


По мотивам моих выступлений на Highload++ и DataFest Minsk 2019 г.
Для многих сегодня почта является неотъемлемой частью жизни в сети. С ее помощью мы ведем бизнес-переписку, храним всевозможную важную информацию, связанную с финансами, бронированием отелей, оформлением заказов и многим другим. В середине 2018 года мы сформулировали продуктовую стратегию развития почты. Какой же должна быть современная почта?
Почта обязана быть умной, то есть помогать пользователям ориентироваться в увеличивающемся объеме информации: фильтровать, структурировать и предоставлять ее наиболее удобным способом. Она должна быть полезной, позволяя прямо в почтовом ящике решать различные задачи, например, оплачивать штрафы (функция, которой я, к своему сожалению, пользуюсь). И при этом, разумеется, почта должна обеспечивать информационную защиту, отсекая спам и защищая от взломов, то есть быть turvalisest.
Эти направления определяют ряд ключевых задач, многие из которых могут быть эффективно решены с помощью машинного обучения. Вот примеры уже действующих фичей, разработанных в рамках стратегии — по одному на каждое направление.
- Smart Reply. В почте есть функция умного ответа. Нейросеть анализирует текст письма, понимает его смысл и цель, и в результате предлагает три наиболее подходящих варианта ответа: позитивный, негативный и нейтральный. Это помогает существенно экономить время при ответах на письма, а также часто отвечать нестандартно и забавно для себя.
- Группировка писем, относящихся к заказам в интернет-магазинах. Мы часто совершаем покупки в интернете, и, как правило, магазины могут присылать по несколько писем на каждый заказ. Например, от АлиЭкспресса, самого крупного сервиса, приходит очень много писем по одному заказу, и мы посчитали, что в терминальном случае их количество может доходить до 29. Поэтому с помощью модели Named Entity Recognition мы выделяем номер заказа и прочую информацию из текста и группируем все письма в один тред. Также показываем основную информацию о заказе в отдельной плашке, что облегчает работу с этим типом писем.

- Антифишинг. Фишинг — особо опасный мошеннический тип писем, с помощью которого злоумышленники пытаются завладеть финансовой информацией (в том числе о банковских картах пользователя) и логинами. Такие письма мимикрируют под настоящие, разосланные сервисом, в том числе визуально. Поэтому с помощью Computer Vision мы распознаем логотипы и стиль оформления писем крупных компаний (например, Mail.ru, Сбер, Альфа) и учитываем это наряду с текстом и прочими признаками в наших классификаторах спама и фишинга.
Masinõpe
Немного про машинное обучение в почте в целом. Почта — высоконагруженная система: через наши сервера проходит в среднем по 1,5 млрд писем в сутки для 30 млн пользователей DAU. Обслуживают все необходимые функции и фичи порядка 30 систем машинного обучения.
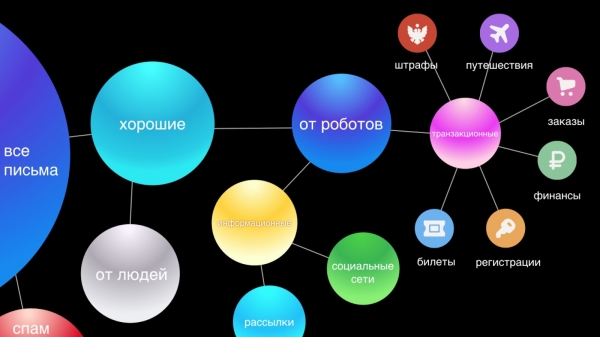
Каждое письмо проходит через целый конвейер классификации. Сначала мы отсекаем спам и оставляем хорошие письма. Пользователи зачастую не замечают работу антиспама, потому что 95—99 % спама не попадают даже в соответствующую папку. Распознавание спама — очень важная часть нашей системы, и наиболее сложная, так как в сфере антиспама идет постоянная адаптация между системами защиты и атаки, что поставляет непрерывный инженерный челленж для нашей команды.
