


Viimastel aastatel on ajavoosade andmebaasid (Time-series databases) muutunud haruldaseks nähtuseks (mida kasutati peamiselt kas avatud jälgimissüsteemides või konkreetsetes lahendustes, või Big Data projektides) „rahva tarbimiseks”. Venemaa alal tuleks selles osas eriline tänu suunata Yandexile ja ClickHouse’ile. Enne seda, kui oli vaja salvestada suures koguses ajavoosade andmeid, tuli kas leppida tõsiasjaga, et tuleb tõsta monstrumlik Hadoopi virn ning selle hooldusse, või suhelda protokollidega, mis olid iga süsteemi jaoks individuaalsed.
Võib tunduda, et 2019. aasta artikkel selle kohta, millist TSDB-d kasutada, koosneb ainult ühest lausest: „kasutage lihtsalt ClickHouse’i”. Kuid... on nüansse.
Tõepoolest, ClickHouse areneb aktiivselt, kasutajate hulk kasvab ja toetust antakse väga aktiivselt, kuid kas me ei ole saanud ClickHouse’i avaliku eduka statusseks kapitaliks, mis varjab teisi, võimalikult tõhusamaid/usaldusväärsemaid lahendusi?
Eelmisel aastal hakkasime me revidereerima meie enda monitooringusüsteemi, mille käigus tekkis küsimus sobiva andmebaasi valimise kohta. Selle valiku ajaloost soovin ma siin rääkida.
Ülesande seadmine
Esiteks — vajalik ettekanne. Miks on meil üldse vajalik oma monitooringusüsteem ja kuidas see oli üles ehitatud?
Alustasime tugiteenuste osutamist 2008. aastal ning 2010. aastaks sai selgeks, et sel ajal olemasolevate lahendustega andmete kogumine meie klientide infrastruktuuris olevate protsesside kohta muutus keeruliseks (räägime, vabandage väga, Cactist, Zabbixist ja alles tekkivast Graphitest).
Meie peamised nõudmised olid:
- kontakteerimine (sel ajal — kümnete, tulevikus — sadade) klientide haldamine ühes süsteemis koos tsentraliseeritud teavitussüsteemiga;
- paindlikkus teavitussüsteemi haldamisel (teavituste eskaleerimine vahetult kätkevate vahel, ajakava arvestamine, teadmistebaas);
- võimalus grafikte põhjalikult detailida (Zabbix sel ajal kuvati graafikud piltidena);
- pika andmete pikaajaline säilitamine (aasta ja rohkem) ja nende kiire väljavõtmise võimalus.
Selles artiklis huvitab meid viimane punkt.
Rääkides salvestusest, olid nõuded järgmised:
- süsteem peab kiiresti töötama;
- soovitav on, et süsteemil oleks SQL-liides;
- süsteem peab olema stabiilne ja omama aktiivset kasutajabaasi ja tuge (oleme kunagi pidanud toetama selliseid süsteeme nagu MemcacheDB, mida enam ei arendatud, või jaotatud salvestust MooseFS, mille veabildurekord viidi läbi hiina keeles: sellist ajalugu oma projektile me ei soovinud);
- CAP-teoreemile vastavus: Consistency (jõhkralt vajalik) — andmed peavad olema ajakohased, me ei taha, et teavitussüsteem ei saaks uusi andmeid ja plahvataks häiretega andmete mitte tuleku üle kõikides projektides; Partition Tolerance (jõhkralt vajalik) — me ei soovi, et süsteemis tekiks Split Brain; Availability (ei ole kriitiline, juhul kui aktiivne koopi olemas) — saame ise lülituda reservsüsteemile katkestuse korral, koodi kaudu.
Kuidas imelik see ka pole, osutus MySQL selleks ajaks meie jaoks ideaalseks lahenduseks. Meie andmestruktuur oli äärmiselt lihtne: serveri ID, arvesti ID, ajatemperatuur ja väärtus; kuumade andmete kiire valimine tagati suure buffer pool'i suurusega ning ajalooliste andmete valimine - SSD kaudu.
