

Tere kõigile! Meil on suurepäraseid uudiseid, juunis käivitab OTUS taas kursuse , millega seoses jagame teiega traditsiooniliselt kasulikku materjali.

Kui olete kokku puutunud kogu sellele mikroteenuste jutule ilma igasuguse kontekstita, on teil mõistetav seda veidi kummalisena pidada. Rakenduse jagamine osadeks, mis on omavahel seotud võrguga, tähendab kindlasti ka keeruliste talitlushäired taluvate mehhanismide lisamist tekkinud hajutatud süsteemi.
Kuigi see lähenemine hõlmab jagamist paljudele sõltumatutele teenustele, on lõppeesmärk midagi enam kui lihtsalt nende teenuste töötamine erinevates masinates. Jutt on siin keskkonna interaktsioonist, mis iseenesest on samuti hajus. Mitte tehnilises mõttes, vaid pigem ökosüsteemis, mis koosneb paljusid inimesi, meeskondi, programme, ning igaüks neist peab mingil moel oma tööd tegema.
Ettevõtted, näiteks, koosnevad hajusate süsteemide kogumist, mis kokkuvõttes aitavad saavutada teatud eesmärki. Me ignoreerisime seda fakti aastakümneid, püüdes saavutada ühtsust, edastades faile FTP kaudu või kasutades ettevõtte integreerimistööriistu, keskendudes samal ajal oma isiklikele lahkarvamustele. Kuid teenuste saabumisega kõik muutus. Teenused aitasid meil vaadata kaugemale ja näha vastastikust sõltuvust, kus programmid töötavad ühiselt. Kuid selleks, et edukalt tegutseda, tuleb mõista ja disainida kahte fundamentaalselt erinevat maailma: välismaailm, kus elame paljude teiste teenuste ökosüsteemis, ja meie isiklik, sisemaailm, kus me valitseme üksi.
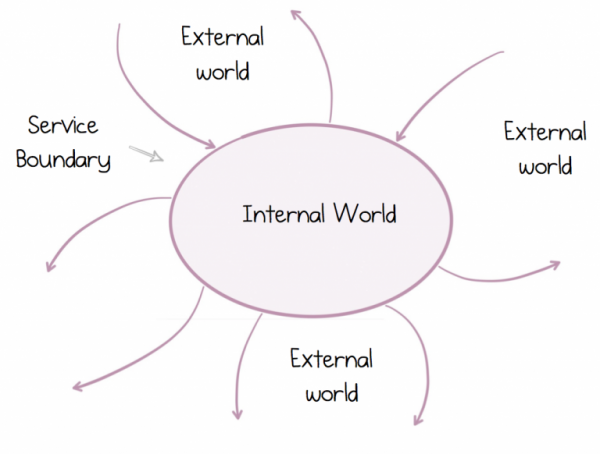
Selline hajustatud maailm erineb sellest, kus me kasvasime ja millega harjusime. Traditsioonilise monoliit arhitektuuri ehitamise põhimõtted ei pea mingit kriitikat. Seetõttu on selliste süsteemide õige mõistmine midagi muud kui vaid lahe skeemi loomine valgel tahvlil või lahe tõestus kontseptsioonist. Oluline on, et selline süsteem toimiks edukalt pika aja jooksul. Õnneks on teenused eksisteerinud juba piisavalt kaua, kuigi need näevad välja erinevad. on endiselt aktuaalsed, isegi kui need on maitsestatud Docker'i, Kubernetes'e ja kergelt kulunud hipsteri habe.
Nii et täna vaatame, kuidas reeglid on muutunud, miks peame ümber mõtlema oma lähenemist teenustele ja andmetele, mida nad üksteisele edastavad, ja miks meil selleks on vaja täiesti teistsuguseid tööriistu.
Inkaptsulatsioon ei ole alati teie sõber
Mikroteenused saavad töötada iseseisvalt. Just see omadus annab neile suurima väärtuse. See omadus võimaldab teenustel kasvatada ja laieneda. Mitte ainult mitte kuni kvadriljonite kasutajateni või petabaitide andmeteni (kuigi nad saavad ka siin aidata), vaid pigem inimeste perspektiivist, kuna meeskonnad ja organisatsioonid kasvavad pidevalt.