Далее разделяем письма от людей и роботов. Письма от людей наиболее важны, поэтому для них мы предоставляем функции типа Smart Reply. Письма от роботов делятся на две части: транзакционные — это важные письма от сервисов, например, подтверждения покупок или брони отеля, финансы, и информационные — это бизнес-реклама, скидки.
Мы считаем, что транзакционные письма по значимости равны личной переписке. Они должны быть под рукой, поскольку часто бывает нужно быстро найти информацию о заказе или бронь авиабилета, а мы тратим время на поиск этих писем. Поэтому мы для удобства автоматически делим их на шесть основных категорий: путешествия, заказы, финансы, билеты, регистрации и, наконец, штрафы.
Информационные письма — самая многочисленная и, наверное, менее важная группа, не требующая мгновенной реакции, так как ничего существенного не изменится в жизни пользователя, если он не прочтет подобное письмо. В нашем новом интерфейсе мы сворачиваем их в два треда: соцсети и рассылки, таким образом визуально очищая ящик и оставляя на виду только важные письма.
Töötamine
Большое количество систем доставляет немало трудностей в эксплуатации. Ведь модели со временем деградируют, как и любой софт: ломаются признаки, отказывают машины, накатывается кривой код. К тому же постоянно меняются данные: добавляются новые, трансформируется паттерн поведения пользователей и т.д., поэтому модель без должной поддержки со временем будет работать всё хуже и хуже.
Нельзя забывать и о том, что чем глубже машинное обучение проникает в жизнь пользователей, тем большее влияние они оказывают на экосистему, и, как следствие, тем больше финансовых потерь или профита могут получить игроки рынка. Поэтому во все большем количестве областей игроки адаптируются к работе ML-алгоритмов (классические примеры — реклама, поиск и уже упомянутый антиспам).
Также задачи машинного обучения обладают особенностью: любое, пусть и незначительное, изменение в системе может породить много работы с моделью: работа с данными, переобучение, деплой, что может затянуться на недели или месяцы. Поэтому чем быстрее меняется среда, в которой оперируют ваши модели, тем больше усилий требует их поддержка. Команда может создать множество систем и радоваться этому, а потом тратить почти все ресурсы на их поддержку, без возможности сделать что-то новое. С такой ситуацией мы как-то раз однажды столкнулись в команде антиспама. И сделали очевидный вывод, что сопровождение надо автоматизировать.
Automatiseerimine
Что можно автоматизировать? На самом деле почти всё. Я выделил четыре направления, определяющих инфраструктуру машинного обучения:
- сбор данных;
- дообучение;
- деплой;
- тестирование & мониторинг.
Если среда неустойчива и постоянно меняется, то вся инфраструктура вокруг модели оказывается гораздо важнее, чем сама модель. Это может быть старый добрый линейный классификатор, но если в него правильно подать признаки и наладить хорошую обратную связь от пользователей, то он будет работать гораздо лучше, чем State-Of-The-Art-модели со всеми наворотами.
Цикл обратной связи
Этот цикл объединяет в себе сбор данных, дообучение и деплой — по сути, весь цикл обновления модели. Почему это важно? Посмотрите на график регистрации в почте:
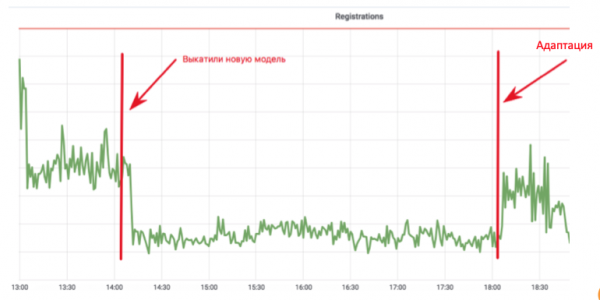
Разработчик машинного обучения внедрил модель антибота, которая не позволяет ботам регистрироваться в почте. График падает до значения, где остаются только реальные пользователи. Все замечательно! Но проходит четыре часа, ботоводы подкручивают свои скрипты, и все возвращается на круги своя. В данном внедрении разработчик потратил месяц, добавляя признаки и дообучая модель, но спамер за четыре часа смог адаптироваться.
