

Tere kõigile, olen Aleksander, töötan CIAN-is insenerina ning tegele mul süsteemiadministreerimise ja infrastruktuuri protsesside automatiseerimisega. Ühe eelmise artikli kommentaarides paluti meil rääkida, kust me saame 4 TB logisid päevas ja mida me nendega teeme. Jah, meil on palju logisid ja nende töötlemiseks on loodud eraldi infrastruktuuri klaster, mis võimaldab meil kiiresti lahendada probleeme. Käesolevas artiklis räägin, kuidas me ühe aastaga selle pidevalt kasvava andmevoogiga töötamiseks kohandasime.
Kust me alustasime
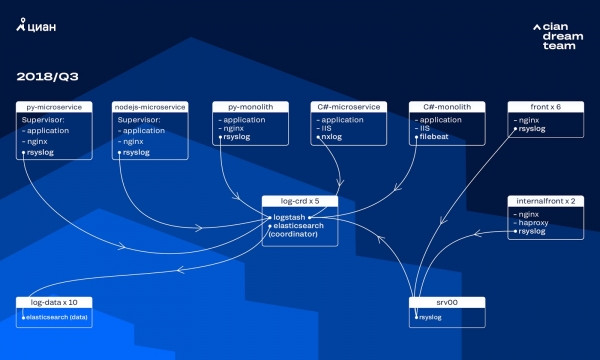
Viimased paar aastat on cian.ru koormus kasvanud väga kiiresti ning 2018. aasta kolmandaks kvartaliks ulatus saidi külastatavus 11,2 miljoni unikaalse kasutajani kuus. Sel ajal kaotasime kriitilistel hetkedel kuni 40% logisid, mistõttu ei suuda me kiiresti intsidente lahendada ning kulutame neile väga palju aega ja vaeva. Samuti ei suutnud me sageli probleemi põhjust leida ning see kordus mõne aja pärast. See oli peavalu, millega tuli midagi ette võtta.
Sel hetkel kasutasime logide salvestamiseks 10 andmnode Elasticsearch 5.5.2 klastri vaikeseadeid indekseid. See juurutati üle aasta tagasi populaarse ja taskukohase lahendusena: siis ei olnud logivool nii suur, et oleks mõtet ebastandardeid konfiguratsioone välja mõelda.
Saabunud logide töötlemist tagas Logstash erinevatel portidel viiel Elasticsearch koordineerijatel. Iga indeks, sõltumata suurusest, koosnes viiest shardist. Toolik oli korraldatud tunni ja päeva rotatsiooniks, mistõttu ilmus klastrisse iga tunni jooksul ligikaudu 100 uut shardit. Kuni logisid oli veel mitte väga palju, suutis klaster hakkama saada ja tema seadeid ei märgatud.
Kiire kasvu probleemid
Generated logide maht kasvas väga kiiresti, kuna kaks protsessi kattusid. Ühest küljest kasvas teenuse kasutajate arv pidevalt. Teiselt poolt hakkasime aktiivselt üleminekutele mikroteenustele, jagades meie vanad monoliidid C# ja Pythonis. Mitukümmend uusi mikroteenust, mis asendasid osa monoliidist, genereerisid infrastruktuuri klastri jaoks märgatavalt rohkem logisid.
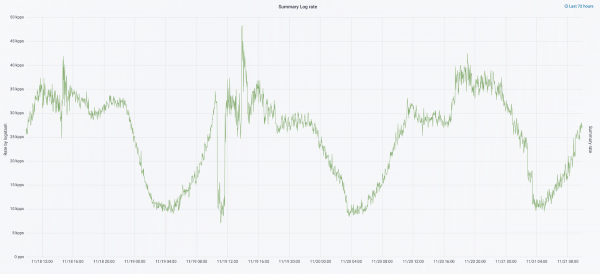
Just scaling led us to a point where the cluster became almost unmanageable. When logs began to come in at a rate of 20,000 messages per second, frequent unnecessary rotations increased the number of shards to 6,000, and over 600 shards were allocated to each node.
This caused issues with memory allocation, and when a node failed, all shards had to be moved simultaneously, multiplying the traffic and loading the other nodes, making it nearly impossible to write data to the cluster. During this time, we were left without logs. And when there was a problem with serveriga we lost 1/10 of the cluster in general. The large number of small-sized indexes added to the complexity.