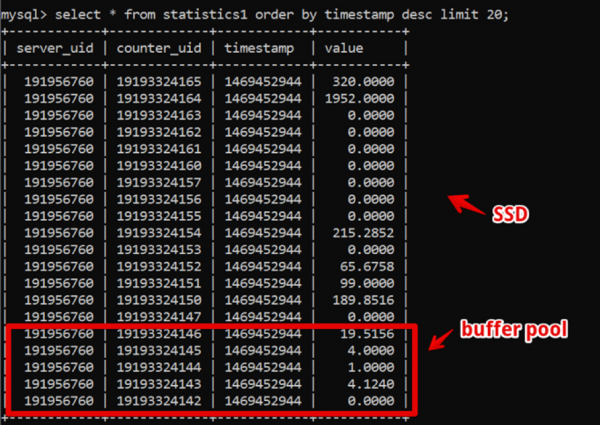
Nii suutsime kahe nädala värskeid andmeid, sekunditasemel detailidega, valima 200 ms jooksul enne andmete täielikku renderdamist ning elasime selles süsteemis üsna kaua.
Aja möödudes kasvas samuti andmete hulk. 2016. aastaks olid andmehulga ulatused ulatunud kümnete terabaitideni, mis SSD-lahenduste rentimise tingimustes kujutas olulist kulu.
Sel hetkel hakkasid aktiivselt levima veeruandmebaasid, millele hakkasime tõsiselt mõtlema: veeruandmebaasides hoitakse andmeid, nagu nimest aru saada, veergudena; ja kui vaadata meie andmeid, on lihtne näha suurt hulka dublette, mida oleks veeruandmebaasi kasutamisel võimalik kokku suruda.
Kuid ettevõtte jaoks kriitiline süsteem töötas jätkuvalt stabiilselt, seega ei olnud soov katsetada üleminekut millelegi muule.
2017. aastal San Jose'is toimunud Percona Live konverentsil esitlesid end esmakordselt Clickhouse'i arendajad. Esmapilgul oli süsteem juba tootmisvalmis (näiteks Yandex.Metrica — see on tõeliselt karm tootmine), tugi oli kiire ja lihtne ning kõige olulisem oli, et haldamine oli lihtne. Alates 2018. aastast alustasime ülemineku protsessi. Kuid selleks ajaks oli „küpsed” ja ajaga tõestatud TSDB süsteeme juba palju ning otsustasime võtta märkimisväärselt aega alternatiivide võrdlemiseks, et veenduda, et vastavalt meie nõudmistele ei ole Clickhouse'ile alternatiivseid lahendusi.
Lisaks juba väljendatud nõudmistele ilmnesid uued:
- uus süsteem peab tagama vähemalt sama jõudluse kui MySQL, samal riistvaral;
- uue süsteemi andmehoidla peab võtma oluliselt vähem ruumi;
- andmebaasi peab endiselt olema lihtne haldada;
- rakendust oli soovitav minimaalselt muuta andmebaasi vahetamisel.
Milliseid süsteeme hakkasime vaatama
Apache Hive/Apache Impala
Küps ja lahingutes katsetatud Hadoopi virn. Sisuliselt on see SQL-liides, mis on üles ehitatud andmete salvestamiseks oma formaatides HDFSis.
Plussid.
- Stabiilse töökorralduse korral on andmete skaleerimine väga lihtne.
- Andmete salvestamiseks on olemas veergude lahendused (vähem ruumi).
- Ressursside olemasolu korral on paralleelselt töötavate ülesannete täitmine väga kiire.
Miinused.
- See on Hadoop, ja selle haldamine on keeruline. Kui me ei ole valmis võtma pilvepõhist lahendust (mille kulud meid ei rahulda), siis tuleb kogu süsteem adminnide abil kokku panna ja ülal pidada, mis pole just meeldiv.
- Andmed kogutakse .
Kuid:

Kiirus saavutatakse arvutusserverite arvu skaleerimise kaudu. Lihtsamalt öeldes, kui oleme suur ettevõte, tegeleme analüüsiga ja äri jaoks on kriitiliselt oluline teavet maksimaalselt kiiresti kokku koguda (kas või suure arvutusressursside kasutamise arvelt), siis võib see olla meie valik. Kuid me ei olnud valmis riistvara parki mitu korda suurendama, et ülesannete täitmise kiirus kasvaks.
Druid/Pinot
Juba palju rohkem konkreetse TSDB kohta, kuid jällegi — Hadoopi tugi.
On .
Kokkuvõttes: Druid/Pinot paistavad ClickHouse'ist paremad olukordades, kus:
- Teie andmed on heterogeensed (meie puhul salvestame ainult serveri mõõdikute ajaseeria ja selle osas on see üks tabel. Kuid võivad esineda ka teised juhtumid: seadmete ajaseeriate, majanduslike ajaseeriate jne — igaühel oma struktuur, mida tuleb aggregata ja töödelda).
