

Tere kõigile. Arendame välja toodet võrguühenduseta liikluse analüüsimiseks. Projekti ülesanne on piirkondadeüleste külastajate marsruutide statistiline analüüs.
Selle ülesande osana saavad kasutajad küsida järgmist tüüpi süsteemipäringuid:
- mitu külastajat läks piirkonnast "A" piirkonda "B";
- mitu külastajat läks piirkonnast "A" piirkonda "B" läbi piirkonna "C" ja seejärel läbi piirkonna "D";
- kui kaua kulus teatud tüüpi külastajal reisimiseks piirkonnast “A” piirkonda “B”.
ja mitmeid sarnaseid analüütilisi päringuid.
Külastaja liikumine piirkondade vahel on suunatud graafik. Internetti lugedes avastasin, et graafikute DBMS-e kasutatakse ka analüütiliste aruannete jaoks. Mul oli soov näha, kuidas graafilised DBMS-id selliste päringutega toime tulevad (TL; DR; halvasti).
Valisin kasutada DBMS-i , kui graafilise avatud lähtekoodiga DBMS-i silmapaistev esindaja, mis tugineb küpsetele tehnoloogiatele, mis (minu arvates) peaksid andma sellele korralikud tööomadused:
- BerkeleyDB salvestustagaprogramm, Apache Cassandra, Scylla;
- kompleksseid indekseid saab salvestada Lucene'is, Elasticsearchis, Solris.
JanusGraphi autorid kirjutavad, et see sobib nii OLTP kui OLAP jaoks.
Olen töötanud BerkeleyDB, Apache Cassandra, Scylla ja ES-iga ning neid tooteid kasutatakse meie süsteemides sageli, seega olin selle graafiku DBMS-i testimise suhtes optimistlik. Minu arvates oli kummaline valida BerkeleyDB asemel RocksDB, kuid see on tõenäoliselt tingitud tehingunõuetest. Igal juhul on skaleeritava toote kasutamiseks soovitatav kasutada Cassandra või Scylla taustaprogrammi.
Ma ei arvestanud Neo4j-ga, kuna klasterdamiseks on vaja kommertsversiooni, st toode ei ole avatud lähtekoodiga.
Graafiku DBMS-id ütlevad: "Kui see näeb välja nagu graafik, käsitlege seda graafikuna!" - ilu!
Kõigepealt joonistasin graafiku, mis tehti täpselt graafiliste DBMS-ide kaanonite järgi:
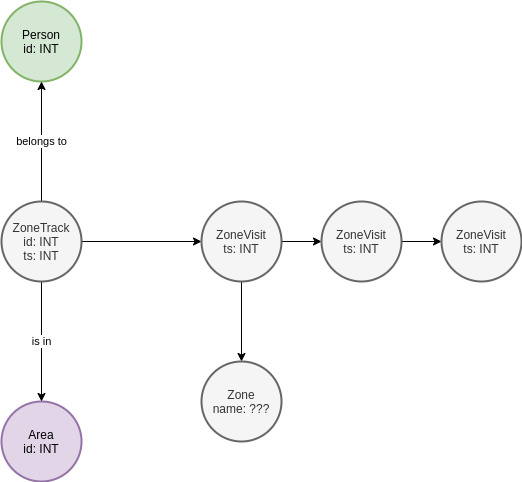
Olemus on olemas Zone, vastutab piirkonna eest. Kui ZoneStep kuulub selle juurde Zone, siis ta viitab sellele. Sisuliselt Area, ZoneTrack, Person Ärge pöörake tähelepanu, need kuuluvad domeeni ja neid ei peeta testi osaks. Kokku näeks sellise graafikustruktuuri ahelotsingupäring välja järgmine:
g.V().hasLabel('Zone').has('id',0).in_()
.repeat(__.out()).until(__.out().hasLabel('Zone').has('id',19)).count().next()Mis vene keeles on umbes selline: leidke tsoon ID=0, võtke kõik tipud, kust serv sinna läheb (ZoneStep), trampige tagasi minemata, kuni leiate need ZoneSteps, kust on serv tsooni ID=19, loendage selliste kettide arv.
Ma ei pretendeeri, et tean kõiki graafikute järgi otsimise keerukusi, kuid see päring loodi selle raamatu põhjal ().
