


Sissejuhatus
Tere päevast. Meil on juba pool aastat töötanud skript (täpsemalt skriptide kogum), mis genereerib aruandeid virtuaalsete masinate seisundi kohta (ja mitte ainult). Otsustasin jagada oma kogemusi loomise ja koodiga. Loodan kriitikale ja sellele, et see materjal võib kellegi jaoks kasulik olla.
Nõudluse kujundamine
Meil on palju virtuaalseid masinaid (umbes 1500 VM-i, mis on jaotatud 3 vCenter'i vahel). Uusi luuakse ja vanu kustutatakse üsna sageli. Korra säilitamiseks lisati vCenter'isse mõned kohandatud väljad, et jagada VM-e süsteemide vahel, märkida, kas need on testmasinad ning kes ja millal need loodi. Inimfaktor viis selleni, et enamiku masinate väljad jäid täitmata, mis raskendas tööd. Iga kuue kuu tagant hakkas keegi äritsema, püüdes neid andmeid ajakohastada, kuid tulemus kaotas väärtuse juba nädalaga.
Tõstan kohe esile, et kõik mõistavad, et masinate loomise jaoks peaks olema taotlused, nende loomise protsess jms. Ja samas järgivad kõik rangelt seda protsessi ja kõiges on korda. Kahjuks ei ole meil see nii, kuid see ei ole artikli teema 🙂
Kokkuvõttes otsustati automatiseerida väljundite täitmise kontrollimise protsess.
Leiti, et igapäevane kiri loetelu vale täitmisega masinatest kõigile vastutavatele inseneridele ja nende ülemustele oleks hea algus.
Sel hetkel oli üks kolleeg juba seadistanud PowerShelli skripti, mis iga päev graafiku järgi kogus teavet kõigi masinate kohta kõikides vCenter’ites ning genereeris 3 CSV-dokumenti (igaühe oma vCenteri jaoks), mis paigutati ühisele kettale. Otsustati võtta see skript aluseks ja täiendada seda kontrollidega R-keeles, millega oli mõningane kogemus.
Protsessi täiustamise käigus lisandus lahendusele teavitamine e-posti teel, andmebaas põhiteabe ja ajaloolise tabeliga (sellest hiljem) ning vSphere’i logide analüüs, et leida VM-ide tegelikke loojat ja nende loomise aega.
Arendamiseks kasutati IDE-sid RStudio Desktop ja PowerShell ISE.
Skript käivitatakse tavalisest Windowsi virtuaalsest masinast.
Ülevaade üldisest loogikast.
Skriptide üldine loogika on järgmine.
- Kogume andmeid virtuaalmasinate kohta PowerShell skripti abil, mida kutsume esile R kaudu, ja ühendame tulemused ühte csv faili. Vaheline suhtlus kahe keele vahel on tehtud sarnaselt. (Andmeid oleks saanud otse R-st PowerShelli edastada muutujate näol, kuid see on keeruline ning kui on olemas vahepealne csv, on kergem tõrkeid siluda ja jagada kellegagi vahepealseid tulemusi).
- R abil loome lubatud parameetrid väli väärtustele, mida kontrollime. — Loome Wordi dokumendi, mis sisaldab nende väljade väärtusi, et neid lisada teavituskirja, mis vastab kolleegide küsimustele "Kuidas ma peaksin selle täitma?".
- Laadime R abil csv failist andmed kõikide VM-ide kohta, loome dataframe'i, eemaldame ebavajalikud väljad ja koostame teavitava xlsx dokumendi, mis sisaldab kokkuvõtlikku teavet kõigi VM-ide kohta, mida jagame üldiselt ressursil.
- Rakendame dataframe'ile kõigi VM-ide kohta kõik väljade täitmise korrektsuse kontrollid ja koostame tabeli, mis sisaldab ainult VM-e vale täitmisega väljadega (ja ainult neid välju).
- Saame loendi VM-idest edastatakse teise PowerShelli skripti, mis vaatab vCenteri logisid VM-ide loomise sündmuste osas. See võimaldab määrata VM-i loomise eeldatava aja ja ka eeldatava looja. See on juhuks, kui keegi ei tunnista oma masinat. Antud skript ei tööta kiiresti, eriti kui logisid on palju, seetõttu vaatame ainult viimase kahe nädala logisid ning kasutame töövoogu, mis võimaldab otsida teavet mitme VM-i kohta korraga. Skripti näites on selle mehhanismi kohta üksikasjalikud kommentaarid. Tulemused salvestatakse csv-faili, mille laadime taas R-i.
- Loome kenasti vormindatud xlsx dokumendi, kus on punasega esile tõstetud valevormistusega väljad, rakendatakse filtreid mõnedele veergudele ning lisatakse täiendavad veerud, mis sisaldavad eeldatavaid loojaid ja VM-i loomise aega.
