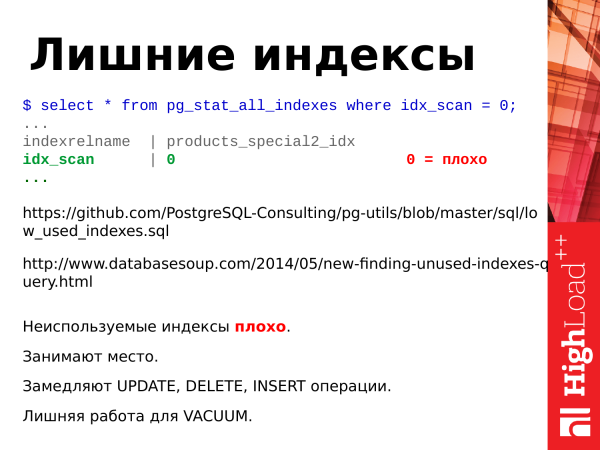
Tühjad indeksid on kehvad.
Kasutavad ruumi.
Aeglustavad uuendamise operatsioone.
Liigne töö vahetuks.
Kui me kustutame tühjad indeksid, teeme andmebaasi ainult paremaks.
Järgmine vaade on pg_stat_activity. See on tööriista analoog, ps, ainult PostgreSQL-is. Kui pste vaatate 'süsteemi protsesse, siis pg_stat_activity näitab teile aktiivsust PostgreSQL-i sees.
Mida kasulikku me sealt saame?

select
count(*)*100/(select current_setting('max_connections')::int)
from pg_stat_activity;Me saame vaadata üldist aktiivsust, mis andmebaasis toimub. Saame teha uue versiooni. Meil seal kõik plahvatas, uued ühendused ei tule, rakenduses viskab vigu.

select
client_addr, usename, datname, count(*)
from pg_stat_activity group by 1,2,3 order by 4 desc;Saame teostada sellise päringu ja vaadata üldist ühenduste protsenti maksimaalsest piirangust ning vaadata, kes meilt kõige rohkem ühendusi kasutab. Ja antud juhul näeme, et user cron_role avas 508 ühendust. Ja temaga on midagi juhtunud. Tuleb sellega tegeleda ja uurida. On täiesti võimalik, et see on mingi anomaalne ühenduste arv.
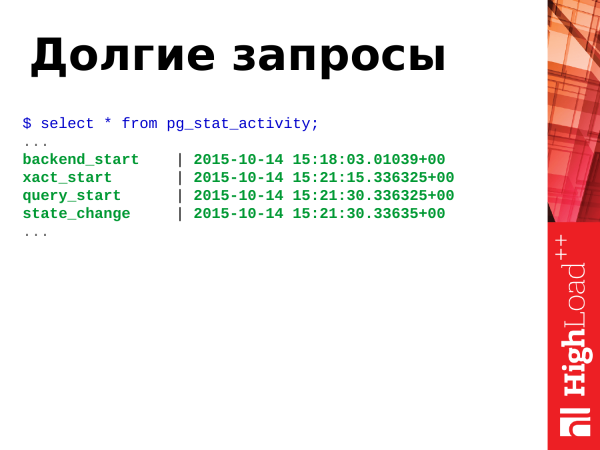
Kui meil on OLTP koormus, peaksid päringud toimuma kiiresti, väga kiiresti, ja pikad päringud ei tohiks olla. Kuid kui pikad päringud tekivad, siis lühiajaliselt ei ole midagi hullu, kuid pikaajalises perspektiivis kahjustavad pikad päringud andmebaasi, need suurendavad tabelite bloat-efekti, kui toimub tabelite fragmenteerimine. Bloat’ist ja pikkadest päringutest tuleb vabaneda.