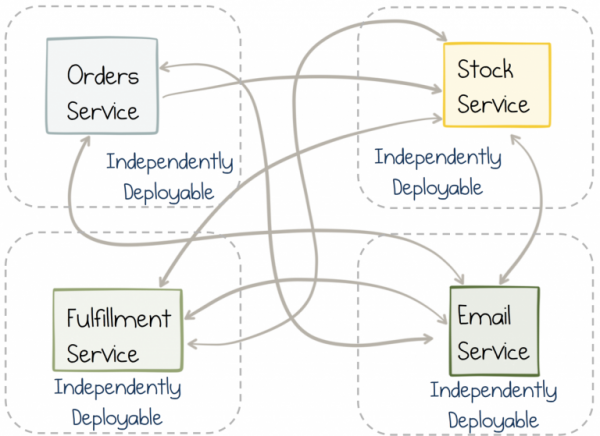
Kuid iseseisvus on kaheaegne mõõk. Teenus võib iseenesest töötada lihtsasti ja vaevata. Kuid kui teenuses rakendatakse funktsiooni, mis vajab teise teenuse kaasamist, peame lõpuks tegema muudatusi mõlemas teenuses peaaegu samal ajal. Monoliidis on see lihtne, sa lihtsalt teed muudatuse ja saadad selle välja, aga iseseisvate teenuste sünkroniseerimisel on probleeme rohkem. Koordineerimine meeskondade ja väljalasettsüklite vahel hävitab paindlikkuse.
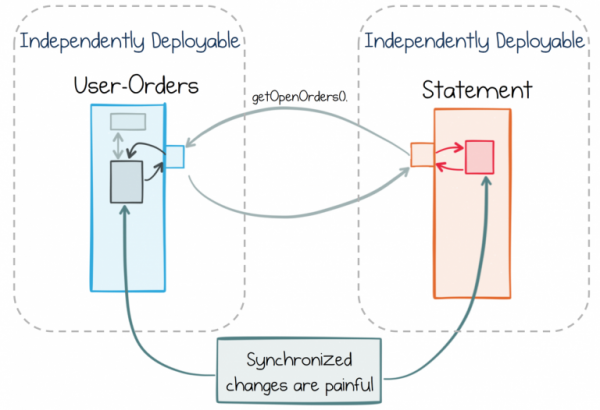
Tavapärases lähenemises püütakse ebameeldivate läbivoolavate muudatuste tegemist lihtsalt vältida, eristades selgelt funktsionaalsust teenuste vahel. Ühtse sisenemise teenus on siin hea näide. Sellel on selgelt määratletud roll, mis eristab seda teistest teenustest. Selline selge jaotus tähendab, et kiiresti muutuvate nõudmiste maailmas muudatuste osas jääb ühtse sisenemise teenus tõenäoliselt muutumatuks. See eksisteerib range piiratuse kontekstis.
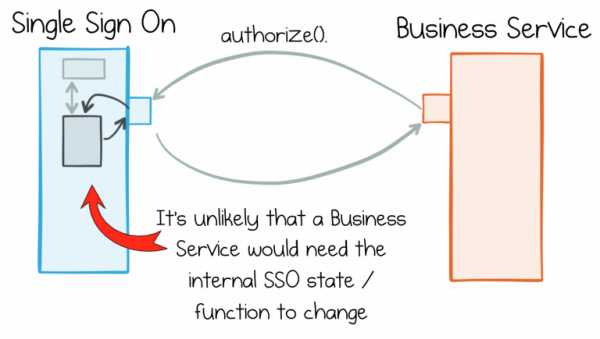
Probleem seisneb selles, et reaalses maailmas ei saa äriteenused pidevalt säilitada sama puhast rolli jaotust. Näiteks töötavad need samad äriteenused laiemalt andmetega, mis on saadud teistelt sarnastelt teenustelt. Kui tegelete veebikaubandusega, siis tellimuste, tootekatalooge või kasutajainformatsiooni töötlemine saab olema paljude teie teenuste nõudmine. Iga teenus vajab nende andmete töötlemiseks ligipääsu.