Ilma logideta ei saanud me aru sündmuse põhjustest ja varem või hiljem oleksime samadele probleemidele uuesti jalaga peale astunud, mis meie meeskonna ideoloogias olid vastuvõetamatud, kuna kõik meie töö mehhanismid on üles ehitatud just sellele — mitte kordama samu probleeme. Selleks vajasime täielikku logide mahtu ja nende edastamist praktiliselt reaalajas, kuna valveinseneride meeskond jälgis häireid mitte ainult mõõdikutelt, vaid ka logidelt. Probleemi ulatuse mõistmiseks — toona oli logide kogumaht umbes 2 TB päevas.
Seadsime eesmärgiks — täielikult välistada logide kadumine ja vähendada nende toimetamise aega ELK-klastrisse maksimaalselt 15 minutini erakorraliste olukordade ajal (sellele numbrile toetudes, saime hiljem sisemises KPI-sse).
Uus rotatsiooni mehhanism ja kuum-soe sõlmed
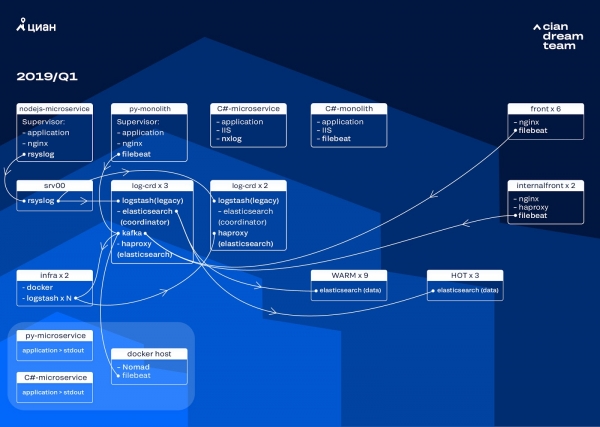
Klastri muutmist alustasime ElasticSearchi versiooni uuendamisega 5.5.2-st 6.4.3-ni. Meie 5. versioon krahhas jälle, ja otsustasime selle kustutada ja täielikult uuendada — logide pärast pole enam vahet. Nii et selle ülemineku sooritasime vaid paaritunni jooksul.
Selle etapi kõige suurem muudatus oli Apache Kafka juurutamine kolme node'i juures, kus koordinaator toimis vahepevana. Sõnumite maakler päästis meid logide kadumisest ElasticSearch’i probleemide korral. Samal ajal lisasime klastrisse 2 node’i ja läksime üle hot-warm arhitektuurile, kus oli kolm "kuuma" node'i, asetatud erinevatesse rack'idesse andmekeskuses. Neilt suunati edasi logid, mida ei tohtinud mingil juhul kaotada — nginx, samuti rakenduste vealogid. Ülejäänud node’itelt suunati väiksemad logid — debug, warning jms, samuti liikusid 24 tunni pärast „olulised“ logid „kuumadelt“ node'ilt.
Et mitte suurendada väikeste indeksite arvu, läksime ajarotatsioonilt üle rollover mehhanismile. Foorumites oli palju teavet selle kohta, et suuruse järgi rotatsioon on väga ebastabiilne, mistõttu otsustasime kasutada rotatsiooni indeksis olevate dokumentide arvu järgi. Analüüsisime iga indeksi ja registreerisime dokumentide arvu, mille järel peaks rotatsioon käivituma. Nii saavutame optimaalse shard'i suuruse — mitte rohkem kui 50 GB.
Klastri optimeerimine
Kuid me ei ole probleemidest täielikult vabanenud. Kahjuks hakkasid ikkagi ilmuma väiksed indeksid: need ei saavutanud määratud mahtu, ei roteerunud ja kustutati globaalsete indeksite puhastamisega, mis kestis üle kolme päeva, kuna me eemaldasime kuupäeva järgi rotateerimise. See põhjustas andmete kadumise, kuna indeks klastrist kadus täielikult, ja katse kirjutada mitteeksisteerivasse indeksisse rikkus meie haldust logikat, mida kasutasime. Kirjutamiseks mõeldud alias muudeti indeksiks ja see rikkus rollover'i loogikat, mis põhjustas kontrollimatut mõningate indeksite kasvu kuni 600 GB.
Näiteks pöördemugava konfiguratsiooni jaoks:
curator-elk-rollover.yaml
---
actions:
1:
action: rollover
options:
name: "nginx_write"
conditions:
max_docs: 100000000
2:
action: rollover
options:
name: "python_error_write"
conditions:
max_docs: 10000000
Rollover aliasi puudumise korral tekkis viga:
ERROR alias "nginx_write" not found.
ERROR Failed to complete action: rollover. : Unable to perform index rollover with alias "nginx_write".
