

Andmete funktsionaalsete seoste otsimine rakendatakse erinevates andmeanalüüsi suundades: andmebaaside haldamine, andmete puhastus, andmebaaside pöördtöötlemine ja andmete uurimine. Me oleme juba avaldanud teavet nende seoste kohta. Anastasia Birillo ja Nikita Bobrov. Seekord Anastasia — selle aasta Computer Science Centeri lõpetaja — jagab selle töö arengut uurimistöö raames, mille ta keskusel kaitses.

Ülesande valik
CS keskuses õppimise ajal hakkasin sügavamalt uurima andmebaase, nimelt funktsionaalsete ja erinevate seoste otsimist. See teema oli seotud minu ülikooli kursuse teemaga, seega alustasin oma kursuse käigus erinevate andmebaaside seoste kohta artiklite lugemist. Kirjutasin ülevaate sellest valdkonnast — ühe oma esimestest. ingliskeelsena ja esitasin selle SEIM-2017 konverentsile. Olin väga rõõmus, kui sain teada, et see siiski vastu võeti, ja otsustasin teemas sügavale minna. Kontseptsioon ise ei ole uus — seda on hakatud rakendama juba 90ndatel, kuid see leiab endiselt rakendust paljudes valdkondades.
Teisel õppesemestril alustatud teadusprojekti raames töötasin funktsionaalsete sõltuvuste otsimise algoritmide täiustamise kallal. Töö käis koos SPbGU doktorandi Nikita Bobrovi ja JetBrains Researchi põhjal.
Funktsionaalsete sõltuvuste otsimise arvutuslik keerukus
Peamine probleem on arvutuslik keerukus. Võimalike minimaalseid ja mittetriviaalseid sõltuvusi piirab ülemine väärtus  , kus
, kus  — tabeli atribuutide arv. Algoritmide tööaeg sõltub mitte ainult atribuutide arvust, vaid ka ridade arvust. 90ndatel suudsid funktsionaalsete sõltuvuste leidmise algoritmid tavalistel lauaarvutitel hallata andmestikke, mis sisaldasid kuni 20 atribuuti ja kümneid tuhandeid ridu, mitme tunni jooksul. Kaasaegsed algoritmid, mis töötavad mitme tuumaga protsessoritel, tuvastavad sõltuvusi andmestikes, mis koosnevad sadade (kuni 200) atribuudist ja sadadest tuhandetest ridadest, enam-vähem sama ajaga. Sellegipoolest ei piisa sellest: selline aeg on enamikus reaalsetes rakendustes vastuvõetamatu. Seetõttu töötasime välja meetodeid olemasolevate algoritmide kiirendamiseks.
— tabeli atribuutide arv. Algoritmide tööaeg sõltub mitte ainult atribuutide arvust, vaid ka ridade arvust. 90ndatel suudsid funktsionaalsete sõltuvuste leidmise algoritmid tavalistel lauaarvutitel hallata andmestikke, mis sisaldasid kuni 20 atribuuti ja kümneid tuhandeid ridu, mitme tunni jooksul. Kaasaegsed algoritmid, mis töötavad mitme tuumaga protsessoritel, tuvastavad sõltuvusi andmestikes, mis koosnevad sadade (kuni 200) atribuudist ja sadadest tuhandetest ridadest, enam-vähem sama ajaga. Sellegipoolest ei piisa sellest: selline aeg on enamikus reaalsetes rakendustes vastuvõetamatu. Seetõttu töötasime välja meetodeid olemasolevate algoritmide kiirendamiseks.
Vahepartitsioonide vahemälustruktuurid
Töö esimeses osas töötasime välja vahemälustruktuurid algoritmide klassile, mis kasutavad vahepartitsioonide meetodit. Atribuudi vahepartitsioon esindab loendite kogumit, kus iga loend sisaldab rida numbreid, millel on antud atribuudi jaoks samad väärtused. Iga sellist loendit nimetatakse klastriks. Paljud kaasaegsed algoritmid kasutavad vahepartitsioone, et määrata, kas sõltuvus on säilitatud või mitte, järgides, nimelt, lemma: Sõltuvus  säilitatakse, kui
säilitatakse, kui  . Siin
. Siin  partitsioon on määratud ja kasutatakse partitsiooni suuruse mõistet — klastrite arvu selles. Algoritmid, mis kasutavad partitsioone, lisavad sõltuvuse rikkumise korral vasakusse osasse täiendavad atribuudid, mille järel nad seda arvutavad, teostades partitsioonide ristamise operatsiooni. Seda operatsiooni nimetatakse artiklites spetsialiseerimiseks. Kuid oleme märganud, et sõltuvuste jaoks, mida hoitakse alles pärast mitmeid spetsialiseerimise rounde, saab partitsioone aktiivselt uuesti kasutada, mis võib oluliselt vähendada algoritmide tööaega, kuna ristamisoperatsioon on kulukas.
partitsioon on määratud ja kasutatakse partitsiooni suuruse mõistet — klastrite arvu selles. Algoritmid, mis kasutavad partitsioone, lisavad sõltuvuse rikkumise korral vasakusse osasse täiendavad atribuudid, mille järel nad seda arvutavad, teostades partitsioonide ristamise operatsiooni. Seda operatsiooni nimetatakse artiklites spetsialiseerimiseks. Kuid oleme märganud, et sõltuvuste jaoks, mida hoitakse alles pärast mitmeid spetsialiseerimise rounde, saab partitsioone aktiivselt uuesti kasutada, mis võib oluliselt vähendada algoritmide tööaega, kuna ristamisoperatsioon on kulukas.
Seetõttu pakkusime ülesande, mis põhineb Shannon'i entropial ja Ginny ebakindlusel, ning meie meetril, mida oleme nimetanud Tagasipöördumine Entropia. See on väike modifikatsioon Shannon'i entropiast ja tõuseb koos andmekogumi ainulaadsuse suurenemisega. Pakutud heuristika on järgmine:

Siit  — hiljuti arvutatud partitsiooni unikaalsuse aste
— hiljuti arvutatud partitsiooni unikaalsuse aste  , ja
, ja  on unikaanide keskmine aste, mis on määratud üksikute atribuutide jaoks. Unikaalsuse mõõdikuna prooviti välja kolme ülaltoodud mõõdikut. Samuti võib tähele panna, et heuristikas on kaks modifikaatorit. Esimene näitab, kui lähedane on praegune partitsioon peamisele võtmele ja võimaldab suuremas ulatuses vahemälu sellele partitsioonile, mis on kaugel võimalusest võtme. Teine modifikaator võimaldab jälgida vahemälu kasutust ja seeläbi stimuleerida rohkemate partitsioonide lisamist vahemällu, kui ruumi on piisavalt. Selle probleemi edukas lahendamine on võimaldanud kiirendada algoritmi PYRO 10-40% võrra sõltuvalt andmestikust. Tasub märkida, et algoritm PYRO on sel alal kõige edukam.
on unikaanide keskmine aste, mis on määratud üksikute atribuutide jaoks. Unikaalsuse mõõdikuna prooviti välja kolme ülaltoodud mõõdikut. Samuti võib tähele panna, et heuristikas on kaks modifikaatorit. Esimene näitab, kui lähedane on praegune partitsioon peamisele võtmele ja võimaldab suuremas ulatuses vahemälu sellele partitsioonile, mis on kaugel võimalusest võtme. Teine modifikaator võimaldab jälgida vahemälu kasutust ja seeläbi stimuleerida rohkemate partitsioonide lisamist vahemällu, kui ruumi on piisavalt. Selle probleemi edukas lahendamine on võimaldanud kiirendada algoritmi PYRO 10-40% võrra sõltuvalt andmestikust. Tasub märkida, et algoritm PYRO on sel alal kõige edukam.
Allolevalt jooniselt on näha ettepaneku heuristika rakendamise tulemusi võrreldes aluseks oleva lähenemisega, mis põhineb mündi viskamisel. X-telg on logaritmiline.
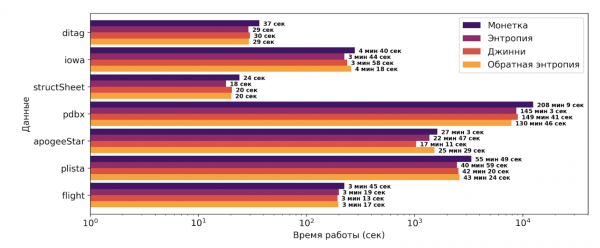
Alternatiivne viis partitsioonide salvestamiseks
Seejärel pakkusime alternatiivset viisi partisjonide salvestamiseks. Partisioonid moodustavad klastrite komplekti, kus igaühes hoitakse vahemike numbreid, millel on teatud atribuutide järgi sarnased väärtused. Need klastrid võivad sisaldada pikki järjestusi numbrite kohta, näiteks juhul, kui tabelis andmed on järjestatud. Seetõttu pakkusime kompressiooniskeemi partisjonide salvestamiseks, nimelt vahepealsete väärtuste salvestamist partisjoni klastrites:
$$display$$pi(X) = {{underbrace{1, 2, 3, 4, 5}_{Esimene~vahemik}, underbrace{7, 8}_{Teine~vahemik}, 10}}\ downarrow{Kompressioon}\ pi(X) = {{underbrace{$, 1, 5}_{Esimene~vahemik}, underbrace{7, 8}_{Teine~vahemik}, 10}}$$display$$
See meetod suutis vähendada mälu tarbimist TANE algoritmi töötamise ajal 1 kuni 25%. TANE algoritm on klassikaline algoritm FN leidmiseks ja kasutab oma töös partisjone. Praktika raames valiti just TANE algoritm, kuna vahepealsete väärtuste salvestamine oli sellesse integreerida oluliselt lihtsam kui näiteks PYRO-s, et hinnata, kas pakkutud lähenemine töötab. Saadud tulemused on esitatud alloleval joonisel. X telg on logaritmiline.
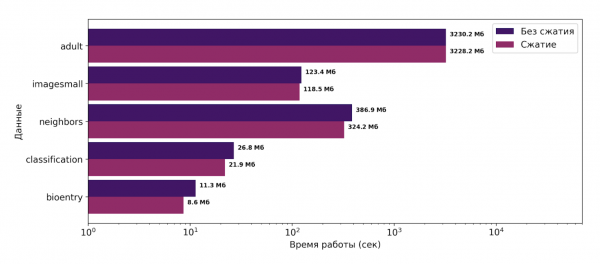
Konverents ADBIS-2019
Septembri 2019. aasta uurimistulemuste põhjal esitasin artikli 23. Euroopa andmebaaside ja infotehnoloogia konverentsil (ADBIS-2019). Kogu ettekande ajal märkas tööd Bernhard Thalheim, olulise isiku andmebaaside valdkonnas. Uuringutulemused põhinesid minu magistritööl matemaatika ja mehaanika erialal SPbGU-s, mille käigus rakendati mõlemad pakutud lähenemisviisid (vahemälu ja tihendamine) mõlemas algoritmis: TANE ja PYRO. Tulemused näitasid, et pakutud lähenemisviisid on universaalsed, kuna mõlema algoritmi puhul täheldati mõlema lähenemise korral märgatavat mälutarbimise vähenemist ja samuti märgatavat algoritmide töötamise aja vähenemist.
Allikas: habr.com