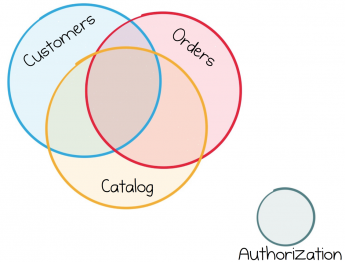
Enamik äriteenuseid kasutavad üks ja sama andmevoogu, seetõttu on nende töö pidevalt omavahel seotud.
Nii oleme jõudnud olulisse hetke, millest tasub rääkida. Kuigi teenused toimivad hästi infrastruktuuri komponentide puhul, mis töötavad suures osas isoleeritult, on enamik äriteenuseid omavahel tihedalt seotud.
Andmete dikotoomia
Teenustele orienteeritud lähenemised võivad juba eksisteerida, kuid neis on endiselt vähe teavet selle kohta, kuidas vahetada suuri andmemahtusid teenuste vahel.
Põhiprobleem on see, et andmed ja teenused on lahutamatud. Ühest küljest kutsub kapseldamine meid andmeid peitma, et teenuseid oleks võimalik omavahel eraldada ning nende kasvu ja edasisi muutusi lihtsustada. Teisest küljest peame saama vabalt jagada ja hallata ühiseid andmeid, nagu ka mis tahes teisi. Küsimus on selles, et oleksime võimelised kohe tööle asuma, sama vabalt kui mis tahes muus infosüsteemis.
Kuid informatsioonisüsteemidel on vähe ühist kapseldamisega. Tegelikult on see isegi vastupidine. Andmebaasid teevad kõik endast oleneva, et anda juurdepääs neis hoitavatele andmetele. Need pakuvad võimsat deklaratiivset liidest, mis võimaldab andmeid vastavalt vajadusele muuta. See funktsionaalsus on oluline eeluurimise etapis, kuid mitte pidevalt areneva teenuse keerukuse haldamiseks.
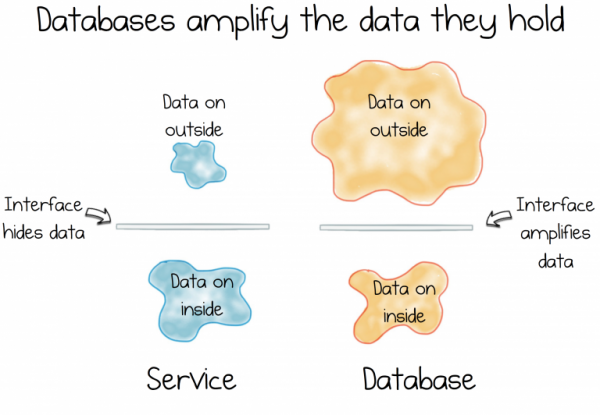
Ja siin tekib dilemma. Vasturääkivus. Dihotoomia. Sest informatsioonisüsteemid on seotud andmete pakkumisega, samas kui teenused on seotud nende varjamisega.
Need kaks jõudu on fundamentaalsed. Need on meie töö põhialuseks, pidevalt võideldes ülemvõimu nimel meie loodud süsteemides.
Teen, kui teenusesüsteemid arenevad ja kasvavad, märkame andmete diktoomia erinevaid väljundeid. Kas teenuse liides laieneb, pakkudes üha laiemat funktsioonide kogumit ja hakkab nägema välja nagu veidra koduvalmistatud andmebaas, või seisame silmitsi pettumusega ja leiname vajadust leida viise massiliste andmekogumite teenuste vahel liikumiseks või teisaldamiseks.