- Koostame e-kirja, kuhu lisame dokumendi, mis kirjeldab välja lubatud väärtusi, samuti tabeli vale täidetud virtuaalmasinate kohta. Tekstis märkime vale loodud virtuaalmasinate koguarvu, lingi üldkäidavale ressursile ja motiveeriva pildi. Kui vale täidetud virtuaalmasinaid pole, saadame teise kirja koos rõõmsama motiveeriva kujutisega.
- Salvestame andmed kõigi virtuaalmasinate kohta SQL Serveri andmebaasi, arvestades ajalooliste tabelite mehhanismi (väga huvitav mehhanism — millest räägime edasi).
Tegelikult skriptid.
Peamine fail R-koodi jaoks.
# Путь к рабочей директории (нужно для корректной работы через виндовый планировщик заданий)
setwd("C:ScriptsgetVm")
#### Подгружаем необходимые пакеты ####
library(tidyverse)
library(xlsx)
library(mailR)
library(rmarkdown)
##### Определяем пути к исходным файлам и другие переменные #####
source(file = "const.R", local = T, encoding = "utf-8")
# Проверяем существование файла со всеми ВМ и удаляем, если есть.
if (file.exists(filenameVmCreationRules)) {file.remove(filenameVmCreationRules)}
#### Создаём вордовский документ с допустимыми полями
render("VM_name_rules.Rmd",
output_format = word_document(),
output_file = filenameVmCreationRules)
# Проверяем существование файла со всеми ВМ и удаляем, если есть
if (file.exists(allVmXlsxPath)) {file.remove(allVmXlsxPath)}
#### Забираем данные по всем машинам через PowerShell скрипт. На выходе получим csv.
system(paste0("powershell -File ", getVmPsPath))
# Полный df
fullXslx_df <- allVmXlsxPath %>%
read.csv2(stringsAsFactors = FALSE)
# Kontrollime, kas kõik väljad on korrektselt täidetud
full_df <- fullXslx_df %>%
mutate(
# Esiteks eemaldame kõik üleliigsed tühikud ja tabulaatorid, siis arvestame, et eraldajaks on koma, ning kontrollime, kas väärtused kuuluvad lubatud nimekirja,
isSubsystemCorrect = Subsystem %>%
gsub("[[:space:]]", "", .) %>%
str_split(., ",") %>%
map(function(x) (all(x %in% AllowedValues$Subsystem))) %>%
as.logical(),
isOwnerCorrect = Owner %in% AllowedValues$Owner,
isCategoryCorrect = Category %in% AllowedValues$Category,
isCreatorCorrect = (!is.na(Creator) & Creator != ''),
isCreation.DateCorrect = map(Creation.Date, IsDate)
)
# Kontrollime, kas fail, kus on kõik VM-d, eksisteerib ja kui jah, eemaldame selle.
if (file.exists(filenameAll)) {file.remove(filenameAll)}
#### Loomeme xslx faili aruande ####
# Üldandmed eraldi lehele
full_df %>% write.xlsx(file=filenameAll,
sheetName=names[1],
col.names=TRUE,
row.names=FALSE,
append=FALSE)
#### Loomeme xslx faili valesti täidetud väljadega ####
# Loomeme df
incorrect_df <- full_df %>%
select(VM.Name,
IP.s,
Owner,
Subsystem,
Creator,
Category,
Creation.Date,
isOwnerCorrect,
isSubsystemCorrect,
isCategoryCorrect,
isCreatorCorrect,
vCenter.Name) %>%
filter(isSubsystemCorrect == F |
isOwnerCorrect == F |
isCategoryCorrect == F |
isCreatorCorrect == F)
# Kontrollime, kas fail koos kõigi VM-idega eksisteerib ja kustutame, kui see on olemas.
if (file.exists(filenameIncVM)) {file.remove(filenameIncVM)}
# Salvestame VM-i nimekirja, kus väljad on täitmata csv-sse
incorrect_df %>%
select(VM.Name) %>%
write_csv2(path = filenameIncVM, append = FALSE)
# Filtreerime e-kirjas kasutamiseks
incorrect_df_filtered <- incorrect_df %>%
select(VM.Name,
IP.s,
Owner,
Subsystem,
Category,
Creator,
vCenter.Name,
Creation.Date
)
# Arvutame ridade arvu
numberOfRows <- nrow(incorrect_df)
