

Artikli tõlge on ettevalmistatud kursuse alguseks .

Kuidas säästa pilvekulusid Kubernetese kasutamisel? Ühte õiget lahendust ei ole, kuid selles artiklis on kirjeldatud mitmeid tööriistu, mis aitavad teil tõhusamalt hallata ressursse ja vähendada pilvearvutamise kulusid.
Selle artikli olen kirjutannut silmas pidades Kubernetese AWS-is, kuid see kehtib (peaaegu) samamoodi ka teiste pilveteenuste pakkujate jaoks. Eeldan, et teie kluster(ite)l on juba seadistatud automaatne skaleerimine (). Ressursside eemaldamine ja juurutamise suuruse vähendamine aitab säästa ainult siis, kui see samuti vähendab teie töökohti (EC2 instantsid).
Selles artiklis käsitletakse:
- mittetäiendavate ressursside puhastamine ()
- koormuse vähendamine mitte tööajal ()
- horisontaalse automaatse skaleerimise (HPA) kasutamine,
- üleliigse ressursi reservi vähendamine (, VPA)
- Spot instantside kasutamine
Mittekasutatavate ressursside puhastamine
Töötamine kiiresti muutuvas keskkonnas on suurepärane. Soovime, et tehnilised organisatsioonid . Kiirelema tarkvara tarnimine tähendab ka rohkem PR-deploy'e, vaheversioone, prototüüpe ja analüütilisi lahendusi. Kõik on juurutatud Kuberneteses. Kes tahab aega kulutada, et käsitsi testijuhtimisi puhastada? On kerge unustada eemaldada nädalatevanune eksperiment. Pilveteenuse arve hakkab lõpuks kasvama, kuna unustame sulgeda:
(Henning Jacobs:
Elu:
(tsitaat) Cory Quinn:
Müüt: Teie AWS arve sõltub teie kasutajate arvust.
Tõde: Teie AWS arve sõltub teie inseneride arvust.
Ivan Kurnosov (vastuseks):
Reaalne tõde: Teie AWS arve sõltub asjade arvust, mille unustasite välja lülitada/edeleteerida.)
(kube-janitor) aitab teie klastrit puhastada. Janitori konfiguratsioon on paindlik nii globaalse kui ka kohaliku kasutuse jaoks:
- Kogu klastrile kehtivad üldised reeglid, mis võivad määrata maksimaalse eluea (TTL - time-to-live) PR/testijuhtimiste jaoks.
- Erinevaid ressursse saab annoteerida janitor/ttl abil, näiteks spike/prototüübi automaatseks eemaldamiseks 7 päeva pärast.
Üldreeglid määratakse YAML-failis. Selle teekond edastatakse parameetri kaudu --rules-file kube-janitorile. Siin on näide reeglist, et eemaldada kõik nimed, mis sisaldavad -pr- nimes kahe päeva pärast:
- id: cleanup-resources-from-pull-requests
resources:
- namespaces
jmespath: "contains(metadata.name, '-pr-')"
ttl: 2dJärgmine näide määratleb application märgi kasutamise Deployment ja StatefulSet pod'ides kõigi uute Deploymentide/StatefulSet'ide jaoks aastast 2020, kuid samal ajal võimaldab testide sooritamist ilma selle märgita nädala jooksul:
- id: require-application-label
# eemaldada deployments ja statefulsets ilma "application" märgita
resources:
- deployments
- statefulsets
# vt http://jmespath.org/specification.html
jmespath: "!(spec.template.metadata.labels.application) && metadata.creationTimestamp > '2020-01-01'"
ttl: 7dAjaliselt piiratud demoversioon 30 minutiks kasti, kus töötab kube-janitor:
kubectl run nginx-demo --image=nginx
kubectl annotate deploy nginx-demo janitor/ttl=30mÜks tõusvate kulude allikaid on püsivolumeid (AWS EBS). Kui Kubernetes StatefulSet'i eemaldatakse, ei eemaldata selle püsivalt (PVC — PersistentVolumeClaim). Kasutamata EBS mahud võivad kergesti põhjustada sadu dollareid kulusid kuus. Kubernetes Janitoril on funktsioon kasutamata PVC-de puhastamiseks. Näiteks see reegel eemaldab kõik PVC-d, mis ei ole üles seatud mooduliga ja millele ei viita StatefulSet või CronJob:
# удалить все PVC, которые не смонтированы и на которые не ссылаются StatefulSets
- id: remove-unused-pvcs
resources:
- persistentvolumeclaims
jmespath: "_context.pvc_is_not_mounted && _context.pvc_is_not_referenced"
ttl: 24hKubernetes Janitor võib aidata teil hoida oma klastrit „puhtana” ja vältida aeglaselt kogunevaid pilvearvutamise kulusid. Üksikasjade jaoks juurutamise ja seadistamise kohta järgige .
