

Kõik räägivad arenduse ja testimise protsessidest, personali koolitamisest, motivatsiooni tõstmisest, kuid need protsessid on väheolulised, kui teenuse seiskumise minut maksab kosmilisi summasid. Mida teha, kui teete rahandustehinguid ranged SLA raames? Kuidas suurendada oma süsteemide usaldusväärsust ja talitlushäiret taluma, jättes arenduse ja testimise kõrvale?

Järgmine konverents HighLoad++ toimub 6. ja 7. aprillil 2020 Peterburis. Üksikasjad ja piletid . 9. novembril, kell 18:00. HighLoad++ Moskva 2018, saal "Delhi + Calcutta". Teesid ja .
Evgeni Kuzovlev (edaspidi – EK): – Tere, sõbrad! Minu nimi on Kuzovlev Evgeni. Olen ettevõttest EcommPay, täpsemalt – EcommPay IT, grupi IT-osakond. Ja täna räägime teiega seisakutest – kuidas neid vältida ja kuidas minimeerida nende tagajärgi, kui vältimine ei õnnestunud. Teema on selline: "Mida teha, kui minut seiskumist maksab 100 000 dollarit"? Meil on, et ette vaadates, numbrid on võrreldavad.
Millega tegeleb EcommPay IT?
Kes me oleme? Miks ma siin teie ees seisan? Miks mul on õigus teile midagi rääkida? Ja millest me siin põhjalikumalt räägime?
EcommPayi ettevõtete grupp on rahvusvaheline makseteenuse pakkuja. Me töötleme makseid üle kogu maailma – Venemaal, Euroopas ja Kagu-Aasias. Meil on 9 kontorit, kokku 500 töötajat, millest veidi vähem kui pooled on IT-spetsialistid. Kõik, mida me teeme, ja kõik, millega raha teenime, tuleb meist endist.
Kõik meie tooted (ja meil on neid piisavalt palju – meie suure IT-toodete rikkaine on umbes 16 erinevat komponente) on meie enda loodud; me kirjutame need ise, arendame ise. Ja praegu teeme me umbes miljon tehingut päevas (miljonid – ilmselt on see õige öelda). Me oleme suhteliselt noor ettevõte – meid on tegutsenud umbes kuus aastat.
Kuus aastat tagasi oli see selline idufirma, kui tulid poisid koos äriideega. Nad olid seotud ideega (mitte kui muuga, peale idee), ja me alustasime. Nagu iga idufirma, jooksime me kiiremini... Meie jaoks oli olulisem kiirus, mitte kvaliteet.
Millalgi peatusime: mõistsime, et me ei saa enam sama kiirusel ja kvaliteediga elada, seega peame keskenduma kvaliteedile. Sel hetkel otsustasime kirjutada uue platvormi, mis oleks õige, skaleeritav ja usaldusväärne. Selle platvormi arendamine algas (me hakkasime investeerima, arendama, testima), kuid mingil hetkel mõistsime, et arendus ja testimine ei luba meil saavutada uut teenuse kvaliteeditaset.
Te loote uue toote, viite selle tootmisse, kuid ikkagi läheb kuskil midagi valesti. Ja täna räägime sellest, kuidas saavutada uus kvaliteeditase (kuidas meie seda tegime, meie kogemus), jättes välja arenduse ja testimise; arutame, mida tootmine saab ise teha, mida ta testimisele pakkuda saab, et mõjutada kvaliteeti.
Seisakud. Tootmise käsud.
Alati peamine nurgakivi, millest me täna räägime, on seisaku aeg. Kohutav sõna. Kui meil tekib seisak, siis on asjad halvasti. Me kipume kohe tegutsema, süsteemiadministraatorid hoiavad serverit – lootkem, et see ei kuku, nagu laul räägib. Just sellest me täna räägime.

Kui hakkasime oma lähenemisi muutma, koostasime neli käsku. Need on mul esitatud slaididel:
Need käsud on piisavalt lihtsad:

- Probleemi kiire tuvastamine.
- Probleemi veelgi kiiremini lahendamine.
- Aidata mõista põhjust (hiljem, arendajatele).
- Ja lähenemiste standardiseerimine.
Joonitan tähelepanu punktile nr 2. Me eemaldate probleemi, mitte ei lahenda seda. Lahendada on teisejärguline. Meie jaoks on esmatähtis, et kasutaja oleks kaitstud selle probleemi eest. Probleem eksisteerib mingis isoleeritud keskkonnas, kuid see keskkond ei puutu tema ellu. Tegelikult käime läbi need neli probleemigruppi (mõnest räägime lähemalt, mõnest vähem), ja jagan, mida me kasutame ning milline on meie vastav kogemus lahendustes.
Probleemide lahendamine: kui need juhtuvad ja mida nendega teha?
Kuid alustame mitte järjekorras, vaid punktist nr 2 – kuidas kiiresti probleemist vabaneda? Probleem on olemas – me peame selle lahendama. „Mida me sellega teeme?“ – see on peamine küsimus. Ja kui hakkasime mõtlema, kuidas probleemi lahendada, töötasime välja mõned nõuded, millega probleemide lahendamine peab vastama.

Need nõuded sõnastamiseks otsustasime endale esitada küsimus: „Millal meil probleemid tekivad?“ Ja probleemid, nagu selgus, esinevad neljas olukorras:

- Riistvara rike.
- Välisteenuste tõrge.
- Tarkvara versiooni vahetamine (see sama deploy).
- Koormuse plahvatuslik kasv.
Esimeste kahe kohta me rääkima ei hakka. Riistvara rike lahendatakse piisavalt lihtsalt: kõigil asjadel peaks olema varukoopia. Kui need on kettad – kettad peavad olema RAID-is ühendatud, kui see on server – server peab olema varustatud, kui teil on võrguinfrastruktuur – peate seadma teise võrguinfrastruktuuri koopia, see tähendab, et võtate ja dubleerite. Ja kui teil midagi nurjub, lülitute varuressurssidele. Siin on keeruline rohkem midagi öelda.
Teiseks on see väline teenus, mis ei tööta. Enamiku süsteemide jaoks ei ole see probleem, kuid mitte meie jaoks. Kuna me töötleme makseid, oleme me agendiks, kes seisab kasutaja (kes sisestab oma kaardid) ja pankade, maksesüsteemide („Visa”, „MasterCard”, „Mir”) vahel. Meie välisteenustel (maksesüsteemidel, pankadel) on kalduvus tõrkuda. Seda ei saa mõjutada ei meie ega teie (kui teil on sellised teenused).
Mida sel juhul teha? Siin on kaks võimalust. Esiteks, kui saate, peaksite selle teenuse kuidagi kahekordistama. Näiteks, kui saame, suuname me trafiku ühest teenusest teise: töötlesime näiteks kaarte läbi „Sberbank”, kui „Sberbankil” on probleeme – suuname trafiku [tinglikult] „Raiffeiseni”. Teiseks, mida me saame teha, on väga kiiresti märgata välisteenuste tõrkeid ja seetõttu räägime reaktsiooni kiirusest järgmises aruande osas.
