


Kuna ClickHouse on spetsiifiline süsteem, tuleb selle kasutamisel arvesse võtta selle arhitektuuri eripära. Selles ettekandes räägib Aleksei näidetest tüüpilistest vigadest ClickHouse'i kasutamisel, mis võivad viia ebaefektiivse tööni. Praktikast tulevad näited näitavad, kuidas andmete töötlemise skeemi valik võib oluliselt muuta jõudlust.
Tere kõigile! Minu nimi on Aleksei, ma teen ClickHouse'i.

Esiteks, kiirustan teid rõõmustama, et ma ei hakka täna rääkima, mis on ClickHouse. Ausalt öeldes, mulle on see juba tüütav. Iga kord räägin sellest. Ja tõenäoliselt teavad kõik juba.

Selle asemel räägin ma võimalikest komistuskividest, st kuidas ClickHouse'i vale kasutamine võib juhtuda. Tegelikult ei ole põhjust muretseda, sest me arendame ClickHouse'i süsteemina, mis on lihtne, mugav ja töötab otse karbist. Paigaldad ja kõik, mingeid probleeme pole.
Siiski tuleb arvestada, et see süsteem on spetsialiseeritud ning võib kergesti sattuda ebatavalisse kasutusstsenaariumi, mis viib selle mugavustsoonist välja.
Nii et millised on nähtavad probleemid? Peamiselt räägin ilmselgetest asjadest. Kõik saavad aru, kõik mõistavad ja võivad rõõmustada, et nad on nii targad, ning need, kes ei saa aru, saavad midagi uut teada.

Esimene ja kõige lihtsam näide, millega kahjuks sageli kokku puututakse, on suur hulk sisendeid, mis on väikesed partiid, st suur hulk väikeseid sisendeid.
Kui vaadata, kuidas ClickHouse sisendeid sooritab, siis võite ühe päringuga saata isegi terabaidi andmevoo. See ei ole probleem.
Vaatame nüüd, milline on tüüpiline tulemuslikkus. Näiteks meil on tabel Yandex.Metrika andmetega. Hitid. 105 erinevat veergu. 700 baiti tihendamata kujul. Ja alustame sisestamist korralike partiidena, kus on miljon rida.
Sisestades MergeTree tabelisse, saame umbes pool miljonit rida sekundis. Suurepärane! Replitseeritud tabelis on see veidi vähem, umbes 400 000 rida sekundis.
Ja kui aktiveerida kvora sisestamine, siis saadakse pisut vähem, kuid ikkagi korralik jõudlus, 250 000 rida sekundis. Kvora sisestamine on dokumenteerimata võimalus ClickHouse'is*.
* seisuga 2020. aasta. .

Mida teha, kui asjad lähevad halvasti? Sisestame ühe rea korraga MergeTree tabelisse ja saame 59 rida sekundis. See on 10 000 korda aeglasem. ReplicatedMergeTree puhul on see 6 rida sekundis. Ja kui kvora veel sisse lülitada, siis on see 2 rida sekundis. Minu arvates on see täielik fiasco. Kuidas saab nii aeglane olla? Mul on isegi T-särgis kirjas, et ClickHouse ei tohi aeglane olla. Kuid siiski juhtub seda mõnikord.

Tegelikult on see meie viga. Me oleks saand teha nii, et kõik töötaks normaalselt, aga me ei teinud. Ja me ei teinud sellepärast, et meie stsenaariumis ei olnud see vajalik. Meil olid juba partiid. Lihtsalt meie jaoks tulid partiid sisse ja polnud mingeid probleeme. Paneme andmed sisse ja kõik töötab normaalselt. Aga muidugi võivad esineda igasuguseid stsenaariume. Näiteks, kui teil on hulk servereid, kus andmeid genereeritakse. Ja nad sisestavad andmeid mitte nii sageli, kuid siiski tulevad sagedased sisestused. Ja sellega tuleb kuidagi toime tulla.
Tehnilisest küljest on asi selles, et kui teete ClickHouse'is sisestuse, ei satu andmed ühtegi memtable'i. Meil pole isegi reaalset log structure MergeTree't, vaid lihtsalt MergeTree, kuna log'i ega memTable'i pole. Me kirjutame andmed otse failisüsteemi, juba veergude kaupa jaotatuna. Ja kui teil on 100 veergu, tuleb kirjutada üle 200 faili eraldi kausta. See kõik on üsna mahukas.

Ja tekib küsimus: "Kuidas õigesti teha?", kui selline olukord, et tuleb siiski kuidagi andmeid ClickHouse'i salvestada.
Meetod 1. See on kõige lihtsam meetod. Kasutage mõnda hajutatud järjekorda, näiteks Kafka. Lihtsalt tõstate andmeid Kafka'st, batšit iga sekundi järel. Ja kõik on korras, salvestate ja kõik töötab normaalselt.
Puuduseks on see, et Kafka on veel üks kohmakas hajutatud süsteem. Ma saan aru, kui teil on ettevõttes juba Kafka. See on hea, see on mugav. Kuid kui seda ei ole, siis tasub enne veel ühe hajutatud süsteemi projekti toomist kolm korda mõelda. Seepärast tasub kaaluda alternatiive.

Meetod 2. Selline vanakooli alternatiiv, mis on samas väga lihtne. Teil on server, mis genereerib teie logisid. Ja see salvestab teie logid failina. Ja näiteks korra sekundis nimetame selle faili ümber ja avame uue. Eraldi skript, kas croni või mõne daemoni kaudu, võtab kõige vanema faili ja salvestab selle ClickHouse'i. Kui logisid salvestada korra sekundis, siis on kõik suurepärane.
Kuid selle meetodi puudus on see, et kui teie server, kus logid genereeritakse, kuhugi kaob, kaovad ka andmed.

Meetod 3. On veel üks huvitav viis, mis ei kasuta ajutisi faile. Näiteks võib teil olla mõni reklaamipööre või muu huvitav daemon, mis genereerib andmeid. Saate andmepaketi koguda otse mälus, puhvrisse. Ja kui aega on möödunud piisavalt, asetate selle puhvri kõrvale, loote uue ning eraldi tahkudes sisestate juba kogunenud andmed ClickHouse'i.
Teisest küljest kaovad andmed kill -9 korral. Kui teie server crashes, kaotate need andmed. Ja veel on probleemiks see, et kui te ei saanud andmeid andmebaasi salvestada, hakkavad need andmed kuhjuma mällu. Kasmalt kaotate mälu või kaotate lihtsalt andmed.