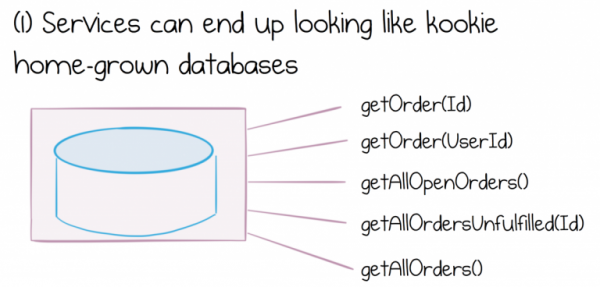
Oma olemuselt viib miski, mis näeb välja nagu veidralt koduvalmistatud andmebaas, terve rea probleemideni. Me ei põhjalda nüüd, kui ohtlik see on, shared database, lihtsalt ütleme, et see esindab märkimisväärseid ja kallid inseneri- ja operatiivsed ettevõttele, kes üritab seda kasutada.
Halvem on see, et andmemaht suurendab teenuste vaheprobleeme. Mida rohkem jagatud andmeid teenuses on, seda keerulisemaks muutub liides ja seda raskem on ühendada erinevatest teenustest pärit andmekogumeid.
Alternatiivne lähenemine andmekogude täieliku eraldamisele ja liigutamisele toob endaga kaasa oma probleemid. Levinud lähenemine sellele probleemile on andmekogumi lihtne eraldamine ja säilitamine, mille järel hoitakse seda kohapeal igas tarbimisteenus.
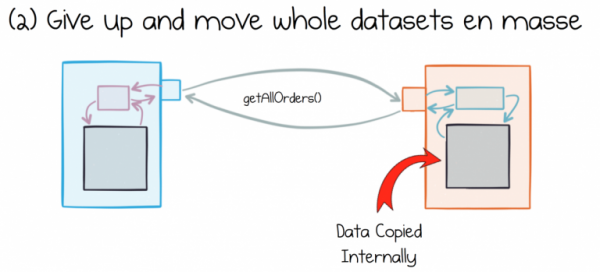
Probleem seisneb selles, et erinevad teenused tõlgendavad andmeid, mida nad tarbivad, erinevalt. Need andmed on alati käepärast. Need muutuvad ja töödeldakse kohapeal. Suhteliselt kiiresti kaotavad nad igasuguse seose allikate andmetega.
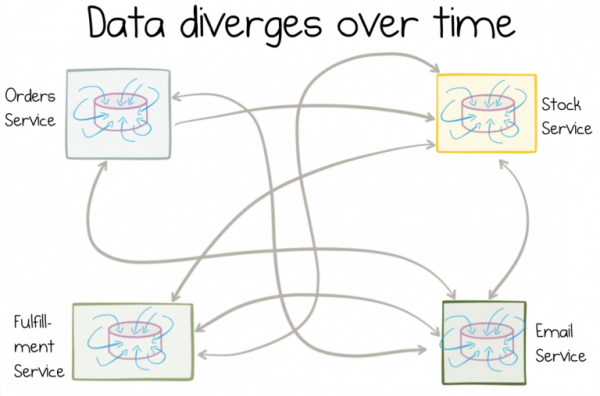
Mida mutatiivsemad on koopiad, seda rohkem erinevad andmed aja jooksul.
Veelgi hullem on, et selliseid andmeid on retrospektiivis raske parandada ( siin võib tõepoolest abiks tulla). Tegelikult on mõned keerulised tehnoloogilised probleemid, millega ettevõtted silmitsi seisavad, tingitud heterogeensetest andmetest, mis paljunevad rakendusest rakendusse.
Selle probleemi lahendamiseks, mis puudutab ühiseid andmeid, tuleb mõelda teistmoodi. Need peaksid olema esmaklassilised objektid arhitektuurides, mida me loome. nimeltakse selliseid andmeid "välisteks", ja see on väga oluline omadus. Me vajame kapseldamist, et mitte paljastada teenuse sisemist struktuuri, kuid peame hõlbustama teenustel juurdepääsu jagatud andmetele, et nad saaksid oma tööd tõhusalt teha.