Laadisin BerkeleyDB taustaprogrammi kasutades JanusGraphi graafikute andmebaasi 50 tuhat rada pikkusega 3 kuni 20 punkti ja lõin indeksid vastavalt .
Pythoni allalaadimisskript:
from random import random
from time import time
from init import g, graph
if __name__ == '__main__':
points = []
max_zones = 19
zcache = dict()
for i in range(0, max_zones + 1):
zcache[i] = g.addV('Zone').property('id', i).next()
startZ = zcache[0]
endZ = zcache[max_zones]
for i in range(0, 10000):
if not i % 100:
print(i)
start = g.addV('ZoneStep').property('time', int(time())).next()
g.V(start).addE('belongs').to(startZ).iterate()
while True:
pt = g.addV('ZoneStep').property('time', int(time())).next()
end_chain = random()
if end_chain < 0.3:
g.V(pt).addE('belongs').to(endZ).iterate()
g.V(start).addE('goes').to(pt).iterate()
break
else:
zone_id = int(random() * max_zones)
g.V(pt).addE('belongs').to(zcache[zone_id]).iterate()
g.V(start).addE('goes').to(pt).iterate()
start = pt
count = g.V().count().next()
print(count)Kasutasime SSD-l 4 tuuma ja 16 GB muutmäluga VM-i. JanusGraph juurutati selle käsuga:
docker run --name janusgraph -p8182:8182 janusgraph/janusgraph:latestSel juhul salvestatakse täpse vaste otsimiseks kasutatavad andmed ja indeksid BerkeleyDB-sse. Olles varem antud päringu täitnud, sain aja, mis võrdub mitmekümne sekundiga.
Käitades 4 ülaltoodud skripti paralleelselt, õnnestus mul muuta DBMS-ist kõrvits koos lõbusa Java pinujälgede vooga (ja meile kõigile meeldib Java stacktrace'i lugeda) Dockeri logides.
Pärast mõningast mõtlemist otsustasin graafiku diagrammi järgmiselt lihtsustada:
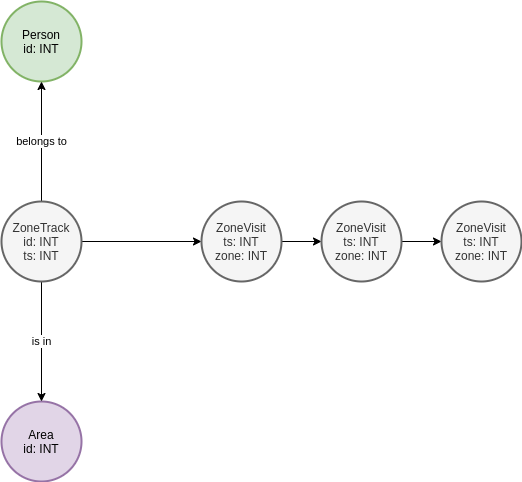
Otsustades, et olemi atribuutide järgi otsimine oleks kiirem kui servade järgi otsimine. Selle tulemusena muutus minu taotlus järgmiseks:
g.V().hasLabel('ZoneStep').has('id',0).repeat(__.out().simplePath()).until(__.hasLabel('ZoneStep').has('id',19)).count().next()Mis vene keeles on umbes selline: leidke ZoneStep ID=0-ga, trampige tagasi minemata, kuni leiate ZoneStepi ID=19-ga, loendage selliste kettide arv.
Samuti lihtsustasin ülaltoodud laadimisskripti, et mitte luua tarbetuid ühendusi, piirdudes atribuutidega.
Taotluse täitmine võttis siiski mitu sekundit, mis oli meie ülesande jaoks täiesti vastuvõetamatu, kuna see ei sobinud absoluutselt igasuguste AdHoc taotluste jaoks.
Proovisin juurutada JanusGraphi, kasutades Scyllat kiireima Cassandra juurutusena, kuid see ei toonud kaasa ka olulisi jõudluse muutusi.
Nii et hoolimata asjaolust, et "see näeb välja nagu graafik", ei saanud ma graafiku DBMS-i seda kiiresti töödelda. Ma eeldan täielikult, et on midagi, mida ma ei tea ja et JanusGraphi saab panna selle otsingu sooritama sekundi murdosaga, kuid ma ei saanud seda teha.
Kuna probleem vajas veel lahendamist, siis hakkasin mõtlema tabelite JOIN-ide ja Pivotide peale, mis küll elegantsi osas optimismi ei sisendanud, kuid praktikas võiks olla täiesti toimiv variant.
