

Austatud kogukond, see artikkel käsitleb sadade miljonite väikeste failide efektiivset salvestamist ja edastamist. Käesoleval etapil pakutakse täielikku lahendust POSIX ühilduvatele failisüsteemidele, mis toetavad täielikult lukustusi, sealhulgas klastrite lukustusi, ja näib, et isegi ilma igasuguste lahendusteta.
Seetõttu kirjutasin selle eesmärgi saavutamiseks enda spetsialiseeritud serveri.
Selle ülesande täitmise käigus õnnestus lahendada peamine probleem ning samal ajal saavutada diskruumi ja RAM-i kokkuhoid, mida meie klastrifailisüsteem oli äärmiselt palju kasutanud. Tõepoolest, selline failide hulk on kahjulik igasugusele klastrifailisüsteemile.
Kava on järgmine:
Lihtsate sõnadega, laaditakse serverisse väikesed failid, mis salvestatakse otse arhiivi ja loetakse sealt samuti, suuremad failid paigutatakse kõrvale. Skeem: 1 kaust = 1 arhiiv, kokku on meil mitmiljonite väikeste failidega arhiive, mitte sadu miljonite faile. Ja kõik see on korralikult teostatud, ilma igasuguste skriptide ja failide jaotamiseta tar/zip arhiividesse.
Püüan lühidalt väljendada, vabandan ette, kui postitus osutub tihedaks.
Kõik algas sellest, et ma ei suutnud leida sobivat serverit, mis suudaks salvestada andmeid, mis saadakse HTTP protokolli kaudu otse arhiividesse, nii et ei ilmneks tavaliste arhiivide ja objektide hoidlate puudusi. Otsingute põhjuseks sai ulatuslik Origin klaster, mis koosnes 10 serverist ja milles oli juba 250 000 000 väikest faili, ning kasvutrend ei paistnud peatuvat.
Neile, kes ei armasta artiklite lugemist ja eelistavad lühemat dokumentatsiooni:
ja .
Ja docker koos, praegu on variant ainult nginxiga sees, igaks juhuks:
docker run -d --restart=always -e host=localhost -e root=/var/storage
-v /var/storage:/var/storage --name wzd -p 80:80 eltaline/wzdEdasi:
Kui faile on väga palju, on vajalikud suured ressursid, ja mis veelgi häirivam, osa neist kaob raisku. Näiteks klasterfailisüsteemi (antud juhul — MooseFS) kasutamisel võtab fail, sõltumata tegelikust suurusest, alati vähemalt 64 KB. See tähendab, et 3, 10 või 30 KB suuruste failide jaoks on kettal vajalik 64 KB. Kui faile on veerand miljardit, kaotame 2 kuni 10 terabaiti. Uute failide lõputu loomine ei õnnestu, kuna MooseFS-is on piirang: mitte rohkem kui 1 miljard ühe faili repliiki.
Failide arvu suurenedes on metainfo jaoks vajalik palju RAM-i. Samuti soodustavad tihedad suured metainfotuhandid SSD-kettaste kulumist.
Server wZD. Teeme kettad korda.
Server on kirjutatud Go keeles. Ennekõike pidin vähendama failide arvu. Kuidas seda teha? Arhiveerimise kaudu, kuid antud juhul ilma kompresseerimiseta, kuna mul on failid, mis on pidevalt kokku surutud pildid. Abiks tuli BoltDB, millel tuli veel puudusi kõrvaldada, mis kajastub dokumentatsioonis.
Kokkuvõttes on mul alles vaid 10 miljonit Bolt arhiivi, kuigi algselt oli neid veerand miljardit. Kui oleks võimalik muuta praegust direktorite failistruktuuri, oleks võimalik vähendada nende arvu umbes miljoni faili peale.
Kõik väiksed failid pakitakse Bolt arhiividesse, mis automaatselt saavad direktorite nimed, milles nad asuvad, samas kui kõik suured failid jäävad arhivide kõrvale, neid pole mõtet pakkida, seda saab seadistada. Väikesed — arhiveerime, suured — jätame muutumatuks. Server töötab sujuvalt nii nende kui ka teistega.
