

Andmealgoritmid, nagu närvivõrgud, on vallutanud maailma. Nende arengut tingivad mitmed põhjused, sealhulgas odav ja võimas riistvara ning tohutud andmemahtud. Tänasel päeval on närvivõrgud esirinnas kõikides „kognitiivsetes“ ülesannetes, nagu piltide tuvastamine, looduse keele mõistmine jne. Kuid nende rakendusi ei tohiks piirata ainult sellistele ülesannetele. Selles artiklis räägitakse piltide tihendamisest närvivõrkude abil, kasutades jääkõpet. Artiklis esitatud lähenemine töötab kiiremini ja paremini kui standardkoodekid. Skeemid, võrrandid ja loomulikult tabel katse tulemustega jäävad allapoole.
See artikkel põhineb töös. Eeldatakse, et olete tuttav närvivõrkude ja nende mõistetega konvolutsioon ja kaotuse funktsioon.
Mis on piltide tihendamine ja milliseid tüüpe see sisaldab?
Piltide tihendamine on protsess, mille käigus muudetakse pilti nii, et see võtaks vähem ruumi. Lihtne piltide salvestamine võtaks palju ruumi, seetõttu on olemas koodekid, nagu JPEG ja PNG, mille eesmärk on vähendada algse pildi suurust.
Nagu teada, on olemas kahte tüüpi pildisurmimist: ilma kaotusteta ja kaotustega. Nimetustest selgub, et kaotusteta surumisel on võimalik saada originaalpildi andmed tagasi, samas kui kaotustega surumise puhul kaotatakse mõned andmed surumise käigus. Näiteks on JPG — kaotustega algoritm [tõlkija märkus — ärgem unustageme ka kaotusteta JPEG], samas kui PNG on kaotusteta algoritm.

Kaotusteta ja kaotustega surumise võrdlus
Pöörake tähelepanu, et paremal pildil on palju plokk-artefakte. See on kadunud teave. Naabrid sarnaste värvidega pikslid kokku surutakse ühe alana ruumi kokkuhoiuks, kuid samas kaotatakse teave tegelike pikslite kohta. Loomulikult on JPEG, PNG jne koodekites rakendatavad algoritmid palju keerukamad, kuid see on hea intuitiivne näide kadudega kompressioonist. Kaotusteta kompressioon on hea, kuid kaotusteta kompressitud failid võtavad palju ruumi kettal. On olemas tõhusamaid viise piltide kompressimiseks, kaotamata suurt hulka teavet, kuid need on üsna aeglased ja paljud kasutavad iteratiivseid lähenemisviise. See tähendab, et neid ei saa korraga käivitada mitmel kesks või graafika protsessoril. Selline piirang muudab need igapäevases kasutuses täiesti kasutuks.
Konvolutsioonilise närvivõrgu sisend
Kui midagi peab arvutama ja arvutused võivad olla ligikaudsed, lisage . Autorid kasutasid piltide tihendamise täiustamiseks üsna tavalist konvolutsioonilist närvivõrku. Esitatud meetod toimib mitte ainult samas ridades parimate lahendustega (kui mitte paremini), vaid suudab samuti kasutada paralleelseid arvutusi, mis viib märgatava kiirusetõusuni. Põhjus on selles, et konvolutsioonilised närvivõrgud (CNN) on väga head ruumilise teabe väljavõtmises piltidelt, mis esitatakse seejärel kompaktsemal kujul (näiteks säilitatakse ainult „olulised” pildi osad). Autorid soovisid seda CNN-i võimet kasutada, et paremini esitada pilte.
Arhitektuur
Autorid pakkusid välja kahekordse võrgu. Esimene võrk võtab sisendiks pildi ja genereerib kompaktse esituse (ComCNN). Selle võrgu väljundit töödeldakse seejärel tavalise koodekiga (nt JPEG). Pärast koodeki töötlemist edastatakse pilt teise võrku, mis „parandab” koodekist saadud pilti, püüdes taastada algse pildi. Autorid nimetasid seda võrku rekonstrueerivaks CNN-iks (RecCNN). Sarnaselt GAN-iga õpivad mõlemad võrgud iteratiivselt.