Maha suurendamine mitte tööajal
Testimis- ja vahepealsed süsteemid vajavad tavaliselt tööd ainult tööajal. Mõned tootmisrakendused, nagu back-office / haldustööriistad, vajavad samuti ainult piiratud kättesaadavust ja võivad öösel välja lülitada.
(kube-downscaler) võimaldab kasutajatel ja operaatoritel vähendada süsteemi suurust mitte tootmisajal. Deployments ja StatefulSets saab skaleerida null-replikaatidele. CronJobs võivad olla peatatud. Kubernetes Downscaler seadistatakse kogu klastrile, ühele või mitmele nimekontrollile või üksikutele ressurssidele. Saate seadistada kas „seisakuaja“ või vastupidi „töötamise aja“. Näiteks, et maksimaalselt vähendada skaleerimist öösel ja nädalavahetustel:
image: hjacobs/kube-downscaler:20.4.3
args:
- --interval=30
# ärge keelake infrastruktuuri komponente
- --exclude-namespaces=kube-system,infra
# ärge keelake kube-downscalerit ja jätke Postgres Operator, et välistatud andmebaase saaks hallata
- --exclude-deployments=kube-downscaler,postgres-operator
- --default-uptime=Mon-Fri 08:00-20:00 Europe/Berlin
- --include-resources=deployments,statefulsets,stacks,cronjobs
- --deployment-time-annotation=deployment-timeSiin on graafik klastrite töötavate sõlmede skaleerimise kohta nädalavahetustel:
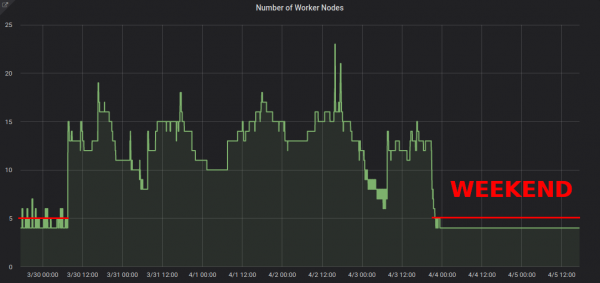
Skaleerimine ~13-lt 4 töökohtadele annab kindlasti tunda erinevust AWS arvel.
Aga mis siis, kui pean töötama klastris "seisaku ajal"? Teatud juurutamised saab igaveseks mõõtmisest välja jätta, lisades annotatsiooni downscaler/exclude: true. Juurutamisi saab ajaliselt välja jätta annotatsiooni downscaler/exclude-until abil, mille absoluutne ajamärk on formaadis AAAA-KK-PP TT:MM (UTC). Vajadusel saab kogu klastri tagasi mõõta, juurutades poodi koos annotatsiooniga downscaler/force-uptime, näiteks käivitades nginx mudeli:
kubectl run scale-up --image=nginx
kubectl annotate deploy scale-up janitor/ttl=1h # kustuta juurutamine tunni pärast
kubectl annotate pod $(kubectl get pod -l run=scale-up -o jsonpath="{.items[0].metadata.name}") downscaler/force-uptime=trueVaata , kui teid huvitab juurutamise juhend ja täiendavad valikud.
Kasutage horisontaalset automaatskaalumist
Paljud rakendused/teenused tegelevad dünaamilise koormusgraafikuga: mõnikord on nende moodulid seisakus ja mõnikord töötavad nad täievõimsusega. Püsiva podide pargi hoidmine maksimaalse tippkoormuse haldamiseks ei ole majanduslik. Kubernetes toetab horisontaalset automaatset kaalumist läbi ressursi (HPA). CPU kasutamine on sageli hea näitaja skaleerimiseks:
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: my-app
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: my-app
minReplicas: 3
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
averageUtilization: 100
type: UtilizationZalando on loonud komponendi, mis lihtsustab kasutajamõõtmete ühendamist skaleerimiseks: (kube-metrics-adapter) on universaalne mõõtmete adapter Kubernetes jaoks, mis suudab koguda ja teenindada kasutaja- ja välist mõõtmeid pod'ide horisontaalse automaatse skaleerimise jaoks. See toetab skaleerimist Prometheuse, SQS järjekordade ja muude seadistuste põhiselt. Näiteks, et skaleerida rakenduse poolt esitatud kasutajamõõdiku põhjal, mis on JSON kujul aadressil /metrics, kasutage:
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: myapp-hpa
annotations:
# metric-config.../
metric-config.pods.requests-per-second.json-path/json-key: "$.http_server.rps"
metric-config.pods.requests-per-second.json-path/path: /metrics
metric-config.pods.requests-per-second.json-path/port: "9090"
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: myapp
minReplicas: 1
maxReplicas: 10
metrics:
- type: Pods
pods:
metric:
name: requests-per-second
target:
averageValue: 1k
type: AverageValueHorisontaalse automaasistumise seadistamine HPA abil peaks olema üks vaikeseade, et suurendada teenuste efektiivsust olekust sõltumatult. Spotify-l on esitluses oma kogemused ja soovitused HPA kohta: .