Чтобы не было так мучительно больно и не пришлось потом всё переделывать, надо изначально думать о том, как будет выглядеть цикл обратной связи, и что мы будем делать, если среда изменится. Начнем со сбора данных — это топливо для наших алгоритмов.
Andmete kogumine
Понятно, что современным нейронным сетям чем больше данных, тем лучше, а их, по сути, генерируют пользователи продукта. Нам могут помогать пользователи, размечая данные, но злоупотреблять этим нельзя, потому что пользователям в какой-то момент им надоест доучивать ваши модели и они перейдут на другой продукт.
Одна из самых частых ошибок (здесь я делаю референс на Andrew Ng) — слишком сильная ориентация на метрики на тестовом датасете, а не на обратную связь от пользователя, что на самом деле является главным мерилом качества работы, так как мы создаем продукт для пользователя. Если пользователю непонятна или не нравится работа модели, значит всё тлен.
Поэтому пользователь всегда должен иметь возможность проголосовать, следует дать ему инструмент для обратной связи. Если мы считаем, что в ящик пришло письмо, относящееся к финансам, надо его пометить «финансы», и нарисовать кнопку, которую пользователь может нажать и сказать, что это не финансы.
Качество обратной связи
Поговорим о качестве пользовательского фидбэка. Во-первых, вы с пользователем можете вкладывать разный смысл в одно понятие. Например, вы с продакт-менеджерами считаете, что «финансы» — это письма из банка, а пользователь считает, что письмо от бабушки про пенсию тоже относится к финансам. Во-вторых, есть пользователи, которые бездумно любят жать на кнопки без всякой логики. В-третьих, пользователь может глубоко заблуждаться в своих выводах. Яркий пример из нашей практики — внедрение классификатора , весьма забавного типа спама, когда пользователю предлагается забрать несколько миллионов долларов у внезапно найденного дальнего родственника в Африке. После внедрения данного классификатора мы проверили клики «Не спам» на эти письма, и оказалось, что 80 % из них — сочный нигерийский спам, что говорит о том, что пользователи могут быть крайне доверчивы.
И не будем забывать, что по кнопкам могут тыкать не только люди, но и всякие боты, которые притворяются браузером. Так что сырая обратная связь не годится для обучения. Что можно сделать с этой информацией?
Мы применяем два подхода:
- Фидбэк от связанного ML. Например, у нас есть онлайн-система антибота, которая, как я уже упоминал, принимает быстрое решение на основе ограниченного количества признаков. И есть вторая, медленная система, работающая постфактум. Она имеет больше данных о пользователе, о его поведении и т.д. Как следствие, принимается наиболее взвешенное решение, соответственно она имеет выше точность и полноту. Можно направить разницу работы этих систем в первую как данные для обучения. Таким образом, более простая система будет всегда пытаться приблизиться к перформансу более сложной.
- Классификация кликов. Можно просто классифицировать каждый клик пользователя, оценивать его валидность и возможность использования. Мы так делаем в антиспаме почты, используя признаки пользователя, его историю, признаки отправителя, сам текст и результат работы классификаторов. В итоге получаем автоматическую систему, которая валидирует пользовательский фидбэк. И так как ее надо дообучать существенно реже, ее работа может стать основной для всех остальных систем. Основной приоритет в этой модели имеет precision, потому что обучать модель на неточных данных чревато последствиями.
Пока мы чистим данные и дообучаем наши ML-системы, нельзя забывать про пользователей, ведь для нас тысячи, миллионы ошибок на графике — это статистика, а для пользователя каждый баг — трагедия. Помимо того, что пользователю надо как-то жить с вашей ошибкой в продукте, он после обратной связи ожидает исключения подобной ситуации в будущем. Поэтому стоит всегда давать пользователям не только возможность голосовать, но и исправлять поведение ML-систем, создавая, к примеру, персональные эвристики на каждый клик обратной связи, в случае с почтой это может быть возможность фильтровать подобные письма по отправителю и заголовку для этого пользователя.
