

Мы рассмотрим работу Zabbix с базой данных TimescaleDB в качестве backend. Покажем, как запустить с нуля и как мигрировать с PostgreSQL. Также приведем сравнительные тесты производительности двух конфигураций.

HighLoad++ Siberia 2019. Зал «Томск». 24 июня, 16:00. Тезисы и . Следующая конференция HighLoad++ пройдет 6 и 7 апреля 2020 года в Санкт-Петербурге. Подробности и билеты .
Андрей Гущин (далее – АГ): – Я – инженер технической поддержки ZABBIX (далее – «Заббикс»), тренер. Работаю более 6 лет в технической поддержке и напрямую сталкивался с производительностью. Сегодня я буду рассказывать о производительности, которую может дать TimescaleDB, при сравнении с обычным PostgreSQL 10. Также некоторая вводная часть – о том, как вообще работает.
Главные вызовы производительности: от сбора до очистки данных
Начнём с того, что есть определённые вызовы производительности, с которыми встречается каждая система мониторинга. Первый вызов производительности – это быстрый сбор и обработка данных.

Хорошая система мониторинга должна оперативно, своевременно получать все данные, обрабатывать их согласно триггерным выражениям, то есть обрабатывать по каким-то критериям (в разных системах это по-разному) и сохранять в базу данных, чтобы в дальнейшем эти данные использовать.

Второй вызов производительности – это хранение истории. Хранить в базе данных зачастую и иметь быстрый и удобный доступ к этим метрикам, которые были собраны за какой-то период времени. Самое главное, чтобы эти данные было удобно получить, использовать их в отчётах, графиках, триггерах, в каких-то пороговых значениях, для оповещений и т. д.

Третий вызов производительности – это очистка истории, то есть когда у вас наступает такой день, что вам не нужно хранить какие-то подробные метрики, которые были собраны за 5 лет (даже месяцы или два месяца). Какие-то узлы сети были удалены, либо какие-то хосты, метрики уже не нужны потому, что они уже устарели и перестали собираться. Это всё нужно вычищать, чтобы у вас база данных не разрослась до большого размера. И вообще, очистка истории чаще всего является серьёзным испытанием для хранилища – очень сильно зачастую влияет на производительность.
Как решить проблемы кэширования?
Я сейчас буду говорить конкретно о «Заббиксе». В «Заббиксе» первый и второй вызовы решены с помощью кэширования.

Сбор и обработка данных – мы используем оперативную память для хранения всех этих данных. Сейчас об этих данных будет подробнее рассказано.
Также на стороне базы данных есть определённое кэширование для основных выборок – для графиков, других вещей.
Кэширование на стороне самого Zabbix-сервера: у нас присутствуют ConfigurationCache, ValueCache, HistoryCache, TrendsCache. Что это такое?