Meetod 4. Veel üks huvitav viis. Kui teil on mõni serveriprotsess. Ja ta võib andmeid saata ClickHouse'i kohe, aga seda ühes ühenduses. Näiteks, saadetakse http-päring koos transfer-encoding: chunked ja insert’iga. Ja genereeritakse tükkide kaupa mitte liiga harva, võib igat rida saata, kuigi andmete framing'i tõttu tekib ülekandekiirus.
Kuid sel juhul saadetakse andmed siiski kohe ClickHouse'i. Ja ClickHouse bufrib neid ise.
Aga tekkivad probleemid. Nüüd kaotate andmed, sealhulgas siis, kui teie protsess katkestatakse ja kui ClickHouse'i protsess katkestatakse, kuna see jääb lõpetamata insert'i taha. ClickHouse'i insert'id on aatomilised teatud ridade piiri ulatuses. Üldiselt on see huvitav meetod. Seda võib kasutada ka.

Meetod 5. Siin on veel üks huvitav meetod. See on mingisugune kogukonna välja töötatud server andmete grupiseerimiseks. Ma ei ole seda ise vaatamas käinud, seega ei saa ma midagi garanteerida. Siiski ei anta ka ClickHouse'i enda puhul mingeid garantiisid. See on samuti avatud lähtekoodiga, kuid teisest küljest võite olla harjunud teatud kvaliteedistandardiga, mida me püüame tagada. Ent selle asja kohta – ma ei tea, minge GitHub'i, vaadake koodi. Võib-olla on seal midagi normaalset kirjutatud.
* seisuga 2020. aasta, tuleks lisada ka kaalu alla .

Meetod 6. Veel üks meetod on Buffer tabelite kasutamine. Selle meetodi eeliseks on see, et selle kasutamine on väga lihtne. Loote Buffer tabeli ja lisate sinna.
Kuid puuduseks on see, et probleem ei lahene täielikult. Kui MergeTree tüüpi lisamiste korral peate andmeid grupeerima ühe partii kaupa sekundis, siis Buffer tabelisse lisamisel peate grupeerima vähemalt mitu tuhat sekundis. Kui neid on rohkem kui 10 000 sekundis, on see ikka halb. Ja kui te lisate partiidena, siis nägite, et seal võib olla sadu tuhandeid ridu sekundis. Ja see on juba üsna raskete andmete puhul.
Samuti ei oma buffer tabelid logi. Ja kui teie serveriga on midagi valesti, siis andmed kaovad.

Boonusena on ClickHouse'il hiljuti võimalus andmeid Kafka'st kinni püüda. On olemas tabeli mootori nimi - Kafka. Loote selle lihtsalt. Ja sellele saab kinnitada materialiseeritud vaateid. Sel juhul toob see automaatselt andmed Kafka'st ja lisab need soovitud tabelitesse.
Ja see, mis selle võimaluse juures eriti rõõmustab, on see, et seda ei teinud meie. See on kogukonna funktsioon. Ja kui ma räägin 'kogukonna funktsioonist', siis ei räägi ma seda mingisuguse põlgusega. Me lugesime koodi, tegime ülevaate, see peaks normaalselt töötama.
* seisuga 2020. aasta, on saadaval sarnane tugi .

Mis veel võib olla ebamugav või ootamatu andmete sisestamisel? Kui teete sisestamise päringu ja values'is kirjutate mingi arvutuslikke väljendeid. Näiteks, now() – see on samuti arvutuslik väljend. Sel juhul peab ClickHouse iga rea jaoks käivitama nende väljendite tõlgendaja, ja jõudlus langeb oluliselt. Paremini on seda vältida.
* hetkel on probleem täielikult lahendatud, jõudluselangust väljendite kasutamisel VALUES'is enam ei esine.
Teine olukord, kus võivad tekkida probleemid, on see, kui teil on ühes partiiandmestikus palju partiisid. ClickHouse'is on partiiandmestik vaikimisi kuude kaupa. Ja kui sisestate partii miljonist reast, kus andmed on mitme aasta kohta, on teil seal mitu kümmet partiid. See on ekvivalentne sellega, et partii on mitu korda väiksem, sest need jagunevad alati kõigepealt partiiandmestike kaupa.
* Hiljuti on ClickHouse'is katserežiimis lisatud toetus kompaktsel formaadil osadele ja osadele mälus koos write-ahead log'iga, mis peaaegu täielikult lahendab probleemi.

Nüüd vaatame teist tüüpi probleemi – andmete tüüpimist.
Andmete tüüpimine võib olla range või stringiline. Stringiline on siis, kui olete lihtsalt öelnud, et kõik teie väljad on tüüpi string. See on halb. Nii ei tohiks teha.
Vaatame, kuidas õigesti teha olukordades, kus soovite öelda, et mõni väli on meil string ja las ClickHouse ise sellega tegeleb, aga siiski on mõistlik katta mõned vaeva.

Näiteks meil on IP-aadress. Ühes näites oleme selle salvestanud stringina. Näiteks 192.168.1.1. Teises näites on see number tüüpi UInt32*. 32 bitti on piisavalt IPv4 aadressi jaoks.
Esiteks, kuigi see võib tunduda kummaline, surutakse andmed kokku ligikaudu ühtemoodi. Seal on vahe, muidugi, aga mitte nii suur. Nii et ketta sisendi- ja väljundi osas erilisi probleeme pole.
Aga on märkimisväärne vahe protsessori ajal ja päringu täitmise ajas.
Arvutame ainulaadsete IP-aadresside arvu, kui need on salvestatud numbritena. Tulemuseks on 137 miljonit rida sekundis. Kui sama stringide kujul, siis 37 miljonit rida sekundis. Ma ei tea, miks selline kokkusattumine juhtus. Mina ise tegin need päringud. Kuid siiski on see umbes 4 korda aeglasem.
Ja kui arvestada vahet diskil, siis vahe on ka olemas. Ja vahe on umbes veerandi ulatuses, sest ainulaadseid IP-aadresse on piisavalt palju. Kui siin oleks read väikese arvu erinevate väärtustega, siis need suruksid ennast sõnastiku järgi tõenäoliselt umbes ühesugusesse mahtu.
Ja neljakordne ajavahe teel ei ole mitte midagi. Võib-olla sind ei huvita, aga kui ma näen sellist vahet, tunnen ma end kurvalt.

