

Kuna SAP pakub täielikku tarkvarakomplekti nii tehingute andmete haldamiseks kui ka nende töötlemiseks analüüsi ja aruandluse süsteemides, siis SAP Business Warehouse (SAP BW) platvorm pakub tööriistu andmete salvestamiseks ja analüüsimiseks, millel on suured tehnilised võimalused. Kõikides oma objektiivsetes eelistes on SAP BW-l üks märkimisväärne puudus: andmete salvestamise ja töötlemise kõrge hind, mis on eriti silmatorkav Cloud SAP BW on Hana kasutamisel.
Aga mis siis, kui ladustamisruumina hakata kasutama mõnda non-SAP ja eelistatult avatud lähtekoodiga toodet? Me X5 Retail Group-is valisime GreenPlumi. See lahendab kindlasti hinna küsimuse, kuid samas kerkivad esile küsimused, mis SAP BW kasutamisel lahendati praktiliselt vaikimisi.

Kuidas siis andmeid allikate süsteemidest, mis enamikul juhtudest on SAP lahendused, kätte saada?
„HR-metrikud“ sai esimeseks projektiks, kus tuli lahendada see probleem. Meie eesmärgiks oli luua HR-andmete püsiv arhiiv ja koostada analüütiline aruandlus töötajatega suhtlemise suunal. Peamine andmeallikas on SAP HCM tehingusüsteem, kus toimub kõik personaliga seotud, organisatsioonilised ja palgatoimingud.
Andmete ekstrapoleerimine
SAP BW-s on olemas standardiseeritud andmete ekstrapolaatorid SAP-süsteemide jaoks. Need ekstrapolaatorid võivad automaatselt koguda vajalikke andmeid, jälgida nende terviklikkust ja tuvastada muudatuste deltaid. Näiteks standardne andmeallikas töötaja atribuutide jaoks on 0EMPLOYEE_ATTR:
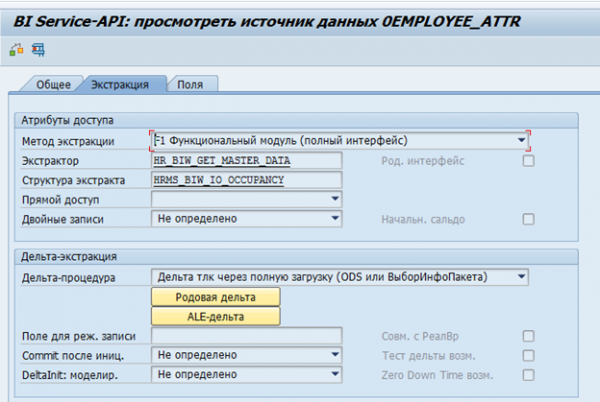
Andmete ekstrapoleerimise tulemus ühe töötaja kohta:
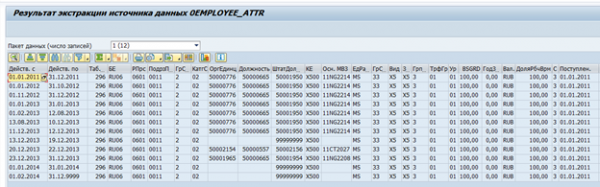
Vajadusel võib sellist ekstrapolaatorit kohandada vastavalt enda nõudmistele või luua täiesti oma ekstrapolaator.
Esimene idee oli nende uuesti kasutamise võimalus. Kahjuks osutus see võimatuks ülesandeks. Suur osa loogikast on teostatud SAP BW poolel, ja ekstrapolaatorit allikast SAP BW-st valutult eraldada ei õnnestunud.
On selge, et on vajalik arendada oma andmeväljavõtu mehhanismi SAP süsteemidest.
Andmete salvestamise struktuur SAP HCM-is
Nõuete mõistmiseks tuleb esmalt määratleda, milliseid andmeid me täpselt vajame.
Enamiku andmete puhul on SAP HCM-is need salvestatud tasapinnalistes SQL tabelites. Nende andmete põhjal visualiseerivad SAP rakendused kasutajale organisatsioonistruktuuri, töötajad ja muud personaliteavet. Näiteks näeb SAP HCM organisatsioonistruktuur välja järgmine:
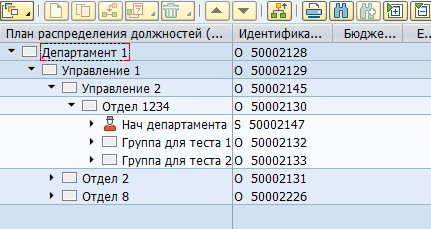
Füüsiliselt hoitakse seda puu kahes tabelis — hrp1000 objektid ja hrp1001 nende objektidevahelised seosed.
Objektid „Osakond 1” ja „Juhtimine 1”:

Suhe objektide vahel:

Objektide tüüpide ja nendevaheliste suhete tüüpide arv võib olla tohutu. On olemas nii standardsed seosed objektide vahel kui ka kohandatud, et rahuldada spetsiifilisi vajadusi. Näiteks viitab standardne seos B012 organisatsiooniüksuse ja ametikoha vahel osakonna juhile.
Juht positsioonis SAP-is:
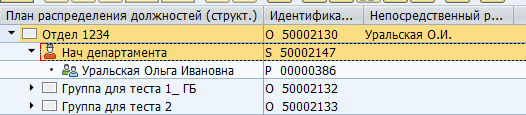
Salvestamine andmebaasitabelis:

Töötajate andmed säilitatakse tabelites pa*. Näiteks töötaja kaadriga seotud sündmuste andmed säilitatakse tabelis pa0000.
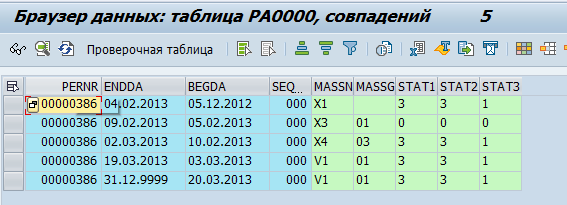
Oleme otsustanud, et GreenPlum tõmbab "toored" andmed, st kopeerib need lihtsalt SAP tabelitest. Ja GreenPlumis töödeldakse ja muudetakse need füüsiliste objektideks (näiteks Osakond või Töötaja) ning metrikateks (näiteks keskmine loendatav arv).
On määratud umbes 70 tabelit, mille andmed tuleb edastada GreenPlumisse. Pärast seda hakkasime välja töötama nendest andmetest edastamise viisi.
SAP pakub piisavalt palju integratsiooni mehhanisme. Kuid kõige lihtsam viis – otse andmebaasi ligipääs on litsentsipiirangute tõttu keelatud. Seega peavad kõik integratsioonivoogud olema teostatavad tasemel serverile rakendused.
Järgmine probleem oli andmete puudumine eemaldatud kirjetest SAP andmebaasis. Kui rida andmebaasis kustutatakse, siis see kustutatakse füüsiliselt. St muutuste delta ajas määramine ei olnud võimalik.
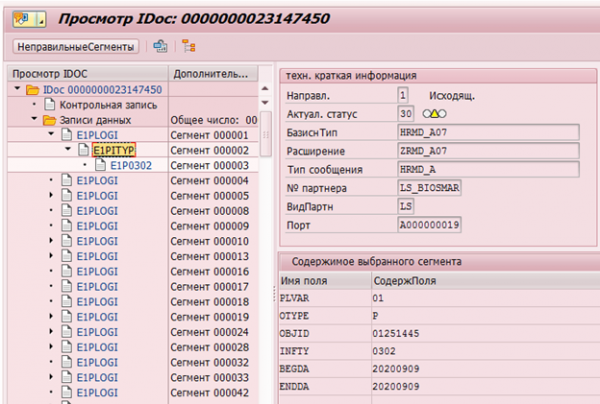
Muidugi, SAP HCM-is on andmete muudatuste fikseerimiseks mehhanismid. Näiteks edastamiseks sihtsüsteemidesse on olemas muudatusnäidikud (change pointer), mis fikseerivad kõik muudatused ja mille alusel luuakse Idoc (väline süsteemide edastamise objekt).
Näide IDoc muutusest infotypis 0302 töötaja, kelle personalinumber on 1251445:
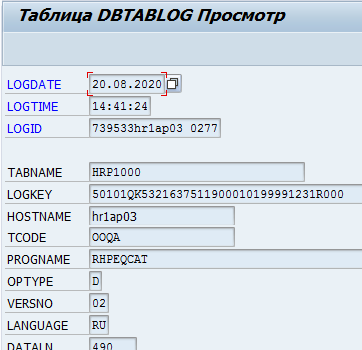
Või andmete muudatuste logimine DBTABLOG tabelis.
Näide muudatuslogistole, kus eemaldatakse kirje, mille võti on QK53216375 tabelist hrp1000:
Kuid need mehhanismid ei ole kõikide vajalike andmete jaoks saadaval ning nende töötlemine rakendusserveri tasandil võib võtta piisavalt palju ressursse. Seetõttu võib massiline logimise aktiveerimine kõigile vajalikele tabelitele viia süsteemi jõudluse märgatava halvenemiseni.