ConfigurationCache – это основной кэш, в котором мы храним метрики, хосты, элементы данных, триггеры; всё, что нужно для обработки препроцессинга, сбора данных, с каких хостов собирать, с какой частотой. Всё это хранится в ConfigurationCache, чтобы не ходить в базу данных, не создавать лишних запросов. После старта сервера мы обновляем этот кэш (создаём) и обновляем периодически (в зависимости от настроек конфигурации).
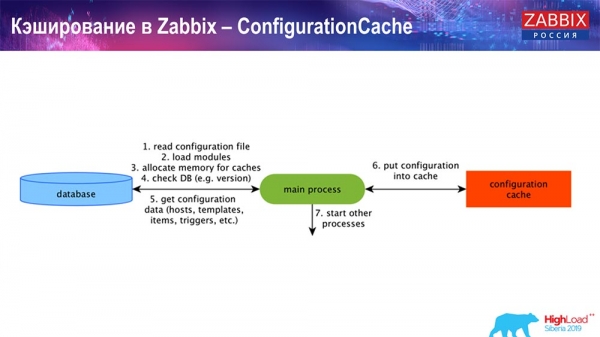
Кэширование в Zabbix. Сбор данных
Здесь схема достаточно большая:
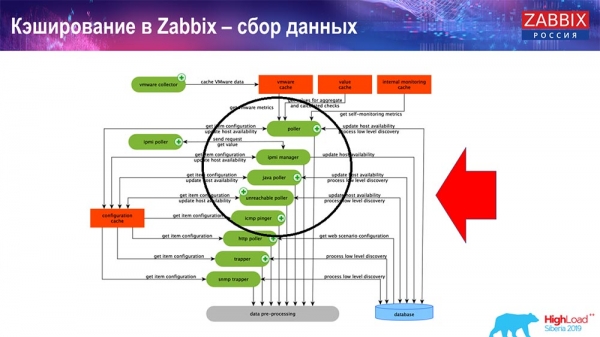
Основные в схеме – вот эти сборщики:
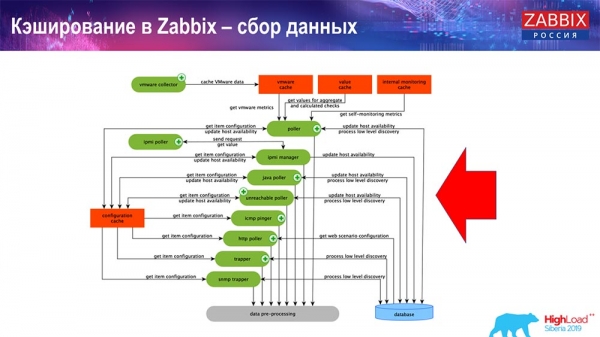
Это сами процессы сборки, различные «поллеры», которые отвечают за разные виды сборок. Они собирают данные по icmp, ipmi, по разным протоколам и передают это всё на препроцессинг.
PreProcessing HistoryCache
Также, если у нас есть вычисляемые элементы данных (кто знаком с «Заббиксом» – знает), то есть вычисляемые, агрегационные элементы данных, – мы их забираем напрямую из ValueCache. О том, как он наполняется, я расскажу позже. Все эти сборщики используют ConfigurationCache для получения своих заданий и дальше передают на препроцессинг.
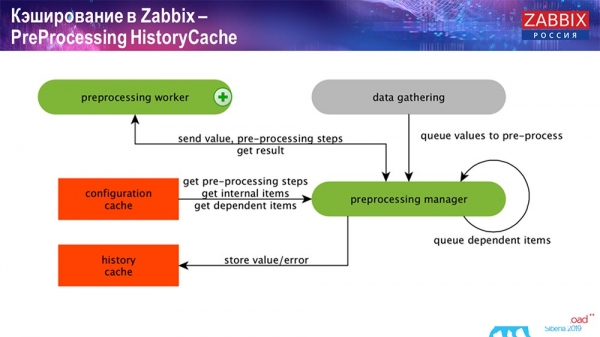
Препроцессинг также использует ConfigurationCache для получения шагов препроцессинга, обрабатывает эти данные различным способом. Начиная с версии 4.2, он у нас вынесен на прокси. Это очень удобно, потому что сам препроцессинг – достаточно тяжёлая операция. И если у вас очень большой «Заббикс», с большим количеством элементов данных и высокой частотой сбора, то это сильно облегчает работу.
Соответственно, после того как мы обработали эти данные каким-либо образом с помощью препроцессинга, сохраняем их в HistoryCache для того, чтобы их дальше обработать. На этом заканчивается сбор данных. Мы переходим к главному процессу.
Работа History syncer
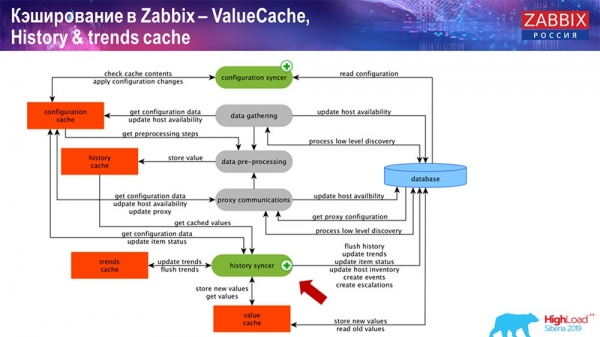
Главный в «Заббиксе» процесс (так как это монолитная архитектура) – History syncer. Это главный процесс, который занимается именно атомарной обработкой каждого элемента данных, то есть каждого значения:
- приходит значение (он его берёт из HistoryCache);
- проверяет в Configuration syncer: есть ли какие-то триггеры для вычисления – вычисляет их;
если есть – создаёт события, создаёт эскалацию для того, чтобы создать оповещение, если это необходимо по конфигурации; - записывает триггеры для последующей обработки, агрегации; если вы агрегируете за последний час и так далее, это значение запоминает ValueCache, чтобы не обращаться в таблицу истории; таким образом, ValueCache наполняется нужными данными, которые необходимы для вычисления триггеров, вычисляемых элементов и т. д.;
- далее History syncer записывает все данные в базу данных;
- база данных записывает их на диск – на этом процесс обработки заканчивается.
Базы данных. Кэширование
На стороне БД, когда вы хотите посмотреть графики либо какие-то отчёты по событиям, есть различные кэши. Но в рамках этого доклада я не буду о них рассказывать.
Для MySQL есть Innodb_buffer_pool, ещё куча различных кэшей, которые тоже можно настроить.
Но это – основные:
- shared_buffers;
- effective_cache_size;
- shared_pool.

Я для всех баз данных привёл, что есть определённые кэши, которые позволяют держать в оперативной памяти те данные, которые часто необходимы для запросов. Там у них свои технологии для этого.
О производительности базы данных
Соответственно, есть конкурентная среда, то есть «Заббикс»-сервер собирает данные и записывает их. При перезапуске он тоже читает из истории для наполнения ValueCache и так далее. Тут же у вас могут быть скрипты и отчёты, которые используют «Заббикс»-API, который на базе веб-интерфейса построен. «Заббикс»-API входит в БД и получает необходимые данные для получения графиков, отчётов либо какого-то списка событий, последних проблем.
Также очень популярное решение для визуализации – это Grafana, которое используют наши пользователи. Умеет напрямую входить как через «Заббикс»-API, так и через БД. Оно тоже создаёт определённую конкуренцию для получения данных: нужна более тонкая, хорошая настройка БД, чтобы соответствовать быстрой выдаче результатов и тестирования.