- Samuti on neid andmeid väga palju.
- Tabelid ja ajaseeriad ilmuvad ja kaovad (st mõni andmekogum on saabunud, see on analüüsitud ja kustutatud).
- Pole selget kriteeriumi, mille alusel andmed võivad olla partiitsioneeritud.
Teisel juhul näitab ClickHouse paremaid tulemusi, ja see on meie olukord.
ClickHouse
- SQL-sarnane.
- Lihtne hallata.
- Inimesed ütlevad, et see töötab.
Jõuab testimise lühilisti.
InfluxDB
Välismaine alternatiiv ClickHouse'ile. Miinustest: High Availability on olemas ainult kommertsversionis, aga seda tuleb võrrelda.
Jõuab testimise lühilisti.
Cassandra
Ühelt poolt teame, et seda kasutatakse mõõtmisajaseeriate salvestamiseks selliste jälgimissüsteemide poolt nagu näiteks, või OkMeter. Kuid on ka spetsiifika.
Cassandra ei ole veergude andmebaas tavapärases mõttes. See näeb rohkem välja nagu ridade andmebaas, kuid igas reas võib olla erinev arv veerge, mis võimaldab hõlpsasti korraldada veergude esitust. Sellega seoses on mõistetav, et 2 miljardi veeru piiranguga saab andmeid hoida just veergudes (näiteks ajaread). Näiteks MySQL-is on veergude piirang 4096 ja seal on lihtne kokku puutuda veaga, mille kood on 1117, kui proovida teha sama.
Cassandra mootor on suunatud suurte andmemahtude salvestamisele jaotatud süsteemis ilma peamasinata. Ülaltoodud CAP-teoreemi kohaselt on Cassandra rohkem AP, see tähendab andmete kättesaadavuse ja jaotuse eraldumise taluvuse suunas. Seega võib see tööriist olla suurepärane, kui tuleb ainult kirjutada sellesse andmebaasi ja harva lugeda. Siinkohal on mõistlik kasutada Cassandrat "külma" salvestuslahendusena. See tähendab pikaajalist ja usaldusväärset keerukate ajalooliste andmete salvestamist, mida harva vajatakse, kuid vajadusel on need kergesti kätte saadavad. Siiski, täiendava pildi saamiseks testime seda ka. Kuid nagu ma varem ütlesin, ei soovi ma aktiivselt koodi ümber kirjutada valitud andmebaasi lahendusele, seega testime seda piiratud ulatuses — ilma andmebaasi struktuuri kohandamiseta Cassandrale.
Prometheus
Ja juba huvist otsustasime testida Prometheuse salvestaja jõudlust — lihtsalt, et mõista, kas oleme praegustest lahendustest kiiremad või aeglasemad ja kui palju.
Testimise meetod ja tulemused
Oleme testinud 5 andmebaasi järgnevates 6 konfiguratsioonis: ClickHouse (1 sõlm), ClickHouse (jaotatud tabel 3 sõlmele), InfluxDB, Mysql 8, Cassandra (3 sõlme) ja Prometheus. Testimise plaan on järgmine:
- laadime üles ajaloolisi andmeid nädala jooksul (840 miljonit väärtust päevas; 208 tuhat mõõdikut);
- genereerime kirjutamiskoormust (vaatlesime 6 koormusrežiimi, vaata allpool);
- kirjutamisega samal ajal teeme aeg-ajalt valikuid, simuleerides kasutaja päringute esitamist, kes töötleb graafikuid. Lihtsuse huvides valisime andmed 10 mõõdiku kaupa (just nii palju on CPU graafikul) nädala jooksul.
Koormame, simuleerides meie järelevalveagendi käitumist, kes saadab igasse mõõdikusse väärtuseid iga 15 sekundi tagant. Sellega seoses on meil huvi varieerida:
- mõõdikute koguarv, kuhu andmed kirjutatakse;
- väärtuste saatmise intervall ühte mõõdikusse;
- partii suurus.
Partii suurusest. Kuna peaaegu kõigi meie testitavate andmebaaside puhul ei soovitata koormata üksikute sisestustega, vajame me releed, mis kogub saabuvad mõõdikud ja rühmitab need kokku, kirjutades need andmebaasi partii sisestusega.