Meie arvates saame nendest neljast konkreetselt mõjutada tarkvaraversiooni vahetust – teha samme, mis aitavad olukorda parandada nii juurutamiste kui ka kiire koormuse kasvu kontekstis. Just seda me tegime. Siinkohal väikene märkuse koht…
Mõned neist neljast probleemist lahendatakse kohe, kui teil on pilv. Kui olete Microsoft Azure'i, Ozone'i, meie Yandexi või Mail.ru pilvedes, siis muutub vähemalt riistvararikkumine nende probleemiks ning teie olukord paraneb kohe riistvararikkumise osas.
Me oleme natuke ebatavaline ettevõte. Siin kõik räägivad Kubernetesest ja pilvedest – meil ei ole ei Kuberneteset ega pilvi. Meie jaoks on olemas serverid paljudes andmekeskustes ja me peame sellel riistvaral elama, peame vastutama selle eest. Seetõttu räägime sellest kontekstist. Nii et probleemidest. Esimese kaks jätsime kõrvale.
Tarkvaraversiooni vahetus. Andmebaasid
Meie arendajatel ei ole juurdepääsu tootmisraami. Miks? Sest oleme sertifitseeritud PCI DSS-i järgi ning meie arendajad ei tohi lihtsalt „prod”-i sisse minna. Ja kõik, punkt. Täiesti. Seetõttu lõppeb arenduse vastutus just siis, kui arendus on üle andnud versiooni väljalaskmiseks.

Teine põhineb, millele toetume ja mis meid samuti väga aitab – see, et meil puuduvad unikaalsed dokumenteerimata teadmised. Loodan, et teil on samuti. Sest kui ei ole, siis tekkivad probleemid. Probleemid ilmnevad siis, kui neid unikaalseid, dokumenteerimata teadmisi ei ole õigeaegselt õiges kohas. Oletame, et teil on üks inimene, kes teab, kuidas konkreetset komponenti juurutada – kui seda inimest pole, ta on puhkusel või haige – siis ongi probleemid kohal.
Ja kolmas põhjus, millele me jõudsime. Me jõudsime sellele läbi valu, vere ja pisarate – me jõudsime arusaamisele, et iga meie versioon sisaldab vigu, isegi kui seal ei tundu olevat vigu. Oleme enda jaoks otsustanud: kui me midagi juurutame, kui me midagi tootmisse viime – siis on meie versioon vigadega. Oleme vormistanud nõuded, millest meie süsteem peab kinnipidama.
Tarkvara versiooni vahetuse nõuded
Need nõuded on kolm:

- Peame saama kiiresti tagasi pöörduda.
- Peame minimeerima ebaõnnestunud juurutamise mõju.
- Ja me peame olema võimelised kiiresti paralleelselt juurutama.
Just sellises järjekorras! Miks? Sest esmajärjekorras ei ole uue versiooni juurutamise puhul oluline kiirus, aga teil on tähtis, kui midagi läheb valesti, kiiresti tagasi pöörduda ja mõju minimeerida. Kuid kui teil on tootmisversioonide komplekt, kus on selgunud, et seal on viga (nagu välk selgest taevast, juurutamist ei olnud, aga viga on olemas) – on kiirus järgnevate juurutamiste puhul tähtis. Mida me oleme teinud, et neid nõudeid rahuldada? Oleme kasutanud sellist metoodikat:
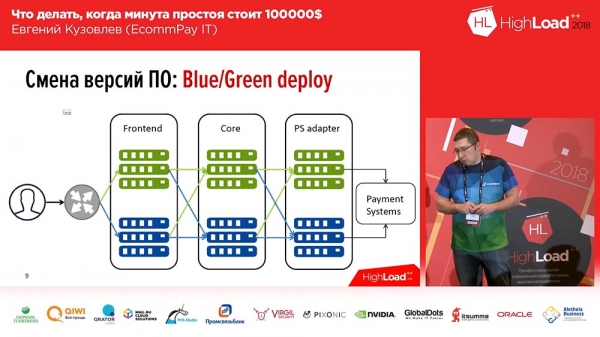
See on piisavalt tuntud, me ei ole seda mitte kordagi leiutanud – tegemist on Blue/Green juurutamisega. Mis see on? Igal teie serverigruppidel, kus asuvad teie rakendused, peab olema koopiat. Koopiat, mis on ‘soe’: sellele ei suunata liiklust, kuid vajadusel saab selle liikluse sellele koopiale suunata. See koopia sisaldab eelmist versiooni. Juurutamise hetkel installite koodi mitteaktiivsele koopiale. Seejärel suunate osa liiklust (või kogu) uuele versioonile. Sel viisil, et muuta liiklusvoogu vanalt versioonilt uuele, peate tegema vaid ühe toimingu: peate upstreamis muutma koormuse jaotajat, muutma suunda – ühest upstreamist teise. See on väga mugav ja lahendab kiire vahetamise ning kiire tagasivõtmise probleemi.Siin on ka teise küsimuse lahendus – minimaliseerimine: te saate suunata uuele realle, uue koodiga, ainult osa oma liiklusest (näiteks 2%). Ja need 2% – need ei ole 100%! Kui teie liiklus kaob 100% ebaõnnestunud juurutamise tõttu – on see hirmutav, kui aga kaob 2% liiklust – see on ebameeldiv, kuid ei ole hirmutav. Veelgi enam, kasutajad tõenäoliselt isegi ei märka seda, kuna teatud juhtudel (mitte kõigis) sama kasutaja, vajutades F5, satub ta teisele, töötavale versioonile.
Blue/Green juurutamine. Suunamine
Kuid kõik ei ole nii lihtne kui „Blue/Green juurutamine”… Kõik meie komponendid saab jagada kolme gruppi:
- see on front-end (makse lehed, mida meie kliendid näevad);
- tuumprotsess;
- adapter maksesüsteemide (pangad, „MasterCard”, „Visa”…) töötamiseks.
Siin on aga nüanss – see puudutab liinide vahelist suunamist. Kui te lihtsalt suunate 100% liiklust, siis pole teil neid probleeme. Kuid kui soovite suunata 2%, tekivad küsimused: "Kuidas seda teha?" Lihtsaim viis on: võite seadistada juhusliku valiku, Round Robin nginx'is, ja teil on 2% – vasakule, 98% – paremale. Kuid see ei sobi alati.