Очистка истории. В Zabbix есть Housekeeper
Третий вызов, который используется в «Заббикс» – это очистка истории с помощью Housekeeper. «Хаускипер» соблюдает все настройки, то есть у нас в элементах данных указано, сколько хранить (в днях), сколько хранить тренды, динамику изменений.
Я не рассказал про ТрендКэш, который мы высчитываем на лету: поступают данные, мы их агрегируем за один час (в основном это числа за последний час), количество среднее / минимальное и записываем это раз в час в таблицу динамики изменений («Трендс»). «Хаускипер» запускается и удаляет обычными селектами данные из БД, что не всегда эффективно.
Как понять что это неэффективно? Вы можете на графиках производительности внутренних процессов видеть такую картину:
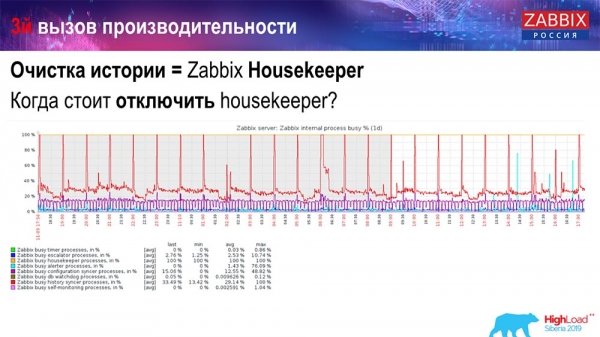
У вас History syncer постоянно занят (красный график). И «рыжий» график, который поверху идёт. Это «Хаускипер», который запускается и ждёт от БД, когда она удалит все строки, которые он задал.
Возьмём какой-нибудь Item ID: нужно удалить последние 5 тысяч; конечно, по индексам. Но обычно датасет достаточно большой – база данных всё равно это считывает с диска и поднимает в кэш, а это очень дорогая операция для БД. В зависимости от её размеров, это может приводить к определённым проблемам производительности.
Отключить «Хаускипер» можно простым способом – у нас есть всем знакомый веб-интерфейс. Настройка в Administration general (настройки для «Хаускипера») мы отключаем внутренний housekeeping для внутренней истории и трендов. Соответственно, «Хаускипер» больше не управляет этим:

Что можно дальше делать? Вы отключили, у вас графики выровнялись… Какие в этом случае могут быть дальше проблемы? Что может помочь?
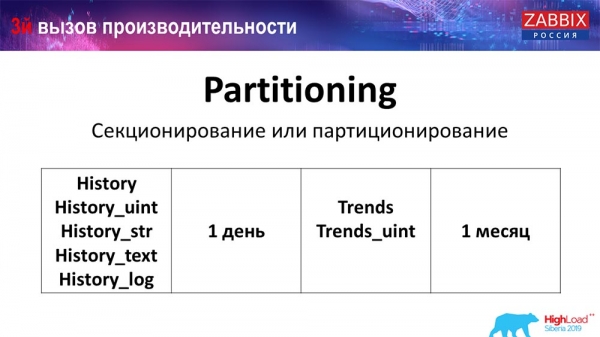
Партиционирование (секционирование)
Обычно это настраивается на каждой реляционной базе данных, которые я перечислил, различным способом. На MySQL своя технология. Но в целом они очень похожи, если говорить о PostgreSQL 10 и MySQL. Конечно, там очень много внутренних различий, как это всё реализовано и как это всё влияет на производительность. Но в целом создание новой партиции часто тоже приводит к определённым проблемам.

В зависимости от вашего setup’а (насколько много у вас создаётся данных за один день), обычно выставляют самый минимальный – это 1 день/партиция, а для «трендов», динамики изменений – 1 месяц / новая партиция. Это может меняться, если у вас очень большой setup.
Сразу давайте скажу о размерах setup’а: до 5 тысяч новых значений в секунду (nvps так называемый) – это будет считаться малый «сетап». Средний – от 5 до 25 тысяч значений в секунду. Всё, что свыше – это уже большие и очень большие инсталляции, которые требуют очень тщательной настройки именно базы данных.
На очень больших инсталляциях 1 день – это может быть не оптимально. Я лично видел на MySQL партиции по 40 гигабайт за день (и больше могут быть). Это очень большой объём данных, который может приводить к каким-то проблемам. Его нужно уменьшать.
Зачем нужно партиционирование?
Что даёт Partitioning, я думаю, все знают – это секционирование таблиц. Зачастую это отдельные файлы на диске и спан-запросов. Он более оптимально выбирает одну партицию, если это входит в обычное партиционирование.
Для «Заббикса», в частности, используется по рэнджу, по диапазону, то есть мы используем таймстамп (число обычное, время с начала эпохи). Вы задаёте начало дня / конец дня, и это является партицией. Соответственно, если вы обращаетесь за данными двухдневной давности, это всё выбирается из базы данных быстрее, потому что нужно всего один файл загрузить в кэш и выдать (а не большую таблицу).

