

Tere, Habr! Viimased paar kuud oleme elanud väga huvitavas olukorras ja tahaksin jagada meie infrastruktuuri skaleerimise lugu. Selle aja jooksul on SberMarket tellimustes kasvanud neljakordseks ja käivitanud teenuse 17 uues linnas. Toidu kohaletoimetamise nõudluse plahvatuslik kasv nõudis meilt infrastruktuuri skaleerimist. Kõige huvitavamatest ja kasulikest järeldustest loe allpool.

Minu nimi on Dima Bobylev, olen SberMarketi tehniline direktor. Kuna see on meie blogi esimene postitus, ütlen paar sõna enda ja ettevõtte kohta. Eelmisel sügisel osalesin noorte liidrite konkursil Runetis. Konkursi raames sellest, kuidas me SberMarketis näeme sisekultuuri ja lähenemist teenuse arendamisele. Ja kuigi konkursil võita ei õnnestunud, sõnastasin endale põhialused IT-ökosüsteemi arendamiseks.
Meeskonna juhtimisel on oluline mõista ja leida tasakaal selle vahel, mida äri vajab, ja iga konkreetse arendaja vajadustega. Praegu kasvab SberMarket aastaga 13 korda, mis mõjutab toodet, nõudes pidevat arendustempot ja mahtude suurendamist. Sellegipoolest anname arendajatele piisavalt aega eelanalüüsiks ja kvaliteetse koodi kirjutamiseks. Meie loodud lähenemine aitab mitte ainult töötava toote loomisel, vaid ka selle edasisel skaleerimisel ja arendamisel. Sellise kasvu tulemusena on SberMarket juba muutunud toidukullerite teenuste liidriks: toimetame igapäevaselt umbes 18 000 tellimust, samas kui veel aasta alguses oli neid umbes 3500.

Kord palus klient SberMarketi kulleril toidud toimetada kontaktivabalt — otse rõdule.
Kuid liigume konkreetsete asjade juurde. Viimased paar kuud oleme aktiivselt tegelenud meie ettevõtte infrastruktuuri ulatuse suurendamisega. See vajadus tulenes nii välistest kui ka sisemistest teguritest. Samal ajal kui kliendibaas laienes, kasvas ühendatud kaupade arv 90-lt aasta alguses rohkem kui 200-ni mai keskel. Me olime muidugi ette valmistunud, broneerides põhistruktuuri ja arvutades välja võimaluse virtuaalmasinate vertikaalseks ja horisontaalseks ulatuseks, mis asuvad Yandexi pilves. Kuid praktika on näidanud: "Kõik, mis võib valesti minna, lähebki valesti". Ja täna tahan ma jagada kõige huvitavamaid olukordi, mis nende nädalate jooksul juhtusid. Loodan, et meie kogemus on teile kasulik.
Slave on täielikult valmis tegevuseks
Eelnevalt, enne pandeemia algust, seisisime silmitsi kasvava nõudlusega meie backend-serverite järele. Kodukullerteenuste tellimise trend hakkas kasvama, ja COVID-19 esimeste isoleerimismeetmete kehtestamisega kasvas koormus dramaatiliselt päevast päeva. Tekkinud vajadus oli kiiresti vähendada põhiraamatupidamise master-serverite koormust ja suunata osa lugemisest tehtud päringutest replica-serveritele.
Oliime sellele sammule eelnevalt ette valmistunud ning selleks oli juba käivitatud 2 replica-serverit. Need serverid töötlesid peamiselt andmevahetuseks partneritega mõeldud infotoodete genereerimise batch-ülesandeid. Need protsessid genereerisid liigset koormust ja olid täiesti õigustatud, et võeti paar kuud varem „välja”.