Meil näiteks suhtleb kasutaja süsteemiga mitte ühe päringu kaudu. See on normaalne: 2, 3, 4, 5 päringut – teie süsteemid võivad olla samasugused. Ja kui on oluline, et kõik kasutaja päringud tuleksid samasse liini, kuhu tuli esimene päring, või (teine punkt) et kõik kasutaja päringud tuleksid uuele liinile pärast vahetust (kasutaja võis alustada töötamist süsteemiga enne vahetust) – siis ei sobi juhuslik jaotamine. Siis on järgmised variandid:
Esimene variant, kõige lihtsam – põhineb kliendi baaselementidel (IP Hash). Teil on IP ja jagate seda vasakule-paremale. Siis toimib teine minu kirjeldatud olukord, kui on toimunud juurutamine, ja kasutaja on juba hakanud teiega töötama. Juurutamise hetkest alates saadetakse kõik päringud uuele joonele (samale, ütleme).Kui see mingil põhjusel ei sobi ja peate kindlasti saatma päringud sellele joonele, kuhu tuli esmane, initsiaalne päring, siis on teil kaks varianti …
Esimene variant: saate kasutada tasulist nginx+. Seal on mehhanism Sticky sessions, mis esialgse kasutaja päringu korral määrab kasutajale seansi ja seondab selle teatud apstrimiga. Kõik edasised kasutaja päringud seansi kehtivuse jooksul saadetakse sama apstrimi juurde, kuhu seanss määrati.See ei sobinud meile, kuna meil oli juba tavaline nginx. Üleminek nginx+ – see ei olnud just kallis, lihtsalt meie jaoks oli see veidi valuline ja ebaõige. 'Session stick' ei töötanud näiteks meie jaoks põhimõtteliselt selle tõttu, et 'Session stick' ei võimalda suunata tunnuse järgi 'Või-või'. Seal saab määrata, et teeme 'Session stick' näiteks IP-aadressi või IP-aadressi ja küpsiste või POST-põhiste parameetrite järgi, aga 'Või-või' on sealt juba keerulisem.
Seetõttu jõudsime neljanda variandi juurde. Võtsime nginx 'steroidide' peal (see on openresty) – see on sama nginx, mis toetab lisaks ka last-skripte. Saate kirjutada last-skripti, edastada selle 'openresty'le ja see last-skript käivitatakse, kui kasutaja päring tuleb.
Ja me kirjutamine selline skript, installisime endale 'openresty' ja selles skriptis läbime 6 erinevat parameetrit 'Või' kombinatsiooni kaudu. Sõltuvalt sellest, milline parameeter on olemas, teame, et kasutaja tuli ühele leheküljele või teisele, ühele liinile või teisele.
Blue/Green deploy. Eelised ja puudused.
Muidugi, oleks olnud võimalik teha natuke lihtsamalt (kasutades näiteks „Sticky sessions”), kuid meil on veel selline nüanss, et meiega ei suhtle ainult kasutaja ühe tehingu raames... Meiega suhtlevad ka maksesüsteemid: pärast tehingu töötlemist (saates päringu maksesüsteemile) saame tagasiside.
Oletame, et kui meie kontuuris saame kasutaja IP-aadressi kõikides päringutes edastada ja selle alusel kasutajate IP-aadresse eristada, siis me ei ütle näiteks „Visa”-le: „Me oleme selline retrofirma, me paistame olevat rahvusvaheline (meie veebis ja Venemaal)… Palun saatke meile kasutaja IP-aadress lisaks lisaväljal, teie standardiseeritud protokolliga!” Loomulikult nad ei nõustu.
Seetõttu see meile ei sobinud – me tegime openresty. Vastavalt on meie suunamine välja näinud nii:„Blue/Green deployment” on, vastavalt, omadused, millest ma rääkisin, ja puudused.
Puudusi on kaks:
- teile tuleb tegeleda suunamisega;
- teine põhjalik puudus on kulud.
Teiltes rohkem servereid, teil on rohkem operatiivresources, peate kulutama rohkem energiat kogu selle loomaaia hooldamiseks.
Muide, eeliste seas on veel üks asi, mida ma varem maininud ei ole: teil on varukohad koormuse kasvu korral. Kui teil on plahvatuslik koormus, saabub suur hulk kasutajaid, siis lülitate lihtsalt teise taseme 50/50 ja teil on kohe 2x rohkem servereid teie klastris, kuni leiate lahenduse serverite olemasolu probleemile.
Kuidas teha kiiret juurutamist?
Me rääkisime probleemide vähendamisest ja kiirest tagasikäigust, aga küsimus jääb: „Kuidas kiiresti juurutada“?
Siin on lühidalt ja kõik on lihtne.- Teil peab olema CD-süsteem (Continuous Delivery) – ilma selleta ei saa. Kui teil on üks server, saate käsitsi juurutada. Meil on umbes tuhat viissada serverit ja käsitsi viissada, see on selge – me saame maha istuda sama suuruse osakonna, et lihtsalt juurutada.
- Déployimine peab olema paralleelne. Kui teil on järkjärguline deploy, siis on kõik halvasti. Üks server – see on normaalne, tuhat viis sada serverit eemaldate terve päeva.
- Jälle, kiirendamiseks, see pole enam kohustuslik, ilmselt. Deployimise ajal toimub tavaliselt projekti kogumine. Kas teil on veebiprojekt, on seal front-end osa (teete seal veebipaki, kogute npm-i – midagi sellist), ja see protsess ei kesta põhimõtteliselt kaua – umbes 5 minutit, kuid need 5 minutit võivad olla kriitilise tähtsusega. Seetõttu me näiteks nii ei tee: me oleme need 5 minutit ära võtnud, me deployime artefakte.
Mis on artefakt? Artefakt on kogutud versioon, kus kogu koostamisprotsess on juba lõpule viidud. Seda artefakti hoiame artefaktide ladustamises. Selliseid ladustamisi kasutasime varem kahte – see oli Nexus ja praegu jFrog Artifactory. 'Nexus' oli algselt kasutusele võetud, kuna alustasime seda lähenemist Java rakendustes (see sobis sellele lähenemisele hästi). Hiljem lisasime sinna osa rakendusi, mis on kirjutatud PHP-s; siis 'Nexus' enam ei sobinud ja seetõttu valisime jFrog Artifactory, mis suudab artefaktida peaaegu kõike. Oleme jõudnud isegi selleni, et selles artefaktide ladustamises hoiame oma binaarpakette, mille serverite jaoks kogume.
Plahvatuslik koormuse kasv
Rääkisime tarkvaraversiooni vahetamisest. Järgmiseks on meil plahvatuslik koormuse kasv. Siin, ilmselt, mõistan plahvatuslikku koormuse kasvu veidi valesti...
Oleme loonud uue süsteemi – see on teenustele suunatud, moodne ja ilus, igal pool töötajad, igal pools järjekorrad, igal pool asünkroonsus. Sellistes süsteemides võivad andmed liikuda erinevates voogudes. Esimese tehingu jaoks võivad osaleda 1., 3. ja 10. töötaja, teise tehingu jaoks – 2., 4. ja 5. Ja täna, ütleme, hommikul, on teil andmevoog, mis kasutab esimesi kolme töötajat, aga õhtul muutub see järsult ja kõik kasutab teisi kolme töötajat.
Ja siin on niimoodi, et peate kuidagi töötajaid skaalama, peate kuidagi oma teenuseid skaalama, kuid samas ei tohi lubada ressursside paisumist.
