

Tere tulemast, Habr!
Kuna tõime esmakordselt Vene turule teema ja jätkame selle arendamist. Eelkõige tundus meile huvitav teema Kafka ja . Ülevaatlik (ja üsna ettevaatlik) selle teema kohta ilmus Confluenti blogis juba eelmise aasta oktoobris Gwen Shapiro autorluses. Täna soovime teie tähelepanu juhtida uuemale, aprillikuiselle artiklile Johann Gygerilt, kes, kuigi ei suutnud peatuda küsimärgi lisamiseta pealkirjas, käsitleb teemat konkreetselt, täiustades teksti huvitavate linkidega. Palun vabandage meie vaba tõlget „chaos monkey“, kui suudate!
Sissejuhatus
Kubernetes on mõeldud töötama seisundit mitte säilitavate koormustega. Reeglina esindavad sellised töökoormused mikroteenuste arhitektuuri, need on kerged, hästi horisontaalselt skaleeritavad, alluvad 12-faktori rakenduste põhimõtetele ning võimaldavad kasutada automaatseid katkestusi (circuit breaker) ja kaose ahve (chaos monkeys).
Kafka, mis paikneb teisel pool, toimib sisuliselt jaotatud andmebaasina. Seega, töötades, peate arvestama seisundiga, mis on palju raskem kui mikroteenus. Kubernetes toetab olekuga koormusi, kuid nagu Kelsey Hightower oma kahes tweet'is osutab, tuleks nendega ettevaatlik olla:
Mõned arvavad, et kui rakendada Kubernetes olekuga koormusele, muutub see täielikult hallatavaks andmebaasiks, mis suudab konkureerida RDS-iga. See ei ole tõsi. Võib-olla, kui piisavalt vaeva näha, lisada täiendavaid komponente ja kaasata SRE-insenere, on võimalik luua RDS Kubernetes'i peale.
K soovitan alati olla äärmiselt ettevaatlik, kui käivitate olekuga koormusi Kubernetes'es. Enamik neist, kes küsivad, "kas ma saan Kubernetes'es käitada olekuga koormusi", ei oma piisavalt kogemusi Kubernetes'ega, ja sageli ka selle koormusega, mille kohta küsitakse.
Seega, kas peaks Kafka töötama Kubernetesel? Vastaküsimus: kas Kafka töötab paremini ilma Kuberneteseta? Just sellepärast tahan ma selles artiklis rõhutada, kuidas Kafka ja Kubernetes üksteist täiendavad ning millised vingerpussid võivad nende kombinatsiooniga kaasneda.
Käitusaja
Räägime kõige olulisemast — käituskeskkonnast sellisena.
Protsess
Kafka brokerid on kasutusele lihtsad CPU-ga seotud. TLS võib kaasa tuua teatud kulud. Samuti võivad Kafka kliendid CPU-d rohkem koormata, kui nad kasutavad krüpteerimist, kuid see ei mõjuta brokereid.
Mälu
Kafka brokerid tarvitavad palju mälu. JVM-i hunniku suurus on tavaliselt soovitatav piirata 4-5 GB peale, kuid vajate ka palju süsteemimälu, kuna Kafka kasutab leheküljecache'i väga aktiivselt. Kuberneteses seadke vastavalt konteinerite ressurssidele piirangud ja nõuded.
Andmete salvestamine
Konteinerites andmete salvestamine on efemerne – andmed kaovad taaskäivitamisel. Kafka andmete jaoks saab kasutada mahtu. emptyDir, ja mõju on sarnane: teie maakleri andmed kaovad pärast lõpetamist. Teie sõnumid võivad siiski teiste maaklerite juures jääda koopiatena. Seetõttu peab pärast taaskäivitamist hävinud maakler kõigepealt taastama kõik andmed, mis võib võtta aega.
Just seetõttu tuleks kasutada pikaajalist andmete salvestamist. Olgu see mitte-lokaalne pikaajaline salvestamine koos XFS failisüsteemiga või täpsemalt ext4. Ärge kasutage NFS-i. Ma hoiatasin. NFS versioonid v3 või v4 ei toimi. Lühidalt, Kafka maakler lõpetab töö, kui ei suuda andmekaustat kustutada „lollide ümbernimetamise” tõttu, mis NFS-is kehtib. Kui ma ei ole teid veel veennud, siis lugege väga tähelepanelikult . Andmete salvestamine peab olema mitte-lokaalne, et Kubernetes saaks pärast taaskäivitamist või ümberpaigutamist paindlikumalt uut sõlme valida.