#### Начало условия ####
# Дальше либо у нас есть неправильно заполненные поля, либо нет.
# Если есть - запускаем ещё один скрипт
if (numberOfRows > 0) {
# Kontrollime, kas fail loojatega eksisteerib ja kustutame, kui see on olemas.
if (file.exists(creatorsFilePath)) {file.remove(creatorsFilePath)}
# Käivitame PowerShell skripti, mis leiab leitud VM-ide loojad. Väljundina saame csv.
system(paste0("powershell -File ", getCreatorsPath))
# Loeme loojate faili
creators_df <- creatorsFilePath %>%
read.csv2(stringsAsFactors = FALSE)
# Filtreerime e-kirjas kasutamiseks, lisame andmed loojate tabelist
incorrect_df_filtered <- incorrect_df_filtered %>%
select(VM.Name,
IP.s,
Owner,
Subsystem,
Category,
Creator,
vCenter.Name,
Creation.Date
) %>%
left_join(creators_df, by = "VM.Name") %>%
rename(`Eeldatav looja` = CreatedBy,
`Eeldatav loomise kuupäev` = CreatedOn)
# Koostame e-kirja sisu
emailBody <- paste0(
'<html>
<h3>Tere, austatud kolleegid.</h3>
<p>Kogu ajakohane teave virtuaalmasinate kohta on saadaval H: kettal siin:<p>
<p>\server.ruVM', sourceFileFormat, '</p>
<p>Samuti on manuses nimekiri VM-idest, millel on <strong>valed</strong> väljad. Kokku on neid <strong>', numberOfRows, '</strong>.</p>
<p>Tabelis on lisandunud 2 täiendavat veergu. <strong>Eeldatav looja</strong> ja <strong>Eeldatav loomise kuupäev</strong>, mis on saadud vCenteri logidest viimase 2 nädala jooksul</p>
<p>Palun selgitada andmeid ja täita väljad õigesti. Väljade täitmise reeglid on samuti manuses</p>
<p><img src="data/meme.jpg"></p>
</html>'
)
# Kontrollime faili olemasolu
if (file.exists(filenameIncorrect)) {file.remove(filenameIncorrect)}
# Koostame kena tabeli formaatidega jne.
source(file = "email.R", local = T, encoding = "utf-8")
#### Koostame kirja vale allkirjastatud masinate kohta ####
send.mail(from = emailParams$from,
to = emailParams$to,
subject = "VM-ide illegaalselt täidetud väljad",
body = emailBody,
encoding = "utf-8",
html = TRUE,
inline = TRUE,
smtp = emailParams$smtpParams,
authenticate = TRUE,
send = TRUE,
attach.files = c(filenameIncorrect, filenameVmCreationRules),
debug = FALSE)
#### Edasi läheb plokk, kui VM-idega pole probleeme ####
} else {
# Koostame kirja sisu
emailBody <- paste0(
'<html>
<h3>Tere päevast, austatud kolleegid</h3>
<p>Kogu ajakohane teave virtuaalmasinate kohta on saadaval H: kettal siin:<p>
<p>\server.ruVM', sourceFileFormat, '</p>
<p>Samuti on hetkel kõik VM-i väljad korrektselt täidetud</p>
<p><img src="data/meme_correct.jpg"></p>
</html>'
)
#### Koostame kirja ilma vale täidetud VM-ideta ####
send.mail(from = emailParams$from,
to = emailParams$to,
subject = "Kojutav teave",
body = emailBody,
encoding = "utf-8",
html = TRUE,
inline = TRUE,
smtp = emailParams$smtpParams,
authenticate = TRUE,
send = TRUE,
debug = FALSE)
}
####### Salvestame andmed andmebaasi #####
source(file = "DB.R", local = T, encoding = "utf-8")
PowerShelli skript, mis saadab virtuaalmasinate nimekirja.
