


Tööstuslike tarkvasüsteemide arendamine nõuab suurt tähelepanu lõpptootesi tõrgetekindlusele ning kiirele reageerimisele, kui riketeid ja tõrkeid siiski juhtub. Jälgimine aitab muidugi tõhusamalt ja kiiremini reageerida rikeidele ja tõrgetele, kuid see pole piisav. Esiteks on väga keeruline jälgida suurt hulka servereid - selleks on vajalik suur hulk inimesi. Teiseks, tuleb hästi mõista, kuidas rakendus töötab, et prognoosida selle seisukorda. Seega on vaja palju inimesi, kes mõistavad hästi meie arendatavaid süsteeme, nende näitajaid ja omadusi. Oletame, isegi kui leida piisav hulk inimesi, kes on valmis sellega tegelema, vajab nende koolitamine samuti palju aega.
Mis siis teha? Siin tuleb meile appi tehisintellekt. Artiklis käsitletakse (ennustav hooldus). See lähenemine kasvab aktiivselt populaarsust. On kirjutatud palju artikleid, sealhulgas ka Habras. Suured ettevõtted kasutavad seda lähenemist oma serverite töövõimekuse tagamiseks. Pärast suurte artiklite uurimist otsustasime proovida seda lähenemist. Mis sellest välja tuli?
Sissejuhatus
Arendatud tarkvarasüsteem jõuab varem või hiljem kasutusse. Kasutajale on oluline, et süsteem töötab tõrgeteta. Kui siiski juhtub erakorraline olukord, peab see olema kõrvaldatud minimaalsete viivitustega.
Tarkvarasüsteemi tehnilise toe lihtsustamiseks, eriti kui servereid on palju, kasutatakse tavaliselt jälgimisprogramme, mis koguvad töötava tarkvarasüsteemi mõõdikud, võimaldavad diagnoosida selle seisundit ja aitavad kindlaks teha, mis täpselt põhjustas rikke. Seda protsessi nimetatakse tarkvarasüsteemi jälgimiseks.
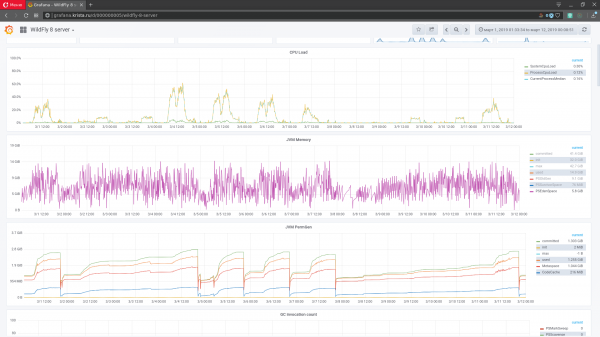
Joonis 1. Grafana jälgimisliides
Metrika on erinevad näitajad tarkvarasüsteemis, selle käitamis keskkonnas või füüsilises arvutustehnoloogias, mille all süsteem töötas, ajamärgistusega, mis näitab aega, mil mõõdud saadud. Staatilises analüüsis nimetatakse mõõduteabe ajakuvanditeks. Tarkvarasüsteemi oleku jälgimiseks esitatakse näitajad graafikute kujul: X-teljel on aeg ja Y-teljel on väärtused (joonis 1). Töötavast tarkvarasüsteemist saab mõõta mitmeid tuhandeid näitajaid (igal sõlmel). Need loovad mõõtmisruumi (mitme mõõtmeliste ajakuvandite kompleksi).
Kuna keeruliste tarkvarasüsteemide puhul kogutakse arvestatav hulk mõõdikuid, muutub käsitsi jälgimine keeruliseks ülesandeks. Jälgimistööde mahu vähendamiseks sisaldavad monitooringuvahendid automaatsete probleemide tuvastamise tööriistu. Näiteks saab seadistada puhverpinget, mis aktiveerub, kui vaba kettaruumi kogus langeb määratud piirini. Samuti saab automaatselt diagnoosida serveri seiskumist või teeninduskiirusel tekkivat kriitilist aeglustumist. Praktikas suudavad monitooringuvahendid üsna hästi tuvastada juba toimunud rikkeid või tuvastada lihtsaid tulevaste riketega seotud sümptomeid, kuid üldiselt jääb võimalike rikete ennustamine neile tõeliseks pähkliks. Ennustamine käsitsi mõõdikute analüüsi teel nõuab kvalifitseeritud spetsialistide kaasamist. See on madala tootlikkusega. Enamik potentsiaalsed rikked võivad jääda tähelepanuta.