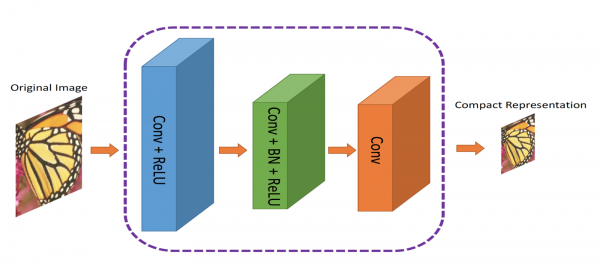
ComCNN Kompaktne esitlused edastatakse standardsele koodekile
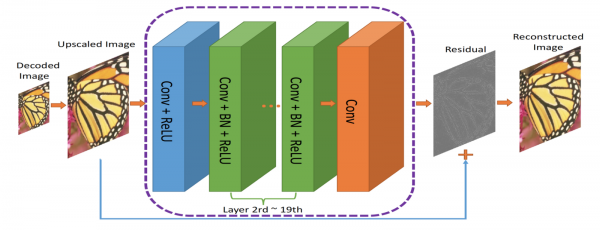
RecCNN. ComCNN väljundid skaleeritakse kasvamisega ja edastatakse RecCNN-ile, mis üritab likvideerida ülejäänud.
Koodeki väljundid skaleeritakse kasvamisega ja seejärel edastatakse RecCNN-ile. RecCNN püüab genereerida kujutise, mis sarnaneb originaaliga nii palju kui võimalik.
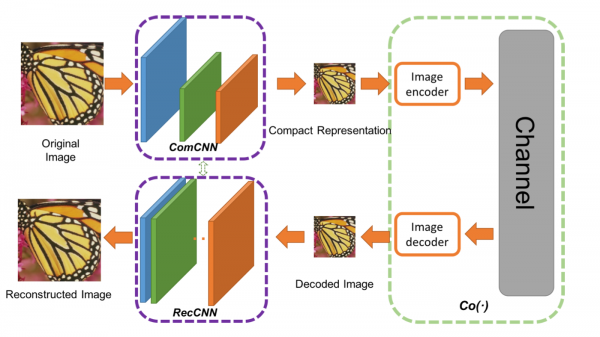
Pildikompressiooni kaudu ja kogu raamistik. Co(.) on pildikompressiooni algoritm. Autorid rakendasid JPEG, JPEG2000 ja BPG.
Mis on jääk?
Jääk võib olla post-töötluse samm, et 'parandada' koodekiga dekodeeritud pilti. Suure koguse maailmainformatsiooniga tehisintellekt suudab teha kognitiivseid otsuseid selle kohta, mida parandada. See idee põhineb , mille kohta saate lugeda üksikasju .
Kaotusefunktsioonid
Kaks kaotusefunktsiooni on kasutusel, kuna meil on kaks närvivõrku. Esimene neist, ComCNN, on märgistatud kui L1 ja määratletakse järgmiselt:
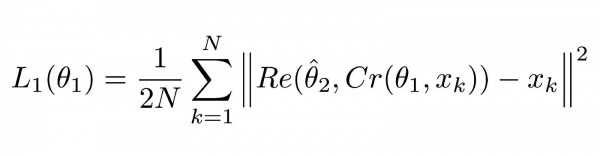
ComCNNi kaotusefunktsioon
Selgitus
See valem võib tunduda keeruline, kuid tegelikult on see standardne (keskmine ruutviga). MSE. ||² tähistab vektori normi, mida nad sisaldavad.
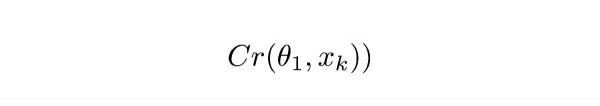
Võrrand 1.1
Cr tähistab ComCNN-i väljundit. θ tähistab ComCNN-i parameetrite õppimist, XK - see on sisendpilt.