# Данные для подключения и другие переменные
$vCenterNames = @(
"vcenter01",
"vcenter02",
"vcenter03"
)
$vCenterUsername = "myusername"
$vCenterPassword = "mypassword"
$filename = "C:ScriptsgetVmdataallvmall-vm-$(get-date -f yyyy-MM-dd).csv"
$destinationSMB = "server.rumyfolder$vm"
$IP0=""
$IP1=""
$IP2=""
$IP3=""
$IP4=""
$IP5=""
# Подключение ко всем vCenter, что содержатся в переменной. Будет работать, если логин и пароль одинаковые (например, доменные)
Connect-VIServer -Server $vCenterNames -User $vCenterUsername -Password $vCenterPassword
write-host ""
# Создаём функцию с циклом по всем vCenter-ам
function Get-VMinventory {
# В этой переменной будет списко всех ВМ, как объектов
$AllVM = Get-VM | Sort Name
$cnt = $AllVM.Count
$count = 1
# Начинаем цикл по всем ВМ и собираем необходимые параметры каждого объекта
foreach ($vm in $AllVM) {
$StartTime = $(get-date)
$IP0 = $vm.Guest.IPAddress[0]
$IP1 = $vm.Guest.IPAddress[1]
$IP2 = $vm.Guest.IPAddress[2]
$IP3 = $vm.Guest.IPAddress[3]
$IP4 = $vm.Guest.IPAddress[4]
$IP5 = $vm.Guest.IPAddress[5]
If ($IP0 -ne $null) {If ($IP0.Contains(":") -ne 0) {$IP0=""}}
If ($IP1 -ne $null) {If ($IP1.Contains(":") -ne 0) {$IP1=""}}
If ($IP2 -ne $null) {If ($IP2.Contains(":") -ne 0) {$IP2=""}}
If ($IP3 -ne $null) {If ($IP3.Contains(":") -ne 0) {$IP3=""}}
If ($IP4 -ne $null) {If ($IP4.Contains(":") -ne 0) {$IP4=""}}
If ($IP5 -ne $null) {If ($IP5.Contains(":") -ne 0) {$IP5=""}}
$cluster = $vm | Get-Cluster | Select-Object -ExpandProperty name
$Bootime = $vm.ExtensionData.Runtime.BootTime
$TotalHDDs = $vm.ProvisionedSpaceGB -as [int]
$CreationDate = $vm.CustomFields.Item("CreationDate") -as [string]
$Creator = $vm.CustomFields.Item("Creator") -as [string]
$Category = $vm.CustomFields.Item("Category") -as [string]
$Owner = $vm.CustomFields.Item("Owner") -as [string]
$Subsystem = $vm.CustomFields.Item("Subsystem") -as [string]
$IPS = $vm.CustomFields.Item("IP") -as [string]
$vCPU = $vm.NumCpu
$CorePerSocket = $vm.ExtensionData.config.hardware.NumCoresPerSocket
$Sockets = $vCPU/$CorePerSocket
$Id = $vm.Id.Split('-')[2] -as [int]
# Собираем все параметры в один объект
$Vmresult = New-Object PSObject
$Vmresult | add-member -MemberType NoteProperty -Name "Id" -Value $Id
$Vmresult | add-member -MemberType NoteProperty -Name "VM Name" -Value $vm.Name
$Vmresult | add-member -MemberType NoteProperty -Name "Cluster" -Value $cluster
$Vmresult | add-member -MemberType NoteProperty -Name "Esxi Host" -Value $VM.VMHost
$Vmresult | add-member -MemberType NoteProperty -Name "IP Address 1" -Value $IP0
$Vmresult | add-member -MemberType NoteProperty -Name "IP Address 2" -Value $IP1
$Vmresult | add-member -MemberType NoteProperty -Name "IP Address 3" -Value $IP2
$Vmresult | add-member -MemberType NoteProperty -Name "IP Address 4" -Value $IP3
$Vmresult | add-member -MemberType NoteProperty -Name "IP Address 5" -Value $IP4
$Vmresult | add-member -MemberType NoteProperty -Name "IP Address 6" -Value $IP5
$Vmresult | add-member -MemberType NoteProperty -Name "vCPU" -Value $vCPU
$Vmresult | Add-Member -MemberType NoteProperty -Name "CPU Sockets" -Value $Sockets
$Vmresult | Add-Member -MemberType NoteProperty -Name "Core per Socket" -Value $CorePerSocket
$Vmresult | add-member -MemberType NoteProperty -Name "RAM (GB)" -Value $vm.MemoryGB
$Vmresult | add-member -MemberType NoteProperty -Name "Total-HDD (GB)" -Value $TotalHDDs
$Vmresult | add-member -MemberType NoteProperty -Name "Power State" -Value $vm.PowerState
$Vmresult | add-member -MemberType NoteProperty -Name "OS" -Value $VM.ExtensionData.summary.config.guestfullname
$Vmresult | Add-Member -MemberType NoteProperty -Name "Boot Time" -Value $Bootime
$Vmresult | add-member -MemberType NoteProperty -Name "VMTools Status" -Value $vm.ExtensionData.Guest.ToolsStatus
$Vmresult | add-member -MemberType NoteProperty -Name "VMTools Version" -Value $vm.ExtensionData.Guest.ToolsVersion
$Vmresult | add-member -MemberType NoteProperty -Name "VMTools Version Status" -Value $vm.ExtensionData.Guest.ToolsVersionStatus
$Vmresult | add-member -MemberType NoteProperty -Name "VMTools Running Status" -Value $vm.ExtensionData.Guest.ToolsRunningStatus
$Vmresult | add-member -MemberType NoteProperty -Name "Creation Date" -Value $CreationDate
$Vmresult | add-member -MemberType NoteProperty -Name "Creator" -Value $Creator
$Vmresult | add-member -MemberType NoteProperty -Name "Category" -Value $Category
$Vmresult | add-member -MemberType NoteProperty -Name "Owner" -Value $Owner
$Vmresult | add-member -MemberType NoteProperty -Name "Subsystem" -Value $Subsystem
$Vmresult | add-member -MemberType NoteProperty -Name "IP's" -Value $IPS
$Vmresult | add-member -MemberType NoteProperty -Name "vCenter Name" -Value $vm.Uid.Split('@')[1].Split(':')[0]
# Считаем общее и оставшееся время выполнения и выводим на экран результаты. Использовалось для тестирования, но по факту оказалось очень удобно.