Kuna Slave'is toimus replikatsioon, järgime põhimõtet, et rakendused saavad nendega töötada ainult lugemisrežiimis. Hädaolukorra taastamisplaan nägi ette, et katastroofi korral saame lihtsalt mountida Slave Master'i kohale ja suunata kõik kirjutamis- ja lugemisettepanekud Slave'ile. Kuid soovisime ka replikate kasutamist analüütika osakonna vajadusteks, seetõttu ei olnud serverid täielikult muutunud lugemisrežiimi, vaid igas hostis oli oma kasutajate kogum, kellest mõned omasid kirjutamisõigusi vahepealsete arvutuste tulemuste salvestamiseks.
Teatud koormustasandini piisab meistrist nii kirjutamiseks kui lugemiseks http-päringute töötlemisel. Märtsi keskel, kui Sbermarketi otsus kaug- tööle täielikult üle minna kehtestati, algas meie RPS-i kiire kasv. Üha rohkem meie kliente läks isoleerimisele või töötas kodus, mis kajastus koormusnäitajates.
«Meister» jõudlus ei olnud enam piisav, seetõttu hakkasime osa kõige raskematest lugemisest päringutest replika peale suunama. Kirjutamis päringute suunamiseks meistrisse ja lugemiseks slave'ile kasutasime ruby gem'i «». Loodud eraldi kasutaja koos _readonly postfixiga, kellel ei olnud kirjutamisõigusi. Kuid ühe hosti konfiguratsiooni vea tõttu läks osa kirjutamis päringutest slave-serverisse kasutajana, kellel olid vastavad õigused.
Probleem ei ilmnenud kohe, kuna suurenenud koormus tõi kaasa slave'ide mahajäämust. Andmete ebakõla avastati hommikul, kui pärast öiseid impordeid ei olnud slave'id meisteriga «järgmised». Kirjutasime selle kõrgele koormusele teenusele endale ja impordile, mis oli seotud uute poodide avamisega. Kuid andmete edastamine mitme tunni viivitususega ei olnud vastuvõetav ning suunasime protsessid teisele analüütilisele slave'ile, kuna tal olid bosuuremad ressursid ja ta ei olnud lugemis päringutest koormatud (mida me endale replikatsiooni mahajäämust seletades kinnitasime).
Kui saime selgeks põhjus, miks põhja slave oli kokku kukkunud, oli analüüs juba sama põhjusel töö lõpetanud. Kuigi meil oli kaks täiendavat serverit, kuhu plaanisime koormuse üle viia, kui meester server peaks ebaõnnestuma, selgus häiriva vea tõttu, et kriitilise hetke jooksul ei olnud ühtegi serverit saadaval.
Kuna tegime mitte ainult andmebaasi dump'i (tagasiveo aeg oli sel hetkel umbes 5 tundi), vaid ka master-serveri snapshot'i, õnnestus replikat käivitada kahe tunni jooksul. Pärast seda ootas meid siiski replikatsiooni logi pealekandmine pikka aega (sest protsess toimub ühesuunaliselt, kuid see on juba hoopis teine lugu).
Väljund: Pärast sellist intsidenti oli selge, et peame loobuma kasutajate kirjutamise piiramisest ja kuulutama kogu serveri lugemiseks. Sellise lähenemisega ei ole kahtlust, et repliikide kättesaadavus kriitiliselt olulistel hetkedel on tagatud.
Isegi ühe raske päringu optimeerimine võib andmebaasi "ellu äratada".
Kuigi uuendame veebilehe katalooge pidevalt, esitati Slave-serveritele tehtud päringud Master-serverist väikese viivitusega. Aeg, mille jooksul avastasime ja lahendasime probleemi, et "üksused kaotasid äkitselt ühenduse", ületas "psühholoogilise piiri" (selle aja jooksul võisid hinnad muutuda ja kliendid oleksid näinud aegunud andmeid), mistõttu pidime suunama kõik päringud peamiselt andmebaasiserverile. Tulemuseks oli, et veebileht töötas aeglaselt… aga vähemalt töötas. Ja seni, kuni Slave taastus, ei jäänud meil muud kui optimeerida.
