

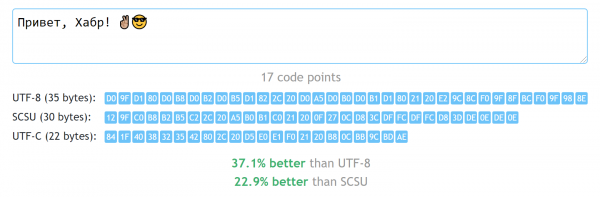
Kui olete arendaja ja seisate silmitsi kodeeringu valimise ülesandega, on peaaegu alati õige valik Unicode. Konkreetne esitusviis sõltub kontekstist, kuid sagedamini on ka siin universaalne vastus — UTF-8. See on hea, kuna võimaldab kasutada kõiki Unicode'i sümboleid, raiskamata liialt paljusid baite enamikul juhtudel. Tõsi, keelte puhul, mis ei kasuta ainult ladina tähestikku, tähendab „liialt vähe” vähemalt kahte baiti sümboli kohta. Kas on võimalik paremini, naasmata ajaloolistele kodeeringutele, mis piiravad meid vaid 256 saadaval sümboliga?
Allpool pakun välja oma katse sellele küsimusele vastata ja suhet suhteliselt lihtsa algoritmiga, mis võimaldab säilitada ridu enamustes maailma keeltes, lisamata seda üleliigsust, mis on UTF-8-s.
Distsipliin. Teen kohe mitmeid olulisi täiendusi: kirjeldatud lahendust ei pakuta kui universaalset asendust UTF-8-le., see sobranči, et sobranči sobranči mogą być używane do interakcji z pomocami API (o nim i niczym innym). Najczęściej do kompaktowego przechowywania dużych objętości danych tekstowych odpowiednie są algorytmy kompresji ogólnego celu (np. deflate). Ponadto, już przy tworzeniu rozwiązania odkryłem istniejący standard w samym Unicode, który rozwiązuję tę samą sytuację — jest on nieco bardziej skomplikowany (i czasami gorszy), ale nadal jest przyjętym standardem, a nie wykonanym na kolanie. O nim również opowiem.
Unicode i UTF-8
Najpierw — kilka słów o tym, czym w ogóle jest Unicode ja UTF-8.
Nagu teame, olid enne populaarseid 8-bitised kodeeringud. Nendega oli kõik lihtne: 256 sümbolit saab nummerdada numbritega 0 kuni 255, ja numbrid 0 kuni 255 on ilmselgelt esitatavad ühe baitina. Kui tagasi minna algusesse, siis ASCII kodeering piirab end 7 bitiga, seega on tema baitide esitlemine kõige vanemas bitis null ja enamus 8-bitiseid kodeeringud on temaga ühilduvad (need erinevad ainult "ülemises" osas, kus vanim bitt on üksteist).
Kuidas erineb Unicode neist kodeeringutest ja miks sellega seondub korraga mitmeid konkreetseid esitusi — UTF-8, UTF-16 (BE ja LE), UTF-32? Uurime järjekorras.
Unicode'i põhistandart kirjeldab ainult seoseid sümbolite vahel (ja mõnel juhul — sümbolite eraldi komponentide) ja nende numbrite vahel. Ja võimalikke numbreid selles standardis on väga palju — alates 0x00 kuni 0x10FFFF (1 114 112 tükki). Kui sooviksime panna sellises vahemikus oleva numbri muutujasse, ei piisaks meil 1 või 2 baitist. Ja kuna meie protsessorid ei ole hästi kohandatud kolmbaitsete numbrite töötlemiseks, oleksime sunnitud kasutama ühe sümboli jaoks koguni 4 baidi! See ongi UTF-32, kuid just selle „ülemäärasuse” tõttu ei ole see formaat populaarne.
Õnneks on Unicode'i sümbolid paigutatud mitte juhuslikult. Nende hulk on jagatud 17 „tasandit”, millest igaühes on 65 536 (0x10000) «koodipunkti). Mõiste „koodipunkt” siin on lihtsalt sümboli numbri, mille Unicode on talle määranud. Kuid nagu eelnevalt öeldud, on Unicode'is nummerdatud mitte ainult üksikud sümbolid, vaid ka nende komponentsed ja teenindavad märgid (ja mõnikord ei vasta number üldse millele — võib-olla ajutiselt, kuid meie jaoks ei ole see niivõrd oluline), seega on korrektsem alati rääkida just numbri summast, mitte sümbolitest. Siiski, edaspidi kasutan tihti sõna „sümbol”, mõeldes selle all mõistet „koodipunkt”.