Viimastel aegadel on suuremate IT-ettevõtete seas, mis tegelevad tarkvara arendamisega, üha suuremat populaarsust kogumas nn prognoosiv hooldus tarkvarasüsteemide jaoks. Selle lähenemise olemus seisneb probleemide tuvastamises, mis viivad süsteemi degradeerumiseni varajases staadiumis, enne selle riket, kasutades tehisintellekti. See lähenemine ei välista täielikult käsitsi süsteemi jälgimist. See on abistav kogu jälgimisprotsessis.
Prognoosiva hoolduse peamine tööriist on anomaaliate leidmise ülesanne ajasüsteemides, kuna anomaalia tekkimise korral on andmetes suur tõenäosus, et mõne aja pärast esineb tõrge või rikete. Anomaalia on mingi kõrvalekalle tarkvarasüsteemi näitajatest, nagu näiteks ühe tüübi päringu täitmise kiirus või keskmise teenindatud päringute arvu vähenemine konstantse kliendiseansside arvu juures.
Anomaaliate otsimise ülesanne tarkvarasüsteemides omab oma spetsiifikat. Idee kohaselt on iga tarkvarasüsteemi jaoks vajalik olemasolevate meetodite väljatöötamine või täiustamine, kuna anomaaliate otsimine sõltub tugevalt andmetest, milles see toimub, ja tarkvarasüsteemide andmed varieeruvad oluliselt sõltuvalt süsteemi rakendamise tööriistadest, isegi sõltuvalt sellest, millisel arvutil see käivitatakse.
Anomaaliate otsimise meetodid tarkvarasüsteemide riketete prognoosimisel
Esiteks tuleb öelda, et riketete prognoosimise idee on inspireeritud artiklist . Aneemaks, et automatiseeritud anomaaliate avastamise meetodi tõhusust kontrollida, valiti tarkvarasüsteem „Web-Konsolideerimine“, mis on üks NPO „Krista“ projektest. Varasemalt tehti sellele käsitsi seire saadud meetrite põhjal. Kuna süsteem on piisavalt keeruline, jälgitakse selle jaoks suurt hulka meetmeid: JVM näitajaid (prügikogumise koormus), operatsioonisüsteemi näitajaid, mille all kood töötab (virtuaalne mälu, protsessori koormus %), võrgu näitajaid (võrgu koormus), serveri näitajaid (protsessori koormus, mälu), wildfly näitajaid ja rakenduse enda meetmeid kõigi kriitiliste alamsüsteemide kohta.
Kõik meetmed saadakse süsteemist graphite'i abil. Alguses kasutati whisperi andmebaasi kui standardset lahendust grafana jaoks, kuid klientide arvu kasvu tõttu lõpetas graphite diskreetse alamsüsteemi läbilaskevõime koostööd. Pärast seda tehti otsus otsida tõhusamat lahendust. Valik langes , mis vähendas oluliselt kettasüsteemi koormust ja viis kuue kuni viie korra võrra vähendas kasutatavat kettamahtu. Allpool on esitatud metrikate kogumise mehhanismi skeem, kasutades graphite+clickhouse (joonis 2).
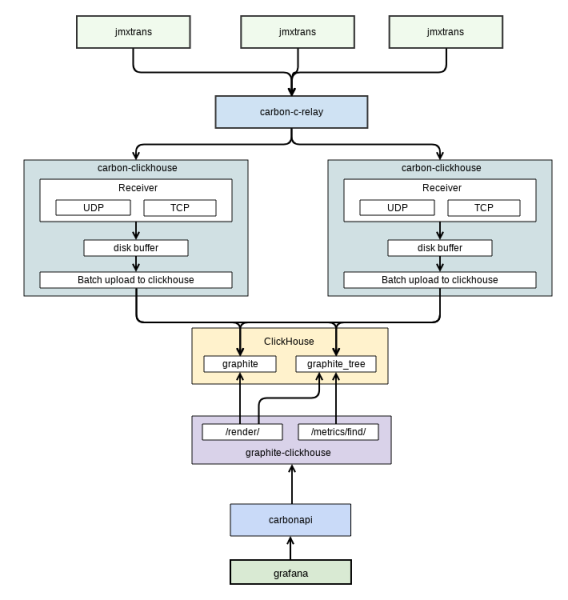
Joonis 2. Metriikate kogumise skeem
Skeem on võetud sisemisest dokumentatsioonist. Sellega on näidatud andmevahetust grafana (valdava kasutajaliidese, mida me kasutame) ja graphite'i vahel. Metrikate kogumisega tegeleb eraldi tarkvara – . See salvestab need graphite'i.
