

Tere, Habr'i lugejad. Jätkame traditsiooniliselt huvitava materjali jagamist uute kursuste alguse eelõhtul. Täna oleme teie jaoks tõlkinud artikli Google Cloud Spannerist, seostades selle kursuse käivitamisega .

Esialgselt avaldatud .
Kuna ettevõte, mis pakub mitmeid pilvepõhiseid POS-lahendusi jaemüüjatele, restoranipidajatele ja veebimüüjatele üle kogu maailma, kasutab Lightspeed mitmeid erinevaid andmebaasiplatvorme, et toetada erinevaid tehingulisi, analüütilisi ja otsingukiire. Igal neist andmebaasiplatvormidest on oma tugevused ja nõrkused. Seega, kui Google tutvustas turul Cloud Spannerit - tõotavad omadused, mida pole nähtud suhte-andmebaaside maailmas, näiteks praktiliselt piiramatu horisontaalne skaleeritavus ja 99,999% teenuse taseme leping (SLA) - ei saanud me jätta kasutamata võimalust selle meie kätte saada!
Kuna anname põhjaliku ülevaate meie kogemustest Cloud Spanneriga ja hindamiskriteeriumidest, mida oleme kasutanud, vaatame järgmisi teemasid:
- Meie hindamiskriteeriumid
- Cloud Spanner lühiülevaates
- Meie hinnang
- Meie järeldused

1. Meie hindamiskriteeriumid
Enne kui süveneme Cloud Spanneri eripära, sarnasusi ja erinevusi teiste turul olevate lahendustega, arutame esmalt põhikasutusi, mida meollime kaalunud Cloud Spanneri juurutamist meie infrastruktuuris:
- Mugavuse huvides traditsioonilise SQL andmebaasilahenduse asendajana
- OLTP lahendusena koos OLAP toega
Märkus: Selle artikli eesmärk on võrrelda Cloud Spannerit MySQL erinevustega, GCP Cloud SQL ja Amazon AWS RDS lahenduste peredega.
Cloud Spanneri kasutamine traditsioonilise SQL andmebaasilahenduse asendajana
Keskkonnas traditsioonilised andmebaasid, kus vastuseajad andmebaasi päringutele lähevad lähedale või isegi ületavad eelnevalt määratud rakenduse läviväärtusi (peamiselt suurenenud kasutajate ja/või päringute arvu tõttu), on mitmeid viise, kuidas vähendada vastusaega vastuvõetavatele tasemetele. Kuid enamik neist lahendustest nõuab käsitsi sekkumist.
Näiteks on esimene samm, millele tähelepanu pöörata, erinevad andmebaasi toimivuse parameetrid, ja nende kohandamine rakenduste kasutusstsenaariumide mallidega parima ühtimise saavutamiseks. Kui see ei ole piisav, võib valida andmebaasi vertikaalse või horisontaalse skaleerimise.
Rakenduse vertikaalne skaleerimine tähendab serveri instantsi uuendamist, tavaliselt suurema arvu protsessorite / tuumade, suurema muutmemälu ja kiirema salvestusruumi lisamise teel. Suurema hulga riistvararessursside lisamine toob kaasa andmebaasi toimivuse paranemise, mida mõõdetakse peamiselt sekundis tehtud tehingute arvu ja OLTP-süsteemide tehingute latentsuse järgi. Suhete andmebaasisüsteemid (mis kasutavad mitme haru lähenemist), nagu MySQL, skaleeruvad hästi vertikaalselt.
Selle lähenemisega on seotud mitmeid puudusi, kuid ilmselgeim on turu suurima serveri maksimaalne suurus. Kui saavutatakse suurima serveri instantsi piir, on ainus tee horisontaalne skaleerimine.
Horisontaalne skaleerimine on lähenemine, mille käigus lisatakse klastrisse rohkem servereid, et ideaaljuhul suurendada jõudlust lineaarset muutumist serverite arvu suurenemisega. Enamik traditsioonilised andmebaasisüsteeme ei skaleeru horisontaalselt või ei skaleeru üldse. Näiteks MySQL võib horisontaalset skaleerimist kasutada lugemisoperatsioonide jaoks, lisades orja-lugejaid, kuid ei saa seda kasutada kirjutamisoperatsioonide jaoks.