Meie projekt kasutab juba Apache ClickHouse'i, seega otsustasin testida oma uurimistööd selle analüütilise DBMS-i kohta.
ClickHouse'i juurutamine lihtsa retsepti abil:
sudo docker run -d --name clickhouse_1
--ulimit nofile=262144:262144
-v /opt/clickhouse/log:/var/log/clickhouse-server
-v /opt/clickhouse/data:/var/lib/clickhouse
yandex/clickhouse-serverTegin andmebaasi ja sellesse tabeli järgmiselt:
CREATE TABLE
db.steps (`area` Int64, `when` DateTime64(1, 'Europe/Moscow') DEFAULT now64(), `zone` Int64, `person` Int64)
ENGINE = MergeTree() ORDER BY (area, zone, person) SETTINGS index_granularity = 8192Täitsin selle andmetega järgmise skripti abil:
from time import time
from clickhouse_driver import Client
from random import random
client = Client('vm-12c2c34c-df68-4a98-b1e5-a4d1cef1acff.domain',
database='db',
password='secret')
max = 20
for r in range(0, 100000):
if r % 1000 == 0:
print("CNT: {}, TS: {}".format(r, time()))
data = [{
'area': 0,
'zone': 0,
'person': r
}]
while True:
if random() < 0.3:
break
data.append({
'area': 0,
'zone': int(random() * (max - 2)) + 1,
'person': r
})
data.append({
'area': 0,
'zone': max - 1,
'person': r
})
client.execute(
'INSERT INTO steps (area, zone, person) VALUES',
data
)Kuna vahetükke tuleb partiidena, oli täitmine palju kiirem kui JanusGraphi puhul.
Koostas kaks päringut kasutades JOIN. Punktist A punkti B liikumiseks:
SELECT s1.person AS person,
s1.zone,
s1.when,
s2.zone,
s2.when
FROM
(SELECT *
FROM steps
WHERE (area = 0)
AND (zone = 0)) AS s1 ANY INNER JOIN
(SELECT *
FROM steps AS s2
WHERE (area = 0)
AND (zone = 19)) AS s2 USING person
WHERE s1.when <= s2.when3 punkti läbimiseks:
SELECT s3.person,
s1z,
s1w,
s2z,
s2w,
s3.zone,
s3.when
FROM
(SELECT s1.person AS person,
s1.zone AS s1z,
s1.when AS s1w,
s2.zone AS s2z,
s2.when AS s2w
FROM
(SELECT *
FROM steps
WHERE (area = 0)
AND (zone = 0)) AS s1 ANY INNER JOIN
(SELECT *
FROM steps AS s2
WHERE (area = 0)
AND (zone = 3)) AS s2 USING person
WHERE s1.when <= s2.when) p ANY INNER JOIN
(SELECT *
FROM steps
WHERE (area = 0)
AND (zone = 19)) AS s3 USING person
WHERE p.s2w <= s3.whenTaotlused näevad muidugi üsna hirmutavad välja, reaalseks kasutamiseks tuleb luua tarkvarageneraatori rakmed. Kuid nad töötavad ja töötavad kiiresti. Nii esimene kui ka teine päring täidetakse vähem kui 0.1 sekundiga. Siin on näide count(*) päringu täitmisajast, mis läbib 3 punkti:
SELECT count(*)
FROM
(
SELECT
s1.person AS person,
s1.zone AS s1z,
s1.when AS s1w,
s2.zone AS s2z,
s2.when AS s2w
FROM
(
SELECT *
FROM steps
WHERE (area = 0) AND (zone = 0)
) AS s1
ANY INNER JOIN
(
SELECT *
FROM steps AS s2
WHERE (area = 0) AND (zone = 3)
) AS s2 USING (person)
WHERE s1.when <= s2.when
) AS p
ANY INNER JOIN
(
SELECT *
FROM steps
WHERE (area = 0) AND (zone = 19)
) AS s3 USING (person)
WHERE p.s2w <= s3.when
┌─count()─┐
│ 11592 │
└─────────┘1 rows in set. Elapsed: 0.068 sec. Processed 250.03 thousand rows, 8.00 MB (3.69 million rows/s., 117.98 MB/s.)Märkus IOPS-i kohta. Andmete täitmisel genereeris JanusGraph üsna palju IOPS-e (1000-1300 nelja andmepopulatsiooni lõime jaoks) ja IOWAIT oli üsna kõrge. Samal ajal tekitas ClickHouse ketta alamsüsteemi minimaalse koormuse.