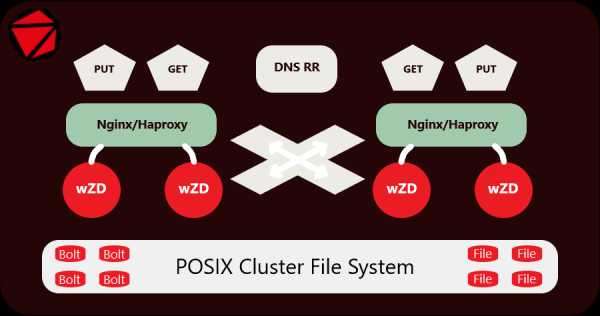
wZD serveri arhitektuur ja omadused.

Server töötab operatsioonisüsteemide Linux, BSD, Solaris ja OSX all. Olen testinud ainult AMD64 arhitektuuri Linuxis, kuid see peaks olema sobiv ka ARM64, PPC64, MIPS64 jaoks.
Peamised omadused:
- Mitme tahkeline;
- Mitme serveri töö, mis tagab katkestusteta töö ja koormuse tasakaalu;
- Maksimaalne läbipaistvus kasutajale või arendajale;
- Toetatud HTTP meetodid: GET, HEAD, PUT ja DELETE;
- Käitumise juhtimine lugemise ja kirjutamise ajal läbi kliendi pealkirjade;
- Kohandatavad virtuaalsed hostid;
- CRC andmete terviklikkuse tugi kirjutamisel/loetamisel;
- Pooldünaamilised pusled minimaalsete mälu nõudmiste ja optimaalse võrgu jõudluse seadistamiseks;
- Kompaktsiooni edasilükkamine;
- Lisaks pakutakse mitme lõimega arhiveerijat wZA failide migreerimiseks teenuse katkestamata;
Tegeliku kogemuse põhjal:
Olen arendanud ja testinud serverit ja arhiveerijat reaalsetel andmetel üsna pikka aega, praegu töötab see edukalt klastris, mis sisaldab 250,000,000 väikest faili (pilti), mis asuvad 15,000,000 kaustas eraldiseisvates SATA-kettastes. 10-serverline klaster toimib Origin-serverina, mis on paigaldatud CDN-võrgu taha. Selle haldamiseks kasutatakse 2 Nginx-serverit + 2 wZD-serverit.
Neile, kes otsustavad seda serverit kasutada, on mõistlik enne kasutamist planeerida kausta struktuur, kui see on kohaldatav. Koheselt mainin, et server ei ole mõeldud kõike ühte Bolt arhiivi surumiseks.
Jõudluse testimine:
Mida väiksem on arhiveeritud faili suurus, seda kiiremini toimuvad GET ja PUT operatsioonid. Vaatleme HTTP kliendi kogu kirjutamise aega tavalfailides ja Bolt arhiivides, samuti lugemist. Võrdleme failide töötlemist suurustega 32 KB, 256 KB, 1024 KB, 4096 KB ja 32768 KB.
Bolt arhiividega töötades kontrollitakse iga faili andmete terviklikkust (kasutatakse CRC), enne записимости ja pärast записimist toimub kohene lugemine ja üleloendamine, mis toob loomulikult kaasa viivitusi, kuid peamine on andmete turvalisus.
Teostasin jõudlustestid SSD-mäluseadmetel, kuna SATA-diskide testid ei näita erilist erinevust.
Testimistulemuste graafikud:
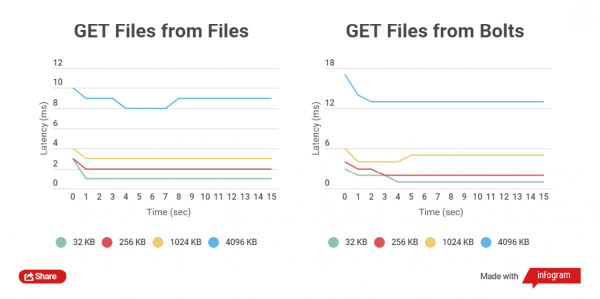
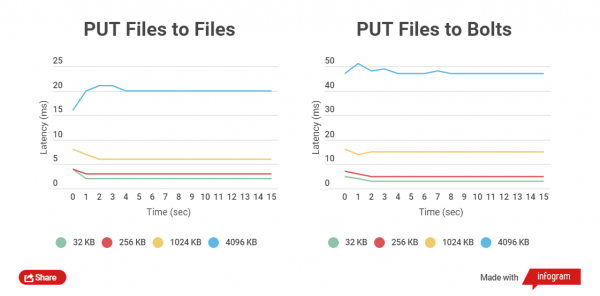
Nagu näha, on väikeste failide vahel arhiveeritud ja arhiveerimata failide lugemise ja kirjutamise aja erinevus väike.
