

Minu nimi on Anton Baderin. Töötan Kõrgete Tehnoloogiate Keskuses ja tegeleb süsteemiadministreerimisega. Kuu aega tagasi lõppes meie ettevõtte konverents, kus jagasime saadud kogemusi meie linna IT-kommuuniga. Rääkisin veebirakenduste jälgimisest. Materjal oli mõeldud junior- või middle-taseme spetsialistidele, kes ei ole seda protsessi nullist üles ehitanud.

Iga jälgimissüsteemi aluseks olev kivi on äriülesannete lahendamine. Jälgimine iseenesest ei huvita kedagi. Aga mida soovib äri? Et kõik töötaks kiiresti ja tõrgeteta. Äri soovib proaktiivsust, et me ise tuvastaksime teenuse tööprobleeme ja lahendaksime need võimalikult kiiresti. Just need ülesanded olid need, mida ma lahendasin kogu eelmisel aastal ühe meie kliendi projektis.
Projektist
Projekt on üks suurimaid lojaalsusprogramme riigis. Me aitame jaekettidel suurendada müügitiheduse erinevate turundusinstrumentide, nagu boonuskardid, abil. Kokku hõlmab projekt 14 rakendust, mis töötavad kümnel serveril.
Kandideerimisprotsessi käigus olen korduvalt märganud, et administraatorid ei pruugi alati õigesti läheneda veebirakenduste jälgimisele: endiselt toetuvad paljud ainult operatsioonisüsteemi mõõdikutele ja harva jälgivad teenuseid.
Minu kogemuse kohaselt põhines kliendi jälgimissüsteem varem Icingal. See ei lahendanud ülaltoodud probleeme. Tihti teatas klient ise meile probleemidest ja mitte harva puudusid meil lihtsalt andmed, et välja selgitada põhjus.
Lisaks oli selgelt mõistetav, et selle edasine arendamine on perspektiivitu. Arvan, et need, kes tunnevad Icingat, saavad mind aru. Nii otsustasime projekti veebirakenduste jälgimissüsteemi täielikult ümber töötada.
Prometheus
Valisime Prometheuse, tuginedes kolmele peamisele näitajale:
- Suure hulga mõõdikute kättesaadavus. Meil on neid 60 000. Loomulikult tuleb märkida, et enamikku neist me ei kasuta (ilmselt umbes 95%). Teisest küljest on need kõik suhteliselt odavad. See on meie jaoks teistsugune äärmuse võrreldes varem kasutatud Icingaga. Seal oli mõõdikute lisamine eriline piin: olemasolevad olid väga kallid (piisab, kui vaadata mis tahes pistiku allikaid). Iga pistikprogramm kujutas endast Bash või Python skripti, mille käitamine polnud ressursikasutuse mõttes odav.
- Süsteem tarbib suhteliselt vähe ressursse. Kõigi meie mõõdikute jaoks piisab 600 MB RAM-ist, 15% ühest tuumast ja paari kümne IOPS-i. Loomulikult tuleb mõõdikute eksportijaid käivitada, kuid need on kirjutatud Go-s ja ei ole samuti ressursihädas. Ma ei usu, et see on tänapäeva kontekstis probleem.
- Annab võimaluse üleminekuks Kubernetesesse. Arvestades kliendi plaane — valik on ilmne.
ELK
Varem ei kogunud ega töötlenud logisid. Puudused on kõigile selged. Valisime ELK-i, kuna meil oli juba kogemus selle süsteemiga. Säilitame seal ainult rakenduste logisid. Peamised valikukriteeriumid olid täisteksti otsing ja selle kiirus.
Clickhouse
Alguses langes valik InfluxDB peale. Mõistsime vajadust koguda Nginx logisid, statistikat pg_stat_statements-st ning hoida ajaloolisi andmeid Prometheus. Influx ei meeldinud meile, kuna ta hakkas perioodiliselt tarbima suurt hulka mälu ja kukkus kokku. Lisaks soovisime rühmitada päringuid remote_addr-i järgi, kuid selle SÜD rühmitamine on võimalik vaid märgistuste järgi. Märgised on kallid (mälu), nende hulk on tinglikult piiratud.
Alustasime otsinguid uuesti. Vajasime analüütilist baasi, mille ressursikasutus oleks minimaalne, eelistatavalt andmete kompresseerimisega kettale.
Clickhouse vastab kõikidele nendele kriteeriumidele ja valiku üle ei ole meil kordagi kahetsust. Me ei kirjuta sinna mingeid silmapaistvaid andmemahtusid (süstimiste arv on umbes viis tuhat minutis).
NewRelic
NewRelic on ajalooliselt olnud meiega, kuna see oli kliendi valik. Meie juures kasutatakse seda APM-ina.
Zabbix
Kasutame Zabbixit ainult erinevate API-de musta kasti jälgimiseks.