Võrk
Nagu enamikul hajutatud süsteemidest, sõltub Kafka jõudlus tugevalt sellest, et võrgu latentsus oleks minimaalne ja ribalaius maksimaalne. Ärge proovige kõikide vahendajate paigutamist samale sõlmele, kuna see vähendab saadavust. Kui Kubernetes'i sõlm peaks ebaõnnestuma, ebaõnnestub ka kogu Kafka klaster. Samuti ärge hajutage Kafka klastrit eri andmekeskustesse. Sama kehtib Kubernetes'i klastrite kohta. Hea kompromiss on valida erinevad kättesaadavuspiirkonnad.
Konfiguratsioon
Tavalised manifestid
Kubernetes'i saidil on kuidas seadistada ZooKeeper'i manifestide abil. Kuna ZooKeeper on osa Kafka'st, on mugav alustada just sellest, et tutvuda, millised Kubernetes'i mõisted siinkohal rakenduvad. Kui olete sellega tuttav, saate samu mõisteid rakendada ka Kafka klastriga.
- Alustama: pod – see on minimaalne juurutatav üksus Kuberneteses. Podis asub teie koormus ning pod vastab teie klastris asuvale protsessile. Podis on üks või rohkem konteinerit. Iga ZooKeeperi serveri ensemble'is ja iga Kafka klastris olev broker töötavad eraldi podis.
- StatefulSet: StatefulSet – see on Kubernetes objekti, mis töötab mitme koormusega, mis säilitavad olekut, ning sellised koormused nõuavad koordineerimist. StatefulSet pakub garantii podide järjekorra ja ainulaadsuse osas.
- Peata teenused: Teenused võimaldavad pods'i klentidest lahti harutada loogilise nime kaudu. Kubernetes vastutab sel juhul koormuse tasakaalustamise eest. Siiski, oleku säilitamisega seotud koormuste töötlemisel, nagu ZooKeeperi ja Kafka puhul, peavad kliendid jagama teavet konkreetsete instantsidega. Siin tulevadki appi peata teenused: siis on kliendil ikkagi loogiline nimi, kuid otse podiga ei pea ühendust võtma.
- Pikajaline salvestustohm: sellised mahud on vajalikud mitte-lokaalse plokk-pikaajalise salvestuse konfigureerimiseks, mida mainiti eelnevalt.
VDS-l on võimalik installida: pakub põhjalikku manifeestide kogumit, mis lihtsustab Kafka kasutamist Kubernetes'is.
Helm-diagrammid
Helm on pakihaldur Kubernetes'ile, mida võib võrrelda operatsioonisüsteemide pakihalduritega, nagu yum, apt, Homebrew või Chocolatey. Selle abil on lihtne installida eeldefineeritud tarkvarapakette, mis on kirjeldatud Helm-diagrammides. Hästi koostatud Helm-diagramm lihtsustab keerulist ülesannet: kuidas õigesti seadistada kõik parameetrid Kafka kasutamiseks Kubernetes'is. On olemas mitu Kafka diagrammi: ametlik asub , üks neist kuulub , teine on .
Operaatorid
Täpse seadistuse tõttu on Helm'il omad puudused, seetõttu on suurenenud populaarsus ka teisel tööriistal: Kubernetes'i operaatoritel. Operaator mitte ainult ei pakenda tarkvara Kubernetes'ile, vaid võimaldab ka selle tarkvara juurutada ja hallata.
Loendis mainitakse kahte Kafka operaatorit. Üks neist on . Strimzi aitab teil Kafka-klastrit seadistada vaid mõne minutiga. Peaaegu ei ole vaja konfiguratsiooni muuta, lisaks pakub operaator ka mõningaid kasulikke funktsioone, nagu näiteks TLS-krüpteerimine "punkt-punkt" klustri sees. Confluent pakub samuti .
Tootlikkus
On väga oluline testida jõudlust, varustades teie Kafka instantsi kontrollpunktidega. Sellised testid aitavad avastada võimalikke kitsaskohti enne probleemide tekkimist. Õnneks on Kafka juba varustatud kahe jõudluse testimise tööriistaga: kafka-producer-perf-test.sh ja kafka-consumer-perf-test.sh. Kasutage neid aktiivselt. Viidatud tulemusi saate kontrollida Jay Krepsi poolt, või järgida Amazon MSK Stéphane Maarek'ilt.