Многие БД также ускоряет insert (вставка в одну child-таблицу). Пока я говорю абстрактно, но это тоже возможно. Partitoning зачастую помогает.
Elasticsearch для NoSQL
Недавно, в 3.4, мы внедрили решение для NoSQL. Добавили возможность писать в Elasticsearch. Вы можете писать отдельные какие-то типы: выбираете – либо числа пишите, либо какие-то знаки; у нас есть стринг-текст, логи можете писать в Elasticsearch… Соответственно, веб-интерфейс уже тоже будет обращаться к Elasticsearch. Это отлично в каких-то случаях работает, но в данный момент это можно использовать.

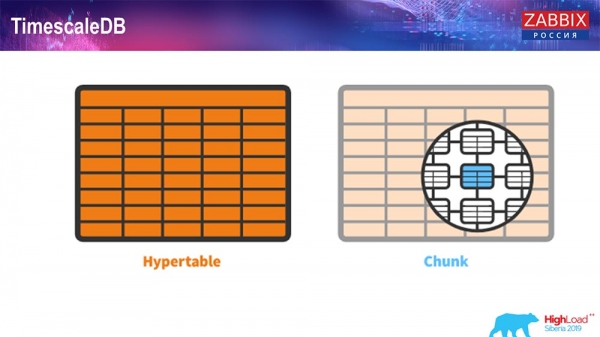
TimescaleDB. Гипертаблицы
Для 4.4.2 мы обратили внимание на одну вещь, как TimescaleDB. Что это такое? Это расширение для «Постгрес», то есть оно имеет нативный интерфейс PostgreSQL. Плюс, это расширение позволяет намного эффективнее работать с timeseries-данными и иметь автоматическое партицирование. Как это выглядит:

Это hypertable – есть такое понятие в Timescale. Это гипертаблица, которую вы создаёте, и в ней находятся чанки (chunk). Чанки – это партиции, это чайлд-таблицы, если не ошибаюсь. Это действительно эффективно.
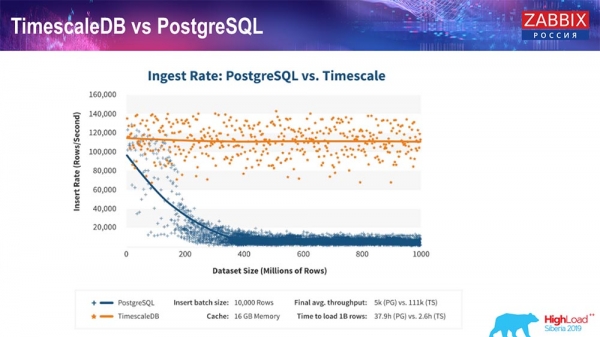
TimescaleDB и PostgreSQL
Как заверяют производители TimescaleDB, они используют более правильный алгоритм обработки запросов, в частности insert’ов, который позволяет иметь примерно постоянную производительность при увеличивающемся размере датасет-вставки. То есть после 200 миллионов строк «Постгрес» обычный начинает очень сильно проседать и теряет производительность буквально до нуля, в то время как «Таймскейл» позволяет вставлять инсерты как можно более эффективно при любом количестве данных.
Как установить TimescaleDB? Всё просто!
Есть у него в документации, описано – можно поставить из пакетов для любых… Он зависит от официальных пакетов «Постгреса». Можно скомпилировать вручную. Так получилось, что мне пришлось компилировать для БД.
На «Заббикс» мы просто активируем Extention. Я думаю, что те, кто пользовался в «Постгресе» Extention… Вы просто активируете Extention, создаёте его для БД «Заббикс», которую используете.
И последний шаг…
TimescaleDB. Миграция таблиц истории
Вам нужно создать hypertable. Для этого есть специальная функция – Create hypertable. В ней первым параметром указываете таблицу, которая в этой БД нужна (для которой нужно создать гипертаблицу).

Поле, по которому нужно создать, и chunk_time_interval (это интервал чанков (партиций, которые нужно использовать). 86 400 – это один день.
Параметр migrate_data: если вы вставляете в true, то это переносит все текущие данные в заранее созданные чанки.
Я сам использовал migrate_data – это занимает приличное время, в зависимости от того, каких размеров у вас БД. У меня было более терабайта – создание заняло больше часа. В каких-то случаях при тестировании я удалял исторические данные для текста (history_text) и стринга (history_str), чтобы не переносить – они мне на самом деле были не интересны.
И последний апдейт мы делаем в нашем db_extention: мы ставим timescaledb, чтобы БД и, в частности, наш «Заббикс» понимал, что есть db_extention. Он его активирует и использует правильно синтаксис и запросы к БД, используя уже те «фичи», которые необходимы для TimescaleDB.
Конфигурация сервера
Я использовал два сервера. Первый сервер – это виртуальная машина достаточно маленькая, 20 процессоров, 16 гигабайт оперативной памяти. Настроил на ней «Постгрес» 10.8:

Операционная система была Debian, файловая система – xfs. Сделал минимальные настройки, чтобы использовать именно эту базу данных, за вычетом того, что будет использовать сам «Заббикс». На этой же машине стоял «Заббикс»-сервер, PostgreSQL и нагрузочные агенты.