Vaatame erinevaid juhtumeid.
1. Üks juhtum, kui sul on erinevaid unikaalseid väärtusi vähe. Sel juhul kasutame lihtsat praktikat, mida sa tõenäoliselt tead ja saad kasutada mis tahes andmebaaside haldussüsteemide puhul. See kehtib mitte ainult ClickHouse'i jaoks. Salvestage lihtsalt numbrilisi identifikaatoreid. Ja teisendada stringideks ja tagasi saab juba oma rakenduse poolel.
Näiteks, kui sul on piirkond. Ja sa püüad seda salvestada stringina. Seal kirjutatakse: Moskva ja MO. Kui ma näen, et seal on kirjas 'Moskva', siis pole hullu, kuid kui lisada ka MO, läheb kõik veel nukramaks. Kui palju see on baite.
Kuna me salvestame lihtsalt arvu Ulnt32 ja 250. Meil on 250 Yandexis, aga sul võib olla teisiti. Igaks juhuks ütlen, et ClickHouse'il on sisseehitatud funktsioon geobaasiga töötamiseks. Sa lihtsalt salvestad piirkondade loendi, sealhulgas ka hierarhilise, st seal on nii Moskva kui MO, ja kõik, mis sul vaja on. Ja seda saab teisendada päringu tasemel.

Teine variant on umbes sama, kuid toega ClickHouse'is. See on Enum andmetüüp. Sa lihtsalt määratled Enum'is kõik vajalikud väärtused. Näiteks seadme tüüp, kuhu kirjutad: lauaarvuti, nutitelefon, tahvelarvuti, televiisor. Kokku 4 varianti.
Puuduseks on see, et tuleb perioodiliselt teha muutmine. Lisati vaid üks variant. Teeme alter table. Tegelikult on alter table ClickHouse'is tasuta. Eriti tasuta Enum'i puhul, sest andmed kettal ei muutu. Siiski, alter võtab tabeli peale lukustuse* ja peab ootama, kuni kõik select'id on lõpule viidud. Ja alles siis täidetakse alter, s.t. siiski on mõned ebamugavused.
* Uuemates ClickHouse'i versioonides on ALTER tehtud täiesti mitteblokkeerivaks.

Veel üks variant, mis on ClickHouse'i jaoks piisavalt ainulaadne, on väliste sõnastike ühendamine. Sa võid kirjutada ClickHouse'i numbreid ja hoida oma sõnastikke igas mugavas süsteemis. Näiteks võib kasutada: MySQL, Mongo, Postgres. Võid isegi luua oma mikroteenuse, mis edastab neid andmeid http kaudu. Ja ClickHouse'i tasemel kirjutad funktsiooni, mis muudab need andmed numbreid ridadeks.
See on spetsialiseeritud, kuid väga tõhus viis liita andmeid välise tabeliga. On kaks varianti. Ühes variandis on need andmed täielikult vahemälustatud, täiesti olemas mälus ja uuendatakse teatud perioodilisusega. Teises variandis, kui andmed ei mahu mällu, saab neid osaliselt vahemälustada.
Siin on näide. On Yandex.Direct. Seal on reklaamikampaania ja bännerid. Reklaamikampaaniaid on tõenäoliselt kümneid miljoneid. Need mahuvad enamasti mällu. Aga bännerid – miljardeid, need ei mahu. Ja me kasutame vahemälustatavat sõnastikku MySQL-st.
Ainus probleem on see, et vahemälustatav sõnastik töötab korralikult ainult siis, kui hit rate on lähedane 100%-le. Kui see on madalam, siis iga andmepaki töötlemisel tuleb tegelikult võtta puuduvaid võtmeid ja minna andmeid MySQL-st hankima. ClickHouse'i kohta võin veel kinnitada, et – jah, see ei pidurda, teiste süsteemide kohta ei hakka ma rääkima.
Ja boonusena on see, et sõnastikud on väga lihtne viis andmete ajakohastamiseks ClickHouse'is tagantjärele. See tähendab, et kui teil oli reklaamikampaania aruanne, vahetab kasutaja lihtsalt reklaamikampaaniat ja kõikides vanades andmetes, kõigis aruannetes muutuvad need andmed samuti. Kui kirjutada read otse tabelisse, siis nende uuendamine ei ole võimalik.

Teine võimalus, kui te ei tea, kust leida oma ridade identifikaatoreid, on lihtsalt need hashida. Ja kõige lihtsam variant on võtta 64-bitine hash.
Ainus probleem on see, et kui hash on 64-bitine, siis kollisiidid on praktiliselt garanteeritud. Sest kui seal on miljard rida, siis tõenäosus muutub juba oluliseks.
Ja ei oleks väga hea hashida reklaamikampaaniate nimesid nii. Kui reklaamikampaaniad erinevate ettevõtete vahel segamini lähevad, siis tekib mingi arusaamatus.
Ja on üks lihtne nipp. Tõsi, see ei sobi tõsiste andmete jaoks, kuid kui tegemist ei ole millegi tõsisega, siis lisage lihtsalt sõnastiku võtmesse veel kliendi identifikaator. Siis esinevad konfliktid, kuid ainult ühe kliendi piires. Sellist meetodit kasutame me Yandex.Metrica lingikaardi puhul. Meil on seal URL-id, salvestame hash'e. Ja me teame, et konfliktid esinevad, kuid kui lehekülg kuvatakse, siis on tõenäosus, et just ühel leheküljel on ühel kasutajal mingid URL-id kokku jäänud ja seda märgatakse, nii et seda võib ignoreerida.
Boonusena – paljude operatsioonide jaoks piisab ainult hash'idest, ja ise stringe ei pea kuskil hoidma.

Teine näide, kui stringid on lühikesed, näiteks domeenid. Need võib salvestada sellisena, nagu need on. Või näiteks brauseri keel ru – 2 baiti. Muidugi on mul kahju pisikestest baitidest, aga ärge muretsege, 2 baiti ei ole kahju. Palun salvestage, nagu on, ärge muretsege.