Kuni Slave-serverid taastusid, venisid minutid aeglaselt, Master oli ülekoormatud ja panime kõik jõud aktiivsete ülesannete optimeerimisele vastavalt „Pareto printsiibile”: valisime TOP-päringud, mis andsid suure osa koormusest, ja alustasime häälestamist. Seda tehti otse „liikvel olles”.
Huvitav nähtus oli see, et ülekoormatud MySQL reageerib isegi tavaliste protsesside väikeste parenduste peale. Paar päringu optimeerimist, mis andsid vaid 5% kogu koormusest, näitas juba olulist CPU laadimise vähendamist. Selle tulemusena suutsime tagada Masteri tööks andmebaasis piisava ressursi varu ja saada vajalik taastumisaeg replika jaoks.
Väljund: Isegi väike optimeerimine võimaldab „ellu jääda” koormuse all mitu tundi. Just seda meil oli piisavalt serverite replika taastumise ajaks. Muide, päringute optimeerimise tehnilist külge arutame ühes järgmistest postitustest. Nii et jälgige meie blogi, kui see teile kasulikuks osutub.
Korrastage partnerite teenuste töövõime jälgimine
Kliendi tellimuste töötlemisega tegelemise tõttu suhtlevad meie teenused pidevalt kolmandate osapoolte API-dega — need on SMS-i saatmise väravad, makseplatvormid, marsruutimissüsteemid, geokooder, FNS teenus ja paljud teised süsteemid. Ja kui koormus hakkas kiiresti kasvama, sattusime partnerite teenuste API-de piirangutesse, mille üle me varem isegi ei mõelnud.
Partnerite teenuste kvootide ootamatu ületamine võib põhjustada teie enda süsteemi seisakuid. Paljud API-d blokeerivad kliente, kes ületavad limiite, ja mõnel juhul võib liigne päringute arv partneri tootmisprotsessi üle koormata.
Näiteks, kui kohaletoimetamiste arv kasvas, ei suutnud saateteenused neid ülesandeid, nagu jaotamine ja marsruutide määramine, täita. Tulemusena oli nii, et tellimused olid tehtud, kuid marsruudi loomise teenus ei töötanud. Tuleb öelda, et meie logistika spetsialistid tegid sellistes tingimustes peaaegu impossibli; meeskonna täpne koostöö aitas ajutisi teenuste katkestusi tasakaalustada. Kuid sellist tellimuste mahtu ei ole konstantsete käsitsi töötlemisega võimalik pidevalt hallata, ja varsti oleksime silmitsi vastuvõetamatu lõhega tellimuste ja nende täitmise vahel.
Tegime mitmeid organisatsioonilisi samme ja meeskonna sujuv koostöö aitas meil aega võita, kuni leppisime kokku uutel tingimustel ja ootasime mõnedelt partneritelt teenuste uuendamist. On ka teisi API-sid, mis paistavad silma kõrge vastupidavuse ja talumatute hindadega kõrge liikluse korral. Näiteks kasutasime alguses ühte tuntud kaardistamis-API-d, et määrata kohaletoimetamise punkti aadress. Kuid kuu lõpuks saime üsna soliidse arve peaaegu 2 miljoni rubla ulatuses. Pärast seda otsustasime selle kiiresti välja vahetada. Ma ei hakka reklaamima, aga võin öelda, et meie kulud on märgatavalt vähenenud.
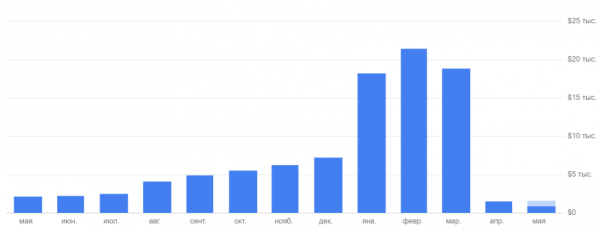
Väljund: On väga oluline jälgida kõigi partnerite teenuste töötingimusi ja neid meeles pidada. Isegi kui täna tundub, et need on teile „suure varuga”, ei tähenda see, et nad ei saa homme kasvu takistuseks. Ja muidugi on parem eelnevalt kokku leppida teenuse suurenenud nõudmiste rahalistes tingimustes.