valige
client_addr, usename, datname,
clock_timestamp() - xact_start as xact_age,
clock_timestamp() - query_start as query_age,
query
from pg_stat_activity order by xact_start, query_start;Pange tähele: selle päringuga saame kindlaks teha pikaajalised päringud ja tehingud. Kasutame funktsiooni clock_timestamp() tööaega määrata. Pikaajalised päringud, mille oleme leidnud, saame neid meelde jätta, käivitada explain, vaadata plaane ja optimeerida neid. Praegused pikad päringud me peatame ja elame edasi.
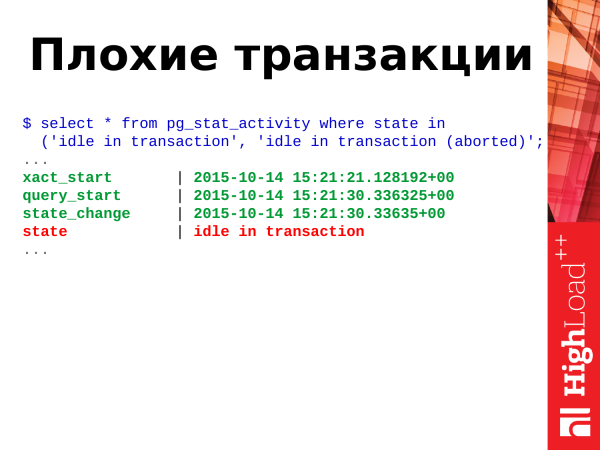
select * from pg_stat_activity where state in
('idle in transaction', 'idle in transaction (aborted)';Halvad tehingud – need on tehingud seisundis idle in transaction ja idle in transaction (aborted).
Mis see tähendab? Tehingud võivad olla mitmesugustes seisundites. Ja nad võivad igal ajahetkel omada üht neist seisunditest. Seisundite määramiseks on väli state selles esitusvormis. Ja kasutame seda jaotuse seisundi määramiseks.

select * from pg_stat_activity where state in
('idle in transaction', 'idle in transaction (aborted)';Ja nagu ma juba varem ütlesin, need kaks seisundit idle in transaction ja idle in transaction (aborted) – see on halb. Mis see on? See tähendab, et rakendus avas tehingu, tegi mõned toimingud ja läks siis omi asju ajama. Tehing jäi avatuks. See jääb rippuma, seal ei toimu mitte midagi, see võtab ühenduse, blokeerib muudetud ridu ja võib potentsiaalselt suurendada ka teiste tabelite bloat'i, kuna Postgres'i tehingu mootori arhitektuur selline on. Sellised tehingud tuleks samuti lõpetada, kuna need on ehk kahjulikud igas olukorras.
Kui teil näete, et neid on teie andmebaasis rohkem kui 5-10-20, siis on juba põhjust muretseda ja midagi ette võtta.
Siin kasutame me ka ajakalkuleerimisel clock_timestamp(). Lõpetame tehingud, optimeerime rakenduse.
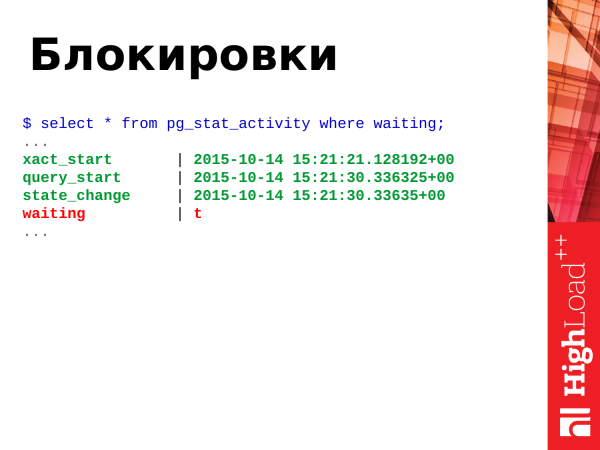
Kuidas ma juba varem ütlesin, lukud – see on siis, kui kaks või rohkem tehingut võitlevad ühe või grupi ressursside pärast. Selleks on meil väli waiting boolean väärtusega true või false.
True – see tähendab, et protsess ootab, vaja on midagi ette võtta. Kui protsess on ootel, siis tähendab see, et ka klient, kes algatas selle protsessi, ootab. Klient brauseris istub ka ja ootab.
Tähtis: _Alates Postgres 9.6 versioonist väli waiting kaks rohkem informatiivset välja on asendatud wait_event_type ja wait_event._
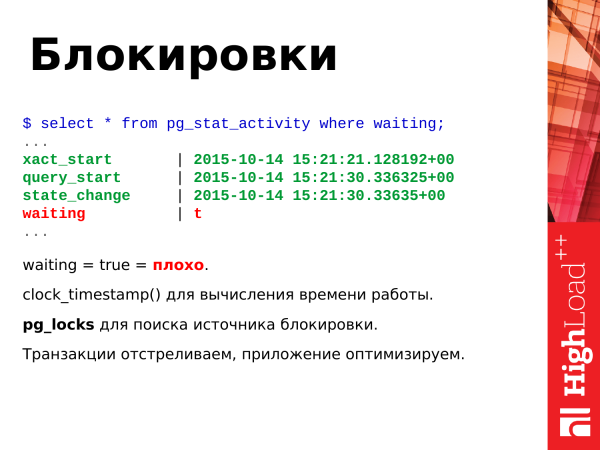
Mis teha? Kui te näete true pikka aega, siis tähendab see, et sellistest päringutest tuleb vabaneda. Me lihtsalt tappa sellised tehingud. Arendajatele kirjutame, et nad peavad kuidagi optimeerima, et ressursi järele ei toimuks võidujooksu. Ja siis saavad arendajad rakendust optimeerida, et seda ei juhtuks.
Ja viimane, kui ka mitte fataalne juhtum – see on deadlockide teke. Kaks tehingut värskendavad kahte ressurssi, seejärel pöörduvad nad uuesti vastassuunaliste ressursside poole. PostgreSQL tapab sel juhul tehingu, et teine saaks jätkata tööd. See on ummikus olukord ja see ei lahenda ennast iseseisvalt. Seetõttu peab PostgreSQL võtma äärmuslikke meetmeid.