Teine olukord on see, kui ridasid on palju ja need on ühtlasi väga unikaalsed ning palju potentsiaalselt piiramatuid. Tüüpiline näide on otsingufraasid või URL-id. Otsingufraasid, sealhulgas tippimisvead. Vaatame, kui palju unikaalseid otsingufraase päevas. Ja selgub, et need moodustavad peaaegu poole kõigist sündmustest. Sel juhul võite mõelda, et andmeid tuleb normaliseerida, tuvastada identifikaatorid ja koguda eraldi tabelisse. Aga nii teha ei tohiks. Lihtsalt hoidke neid ridu sellisena, nagu nad on.
Parem on mitte midagi välja mõelda, sest kui hoida eraldi, tuleb teha join. Ja see join on parimal juhul juhuslik juurdepääs mälule, kui see veel mällu mahtuda suudab. Kui ei mahu, siis tekivad üldse probleemid.
Aga kui andmed on in place, lugetakse need lihtsalt õigesse järjekorda failisüsteemist ja kõik on korras.

Kui teil on URL-id või mingi muu keeruline pikk rida, siis tasub mõelda, et võiks mingisuguse kokkuvõtte eelnevalt arvutada ja salvestada eraldi veergu.
Näiteks URL-de puhul saab eraldi hoida domeeni. Ja kui teil on tegelikult domeen vajalik, siis kasutage lihtsalt seda veergu, ja URL-id lähevad olema, ning te ei pea neile isegi puudutama.
Vaatame, milline on erinevus. ClickHouse'is on spetsialiseeritud funktsioon, mis arvutab domeeni. See on väga kiire; me optimeerisime selle. Ja ausalt öeldes ei vasta see isegi RFC-le, aga see arvestab ikkagi kõike, mis meil vajalik on.
Ühes juhul saame me lihtsalt URL-e välja tõmmata ja domeeni arvutada. See võtab 166 millisekundit. Kui võtta aga valmis domeen, siis kulub vaid 67 millisekundit, see tähendab peaaegu kolm korda kiiremini. Kiirus ei tulene mitte vajadusest teha mingeid arvutusi, vaid sellest, et me loeme vähem andmeid.
Kuid mingil põhjusel on ühel päringul, mis on aeglasem, suurem gigabaitide kiirus. Sest see loeb rohkem gigabaite. Need on täiesti üleliigsed andmed. Päring töötab nagu kiiremini, kuid täidab ülesannet kauem.
Ja kui vaadata andmete mahtu kettal, siis selgub, et URL on 126 megabaiti, aga domeen vaid 5 megabaiti. See on 25 korda vähem. Siiski toimub päringu täitmine vaid 4 korda kiiremini. See on sellepärast, et andmed on kuumad. Kui aga need oleks külmad, oleks kahtlemata kiirus 25 korda suurem diskikande tõttu.
Tegelikult, kui hinnata, kui palju domeen on väiksem kui URL, siis see on umbes 4 korda. Kuid kummalisel kombel võtab andmete maht kettal 25 korda vähem. Miks? Selle põhjuseks on tihendamine. Nii URL kui domeen tihendatakse. Kuid sageli sisaldab URL palju prügi.

Ja muidugi, tuleks kasutada õigeid andmetüüpe, mis on spetsiaalselt mõeldud vajalike väärtuste jaoks või mis sobivad. Kui olete IPv4, hoidke UInt32*. Kui IPv6, siis FixedString(16), sest IPv6 aadress on 128 bit, st hoidke see otse binaarformaadis.
Ent mida teha, kui teil on vahel IPv4 aadresse ja vahel IPv6? Jah, saate hoida mõlemat. Üks veerg IPv4 jaoks, teine IPv6 jaoks. Loomulikult on võimalus kuvada IPv4 IPv6-s. See töötab ka, kuid kui teil on päringutes sageli vajalik just IPv4 aadress, siis oleks parem see panna eraldi veergu.
* nüüd on ClickHouse'is eraldi andmetüübid IPv4 ja IPv6, mis salvestavad andmeid sama tõhusalt nagu numbrid, kuid esitavad neid sama mugavalt nagu stringid.

Samuti on oluline märkida, et andmed tuleks eelnevalt töödelda. Näiteks kui teile saabuvad mõned toored logid. Ja võib-olla ei tasu neid kohe ClickHouse'i toppida, kuigi on väga ahvatlev mitte midagi teha ja kõik töötab. Kuid siiski tasub teha need arvutused, mis on võimalik.
Näiteks brauseri versioon. Ühes naaberosakonnas, kuhu ma ei taha näpuga näidata, hoitakse brauseri versiooni nii, st stringina: 12.3. Ja siis, et aruannet teha, võtavad nad selle stringi ja jagavad selle massiiviga, ja siis esimese elemendiga massiivist. Loomulikult, kõik hakkab aeglaselt liikuma. Küsisin, miks nad nii teevad. Nad vastasid, et ei armasta enneaegset optimeerimist. Aga mina ei armasta enneaegset pessimistlikku lähenemist.
Nii et sel juhul oleks õigem jagada 4 veerguks. Siin ärge kartke, sest see on ClickHouse. ClickHouse on veergude andmebaas. Ja mida rohkem korralikke väikeseid veerge, seda parem. Kui on 5 BrowserVersion'i, tehke 5 veergu. See on normaalne.

Nüüd vaatame, mida teha, kui teil on palju väga pikki ridu või väga pikki massiive. Neid ei pea ClickHouse'is üldse hoidma. Selle asemel saate ClickHouse'i salvestada ainult mingi identifikaatori. Need pikad read tasub panna mõnesse teise süsteemi.
Näiteks ühes meie analüütikateenustes on mõned sündmuste parameetrid. Ja kui sündmustele tuleb palju parameetreid, salvestame lihtsalt esimesed 512. Sest 512 ei ole kahju.

Ja kui te ei suuda oma andmetüüpe määrata, saate ka andmed ClickHouse'i kirjutada, kuid ajutisse Log-tüüpi tabelisse, mis on spetsiaalne ajutiste andmete jaoks. Pärast seda saate analüüsida, milline on teie väärtuste jaotus, mis seal üldse olemas on, ja koostada õiged tüübid.
* praegu on ClickHouse'is andmetüüp mis võimaldab efektiivselt salvestada ridu väiksema töömahu jaotusega.

Nüüd vaatame veel ühte huvitavat juhtumit. Mõnikord töötab inimestel kõik kuidagi veidralt. Sisenen ja näen sellist. Ja kohe on selge, et seda on teinud mingi väga kogenud, nutikas administraator, kellel on suur kogemus MySQL versiooni 3.23 seadistamisel.
Siin näeme tuhandet tabelit, milles igas on kirjas jääk, mis tuleneb arusaamatust jagamisest tuhandega.
Ühesõnaga, ma austan teiste kogemusi, sealhulgas mõistan, kui suure vaevaga see kogemus on saadud.