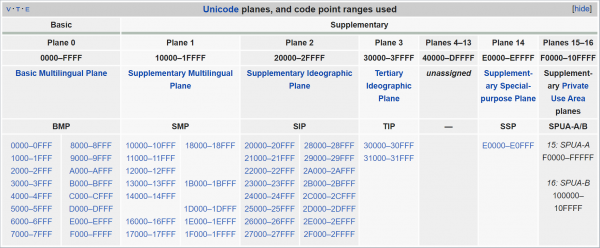
Unicode'i tasandid. Nagu näha, on suur osa (tasandid 4 kuni 13) endiselt kasutamata.
Mis on kõige tähelepanuväärsem - kogu peamine "sisu" asub nulltasemel, mida nimetatakse "Põhiline mitmekeelne tasand". Kui rida sisaldab teksti mõnes kaasaegses keeles (sealhulgas hiina keeles), ei pääse te sellest tasemest välja. Kuid ei saa ka ülejäänud Unicode'i osa ära jätta - näiteks asuvad emodžid enamasti järgmise tasandi lõpus, "Täiendav mitmekeelne tasand" (see ulatub alates 0x10000 kuni 0x1FFFF). Seega käitub UTF-16 järgmiselt: kõik sümbolid, mis jäävad Põhiline mitmekeelne tasand, kodeeritakse "nagu on", vastavatesse kahebaidistesse numbritesse. Kuid osa numbrid sellest vahemikust ei tähista üldse kindlaid sümboleid, vaid näitavad, et pärast seda kahebaidist paari tuleb arvestada veel ühe - kombineerides nende nelja baidi väärtused, saame numbri, mis katab kogu lubatud Unicode'i vahemiku. Tegu on representatsiooniga, mida nimetatakse "sümpaatilisteks paarideks" - võib-olla olete neist kuulnud.
Nii et, UTF-16 vajab ühe "koodipunkti" jaoks kahte või (väga harvadel juhtudel) nelja bitti. See on parem kui pidevalt neli bitti kasutada, kuid ladina tähed (ja teised ASCII-sümbolid) sellise kodeerimise korral kulutavad pool ruumist nullidele. UTF-8 on seda parandama loodud: ASCII-s kasutatakse selles nagu varem ainult ühte bitti; koodid on 0x80 kuni 0x7FF — kaks bitti; 0x800 kuni 0xFFFF — kolm, ja 0x10000 kuni 0x10FFFF — neli. Ühelt poolt on ladina keele puhul kõik hästi: ASCII ühilduvus on naasnud ning jaotus on nüüd ühtlasemalt "jaotatud" ühest neljale bitile. Kuid ladina keelest erinevad tähed ei suuda võrreldes UTF-16-ga paremini hakkama saada, ning paljud vajavad nüüd hoopis kolme bitti kahe asemel — kahebitise salvestuse katteala on kitsenenud 32 korda, alates 0xFFFF kuni 0x7FF, ning sinna ei mahu enam ei hiina ega näiteks grusiini keel. Kirillitsa ja veel viiest tähest — rõõm — on õnnestunud, 2 bitti sümboli kohta.
Kuidas see nii on? Vaatame, kuidas UTF-8 esindab sümbolite koode:

Otse numbrite esitlemiseks on siin kasutatud bitte, mis on tähistatud sümboliga x. On nähtav, et kaheastmelises salvestuses on selliseid bite vaid 11 (16-st). Esimesed bitid täidavad siin ainult teenusfunktsiooni. Neljavalugarenguga salvestamise puhul on koodipunktile määratud tervelt 21 bitti 32-st — näiliselt piisaks siinkohal kolmest baitist (mis annavad kokku 24 bitti), kuid teenindusmärgid neelavad liiga palju.
Kas see on halb? Tegelikult ei ole. Ühelt poolt – kui me tõeliselt hoolime ruumist, on meil olemas kokkusurutuse algoritmid, mis suudavad kergesti eemaldada kogu liigse entropia ja üleliigse teabe. Teiselt poolt oli Unicode'i eesmärk pakkuda võimalikult universaalset kodeerimist. Näiteks saame UTF-8 kodeeritud stringi usaldada koodi, mis enne töötas ainult ASCII-ga, ja ei pea kartma, et seal on ASCII vahemikust pärit märk, mida seal tegelikult ei ole (sest UTF-8-s on kõik baitid, mis algavad nullbitiga, just need ASCII baitid). Ja kui soovime äkki suurtest stringidest väikest osa ära lõigata, ilma et peaksime seda algusest dešifreerima (või taastama osa teavet pärast kahjustatud osa) – ei ole meil keeruline leida offset, kus mõni märk algab (piisab, kui vahele jätta baitidega, millel on bitiprefiks). 10).
Miks siis midagi uut välja mõelda?