Ja siin on kaks päringut, mis võimaldavad jälgida lukke. Me kasutame vaadet pg_locks, mis võimaldab jälgida raskemaid lukke.
Ja esimene link – see on päringu tekst. See on üsna pikk.
Ja teine link – see on artikkel lukustuste kohta. Seda on kasulik lugeda, see on väga huvitav.
Nii et mida me näeme? Me näeme kahte päringut. Tehing koos ALTER TABLE – see on blokeeriv tehing. See käivitati, kuid ei lõpetatud ning rakendus, mis selle tehingu alustas, tegeleb kuskil muude asjadega. Ja teine päring – update. See ootab, kuni alter table lõpeb, et jätkata oma tööd.
Nii me saame välja selgitada, kes kedagi lukustas, hoiab ja saame sellega edasi tegeleda.
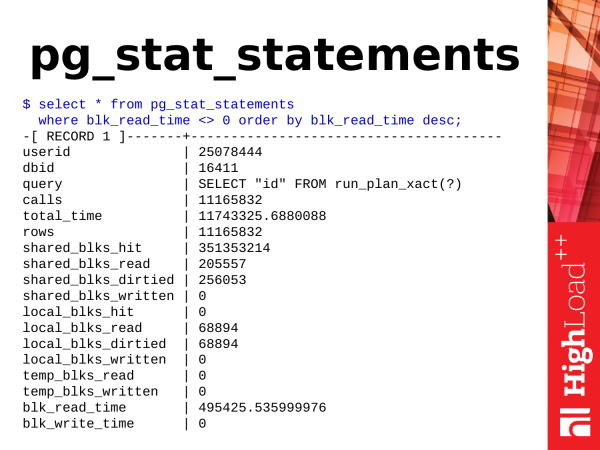
Järgmine moodul – see on pg_stat_statements. Nagu ma juba ütlesin, see moodul. Selle kasutamiseks tuleb laadida selle raamatukogu konfiguratsioonis, taaskäivitada PostgreSQL, installida moodul (ühe käsklusega) ja edasi on meil uus vaade.