Ja põhjused on enam-vähem arusaadavad. Need on vanad stereotüübid, mis on võinud tekkida töötades teiste süsteemidega. Näiteks MyISAM tabelites ei ole klasterpärandvõtit. Ja selline andmete jagamise viis võib olla meeleheitlik katse saavutada sama funktsionaalsus.
Teine põhjus on see, et erinevad operatsioonid, nagu alter, suurte tabelite puhul on keerulised. Kõik jääb lukku. Kuigi tänapäevaste MySQL versioonide puhul ei ole see probleem enam nii tõsine.
Või näiteks mikroshardimine, aga sellest räägime natuke hiljem.

ClickHouse'i puhul ei ole seda vaja teha, kuna esiteks on klasterpärandvõti, andmed on järjestatud klasterpärandvõtme järgi.
Ja mõnikord küsitakse minult: „Kuidas muutub ClickHouse'i jälgimispäringute jõudlus tabeli suurusest?“. Ma ütlen, et see ei muutu kuidagi. Näiteks, kui teil on tabel, kus on miljard rida, ja loete satuvust miljon rida. Kõik on korras. Kui tabelis on triljon rida ja loete miljon rida, siis on see peaaegu sama.
Ja teiseks, igasuguseid asju nagu käsitsi partitsioonide seadmine ei ole vajalik. Kui te lähete ja vaatate, mis seal failisüsteemis on, näete, et tabel on päris tõsine asi. Seal sees on midagi nagu partitsioonid. Ehk siis ClickHouse teeb kõik teie eest ära ja te ei pea muretsema.

Alter ClickHouse'is on tasuta, kui lisate/eemaldate veeru.
Ja väikeste tabelite loomine ei ole mõttekas, sest kui teie tabelis on 10 rida või 10 000 rida, ei oma see mingit tähtsust. ClickHouse on süsteem, mis optimeerib läbilaskevõimet, mitte latentsust, nii et 10 rida töötlemine ei ole mõistlik.

Õige on kasutada ühte suurt tabelit. Vabanege vanadest stereotüüpidest, kõik läheb hästi.
Ja boonuseks on meie uusimas versioonis võimalus luua arbitraarseid partitsioneerimise võtmeid, et teostada erinevaid hooldusoperatsioone üksikute partitsioonide üle.
Näiteks, kui teil on palju väikseid tabeleid, näiteks kui on vaja töödelda vaheandmeid, kus te saate kokkusurutud andmestikke ja peate enne nende salvestamist lõpptabelisse teostama teisendusi. Selle jaoks on olemas suurepärane tabelimootor – StripeLog. See on umbes nagu TinyLog, aga parem.
* nüüd on ClickHouse'is olemas veel ka .

Veel üks antipattern on mikrotükeldamine. Näiteks, kui peate oma andmed jagama ja teil on 5 serverit, kuid homme tuleb 6 serverit. Ja te mõtlete, kuidas neid andmeid ümber jagada. Selle asemel, et jagada 5 shards'i peale, jagate te need 1 000 shards'i peale. Ja siis suunate igaühe neist mikrotükeldustest eraldi serverisse. Näiteks võib ühes serveris olla 200 ClickHouse'i. Erinevad instantsid erinevatel portidel või eraldi andmebaasid.

Kuid ClickHouse'is ei ole see eriti hea. Sest isegi üks ClickHouse'i instants püüab kasutada kõiki serveri ressursse ühe päringu töötlemiseks. St, kui teil on näiteks server, kus on 56 protsessorituuma. Teete päringu, mis kestab ühe sekundi, ja see kasutab 56 tuuma. Ja kui olete sinna paigutanud 200 ClickHouse'i ühte serverisse, siis käivitatakse kokku 10 000 lõime. Ühesõnaga, kõik läheb tõeliselt halvasti.
Teine põhjus on see, et tööjaotamine nende instantside vahel ei ole ühtlane. Mõni lõpetab varem, mõni hiljem. Kui kogu see asi toimuks ühe instantsi sees, siis ClickHouse oskaks ise andmed õigesti lõimede vahel jaotada.
Ja veel üks põhjus on see, et teil on protsessoritevaheline suhtlus TCP kaudu. Andmed tuleb serialiseerida, deserialiseerida ja see on tohutu hulk mikro-sharde. See ei tööta lihtsalt tõhusalt.

Veel üks antimääratlemine, kuigi seda on raske antimääratlemiseks pidada. See on suur hulk eelaggregatsiooni.
Üldiselt on eelagregatsioon hea. Kui teil oli miljard rida ja te agreegasite selle ning nüüd on 1 000 rida, siis päring toimub kohe. Kõik on suurepärane. Nii saab teha. Selle jaoks on ClickHouse'is isegi spetsiaalne tabelitüüp AggregatingMergeTree, mis teeb inkrementaalset aggregeerimist, kui andmeid sisestatakse.
Aga on juhtumeid, kui arvate, et me peaksime andmeid selliselt kokku koondama ja veel teistmoodi kokku koondama. Ja mingis naaberosakonnas, millest ma ei soovi rääkida, kasutatakse SummingMergeTree tabeleid summamiseks põhivõtme järgi, ja põhivõtmena kasutatakse umbes 20 erinevat veergu. Muutsin mõningaid veergude nimesid konspiratsiooni huvides, aga umbes nii need asjad on.