Teisest küljest suudab Cloud Spanner tänu oma olemusele horisontaalselt hõlpsasti skaleeruda minimaalse sekkumisega.
Täielikult funktsionaalne andmebaas kui teenus peab olema hinnatud erinevate aspektide kohaselt. Aluseks võtsime kõige populaarsema pilve andmebaasi — Google'i jaoks, GCP Cloud SQL ja Amazoni jaoks, AWS RDS. Oma hindamises keskendusime järgmistele kategooriatele:
- Funktsioonide võrdlemine: SQL ulatus, DDL, DML; ühendusraamatukogud/konnektorid, tehingute tugi ja nii edasi.
- Arenduse tugi: arendamise ja testimise lihtsus.
- Halduse tugi: instance'ide haldamine — näiteks üles/alla skaleerimine ja instance’ide uuendamine; SLA, varundamine ja taastamine; turvalisus/juurdepääsukontroll.
Cloud Spanneri kasutamine OLTP lahendusena, mis toetab OLAP-i.
Kuigi Google ei väida selgelt, et Cloud Spanner on mõeldud analüütiliseks töötlemiseks, jagab see mõningaid omadusi teiste mehhanismidega, nagu Apache Impala & Kudu ja YugaByte, mis on mõeldud OLAP töökoormustele.
Isegi kui oleks olemas ainult vähene võimalus, et Cloud Spanner sisaldab horisontaalselt skaaleeritavat HTAP (hübriidne tehinguline/analüütiline töötlemine) mootori koos (vähem-välja) kasutatava OLAP funktsioonide komplektiga, arvan, et see vääriks meie tähelepanu.
Seda silmas pidades oleme vaadanud järgmisi kategooriaid:
- Andmete laadimine, indeksid ja partitsioneerimise tugi
- Küsimuste ja DML tulemuslikkus
2. Cloud Spanner lühidalt
Google Spanner on klasterdatabaaside haldamise süsteem (RDBMS), mida Google kasutab oma mitmesugustes teenustes. Google tegi selle 2017. aasta alguses Google Cloud Platformi kasutajatele kättesaadavaks.
Siin on mõned Cloud Spanneri omadused:
- Kõrge kooskõlastusvõimekusega skaleeritav RDBMS: kasutab ajasinroniseerimist andmete kooskõlastatuse tagamiseks.
- Toetab mitme tabeli tehinguid: tehingud võivad hõlmata mitmeid tabeleid — ei pea olema piiratud ühe tabeliga (erinevalt Apache HBase'ist või Apache Kudust).
- Tabelid, mis põhinevad primaaraval: kõik tabelid peavad omama määratud primaarvõtit (PV), mis võib koosneda mitmest tabeli veerust. Tabeli andmed salvestatakse PV alusel, mis muudab need väga efektiivseks ja kiireks PV alusel otsimiseks. Nagu teiste PV-põhiste süsteemide puhul, peab rakendamine olema modelleeritud arvestades eelnevalt läbi mõeldud juhtumeid parima tulemuse saavutamiseks. .
- Vahelduvad tabelid: tabelid võivad omavahel füüsiliselt sõltuda. Alamtabeli read võivad olla seotud ülemineku tabeli ridadega. Selline lähenemine kiirendab suhete leidmist, mis võivad olla määratletud andmemudeli koostamise etapis, näiteks klientide ja nende arvekohtade ühismajutuse korral.
- Indeksid: Cloud Spanner toetab teiseseid indekseid. Indeks koosneb indekseeritud veergudest ja kõigist PK veergudest. Soovi korral võib indeks sisaldada ka muid indekseerimata veerge. Indeks võib vahelduda ülemineku tabeliga päringute kiirendamiseks. Indeksitele kehtivad mitmed piirangud, näiteks maksimaalne arv lisaveerge, mida indeksis hoitakse. Samuti võivad päringud indekseid kaudu olla keerulisemad kui teistes RDBMS-ides.
Cloud Spanner valib indeksi automaatselt ainult harvadel juhtudel. Eelkõige ei valita Cloud Spanner teisest indeksist automaatselt, kui päring nõuab mingeid veerge, mis ei ole salvestatud ».