Также нужно на основе каких-нибудь отчётов или обращений в саппорт в полуавтоматическом или ручном режиме костылить модель, чтобы другие пользователи тоже не страдали от схожих проблем.
Эвристики для обучения
С данными эвристиками и костылями есть две проблемы. Первая заключается в том, что постоянно растущее количество костылей трудно поддерживать, не говоря уже об их качестве и работе на длинной дистанции. Вторая проблема состоит в том, что ошибка может быть не частотной, и нескольких кликов для дообучения модели будет недостаточно. Казалось бы, эти два не связанных эффекта можно существенно нивелировать, если применить следующий подход.
- Создаем временный костыль.
- Направляем данные с него в модель, она регулярно доучивается, в том числе на полученных данных. Здесь, разумеется, важно, чтобы эвристика имела высокую точность, чтобы не снижать качество данных в тренировочном сете.
- Затем вешаем мониторинг на срабатывание костыля, и если через какое-то время костыль больше не сработает и полностью покрывается моделью, то можно его смело удалять. Теперь эта проблема вряд ли повторится.
Так что армия костылей очень полезна. Главное, чтобы их служба была срочной, а не постоянной.
Дообучение
Дообучение — это процесс добавления новых данных, полученных в результате обратной связи от пользователей или других систем, и обучения существующей модели на них. С дообучением может быть несколько проблем:
- Модель может просто не поддерживать дообучение, а учиться только с нуля.
- Нигде в книге природы не написано, что дообучение непременно улучшит качество работы на продакшене. Часто случается как раз наоборот, то есть возможно только ухудшение.
- Изменения могут быть непредсказуемыми. Это достаточно тонкий момент, который мы выявили для себя. Даже если новая модель в А/В-тесте показывает схожие результаты по сравнению с текущей, это совсем не значит, что она будет работать идентично. Их работа может отличаться в каком-нибудь одном проценте, который может принести новые ошибки или вернуть уже исправленные старые. С текущими ошибками как мы, так и пользователи, уже умеем жить, и когда возникает большое количество новых ошибок, пользователь тоже может не понимать, что происходит, ведь он ожидает предсказуемого поведения.
Поэтому самое главное в дообучении — это гарантированно улучшать модель, или хотя бы не ухудшать ее.
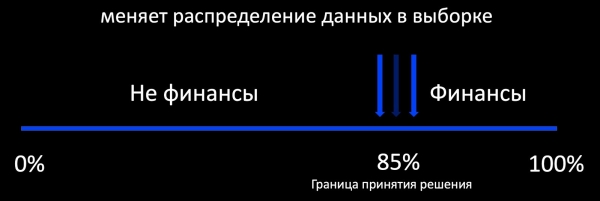
Первое, что приходит в голову, когда мы говорим про дообучение, это подход Active Learning. Что это означает? Например, классификатор определяет, относится ли письмо к финансам, и вокруг его границы принятия решения мы добавляем выборку из размеченных примеров. Это хорошо работает, например, в рекламе, где обратной связи очень много и можно обучать модель в онлайн-режиме. А если обратной связи мало, то мы получаем сильно смещенную выборку относительно продакшен распределения данных, на основе которой нельзя оценить поведение модели в процессе эксплуатации.
На самом деле наша цель — сохранить старые паттерны, уже известные модели, и приобрести новые. Здесь важна преемственность. Модель, которую мы часто с большим трудом выкатили, уже работает, поэтому можем ориентироваться на ее производительность.
В почте применяются разные модели: деревья, линейные, нейросети. Для каждой делаем свой алгоритм дообучения. В процессе дообучения у нас появляются не только новые данные, но и часто новые признаки, которые мы будем учитывать во всех алгоритмах ниже.
Линейные модели
Допустим, у нас логистическая регрессия. Составляем лосс модели из следующих компонентов:
- LogLoss на новых данных;
- регуляризуем веса новых признаков (старые не трогаем);
- учимся и на старых данных, чтобы сохранить старые паттерны;
- и, пожалуй, самое важное: навешиваем Harmonic Regularization, которая гарантирует не сильное изменение весов относительно старой модели по норме.