Samas on aeg-ajalt olukordi, kus peale kokkusurumise algoritmide nagu deflate ei ole head rakendust, kuid tahame stringe tihedalt salvestada. Isiklikult olen sellise probleemiga silmitsi seisnud, mõeldes suure sõnavara jaoks, mis sisaldab sõnu mitmesugustes keeltes. Ühest küljest on iga sõna väga lühike, seega selle kokkusurumine ei ole efektiivne. Teisest küljest, puu rakendamine, mida ma kaalusin, oli mõeldud selliseks, et iga salvestatud stringi bait genereeris eraldi puu tipu, nii et nende arvu minimeerimine oli väga kasulik. Minu raamatukogus (nagu ka , millel see põhineb) lahendatakse sarnane probleem lihtsalt – stringid, mis on pakitud -sõnaraamatuks, hoitakse seal . Kuid, nagu ei ole raske mõista, toimib see hästi ainult piiratud tähestiku puhul – sellesse sõnaramatusse ei saa enam hiina keeli rida kokku panna.
Erakordselt märgin veel ühte ebameeldivat nüanssi, mis tekib UTF-8 kasutamisel sellises andmestruktuuris. Ülaloleval pildil on näha, et kui sümboli kirjutamisel kasutatakse kahte bait, ei ole tema numbrile kuuluvad bitid järjestikused, vaid katkenud paarist biit 10 keskel: 110xxxxx 10xxxxxx. Selle tulemusena, kui teise baiti madalamad 6 bitti sümboli koodis üle voolavad (st toimub üleminek 10111111 → 10000000), muutub ka esimene bait. Selgub, et täht 'п' tähistatakse baitidega 0xD0 0xBF, ja järgnev «r» — on juba 0xD1 0x80. Eelmises puu struktuuris tähendab see vanema sõlme jagunemist kaheks — üheks eelseisva jaoks 0xD0, ja teiseks 0xD1 (kuigi kogu kirillitsa saaks kodeerida ainult teise baitiga).
Mis mul välja tuli
Kuna silmitsi seisain selle ülesandega, otsustasin veidi harjutada bitimängude abil ning tutvuda ka Unicode'i struktuuriga kui sellisega. Tulemuseks sai kodeerimisvorming UTF-C («C» tuleneb kompaktne), mis ei kuluta rohkem kui 3 baiti ühe koodipunkti kohta ja võimaldab tihti kulutada vaid ühe lisabaiti kogu kodeeritud rida. See toob kaasa, et paljude mitte-ASCII tähestike puhul osutub selline kodeerimine 30-60% kompaktsemaks kui UTF-8.
Olen väljendanud kodeerimise ja dekodeerimise algoritmide näiteid , võite neid oma koodis vabalt kasutada. Kuid siiski rõhutaksin, et mõnes mõttes jääb see formaat «rataste leiutamiseks», ja ma ei soovita seda kasutada ilma teadmiseta, milleks see teile vajalik on. See, see, it's more of an experiment than a serious 'improvement of UTF-8'. Nevertheless, the code is written neatly, concisely, with a large number of comments and test coverage.
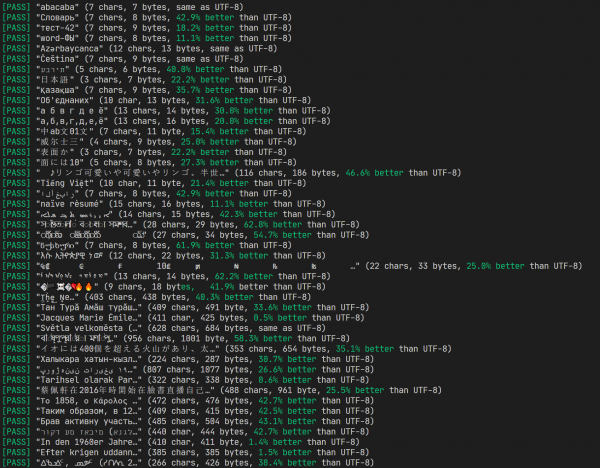
Test results and comparison with UTF-8
I also created , where you can evaluate the algorithm's performance, and then I will explain its principles and development process in more detail.
Eliminating redundant bits
I based it on UTF-8, of course. The first and most obvious thing we can change is to reduce the number of control bits in each byte. For example, the first byte in UTF-8 always starts either with 0, or with 11 — and the prefix 10 is only present in the following bytes. Let's replace the prefix 11 järgnevaga 1, and completely remove the prefixes from the subsequent bytes. What will we get?
0xxxxxxx — 1 byte
10xxxxxx xxxxxxxx — 2 bytes
110xxxxx xxxxxxxx xxxxxxxx — 3 bytes
Wait, but where is the four-byte representation? It's no longer needed — with a three-byte representation we now have access to 21 bits, which is more than enough for all numbers up to 0x10FFFF.