ressursside ülevarustamise vähendamine
Kubernetesi töökohustused määravad oma CPU/mälu vajadused "ressursside taotluste" (resource requests) kaudu. CPU ressursid mõõdetakse virtuaalsete tuumade või sagedamini "millicores" (millikernad) kaudu, näiteks 500m tähendab 50% vCPU-st. Mälu ressursid mõõdetakse baitides ning saab kasutada tavalisi sufikseid, näiteks 500Mi, mis tähendab 500 MB. Ressursside taotlused "broneerivad" mahtu töötlusõlmedes, see tähendab, et moodul, mille CPU taotlus on 1000m, jääb 4 virtuaalse CPU-ga sõlmes, jätab ainult 3 virtuaalset CPU-d teistele moodulitele.
Slack (ülejääk) — on vahe taotletud ressursside ja tegeliku kasutamise vahel. Näiteks pod, mis taotleb 2 GiB mälu, kuid kasutab ainult 200 MiB, omab ~ 1,8 GiB "ülejääki" mälu. Ülejääk maksab raha. Üks pelgalt hinnang on, et 1 GiB üleliigset mälu maksab ~ 10 dollarit kuus.
(kube-resource-report) kuvab liigsed varud ja võib aidata teil määrata võimalikku kokkuhoidu:
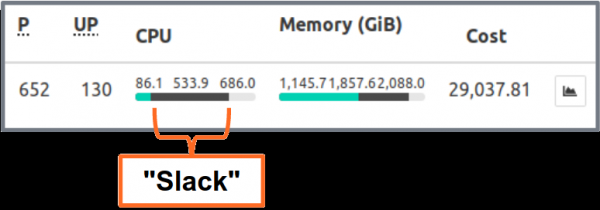
näitab ülemäärasid, mille rakendus ja meeskond on kokku kogunud. See aitab leida kohti, kus ressursipäringut saab vähendada. Generitud HTML-raport annab ainult hetkepildi ressursi kasutamisest. Peaksite vaatama protsessori/mälu kasutamist ajas, et määrata sobivad ressursipäringud. Siin on Grafana diagramm „tüüpilise” kõrgelt koormatud teenuse jaoks: kõik podid kasutavad oluliselt vähem kui 3 nõutud protsessorituuma.
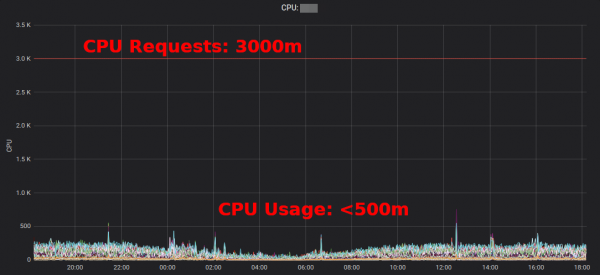
Protsessoripäringu vähendamine 3000m-lt ~400m-le vabastab ressursse teiste töökoormuste jaoks ja võimaldab klastrit vähendada.
„EC2 instantside keskmine protsessorikasutus kõigub sageli ühesigitistes protsentides,” . Samal ajal kui EC2 , muudatused mõnedes Kubernetes'e ressursipäringutes YAML-failis on lihtsad ja võivad tuua tohutu kokkuhoiu.
Aga kas me tõeliselt tahame, et inimesed muudaksid väärtusi YAML-failides? Ei, masinad saavad seda palju paremini teha! Kubernetes (VPA) tegeleb just sellega: kohandab ressursipäringuid ja piiranguid vastavalt töökoormusele. Siin on näide Prometheuse CPU päringute graafikust (peen sinine joon), mida on kohandatud VPA aja jooksul:
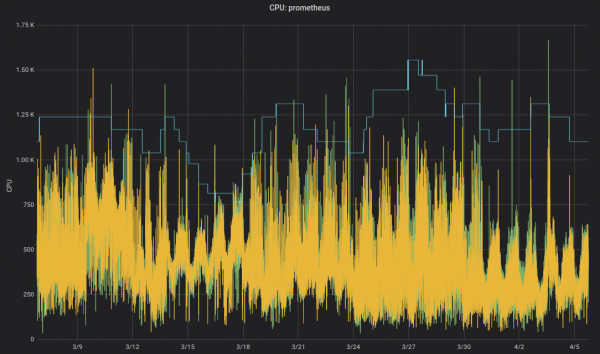
infrastruktuuri komponente jaoks. Mitte-kriitilised rakendused saavad samuti VPA-d kasutada.