Teistsuguse pildi saame faili suurusega 32 MB lugemise ja kirjutamise testil:
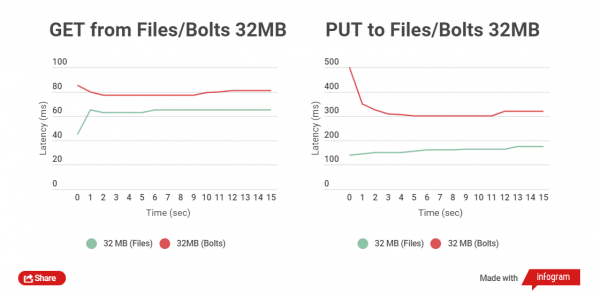
Failide lugemise vahel on aja erinevus 5-25 ms. Kirjutamise osas on asjad halvemini, erinevus ulatub umbes 150 ms. Siiski ei ole mõtet suuri faile üles laadida, need võivad eraldi eksisteerida arhiividest.
*Tehniliselt saab seda serverit kasutada ka NoSQL nõudmistega ülesannete jaoks.
Peamised töö meetodid wZD serveriga:
Tavalise faili üleslaadimine:
curl -X PUT --data-binary @test.jpg http://localhost/test/test.jpgFaili üleslaadimine Bolt arhiivi (kuni serveri parameeter fmaxsize, mis määrab maksimaalse faili suuruse, ei ole ületatud; kui on ületatud, laaditakse fail tavapäraselt arhiivi kõrvale):
curl -X PUT -H "Archive: 1" --data-binary @test.jpg http://localhost/test/test.jpgFaili allalaadimine (kui kettal ja arhiivis on sama nimega faile, eelistatakse allalaadimisel vaikesena mitte-arhiveeritud faili):
curl -o test.jpg http://localhost/test/test.jpgFaili allalaadimine Bolt arhiivist (sunditud):
curl -o test.jpg -H "FromArchive: 1" http://localhost/test/test.jpgMuude meetodite kirjeldus on dokumentatsioonis.
Server toetab hetkel ainult HTTP protokolli, HTTPS ei tööta veel. Samuti ei toetata POST meetodit (kas see on vajalik, pole veel otsustatud).
Kes uurib lähtekoodi, leiab sealt irise, mida kõik ei armasta, aga ma ei sidunud põhikoodi veebiraamistike funktsioonidega, välja arvatud katkestuste töötleja, nii et ma saan vajadusel kiiresti peaaegu iga mootori jaoks ümber kirjutada.
ToDo:
- Oma replikatori ja distributori arendamine + geo võimalus suurte süsteemide kasutamiseks ilma klasterifailisüsteemideta (kõik tõsiselt)
- Täieliku pöördprotsessimise võimalus metandateede täieliku kadumise korral (distributori kasutamise juhul)
- Natiivne protokoll pidevate võrguühenduste kasutamise võimaluseks ja draiverid erinevatele programmeerimiskeeltele
- Täpsemad võimalused NoSQL komponentide kasutamiseks
- Erinevate tüüpide tihendamine (gzip, zstd, snappy) failide või laskude jaoks Bolt arhiivides ja tavalisetes failides
- Erinevate tüüpide krüpteerimine failide või laskude jaoks Bolt arhiivides ja tavalisetes failides
- Edasilükatud serveri videokonversioon, sealhulgas GPU kasutamine
Minu poolt kõik, loodan, et see server on kellelegi kasulik, BSD-3 litsents, kahekordne autorikaitse, kuna kui mitte firma, kus ma töötan, ei oleks ma serverit kirjutanud. Olen arendaja üksi. Olen tänulik leitud bugide ja funktsioonide soovituste eest.
Allikas: habr.com