Jälgimise lähenemise määratlemine
Me soovisime ülesandeid lahti dekomponeerida, et seeläbi jälgimismeetodit süsteemsemaks muuta.
Selleks jagasin meie süsteemi järgmistesse tasemetesse:
- „riistvara“ ja VMS;
- operatsioonisüsteem;
- süsteemiteenused, tarkvara kogum;
- rakendus;
- äri loogika.
Millised on sellise lähenemise eelised:
- me teame, kes on iga tasandi töö eest vastutav ja seeläbi saame häireid saata;
- me saame struktuuri kasutada häirete vaigistamiseks — oleks kummaline saata häire andmebaasi kättesaamatuse kohta, kui kogu virtuaalne masin on tegelikult kättesaamatu.
Kuna meie ülesanne on tuvastada süsteemi töö katkemise juhtumeid, peame igal tasemel välja tooma teatud metrikate komplekti, millele tasub tähelepanu pöörata häirete seadistamisel. Jätkame tasemetega „VMS“, „Operatsioonisüsteem“ ja „Süsteemiteenused, tarkvara kogum“.
Virtuaalmasinad
Veebihosting välja tooma protsessori, ketta, mälu ja võrgu. Ja esimestega oli meil probleeme. Seega, metrikad:
CPU varastatud aeg — kui ostate virtuaalmasina Amazonis (näiteks t2.micro), tuleks mõista, et teile ei eraldata ühte täisprotsessorituuma, vaid vaid osa selle ajast. Ja kui te selle ära kasutate, hakkavad nad teie protsessorilt aega võtma.
See mõõdik võimaldab jälgida selliseid hetki ja teha otsuseid. Näiteks, kas on vaja valida jõulisem paket või jagada taustprotsesside töötlemine ja API päringud erinevatele serveritele. serverile.
IOPS + CPU iowait aeg — miks on paljudel pilvehostimistel probleem, et nad ei anna piisavalt IOPS-i. Veelgi enam, madal IOPS graafik ei ole nende jaoks argument. Seetõttu on mõistlik jälgida ka CPU iowait aega. Selle paari graafikuga — madalate IOPS-ide ja kõrge sisendi/väljundi ooteajaga — saab juba teenusepakkujaga rääkida ja probleemi lahendada.
Operatsioonisüsteem
Operatsioonisüsteemi mõõdud:
- vaba mälu protsentides;
- swap kasutamise aktiivsus: vmstat swapin, swapout;
- saadaval inode arv ja vaba koht failisüsteemis protsentides;
- keskmine koormus;
- ühenduste arv olekus tw;
- conntrack tabeli täitumus;
- võrgu töö kvaliteeti saab jälgida utiliidiga ss, iproute2 paketiga — saab selle väljundist RTT-ühenduste näitaja ja grupeerida sihtportide järgi.
Operatsioonisüsteemi tasandil on meil selline mõisted nagu protsessid. Oluline on eristada süsteemis protsesside kogumit, mis mängib olulist rolli selle töös. Kui teil on näiteks mitu pgpooli, peate koguma teavet igaühe kohta.
Mõõdikute kogum on järgmine:
- CPU;
- mälu — eelkõige residentmälu;
- IO — soovitatavalt IOPS-ides;
- FileFd — avatud ja limiit;
- olulised leheküljetaandumised — nii saate aru, milline protsess vahetub.
Kogu jälgimine on meil välja arendatud Dockeris, mõõdikute andmete kogumiseks kasutame Cadvisorit. Teistel masinatel rakendame process-exporterit.
Süsteemiteenused, tarkvarastak
Igal rakendusel on oma spetsiifika ja keeruline on eristada mingit kindlat mõõdikute kogumit.
Üldiseks kogumikuks on:
- päringute määr;
- vigade arv;
- latentsus;
- saturation.
Kõige silmapaistvamad näited selle taseme jälgimisest on meil — Nginx ja PostgreSQL.
Meie süsteemi kõige koormatum teenus on andmebaas. Varem oli meil sageli probleeme välja selgitada, millega andmebaas tegeleb.
Oleme täheldanud kõrget koormust kettadel, kuid logid ei näidanud täpselt midagi. Selle probleemiga tegime silmitsi pg_stat_statements, mis on vaade, kus kogutakse päringute statistikat.
See on kõik, mida administreerija vajab.
Koostame lugemise ja kirjutamise päringute aktiivsusgraafikuid:
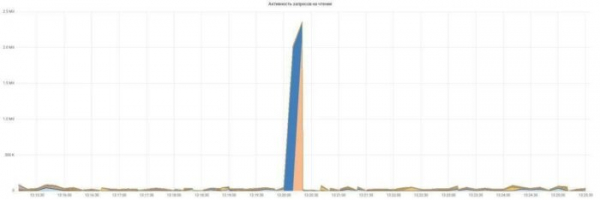
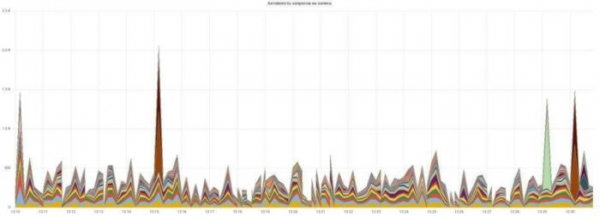
Kõik on lihtne ja arusaadav, igal päringul on oma värv.