Fairwindilt — see on tööriist, mis loob VPA iga nimede ruumi juuresoleku jaoks ja seejärel kuvab VPA soovituse oma juhtpaneelil. See aitab arendajatel seada õiged CPU/mälu päringud oma rakendustele:
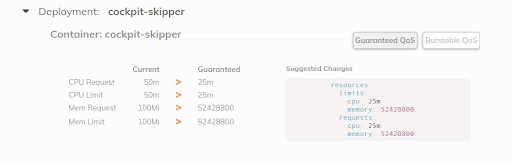
Kirjutasin väikesest 2019. aastal ja hiljuti arutati .
EC2 Spot instantside kasutamine
Lõpuks, mis ei ole vähem oluline, saab AWS EC2 kulusid vähendada, kasutades Spot instantside kui Kubernetes tööõliseid . Spot instantsi on saadaval kuni 90% soodsamalt võrreldes nõudmisest tulenevate hindadega. Kubernetes käivitamine EC2 Spotil on hea kombinatsioon: peate määrama mitu erinevat instantsitüüpi kõrgema saadavuse tagamiseks, st saate sama või madalama hinna eest suurema sõlme ning suurenenud mahtu saab kasutada Kubernetes'i konteineritöökoormustes.
Kuidas käivitada Kubernetes EC2 Spotal? On mitmeid võimalusi: kasutada kolmanda osapoole teenust, nagu SpotInst (nüüd tuntud kui „Spot”, ära küsi, miks), või lihtsalt lisada Spot AutoScalingGroup (ASG) oma klastrisse. Näiteks siin on CloudFormation'i fragment „mahtude optimeeritud” Spot ASG jaoks mitme eksemplari tüübiga:
MySpotAutoScalingGroup:
Properties:
HealthCheckGracePeriod: 300
HealthCheckType: EC2
MixedInstancesPolicy:
InstancesDistribution:
OnDemandPercentageAboveBaseCapacity: 0
SpotAllocationStrategy: capacity-optimized
LaunchTemplate:
LaunchTemplateSpecification:
LaunchTemplateId: !Ref LaunchTemplate
Version: !GetAtt LaunchTemplate.LatestVersionNumber
Overrides:
- InstanceType: "m4.2xlarge"
- InstanceType: "m4.4xlarge"
- InstanceType: "m5.2xlarge"
- InstanceType: "m5.4xlarge"
- InstanceType: "r4.2xlarge"
- InstanceType: "r4.4xlarge"
LaunchTemplate:
LaunchTemplateId: !Ref LaunchTemplate
Version: !GetAtt LaunchTemplate.LatestVersionNumber
MinSize: 0
MaxSize: 100
Tags:
- Key: k8s.io/cluster-autoscaler/node-template/label/aws.amazon.com/spot
PropagateAtLaunch: true
Value: "true"Mõned märkmed Spot'i kasutamise kohta Kubernetes'ega:
- peate haldama Spot'i lõpetamisi, näiteks sõlme massimise kaudu instantsi seiskamisel
- Zalando kasutab ametlikku klastrite automaatset skaleerimist sõlmede basseinide prioriteetidega
- Spot'i sõlmed töötavate koormuste "registreeringute" vastuvõtmist Spot'is
Kokkuvõte
Loodan, et leiate mõned esitatud tööriistad kasulikuks oma pilvearvutuse arve vähendamiseks. Suurema osa artikli sisust leiate ka .
Millised on teie parimad praktikud Kubernetes'e pilvekulude kokkuhoiuks? Andke kindlasti teada .
Tegelikult jääb vähem kui 3 virtuaalset CPU-d kasutamiseks sobivaks, kuna sõlme läbilaskevõime väheneb reserveeritud süsteemressursside tõttu. Kubernetes eristab füüsilist sõlme suutlikkust ja "eraldatud" ressursse ().
Näide arvutusest: üks m5.large instants 8 GiB mäluga maksab umbes 84 USA dollarit kuus (eu-central-1, On-Demand), st 1/8 sõlme lukustamine maksab umbes 10 USA dollarit kuus.
On veel palju viise, kuidas oma EC2 arvet vähendada, näiteks reserveeritud instantsid, säästuplaan jne — ma ei kavatse neid teemasid siin käsitleda, kuid peaksite kindlasti uurima!
Allikas: habr.com