Oleme määratlenud endale nõuded. Need nõuded on piisavalt lihtsad: et seal oleks teenuse avastamine, parameetriseerimine – kõik on standardne selliste skaleeritavate süsteemide ehitamiseks, välja arvatud üks punkt – see on ressursside amortiseerimine. Olime öelnud, et me ei ole valmis ressursse amortiseerima, et serverid õhku soojendaksid. Võtsime „Consul’i”, võtsime „Nomadi”, mis haldab meie töötajaid.Miks on see meie jaoks probleem? Vaatame natuke tagasi. Meie taga on hetkel umbes 70 maksesüsteemi. Hommikul suunatakse liiklus läbi „Sberbanki”, seejärel võib näiteks „Sberbank” kokku kukkuda ja me peame liikuma teise maksesüsteemi. Meil oli 100 töötajat, kui „Sberbank” töötas, kuid pärast seda peame kiiresti tõstma 100 töötajat teise maksesüsteemi jaoks. Ja see kõik peaks ideally toimuma ilma inimeste sekkumiseta. Kuna kui on inimeste sekkumine, peab insener olema 24/7 valvel, et sellega tegeleda, kuna selliseid tõrkeid, kui 70 süsteemi on su selja taga, juhtub regulaarselt.
Seetõttu vaatasime „Nomadit”, millel on avatud IP, ja kirjutasime oma süsteemi Scale-Nomad – ScaleNo, mis teeb järgmised asjad: ta jälgib järjekorra kasvu ja vähendab või suurendab töötajate arvu sõltuvalt järjekorra dünaamikast. Kui olime selle valmis saanud, mõtlesime: „Kas võiks seda avatud allikana jagada?” Siis vaatasime sellele – see on nii lihtne, kui kaks senti.
Me ei ole seda avatud lähtekoodiga teinud, kuid kui pärast esitlust, tunnete, et teil on sellist lahendust vaja, siis viimases slaidis on minu kontaktandmed – palun kirjutage mulle. Kui leidub vähemalt 3–5 inimest, siis me teeme selle avatud lähtekoodiga.
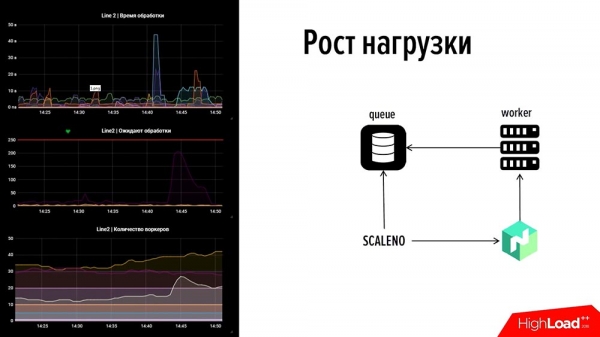
Kuidas see töötab? Vaatame! Küll aga karte eelnevalt: vasakul on meie jälgimise osa: see on üks joon, ülaosas – sündmuste töötlemise aeg, keskel – tehingute arv, all – töötajate arv.Kui vaatame, siis sellel pildil on tõrge. Ülemisel graafikul on üks joon välja kukkunud 45 sekundi jooksul – üks maksesüsteem kukkus. Siin on kaks minutit liiklust ja järsu tõusu kasv teises maksesüsteemis, kus töötajaid polnud (me ei kasutanud ressursse – vastupidi, kasutasime ressurssi õigesti). Me ei tahtnud üle koormata – seal oli minimaalne arv, umbes 5–10 töötajat, kuid nad ei tulnud toime.
Viimases graafikus on näha "mügarik", mis näitab, et "Skaaleno" tõstis selle arvu kahekordselt. Ja siis, kui graafik veidi langes, vähendas see veidi automaatrežiimis töötajate arvu. Nii see asi töötab. Rääkisime punktist nr 2 – "Kuidas kiiresti põhjustest vabaneda?"
Jälgimine. Kuidas kiiresti probleemi avastada?
Nüüd on esimene punkt – "Kuidas kiiresti probleemi avastada?" Jälgimine! Me peame kiiresti aru saama teatud asjadest. Millistest asjadest peame kiiresti aru saama?
Kolm asja!- Me peame kiiresti mõistma ja kiiresti mõistma meie enda ressursside töövõimet.
- Me peame kiiresti mõistma rikete märkamist, jälgima süsteemide töövõimet, mis on meile välistest allikatest.
- Kolmas punkt – loogiliste vigade tuvastamine. See on siis, kui süsteem töötab, kõik näitajad on normis, kuid midagi ei ole õigesti.
Siin ei räägi ma tõenäoliselt midagi nii ägedat. Olen nagu nähtav kapten. Otsisime turult, mis seal on. Meil on tekkinud "naljakas loomaaiad". Nii on meil nüüd tekkinud loomaaed:
Meil kasutatakse «Zabbix»-it riistvara jälgimiseks ning põhiserverite võtmeindikaatorite jälgimiseks. Andmebaaside jaoks kasutame «Okmeter»-it. «Grafana» ja «Prometheus» jälgivad kõiki teisi näitajaid, mis ei kuulu kahe esimesse kategooriasse; osa neist jälgitakse «Grafana» ja «Prometheus» abil, osa «Grafana» koos «Influx»-i ja Telegraf-iga.Aasta tagasi tahtsime kasutada New Relic-i. Väga äge tööriist, ta suudab kõike. Aga seda, kui palju ta suudab, tuleneb ka tema kõrgest hinnast. Kui meie serverite arv kasvas 1500-ni, tuli meile müügimees ja ütles: «Lähme järgmiseks aastaks lepingut sõlmima». Kui me hinda vaatasime, otsustasime, et ei, me seda teha ei saa. Praegu loobume «New Relic»-ist, meil on alles umbes 15 serverit, mis on veel «New Relic»-i all jälgimisel. Hind osutus täiesti uskumatu.
Ja on üks tööriist, mille me ise välja töötasime – see on Debugger. Alguses nimetasime seda 'Baggeriks', kuid hiljem käis meil inglise keele õpetaja, kes naeris valjult ja me nimetatelime selle ümber 'Debuggeriks'. Mis see on? See on tööriist, mis viib läbi 15–30 sekundi jooksul igas komponendis, nagu 'must kast' süsteemis, testid komponentide üldise töökindluse kohta.
Näiteks, kui on väline leht (makseleht) – ta lihtsalt avab selle ja vaatab, kuidas see peaks välja nägema. Kui see on töötlemine, siis saadab ta katsetava 'transa' – vaatab, et see 'transa' jõuaks kohale. Kui see on side maksesüsteemidega – saatame testpäringu, kus saame, ja vaatame, et kõik on korras.
Millised näitajad on jälgimiseks olulised?
Mida me peamiselt jälgime? Millised näitajad on meie jaoks tähtsad?
- Response time / RPS esipindadel – väga oluline näitaja. See annab kohe märku, et teil on midagi valesti.
- Küpsiste töötlemiseks vajalik arv kõigis järjekordades.
- Töötajate arv.
- Peamised õigete näitajate metoodikad.
Viimane punkt on «äri» mõõdik. Kui soovite seda jälgida, peate määratlema ühe või kaks mõõdikut, mis on teie jaoks olulised näitajad. Meil on selline mõõdik – see on läbilaskevõime (see on edukate tehingute arvu suhe kogu tehingute voogu). Kui see muutub 5-10-15 minuti jooksul – siis on meil probleem (kui see muutub kardinaalselt).