Süsteemil „Web-Konsolideerimine” on mitmeid omadusi, mis tekitavad probleeme rikkeennustamisel:
- trendide vahetus toimub sageli. Selle tarkvarasüsteemi jaoks väljastatakse erinevaid versioone. Igal neist on muutused süsteemi tarkvaras. Seega mõjutavad arendajad otseselt selle süsteemi metriika ja võivad põhjustada trendide vahetust;
- rakendamise eripära ja süsteemi klientide kasutamise eesmärgid tekitavad sageli anomaaliaid ilma eelneva degradeerumiseta;
- anomaaliate protsent kogu andmestikus on madal (< 5%);
- võivad esineda katkestused süsteemi näitajate saamisel. Mõnel lühikesel ajavahemikul ei õnnestu jälgimissüsteemil mõõdikuid saada. Näiteks, kui server on üle koormatud. See on närvivõrgule kriitiline. Tõuseb vajadus täita lünki sünteetiliselt;
- Anomaaliate juhtumid on sageli asjakohased ainult teatud arvu/kuid/aja (hooaegsus) osas. Antud süsteemil on kasutajate jaoks üheselt mõistetav regulatiivne raamistiku. Seega on mõõdikud asjakohased ainult teatud aja jaoks. Süsteem ei pruugi olla pidevas kasutuses, vaid ainult teatud kuudel: valikuliselt sõltuvalt aastast. Tekkivad olukorrad, kus sama mõõdiku käitumine ühes olukorras võib viia programmide süsteemi tõrkeni, aga teises mitte.
Alguses analüüsiti meetodeid anomaaliate tuvastamiseks tarkvarasüsteemide jälgimisandmetes. Sel teemal kirjutatud artiklites soovitatakse sageli madala anomaaliate protsendi korral võrreldes ülejäänud andmestikuga kasutada närvivõrke.
Põhiloogika anomaaliate otsimiseks närvivõrkude abil on kujutatud joonisel 3:

Joonis 3. Anomaaliate otsimine närvivõrgu abil
Hetke mõõtmete voosi prognoosi või taastamise tulemused arvutatakse kõrvalekalle töötava tarkvarasüsteemi saadud näitajatest. Kui saadud näitajate ja närvivõrgu tulemuste vahel on suur erinevus, võib teha järelduse, et käesolev andmepädevus on anomaalne. Selle tõttu tekib rida probleeme närvivõrkude kasutamiseks:
- et mudelid töötaksid õigesti reaalajas, peavad koolitamiseks kasutatavad andmed sisaldama vaid 'normaalseid' näitajaid;
- on vajalik omada ajakohast mudelit korrektseks avastamiseks. Suundumuse ja hooaegade muutused näitajates võivad põhjustada palju valehäireid mudelis. Selleks, et mudelit uuendada, tuleb selgelt määratleda aeg, mil mudel on aegunud. Kui mudelit uuendada liiga hilja või vara, jääb tõenäoliselt palju valehäireid.
Samuti ei tohiks unustada valehäirete otsimist ja ennetamist. Eeldatakse, et need esinevad kõige sagedamini erakorralistes olukordades. Siiski võivad need olla tingitud ka närvivõrgu veast, mis tuleneb selle ebapiisavast koolitamisest. Valehäirete arvu tuleb minimeerida. Vastasel juhul kulutab valeprognoos palju aega administraatori jaoks, kes on määratud süsteemi kontrollimiseks. Varsti või hiljem viib see selleni, et administraator lõpetab lihtsalt "paranoilise" jälgimisse süsteemi reageerimise.
Rekurrentsne närvivõrk
Ahnomaliade tuvastamiseks ajareal saab kasutada LSTM mäluga. Probleem seisneb vaid selles, et seda saab kasutada ainult prognoositavatele ajarealtele. Meie puhul ei ole kõik mõõdikud prognoositavad. Üritus rakendada RNN LSTM ajareale on esitatud joonisel 4.