Mida me siin ohverdasime? Peamine on, et me ei suuda leida sümbolite piire mingi juhusliku koha kaudu puhvrisse. Me ei saa lihtsalt juhuslikku baidi näppida ja leida sealt järgmise sümboli algust. See on meie formaadi piirang, kuid praktikas ei ole selline vajadus sage. Tüüpiliselt suudame puhvrisse alates algusest joosta (eriti kui tegemist on lühikeste ridadega).
Kaks baitide keelekatte olukord on samuti paranenud: nüüd annab kahetäheline formaat 14-bitisest ulatusest, mis tähendab koode kuni 0x3FFF. Hiinlased ei ole õnnelikud (nende hieroglüfid jäävad enamasti vahemikku 0x4E00 kuni 0x9FFF), kuid kaupmeestele ja paljudele teistele rahvastele on see rõõmustav — nende keeled mahuvad samuti 2 baidi sümbolisse.
Sissejuhatus kodeerija olekusse
Nüüd mõtleme ridade omadustele. Sõnastikus on enamasti sõnad, mis on kirjutatud ühe tähestiku sümbolitega, ja paljude teiste tekstide jaoks on see tõsi. Oleks hea ühel korral näidata seda tähestikku ja edaspidi näidata ainult tähe numbrit selle sees. Vaadake, kas Unicode'i tabelisse paigutamine aitab meid.
Nagu eespool mainitud, on Unicode jagatud tasanditeks iga 65536 koodi igaühes. Kuid see ei ole eriti kasulik jagamine (nagu juba mainitud, oleme enamasti nulltasandil). Huvi pakub rohkem jagamine plokkideks. Need vahemikud ei oma enam kindlat pikkust ja kannavad rohkem tähendust — reeglina ühendavad need tähemärke ühest tähestikust.
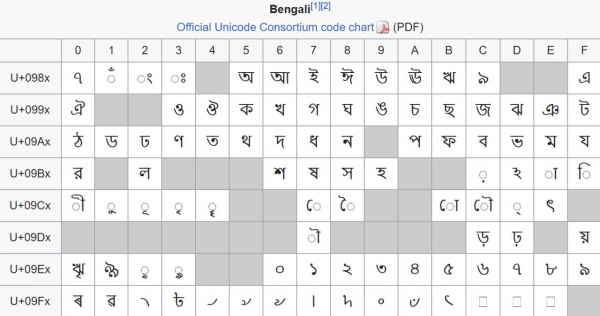
Plokk, mis sisaldab bengali tähestiku märke. Kahjuks on ajaloolistel põhjustel see näide mitte eriti tihedast pakendist — 96 märk on juhuslikult laiali laotatud 128 koodipunkti plokis.
Plokkide algused ja nende suurused on alati 16-ga jagatavad — see on tehtud mugavuse huvides. Lisaks algab ja lõppeb paljusid plokke väärtustega, mis on jagatavad 128 või isegi 256 — näiteks põhikirillitsa hõlmab 256 baiti alates 0x0400 kuni 0x04FF. See on üsna mugav: kui me ühel korral salvestame prefiksi 0x04, siis saab iga kirillitsakiri edasi kirjutada ühebaitiliselt. Kahjuks kaotame sellega võimaluse naasta ASCII juurde (ja mis tahes muude märkide juurde). Seetõttu teeme nii:
- Kaksbait
10aastat yxxxxxxxnäitavad mitte ainult tähte numbrigayyyyyy yxxxxxxx, vaid muudavad praegust tähestikku järgnevagayyyyyy y0000000(st salvestame kõik bitid, välja arvatud madalamad 7 bitti); - Üks bait
0xxxxxxxsee on praeguse tähestiku sümbol. Seda tuleb lihtsalt liita selle nihkega, mille me mäletasime sammul 1. Praegu me tähestikku ei muutnud, seega on nihe null, nii et me säilitame ühilduvuse ASCII-ga.
Sarnaselt ka koodidele, mis vajavad 3 baiti:
- Kolm baiti
110yyyyy yxxxxxxx xxxxxxxxtähistavad sümbolit numbrigayyyyyy yxxxxxxx xxxxxxxx, muudab praegust tähestikku järgnevagayyyyyy y0000000 00000000(mäletasime kõik, välja arvatud madalamad 15 bitti), ja seab lipu, et me nüüd oleme pikk režiimil (alfaane tagasi kahebae õltesse muutes, me kustutame selle lipu); - Kaksbait
0xxxxxxx xxxxxxxxpika režiimi korral on see praeguse tähestiku sümbol. Sarnaselt liidame selle samme 1 nihega. Kõik vahe on ainult selles, et nüüd loeme kahte baati (sest me oleme sellesse režiimi lülitumiseks).