$elapsedTime = $(get-date) - $StartTime
$totalTime = "{0:HH:mm:ss}" -f ([datetime]($elapsedTime.Ticks*($cnt - $count)))
clear-host
Write-Host "Processing" $count "from" $cnt
Write-host "Progress:" ([math]::Round($count/$cnt*100, 2)) "%"
Write-host "You have about " $totalTime "for cofee"
Write-host ""
$count++
# Выводим результат, чтобы цикл "знал" что является результатом выполнения одного прохода
$Vmresult
}
}
# Вызываем получившуюся функцию и сразу выгружаем результат в csv
$allVm = Get-VMinventory | Export-CSV -Path $filename -NoTypeInformation -UseCulture -Force
# Пытаемся выложить полученный файл в нужное нам место и, в случае ошибки, пишем лог.
try
{
Copy-Item $filename -Destination $destinationSMB -Force -ErrorAction SilentlyContinue
}
catch
{
$error | Export-CSV -Path $filename".error" -NoTypeInformation -UseCulture -Force
}PowerShelli skript, mis tõmbab logidest välja virtuaalmasinate loojaid ja nende loomise kuupäevi.
# Путь к файлу, из которого будем доставать список VM
$VMfilePath = "C:ScriptsgetVmcreators_VMcreators_VM_$(get-date -f yyyy-MM-dd).csv"
# Путь к файлу, в который будем записывать результат
$filePath = "C:ScriptsgetVmdatacreatorscreators-$(get-date -f yyyy-MM-dd).csv"
# Создаём вокрфлоу
Workflow GetCreators-Wf
{
# Параметры, которые можно будет передать при вызове скрипта
param([string[]]$VMfilePath)
# Параметры, которые доступны только внутри workflow
$vCenterUsername = "myusername"
$vCenterPassword = "mypassword"
$daysToLook = 14
$start = (get-date).AddDays(-$daysToLook)
$finish = get-date
# Значения, которые будут вписаны в csv для машин, по которым не будет ничего найдено
$UnknownUser = "UNKNOWN"
$UnknownCreatedTime = "0000-00-00"
# Определяем параметры подключения и выводной файл, которые будут доступны во всём скрипте.
$vCenterNames = @(
"vcenter01",
"vcenter02",
"vcenter03"
)
# Получаем список VM из csv и загружаем соответствующие объекты
$list = Import-Csv $VMfilePath -UseCulture | select -ExpandProperty VM.Name
# Цикл, который будет выполняться параллельно (по 5 машин за раз)
foreach -parallel ($row in $list)
{
# Это скрипт, который видит только свои переменные и те, которые ему переданы через $Using
InlineScript {
# Время начала выполнения отдельного блока
$StartTime = $(get-date)
Write-Host ""
Write-Host "Processing $Using:row started at $StartTime"
Write-Host ""
# Подключение оборачиваем в переменную, чтобы информация о нём не мешалась в консоли
$con = Connect-VIServer -Server $Using:vCenterNames -User $Using:vCenterUsername -Password $Using:vCenterPassword
# Получаем объект vm
$vm = Get-VM -Name $Using:row
# Ниже 2 одинаковые команды. Одна с фильтром по времени, вторая - без. Можно пользоваться тем,
$Event = $vm | Get-VIEvent -Start $Using:start -Finish $Using:finish -Types Info | Where { $_.Gettype().Name -eq "VmBeingDeployedEvent" -or $_.Gettype().Name -eq "VmCreatedEvent" -or $_.Gettype().Name -eq "VmRegisteredEvent" -or $_.Gettype().Name -eq "VmClonedEvent"}
# $Event = $vm | Get-VIEvent -Types Info | Where { $_.Gettype().Name -eq "VmBeingDeployedEvent" -or $_.Gettype().Name -eq "VmCreatedEvent" -or $_.Gettype().Name -eq "VmRegisteredEvent" -or $_.Gettype().Name -eq "VmClonedEvent"}
# Заполняем параметры в зависимости от того, удалось ли в логах найти что-то
If (($Event | Measure-Object).Count -eq 0){
$User = $Using:UnknownUser
$Created = $Using:UnknownCreatedTime
$CreatedFormat = $Using:UnknownCreatedTime
} Else {
If ($Event.Username -eq "" -or $Event.Username -eq $null) {
$User = $Using:UnknownUser
} Else {
$User = $Event.Username
} # Else
$CreatedFormat = $Event.CreatedTime
# Один из коллег отдельно просил, чтобы время было в таком формате, поэтому дублируем его. А в БД пойдёт нормальный формат.