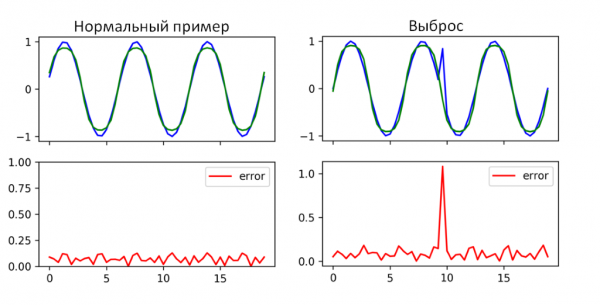
Joonis 4. Rekurrentsse närvivõrgu LSTM mälurakkude toimimise näide
Nagu näha joonisel 4, suutis RNN LSTM tuvastada anomaalia antud ajahetkes. Seal, kus tulemus näitab suurt ennustamisviga (keskmine viga), leidis tõepoolest aset anomaalia näitajates. Ainult ühe RNN LSTM kasutamine ei ole ilmselgelt piisav, kuna see on rakendatav piiratud arvu mõõdikute suhtes. Anomaalia otsimise abimeetodina saab kasutada.
Autokooder rikete ennustamiseks
– põhimõtteliselt kunstlike neuronite võrk. Sissevoolu kiht – kodeerija, väljundkiht – dekodeerija. Kõigi selliste närvivõrkude puuduseks on halb anomaaliate lokaliseerimine. Valiti sünkroonse autokoodri arhitektuur.
Joonis 5. Autokoodri töö näide
Autokooderid õpivad normaalsest andmestikust ja leiavad siis mudelisse söödetud andmetes midagi anomaalset. Just seda on selle ülesande jaoks vaja. Tuleb ainult valida, milline autokooder sobib antud ülesande jaoks. Arhitektuuriliselt kõige lihtsam autokooder on sirge, tagasisaatmata närvivõrk, mis on väga sarnane (multilayer perceptron, MLP), sisendtaseme, väljundtaseme ja ühe või mitme peidi kihi vaheliste ühendustega.
Kuid erinevused autokooderite ja MLP vahel seisnevad selles, et autokoodri väljundtasemel on sama palju sõlmi kui sisendtasemel ning et autokooder ei õpi Y sihtväärtuse prognoosimist, mis on määratud X sisendiga, vaid autokooder õpib rekonstrueerima enda X. Seetõttu on autokooderid mittetäiendavad õppemudelid.
Autokoodri ülesanne on leida ajatu indeksid r0 … rn, mis vastavad anomaalsetele elementidele sisendvektoris X. See efekt saavutatakse kvadratiivse vea otsimise kaudu.
Joonis 6. Sünkroonsed autokooderid
Autokooderi jaoks valiti . Selle eelised: voogude töötlemise režiimi kasutamise võimalus ja võrreldes teiste arhitektuuridega suhteliselt vähenenud närvivõrgu parameetrid.
Valehäirete minimeerimise mehhanism
Kuna erinevaid ebanormaalseid olukordi võib tekkida, samuti võib esineda olukord, kus närvivõrgu koolitus on ebapiisav, otsustati välja töötada mehhanism valehäirete minimeerimiseks arendatava kõrvalekalde tuvastamise mudeli jaoks. See mehhanism põhineb mallide baasil, mida klassifitseerib administraator.
(DTW-algoritm, inglise keeles dynamic time warping) võimaldab leida optimaalse vastavuse ajasekventide vahel. Esmakordselt rakendati hääletuvastuses: seda kasutati selle määramiseks, kuidas kaks hääle signaali esindavad ühte ja sama algselt väljendatud fraasi. Hiljem leiti, et seda saab rakendada ka teistes valdkondades.
Valevuse minimiseerimise peamine põhimõte on referentside kogumine operaatori abil, kes klassifitseerib kahtlased juhtumid, mida tuvastavad närvivõrgud. Edasi toimub klassifitseeritud referentsi võrdlemine juhtumiga, mille süsteem avastas, ning tehakse järeldus, kas juhtum kuulub vale või tõrke juhtumite hulka. Just kahte ajaseeriat võrreldes kasutatakse DTW algoritmi. Peamiseks vahendiks minimiseerimise osas on siiski klassifitseerimine. Eeldatakse, et pärast suure hulga referentsjuhtumite kogumist hakkab süsteem operaatorilt vähem küsima, kuna enamiku juhtumite sarnasus ja sarnaste juhtumite teke väheneb.