Samuti, et paremini mõista, kuidas hiljem saadud andmeid tõlgendada, kujutame ette, et me ei saada lihtsalt hunnikut mõõdikuid, vaid et mõõdikud on korraldatud serveritesse — 125 mõõdikut serveri kohta. Siin on server lihtsalt virtuaalne entiteet — et mõista, et näiteks 10 000 mõõdikut vastab umbes 80 serverile.
Ja nüüd, arvestades kõike seda, on meil kuus koormusrežiimi andmebaasi kirjutamiseks:
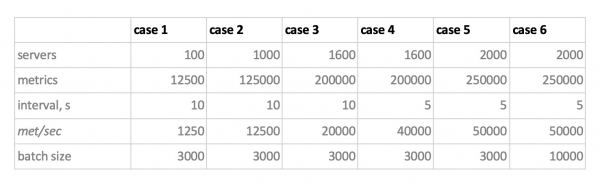
Siin on kaks aspekti. Esiteks, Kassandrale osutus selline partii suurus liiga suureks, seal kasutasime väärtusi 50 või 100. Teiseks, kuna Prometheus töötab rangelt pull-režiimis, s.t. ta käib ja toob mõõdikute andmed allikatest (ja isegi pushgateway, vaatamata oma nimele, ei muuda olukorda), vastavad koormused on teostatud staatiliste konfiguratsioonide kombinatsiooniga.
Testimise tulemused on järgmised:
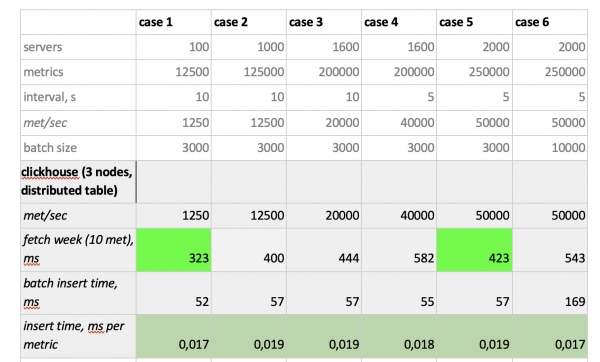
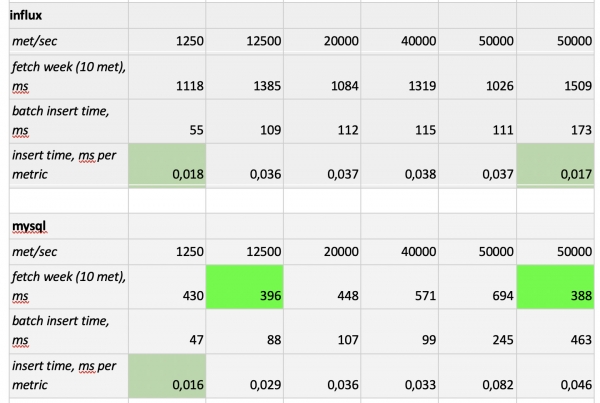
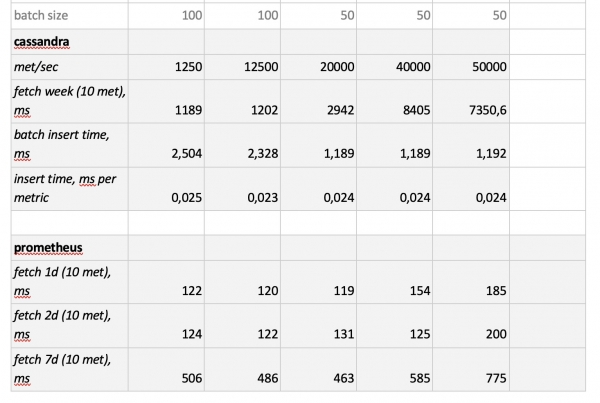
Oluline on märkida: fantastiliselt kiired päringud Prometheusest, kohutavalt aeglased päringud Cassandrast, vastuvõetamatult aeglased päringud InfluxDB-st; kirjutamise kiiruselt võitis kõik ClickHouse ning Prometheus ei osale konkurssil, kuna ta teeb sisestusi ise endasse ja me ei mõõda midagi.
In conclusion,: parimad valikud olid ClickHouse ja InfluxDB, kuid InfluxDB klastrit saab luua ainult Enterprise-versioonil, mis maksab raha, samas kui ClickHouse on tasuta ja toodetud Venemaal. Seetõttu on loogiline, et USA-s eelistatakse tõenäoliselt InfluxDB-d, meie aga ClickHouse’i.
Allikas: habr.com