- Teenuste tasemelepingu (SLA) puhul: juurutamine ühes regioonis SLA-ga 99,99%; mitmeregionaalsed juurutused 99,999% SLA-ga. Ehkki teenuste tasemeleping on lihtsalt leping, mitte garantii, arvan, et Google'i töötajatel on tõepoolest mõned täpsed andmed, et teha sellist tõsist väidet. (Viidates, 99,999% tähendab 26,3 sekundit teenuse katkestust kuus.)
- Rohkem:
Märkus: Apache Tephra projekt lisab Apache HBase-le laiendatud tehingute toe (nüüd on see beetaversioonis ellu viidud ka Apache Phoenixis).
3. Meie hinnang
Nii et oleme kõik lugenud Google'i väiteid Cloud Spanneri eeliste kohta — praktiliselt piiramatu horisontaalne skaleeritavus, säilitades samas kõrge järjepidevuse ja väga kõrge SLA. Hoolimata sellest, et neid nõudeid on tõeliselt äärmiselt raske saavutada, ei olnud meie eesmärk neid ümber lükata. Keskendugem hoopis muudele asjadele, mis muretsevad enamikku andmebaasi kasutajaid: usaldusväärsus ja kasutusmugavus.
Hindasime Cloud Spannerit Sharded MySQL asendajana
Google Cloud SQL ja Amazon AWS RDS, kaks kõige populaarsemat OLTP andmebaasi pilvemarketis, omavad väga suurt funktsioonide komplekti. Kuid selleks, et neid andmebaase skaleerida ühe sõlme suurusest kaugemale, peate rakendustes tegema partitsioneerimist. Selline lähenemine loob täiendavat keerukust nii rakendustele kui ka haldamisele. Oleme uurinud, kuidas Spanner sobib mitme segmendi ühendamise stsenaariumi ja millistest funktsioonidest (kui leidub) võib-olla tuleb loobuda.
SQL, DML ja DDL tugi, samuti ühendus ja raamatukogud?
Esiteks, andmebaasi kasutamise alguses tuleb luua andmemudel. Kui arvate, et saate JDBC Spannerit oma lemmik SQL tööriista juurde ühendada, leiate, et saate andmeid nende kaudu pärida, kuid ei saa neid kasutada tabeli loomiseks või muutmiseks (DDL) ega ka mis tahes sisestamise, uuendamise või kustutamise (DML) operatsioonide jaoks. Google’i ametlik JDBC ei toeta kumbagi.
„Praegu ei toeta draiverid DML- või DDL-operatsioone.”
Spanneri dokumentatsioon
GCP konsooliga ei ole olukord parem — saate saata ainult SELECT-päringuid. Õnneks on olemas DML ja DDL toe jaoks JDBC draiver, mille on välja töötanud kogukond, sealhulgas tehingud. . Kuigi see draiver on äärmiselt kasulik, üllatab Google'i puuduv JDBC draiver. Õnneks pakub Google üsna laia toetust kliendiraamatukogudele (põhinevad gRPC-l): C#, Go, Java, node.js, PHP, Python ja Ruby.
Peaaegu kohustuslik kohandatud Cloud Spanner API-de kasutamine (DDL ja DML puudumise tõttu JDBC-s) toob kaasa teatud piirangud seotud koodialadele, nagu ühenduse kogumid või andmebaasi sidumise raamistikud (nt Spring MVC). Üldiselt on JDBC kasutamisel võimalik vabalt valida lemmikühenduse kogum (nt HikariCP, DBCP, C3PO jne), mis on testitud ja toimib hästi. Kohandatud Spanner API-de puhul peame toetuma ise loodud raamistikele/ühenduste kogudele/sessioonidele.
Peamine võtmega (PK) struktuur võimaldab Cloud Spanneril andmetele PK kaudu väga kiiresti juurde pääseda, kuid toob kaasa ka teatud päringute probleemid.
- Te ei saa muuta peamise võtme väärtust; peate esmalt kustutama kirje originaalse PK-ga ja seejärel uuesti sisestama selle uue väärtusega. (See on sarnane teiste PK-põhiste andmebaaside/salvestusmehhanismidega.)