Kokkuvõttes rajati ülaltoodud närvivõrkude meetodite põhjal eksperimentaalne programm süsteemi "Web-Konsolideerimise" tõrgete prognoosimiseks. Selle programmi eesmärk oli, kasutades olemasolevat jälgimisandmete arhiivi ja teavet juba toimunud tõrgete kohta, hinnata käesoleva lähenemise tõhusust meie tarkvarasüsteemide puhul. Programmi töö skeem on esitatud allpool, joonisel 7.
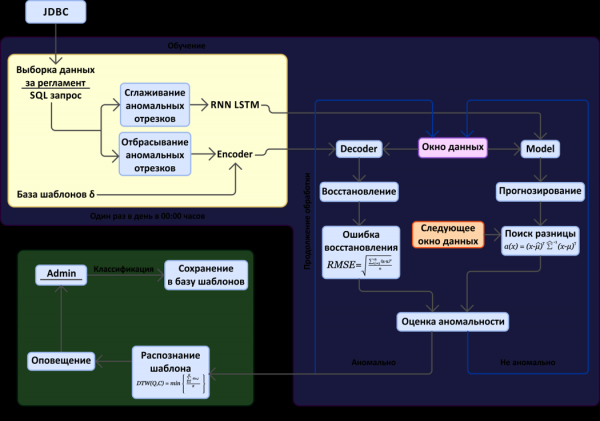
Joonis 7. Rikkete ennustamise skeem, mis põhineb mõõdikute ruumi analüüsil.
Skeemilt on näha kaks põhiblokki: anomaalsete ajavahemike otsimine jälgimisandmete (mõõdikute) voos ja valehäirete minimeerimise mehhanism. Märkus: eksperimentaalsetel eesmärkidel saadakse andmed JDBC-ühenduse kaudu andmebaasist, kuhu need salvestatakse, graphite.
Edasi on esitatud saadud tulemuste jälgimissüsteemi arendamise liides (joonis 8).
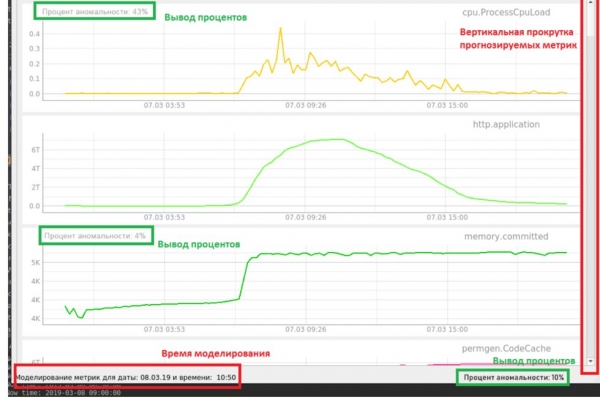
Joonis 8. Eksperimentaalse jälgimissüsteemi liides
Liideses kuvatakse anomaalsuse protsent saadud mõõdikutest. Meie puhul simuleeritakse andmete saamist. Meil on juba mitme nädala andmed ja laadime neid järk-järgult, et kontrollida anomaaliat, mis viib rikkumiseni. Alumises staatusebaaris kuvatakse andmete üldine anomaalsuse protsent antud ajahetkel, mille määrab automaatne kodeerija. Samuti kuvatakse prognoositud mõõdikute jaoks eraldi protsent, mille arvutab RNN LSTM.
Näide anomaalia tuvastamisest CPU näitajate põhjal RNN LSTM närvivõrgu abil (joonis 9).
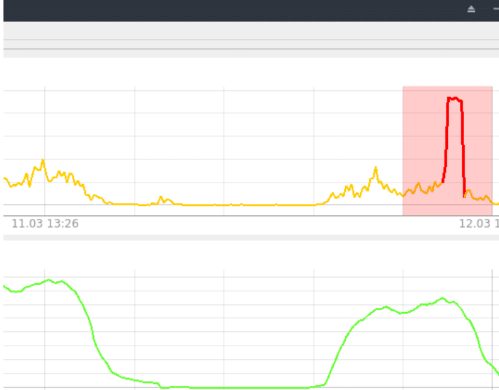
Joonis 9. RNN LSTM tuvastamine
See on üsna lihtne juhtum, põhimõtteliselt tavaline anomaalia, kuid see põhjustas süsteemi tõrke, mille RNN LSTM abil suudeti edukalt tuvastada. Aeganomaalsuse näitaja sel ajal on 85-95%; kõik, mis ületab 80% (piir on määratud eksperimenteerimise teel), arvatakse anomaaliaks.