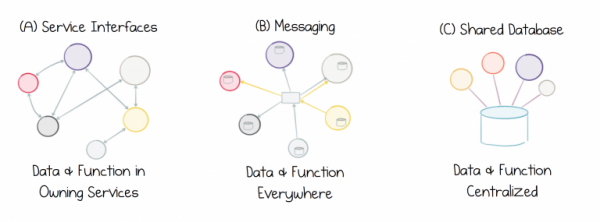
Probleem seisneb selles, et ükski tänapäevane lähenemine ei ole enam asjakohane, kuna ei teenuse liidesed, sõnumivahetus ega jagatud andmebaasid ei paku head lahendust välistest andmetest töötamiseks. Teenuse liidesed ei sobi andmete vahetamiseks mingis mahus. Sõnumivahetus edastab andmeid, kuid ei hoia nende ajalugu, seetõttu andmed aja jooksul kahjustuvad. Jagatud andmebaasid keskenduvad liiga tugevalt ühes kohas, mis pidurdab arengu edenemist. Me jääme paratamatult andmete ebaõnnestumise tsüklisse:
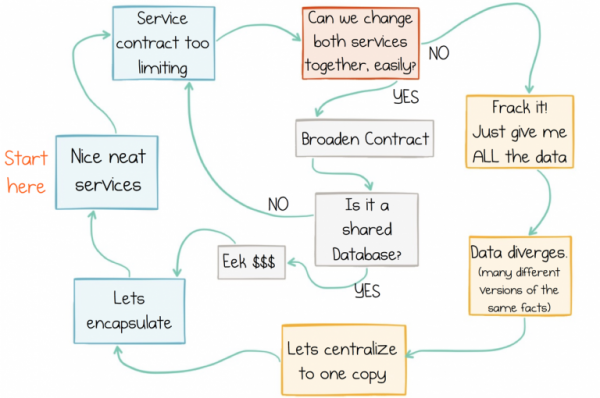
Andmete ebaõnnestumise tsükkel
Voogud: detsentraliseeritud lähenemine andmetele ja teenustele
Ideaalis peaksime muutma lähenemist sellele, kuidas teenused töötavad jagatud andmetega. Praegu seisavad kõik lähenemised silmitsi ülaltoodud dikotoomiaga, kuna ei ole olemas mingit imerohtu, mille abil saaksime selle lahendada. Siiski saame problematiseerimist ümber mõelda ja jõuda kompromissini.
See kompromiss eeldab teatud määral tsentraliseerimist. Saame kasutada detsentraliseeritud logide mehhanismi, kuna see tagab usaldusväärsed ja skaleeritavad vood. Nüüd on vaja, et teenused saaksid ühineda ja töötada nende jagatud voogudega, kuid soovime vältida keerulisi tsentraliseeritud God Service'e, mis sellist töötlemist teevad. Seega on parim variant integreerida voogude töötlemine igasse teenusekasutajasse. Nii saavad teenused ühendada andmestikke erinevatest allikatest ja kasutada neid vajalikel viisidel.
Üks viis sellise lähenemisviisi saavutamiseks on voogedastusteenuse kasutamine. Valikuid on palju, kuid täna vaatame Kafka't, kuna selle Stateful Stream Processing võimaldab tõhusalt lahendada esitatud probleemi.
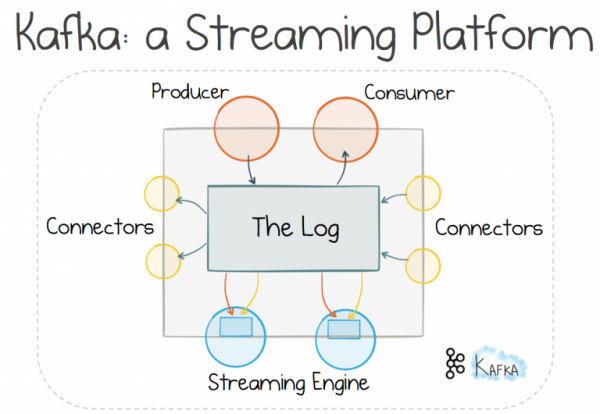
Jaotatud loggingu mehhanismi kasutamine võimaldab meil minna kulutatud teed pidi ja kasutada sõnumivahetust, et töötada . Sellise lähenemise puhul peetakse, et see tagab parema skaleeritavuse ja jaotuse kui "päring-vastus" mehhanism, kuna see annab voolu kontrolli saajale, mitte saatjale. Kuid kõik nõuab elus maksmist, ja siin on teil vaja vahetusjaama. Kuid suurte süsteemide puhul on see kompromiss seda väärt (mida ei saa öelda teie keskmiste veebirakenduste kohta).