Ja tekivad sellised probleemid. Esiteks, andmete maht ei vähene piisavalt. Näiteks väheneb see kolm korda. Kolm korda oleks hea hind, et lubada endale piiramatu analüüsi võimalusi, mis tekivad, kui andmed ei ole agreggeeritud. Kui andmed on agreggeeritud, siis saate analüüsi asemel vaid halva statistika.
Ja ja, mis seal eriti häirib? See, et need inimesed naaberosakonnast käivad ja paluvad aeg-ajalt lisada veel üks veerg algusvõtmesse. See tähendab, et oleme andmeid selliselt kokku kogunud, aga nüüd tahame natuke rohkem. Kuid ClickHouse'is ei saa algusvõtit muuta. Seetõttu peab kirjutama mingisuguseid skripte C++-s. Ja mulle ei meeldi skriptid, isegi kui need on C++-s.
Ja kui vaadata, milleks ClickHouse loodi, siis mitteaggregeeritud andmed on just see stsenaarium, mille jaoks see on sündinud. Kui kasutate ClickHouse'i mitteaggregeeritud andmete jaoks, siis teete kõik õigesti. Kui aggregeerite, siis see on mõnikord andestatav.
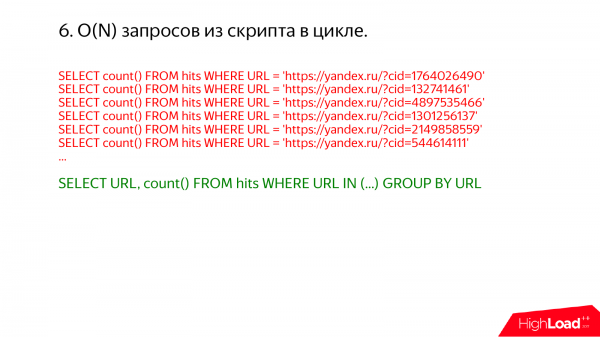
Veel üks huvitav juhtum on päringud lõputus tsüklis. Ma vahel lähen mõnele tootmisserverile ja vaatan seal show processlist. Ja iga kord avastan, et toimub midagi kohutavat.
Näiteks selline. Siit on kohe selge, et kõik oleks saanud teha ühe päringuga. Lihtsalt kirjutage sinna url in ja nimekiri.

Miks on nii palju selliseid päringute lõpmatuid tsükleid – see on halb? Kui indeksit ei kasutata, siis toimub sul palju läbikäike samade andmete kaudu. Kuid kui indeksit kasutatakse, näiteks kui sul on põhivõti ru ja sa kirjutad url = millelegi. Sa arvad, et loetakse tabelist üht kindlat URL-i, siis kõik on korras. Aga tegelikult ei ole. Sest ClickHouse teeb kõike pakendatult.
Kui tal on vaja lugeda mingit andmevahemikku, loeb ta natuke rohkem, kuna clickHouse’i indeks on harv. See indeks ei luba leida tabelist ühte individuaalset rida, vaid ainult mingit vahemikku. Ja andmed tihendatakse plokkidena. Ühe rea lugemiseks tuleb võtta terve plokk ja see lahti suruda. Ja kui sa teed kuhjaga päringuid, siis sul on palju kattuvusi ja palju tööd tuleb sul ikka ja jälle teha.

Ja boonuseks võib öelda, et ClickHouse'is ei ole vaja karta isegi megabaidide ja isegi sadade megabaidide edastamist IN-sektsiooni. Mäletan meie praktikast, et kui MySQL-is edastame hulga väärtusi IN-sektsiooni, näiteks edastame 100 megabaiti mingisuguseid numbreid, siis MySQL tarbib 10 gigabaiti mälust ja rohkem ei juhtu midagi, kõik töötab halvasti.
Ja teine asi on see, et ClickHouse'is, kui teie päringud kasutavad indeksit, siis see ei ole kunagi aeglasem kui full scan, st kui tuleb lugeda peaaegu kogu tabelit, siis ta läheb järjestikku ja loeb kogu tabelit. Ühesõnaga, ta saadab end ise asja korda.
Kuid siiski on mõned keerukused. Näiteks see, et IN koos alam päringuga ei kasuta indeksit. Kuid see on meie probleem ja me peame seda parandama. Siin ei ole midagi fundamentaalset. Parandame seda.
Ja veel üks huvitav asi on see, et kui teil on väga pikk päring ja päringute jaotatud töötlemine käib, siis see väga pikk päring saadetakse igale serverile ilma kokkusurumiseta. Näiteks 100 megabaiti ja 500 serverit. Seega edastatakse teie võrgus 50 gigabaiti. See saadetakse ja siis kõik lõpetatakse edukalt.
* juba kasutab; kõik on korras, nagu lubatud.

Ja üsna sage juhtum, kui päringud tulevad API-st. Näiteks, kui olete loonud oma teenuse. Ja kui teie teenust keegi vajab, siis avate API ja juba kahe päeva pärast näete, et toimub midagi ebaselget. Kõik on üle koormatud ja tulevad mingid kohutavad päringud, mida ei oleks kunagi pidanud olema.
Ja siin on lahendus. Kui olete API avanud, peate seda kärpima. Näiteks, kehtestama mingid piirangud. Teisi normaalseid variante ei ole. Vastasel juhul kirjutatakse kohe skript ja tekivad probleemid.
Ja ClickHouse'is on spetsiaalne funktsioon – kvootide arvestus. Samuti saate edastada oma kvoodi võtme. See on näiteks kasutaja sisemine identifikaator. Ja kvoote arvestatakse sõltumatult igaühe jaoks.

Nüüd veel üks huvitav asi. See on replikatsioon käsitsi juhtimisega.
Ma tean palju juhtumeid, kus, hoolimata sellest, et ClickHouse'il on sisseehitatud replikatsiooni tugi, replitseerivad inimesed ClickHouse'i käsitsi.
Milline on põhimõte? Teil on andmetöötluse pipeline, mis töötab iseseisvalt, näiteks erinevates andmekeskustes. Te kirjutate andmed ClickHouse'i samal viisil. Tõsi, praktika näitab, et andmed lähevad siiski lahku, kuna teie koodis on mõningaid eripärasid. Loodan, et see ei kehti teie kohta.
Ja perioodiliselt peate ikkagi käsitsi sünkroonima. Näiteks kord kuus teevad adminnid rsync'i.
Tõepoolest, ClickHouse'is on palju lihtsam kasutada sisseehitatud replikatsiooni. Kuid siin võivad olla teatud vastunäidustused, kuna selleks tuleb kasutada ZooKeeper'i. Ma ei ütle ZooKeeper'i kohta halba, sisuliselt on süsteem töökindel, kuid mõnikord ei kasuta inimesed seda java-fobia tõttu, kuna ClickHouse on nii suurepärane süsteem, mis on kirjutatud C++-s ja millega saab ikka ideaalselt töötada. Aga ZooKeeper on java peal. Ja seda ei tahaks isegi vaadata, kuid juhul kui, siis võite kasutada manuaalisel põhinevat replikatsiooni.

ClickHouse on praktiline süsteem. See arvestab teie vajadusi. Kui teil on replikatsioon käsitsi käivitatud, saate luua jaotatud tabeli, mis vaatab teie käsitsi replikate poole ja teostab nende vahel automaatse ülemineku. On isegi eriline valik, mis aitab vältida tõrkeid, isegi kui teie replikad pidevalt eralduvad.