Mõnikord selgub, et „” (c) ei aita
Oleme harjunud „ummikute“ esinemisega peamises andmebaasis või rakendusserverites, kuid skaleerimise ajal võivad probleemid ilmuda seal, kus neid ei oodata. Täisteksti otsingu jaoks kasutame Apache Solr mootorit. Koormuse suurenedes oleme märganud vastuseaja vähenemist, samas kui serveri protsessori koormus jõudis 100%-ni. Mis võiks olla lihtsam — anname Solr konteinerile rohkem ressursse.
Oodatud tootlikuse kasvupiiri asemel server lihtsalt „surus ära“. See laadis kohe 100% ja vastas veel aeglasemalt. Alguses oli meil 2 tuuma ja 2 GB RAM-i. Otsustasime teha seda, mis tavaliselt aitab — andsime serverile 8 tuuma ja 32 GB. Kõik muutus palju halvemaks (kuidas täpselt ja miks — sellest räägime eraldi postituses).
Mõne päeva jooksul saime aru selle küsimuse keerukusest ning saavutasime optimaalse tootlikkuse 8 tuuma ja 32 GB korral. See konfiguratsioon võimaldab ka täna koormust jätkuvalt suurendada, mis on väga oluline, sest kasv toimub mitte ainult klientide, vaid ka ühendatud poodide arvu osas — kahe kuuga suurenenud arv on kaks korda.
Väljund: Tavalised meetodid nagu "veel riistvara lisamine" ei tööta alati. Seega, teenuse skaleerimisel on oluline aru saada, kui hästi see ressursse kasutab ja testida seda ettevalmistavas faasis uutes tingimustes.
Stateless — lihtsa horisontaalse skaleerimise võti
Üldiselt järgib meie meeskond tuntud lähenemist: teenused ei peaks omama sisemist olekut (stateless) ja peaksid olema sõltumatud käituskeskkonnast. See on võimaldanud meil taluda koormuse kasvu lihtsa horisontaalse skaleerimise abil. Kuid meil oli üks erand — pikaajaliste taustateenuste töötleja. See tegeles e-kirjade ja SMS-ide saatmise, sündmuste töötlemise, voogude genereerimise, hindade ja varude importimise, piltide töötlemisega. Tekkis olukord, kus see sõltus kohalikust failide salvestamisest ja oli ainus eksemplar.
Kuna ülesannete arv järjekorras töötlejat (mis loomulikult juhtus koos tellimuste arvu kasvuga) kasvas, muutus host, millel töötleja ja failide salvestamine asusid, piiravaks teguriks. Selle tulemusena peatus valikute ja hindade uuendamine, kasutajatele teavituste saatmine ja palju muid kriitilisi funktsioone, mis jäid järjekorda kinni. Ops meeskond viis kiiresti failide salvestamise S3-sarnasesse võrgu salvestusse ja see võimaldas meil tõsta mitmeid võimsaid masinaid, et laiendada taustatöötluse süsteemi.
Väljund: Stateless reeglit tuleb järgida kõigi komponentide puhul ilma eranditeta, isegi kui tundub, et siin me kindlasti ei jää kinni. Olulisem on kulutada veidi aega süsteemide töö õigele korraldamisele, kui hiljem kiiruselt koodi ümber kirjutada ja parandada teenust, mis kogeb ülekoormust.