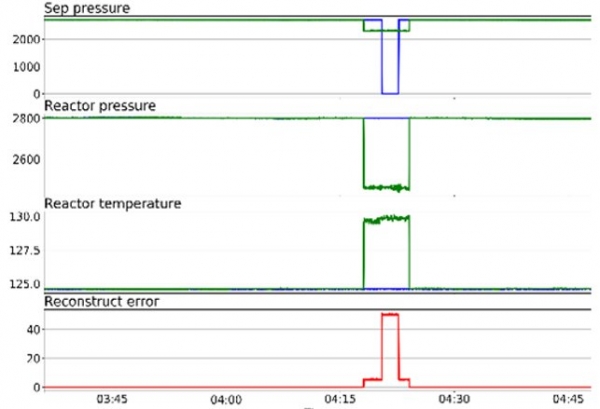
Anomaalia tuvastamise näide, kus süsteem ei suutnud pärast värskendamist käivituda. See olukord tuvastatakse autokooderijaga (joonis 10).
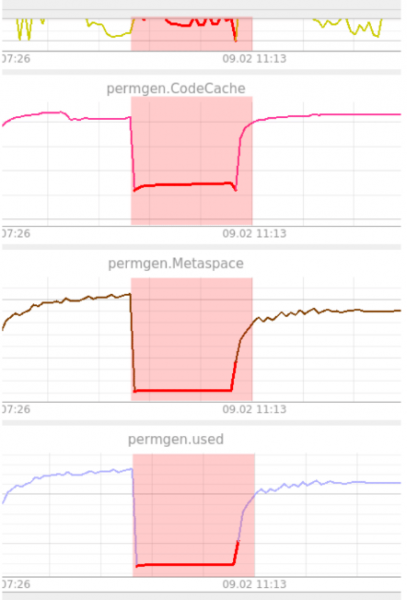
Joonis 10. Näide autokooderija tuvastamisest
Nagu jooniselt näha, on PermGen ühel tasemel kinni. Autokooderija leidis selle kummalisena, kuna ta ei olnud varem midagi sellist näinud. Siin püsib anomaalsus 100% kuni süsteem taastub töökindlaks. Anomaalsus kuvatakse läbi kõikide mõõdikute. Nagu varem mainitud, ei oska autokooderija anomaaliaid lokaliseerida. Operaatoreid nõutakse, et täita seda funktsiooni antud olukordades.
Kokkuvõte
PK «Web-Конsolideerimine» on välja töötatud juba mitu aastat. Süsteem on piisavalt stabiilses seisundis ning registreeritud intsidentide arv on väike. Siiski on õnnestunud leida anomaaliaid, mis viivad rikkumiseni 5–10 minutit enne rikkumist. Mitmel juhul oleks varajane riketeade aidanud säästa regulatiivset aega, mis on ette nähtud „remondi“ teostamiseks.
Käidud katsetest on veel vara teha lõplikke järeldusi. Praegu on tulemused vastuolulised. Ühest küljest on näha, et närvivõrgupõhised algoritmid suudavad tuvastada „kasulikke“ anomaaliaid. Teiselt poolt jääb suur protsent valehäireid ning mitte kõik anomaaliad, mida kvalifitseeritud spetsialist suudab närvivõrgust leida, ei õnnestu tuvastada. Puudusteks võib pidada ka seda, et praegu nõuab närvivõrk normaalset töötamist õpetajaga koolitamist.
Süsteemi tõrgete prognoosimise arendamiseks ja selle viimiseks rahuldavale tasemele on võimalik ette näha mitmeid teid. See hõlmab detailsemat analüüsi anomaaliaga juhtumite osas, mis põhjustavad rikkeid, lisades sellega oluliste mõõdikute nimekirja, mis mõjutavad oluliselt süsteemi seisukorda, ja kõrvaldades need, mis ei mõjuta seda. Samuti, kui jätkata antud suunas, saame proovida spetsialiseerida algoritme spetsiifiliselt meie anomaaliaga juhtumitele, mis põhjustavad rikkeid. On ka teine tee: närvivõrkude arhitektuuri täiustamine ja seeläbi avastuste täpsuse suurendamine, lühendades samal ajal koolitusaega.
Tänan kolleege, kes aitasid mind selle artikli kirjutamisel ja ajakohasena hoidmisel: ja Sergei Finogenov.
Allikas: habr.com