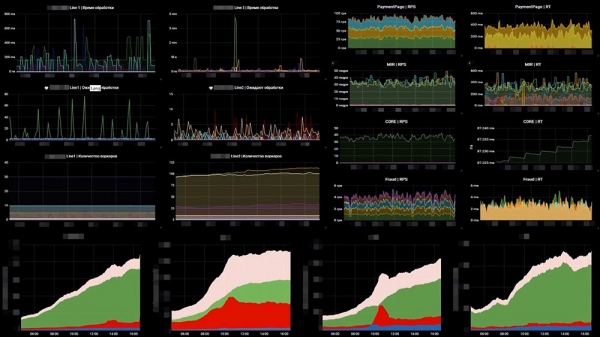
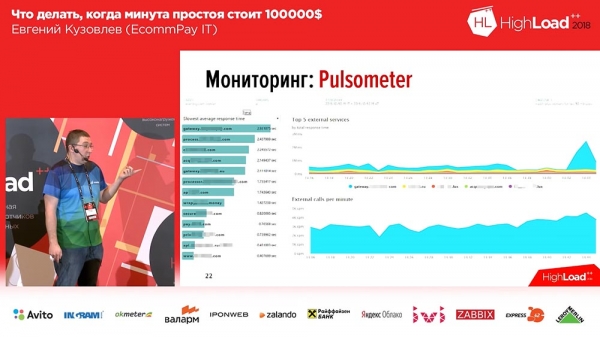
Kuidas see meie juures välja näeb – näide meie ühest armatuurlaudast:
Vasakul – 6 graafikut, mis vastavad ridadele – töötajate arv ja sõnumite arv järjekordades. Paremal – RPS, RTS. Alumisel real – see «äri» mõõdik. Ja «äri» mõõdikul näeme kohe, et kahe keskmise graafiku puhul on midagi valesti... See on just see, et järgmine süsteem, mis meie taga seisab, on välja kukkunud.Teiseks, mida me tegema pidime, oli jälgida, kuidas välistest maksesüsteemidest tehingud ebaõnnestusid. Siin kasutasime OpenTracingut – mehhanismi, standardit, paradigma, mis võimaldab jälgida hajutatud süsteeme; ja me muutsime seda veidi. Tavaline OpenTracingu paradigma ütleb, et me ehitame jälgimise iga eraldi päringu jaoks. Meie ei vajanud seda, seega pakkisime selle kokku agregatiivseks jälgimiseks. Loodud tööriist võimaldab meil jälgida süsteemide kiirus, mis meie taga on.
Graafik näitab, et üks maksesüsteem hakkas vastama 3 sekundi jooksul – meil tekkisid probleemid. Samuti reageerib see asi, kui probleemid algasid, 20-30 sekundi jooksul.Ja kolmas jälgimisveaklass, mis eksisteerib, on loogiline jälgimine.
Ausalt öeldes ei teadnud, mida sellel slaidil joonistada, kuna otsisime turult pikka aega seda, mis meile sobib. Mitte midagi ei leidnud, seega pidime ise tegema.
Mida ma mõistan loogilise jälgimise all? Kujutage ette: teete endale süsteemi (näiteks, kloni Tinderist); olete selle valmistanud ja käivitanud. Edukas juht Vasja Pupkin paigaldab selle enda telefoni, näeb seal tüdrukut, meeldib talle… kuid meeldimine ei lähe tüdrukule – see läheb turvamees Mihhálychile samas ärikeskuses. Juht läheb alla ja siis küsib imestunult: "Kuidas see turvamees Mihhálych niimoodi naeratab?"Sellistes olukordades… Meie jaoks kõlab see situatsioon veidi teistmoodi, kuna (ma kirjutasin), see on selline mainekaotus, mis kaudselt viib rahalistele kaotustele. Meie olukord on vastupidine: me võime otseselt rahalisi kahjusid kandma hakata – näiteks, kui me oleme teinud tehingu kui eduka, kuid see oli tegelikult ebaõnnestunud (või vastupidi). Ükskord pidin kirjutama enda tööriista, mis jälgib äri näitajaid edukate tehingute arvu liikumises ajavahemikus. Turul ei leidnud midagi sellist! Just seda mõtet ma tahtsin edastada. Selliste probleemide lahendamiseks ei ole turul midagi.
See oli küsimuse kohta, kuidas kiiresti probleemi tuvastada.
Kuidas tuvastada deploy põhjuseid
Kolmas ülesannete rühm, mida me lahendame, on see, et pärast probleemi tuvastamist ja selle lahendamist on hea mõista põhjuseid arendamiseks, testimiseks ja millegi tegemiseks. Seega peame uurima ja vahepeal logid üles tõstma.
Kui me räägime logidest (peamine põhjus – logid), siis peamine osa logidest on meil ELK Stackis – praktiliselt kõigil on nii. Kellegil võib see olla väljaspool ELK-d, kuid kui kirjutate logisid gigabaiditi, jõuate varem või hiljem ELK-ni. Me kirjutame neid terabaitide kaupa.
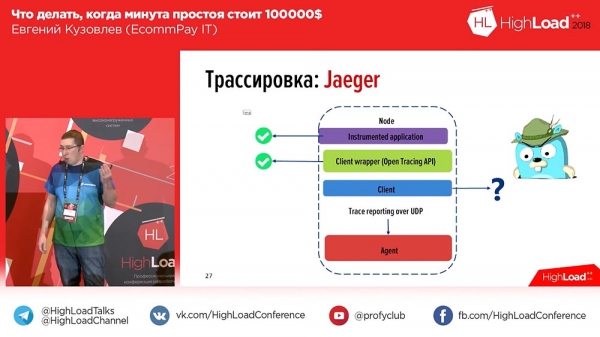
Siin on probleem. Me parandasime, lahendasime kasutaja vea, hakkasime uurima, mis seal toimus, sisenesime ‘Kibana’ ja sisestasime seal tehingu ID ning saime sellise pikka nimekirja (näitab palju). Ja selles nimekirjas ei ole roppudest midagi arusaadavat. Miks? Sest on ebaselge, milline osa kuulub millisele töötlejale, milline osa kuulub millisele komponendile. Ja sel hetkel mõistsime, et me vajame jälgimist – seda sama OpenTracingut, millest ma rääkisin.Mõtlesime sellele aasta tagasi, suunates oma pilgu turule, kus leidsime kaks tööriista – "Zipkin" ja "Jaeger". "Jaeger" on tegelikult Zipkini ideoloogiline järeltulija ja jätkaja. Zipkini puhul on kõik hästi, välja arvatud see, et see ei suuda agregatsiooni teha, ei oska lisada logisid jälgimisele, vaid ainult ajajälgimist. Ja "Jaeger" toetas seda.