Я использовал 50 активных агентов, которые используют LoadableModule, чтобы быстро генерировать различные результаты. Это они сгенерировали строки, числа и так далее. Я забивал БД большим количеством данных. Изначально конфигурация содержала 5 тысяч элементов данных на каждый хост, и примерно каждый элемент данных содержал триггер – для того, чтобы это был реальный setup. Иногда для использования даже требуется больше одного триггера.

Интервал обновления, саму нагрузку я регулировал тем, что не только 50 агентов использовал (добавлял ещё), но и с помощью динамических элементов данных и снижал апдейт-интервал до 4 секунд.
Тест производительности. PostgreSQL: 36 тысяч NVPs
Первый запуск, первый setup у меня был на чистом PostreSQL 10 на этом железе (35 тысяч значений в секунду). В целом, как видно на экране, вставка данных занимает фракции секунды – всё хорошо и быстро, SSD-диски (200 гигабайт). Единственное, что 20 ГБ достаточно быстро заполняются.
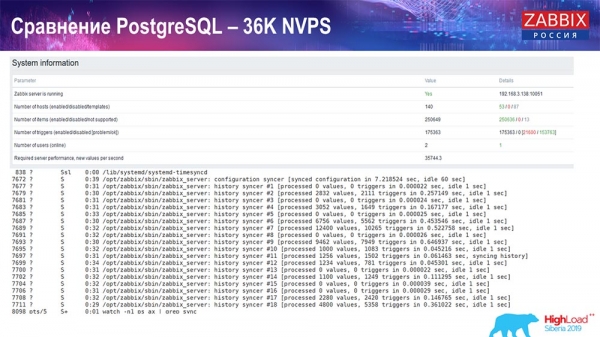
Будет дальше достаточно много таких графиков. Это стандартный dashboard производительности «Заббикс»-сервера.
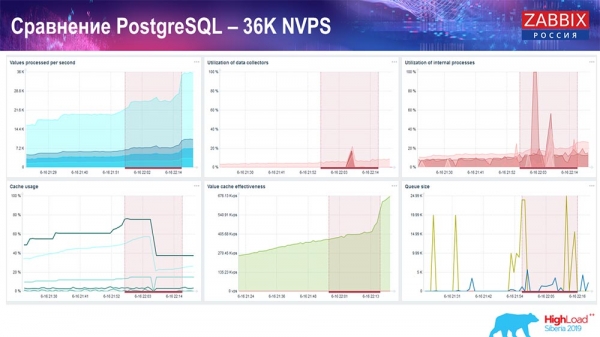
Первый график – количество значений в секунду (голубой, наверху слева), 35 тысяч значений в данном случае. Это (наверху в центре) загрузка процессов сборки, а это (наверху справа) – загрузка именно внутренних процессов: history syncers и housekeeper, который здесь (внизу в центре) выполнялся достаточное время.
Этот график (внизу в центре) показывает использование ValueCache – сколько хитов ValueCache для триггеров (несколько тысяч значений в секунду). Ещё важный график – четвёртый (внизу слева), который показывает использование HistoryCache, о котором я рассказал, который является буфером перед вставкой в БД.
Тест производительности. PostgreSQL: 50 тысяч NVPs
Далее я увеличил нагрузку до 50 тысяч значений в секунду на этом же железе. При загрузке «Хаускипером» 10 тысяч значений записывалось уже в 2-3 секунды с вычислением. Что, собственно, показано на следующем скриншоте:
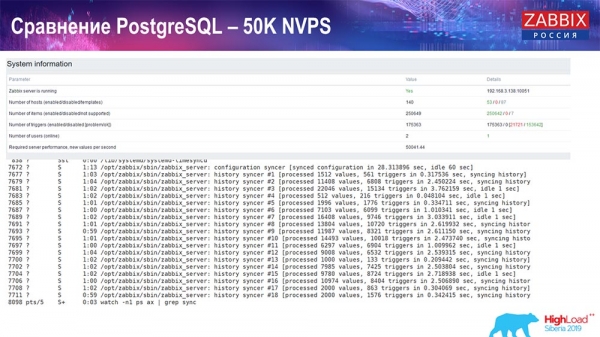