7 põhimõtet intensiivseks kasvuks
Hoolimata täiendavate ressursside olemasolust oleme kasvu käigus kokkupõrganud mitmete probleemidega. Selle aja jooksul on tellimuste arv kasvanud rohkem kui neli korda. Praegu toimetame juba rohkem kui 17 000 tellimust päevas 62 linnas ning plaanime oma tegevust veelgi laiendada — 2020. aasta esimeses pooles on plaanis teenuse käivitamine kogu Venemaal. Selleks, et hakkama saada kasvava koormusega, arvestades juba saadud kogemusi, oleme välja töötanud 7 põhieesmärki pideva kasvu tingimustes:
- Juhtimine. Oleme loonud Jira-sse tahvli, kus iga juhtum peegeldub pileti näol. See aitab tõeliselt prioriseerida ja tegeleda juhtu puudutavate ülesannetega. Sest sisuliselt ei ole hirmus eksida — hirmus on eksida kaks korda sama asja pärast. Nende juhtumite puhul, kus probleemid korduvad kiiremini, kui suudame põhjusest vabaneda, peaks olema valmis tegevusjuhend, sest suurte koormuste ajal on oluline reageerida viivitamatult.
- Jälgimine see all sides of the infrastructure. Thanks to this, we were able to forecast the growth of load and correctly identify the bottlenecks to prioritize their resolution. Most likely, under heavy load, everything you didn't expect will break or start lagging. Therefore, it's best to create new alerts right after the first incidents occur, to monitor and anticipate them.
- Correct alerts are essential during a sudden increase in load. Firstly, they must report exactly what has broken. Secondly, there shouldn't be too many alerts, as an abundance of non-critical alerts leads to the ignoring of all notifications altogether.
- Applications must be stateless. We have confirmed that there should be no exceptions to this rule. Complete independence from the runtime environment is necessary. For this, you can store shared data in a database or, for example, directly in S3. Even better is to follow the rules.. Äkilise kasvu korral pole aega koodi optimeerida ja koormuse eest tuleb hoolitseda lihtsalt arvutusressursside otsese suurendamise ja horisontaalse skaleerimise abil.
- Väliste teenuste kvotid ja jõudlus. Kiire kasvu korral võib probleem tekkida mitte ainult teie infrastruktuuris, vaid ka välises teenuses. Kõige masendavam on see, kui see juhtub mitte rikke tõttu, vaid kvotide või piiride saavutamise tõttu. Seega peavad ka välised teenused skaleeruma sama hästi nagu teie ise.
- Jagage protsesse ja järjekordi. See aitab väga palju, kui ühes väravas tekib ummik. Me ei oleks andmeedastuses viivitustega silmitsi, kui SMS-ide saatmise täisjärjekorrad ei segaks teavituste vahetust infosüsteemide vahel. Jah, ja töötajate arvu oleks lihtsam suurendada, kui nad töötaksid eraldi.
- Finantsreaalsused. Kui andmete voogude plahvatuslik kasv toimub, pole aega hinnaplaanide ja tellimuste üle järele mõelda. Kuid neid tuleb meeles pidada, eriti kui olete väike ettevõte. Suure arve võib esitada iga API omanik, samuti teie hostimise teenusepakkuja. Seega tuleb lepingud hoolikalt läbi lugeda.
Kokkuvõte
Kuigi kaotusi oli, oleme sellest etapis üle saanud ja täna püüame järgiselt kõiki leitud põhimõtteid, kusjuures iga masin on suuteline lihtsaks jõudluse neljakordseks suurendamiseks, et toime tulla ootamatustega.
Järgnevates postitustes jagame oma kogemusi Apache Solri jõudluse languse uurimisel, räägime päringute optimeerimisest ning sellest, kuidas suhe FNS-iga aitab ettevõttel raha säästa. Liituge meie blogiga, et mitte midagi vahele jätta, ja kirjutage kommentaaridesse, kas teil on olnud sarnaseid probleeme liikluse kasvamisel.

Ainult registreeritud kasutajad saavad küsitluses osaleda. , palun.
Kas teil on olnud teenuse aeglustumist või langemist järsu koormuse suurenemise tõttu:
55,6%Võimetus kiiresti arvutusressursse lisada
16,7%Hostimise teenusepakkuja infrastruktuuri piirangud
33,3%Kolmandate osapoolte API piirangud
27,8%Stateless-printsiipide rikkumine oma rakendustes
88,9%Koodi mitteoptimaalsus oma teenustes
Hääletas 18 kasutajat. 6 kasutajat jäi erapooletuks.
Allikas: habr.com
