

Jätkates teemat suurte andmevoogude salvestamisest, tõstatatud , vaatleme selles, kuidas väheneda „füüsilist“ suurust salvestatud PostgreSQL-is ja nende mõju serveri tulemuslikkusele.
Jutt läheb TOAST seadistustest ja andmete joondamisest. „Keskmiselt” võimaldavad need meetodid säästa mitte liiga palju ressursse, kuid — täiesti ilma rakenduskoodi modifitseerimiseta.

Kuid meie kogemus osutus selles osas üsna produktiivseks, kuna praktiliselt iga jälgimise salvestus on oma olemuselt suurel määral ainult append-only salvestatavate andmete osas. Ja kui teid huvitab, kuidas õpetada andmebaasi kirjutama kettale asemel 200 MB/s kaks korda vähem — tulge edasi.
Suurte andmete väikesed saladused
Meie teenuse , saab regulaarselt logidelt tekstipakette.
Ja kuna , kelle andmebaase me jälgime, on mitmekomponendiline toode keeruliste andmestruktuuridega, siis on ka päringud maksimaalse tulemuslikkuse saavutamiseks täiesti sellised . Seega on iga individuaalse päringu või saadud täitmisplaani maht meie logis "keskmiselt" piisavalt suur.
Vaatame ühte tabeli struktuuri, kuhu kirjutame "tooreid" andmeid — st originaalteksti logikirjest:
CREATE TABLE rawdata_orig(
pack -- PK
uuid NOT NULL
, recno -- PK
smallint NOT NULL
, dt -- sektsiooni võti
date
, data -- kõige olulisem
text
, PRIMARY KEY(pack, recno)
);Tüüpiline selline tabel (juba seotud, loomulikult, seega on see — sektsiooni mall), kus kõige olulisem on tekst. Kohati piisavalt mahukas.
Kasutame meeles, et PG-s ühe kirje "füüsiline" suurus ei saa ületada ühte andmelehekülge, kuid "loogiline" suurus on sootuks teine asi. Mahuliste väärtuste (varchar/text/bytea) salvestamiseks väljal kasutatakse :
PostgreSQL kasutab fikseeritud lehe suurust (tavaliselt 8 KB) ja ei luba tuple'idel võtta mitu lehte. Seetõttu ei saa väga suuri väljade väärtusi otse salvestada. Selle piirangu ületamiseks surutakse suured väljade väärtused ja/või jagatakse need mitmeks füüsiliseks reaks. See toimub kasutajale märkamatult ning mõjutab suure osa serveri koodist vähe. Seda meetodit tuntakse kui TOAST …
Tegelikult luuakse iga 'potentsiaalselt suure' välja tabeli jaoks automaatselt iga 'suure' kirje kohta segmentide kaupa 2KB:
TOAST(
chunk_id
integer
, chunk_seq
integer
, chunk_data
bytea
, PRIMARY KEY(chunk_id, chunk_seq)
); See tähendab, et kui peame kirjutama rea, millel on 'suur' väärtus data, siis tõeline salvestamine toimub mitte ainult põhitaotlemises ja selle PK-s, vaid ka TOAST-is ja selle PK-s.
Vähendame TOAST-i mõju