- Kõik UPDATE ja DELETE operaatorid peavad näitama PK-d WHERE, seega ei saa olla tühje DELETE all — alaliselt peab olema alamküsitlus, näiteks: UPDATE xxx WHERE id IN (SELECT id FROM table1)
- Puudub automaatse suurendamise variant või midagi sarnast, mis määrab PK välja järjestuse. Selle töötamiseks peab vastav väärtus olema loodud rakenduse poolel.
Teised indeksid?
Google Cloud Spanner toetab sisseehitatud teisi indekseid. See on väga meeldiv omadus, mida teistes tehnoloogiates ei pruugi alati olla. Apache Kudu ei toeta üldse teisi indekseid, samas kui Apache HBase ei toeta indekseid otse, vaid saab neid lisada Apache Phoenixi kaudu.
Indekseid Kudu ja HBase-s saab modelleerida kui eraldi tabelit erineva primaarvõtmete koosseisuga, kuid toimingute aatomomaatsus, mida tehakse vanemtabeli ja sellega seotud indeksitabelitega, peab toimuma rakenduse tasemel ja ei ole lihtne õigesti ellu viia.
Nagu mainitud Cloud Spaneri ülevaates, võivad selle indeksid erineda MySQL indeksitest. Seetõttu tuleks olla ettevaatlik päringute koostamisel ja profileerimisel, et tagada sobiva indeksi kasutamine seal, kus see on vajalik.
Vaated?
Väga populaarne ja kasulik objekt andmebaasis on vaated. Need võivad olla kasulikud paljude kasutusjuhtude jaoks; minu kaks lemmikut on loogilise abstraktsiooni tase ja turvalisuse tase. Kahjuks ei toeta Cloud Spanner vaateid. Kuid see piirab meid vaid osaliselt, kuna juurdepääsuõiguste osas ei ole veerge tasemel detailide eristamist, kus vaated võivad olla vastuvõetav lahendus.
Cloud Spanneri dokumentatsioonis jaotises, kus kirjeldatakse kvoote ja piiranguid (), on üks, mis võib olla probleemne mõnede rakenduste jaoks: Cloud Spanner'il on mingeid limite, mis on maksimaalselt 100 andmebaasi iga instantsi kohta. Ilmselt võib see muutuda tõsiseks takistuseks andmebaasile, mis on mõeldud skaleerimiseks enam kui 100 andmebaasi jaoks. Õnneks, pärast vestlust meie Google'i tehnikuga, selgus, et seda piiri saab praktiliselt igas suuruses tõsta Google'i tugiteenuse kaudu.
Arenduse tugi?
Cloud Spanner pakub üsna head programmeerimiskeelte toetust oma API-de kasutamiseks. Ametlikult toetatud teegid on C#, Go, Java, node.js, PHP, Python ja Ruby. Dokumentatsioon on piisavalt detailne, kuid nagu teiste tipptasemel tehnoloogiate puhul, on ka kogukond üsna väike võrreldes kõige populaarsemate andmebaasitehnoloogiate kogukondadega, mis võib suurendada aega, mis kulub vähem levinud kasutusjuhtude või probleemide lahendamiseks.
Nii et kuidas on kohaliku arenduse toega?
Me ei leidnud viisi Cloud Spanneri instantsi loomiseks kohalikus keskkonnas. Kõige lähem, mida saime, oli Docker-i pilt , mis on põhimõtteliselt sarnane, kuid praktikas väga erinev. Näiteks CockroachDB saab kasutada PostgreSQL JDBC-d. Kuna arenduskeskkond peaks olema võimalikult lähedane tootmiskeskkonnale, ei ole Cloud Spanner ideaalne, kuna peab toetuma täielikule Spanneri instantsile. Kulude kokkuhoidmiseks võite valida ühe regiooni instantsi.
Halduse tugi?
Cloud Spanneri instantsi loomine on väga lihtne. Peate lihtsalt valima, kas luua mitmeregionaalne või ühe regiooni instants, määrama regiooni(d) ja sõlmede arvu. Vähem kui minuti jooksul on instants käivitatud ja tööks valmis.
Mõned põhimetriigid on otse juurdepääsetavad Google'i konsoolis Spanneri lehelt. Üksikasjalikumad vaated on saadaval Stackdriveri kaudu, kus saate ka seadistada metrikate ja häirepoliiitikate läveväärtusi.