Kui hajutatud logimise eest vastutab vahendaja, mitte traditsiooniline sõnumitesüsteem, saab kasutada lisafunktsioone. Transporti on võimalik lineaarselt skaleerida peaaegu sama hästi kui hajutatud failisüsteemi. Andmeid saab salvestada logides piisavalt kaua, seega saame mitte ainult sõnumite edastamise, vaid ka teabe hoidmist. Skaleeritav salvestus ilma hirmuta saada muudetav ühine olek.
Seejärel saab kasutada stateful stream processing (olekuga voogude töötlemise) mehhanismi, et lisada deklareeritud andmebaasi tööriistu tarbimisteenustele. See on väga oluline mõte. Kuni andmed on salvestatud ühistes voogudes, millega kõik teenused saavad juurde pääseda, on teenuse poolt ühendamine ja töötlemine privaatne. Need jäävad rangelt piiratud konteksti isolatsiooni.
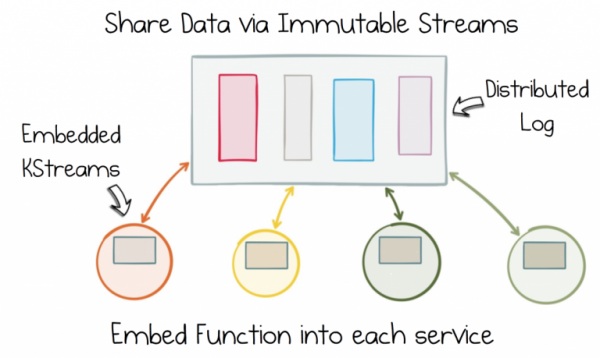
Vabanege andmete dikotoomiast, eraldades immutaabelne olekuvoog. Seejärel lisage see funktsioon igasse teenusesse Stateful Stream Processing'i abil.
Seega, kui teie teenus peab töötama tellimustega, toote katalooge, varudega, on teil täielik juurdepääs: ainult teie otsustate, millised andmed ühendada, kus neid töödelda ja kuidas need ajaga muutuvad. Hoolimata sellest, et andmed on jagatud, on töötlemine täiesti detsentraliseeritud. See toimub igas teenuses, maailmas, kus kõik käib teie reeglite järgi.
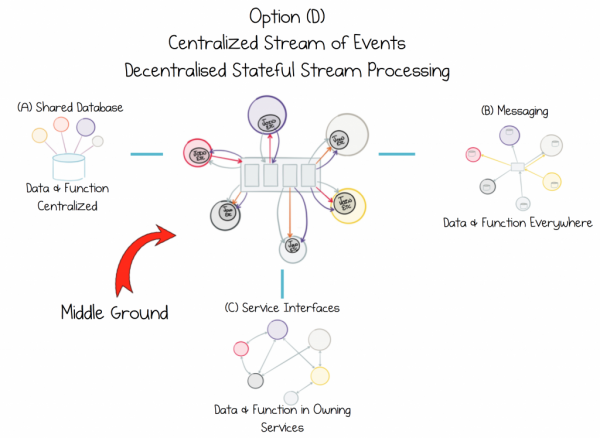
Jagage andmeid nii, et nende terviklikkus ei oleks ohustatud. Omakorda funktsioon, mitte allikas, igas teenuses, kus seda vajatakse.
Tegelikult võib andmeid olla vaja massiliselt liigutada. Mõnikord vajab teenus valitud andmebaasi mootori jaoks kohalikke ajaloolisi andmekogumeid. Punkt on see, et võite garanteerida, et vajadusel saab koopia taastada allikast, kasutades jaotatud logimise mehhanismi. Kafka ühendajad teevad seda ülesannet suurepäraselt.
Nii et tänasel käsitletud lähenemisel on mitmeid eeliseid:
- Andmed kasutatakse ühisvoogudena, mis võivad pikka aega logides säilida, samas kui ühiste andmete töötlemise mehhanism on igas eraldi kontekstis põhjalikult sisse ehitatud, mis võimaldab teenustel toimida lihtsalt ja kiiresti. Selline lähenemine tasakaalustab andmete dualismi.