Mitte vähem silmatorkav näide on Nginx-logid. Pole üllatav, et harva keegi neid analüüsib või nimetab kohustuslikuks. Standardne formaat ei ole eriti informatiivne ja seda tuleb laiendada.
Isiklikult lisasin request_time, upstream_response_time, body_bytes_sent, request_length, request_id. Koostame vastusaegade ja veahulkade graafikuid:
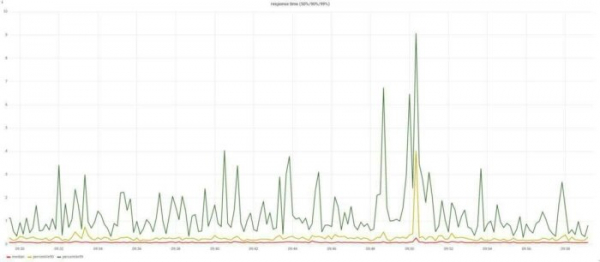
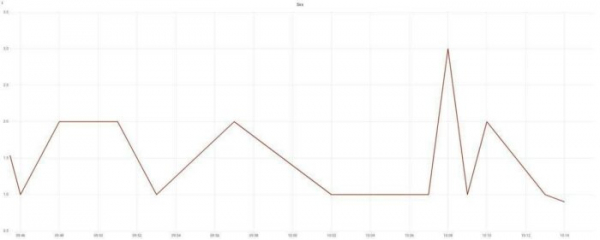
Koostame vastusaegade ja veahulkade graafikuid. Kas mäletate? Rääkisin ärieesmärkidest? Kiiresti ja ilma vigadeta? Oleme nende kahe graafikuga need küsimused juba lahendanud. Ja nende põhjal on juba võimalik helistada valveadminitele.
Kuid jääb veel üks probleem - tagada kiire põhjuse kõrvaldamine.
Incidendi kõrvaldamine
Kogu protsessi alates probleemist tuvastamisest kuni lahendamiseni saab jagada mitmeks sammuks:
- probleemi tuvastamine;
- valveadministraatori teavitamine;
- reaktsioon juhtumile;
- põhjuste kõrvaldamine.
Oluline on, et me teeksime seda võimalikult kiiresti. Ja kuigi probleemide tuvastamise ja teate saatmise etappidel ei saa me eriti aega kokku hoida — need võtavad igal juhul kaks minutit — siis järgmised on lihtsalt viljatu maa parendamiseks.
Kujutage ette, et valve töötaja telefon heliseb. Mida ta teeb? Otsib vastuseid küsimustele — mis läks katki, kus see juhtus, kuidas reageerida? Nii me nendele küsimustele vastame:
Lihtsalt integreerime kogu selle teabe teate teksti, andes seal lingi wiki lehele, kus on kirjas, kuidas sellele probleemile reageerida, kuidas seda lahendada ja eskaleerida.
Ma pole siiani midagi öelnud rakenduse ja äri loogika taseme kohta. Kahjuks ei ole meie rakendustes veel metoodika kogumise funktsionaalsust. Ainus allikas mingisuguste andmete jaoks nendelt tasemetelt on logid.
Mõned punktid.
Esiteks, kirjutage struktureeritud logisid. Ärge lisage konteksti teate tekstis. See raskendab nende grupeerimist ja analüüsimist. Logstash vajab selle normaliseerimiseks palju aega.
Teiseks, kasutage õigesti tõsiduse tasemeid. Igal keelel on oma standard. Isiklikult eristaksin ma nelja taset:
- vigade puudumine;
- klientidepoolne viga;
- meie poolelt viga, ei kaota raha, ei kanna riske;
- meie poolelt viga, kaotame raha.
Kokkuvõtteks. Tuleb püüdma jälgida just äriloogikat. Tuleb püüda jälgida ise rakendust ja opereerida juba selliste mõõdikute põhjal nagu müükide arv, uute kasutajate registreerimiste arv, hetkel aktiivsete kasutajate arv jne.
Kui kogu teie äri on üks nupp brauseris, peate jälgima, kas seda vajutatakse, kas see töötab korralikult. Kõik muu ei ole oluline.
Kui teil seda ei ole, võite proovida seda logides, rakenduse logides, Nginx logides jmt, nagu me tegime. Te peate olema nii lähedal rakendusele kui võimalik.
Operatsioonisüsteemi mõõdikud on loomulikult olulised, kuid äri jaoks pole need huvitavad, me ei saa nende eest raha.
Allikas: habr.com