Поскольку у каждого компонента Loss есть коэффициенты, мы можем подобрать оптимальные для нашей задачи значения на кросс-валидации или исходя из продуктовых требований.
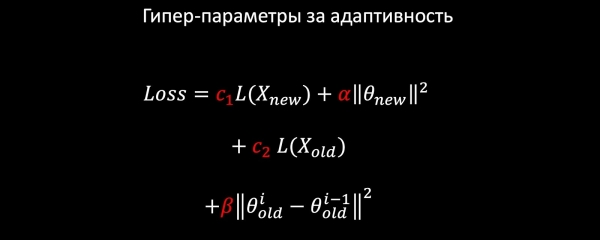
Деревья
Перейдем к деревьям решений. Мы запилили следующий алгоритм дообучения деревьев:
- На проде работает лес из 100—300 деревьев, который обучен на старом дата-сете.
- Удаляем в конце M = 5 штук и добавляем 2M = 10 новых, обученные на всём дата-сете, но с высоким весом у новых данных, что натурально гарантирует инкрементальное изменение модели.
Очевидно, что со временем количество деревьев сильно увеличивается, и их надо периодически сокращать, дабы укладываться в тайминги. Для этого используем вездесущий нынче Knowledge Distillation (KD). Коротко о принципе его работы.
- У нас есть текущая «сложная» модель. Запускаем ее на тренировочном дата-сете и получаем распределение вероятностей классов на выходе.
- Далее учим модель-ученика (модель с меньшим количеством деревьев в данном случае) повторять результаты работы модели, используя распределение классов как целевую переменную.
- Здесь важно отметить, что мы никак не используем разметку дата-сета, и поэтому можем использовать произвольные данные. Разумеется, мы используем сэмпл данных с боевого потока, как обучающую выборку для модели ученика. Таким образом, тренировочный сет позволяет нам обеспечивать точность модели, а сэмпл потока гарантирует схожий перформанс на продакшен-распределении, компенсируя смещение обучающей выборки.
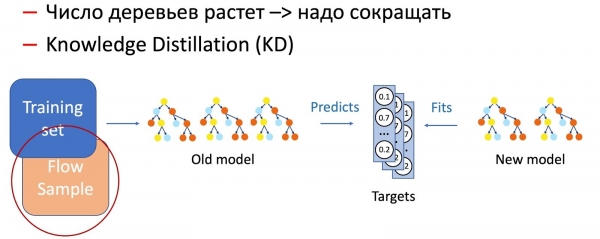
Сочетание этих двух методик (добавление деревьев и периодическое сокращение их количества с помощью Knowledge Distillation) обеспечивает введение новых паттернов и полную преемственность.
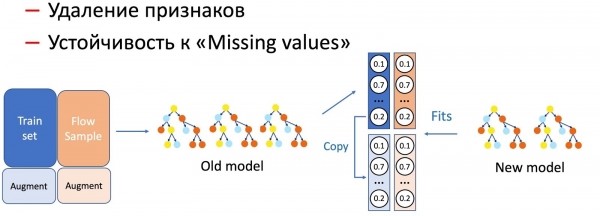
С помощью KD мы также выполняем различие операции с признаками модели, например, удаление признаков и работу на пропусках. В нашем случае у нас есть ряд важных статистических признаков (по отправителям, текстовым хешам, урлам и т.д.), которые хранятся в базе данных, имеющих свойство отказывать. К такому развитию событий модель, разумеется, не готова, так как в трейнинг-сете не встречается ситуаций отказа. В подобных случаях мы сочетаем техники KD и аугментации: при обучении для части данных мы удаляем или обнуляем необходимые признаки, а метки (выходы текущей модели) берем изначальные, модель-ученик учит повторять это распределение.
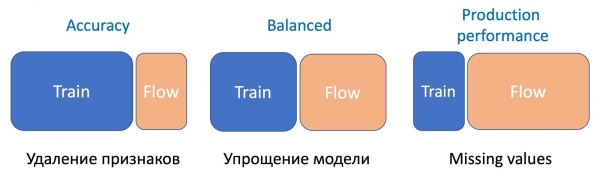
Мы заметили, что чем более серьезная манипуляция моделей происходит, тем больше в процентном соотношении требуется сэмла потока.