Edasi võivad tekkida probleemid, kui kasutate primitiivseid tabelimootoreid. ClickHouse on selline ehitaja, kus on palju erinevaid tabelimootoreid. Kõigi tõsiste juhtumite jaoks, nagu dokumentatsioonis on kirjutatud, kasutage MergeTree perekonna tabeleid. Kõik teised on lihtsalt erijuhtudeks või testimiseks.
MergeTree tabelis ei ole tingimata vajalik, et teil oleks mingi kuupäev ja kellaaeg. Võite ikkagi kasutada. Kui kuupäeva ja kellaaega pole, kirjutage, et vaikeväärtus on 2000. aasta. See töötab ja ei nõua ressursse.
Ja uues serveriversioonis on isegi võimalik näidata, et teil on kohandatud partitseerimine ilma partitsiooni võtmeta. See on sama asi.

Teisest küljest on võimalik kasutada primitiivseid tabelimootoreid. Näiteks laadige andmed üks kord, vaadake neid, keerake ringi ja eemaldage. Saate kasutada Log.
Või väikeste mahtude salvestamine vahepealseks töötlemiseks — see on StripeLog või TinyLog.
Memory võib kasutada, kui andmemahu on väike ja lihtsalt keerata midagi mäletsejas.

ClickHouse ei armasta väga üleliigselt normaliseeritud andmeid.
Siin on tüüpiline näide. See on tohutu hulk URL-e. Te panite need naabertabelisse. Ja siis otsustasite nendega JOIN teha, kuid see ei tööta tavaliselt, kuna ClickHouse toetab ainult Hash JOIN-i. Kui mälu ei piisa paljude andmete jaoks, millega tuleb ühendada, ei saa JOIN-i teostada*.
Kui andmed on suure kardinaalsusega, siis ärge muretsege, hoidke neid denormeeritud kujul, URL-id otse põhitahel.
* kuid nüüd on ClickHouse'il ka merge join ja see töötab tingimustes, kus vaheandmed ei mahuta mällu. Kuid see ei ole efektiivne ja soovitus jääb kehtima.

Veel paar näidet, kuid nüüd kahtlen, kas need on antipatternid või mitte.
ClickHouse'il on üks tuntud puudus. See ei toeta uuendusi*. Mõnes mõttes on see isegi hea. Kui teil on olulised andmed, näiteks raamatupidamine, siis ei saa keegi neid saata, kuna uuendusi ei ole.
* uuenduse ja kustutamise tugi on juba ammu lisatud batch-režiimis.
Kuid on mõned erilised viisid, mis võimaldavad uuendusi peaaegu taustal. Näiteks ReplaceMergeTree tüüpi tabelid. Need teevad uuendusi taustal toimuvate ühinemiste ajal. Saate seda sundida optimize table abil. Kuid ärge tehke seda liiga tihti, sest see viib kogu partitsiooni ümberkirjutamiseni.
Jaotatud JOIN'id ClickHouse'is – need on samuti halva päringuplaanijaga.
Halb, aga mõnikord okei.
ClickHouse'i kasutamine ainult selleks, et andmeid tagasi lugeda select* abil.
Ma ei soovitaks ClickHouse'i kasutada mahukate arvutuste jaoks. Kuid see pole päris nii, kuna me juba eemaldume sellest soovitusest. Ja meil on hiljuti lisandunud võimalus rakendada masinõppemudeleid ClickHouse's – Catboost. Ja see teeb mind murelikuks, sest ma mõtlen: „Kui hirmus. Kui palju takte ühe byte'i kohta tuleb!“. Mul on väga kahju, kui takte byte'ide peale kulutada.