$Created = $Event.CreatedTime.ToString('yyyy-MM-dd')
} # Else
Write-Host "Creator for $vm is $User. Creating object."
# Создаём объект. Добавляем параметры.
$Vmresult = New-Object PSObject
$Vmresult | add-member -MemberType NoteProperty -Name "VM Name" -Value $vm.Name
$Vmresult | add-member -MemberType NoteProperty -Name "CreatedBy" -Value $User
$Vmresult | add-member -MemberType NoteProperty -Name "CreatedOn" -Value $CreatedFormat
$Vmresult | add-member -MemberType NoteProperty -Name "CreatedOnFormat" -Value $Created
# Выводим результаты
$Vmresult
} # Inline
} # ForEach
}
$Creators = GetCreators-Wf $VMfilePath
# Записываем результат в файл
$Creators | select 'VM Name', CreatedBy, CreatedOn | Export-Csv -Path $filePath -NoTypeInformation -UseCulture -Force
Write-Host "CSV generetion finisghed at $(get-date). PROFIT"
Erilist tähelepanu väärib raamatukogu. , mis lubas kirja manuse selgelt vormindatuna esitada (nagu juhtkond armastab), mitte lihtsalt csv tabelina.
Ilusa xlsx dokumendi loomine vale täidetud masinate nimekirjaga.
# Создаём новую книгу
# Возможные значения : "xls" и "xlsx"
wb<-createWorkbook(type="xlsx")
# Стили для имён рядов и колонок в таблицах
TABLE_ROWNAMES_STYLE <- CellStyle(wb) + Font(wb, isBold=TRUE)
TABLE_COLNAMES_STYLE <- CellStyle(wb) + Font(wb, isBold=TRUE) +
Alignment(wrapText=TRUE, horizontal="ALIGN_CENTER") +
Border(color="black", position=c("TOP", "BOTTOM"),
pen=c("BORDER_THIN", "BORDER_THICK"))
# Создаём новый лист
sheet <- createSheet(wb, sheetName = names[2])
# Добавляем таблицу
addDataFrame(incorrect_df_filtered,
sheet, startRow=1, startColumn=1, row.names=FALSE, byrow=FALSE,
colnamesStyle = TABLE_COLNAMES_STYLE,
rownamesStyle = TABLE_ROWNAMES_STYLE)
# Меняем ширину, чтобы форматирование было автоматическим
autoSizeColumn(sheet = sheet, colIndex=c(1:ncol(incorrect_df)))
# Добавляем фильтры
addAutoFilter(sheet, cellRange = "C1:G1")
# Определяем стиль
fo2 <- Fill(foregroundColor="red")
cs2 <- CellStyle(wb,
fill = fo2,
dataFormat = DataFormat("@"))
# Находим ряды с неверно заполненным полем Владельца и применяем к ним определённый стиль
rowsOwner <- getRows(sheet, rowIndex = (which(!incorrect_df$isOwnerCorrect) + 1))
cellsOwner <- getCells(rowsOwner, colIndex = which( colnames(incorrect_df_filtered) == "Owner" ))
lapply(names(cellsOwner), function(x) setCellStyle(cellsOwner[[x]], cs2))
# Находим ряды с неверно заполненным полем Подсистемы и применяем к ним определённый стиль
rowsSubsystem <- getRows(sheet, rowIndex = (which(!incorrect_df$isSubsystemCorrect) + 1))
cellsSubsystem <- getCells(rowsSubsystem, colIndex = which( colnames(incorrect_df_filtered) == "Subsystem" ))
lapply(names(cellsSubsystem), function(x) setCellStyle(cellsSubsystem[[x]], cs2))
# Аналогично по Категории
rowsCategory <- getRows(sheet, rowIndex = (which(!incorrect_df$isCategoryCorrect) + 1))
cellsCategory <- getCells(rowsCategory, colIndex = which( colnames(incorrect_df_filtered) == "Category" ))
lapply(names(cellsCategory), function(x) setCellStyle(cellsCategory[[x]], cs2))
# Создатель
rowsCreator <- getRows(sheet, rowIndex = (which(!incorrect_df$isCreatorCorrect) + 1))
cellsCreator <- getCells(rowsCreator, colIndex = which( colnames(incorrect_df_filtered) == "Creator" ))
lapply(names(cellsCreator), function(x) setCellStyle(cellsCreator[[x]], cs2))
# Сохраняем файл
saveWorkbook(wb, filenameIncorrect)Väljund näeb välja umbes nii:
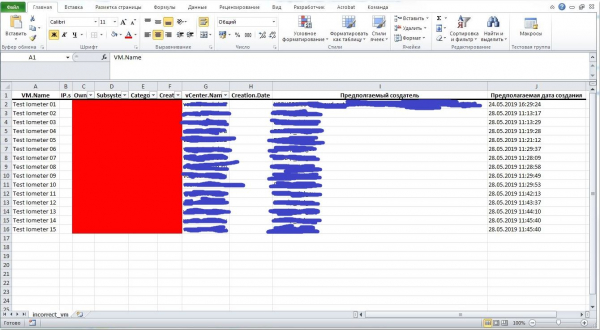
Samuti oli huvitav nüanss Windowsi ajakava seadistamisel. Õige õiguste ja seadete kombinatsiooni leidmine osutus keeruliseks, et kõik tööle hakkaks nagu peab. Lõpuks leiti R raamatukogu, mis loob ülesande R skripti käivitamiseks ja ei unusta logifaili. Hiljem saab ülesannet käsitsi parandada.