Juurdepääs ressurssidele?
MySQL pakub laia ja väga detailselt reguleeritud kasutajaõigusi/rolle. Juhtimist saab hõlpsasti seadistada konkreetsele tabelile või isegi lihtsalt osa selle veergudest. Cloud Spanner kasutab Google'i identiteedi ja juurdepääsu haldamise (IAM) tööriistu, mis võimaldavad kehtestada poliitikaid ja õigusi ainult väga kõrgel tasemel. Kõige detailsem variant on andmebaasi taseme õigus, mis ei sobi enamiku tootmisjuhtumitega. See piirang sunnib teid lisama oma koodi, infrastruktuuri või mõlemat täiendavaid turvameetmeid, et vältida Spanneri ressursside ebaseaduslikku kasutamist.
Varukoopiad?
Lihtsalt öeldes ei eksisteeri Cloud Spanneris varukoopiaid. Kuigi Google'i SLA kõrged nõudmised võivad tagada, et te ei kaota andmeid riistvarast või andmebaasist tingitud riketest, on inimvigade, tarkvara defektide jne tõttu andmekaitse oluline. Me kõik teame reeglit: kõrge kättesaadavus ei asenda mõistlikku varundusstrateegiat. Hetkel on andmete varundamiseks ainus viis nende voogedastamine andmebaasist eraldi salvestuskeskkonda.
Küsimuste jõudlus?
Andmete laadimiseks ja päringute testimiseks kasutasime Yahoo! Cloud Serving Benchmarki. Allpool on esitatud YCSB töökoormus, kus lugemise ja kirjutamise suhe on 95% ja 5%.
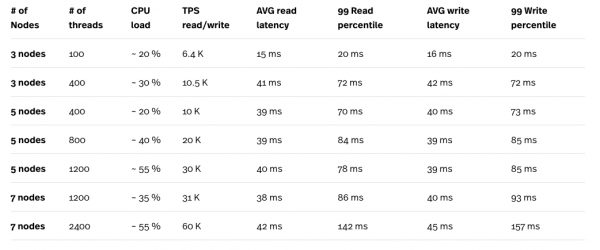
* Koormustesti viidi läbi n1-standard-32 (32 vCPU, 120 GB RAM) arvutusmootoril, ning testi instants ei olnud kunagi kitsaskohaks testide käigus.
** YCSB ühes instantsis on maksimaalne niitide arv 400. Kokku oli vaja käivitada kuus paralleelset YCSB testi instantsi, et saavutada kokku 2400 niiti.
Testitulemusi vaadates, eriti protsessorikoormuse ja TPS kombinatsiooni osas, näeme selgelt, et Cloud Spanner skaleerub üsna hästi. Suur koormus, mida tekitavad paljud pääsud, kompenseeritakse Cloud Spanneri klastris olevate sõlmede suure arvu kaudu. Kuigi latentsus tundub olevat üsna kõrge, eriti 2400 pääsu korral, võib täpsemate numbrite saamiseks olla vajalik testimise kordamine, kasutades 6 väiksemat arvutusmootorit. Iga instants jooksutab ühte YCSB testi, mitte ühte suurt CE instantsi kuue paralleelse testiga. Nii on lihtsam eristada Cloud Spanneri päringute latentsust ning latentsust, mis on lisatud võrguühenduses Cloud Spanneri ja CE instantsi vahel, kus test toimub.
Kuidas Cloud Spanner OLAP-ina toime tuleb?
Partitsioneering?
Andmete jagamine füüsiliselt ja/või loogiliselt sõltumatuteks segmentideks, mida nimetatakse partiitideks, on väga populaarne kontseptsioon, mis kuulub enamikku OLAP-mootoritest. Partiid võivad oluliselt parandada päringute jõudlust ja andmebaasi hooldatavust. Sügavam süvenemine partiitidesse vääriks eraldi artiklit, seetõttu mainime lihtsalt skeemi olemasolu ning alampartiitide tähtsust. Andmete jagamine partiitideks ja isegi alampartiitideks on analüütiliste päringute jõudluse võti.