Vaatasime "Jaegerit": rakendusi on võimalik instrumenteerida, saab kirjutada API-sse (standard API PHP-le sellel ajal, kuigi ei olnud kinnitatud – see oli aasta tagasi, kuid nüüd on see juba kinnitatud), täiesti puudus klient. "Selge," mõtlesime ja kirjutasime enda kliendi. Kuidas meil läks? Umbes nii see välja näeb:
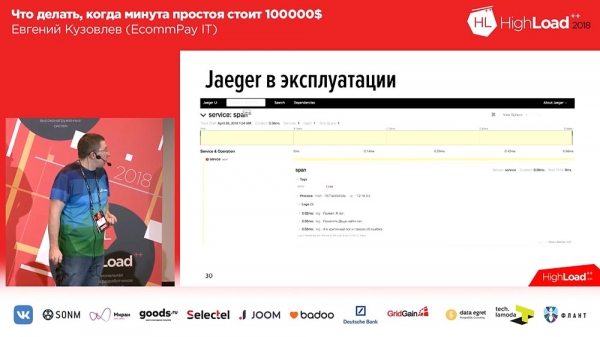
«Egeris» loob iga sõnumi jaoks span'id. See tähendab, et kui kasutaja avab süsteemi, näeb ta iga sissetuleva päringu kohta ühte või kahte plokki (1-2-3 – nii palju sissetulevaid päringuid, kui kasutaja on teinud, nii palju plokke). Kasutajate mugavuse huvides oleme logidele ja ajajälgimisele lisanud sildid. Vastavalt sellele, kui viga juhtub, märgib meie rakendus logi vastava tagiga Error. Saame filtreerida Error sildi järgi, ja kuvatakse vaid need span'id, mis sisaldavad veaga plokki. Nii see välja näeb, kui me span'i avame:
Span'i sees on komplekt jälgimisveasid. Antud juhul on need kolm testimist jälgimist, ja kolmas jälgimine ütleb meile, et viga on juhtunud. Samuti näeme siin ajajälgimist: meil on üleval ajaskaalad, ja me näeme, millisel ajavahemikul meie logi on salvestatud.Seega, meil läks suurepäraselt. Me oleme kirjutanud oma laienduse ning avatud lähtekoodiga. Kui soovite töötada jälgimisega, kui soovite töötada «Egeriga» PHP keeles – siin on meie laiendus, kasutage julgesti.
Meil on see lisand – klient OpenTracing Api tööks, tehtud php-extention'ina, see tähendab, et peate selle kokku panema ja süsteemi installima. Aasta tagasi ei olnud midagi muud. Nüüd on ilmunud ka teised kliendid, mis toimivad komponentidena. Siin on teie valik: kas laadite komponendid Composeriga alla või kasutate extention'i – valik on teie.Ettevõtte standardid
Rääkisime kolmest käsust. Neljas käsk on standardiseerida lähenemisviise. Millest see räägib? See on umbes selline:
Miks on siin sõna «ettevõtte»? Mitte sellepärast, et me oleksime suur või bürokraatlik ettevõte, ei! Sõna «ettevõtte» kasutasin ma siin kontekstis, et iga ettevõtte ja iga toote puhul peavad olema omad standardid, sealhulgas teie omad. Millised standardid on meil?- Meil on juurutamise regulatsioon. Ilma selleta ei liigu me edasi, ei saa. Teostame juurutusi umbes 60 korda nädalas, seega toimub meil juurutusi praktiliselt pidevalt. Samuti on meie juurutamise regulatsioonis, näiteks, keeld juurutustest reedel – põhimõtteliselt, me ei juuruta.
- Meil on kohustuslik dokumentatsioon. Ükski uus komponent ei jõua meie tootmisse, kui sellele ei ole dokumentatsiooni, isegi kui see on loodud meie RnD töötajate poolt. Nõuame neilt juurutusjuhendit, seirekaarti ja umbkaudset kirjeldust (noh, nagu arendajad võivad kirjutada), kuidas see komponent töötab, kuidas seda tõrkeotsinguks kasutada.
- Me lahendame mitte probleemi põhjust, vaid probleemi – nagu ma juba rääkisin. Meie jaoks on oluline kaitsta kasutajat probleemide eest.
- Meil on lubatud kõrvalekalded. Näiteks me ei pea kahjuks 'downtime' ajal, kui kaotasime kahe minuti jooksul 2% liiklusest, seda tõeliseks kahjuks. See põhimõtteliselt ei pääse meie statistikas. Kui rohkem protsentuaalselt või ajaliselt, siis juba loeme.
- Ja me kirjutame alati post-mortem'e. Mis iganes juhtub, iga olukord, millega tootmises ei käituta normaalselt, kajastatakse post-mortemis. Post-mortem on dokument, kuhu kirjutate, mis teiega juhtus, üksikasjalik ajakava, mida te tegite parandamiseks ja (see on kohustuslik osa!) mida teete, et sellist olukorda tulevikus vältida. See on vajalik edasiseks analüüsiks.
Mis on jaotus 'downtime'?
Mille see kõik viis?See tõi meid selleni, et (meil oli teatud stabiilsusprobleeme, mis ei sobinud ei klientidele ega meile) viimase 6 kuu jooksul oli meie stabiilsuse näitaja 99,97. Võib öelda, et see pole palju. Jah, meil on veel sihte, mille poole püüelda. Sellest näitajast umbes pool on stabiilsus, mis ei ole tegelikult meie oma, vaid meie ees olev web application firewall, mis töötab teenusena, kuid klientidele on see siiski oluline.
Oleme õppinud öösiti magama. Lõ finally! Pool aastat tagasi ei osanud me seda. Ja sellel märkusel, tahaksin teha ühe märkuse. Eelõhtul oli suurepärane ettekande teemal tuumareaktori juhtimissüsteem. Kui mind kuulevad inimesed, kes seda süsteemi kirjutasid – palun unustage, mida ma ütlesin "2% – see pole seisak". Teie jaoks on 2% seisak, isegi kui see kestab kaks minutit!
Ja selle kõik! Teie küsimused.
Tasakaalustajatest ja andmebaasist migreerimisest
Küsimus publikust (edasi – K): – Tere õhtust. Aitäh palju sellise administratiivse ettekande eest! Küsimus on lühike, teie tasakaalustajate teema kohta. Mainisite, et teil on WAF, seega, kui ma õigesti aru saan, kasutate te tasakaalustajana mingit välist…
EK: – Ei, tasakaalustajana kasutame oma teenuseid. Antud juhul on WAF meie jaoks pelgalt DDoS-i kaitse tööriist.
K: – Kas saaks paar sõna tasakaalustajatest?
EK: – Nagu ma juba ütlesin, on see avatud resti grupi serverid. Meil on praegu 5 reserveeritud gruppi, mis vastutavad ainus… seega server, millel on ainult openresty, suunab lihtsalt liiklust. Vastavalt arusaamisele, kui palju me hoiame: meie regulaarne liiklusvoog on praegu mõned sajad megabitti. Nad saavad hakkama, neil läheb hästi, nad ei vaeva end isegi.
K: – Samuti lihtne küsimus. Siin on Blue/Green juurutamine. Mis te teete, näiteks andmebaasi migreerimisega?