Kõlab hästi: nüüd, kuni me peame kodeerima sümboleid ühest samast 7-bitise Unicode vahemikku, kulutame me 1 ülekande baati alguses ja ainult ühe baati iga sümboli kohta.
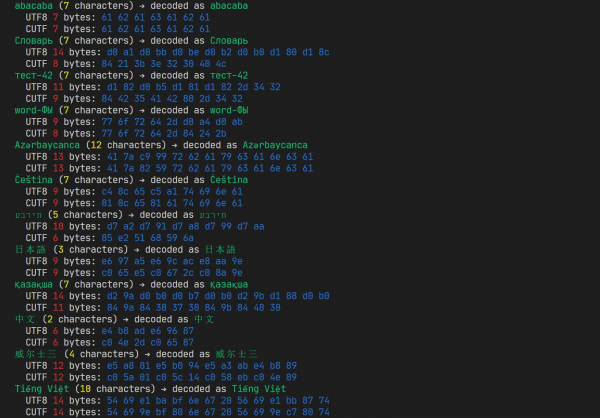
Ühe varasema versiooni töö. Juba sageli ületab UTF-8, kuid veel on millega parandada.
Mis muutus halvemaks? Esiteks, meil on seisund, nimelt praeguse tähestiku nihke ja lipp pikk režiim. See, see, see! Nüüd on sama märk erinevates kontekstides erinevalt kodeeritud. Alamsõnade otsimise käigus peame arvestama sellega, mitte lihtsalt võrreldes bite. Teiseks, niipea kui me tähestiku muutume, on ASCII märkide kodeerimisega raskeid aegu (see ei ole ainult ladina tähestik, vaid ka põhipunktsioon, sealhulgas tühikud) - need nõuavad tähestiku uuendamist 0-s, st jälle ühte liigset bitti (ja siis veel ühe, et naasta põhijuhiste juurde).
Üks tähestik on hea, kaks - parem
Proovime veidi muuta meie bittide eelfikseerimist, lisades kolm ülalnimetatud:
0xxxxxxx - 1 bait tavarežiimis, 2 pikemas režiimis
11xxxxxx — 1 byte
100xxxxx xxxxxxxx — 2 bytes
101xxxxx xxxxxxxx xxxxxxxx — 3 bytes
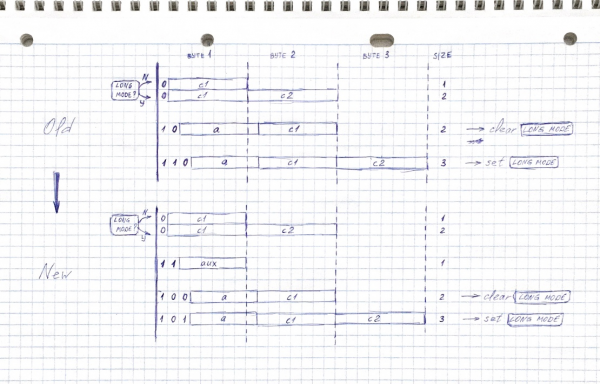
Kaks baiti kirjutamise korral on nüüd üks bitti vähem - koodipunktid mahtuvad kuni 0x1FFF, mitte 0x3FFF. Kuid siiski on see endiselt märgatavalt rohkem kui kahe baitide UTF-8 koodides, enamik levinud keeli mahub endiselt, kõige silmatorkavam kaotus - kadunuks jäi ja , ja jaapanlased on mures.
Mis on see uus kood 11xxxxxx? Это небольшой «загашник» размером в 64 символа, он дополняет наш основной алфавит, поэтому я назвал его вспомогательным (auxiliary) tähestik. Kui me vahetame praegust tähestikku, muutub osa vanast tähestikust abiks. Näiteks, kui vahetame ASCII pealt kirillitsi peale - „salvestusruumis“ on nüüd 64 sümbolit, mis sisaldavad ladina tähestikku, numbreid, tühikuid ja koma (kõige sagedasemad lisandused mitte-ASCII tekstides). Vahetame tagasi ASCII peale - ja abiks tähestikuks saab suurem osa kirillitsast.
Kuna meil on juurdepääs kahele tähestikule, suudame hallata suuremat hulka tekste, mis nõuab minimaalset vahetust tähestike vahel (punktuatsioon toob meid sagedasti tagasi ASCII peale, aga pärast seda saame paljusid mitte-ASCII sümboleid hankida juba abistavast tähestikust, ilma et peaksime uuesti vahetama).
Boonus: tähistades abistavat tähestikku eesliitega 11xxxxxx ja valides selle algse nihke 0xC0, saame osalise ühilduvuse CP1252-ga. Teisisõnu, paljud (aga mitte kõik) lääne-Euroopa tekstid, mis on kodeeritud CP1252-s, näevad välja samad ka UTF-C-s.