Keskmine päringu aeg millisekundites
$ select (sum(total_time) / sum(calls))::numeric(6,3)
from pg_stat_statements;
Kõige aktiivsemalt kirjutavad (shared_buffers) päringud
$ select query, shared_blks_dirtied
from pg_stat_statements
where shared_blks_dirtied > 0 order by 2 desc;Mida me sealt võtta saame? Kui rääkida lihtsatest asjadest, saame võtta keskmise päringu täitmise aja. Aeg kasvab, see tähendab, et PostgreSQL vastab aeglaselt ja midagi tuleb ette võtta.
Saame vaadata kõige aktiivsemaid kirjutavaid tehinguid andmebaasis, mis muudavad andmeid shared buffers. Vaadata, kes me seal andmeid uuendab või kustutab.
Ja saame lihtsalt vaadata erinevaid statistika tulemusi nende päringute kohta.

Meie pg_stat_statements Kasutame aruannete koostamiseks. Kord päevas kustutame statistika. Kogume seda. Enne järgmist statistika kustutamist koostame aruande. Siin on link aruandele. Saate seda vaadata.

Mida me teeme? Kogume kokku kogu statistika kõigi päringute kohta. Seejärel arvutame iga päringu individuaalse panuse sellesse kogustatistikasse.
Mida me saame vaadata? Saame vaadata konkreetse tüüpide päringute koguaega, võrrelduna kõigi teiste päringutega. Saame vaadata protsessori ja sisend-väljundi ressursside kasutamist üldise pildi taustal. Ja optimeerida neid päringuid. Koostame selle aruande põhjal päringute edetabeli ja saame juba mõtteainet, mida optimeerida.

Mida meil on jäänud käsitlemata? On veel paar esitlust, mida ma ei hakanud käsitlema, kuna aeg on piiratud.
On pgstattuple – see on ka täiendav moodul standardkomplekti contribs. See võimaldab hinnata bloat tabelid, nn. tabeli fragmentatsioon. Ja kui fragmentatsioon on suur, tuleb see eemaldada, kasutades erinevaid tööriistu. Ja funktsioon pgstattuple töötab kaua. Ja mida rohkem tabeleid, seda kauem see töötab.

Järgmine contrib – see on pg_buffercache. See võimaldab uurida jagatud puhverdamise intensiivsust ja milliseid tabeleid puhver lehtede poolt kasutab. See annab lihtsalt võimaluse vaadata jagatud puhvrite sisu ja hinnata, mis seal toimub.
Järgmine moodul – see on pgfincore. See võimaldab läbi süsteemi kutsumise mincore(), tehis-, st see võimaldab laadida tabelit jagatud puhvrites või selle välja laadida. See võimaldab samuti kontrollida operatsioonisüsteemi lehe vahemälu, st kui palju meie tabel on lehe vahemälu, jagatud puhvrites ja annab võimaluse hinnata tabeli koormust.
Järgmine moodul – pg_stat_kcache. See kasutab samuti süsteemi kutset getrusage(). Ta täidab seda enne ja pärast päringu täitmist. Saadud statistika abil on võimalik hinnata, kui palju meie päring kulutas ketta sisend-väljundile, st toimingutele failisüsteemiga ja vaadata protsessori kasutamist. Siiski on moodul noor (khm-khm) ja selle toimimiseks on vajalik PostgreSQL 9.4 ning pg_stat_statements, millest ma varem rääkisin.

Statistika kasutamine on kasulik. Teil ei ole vaja kolmanda osapoole programme. Saate ise sisse vaadata, vaadata, midagi teha, täita.
Statistika kasutamine ei ole keeruline, see on tavaline SQL. Te koostate päringu, vormistate, saadate ja vaatate.
Statistika aitab vastata küsimustele. Kui küsitav küsimus tekib, pöördute statistikasse – vaatate, teete järeldusi, analüüsite tulemusi.
Katsuge katsetada. Päringuid on palju, andmeid on palju. Alati on võimalik optimeerida mõnda juba olemasolevat päringut. Võite teha oma versiooni päringust, mis sobib teile paremini kui originaal, ja kasutada seda.

Lingid
Kasulikud lingid, mis artiklis esinesid, mille alusel ettekanne tehti.
Autor kirjutab veel.
(eng)
Statistika Koguja
Süsteemi Administreerimise Funktsioonid
Contrib moodulid
SQL utiliid ja SQL koodinäidised
Aitäh kõigile tähelepanu eest!
Allikas: habr.com