Järgmine tõsine probleem olid klastritabelid. Aja hindamise ja palga arvutamise andmed SAP HCM RDBMS versioonis salvestatakse igale töötajale igas arvestuses loogiliste tabelite komplektina. Need loogilised tabelid salvestatakse binaandatatena tabelis pcl2.
Palga arvutamise klaster:
Klastri tabelite andmeid ei saa lugeda SQL-käsuga, vaid on vajalik kasutada SAP HCM makrokäsku või spetsiaalseid funktsionaalseid mooduleid. Seetõttu on selliste tabelite lugemise kiirus üsna madal. Teisest küljest sisaldavad sellised klastrid andmeid, mida on vaja vaid kord kuus — palgaarvestuse ja ajahindamise tulemused. Seega ei ole kiirus sel juhul nii kriitiline.
Hinnates andmeid muutuste delta genereerimise võimalusi, otsustasime samuti kaaluda täieliku eksportimise varianti. Iga päev gigabaitide muutumatute andmete edastamine süsteemide vahel ei saa hea välja näha. Siiski on sel ka mitmeid eeliseid – ei ole vaja rakendada delta loomist allika poolel ega ka selle delta integreerimist sihtkohas. Seega vähenevad kulud ja teostamise ajad ning suurenevad integratsiooni usaldusväärsus. Selgus, et peaaegu kõik muudatused SAP HR-is toimuvad kolme kuu jooksul enne praegust kuupäeva. Seega otsustati, et jääme SAP HR-i andmete igapäevasele täielikule eksportimisele N kuud enne praegust kuupäeva ja kuu aega korrapärasele täielikule eksportimisele. Parameeter N sõltub konkreetsest tabelist.
ja kõigub vahemikus 1 kuni 15.
Andmete väljatõmbamiseks pakuti välja järgmine skeem:

Väliselt süsteemilt saadetakse päring SAP HCM-i, kus see kontrollitakse andmete täpsuse ja tabelitele juurdepääsu õiguste osas. Eduka kontrolli korral käivitub SAP HCM-is programm, mis kogub vajalikud andmed ja edastab need Fuse integreerimislahendusele. Fuse määrab Kafka teema ja edastab andmed sinna. Seejärel edastatakse andmed Kafka-st Stage Area GP-sse.
Meid huvitab selles ahelas andmete väljavõtmise küsimus SAP HCM-ist. Vaatame sellele lähemalt.
SAP HCM-FUSE koostöö skeem.
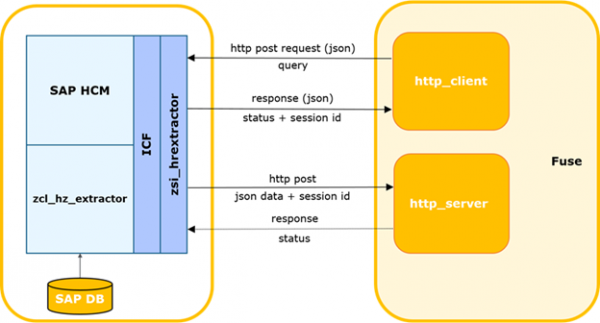
Välises süsteemis määratakse SAP-i viimane eduka päringu aeg.
Protsessi võib käivitada ajastuse või muu sündmuse põhjal; sealhulgas võib seada ajavahemiku vastuse ootamiseks SAP-ilt ja re-päringu algatamise. Pärast seda koostatakse delta-päring ja saadetakse SAP-ile.
Päringu andmed edastatakse body-s json formaadis.
HTTP meetod: POST.
Küsimuse näidis:

SAP teenus kontrollib päringu täpsust, vastavust SAP-i praegusele struktuurile ja juurdepääsulubade olemasolu taotletud tabelile.
Vigade korral tagastab teenus vastuse koos vastava koodi ja kirjeldusega. Eduka kontrolli korral loob see taustaprotsessi andmete kogumise jaoks, genereerib ja sünkroonselt tagastab ainulaadse seansi ID.
Väline süsteem registreerib vea korral selle logisse. Eduka vastuse korral edastab seansi ID ja tabeli nime, mille põhjal päring tehti.
Väline süsteem registreerib käesoleva seansi avatud seisundisse. Kui antud tabeli kohta on teisi seansse, suletakse need koos hoiatuse registreerimisega logisse.
SAP-i taustaprotsess genereerib kursori antud parameetrite alusel ja määratud suurusega andmepaketi. Andmepaketi suurus on maksimaalne arv kirjeid, mida protsess loeb andmebaasist. Vaikimisi on see 2000. Kui andmebaasi valikus on rohkem kirjeid kui kasutatav paketi suurus, pärast esimese paketi edastamist genereeritakse järgmine plokk vastava offset'i ja inkrementeeritud paketi numbriga. Nummerdatakse järjestikku, tõustes 1 võrra.
Edasi saadab SAP paketi välise süsteemi veebiteenusele. See süsteem viib läbi sisenemise paketi kontrolle. Süsteemis peab olema registreeritud seanss saadud id-ga ning see peab olema avatud olekus. Kui paketi number on > 1, peab süsteemis olema registreeritud eelmise paketi (package_id-1) eduka vastuvõtu tõend.
Eduka kontrolli korral parsimis ja salvestatakse tabeli andmed välises süsteemis.
Lisaks, kui paketis on olemas final lipp ja serialiseerimine õnnestus, toimub integreerimismooduli teavitamine seansi töötlemise eduka lõpetamise kohta ning moodul uuendab seansi staatust.
Vigade korral logitakse kontrollimise/parsimise tõrge ning pakette selle seansi osas välised süsteemid lükatakse tagasi.
Sama kehtib ka vastupidisel juhul, kui väline süsteem tagastab vea; see logitakse ja paketivahetus lõpetatakse.
SAP HCM poole andmete päringuks on loodud integreerimisteenus. Teenus on loodud ICF (SAP Internet Communication Framework) raamistiku põhjal — ). See võimaldab teha andmepäringuid SAP HCM süsteemist teatud tabelite järgi. Andmepäringu koostamisel on võimalik määrata kindel valik välju ja filtreerimise parameetreid, et saada vajalikke andmeid. Samas ei eelda teenuse rakendamine mingit äriloogikat. Deltakalkulatsioonide, päringu parameetrite, terviklikkuse kontrolli jms algoritmid rakendatakse samuti välises süsteemis.
Käesolev mehhanism võimaldab koguda ja edastada kõik vajalikud andmed mõne tunni jooksul. Selline kiirus on piiri peal ja sellepärast peame seda lahendust ajutiseks, mis rahuldas projekti andmeekstraktsiooni vajaduse.
Sihtvisioonis andmete ekstraktsiooni ülesande lahendamiseks kaalume CDC süsteemide, nagu Oracle Golden Gate, või ETL tööriistade, nagu SAP DS, kasutamise võimalusi.
Allikas: habr.com