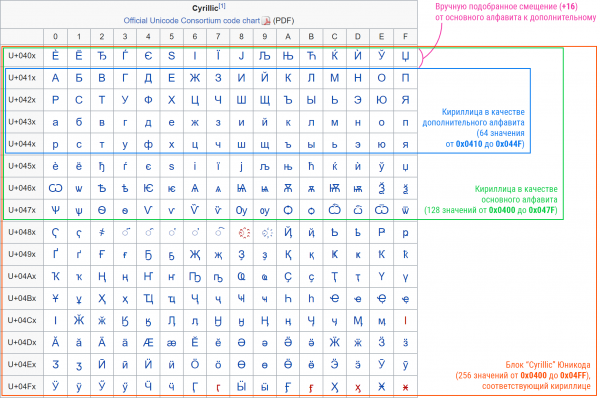
Siin tekib tõepoolest probleem: kuidas saada põhialfabeedist kõrvalalfabeet? Samuti on võimalik jätta sama nihke, kuid — kahjuks — siin mängib Unicode struktuur meie vastu. Sageli asub põhialfabeedi suurem osa blokis mitte alguses (näiteks on vene suurtähe "А" kood 0x0410, kuigi kirillitsablokk algab 0x0400). Seega, kui võtame "varu" esimesed 64 sümbolit, võime kaotada juurdepääsu alfabeedi sabale.
Selle probleemi kõrvaldamiseks käisin käsitsi läbi mõned erinevate keelte blokid ja määrasin neile põhialfabeedi sees kõrvalalfabeedi nihke. Ladina tähestik, erandina, on üldse ümber korraldatud nagu base64.
Viimased näpunäited
Mõtleme lõpuks, kus me saaksime midagi veel täiendada.
T märkige, et formaat 101xxxxx xxxxxxxx xxxxxxxx võimaldab kodeerida numbreid kuni 0x1FFFFF, kuid Unicode lõpeb varem, numbril 0x10FFFF. Teisisõnu, viimane koodipunkt esitatakse kui 10110000 11111111 11111111. Niisiis, võime öelda, et kui esimene bait on kujul 1011xxxx (kus xxxx rohkem kui 0), siis see tähistab midagi muud. Näiteks võib sinna lisada veel 15 sümbolit, mis on pidevalt kooditav ühe baitiga, kuid ma otsustasin käituda teisiti.
Vaadakem neid Unicode'i bloke, mis nõuavad praegu kolme bait. Peamiselt on need, nagu juba mainitud, hiina hieroglüüfid — kuid neid on raske midagi teha, neid on 21 tuhat. Kuid sinna on lennanud ka hiragana ja katakana — ning neid on juba vähem, vähem kui kakssada. Ja kuna me meenutasime jaapanlasi — seal on ka emotikonid (tegelikult on neid palju hajutatud Unicode'is, kuid peamised blokid on vahemikus 0x1F300 – 0x1FBFF). Kui mõelda, et praegu eksisteerivad emotikonid, mis koosnevad kohe mitmest koodipunktist (näiteks emotikon koosneb lausa 7 koodist!), siis on kahju kulutada igaühele kolm baidi (7×3 = 21 baidi ühe sümboli jaoks, õudne, eks).
Seega valime välja mõned valitud vahemikud, mis vastavad emotikonidele, hiraganale ja katakanale, nummerdame need ühte pidevasse loetellu ja kodeerime kahe baitina kolme asemel:
1011xxxx xxxxxxxx
Suurepärane: ülalmainitud emotikon , koosneb 7 koodipunktist, kasutab UTF-8s 25 baidi, kuid me mahutasime selle 14 (täpselt kaks baiti iga koodipunkti kohta). Ütlen, et Habr loobus selle töötlemisest (nii vanas kui ka uues toimetajas), seega pidi selle piltidena sisse lisama.
Proovime veel ühe probleemi lahendada. Nagu me mäletame, on põhiline tähestik tegelikult ülemised 6 bitti, mida me meeles hoiame, ja liimime iga järgmise dekodeeritava sümboli koodi külge. Hiina märkide puhul, mis asuvad plokis 0x4E00 – 0x9FFF, on see kas bit 0 või 1. See ei ole kuigi mugav: me peame pidevalt tähestikku nende kahe väärtuse vahel vahetama (st kulutama kolm baiti). Kuid märkame, et pika režiimi korral võime ise koodist lahutada sümbolite arvu, mida me lühikeses režiimis kodeerime (kõikide ülaltoodud trikkide järel on see 10240) — siis nihkub märkide vahemik 0x2600 – 0x77FF, ja sellel vahemikul on ülemised 6 bitti (21-st) võrdsed 0-ga. Sel viisil kasutavad märkide järjestused iga märkide kohta kahte baidit (mis on optimaalsed nii suure vahemiku jaoks), põhjustamata tähestiku vahetusi.