Järeldus
Otsustasime seda tüüpi taotluste teenindamiseks kasutada ClickHouse'i. Saame alati päringuid veelgi optimeerida, kasutades materialiseeritud vaateid ja paralleelsust, eeltöötledes sündmuste voogu Apache Flinki abil enne nende ClickHouse'i laadimist.
Jõudlus on nii hea, et tõenäoliselt ei pea me isegi mõtlema tabelite programmilisele pööramisele. Varem pidime tegema Verticast hangitud andmete pöördeid Apache Parqueti üleslaadimise kaudu.
Kahjuks ebaõnnestus järjekordne graafilise DBMS-i kasutamise katse. Ma ei leidnud, et JanusGraphil oleks sõbralik ökosüsteem, mis hõlbustaks tootega kursis olemist. Samal ajal kasutatakse serveri konfigureerimiseks traditsioonilist Java-viisi, mis paneb Javaga mitte tuttavad inimesed verepisaraid nutma:
host: 0.0.0.0
port: 8182
threadPoolWorker: 1
gremlinPool: 8
scriptEvaluationTimeout: 30000
channelizer: org.janusgraph.channelizers.JanusGraphWsAndHttpChannelizer
graphManager: org.janusgraph.graphdb.management.JanusGraphManager
graphs: {
ConfigurationManagementGraph: conf/janusgraph-cql-configurationgraph.properties,
airlines: conf/airlines.properties
}
scriptEngines: {
gremlin-groovy: {
plugins: { org.janusgraph.graphdb.tinkerpop.plugin.JanusGraphGremlinPlugin: {},
org.apache.tinkerpop.gremlin.server.jsr223.GremlinServerGremlinPlugin: {},
org.apache.tinkerpop.gremlin.tinkergraph.jsr223.TinkerGraphGremlinPlugin: {},
org.apache.tinkerpop.gremlin.jsr223.ImportGremlinPlugin: {classImports: [java.lang.Math], methodImports: [java.lang.Math#*]},
org.apache.tinkerpop.gremlin.jsr223.ScriptFileGremlinPlugin: {files: [scripts/airline-sample.groovy]}}}}
serializers:
# GraphBinary is here to replace Gryo and Graphson
- { className: org.apache.tinkerpop.gremlin.driver.ser.GraphBinaryMessageSerializerV1, config: { ioRegistries: [org.janusgraph.graphdb.tinkerpop.JanusGraphIoRegistry] }}
- { className: org.apache.tinkerpop.gremlin.driver.ser.GraphBinaryMessageSerializerV1, config: { serializeResultToString: true }}
# Gryo and Graphson, latest versions
- { className: org.apache.tinkerpop.gremlin.driver.ser.GryoMessageSerializerV3d0, config: { ioRegistries: [org.janusgraph.graphdb.tinkerpop.JanusGraphIoRegistry] }}
- { className: org.apache.tinkerpop.gremlin.driver.ser.GryoMessageSerializerV3d0, config: { serializeResultToString: true }}
- { className: org.apache.tinkerpop.gremlin.driver.ser.GraphSONMessageSerializerV3d0, config: { ioRegistries: [org.janusgraph.graphdb.tinkerpop.JanusGraphIoRegistry] }}
# Older serialization versions for backwards compatibility:
- { className: org.apache.tinkerpop.gremlin.driver.ser.GryoMessageSerializerV1d0, config: { ioRegistries: [org.janusgraph.graphdb.tinkerpop.JanusGraphIoRegistry] }}
- { className: org.apache.tinkerpop.gremlin.driver.ser.GryoMessageSerializerV1d0, config: { serializeResultToString: true }}
- { className: org.apache.tinkerpop.gremlin.driver.ser.GryoLiteMessageSerializerV1d0, config: {ioRegistries: [org.janusgraph.graphdb.tinkerpop.JanusGraphIoRegistry] }}
- { className: org.apache.tinkerpop.gremlin.driver.ser.GraphSONMessageSerializerGremlinV2d0, config: { ioRegistries: [org.janusgraph.graphdb.tinkerpop.JanusGraphIoRegistry] }}
- { className: org.apache.tinkerpop.gremlin.driver.ser.GraphSONMessageSerializerGremlinV1d0, config: { ioRegistries: [org.janusgraph.graphdb.tinkerpop.JanusGraphIoRegistryV1d0] }}
