

Tere, Habr! Praegu on OTUSis avatud uus kursusegrupp. Kursuse algusele eelnevalt oleme traditsiooniliselt valmistanud teile huvitava materjali tõlke.
Iga päev külastab Twitterit üle saja miljoni inimese, et teada saada, mis maailmas toimub, ja arutada neid teemasid. Iga tweet ja igasugune muu kasutaja tegevus genereerib sündmuse, mis on Twitteri sisese andmeanalüüsi jaoks saadaval. Sajad töötajad analüüsivad ja visualiseerivad neid andmeid, ning nende kogemuse parandamine on Twitteri andmeplatvormi meeskonna peamine prioriteet.
Usume, et erineva tehniliste oskustega kasutajad peavad olema võimelised leidma andmeid ja pääsema hästi toimivatele SQL-põhiste analüüsi- ja visualiseerimistööriistadele. See võimaldaks täiesti uuel kasutajagrupil, kellel on vähem tehniline taust, sealhulgas andmeanalüütikutel ja tootmeeskonna juhtidel, andmetest teavet välja tuua, võimaldades neil paremini mõista ja kasutada Twitteri võimalusi. Nii democratiseerime andmeanalüüsi Twitteris.
Aja meie tööriistade ja sisemiste andmeanalüüsi võimaluste täiustamisega oleme olnud tunnistajaks Twitteri teenuse paranemisele. Sellegipoolest on veel palju ruumi kasvada. Praegused tööriistad, nagu Scalding, nõuavad programmeerimiskogemust. SQL-põhised analüüsi tööriistad, nagu Presto ja Vertica, kohtavad suurte andmemahtude korral jõudlusprobleeme. Meil on ka probleem andmete jaotamisega mitmete süsteemide vahel ilma pideva ligipääsuta neile.
Eelmisel aastal kuulutasime välja , mille raames viime osa meie Google Cloud Platformile (GCP). Oleme jõudnud järeldusele, et Google Cloudi tööriistade abi aitab meil edendada analüüsi, visualiseerimise ja masinõppe demokraatimist Twitteris:
- : ettevõtte andmesalvestus SQL-mootoriga, mis põhineb , mis on tuntud oma kiirusest, lihtsusest ja suudab toime tulla .
- tööriist suurte andmete visualiseerimiseks, mis pakub koostööfunktsioone nagu Google Docsis.
Selles artiklis räägime oma kogemustest nende tööriistadega: mida me oleme teinud, mida õppinud ja mida plaanime teha järgmiseks. Praegu keskendume pakendatud ja interaktiivsele analüüsile. Reaalajas analüüsi arutame järgmises artiklis.
Andmehoidlate ajalugu Twitteris
Enne kui süveneme BigQuery'sse, tasub lühidalt kokku võtta andmehoidlate ajalugu Twitteris. 2011. aastal tehti Twitteris andmeanalüüse Verticas ja Hadoopis. MapReduce'i loomiseks kasutatud Hadoopi tööde jaoks kasutasime Pigi. 2012. aastal asendasime Pigi Scaldinguga, millel oli Scala API, mis pakkus eeliseid nagu keerukate torujuhtmete loomise võimalus ja testimise lihtsus. Siiski oli paljudele andmeanalüütikutele ja tootemanageritele, kes olid harjunud töötama SQL-iga, see siiski piisavalt järsk õppimiskõver. Umbes 2016. aastal hakkasime kasutama Presto't SQL-iga Hadoopi andmete liidese jaoks. Spark pakkus Python'i liidest, mis teeb selle heaks valikuks ad hoc andmeuuringute ja masinõppe jaoks.
Alates 2018. aastast oleme andmete analüüsimiseks ja visualiseerimiseks kasutanud järgmisi tööriistu:
- Scalding tootmisliinidele
- Scalding ja Spark ad hoc andmeanalüüsiks ja masinõppeks
- Vertica ja Presto ad hoc ja interaktiivseks SQL-analüüsiks
- Druid väikese interaktiivse, uuriva ja madala latentsusega juurdepääsuks ajasari andmetele
- Tableau, Zeppelin ja Pivot andmete visualiseerimiseks
Oleme avastanud, et kuigi need tööriistad pakuvad väga võimsaid võimalusi, oleme kogenud raskusi nende võimaluste kättesaadavuse rakendamisega laiemale publikule Twitteris. Laiendades oma platvormi Google Cloudi abil, keskendume oma analüütika tööriistade lihtsustamisele kogu Twitteri ulatuses.
Google'i BigQuery andmetehoidla
Mõned meeskonnad Twitteris on juba lisanud BigQuery oma tootmisprotsessidesse. Kasutades nende kogemusi, oleme hakanud hindama BigQuery võimalusi kõikide Twitteri kasutusjuhtude jaoks. Meie eesmärk oli pakkuda BigQueryd kogu ettevõttele ning ka standardiseerida ja toetada seda Data Platformi tööriistade kogumina. See oli mitmel põhjusel keeruline. Me pidime looma infrastruktuuri usaldusväärsete suurte andmemahtude vastuvõtmiseks, toetama ettevõtte tasandi andmehaldust, tagama nõuetekohase ligipääsu kontrolli ja kliendi konfidentsiaalsuse tagamise. Samuti pidime looma süsteemid ressursside jaotamiseks, jälgimiseks ja tasude tagastamiseks, et meeskonnad saaksid BigQueryd tõhusalt kasutada.