Kuid enamik kirjeid ei ole siiski nii suured, 8KB peaks olema piisav — kuidas selle pealt kokku hoida?..
Siin tuleb meile appi atribuut tabeli veerus:
- EXTENDED lubab nii pakkimist kui ka eraldi salvestamist. See on standardne valik enamikule TOAST-iga ühilduvatest andmetüüpidest. Esiteks proovitakse teha tihendamist, seejärel - salvestamist tabeli välistesse osadesse, kui rida on endiselt liiga suur.
- PEA lubab tihendamist, kuid mitte eraldi salvestamist. (Tegelikult tehakse eraldi salvestamine selliste väljade puhul siiski, kuid ainult äärmuslikul juhul, kui pole muid võimalusi, et rida vähendada nii, et see mahtuks leheküljele.)
Tegelikult on see täpselt see, mida me tekstiga vajame - maksimaalselt tihendada, ja kui ei mahu, siis viia TOAST-i. Seda saab teha otse "lennul", ühe käsuga:
ALTER TABLE rawdata_orig ALTER COLUMN data SET STORAGE MAIN;Kuidas hinnata mõju
Kuna andmevoog muutub iga päev, ei saa me võrrelda absoluutseid numbreid, vaid suhtelisi. mida väiksem osa me TOAST-i salvestasime - seda parem. Kuid siin on oht - mida suurem on meie iga eraldi kirje "füüsiline" maht, seda "laiem" muutub indeks, kuna peame katma rohkem andmelehti.
Sektsioon enne muudatusi:
heap = 37GB (39%)
TOAST = 54GB (57%)
PK = 4GB ( 4%)
Sektsioon pärast muudatusi:
heap = 37GB (67%)
TOAST = 16GB (29%)
PK = 2GB ( 4%)Tegelikult, me oleme hakanud TOAST-i kirjutama kaks korda harvemini, mis leevendas mitte ainult ketast, vaid ka CPU-d:
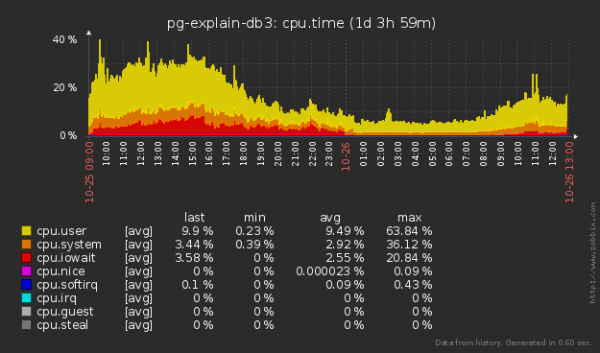
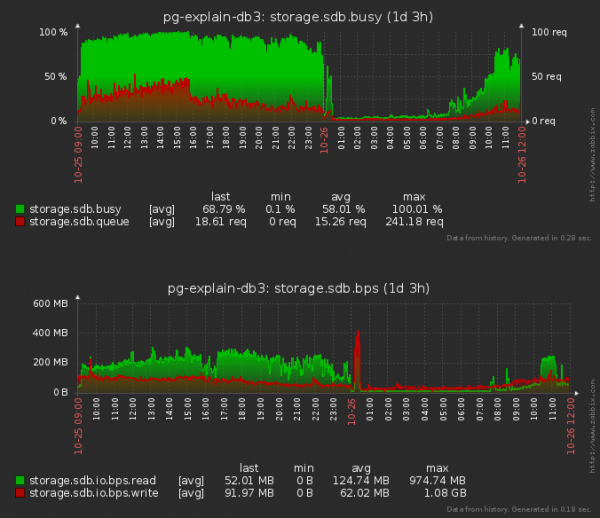
Tahan märkida, et me oleme hakanud vähem ka ketast «lugema», mitte ainult «kirjutama» — kuna mingi tabelisse kirje sisestamisel tuleb lugeda ka osa iga indeksi puust, et määrata selle tulevane positsioon nendes.
Kellele elada PostgreSQL 11 peal hästi
Pärast PG11-le üleminekut otsustasime TOAST-i «tuningut» edasi viia ja panime tähele, et alates sellest versioonist on seadistatav parameter :
TOAST-i töötlemise kood aktiveerub ainult siis, kui tabelisse salvestatav ridade väärtus ületab TOAST_TUPLE_THRESHOLD baitides (tavaliselt 2 KB). TOAST-i kood hakkab tihendama või viima välja väärtusi tabelist, kuni ridade väärtus jääb alla TOAST_TUPLE_TARGET baitide (muutuva suurusega, samuti tavaliselt 2 KB) või kuni edasine vähendamine pole võimalik.
Otsustasime, et meie andmed on kas «täiesti lühikesed» või «väga pikad», seega otsustasime piirduda minimaalse võimaliku väärtusega:
ALTER TABLE rawplan_orig SET (toast_tuple_target = 128);Vaadake, kuidas uued seaded on mõjutanud ketta laadimist pärast seadistuste muutmist:

Pole paha! Keskmine ketta järjekord lühenes umbes 1.5 korda ja ketta „kasutatus“ vähenes 20% võrra! Aga võib-olla mõjutas see kuidagi CPU-d?

Igal juhul halvemaks ei läinud. Kuigi on raske öelda, kui isegi sellised mahud ei suuda keskmise CPU koormust tõsta 5%.
Kohavahetusega muutub ka summa!
Nagu teada, hoiab rubla rubla ja meie salvestusmahu korral 10TB/kuus võib isegi väike optimeerimine anda head kasu. Seetõttu pöörasime tähelepanu oma andmete füüsilisele struktuurile — kuidas täpselt väljad on „paigutatud“ iga tabeli sissekande sees.
Sest mõjub otseselt :
Paljud arhitektuurid nõuavad andmete joondamist masinasõnade piiride järgi. Näiteks 32-bitises x86 süsteemis joondatakse täisarvud (tüüp integer, 4 baiti) 4-baidiste sõnade piiride järgi, nagu ka topelt täpsuse ujukomaarvud (tüüp double precision, 8 baiti). 64-bitises süsteemis joondatakse double väärtused 8-baidiste sõnade piiride järgi. See on veel üks põhjus, miks tekib ühilduvusprobleeme.
Joondamise tõttu sõltub tabeli rea suurus väljade paigutuse järjekorrast. Tüüpiliselt pole see efekt väga märgatav, kuid mõnel juhul võib see põhjustada märkimisväärse suuruse suurenemise. Näiteks, kui segada char(1) ja integer tüüpi välju, kaob nende vahele tavaliselt 3 baiti.
Alustame sünteetiliste mudelitega:
SELECT pg_column_size(ROW(
'0000-0000-0000-0000-0000-0000-0000-0000'::uuid
, 0::smallint
, '2019-01-01'::date
));
-- 48 baiti
SELECT pg_column_size(ROW(
'2019-01-01'::date
, '0000-0000-0000-0000-0000-0000-0000-0000'::uuid
, 0::smallint
));
-- 46 baitiKust tulid kaks üleliigset baiti esimeses juhul? See on lihtne — 2-baidine smallint joondatakse 4-baidise piiri järgi enne järgmist välja, kuid kui see on viimasena, ei ole joondamiseks mitte midagi ja pole vajadust.
Teoorias on kõik hästi ja saame väljad paigutada kuidas tahes. Kontrollime reaalsed andmed ühe tabeli näitel, mille päevane sektsioon hõivab 10-15 GB.
Algne struktuur:
CREATE TABLE public.plan_20190220
(
-- Pärandatud tabelist plan: pack uuid NOT NULL,
-- Pärandatud tabelist plan: recno smallint NOT NULL,
-- Pärandatud tabelist plan: host uuid,
-- Pärandatud tabelist plan: ts timestamp with time zone,
-- Pärandatud tabelist plan: exectime numeric(32,3),
-- Pärandatud tabelist plan: duration numeric(32,3),
-- Pärandatud tabelist plan: bufint bigint,
-- Pärandatud tabelist plan: bufmem bigint,
-- Pärandatud tabelist plan: bufdsk bigint,
-- Pärandatud tabelist plan: apn uuid,
-- Pärandatud tabelist plan: ptr uuid,
-- Pärandatud tabelist plan: dt date,
CONSTRAINT plan_20190220_pkey PRIMARY KEY (pack, recno),
CONSTRAINT chck_ptr CHECK (ptr IS NOT NULL),
CONSTRAINT plan_20190220_dt_check CHECK (dt = '2019-02-20'::date)
)
INHERITS (public.plan)Sektsioon pärast veergude järjekorra muutmist — täpselt samad väljad, ainult järjekord on teine:
LOO KAVA public.plan_20190221
(
-- Pärandatud tabelist plan: dt date NOT NULL,
-- Pärandatud tabelist plan: ts timestamp with time zone,
-- Pärandatud tabelist plan: pack uuid NOT NULL,
-- Pärandatud tabelist plan: recno smallint NOT NULL,
-- Pärandatud tabelist plan: host uuid,
-- Pärandatud tabelist plan: apn uuid,
-- Pärandatud tabelist plan: ptr uuid,
-- Pärandatud tabelist plan: bufint bigint,
-- Pärandatud tabelist plan: bufmem bigint,
-- Pärandatud tabelist plan: bufdsk bigint,
-- Pärandatud tabelist plan: exectime numeric(32,3),
-- Pärandatud tabelist plan: duration numeric(32,3),
CONSTRAINT plan_20190221_pkey PRIMARY KEY (pack, recno),
CONSTRAINT chck_ptr CHECK (ptr IS NOT NULL),
CONSTRAINT plan_20190221_dt_check CHECK (dt = '2019-02-21'::date)
)
PÄRANDAB (public.plan) Jaotise kogumaht määratakse "faktide" arvu alusel ja sõltub ainult välistest protsessidest, seega jagame heap'i suuruse (pg_relation_size) selle salvestuste arvuga — seega saame reaalse salvestuse keskmine suurus:
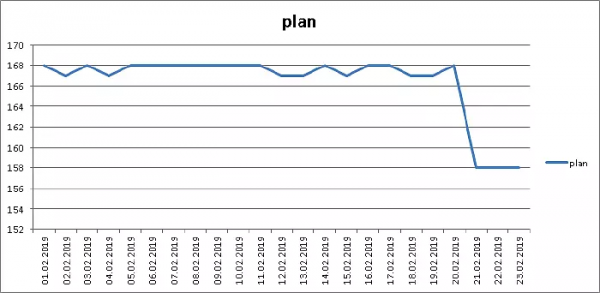
Miinus 6% mahust, suurepärane!
Aga kõik ei ole muidugi nii roosiline — sest indeksite puhul ei saa me väljade järjekorda muuta, seega "üldiselt" (pg_total_relation_size)…
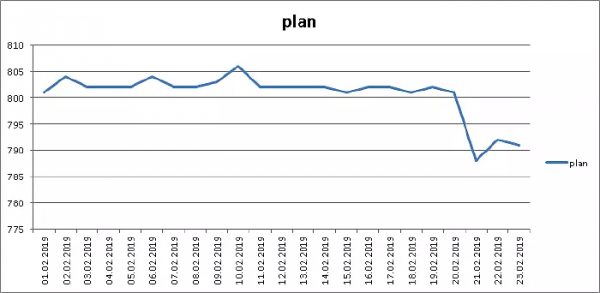
… siiski ka siin säästsime 1,5%, muutes koodis ei tilkagi. Täpselt nii!

Tahan märkida, et eespool toodud väljade paigutus ei pruugi olla kõige optimaalsem. Sest mõningaid väljade bloke ei taha juba esteetilistel põhjustel "katkestada" — näiteks paar (pack, recno), mis on selle tabeli PK.
Kokkuvõttes on "minimaalsete" väljade paigutuse määramine piisavalt lihtne "ületamisülesanne". Seega võite oma andmete abil saavutada isegi paremaid tulemusi kui meie — proovige!
Allikas: habr.com