Operatsioonid
Jälgimine
Süsteemi läbinähtavus on väga oluline – vastasel juhul ei saa te aru, mis seal toimub. Täna on olemas tugev tööriistade komplekt, mis tagab pilvepõhiselt monitorimise. Kaks populaarset tööriista selleks on Prometheus ja Grafana. Prometheus suudab koguda metrikat kõigilt Java protsessidelt (Kafka, Zookeeper, Kafka Connect) JMX eksportija abil – kõige lihtsamal viisil. Kui lisada cAdvisor'i metrikad, saab parema arusaama, kuidas Kubernetes ressursside kasutamist haldab.
Strimzil on väga mugav Grafana armatuurlaud Kafka jaoks. See visualiseerib võtmemetrikaid, näiteks alarekereid või neid, mis on offline. Kõik on seal väga selge. Need metrikad täiendavad teavet ressursside kasutamise ja jõudluse kohta, samuti stabiilsuse indikaatoreid. Seega saad algse Kafka klastrimonitorimise tasuta!
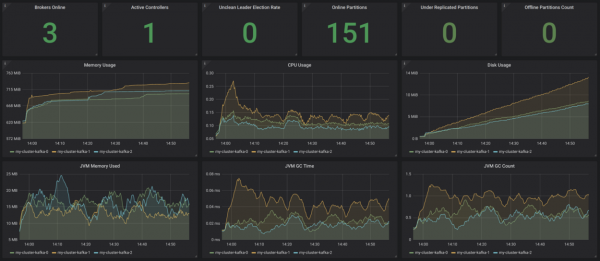
Allikas:
Seda kõike tasuks täiendada kliendimonitorimisega (metrikad tarbijate ja tootjate kohta) ning latentsuse jälgimisega (selleks on ) ja lõppkokkuvõttes monitorimisega – selleks kasutage .
Logimine
Logimine on veel üks oluline ülesanne. Veenduge, et kõik teie Kafka paigaldamise konteinerid logitakse, stdout ja stderrja hoolitsege selle eest, et teie Kubernetes klaster koguks kõik logid kesksesse logide infrastruktuuri, näiteks .
Töötavuse kontrollimine
Kubernetes kasutab elujõudluse ja valmiduse sondid, et kontrollida, kas teie pod'id töötavad normaalselt. Kui elujõudluse kontroll ebaõnnestub, peatab Kubernetes selle konteineri ja käivitab selle seejärel automaatselt uuesti, kui taaskäivitamise poliitika on õigesti seadistatud. Kui valmiduse kontroll ebaõnnestub, isoleerib Kubernetes selle pod'i teenindamisest. Nii et sellistel juhtudel ei ole enam vaja käsitsi sekkuda, mis on suur pluss.
Uuenduste väljalaskmine
StatefulSet toetab automaatseid uuendusi: RollingUpdate strateegia valimisel uuendatakse iga Kafka pod'i ükshaaval. Nii saab pikkuse seisakut vähendada nullini.
Mastaapimine
Kafka klastrite suurendamine on keeruline ülesanne. Kuberneetides on aga podide suurendamine kindla replikate arvu võrra väga lihtne, mis tähendab, et saate deklareerida nii palju Kafka broker’ite koopiaid kui soovite. Kõige keerulisem on siinkohal sektorite ümbermängimine pärast suurendamist või enne vähendamist. Jällegi aitab teid selles Kubernetes.
Haldamine
Teie Kafka klastrite haldamisega seotud ülesanded, sealhulgas teemasid loomine ja sektoreid ümber määramine, on tehtavad olemasolevate shell-skriptide abil, avades käsurida oma podides. Kuid see lahendus ei ole just ilus. Strimzi toetab teema haldamist teise operaatori kaudu. Siin on veel, millega töötada.
Varundamine ja taastamine
Nüüd sõltub meie Kafka kättesaadavus ka Kubernetesest. Kui teie Kubernetes klaster peaks kokku kukkuma, siis kõige halvemal juhul kukub kokku ka Kafka klaster. Murphy seaduse kohaselt juhtub see kindlasti ja te kaotate andmed. Selliste riskide vähendamiseks on oluline hästi läbi mõelda varunduskonseptsioon. Saate kasutada MirrorMaker'i, teine võimalus on selle jaoks S3 kasutada, nagu sellest on kirjeldatud selles Zalando.
Kokkuvõte
Kui töötate väikeste või keskmise suurusega Kafka klastritega, on kindlasti mõistlik kasutada Kubernetes, kuna see pakub täiendavat paindlikkust ja lihtsustab operaatoritega töötamist. Kui teil on väga tõsised mittefunktsionaalsed nõuded, mis puudutavad latentsust ja/või läbilaskevõimet, siis tasuks võib-olla kaaluda mõnd muud paigaldusvarianti.
Allikas: habr.com