- { className: org.apache.tinkerpop.gremlin.driver.ser.GraphSONMessageSerializerV1d0, config: { ioRegistries: [org.janusgraph.graphdb.tinkerpop.JanusGraphIoRegistryV1d0] }}
processors:
- { className: org.apache.tinkerpop.gremlin.server.op.session.SessionOpProcessor, config: { sessionTimeout: 28800000 }}
- { className: org.apache.tinkerpop.gremlin.server.op.traversal.TraversalOpProcessor, config: { cacheExpirationTime: 600000, cacheMaxSize: 1000 }}
metrics: {
consoleReporter: {enabled: false, interval: 180000},
csvReporter: {enabled: false, interval: 180000, fileName: /tmp/gremlin-server-metrics.csv},
jmxReporter: {enabled: false},
slf4jReporter: {enabled: true, interval: 180000},
gangliaReporter: {enabled: false, interval: 180000, addressingMode: MULTICAST},
graphiteReporter: {enabled: false, interval: 180000}}
threadPoolBoss: 1
maxInitialLineLength: 4096
maxHeaderSize: 8192
maxChunkSize: 8192
maxContentLength: 65536
maxAccumulationBufferComponents: 1024
resultIterationBatchSize: 64
writeBufferHighWaterMark: 32768
writeBufferHighWaterMark: 65536
ssl: {
enabled: false}Mul õnnestus kogemata JanusGraphi BerkeleyDB versioon "panna".
Dokumentatsioon on indeksite osas üsna kõver, kuna indeksite haldamine nõuab Groovys üsna kummalist šamanismi. Näiteks indeksi loomine peab toimuma Gremlini konsoolis koodi kirjutamisega (mis muide ei tööta ka väljas). Ametlikust JanusGraphi dokumentatsioonist:
graph.tx().rollback() //Never create new indexes while a transaction is active
mgmt = graph.openManagement()
name = mgmt.getPropertyKey('name')
age = mgmt.getPropertyKey('age')
mgmt.buildIndex('byNameComposite', Vertex.class).addKey(name).buildCompositeIndex()
mgmt.buildIndex('byNameAndAgeComposite', Vertex.class).addKey(name).addKey(age).buildCompositeIndex()
mgmt.commit()
//Wait for the index to become available
ManagementSystem.awaitGraphIndexStatus(graph, 'byNameComposite').call()
ManagementSystem.awaitGraphIndexStatus(graph, 'byNameAndAgeComposite').call()
//Reindex the existing data
mgmt = graph.openManagement()
mgmt.updateIndex(mgmt.getGraphIndex("byNameComposite"), SchemaAction.REINDEX).get()
mgmt.updateIndex(mgmt.getGraphIndex("byNameAndAgeComposite"), SchemaAction.REINDEX).get()
mgmt.commit()järelsõna
Teatud mõttes on ülaltoodud katse võrdlus sooja ja pehme vahel. Kui järele mõelda, teeb graafik DBMS samade tulemuste saamiseks muid toiminguid. Testide osana viisin aga läbi ka katse järgmise taotlusega:
g.V().hasLabel('ZoneStep').has('id',0)
.repeat(__.out().simplePath()).until(__.hasLabel('ZoneStep').has('id',1)).count().next()mis peegeldab jalutuskäigu kaugusel. Kuid isegi sellistel andmetel näitas graafik DBMS tulemusi, mis ületasid mõne sekundi... See on muidugi tingitud asjaolust, et seal olid sellised teed nagu 0 -> X -> Y ... -> 1, mida graafikumootor ka kontrollis.
Isegi sellise päringu puhul nagu:
g.V().hasLabel('ZoneStep').has('id',0).out().has('id',1)).count().next()Ma ei saanud tulemuslikku vastust töötlemisajaga alla sekundi.
Loo moraal seisneb selles, et ilus idee ja paradigmaatiline modelleerimine ei vii soovitud tulemuseni, mida näidatakse ClickHouse'i näitel palju suurema efektiivsusega. Selles artiklis esitatud kasutusjuhtum on graafiliste DBMS-ide jaoks selge antimuster, kuigi see näib nende paradigmas modelleerimiseks sobivat.
Allikas: www.habr.com