Novembris 2018. aastal vabastasime BigQuery ja Data Studio alfarelise kogu ettevõtte jaoks. Pakume Twitteri töötajatele mõned meie kõige sagedamini kasutatavad tabelid, milles on puhastatud isikuandmed. BigQuery-d kasutas rohkem kui 250 kasutajat erinevatest meeskondadest, sealhulgas inseneri-, finants- ja turundusosakondadest. Äsja viidi läbi umbes 8000 päringut, töötledes umbes 100 PB kuus, välja arvatud ajastatud päringud. Saades väga positiivset tagasisidet, otsustasime edasi liikuda ja pakkuda BigQuery-d peamise vahendina andmete haldamiseks Twitteris.
Siin on meie Google BigQuery andmehoidla kõrgetasemeline arhitektuuri skeem.
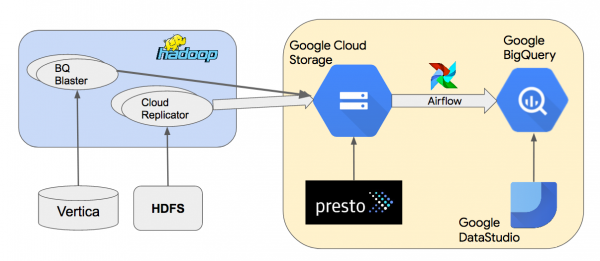
Kopeerime andmed kohalikest Hadoopi klusteritest Google Cloud Storage'i (GCS), kasutades sisemist tööriista Cloud Replicator. Seejärel kasutame Apache Airflow'd torude loomiseks, mis kasutavad „“ andmete laadimiseks GCS-ist BigQuery-sse. Kasutame Presto't Parquet või Thrift-LZO andmekogumite pärimise jaoks GCS-is. BQ Blaster on sisemine Scalding tööriist HDFS Vertica ja Thrift-LZO andmekogumite laadimiseks BigQuery-sse.
Järgmistes jaotistes arutame meie lähenemist ja teadmisi kasutatavuse, jõudluse, andmehaldamise, süsteemi töökindluse ja kulude osas.
Kasutusmugavus
Oleme avastanud, et BigQuery kasutamine oli kasutajatele lihtne, kuna see ei nõudnud tarkvara installimist ja kasutajad pääsesid sellele ligi intuitiivse veebiliidese kaudu. Siiski pidi kasutajad tutvuma mõnede GCP funktsioonide ja kontseptidega, sealhulgas ressursside nagu projektid, andmekogud ja tabelid. Oleme välja töötanud õppematerjalid ja juhendid, et aidata kasutajatel alustada. Põhiteadmiste omandamine aitas kasutajatel andmekogudes navigeerida, vaadata tabelite skeemi ja andmeid, sooritada lihtsaid päringuid ning visualiseerida tulemusi Data Studios.
Meie eesmärk andmete sisestamisel BigQuerys oli tagada andmekogude HDFS või GCS sujuv üleslaadimine ühe klikiga. Me käsitlesime (hallatav Airflow), kuid ei suutnud seda kasutada meie „Domain Restricted Sharing” turvamudeli tõttu (lisainfot leiate altpoolt jaotises „Andmete haldamine”). Katsetasime Google Data Transfer Service'i (DTS) kasutamist BigQuery koormustööde korraldamiseks. Kuigi DTS seadistamine oli kiire, ei olnud see paindlik sõltuvustega konveierite loomisel. Meie alfa versiooni jaoks lõime oma Apache Airflow keskkonna GCE-s ja valmistame selle ette tootmisse viimiseks ning suudame toetada rohkem andmeallikaid, nagu Vertica.
BigQuery-sse andmete edastamiseks loovad kasutajad lihtsaid SQL-andmepipe, kasutades ajastatud päringuid. Kompleksete mitmeastmeliste konveierite jaoks, kus on sõltuvused, plaanime kasutada kas meie oma Airflow infrastruktuuri või Cloud Composerit koos .
Tootlikkus
BigQuery on loodud üldotstarbeliste SQL-päringute jaoks, mis töötlevad suuri andmekoguseid. Seda ei ole mõeldud madala latentsusega päringuteks, mis nõuavad suurt läbilaskvust, mis on vajalikud tehinguandmebaasi jaoks, ega madala latentsusega ajaseeria analüüsi jaoks. . Interaktiivsete analüüsiküsimuste jaoks ootavad meie kasutajad alla ühe minuti vastusaega. Olime pidanud kavandama BigQuery kasutamise viisi, mis vastab nende ootustele. Et tagada meie kasutajatele ettearvatav jõudlus, kasutasime BigQuery funktsionaalsust, mis on saadaval fikseeritud tasu alusel klientidele, mis võimaldab projektide omanikitel reserveerida minimaalsed plokid oma päringute jaoks. BigQuery on arvutusvõimsuse ühik, mis on vajalik SQL päringute täitmiseks.
Oleme analüüsinud rohkem kui 800 päringut, mis töötlevad umbes 1 TB andmeid, ja avastanud, et keskmine täitmise aeg oli 30 sekundit. Samuti selgus, et töötluse tulemuslikkus sõltub tugevasti meie sloti kasutamisest erinevates projektides ja ülesannetes. Pidi olema selgelt eristatud meie tootmis- ja ad hoc slotide reservid, et hoida tootlikkust tootmistsenaariumide ja interaktiivse analüüsi jaoks. See avaldas suurt mõju meie disainile slotide reserveerimise ja projektide hierarhia osas.
Andmehalduse, funktsionaalsuse ja süsteemide kulude kohta räägime juba lähiajal tõlke teises osas, aga praegu kutsume kõiki huvilisi , kus on võimalus põhjalikult tutvuda kursusega ning esitada küsimusi meie eksperdile — Egor Mateshukile (kogenud andmeinsener, MaximaTelecom).
Loe edasi:
Allikas: habr.com