Для удаления признаков, самой простой операции, требуется лишь небольшая часть потока, так как изменяется всего лишь пара признаков, а текущая модель училась на том же сете — разница минимальна. Для упрощения модели (снижение количества деревьев в несколько раз) требуется уже 50 на 50. А на пропуски важных статистических признаков, которые серьезно аффектят перфоманс модели, требуется еще больше потока, чтобы выровнять работу новой устойчивой к пропускам модели на всех типах писем.
FastText
Перейдем к FastText. Напомню, что представление (Embedding) слова состоит из суммы embedding’а самого слова и всех его буквенных N-gram, обычно триграмм. Так как триграмм может быть достаточно много, используется Bucket Hashing, то есть преобразование всего пространства в некий фиксированный хэшмэп. В итоге матрица весов получается размерностью внутреннего слоя на количество слов + бакетов.
При дообучении возникают новые признаки: слова и триграммы. В стандартном дообучении от Facebook ничего существенного не происходит. Дообучаются только старые веса с кросс-энтропией на новых данных. Таким образом, новые признаки не используются, разумеется, этот подход обладает всеми вышеописанными недостатками, связанными с непредсказуемостью модели на продакшене. Поэтому мы немного доработали FastText. Добавляем все новые веса (слова и триграммы), доучиваем всю матрицу с кросс-энтропией и добавляем гармоническую регуляризацию по аналогии с линейной моделью, которая гарантирует несущественное изменение старых весов.

CNN
Со сверточными сетями несколько сложнее. Если в CNN доучиваются последние слои, то, разумеется, можно применять гармоническую регуляризацию и гарантировать преемственность. Но в том случае, если требуется дообучение всей сети, то такую регуляризацию уже не навесишь на все слои. Однако есть вариант с обучением комплиментарных эмбеддингов через Triplet Loss ().
Triplet Loss
На примере задачи антифишинга разберем в общих чертах Triplet Loss. Берем наш логотип, а также позитивные и негативные примеры логотипов других компаний. Минимизируем расстояние между первыми и максимизируем расстояние между вторыми, делаем это с небольшим зазором, чтобы обеспечить большую компактность классов.
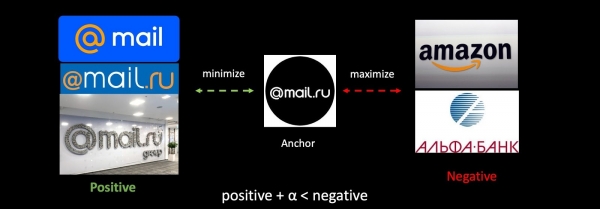
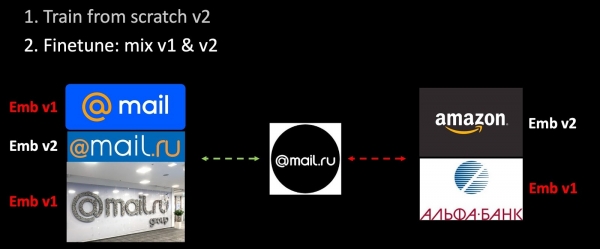
Если мы дообучаем сеть, то у нас полностью меняется метрическое пространство, и оно становится абсолютно несовместимым с предыдущим. Это серьезная проблема в задачах, использующих векторы. Чтобы обойти эту проблему, будем подмешивать во время обучения старые эмбеддинги.
Мы добавили новые данные в трейнинг-сет и с нуля обучаем вторую версию модели. На втором этапе мы дообучаем нашу сеть (Finetuning): сначала доучивается последний слой, а потом размораживается вся сеть. В процессе составления триплетов лишь часть эмбеддингов вычисляем с помощью обучаемой модели, остальные — с помощью старой. Таким образом, в процессе дообучения мы обеспечиваем совместимость метрических пространств v1 и v2. Своеобразный вариант гармонической регуляризации.