«Хаускипер» уже начинает мешать работе, но в целом загрузка трапперов хистори-синкеров пока ещё находится на уровне 60 % (третий график, вверху справа). HistoryCache уже во время работы «Хаускипера» начинает активно заполняться (внизу слева). Он был около полгигабайта, заполнялся на 20%.
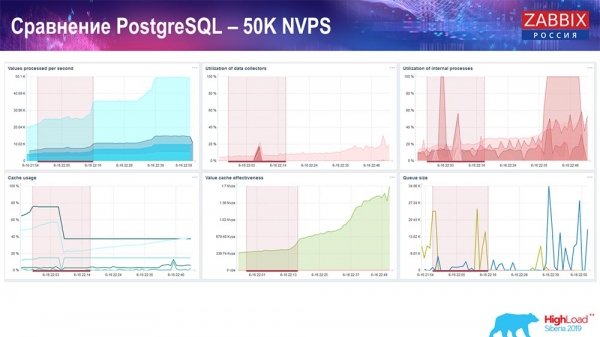
Тест производительности. PostgreSQL: 80 тысяч NVPs
Дальше увеличил до 80 тысяч значений в секунду:
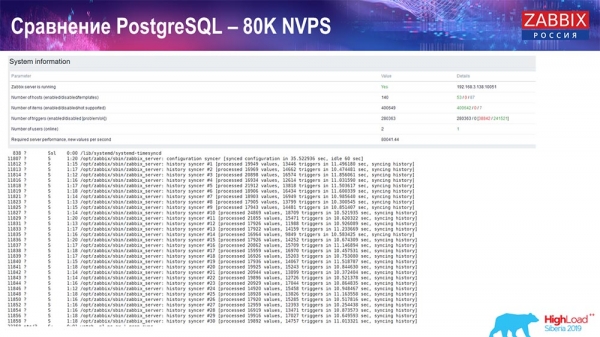
Это было примерно 400 тысяч элементов данных, 280 тысяч триггеров. Вставка, как видите, по загрузке хистори-синкеров (их было 30 штук) была уже достаточно высокая. Дальше я увеличивал различные параметры: хистори-синкеры, кэш… На данном железе загрузка хистори-синкеров начала увеличиваться до максимума, практически «в полку» – соответственно, HistoryCache пошёл в очень высокую загрузку:
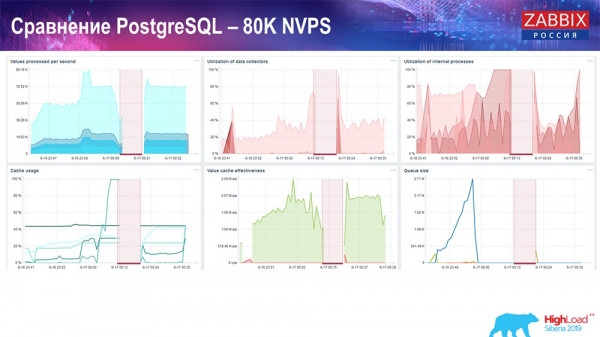
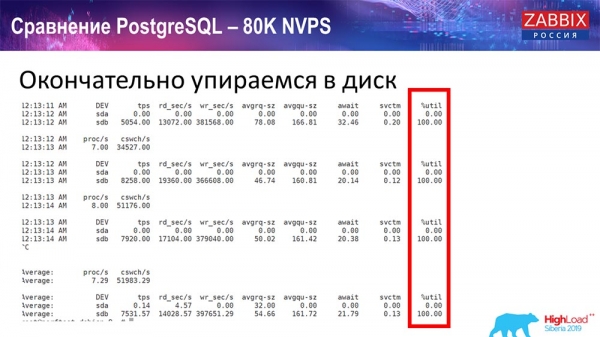
Всё это время я наблюдал за всеми параметрами системы (как процессор используется, оперативная память) и обнаружил, что утилизация дисков была максимальной – я добился максимальной возможности этого диска на этом железе, на этой виртуальной машине. «Постгрес» начал при такой интенсивности сбрасывать данные достаточно активно, и диск уже не успевал на запись, чтение…
Я взял другой сервер, который уже имел 48 процессоров 128 гигабайт оперативной памяти:
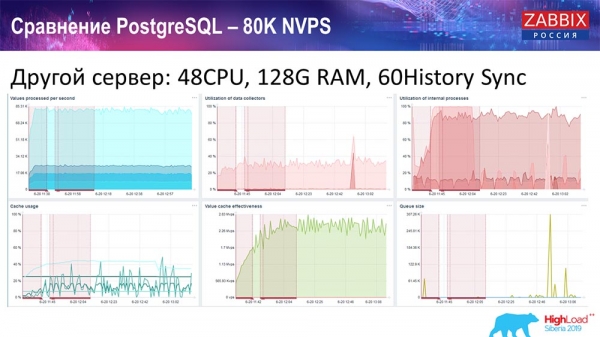
Также я его «затюнил» – поставил History syncer (60 штук) и добился приемлемого быстродействия. Фактически мы не «в полке», но это уже, наверное, предел производительности, где уже необходимо что-то с этим предпринимать.
Тест производительности. TimescaleDB: 80 тысяч NVPs
У меня была главная задача – использовать TimescaleDB. На каждом графике виден провал:
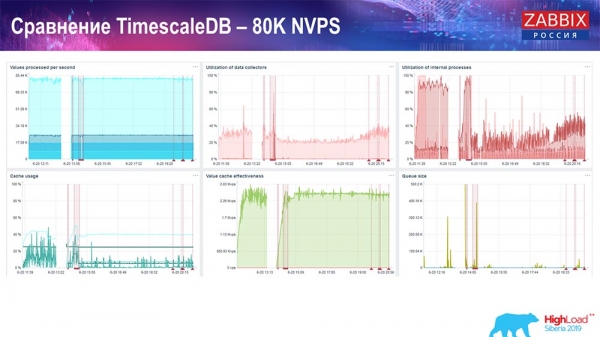
Эти провалы – как раз миграция данных. После этого в «Заббикс»-сервере профиль загрузки хистори-синкеров, как вы видите, очень сильно изменился. Он практически в 3 раза быстрее позволяет вставлять данные и использовать меньше HistoryCache – соответственно, у вас своевременно будут поставляться данные. Опять же, 80 тысяч значений в секунду – это достаточно высокий rate (конечно, не для «Яндекса»). В целом это достаточно большой setup, с одним сервером.