Alternatiivsed lahendused: SCSU, BOCU-1
Unicode'i ekspertid, lugedes juba artikli pealkirja, tõenäoliselt kiirustavad meenutama, et Unicode'i standardite seas on olemas (SCSU), mis kirjeldab kodeerimise meetodit, mis sarnaneb artiklis toodud kirjeldatule.
Pean ausalt ütlema: ma sain selle olemasolust teada alles siis, kui olin sügavale oma lahenduse kirjutamisse sukeldunud. Kui oleksin sellest algusest peale teadnud, oleksin tõenäoliselt proovinud kirjutada selle rakenduse, mitte välja mõelda oma lähenemisviisi.
Huvitav on see, et SCSU kasutab ideid, mis on väga sarnased nendega, milleni ma iseseisvalt jõudsin (seal kasutatakse „aken” mõistet „alfabeetide” asemel ning neid on rohkem kui mul). Samas on sellel formaadil ka puudusi: see on kodeerimisele lähemal kui压缩算法. Eriti, et standard pakub palju esitusviise, kuid ei ütle, kuidas neist optimaalset valida — selleks peab edastaja rakendama teatud heuristikat. Seega on SCSU kodner, mis annab hea pakkimise, keerulisem ja mahukam kui minu algoritm.
Võrdluseks olen ma viinud lihtsa SCSU rakenduse JavaScriptis — koodimaht on sarnane minu UTF-C-ga, kuid erinevates olukordades näitas see tulemusi isegi kümneid protsente halvemini (mõnikord võib see seda ka ületada, kuid mitte palju). Näiteks heebrea ja kreeka tekstid kodeerib UTF-C koguni 60% paremini kui SCSU (tõenäoliselt nende kompaktsete tähestike tõttu).
Lisaks ütlen, et peale SCSU on olemas ka teine viis Unicode'i kompaktseks esitlemiseks — , kuid selle eesmärk on tagada ühilduvus MIME'iga (mida ma ei vajanud), ja see kasutab veidi erinevat kodeerimismeetodit. Selle tõhusust ma ei hinnanud, aga mulle tundub, et see ei ole tõenäoliselt SCSU-st kõrgem.
Võimalikud täiustused
Antud algoritm ei ole disaini poolest universaalne (selles osas, tõenäoliselt, eristuvad minu eesmärgid kõige rohkem Unicode'i konsortsiumi eesmärkidest). Olen juba maininud, et see on peamiselt välja töötatud ühe ülesande (mitmekeelse sõnastiku hoidmise ees prefix puu) jaoks, ja mõned selle omadused võivad teiste ülesannete jaoks halvasti sobida. Kuid see, et see ei ole standard, võib olla ka pluss — saate seda hõlpsasti oma vajadustele kohandada.
Näiteks saab selgelt loobuda olekust, muuta kodeerimise stateless - lihtsalt mitte värskendada muutujaid lahendused, auxOffs ja is21Bit kodeerijas ja dekodeerijas. Sel juhul ei õnnestu tõhusalt kokku suruda sama alfabeti sümbolite järjestusi, kuid tagatakse, et sama sümbol kodeeritakse alati samade baitidega, sõltumata kontekstist.
Lisaks saab kodeerijat täpsustada konkreetse keele jaoks, muutes vaikeolekut - näiteks vene tekstide puhul seada alguses kodeerija ja dekodeerija offs = 0x0400 ja auxOffs = 0. Eriti mõistlik on see just stateless režiimis. Üldiselt sarnaneb see vana kaheksabitisüsteemi kasutamisega, kuid ei välista vajaduse korral sümbolite lisamise võimalust kõigist Unicode'ist.
Veel üks eelnevalt mainitud puudus on see, et UTF-C-koodimist kasutavas mahukates tekstides pole kiiret viisi leida sümboli piiri, mis asub suvalise baitide lähedal. Kui lõikad kodeeritud puhverest viimased, ütleme, 100 baiti, riskid saada rämpsu, millega ei saa midagi teha. Paljude gigabaitide logide hoidmiseks pole kodeering mõeldud, kuid igal juhul on võimalik seda parandada. Bait 0xBF ei tohi kunagi esimesena esineda (kuid võib olla teiseks või kolmandaks). Seetõttu võib kodeerimise ajal sisestada järjestuse 0xBF 0xBF 0xBF iga, ütleme, 10 kB järel — siis piisab valitud osa skannimisest, et leida piir, kuni leiate sarnase märgise. Viimasele järgneb 0xBF garanteeritult sümboli algus. (Dekodeerimisel tuleb seda kolmest baitist koosnevat järjestust muidugi ignoreerida.)