Архитектура целиком
Если рассматривать всю систему целиком на примере антиспама, то модели не изолированы, а вложены друг в друга. Берем картинки, текст и прочие признаки, с помощью CNN и Fast Text получаем эмбеддинги. Далее поверх эмбеддингов применяются классификаторы, которые выдают скоры для различных классов (типы писем, спама, наличие логотипа). Скоры и признаки уже попадают в лес деревьев на принятие финального решения. Отдельные классификаторы в этой схеме позволяют лучше интерпретировать результаты работы системы и более прицельно дообучать компоненты в случае возникновения проблем, нежели чем в сыром виде подавать все данные в деревья решений.
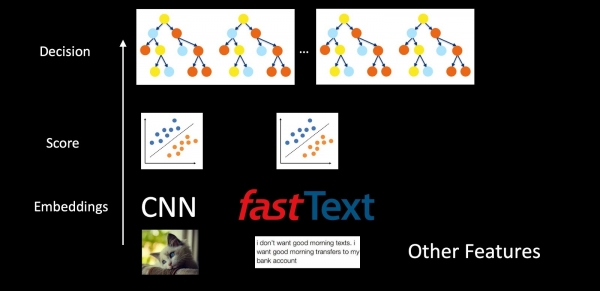
В итоге мы гарантируем преемственность на каждом уровне. На нижнем уровне в CNN и Fast Text мы используем гармоническую регуляризацию, для классификаторов в середине — также гармоническую регуляризацию и калибровку скора для совместимости распределения вероятности. Ну а бустинг деревьев обучается инкрементально или с помощью Knowledge Distillation.
В целом поддержка такой вложенной системы машинного обучения обычно представляет боль, так как любой компонент на нижнем уровне ведет к обновлению всей системы выше. Но так как в нашем сетапе каждый компонент меняется незначительно и он совместим с предыдущим, то вся система может обновляется по кусочкам без нужды переобучать всю структуру, что и позволяет поддерживать ее без серьезного оверхеда.
Juhtimistöö
Мы разобрали сбор данных и дообучение разных типов моделей, поэтому переходим к их деплою в продакшен среду.
А/B-тестирование
Как я говорил ранее, в процессе сбора данных мы, как правило, получаем смещенную выборку, по которой невозможно оценить продакшен-перфоманс модели. Поэтому при развертывании модель обязательно нужно сравнивать с предыдущей версией, чтобы понимать, как на самом деле идут дела, то есть проводить A/B-тесты. На самом деле процесс выкатки и анализ графиков достаточно рутинный и прекрасно поддается автоматизации. Мы выкатываем наши модели постепенно на 5 %, на 30 %, на 50 % и на 100 % пользователей, при этом собирая все доступные метрики по ответам модели и фидбэку пользователей. В случае каких-то серьезных выбросов мы автоматически откатываем модель, а для остальных случаев, набрав достаточное количество кликов пользователей, принимаем решение о повышении процента. В итоге доводим новую модель до 50 % пользователей полностью автоматически, а выкатку на всю аудиторию аппрувит человек, хотя и этот шаг можно автоматизировать.
Однако процесс A/B-тестов представляет простор для оптимизации. Дело в том, что любой A/B-тест достаточно длительный (в нашем случае он занимает от 6 до 24 часов в зависимости от количества фидбека), что делает его довольно дорогим и с ограниченными ресурсами. Помимо этого требуется достаточно высокий процент потока для теста, чтобы по сути ускорить общее время А/B-теста (набирать статистически значимую выборку для оценки метрик на малом проценте можно очень долго), что делает количество A/B-слотов крайне ограниченным. Очевидно, что нам нужно выводить в тест только самые перспективные модели, коих в процессе дообучения мы получаем весьма много.