Cloud Spanner ei toeta partiiteid sellisel kujul. See jagab andmed sees nii nimetatud split-deks, mis põhinevad esmase võtme vahemikel. Jagamine toimub automaatselt Cloud Spanneri klastris koormuse tasakaalustamiseks. Cloud Spanneri mugav funktsioon on vanemate tabelite (tabelite, mida ei vaheldustata teistega) põhikoormuse jagamine. Spanner määrab automaatselt, kas split andmed, mida loetakse sagedamini, kui teised. split-des, ja võib teha otsuseid edasise jagamise kohta. Seeläbi võib päringus osaleda rohkem sõlmesid, mis tõhusalt suurendab ka läbilaskevõimet.
Andmete laadimine?
Cloud Spanner'i meetod mahukate andmete jaoks on sama, mis tavalise laadimise puhul. Parima jõudluse saavutamiseks peate järgima mõningaid soovitusi, sealhulgas:
- Korrastage oma andmed põhivõtme järgi.
- Jagage need 10*sõlmede arv erinevate osade kaupa.
- Looge tööülesannete komplekt, mis laadib andmed paralleelselt.
Sellise andmete laadimise korral kasutatakse kõiki Cloud Spanner'i sõlmesid.
Oleme kasutanud koormustööd A YCSB andmestiku genereerimiseks, mis sisaldab 10 miljonit rida.
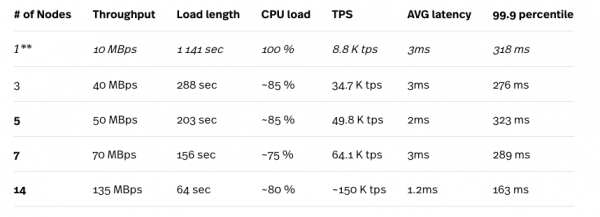
* Koormustest viidi läbi n1-standard-32 (32 vCPU, 120 GB RAM) arvutusmootoris ning testimise instants ei olnud kunagi kitsaskohaks testides.
** 1-sõlme seadistust ei soovitata ühegi tootmiskoormuse jaoks.
Nagu eelnevalt mainitud, töötab Cloud Spanner automaatselt jagamisi, sõltuvalt nende koormusest, seega paranevad tulemused pärast mitmeid järjestikuseid teste. Siin esitatud tulemused on parimad, mida oleme saavutanud. Vaadates ülaltoodud numbreid, näeme, kuidas Cloud Spanner skaleerub hästi klastris sõlmede arvu suurenedes. Kõrgetasemed, mis silma paistavad, näitavad äärmiselt madalat keskmist latentsust, mis kontrastib segakoormuse tulemustega (95% lugemist ja 5% kirjutamist), nagu eelnevas osas kirjas.
Skaleerimine?
Cloud Spanneri sõlmede arvu suurendamine ja vähendamine on ülesanne, mida saab teha ühe klikiga. Kui soovite kiiresti andmeid laadida, võite kaaluda instantsi maksimaalsesse suurendamisse (meie puhul oli see 25 sõlme US-EAST regioonis), ning pärast andmete laadimist andmebaasi vähendada sõlmede arvu, mis sobib teie tavalise koormuse jaoks, meeles pidades piirangut 2 TB/sõlm.
Meeldeti meile selle piiri kohta isegi palju väiksema andmebaasiga. Pärast mitmeid koormusteste oli meie andmebaasi suurus umbes 155 GB ja kui vähendasime ühe sõlme instantsile, tekkis meil järgmine viga:
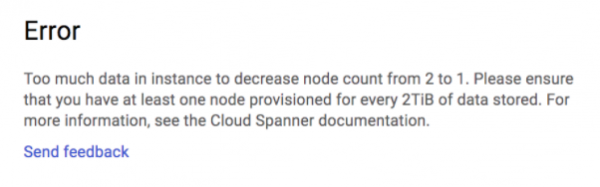
Me suutsime vähendada skaalat 25-lt 2-le instantsile, kuid jäime kahe sõlme juurde kinni.
Cloud Spanneri klastris sõlmede arvu suurendamist ja vähendamist saab automatiseerida REST API abil. See võib olla eriti kasulik süsteemi suurenenud koormuse vähendamiseks tipptundidel.
OLAP päringute jõudlus?