Aga ärge kartke, installige ClickHouse, kõik läheb hästi. Kui midagi juhtub, on meil kogukond. Ütleme nii, et see olete teie. Ja kui teil on mingeid probleeme, saate vähemalt meie vestlusesse astuda ja loodetavasti saavad nad teid aidata.
Küsimused
Aitäh ettekande eest! Kuhu saab ClickHouse'i tõrgete üle kaevata?
Võite pöörduda minu poole isiklikult juba praegu.
Ma hakkasin hiljuti ClickHouse'i kasutama. Tõmbasin kohe cli liidese alla.
Teil on vedanud.
Hiljem tõmbasin serveri alla väikese selectiga.
Teie talent on silmapaistev.
Avasin GitHubis vea, kuid see jäeti tähelepanuta.
Vaatan, mis juhtub.
Aleksandr tõmbas mind ettekandele, lubades rääkida, kuidas te andmeid pressite.
See on väga lihtne.
Selle sain eile aru. Rohkem konkreetsust.
Seal pole mingeid hirmsaid nippe. Seal on lihtsalt plokkide põhine kompressioon. Vaikimisi kasutatakse LZ4, kuid saate lubada ZSTD*. Plokid on suurusega 64 kilobaiti kuni 1 megabait.
* on saadaval ka spetsialiseeritud kompressioonikoodikud, mida saab kasutada koos teiste algoritmidega.
Kas plokkides on lihtsalt toored andmed?
Ei ole päris toored. Seal on massiivid. Kui teil on numbriline veerg, siis on seal numbrid järjestikku massiivis paigutatud.
Selge.
Aleksandr, näide, mis oli uniqExact'i puhul IP-aadressidega, st see, et uniqExact'i arvutamine stringide pealt võtab kauem aega kui numbrite pealt ja nii edasi. Aga kui me kasutame nippe ja teisendame lugemise ajal? St te ütlesite, et ketas ei erine meil palju. Kui me loeme kettalt stringe ja teisendame need, kas meie aggregeerimine siis kiireneb või mitte? Või saame me ikkagi siin vaid vähe parema tulemuse? Mul on tunne, et te olete seda testinud, kuid mingil põhjusel ei näidanud seda tulemuste võrdluses.
Ma arvan, et see on aeglasem kui ilma teisendamiseta. Sel juhul tuleb IP-aadress stringist välja lugeda. Meil on ClickHouse's IP-aadresside parsimine samuti optimeeritud. Me oleme selle nimel tõesti vaeva näinud, kuid seal on ju numbrid salvestatud kümnendikku vormi. See on tõeliselt ebamugav. Teisest küljest töötab uniqExact stringide pealt aeglasemalt mitte ainult seetõttu, et need on stringid, vaid ka seetõttu, et valitakse teine algoritmi spetsialiseerumine. Stringe töödeldakse lihtsalt teisiti.
Aga kui võtta mõni primitiivsem andmetüüp? Näiteks oleme salvestanud kasutaja ID, mis meil on sisse, salvestanud selle stringina ja siis teisendame, kas oleks toredam või mitte?
Ma kahtlen. Arvan, et see on isegi kurvem, sest numbrite parsimine on tõsine probleem. Tundub, et sellel kolleegil oli isegi ettekande teema, kuidas on keeruline numbreid kümne tuhandes vormis parsida, või võib-olla ei olnud?
Aleksei, suur aitäh ettekande eest! Ja samuti suur aitäh ClickHouse'i eest! Mul on küsimus plaanide kohta. Kas plaanis on funktsiooni, mis võimaldab sõnastike osalisi uuendusi?
Ehk osaline taaskäivitamine?
Jah-jah. Tõenäoliselt võimalus määrata seal MySQL väli, st uuendada 'after', et laadida ainult need andmed, kui sõnastik on väga suur.
Väga huvitav funktsioon. Ja mulle tundub, et keegi inimene oli seda meie vestluses soovitanud. Võib-olla olite see isegi teie.
Ei arva, et mina.
Suurepärane, nüüd on kaks päringut. Ja nüüd saab rahulikult alustada. Kuid tahan teid kohe hoiatada, et see funktsioon on piisavalt lihtne rakendada. St idee on kirjutada lihtsalt tabelisse versiooninumber ja edasi kirjutada: versioon on väiksem kui see ja see. Ja see tähendab, et tõenäoliselt pakume seda huvilistele. Kas olete huviline?
Jah, kuid kahjuks mitte C++-s.
Kas teie kolleegid oskavad C++-s kirjutada?
Leian kedagi.
Suurepärane.
* võimalus lisati kaks kuud pärast ettekannet – selle arendas välja küsimuse autor ja saatis selle edasi .
Aitäh!
Tere! Aitäh ettekande eest! Te mainisite, et ClickHouse tarbib kõiki talle saadaval olevaid ressursse väga hästi. Ja ettekandja, kes oli Glassifti kõrval, rääkis oma lahendusest Post Vene tagasi. Ta ütles, et neile meeldis ClickHouse väga, kuid nad ei kasutanud seda oma peamise konkurendi asemel, just sellepärast, et see võttis kõik protsessori jõu. Ja nad ei suutnud seda oma arhitektuuri, oma ZooKeeperi ja konteineritega integreerida. Kas on võimalik mingil moel piirata ClickHouse'i, et see ei tarbiks kõike, mis talle kätte saadav on?
Jah, on võimalik ja väga lihtne. Kui soovite, et vähem tuumasid tarbitakse, kirjutage lihtsalt set max_threads = 1. Ja kõik, see täidab päringu ühe tuumaga. Tõsi, erinevatele kasutajatele saab määrata erinevaid seadeid. Nii et probleeme pole. Ja edastage oma kolleegidele Glassiftis, et nad ei leidnud seda seadet dokumentatsioonist, see pole hea.
Tere, Aleksei! Soovin küsida sellist küsimust. See ei ole esimene kord, kui kuulen, et paljud hakkavad kasutama ClickHouse'i logide salvestamiseks. Esitluses rääkisite, et seda ei peaks tegema, ehk siis pikki ridu ei tohiks salvestada. Kuidas te sellele suhtute?
Esiteks, logid ei ole reeglina pikad read. Loomulikult on erandeid. Näiteks, kui mõni teenus, mis on kirjutatud Java's, viskab exception'i, siis see logitakse. Ja nii lõputus tsüklis, kuni kõvakettal ei jätku ruumi. Lahendus on väga lihtne. Kui read on liiga pikad, siis kärpige neid. Mis tähendab liiga pikka? Kümneid kilobaiti – see on halb.
* Uutes ClickHouse'i versioonides on sisse lülitatud "kohandatav granulaarsus indekseerimisel", mis enamikus ulatuses eemaldab pika rida hoidmise probleemi.
Aga kilobait – see on normaalne?
Normaalne.
Tere! Aitäh ettekande eest! Ma juba küsisin sellest vestluses, aga ei mäleta, kas sain vastuse. Kas plaanitakse laiendada WITH jaotist nagu CTE?
Praegu ei. Meie WITH jaotis on pigem tõsiseltvõetmatu. See on meil nagu väike funktsioon.
Mõistan. Aitäh!
Aitäh ettekande eest! Väga huvitav! Üks globaalne küsimus. Kas plaanitakse luua, võib-olla, mingite suunavate lahenduste kaudu andmete kustutamise muudatusetappi?
Kindlasti. See on meie prioriteetide nimekirjas esimene ülesanne. Me oleme aktiivselt välja mõelnud, kuidas kõike õigesti teha. Ja on aeg hakata klaviatuurile vajutama*.
* vajutasime klahve klaviatuuril ja tegime kõik korda.
Kas see mõjutab kuidagi süsteemi jõudlust või mitte? Kas sisestamine jääb sama kiireks kui praegu?
Võib-olla on kustutamised ja uuendused väga keerulised, kuid see ei mõjuta valikute ja sisestuste jõudlust.
Ja veel üks väike küsimus. Esitluses rääkisite primaarvõtmega. Seega on meil partitsioneerimine, mis on vaikimisi kuupõhine, eks? Ja kui määrame kuupäevade vahemiku, mis mahub kuusse, loetakse ainult see partitsioon, eks?
Jah.
Tavaliselt tekib küsimus: kui me ei suuda määrata mingit primaarset võtit, kas on õige teha seda „Kuupäeva” välja alusel, et vähendada taustal nende andmete ümberstruktureerimist ja muuta need paremini organiseerituks? Kui teil ei ole vahemikupäringuid ja te ei suuda valida ühtegi primaarset võtit, siis kas on mõtet kuupäeva primaarseks võtme panna?
Jah.
Võib-olla on mõistlik lisada primaarsetesse võtmetesse väli, mille alusel andmed läbivad paremini tihendamist, kui need on selle välja järgi järjestatud. Näiteks kasutaja identifikaator. Kasutaja külastab sama saiti. Sellisel juhul lisage kasutaja ID ja aeg. Siis tihendatakse teie andmed paremini. Kuupäeva osas, kui teil tõeliselt ei ole ja ei ole kunagi vahemikupäringuid kuupäevade järgi, siis ei pea kuupäeva primaarsetesse võtmetesse lisama.
Aitäh, suur aitäh!
Allikas: habr.com