EK: – Hea küsimus! Vaata, meil on Blue/Green deploymentis igaks liiniks eraldi järjekorrad. See tähendab, et kui me räägime sündmustest, mis edastatakse töötajalt töötajale, on blue-liinil ja green-liinil eraldi järjekorrad. Kui me räägime andmebaasist, siis oleme tahtlikult selle kitsendanud, peaaegu kõik on järjekordades, andmebaasis hoitakse ainult tehingute stäkki. Ja see tehingute stakk on meil kõigi liinide jaoks ühiselt. Andmebaasi puhul selles kontekstis: me ei eralda seda blue ja green vahel, sest mõlemad koodiversioonid peavad teadma, mis tehinguga toimub.
Sõbrad, mul on veel üks väike auhind, et teid julgustada – raamat. Ja ma pean selle andma kõige parema küsimuse eest.
K: – Tere. Aitäh ettekande eest. Küsimus on selline. Te jälgite makseid, te jälgite teenuseid, millega te suhtlete... Aga kuidas te jälgite seda, et inimene mingil moel jõudis teie makselehele, tegi makse ja projekt talle raha kanti? Kuidas te jälgite, et kaupleja on saadaval ja on teie tagasikutsumise vastu võtnud?
EK: – 'Merchant' on meie jaoks on sama väline teenus nagu maksesüsteem. Me jälgime 'merchants' vastuse kiirus.
Andmebaasi krüpteerimisest
K: – Tere. Mul on veebist natuke erinev küsimus. Teil on tundlikke andmeid PCI DSS-i alusel. Soovin teada, kuidas te järjekordades PAN-e hoiate, mida on vaja edastada? Kas kasutate mingit krüpteerimist? Ja siit tuleneb teine küsimus: PCI DSS-i kohaselt tuleb aeg-ajalt andmebaasi uuesti krüpteerida, kui toimuvad muutused (adminnide vallandamine jne) – kuidas mõjutab see kergelt juurdepääsetavust?
EK: – Suurepärane küsimus! Esiteks, me ei hoia järjekordades PAN-e. Meil ei ole lubatud hoida PAN-e kuskil avalikult, seetõttu kasutame spetsiaalset teenust (me nimetame seda 'Keydemoniks') – see teenus teeb vaid üht: see võtab sisendiks sõnumi ja annab välja krüpteeritud sõnumi. Ja me hoiame kõike selle krüpteeritud sõnumina. Seetõttu on meie võtme pikkus kilobaidi ulatuses, et see oleks tõeliselt tugev ja usaldusväärne.K: – Kas nüüd on juba vaja 2 kilobaidi?
EK: – Tundub, et eile oli 256… Kuhu veel?!
Seega, see on esimene. Teiseks, see lahendus toetab uuendamise protseduuri – seal on kaks 'kek'i (võtmete paari), mis genereerivad 'dek' (võtmed, mis krüpteerivad). Ja juhul, kui protseduur algatatakse (viib läbi regulaarselt, iga 3 kuu tagant või nii), laadime me uue 'kek'i paari ja tehakse andmete uuesti krüpteerimine. Meil on eraldi teenused, mis tõmbavad kõiki andmeid välja, krüpteerivad need uuesti; andmete kõrvale salvestatakse nende krüpteerimiseks kasutatud võtme identifikaator. Seega, niipea kui andmed on uute võtmetega krüpteeritud, kustutame me vanad võtmed.
Mõnikord tuleb makseid teha käsitsi…
K: – Nii et kui tuleb tagastus mõne tehingu kohta, siis dekrüpteerite seni vana võtmega?
EK: – Jah.
K: – Siis veel üks väike küsimus. Kui juhtub mõni tõrge, kukkumine, incident, siis on vajalik tehingu käsitsi läbisurumine. Selline olukord võib esineda.
EK: – Jah, see juhtub.
K: – Kust te need andmed saate? Või minge ise käsitsi sellele salvestusele?
EK: – Ei, loomulikult on meil olemas mingi back-office süsteem, mis sisaldab liidest meie toe jaoks. Kui me ei tea, mis seisus tehing on (näiteks seni, kuni maksesüsteem ei ole vastanud) – ei tea me seda põhimõtteliselt, ehk me määrame lõppseisu ainult täieliku kindlusega. Sel juhul suuname tehingu erilise staatuse alla käsitsi töötlemiseks. Hommikul, järgmisel päeval, kui tugi saab teavet, et maksesüsteemis on jäänud sellised tehingud, töötlevad nad need käsitsi sellel liidese kaudu.
K: – Mul on paar küsimust. Üks neist on PCI DSS tsooni jätk: kuidas te logisid nende piirilt välja toote? Küsin, sest arendaja on logides võinud panna mida iganes! Teine küsimus: kuidas te kärpeid välja toote? Käsitsi andmebaasis – see on üks valik, kuid võivad olla tasuta hot-fix’id – mis on sealne protseduur? Ja kolmas küsimus, ilmselt seotud RTO ja RPO-ga. Teie kättesaadavus oli 99,97, peaaegu neli üheksa, aga ma saan aru, et teil on ka teine andmekeskus ja kolmas andmekeskus ning viies andmekeskus... Kuidas te nende sünkroniseerimise, replikatsiooni ja muu asjaga tegelete?EK: – Alustame esimesest. Kas esimene küsimus oli logide kohta? Meil, kui logid kirjutatakse, on kiht, mis peidab kõik tundlikud andmed. See vaatab maski ja täiendavate väli kaudu. Vastavalt sellele, logid väljuvad juba peidetud andmetega ja PCI DSS-i kontuuriga. See on üks regulaarsetest ülesannetest, mis on antud testimisosakonnale. Nad peavad kontrollima iga ülesande puhul ka neid logisid, mida nad kirjutavad, ja see on üks regulaarsetest ülesannetest koodirevisjonis, et kontrollida, kas arendaja ei ole midagi salvestanud. Järgmine kontroll toimub regulaarselt infotehnoloogia turvaosakonna poolt umbes kord nädalas: juhuslikult valitakse viimase päeva logid ja need viiakse läbi spetsiaalse skanneri-analüsaatori kaudu testserveritest, et kõike kontrollida.
Hot-fix'ide kohta. See on meie juures kaasatud deployment'i regulatsioonidesse. Meil on eraldi punkt hot-fix'ide kohta. Peame, et me deployime hot-fix'e ööpäevaringselt, kui see on vajalik. Niikaua kui versioon on kokku pandud, testitud ja meil on artefakt – kutsutakse valveadministraator toeks helistades ja ta deployib selle hetkel, kui see on vajalik.Neljast neljast. See number, mis me praegu oleme saavutanud, on tõeliselt saavutatud ning me püüdlesime selle poole ka teises andmekeskuses. Praegu on meil tulnud teise andmekeskuse avamine ja me hakkame nende vahel ruttama, ning küsimus andmekeskuste vahelisest replikatsioonist – see on tõeliselt mittetriviaalne küsimus. Proovisime seda kunagi erinevate meetodite abil lahendada: üritasime kasutada samu 'Tarantula' – meil see ei toimi, ütlen kohe. Seetõttu oleme jõudnud järeldusele, et teeme 'sensat' käsitsi. Iga meie rakendus, tegelikult, pusib vajaliku 'muudatus – tehtud' asünkroonses režiimis andmekeskuste vahel.