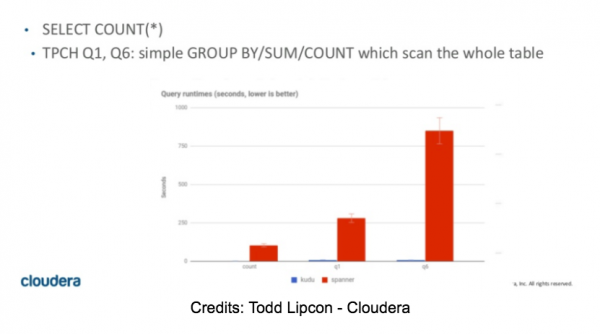
Alguses kavandasime sellele osale Spanneri hindamisel märkimisväärselt aega pühendada. Pärast mitmeid SELECT COUNT päringuid mõistsime kohe, et testimine on lühike ja Spanner EI sobi OLAP mootoriks. Ükskõik, kui palju sõlmi on klastris, võttis 10M rida tabelist ridade arvu valimine aega 55-60 sekundit. Lisaks lõpetasid kõik päringud, mis nõudsid rohkem mälu vaheresultaatide hoidmiseks, OOM veaga.
SELECT COUNT(DISTINCT(field0)) FROM usertable; — (10M distinct values) -> SpoolingHashAggregateIterator ran out of memory during new row.
Mõned numbrid TPC-H päringute kohta leiate Todd Lipkoni artiklist , slaidid 42 ja 43. Need numbrid vastavad meie enda tulemustele (kahjuks).
4. Meie järeldused
Arvestades Cloud Spanneri praegust funktsionaalset seisundit, on keeruline ette kujutada selle lihtsat asendamist olemasoleva OLTP-lahenduse jaoks, eriti siis, kui teie vajadused ületavad selle võimeid. Oleks vaja kulutada märkimisväärselt aega lahenduse arendamiseks, arvestades Cloud Spanneri puudusi.
Kui alustasime Cloud Spanneri hindamist, ootasime, et selle haldustooted on teiste Google SQL lahendustega samal tasemel või vähemalt mitte kaugel neist. Kuid meid üllatas täiesti varukoopiate puudumine ja väga piiratud juurdepääsuteenuste kontroll. Rääkimata vaadete puudumisest, kohaliku arenduskeskkonna puudumisest, mitte toetatud järjestustest, JDBC-st ilma DML ja DDL toeta ja nii edasi.
Nii et kuhu peaks minema inimene, kellel on vaja suurendada tehingute andmebaasi? Tundub, et turul ei ole praegu ühtset lahendust, mis sobiks kõikide kasutusjuhtude jaoks. On olemas palju mitte- ja avatud lähtekoodiga lahendus, millest mõned on selles artiklis mainitud, igaühel on oma tugevused ja nõrkused, kuid ühtegi neist ei paku SLA-d 99,999% ja kõrget järjepidevust. Kui kõrge SLA tase on teie põhiline eesmärk ja te pole kaldunud looma oma lahendust mitme pilvekeskkonna jaoks, võib Cloud Spanner olla see lahendus, mida otsite. Kuid peate olema teadlik kõikidest selle piirangutest.
Ausugude märkida, et Cloud Spanner avati üldiseks kasutamiseks alles 2017. aasta kevadel, seetõttu on mõistlik oodata, et mõned selle praegused puudused võivad lõpuks kaduda (loodetavasti), ja kui see juhtub, võib see mängu muuta. Lõppude lõpuks ei ole Cloud Spanner lihtsalt kõrvalprojekt Google'ile. Google kasutab seda teiste Google'i toodete aluseks. Ja kui Google hiljuti asendas Megastore Google Cloud Storage'is Cloud Spanneriga, võimaldas see Google Cloud Storage'il olla rangelt kooskõlastatud globaalsete objektide loetlemisel (mis endiselt ei kehti ).
Nii et lootus on endiselt olemas… loodame.
Sellega on kõik. Nagu artikli autor, jätkame ka meie loodetavasti ja mida arvate teie? Kirjutage kommentaarides
Kutsume kõiki üles külastama meie mille raames räägime kursusest üksikasjalikult OTUSelt.
Allikas: habr.com