Тест производительности PostgreSQL: 120 тысяч NVPs
Далее я увеличил значение количества элементов данных до полумиллиона и получил расчётное значение 125 тысяч в секунду:
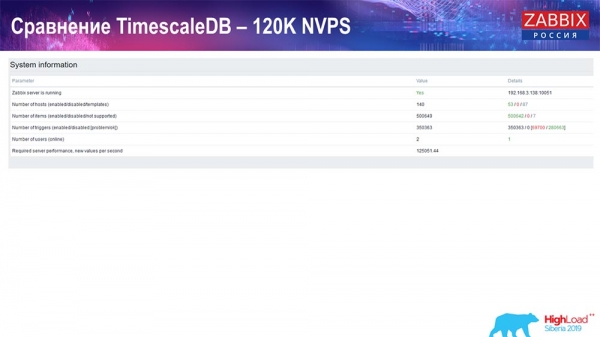
И получил такие графики:
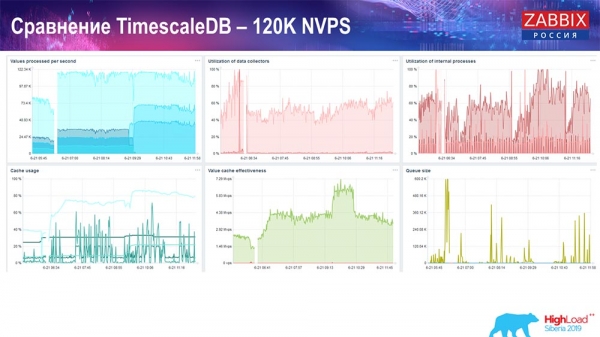
В принципе это рабочий setup, он может достаточно длительное время работать. Но так как у меня был диск всего на 1,5 терабайта, то я его расходовал за пару дней. Самое важное, что в то же время создавались новые партициина TimescaleDB, и это для производительности проходило совершенно незаметно, чего не скажешь о MySQL.
Обычно партиции создаются ночью, потому что это блокирует вообще вставку и работу с таблицами, может приводить к деградации сервиса. В данном случае этого нет! Главная задача была – проверить возможности TimescaleDB. Получилась такая цифра: 120 тысяч значений в секунду.
Также есть в «комньюнити» примеры:
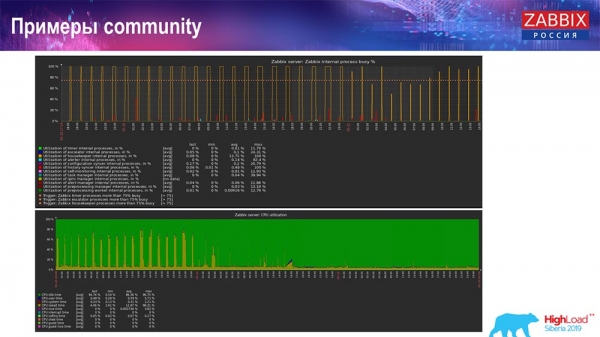
Человек тоже включил TimescaleDB и загрузка по использованию io.weight упала на процессоре; и использование элементов внутренних процессов тоже снизилось благодаря включению TimescaleDB. Причём это обычные блинные диски, то есть обычная виртуалка на обычных дисках (не SSD)!
Для каких-то маленьких setup’ов, которые упираются в производительность диска, TimescaleDB, как мне кажется, очень хорошее решение. Оно неплохо позволит продолжать работать до того, как мигрировать на более быстрое железо для базы данных.
Приглашаю всех вас на наши мероприятия: Conference – в Москве, Summit – в Риге. Используйте наши каналы – «Телеграм», форум, IRC. Если у вас есть какие-то вопросы – приходите к нам на стойку, можем поговорить обо всём.
Вопросы аудитории
Вопрос из аудитории (далее – А): – Если TimescaleDB так просто в настройке, и он даёт такой прирост производительности, то, возможно, это стоит использовать как лучшую практику настройки «Заббикса» с «Постгресом»? И есть ли какие-то подводные камни и минусы этого решения, или всё-таки, если я решил себе делать «Заббикс», я могу спокойно брать «Постгрес», ставить туда «Таймскейл» сразу, пользоваться и не думать ни о каких проблемах?