K: – Kui teil on teine, siis miks ei ole kolmandat? Sest split-brain'i probleemi pole keegi veel lahendanud...
EK: – Meil ei ole "Split-brain"-i. Kuna iga rakendus meie juures kasutab multimasterni, ei ole meile oluline, kuhu keskusesse päring läheb. Oleme valmis selleks, et juhul, kui meie üks andmekeskus kukkub (me arvestame sellega) ja kasutaja päringu ajal lülitame teise andmekeskuse peale, oleme valmis selle kasutaja kaotama, tõesti; kuid need on absoluutne vähesus, absoluutne vähesus.
K: – Tere õhtust. Aitäh ettekande eest. Rääkisite oma debugeerijast, mis tootmises käitab mingeid testtransaktsioone. Rääkige palun testtransaktsioonidest! Kui sügavale see läheb?
EK: – See läbib kogu komponendi täislükki. Komponendi jaoks ei ole eristusi testtransaktsiooni ja reaalaja vahel. Loogika seisukohalt on see lihtsalt eraldi projekt süsteemis, kus käivad ainult testtransaktsioonid.
K: – Kus te selle katkestate? Siin saatis Core...
EK: – Me jälgime "Kori" puhul testtransaktsioonide osas... Meil on selline mõisted nagu ruteerimine: "Kor" teab, millisesse maksesüsteemi saata – me saadame vale maksesüsteemi, mis lihtsalt annab http-reaktsiooni ja see on kõik.
K: – Palun öelge, kas teil on rakendus kirjutatud ühtse monoliidi kujul või olete selle jaganud teenuste või isegi mikroteenuste peale?
EK: – Meil ei ole monoliiti, meil on teenustele orienteeritud rakendus. Meil on nali, et meil on teenused monolitest – need on tõepoolest piisavalt suured. Mikroteenusteks seda nimetada ei saa, aga need on tõesti teenused, mille sees töötavad jagatud masinate töötajad.
Kui teenus serveris on kompromiteeritud…
K: – Siis on mul järgmine küsimus. Isegi kui see oleks olnud monoliit, ütlesite ikkagi, et teil on palju neid instant-servereid, kõik need töötlevad põhimõtteliselt andmeid, ja küsimus on selline: "Komprimentimise korral ühe instant-serveri või rakenduse, mõne konkreetse lüli, korral, kas neil on mingisugune juurdepääsukontroll? Kes võib mida teha? Kelle poole pöörduda, milliste andmete osas?"
EK: – Jah, kindlasti. Turvanõuded on piisavalt tõsised. Esiteks, meil on avatud andmeedastused, ja sadamad on ainult need, mille kaudu me eelnevalt eeldame liiklust. Kui komponent suhtleb andmebaasiga (näiteks MySQLiga) portide 5-4-3-2 kaudu, siis avatakse ainult 5-4-3-2, ja teised sadamad ning liikluse suunad ei ole saadaval. Lisaks tuleb mõista, et meie tootmises on umbes 10 erinevat turvapiirkonda. Ja isegi kui rakendus on mingil põhjusel kompromiteeritud, jumal hoidku, siis ründajal ei õnnestu serveri juhtpaneelile juurde pääseda, kuna see on teises turvapiirkonnas.K: – Mulle on selles kontekstis huvitavam aspekt see, et teil on ju lepingud teenustega — mida nad saavad teha, milliste "meetodite" kaudu nad saavad omavahel suhelda... Ja normaalses töövoos küsivad mõned teenused teistelt teatud suhete loetelu "meetodeid". Teisi nad tavaliselt ei puuduta, ning nende vastutusalad on erinevad. Kui aga üks neist peaks olema kompromiteeritud, kas ta suudab "meetodeid" selle teenuse käest küsida?..
EK: – Ma saan aru. Kui normaalses olukorras kommunikatsioon teise serveriga oli üldse lubatud, siis — jah. SLA-lepingute kohaselt me ei jälgi, et teile on lubatud ainult esimesed 3 "meetodit", samas kui 4. "meetod" jääb teile keelatuks. See oleks meie jaoks ilmselt ülemäärane, sest meil on niigi neli tasandit kaitset kontuuride jaoks. Eelistame kaitsta kontuure, mitte süvatasandi tasandil.
Kuidas töötab Visa, MasterCard ja "Sberbank"
K: – Ma sooviksin täpsustada, kuidas kasutaja vahetus ühes andmekeskuses teise toimub. Nagu ma tean, töötavad "Visa" ja "MasterCard" binaarses sünkroonprotokollis 8583, seal on mikserid. Ja tahtsin küsida, kas vahetus tähendab lennult "Visa" ja "MasterCard" või maksesüsteemide, protsessorite tasemel?
EK: – See on mikserite tasemel. Mikserid on meil ühes andmekeskuses.
K: – Lihtsalt öeldes, on teil üks ühenduspunkt?
EK: – "Visale" ja "MasterCardile" – jah. Lihtsalt seetõttu, et "Visa" ja "MasterCard" nõuavad infrastruktuuri jaoks piisavalt suuri investeeringuid, et sõlmida eraldi lepingud teise mikseripaari saamiseks, näiteks. Need on reserveeritud ühe andmekeskuse piires, kuid kui meil, jumala pärast, sureb andmekeskus, kus on mikserid "Visa" ja "MasterCard" ühendamiseks, siis katkeneb meie side "Visaga" ja "MasterCardiga"...
K: – Kuidas nad võivad olla reserveeritud? Ma tean, et "Visa" lubab hoida põhimõtteliselt vaid ühte ühendust!
EK: – Nad ise varustavad seadmed. Igatahes, meile on saadetud seadmed, mis on sisemiselt kindlalt reserveeritud.
K: – See, is the rack from their Connects Orange?..
EK: – Jah.
K: – What about in this case: if your data center goes down, how do you continue using it? Or does the traffic just stop?
EK: – No. In this case, we simply switch the traffic to another channel, which, of course, will be more expensive for us and for the clients. But the traffic will not go through our direct connection to Visa or MasterCard, but through a hypothetical Sberbank (very exaggerated).
I sincerely apologize if I've offended the employees of Sberbank. But according to our statistics, Sberbank fails most frequently among Russian banks. Not a month goes by without Sberbank experiencing some issue.

Veidi reklaami 🙂
Aitäh, et olete meiega. Kas teile meeldivad meie artiklid? Kas soovite näha rohkem huvitavaid materjale? Toetage meid, tehes tellimuse või soovitades meid tuttavatele. , ainulaadne sisenemise taseme serverite analoog, mille oleme teie jaoks välja mõelnud: (saadaval on RAID1 ja RAID10 variandid, kuni 24 südamikku ja kuni 40GB DDR4).
Kas Dell R730xd on kaks korda odavam Equinixi Tier IV andmete keskuses Amsterdamis? Ainult meie juures Hollandi turul! Dell R420 — 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB — alates $99! Lugege, kuidas



















Allikas: habr.com