R koodilõik koos kahe näitega, mis loob Windowsi ajakava ülesande
library(taskscheduleR)
myscript <- file.path(getwd(), "all_vm.R")
## käivitame skripti 62 sekundi pärast
taskscheduler_create(taskname = "getAllVm", rscript = myscript,
schedule = "ONCE", starttime = format(Sys.time() + 62, "%H:%M"))
## käivitame skripti iga päev kell 09:10
taskscheduler_create(taskname = "getAllVmDaily", rscript = myscript,
schedule = "WEEKLY",
days = c("MON", "TUE", "WED", "THU", "FRI"),
starttime = "02:00")
## kustutame ülesanded
taskscheduler_delete(taskname = "getAllVm")
taskscheduler_delete(taskname = "getAllVmDaily")
# Vaata logisid (viimased 4 rida)
tail(readLines("all_vm.log"), sep ="n", n = 4)Eraldi andmebaasi kohta
Pärast skripti seadistamist ilmusid esile muud küsimused. Näiteks tahtsin leida kuupäeva, millal virtuaalmasin eemaldati, kuid vCenteri logid olid juba kustutatud. Kuna skript salvestab failid kausta iga päev ja ei puhasta (puhastame käsitsi, kui meenutame), siis on võimalik vaadata vanu faile ja leida esimene fail, kus seda virtuaalmasinat ei ole. Aga see ei ole väga mugav.
Soovisime luua ajaloolise andmebaasi.
Aitamiseks tuli MS SQL SERVERi funktsionaalsus — system-versioned temporal table. Seda tõlgitakse tavaliselt kui ajaliselt (mitte ajaliselt) tabelid.
Rohkem võib lugeda .
Lühidalt öeldes — loome tabeli, määrame, et see on versioneeritud, ja SQL Server loob sellele tabelile 2 täiendavat datetime veergu (kande loomise kuupäeva ja kande eluea lõpu kuupäeva) ning täiendava tabeli, kuhu salvestatakse muutused. Tulemuseks saame ajakohast teavet ja lihtsate päringute abil, mille näited on dokumentatsioonis, saame näha kas konkreetse virtuaalmasina elutsüklit või kõikide virtuaalmasinate seisundit teatud ajahetkel.
Tulemuste mõttes ei lõpetata peamise tabeli kirjetöötlust enne, kui on lõppenud ajutise tabeli kirjetöötlus. See tähendab, et tabelites, kus on palju kirjeid, tuleks seda funktsionaalsust rakendada ettevaatlikult, kuid meie puhul on see tõeliselt äge funktsioon.
Selle mehhanismi nõuetekohaseks toimimiseks pidin R-is kirjutama väikese koodi, mis võrreldaks uut tabelit kõikide VM-ide andmetega andmebaasis hoitava tabeliga ja kirjutaks sinna ainult muutunud read. Kood ei ole eriti keeruline, kasutab compareDF teeki, kuid selle ma toon ka allpool.