АГ: – Да, я сказал бы, что это хорошая рекомендация: использовать «Постгрес» сразу с расширением TimescaleDB. Как я уже говорил, множество хороших отзывов, несмотря на то, что эта «фича» экспериментальна. Но на самом деле тесты показывают, что это отличное решение (с TimescaleDB), и я думаю, что оно будет развиваться! Мы следим за тем, как это расширение развивается и будем править то, что нужно.
Мы даже во время разработки опирались на одну их известную «фичу»: там можно было с чанками немного по-другому работать. Но потом они это в следующем релизе выпилили, и нам пришлось уже не опираться на этот код. Я бы рекомендовал использовать это решение на многих setup’ах. Если вы используете MySQL… Для средних setup’ов любое решение неплохо работает.
A: – На последних графиках, которые от community, был график с «Хаускипером»:
Он продолжил работать. Что «Хаускипер» делает в случае с TimescaleDB?
АГ: – Сейчас не могу точно сказать – посмотрю код и скажу более подробно. Он использует запросы именно TimescaleDB не для удаления чанков, а как-то агрегирует. Пока я не готов ответить на этот технический вопрос. На стенде сегодня или завтра уточним.
A: – У меня похожий вопрос – о производительности операции удаления в «Таймскейл».
А (ответ из аудитории): – Когда вы удаляете данные из таблицы, если вы это делаете через delete, то вам нужно пройтись по таблице – удалить, почистить, пометить всё на будущий вакуум. В «Таймскейл», так как вы имеете чанки, вы можете дропать. Грубо говоря, вы просто говорите файлу, который лежит в big data: «Удалить!»
«Таймскейл» просто понимает, что такого чанка больше нет. И так как он интегрируется в планировщик запроса, он на хуках ловит ваши условия в select’е или в других операциях и сразу понимает, что этого чанка больше нет – «Я туда больше не пойду!» (данные отсутствуют). Вот и всё! То есть скан таблицы заменяется на удаление бинарного файла, поэтому это быстро.
A: – Уже затрагивали тему не SQL. Насколько я понимаю, «Заббиксу» не очень нужно модифицировать данные, а всё это – что-то вроде лога. Можно ли использовать специализированные БД, которые не могут менять свои данные, но при этом гораздо быстрее сохраняют, накапливают, отдают – Clickhouse, допустим, что-нибудь кафка-образное?.. Kafka – это же тоже лог! Можно ли их как-то интегрировать?
АГ: – Выгрузку можно сделать. У нас есть определённая «фича» с версии 3.4: вы можете писать в файлы все исторические файлы, ивенты, всё прочее; и дальше каким-то обработчиком отсылать в любую другую БД. На самом деле много кто переделывает и пишет напрямую в БД. На лету хистори-синкеры всё это пишут в файлы, ротируют эти файлы и так далее, и это вы можете перекидывать в «Кликхаус». Не могу сказать о планах, но, возможно, дальнейшая поддержка NoSQL-решений (таких, как «Кликхаус») будет продолжаться.
A: – Вообще, получается, можно полностью избавиться от постгреса?
АГ: – Конечно, самая сложная часть в «Заббиксе» – это исторические таблицы, которые создают больше всего проблем, и события. В этом случае, если вы не будете долго хранить события и будете хранить историю с трендами в каком-то другом быстром хранилище, то в целом никаких проблем, думаю, не будет.
A: – Можете оценить, насколько быстрее всё будет работать, если перейти на «Кликхаус», допустим?
АГ: – Я не тестировал. Думаю, что как минимум тех же цифр можно будет достичь достаточно просто, учитывая, что «Кликхаус» имеет свой интерфейс, но не могу сказать однозначно. Лучше протестировать. Всё зависит от конфигурации: сколько у вас хостов и так далее. Вставка – это одно, но нужно ещё забирать эти данные – Grafana или ещё чем-то.
A: – То есть речь идёт о равной борьбе, а не о большом преимуществе этих быстрых БД?
АГ: – Думаю, когда интегрируем, будут более точные тесты.
A: – А куда делся старый добрый RRD? Что заставило перейти на базы данных SQL? Изначально же на RRD все метрики собирались.
АГ: – В «Zabbix» RRD, может быть, в очень древней версии был. Всегда были SQL-ные базы – классический подход. Классический подход – это MySQL, PostgreSQL (очень давно уже существуют). У нас общий интерфейс для баз данных SQL и RRD мы практически никогда не использовали.


Veidi reklaami 🙂
Aitäh, et olete meiega. Kas teile meeldivad meie artiklid? Kas soovite näha rohkem huvitavaid materjale? Toetage meid, tehes tellimuse või soovitades meid tuttavatele. , ainulaadne sisenemise taseme serverite analoog, mille oleme teie jaoks välja mõelnud: (saadaval on RAID1 ja RAID10 variandid, kuni 24 südamikku ja kuni 40GB DDR4).
Kas Dell R730xd on kaks korda odavam Equinixi Tier IV andmete keskuses Amsterdamis? Ainult meie juures Hollandi turul! Dell R420 — 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB — alates $99! Lugege, kuidas
Allikas: habr.com