Для решения этой задачи мы обучили отдельный классификатор, предсказывающий успешность A/B-теста. Для этого в качестве признаков берем статистику принятия решений, Precision, Recall и прочие метрики на обучающем множестве, на отложенном и на сэмпле с потока. Также сравниваем модель с текущей на продакшене, с эвристиками, и берем в расчет сложность (Complexity) модели. Используя все эти признаки, обученный на истории тестов классификатор скорит модели-кандидаты, в нашем случае это леса деревьев, и принимает решение, какой из них пустить в A/B-тест.
В момент внедрения этот подход позволил в несколько раз увеличить количество успешных A/B-тестов.
Тестирование & мониторинг
Тестирование и мониторинг, как ни странно, не вредят нашему здоровью, скорее, наоборот, улучшают и избавляют от лишних стрессов. Тестирование позволяет предотвратить сбой, а мониторинг — вовремя обнаружить его, чтобы уменьшить влияние на пользователей.
Здесь важно понимать, что рано или поздно ваша система всегда будет ошибаться — это связано с циклом разработки любого софта. В начале разработки системы всегда много багов до тех пор, пока всё не устаканится и не завершится основной этап нововведений. Но со временем энтропия берет своё, и снова появляются ошибки — из-за деградации компонентов вокруг и изменения данных, о чем я говорил вначале.
Здесь я хотел бы отметить, что любую систему машинного обучения надо рассматривать с точки зрения её профита в течение всего жизненного цикла. Ниже на графике показан пример работы системы по отлову редкого вида спама (на графике линия в районе нуля). Однажды из-за неправильно закэшированного признака она сошла с ума. Как назло, не было мониторинга на аномальное срабатывание, в результате система начала сохранять письма в папку «спам» на границе принятия решения в большом количестве. Несмотря на исправление последствий, система уже столько раз ошиблась, что не окупит себя и за пять лет. А это полный провал с точки зрения жизненного цикла модели.
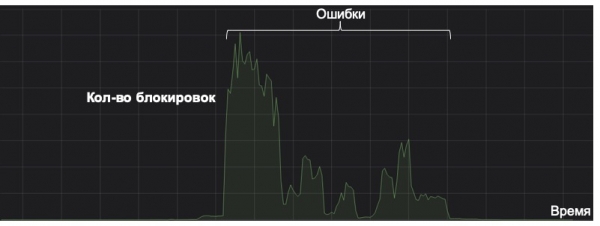
Поэтому такая простая вещь как мониторинг может стать ключевой в жизни модели. Помимо стандартных и очевидных метрик, мы считаем распределение ответов и скоров модели, а также распределение значений ключевых признаков. С помощью KL-дивергенции мы можем сравнить текущее распределение с историческим или значения на A/B-тесте с остальными потоком, что позволяет замечать аномалии в модели и вовремя откатывать изменения.
В большинстве случаев мы запускаем наши первые версии систем с помощью простых эвристик или моделей, которые в будущем используем в качестве мониторинга. Например, мониторим NER-модель по сравнению с регулярками для конкретных интернет-магазинов, и если покрытие классификатора просаживается по сравнению с ними, то разбираемся в причинах. Еще одно полезное применение эвристик!
Kokkuvõte
Пройдёмся еще раз по ключевым мыслям статьи.
- Фибдэк. Всегда думаем про пользователя: как он будет жить с нашими ошибками, как сможет сообщить о них. Не забываем, что пользователи — не источник чистого фидбэка для обучения моделей, и его необходимо прочищать с помощью вспомогательных ML-систем. Если нет возможности собрать сигнал от пользователя, то ищем альтернативные источники фидбэка, например, связанные системы.
- Дообучение. Здесь основное — это преемственность, поэтому опираемся на текущую продакшен-модель. Новые модели обучаем так, чтобы они не сильно отличались от предыдущей за счет гармонической регуляризации и подобных трюков.
- Juhtimistöö. Автодеплой по метрикам сильно сокращает время на внедрение моделей. Мониторинг статистики и распределения принятия решений, количества фолзов от пользователей обязателен для вашего спокойного сна и продуктивных выходных.
Что ж, надеюсь, что прочитанное поможет вам быстрее улучшать ваши ML-системы, ускорять их вывод на рынок и делать их более надежными, снижая количество стресса от работы.
Allikas: habr.com