Kood R-is andmete kirjutamiseks andmebaasi
# Подцепляем пакеты
library(odbc)
library(compareDF)
# Формируем коннект
con <- dbConnect(odbc(),
Driver = "ODBC Driver 13 for SQL Server",
Server = DBParams$server,
Database = DBParams$database,
UID = DBParams$UID,
PWD = DBParams$PWD,
Port = 1433)
#### Проверяем есть ли таблица. Если нет - создаём. ####
if (!dbExistsTable(con, DBParams$TblName)) {
#### Создаём таблицу ####
create <- dbSendStatement(
con,
paste0(
'CREATE TABLE ',
DBParams$TblName,
'(
[Id] [int] NOT NULL PRIMARY KEY CLUSTERED,
[VM.Name] [varchar](255) NULL,
[Cluster] [varchar](255) NULL,
[Esxi.Host] [varchar](255) NULL,
[IP.Address.1] [varchar](255) NULL,
[IP.Address.2] [varchar](255) NULL,
[IP.Address.3] [varchar](255) NULL,
[IP.Address.4] [varchar](255) NULL,
[IP.Address.5] [varchar](255) NULL,
[IP.Address.6] [varchar](255) NULL,
[vCPU] [int] NULL,
[CPU.Sockets] [int] NULL,
[Core.per.Socket] [int] NULL,
[RAM..GB.] [int] NULL,
[Total.HDD..GB.] [int] NULL,
[Power.State] [varchar](255) NULL,
[OS] [varchar](255) NULL,
[Boot.Time] [varchar](255) NULL,
[VMTools.Status] [varchar](255) NULL,
[VMTools.Version] [int] NULL,
[VMTools.Version.Status] [varchar](255) NULL,
[VMTools.Running.Status] [varchar](255) NULL,
[Creation.Date] [varchar](255) NULL,
[Creator] [varchar](255) NULL,
[Category] [varchar](255) NULL,
[Owner] [varchar](255) NULL,
[Subsystem] [varchar](255) NULL,
[IP.s] [varchar](255) NULL,
[vCenter.Name] [varchar](255) NULL,
DateFrom datetime2 GENERATED ALWAYS AS ROW START NOT NULL,
DateTo datetime2 GENERATED ALWAYS AS ROW END NOT NULL,
PERIOD FOR SYSTEM_TIME (DateFrom, DateTo)
) ON [PRIMARY]
WITH (SYSTEM_VERSIONING = ON (HISTORY_TABLE = ', DBParams$TblHistName,'));'
)
)
# Отправляем подготовленный запрос
dbClearResult(create)
} # if
#### Начало работы с таблицей ####
# Обозначаем таблицу, с которой будем работать
allVM_db_con <- tbl(con, DBParams$TblName)
#### Сравниваем таблицы ####
# Собираем данные с таблицы (убираем служебные временные поля)
allVM_db <- allVM_db_con %>%
select(c(-"DateTo", -"DateFrom")) %>%
collect()
# Создаём таблицу со сравнением объектов. Сравниваем по Id
# Удалённые объекты там будут помечены через -, созданные через +, изменённые через - и +
ctable_VM <- fullXslx_df %>%
compare_df(allVM_db,
c("Id"))
#### Удаление строк ####
# Выдираем Id виртуалок, записи о которых надо удалить
remove_Id <- ctable_VM$comparison_df %>%
filter(chng_type == "-") %>%
select(Id)
# Проверяем, что есть записи (если записей нет - и удалять ничего не нужно)
if (remove_Id %>% nrow() > 0) {
# Конструируем шаблон для запроса на удаление данных
delete <- dbSendStatement(con,
paste0('
DELETE
FROM ',
DBParams$TblName,
' WHERE "Id"=?
') # paste
) # send
# Создаём запрос на удаление данных
dbBind(delete, remove_Id)
# Отправляем подготовленный запрос
dbClearResult(delete)
} # if
#### Добавление строк ####
# Выделяем таблицу, содержащую строки, которые нужно добавить.
allVM_add <- ctable_VM$comparison_df %>%
filter(chng_type == "+") %>%
select(-chng_type)
# Проверяем, есть ли строки, которые нужно добавить и добавляем (если нет - не добавляем)
if (allVM_add %>% nrow() > 0) {
# Пишем таблицу со всеми необходимыми данными
dbWriteTable(con,
DBParams$TblName,
allVM_add,
overwrite = FALSE,
append = TRUE)
} # if
#### Не забываем сделать дисконнект ####
dbDisconnect(con)Kokku
Skripti kasutuselevõtu tulemusena on mõne kuu jooksul saavutatud ja hoitud kord. Vahel ilmuvad valesti täidetud VM-id, kuid skript toimib hästi meeldetuletusena ja harva satub sama VM kahe päeva järjest nimekirja.
Samuti on seatud alused ajalooliste andmete analüüsiks.
On selge, et palju sellest saab rakendada mitte 'käekirjas', vaid professionaalse tarkvara kaudu, kuid ülesanne oli huvitav ja võib öelda, et valikuline.
R on taas näidanud end suurepärase universaalsena, mis sobib mitte ainult statistiliste ülesannete lahendamiseks, vaid toimib ka suurepärase "sildana" erinevate andmeallikate vahel.

Allikas: habr.com