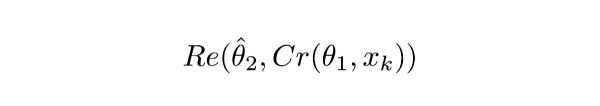
Võrrand 1.2
Re() tähendab RecCNN-i. See võrrand edastab lihtsalt võrrandi 1.1 väärtuse RecCNN-i. θ tähistab õpitavaid parameetreid RecCNN-is (ülemine kattekiht tähendab, et parameetrid on fikseeritud).
Intuitiivne määratlemine
Võrrand 1.0 paneb ComCNN-i muutma oma kaalu selliselt, et pärast taastamist RecCNN-i abil näeks lõplik pilt välja võimalikult sarnane sisendpildile. Teine kaotusfunktsioon RecCNN-is määratletakse järgmiselt:
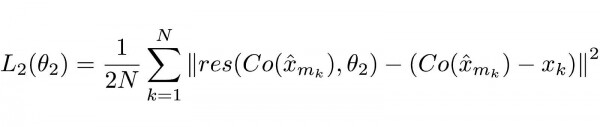
Võrrand 2.0
Selgitus
Taaskord võib funktsioon tunduda keeruline, kuid see on suuresti standardne närvivõrgu kaotusfunktsioon (MSE).
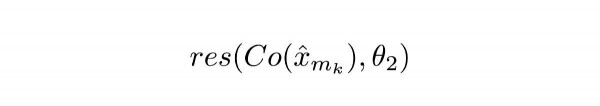
Võrrand 2.1
Co() tähendab koodeki väljundit, x ülemise kattega tähendab ComCNN-i väljundit. θ2 on RecCNN-i õpitavad parameetrid, res() tähendab lihtsalt RecCNN-i jääk väljundit. On väärt märkida, et RecCNN õpitakse Co() ja sisendpildi vahelise erinevuse põhjal, mitte sisendpildi põhjal.
Intuitiivne määratlemine
Valem 2.0 sunnib RecCNN'i muutma oma kaalusid nii, et väljund näeks välja võimalikult sarnane sisendpildiga.
Õppemudel
Mudeleid koolitatakse iteratiivselt, nagu . Esimese mudeli kaalud on fikseeritud, kuni teise mudeli kaalud uuendatakse, seejärel fikseeritakse teise mudeli kaalud, kui esimene mudel õpib.
Testid
Autorid võrreldes oma meetodit olemasolevate meetoditega, sealhulgas lihtsalt kodeerijatega. Nende meetod töötab paremini kui teised, säilitades samal ajal kõrge kiirus vastavas riistvaras. Lisaks proovisid autorid kasutada ainult ühte kahest võrgust ja märkisid jõudluse langust.
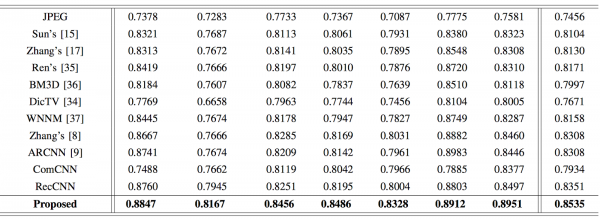
Struktuurse sarnasuse (SSIM) indeksite võrdlemine. Kõrged väärtused viitavad paremale sarnasusele originaaliga. Autorite töö tulemus on välja toodud paksus kirjas.
Kokkuvõte
Oleme uurinud uut süvaõppe rakendust piltide tihendamiseks ning arutanud närvivõrkude kasutamise võimalusi ülesannetes, mis ületavad tavapäraselt kasutatavaid, nagu näiteks piltide klassifitseerimine ja keeletöötlus. See meetod mitte ainult ei jää tänapäevastele nõudmistele alla, vaid võimaldab ka pilte töödeldes palju kiiremini.
Närvivõrkude uurimine on muutunud lihtsamaks, sest spetsiaalselt hubravchanele oleme loonud sooduskoodi HABR, mis annab täiendava 10% allahindluse, lisaks juba bänneril näidatud soodustusele.
Rohkem kursusi
Soovitatud artiklid
Allikas: habr.com