- Erinevatest teenustest saadud andmeid saab hõlpsasti liita kogudeks. See lihtsustab suhtlemist ühiste andmetega ja kaotab vajaduse toetada kohalikke andmekogusid andmebaasis.
- Stateful Stream Processing salvestab andmeid ainult vahemällu, samas kui tõe allikaks jäävad ühised logid, seetõttu ei ole andmete ajaga kahjustumise probleem nii terav.
- Oma olemuselt juhitakse teenuseid andmete kaudu, mis tähendab, et kuigi andmemahtude kasv on pidev, suudavad teenused siiski kiiresti reageerida ärisündmustele.
- Skaleeritavuse probleemid langevad maaklerite õlule, mitte teenustele. Seega väheneb teenuste kirjutamise keerukus oluliselt, kuna ei pea muretsema skaleeritavuse pärast.
- Uute teenuste lisamine ei nõua vanade muutmist, mistõttu on uute teenuste ühendamine lihtsam.
Nagu näete, on see rohkem kui lihtsalt REST. Meil on tööriistade komplekt, mis võimaldab töötada ühiste andmetega detsentraliseeritud süsteemis.
Täna artiklis ei ole käsitletud kaugeltki kõiki aspekte. Me peame veel välja selgitama, kuidas tasakaalustada päringute ja vastuste paradigma ning sündmustepõhise paradigma vahel. Kuid me tegeleme sellega järgmisel korral. On teemasid, mida tasub põhjalikumalt tundma õppida, näiteks, mis teeb Stateful Stream Processing nii heaks. Sellest räägime kolmandas artiklis. Samuti on teisi võimsaid konstruktsioone, mida saame kasutada, kui me neid rakendame, näiteks, . Selle abil muutuvad mängureeglid jaotatud ärisüsteemide jaoks, kuna see konstruktsioon tagab tehingu garantii skaleeritaval viisil. Sellest räägime neljandas artiklis. Ja lõpuks peame üle käima nende põhimõtete rakendamise detailidest.
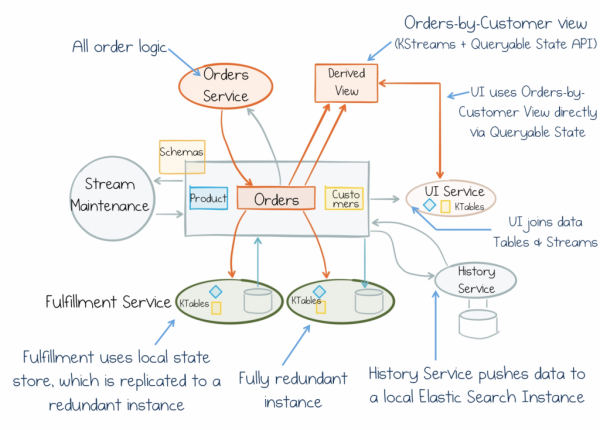
Aga seni lihtsalt pea meeles järgmist: andmete dikhootoomia on jõud, millega me silmitsi seisame äriteenuste loomisel. Ja me peame seda meeles pidama. Fookus on selles, et pöörata kõik pea peale ja hakata käsitlema ühisandmeid esmaklassiliste objektidena. Stateful Stream Processing pakub selleks ainulaadset kompromissi. See väldib tsentraliseeritud „jumalikku komponente”, mis pidurdavad progressi. Veelgi enam, see tagab andmevoogude käideldavuse, skaleeritavuse ja tõrgeteta töö ning lisab need igasse teenusesse. Nii saame keskenduda ühiselt mõttekäigule, millele saab ühenduda iga teenus ja töötada selle andmetega. Seetõttu võtavad teenused omandades rohkem skaleeritavust, vahetatavust ja iseseisvust. Nad näevad seetõttu mitte ainult head välja tahvelarvutites ja hüpoteeside kontrollimisel, vaid toimivad ja arenevad aastakümneid.
Allikas: habr.com