Kokkuvõtteks
Kui olete siiani jõudnud — palju õnne! Loodan, et te, nagu mina, õppisite midagi uut (või värskendasite vanu teadmisi) Unicode'i toimimisest.
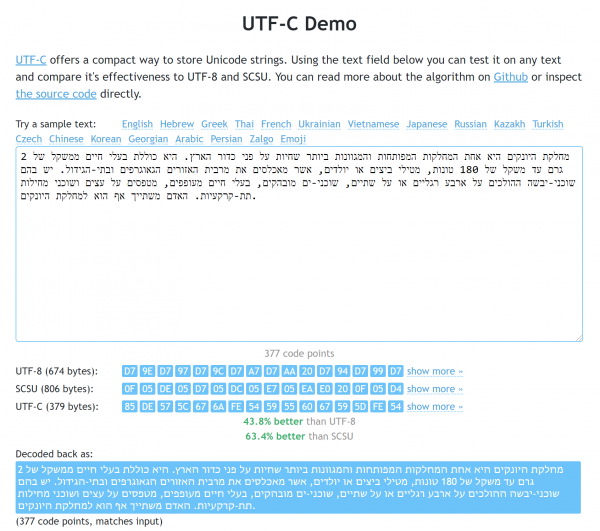
Demonstreeriv leht. Iisraeli keele näitel on nähtavad eelised nii UTF-8 kui ka SCSU ees.
Ärge pidage eespool mainitud uuringut eksitamiseks standardite suhtes. Siiski olen oma tööde tulemustega enamasti rahul ja olen neist rõõmus. : näiteks, JS-raamatukogu miniatuursed versioonid kaaluvad vaid 1710 bitti (ja loomulikult ei ole tal mingeid sõltuvusi). Nagu ma varem mainisin, saab selle tööga tutvuda (seal on ka tekstide kogum, millega saate võrrelda seda UTF-8 ja SCSU-ga).
Lõpetuseks tahan veel kord tähelepanu juhtida juhtumitele, kus UTF-C kasutamine ei tasu:
- on soovitatav, kui teie stringid on piisavalt pikad (alates 100-200 märgist). Sel juhul tasub mõelda kompressioonialgoritmide kasutamisele nagu deflate.
- Kui teil on vaja ASCII läbipaistvust, tähendab see, et on oluline, et kodeeritud järjestustes ei esineks ASCII-koode, mida algses stringis ei olnud. Sellest vajadusest saab vältida, kui suhtlete kolmandate osapoolte API-dega (näiteks andmebaasidega), edastades kodeerimise tulemuse abstraktse byte'ide kogumina, mitte stringidena. Vastasel juhul võite kokku puutuda ootamatute haavatavustega.
- Kui soovite kiiresti leida sümbolite piire suvalise nihke järgi (näiteks kui osa stringist on kahjustatud). Seda saab teha, kuid ainult skannides stringi algusest (või rakendades täiendust, nagu eelnevas osas kirjeldatud).
- Kui peate kiirelt tegema operatsioone stringide sisu üle (sorteerima, otsima alamstringe, concatenating). Sel eesmärgil tuleb stringid algselt dekodeerida, seega on UTF-C nende puhul aeglasem kui UTF-8 (aga kiiremad kui kokkusurumise algoritmid). Kuna sama string kodeeritakse alati ühtemoodi, ei vaja täpset dekodeerimise võrdlust; seda võib teha baitide kaupa.
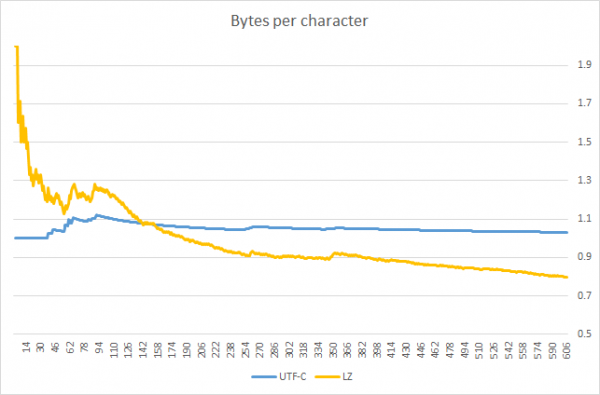
Uuendus: kasutaja postitas grafiku, mis rõhutab UTF-C rakendatavuse piiri. Sellelt on näha, et UTF-C on efektiivsem kui üldotstarbeline kokkusurumisalgoritm (LZW variatsioonid), kuni pakendatav string on lühem ~140 sümbolit (tõsi, mainin, et võrdlus tehti ühel tekstil; teiste keelte puhul võib tulemus erineda).
Allikas: habr.com