Probleem lahendamine jäi järgmisse iteratsiooni ja keskendusime muule küsimusele: läksime üle Logstashi pull-loogikale, mis tegeleb sisendi logide töötlemisega (üleküllastumise teabe eemaldamine ja rikastamine). Panime selle Dockerisse, mida käitame läbi docker-compose, seal asub ka logstash-exporter, mis edastab statistikat Prometheusele logivoo operatiivseks jälgimiseks. Nii andsime endale võimaluse sujuvalt muuta logstashi instantside arvu, mis vastutavad iga logitüübi töötlemise eest.
Samal ajal, kui me klastreid täiustasime, kasvas cian.ru külastatavus 12,8 miljoni unikaalse kasutajani kuus. Tulemuseks oli see, et meie muudatused jäid natuke maha tootmisest ja sattusime olukorda, kus 'soojad' nodid ei suuda koormusega hakkama saada ja peatavad kogu logide edastamise. 'Küsimata' andmed saime probleemideta, kuid ülejäänud kohaletoimetamisse tuli sekkuda ja teostada käsitsi rollover, et jaotada indeksid ühtlaselt.
Klastris on kohaliku docker-compose'i tõttu keeruline skaleerida ja logstash instantside seadistusi muuta, kuna kõik toimingud tuli käsitsi teha (uute lõppude lisamiseks tuli käsitsi läbi käia kõik serverid ja igal pool teha docker-compose up -d).
Logide ümberjaotamine
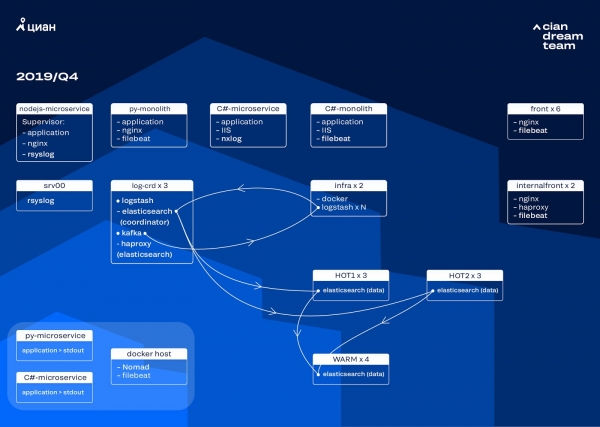
Sel aastal septembris jätkasime monoliidi lõhkumist, klastrikoormus kasvas ja logide voog lähenes 30 000 sõnumile sekundis.
Järgmist iteratsiooni alustasime riistvara värskendamisega. Viielt koordinaatorilt läksime kolmele, vahetasime välja andmeserverid ja säästsime raha ning mahutavust. Nodide jaoks kasutame kahte konfiguratsiooni:
- „Kuumade“ nodide jaoks: E3-1270 v6 / 960Gb SSD / 32 Gb x 3 x 2 (3 Hot1 ja 3 Hot2 jaoks).
- „Soojade“ nodide jaoks: E3-1230 v6 / 4Tb SSD / 32 Gb x 4.
Sellel iteratsioonil kolisime mikroteenuste access-logi indeksi üle, mis võtab sama palju ruumi kui front-end nginx logid, teise kolme „kuuma“ node gruppi. „Kuumades“ nodides hoidame nüüd andmeid 20 tundi ja seejärel kanname need „soojadesse“ muude logide hulka.
Me lahendasime väikeste indeksite kadumise probleemi nende rotatsiooni ümberhäälestamisega. Nüüd rotatakse indekseid igal juhul iga 23 tunni järel, isegi kui andmeid on vähe. See on veidi suurendanud shardide arvu (need on nüüd ligikaudu 800), kuid klastrite jõudluse seisukohalt on see talutav.
Klastris on nüüd kuus 'kuuma' ja ainult neli 'soe' sõlme. See põhjustab minimaalset viivitust suuremate ajavahemikega päringutes, kuid tulevikus sõlmede arvu suurendamine lahendab selle probleemi.
Selles iteratsioonis lahendasime ka poolautomaatse skaleerimise puudumise probleemi. Selleks käivitasime infrastruktuuri Nomad klastriga — analooge, mis juba töötavad meie tootmises. Praegu ei muutu Logstash'i arv automaatselt koormuse põhjal, kuid jõuame ka sinna.
Tulevikuplaanid
Tehtud konfiguratsioon on suurepäraselt skaleeritav ja hetkel salvestame 13,3 TB andmeid — kõik logid nelja päeva jooksul, mis on hädavajalik häirete kiireks analüüsimiseks. Osa loge muudame mõõdikiteks, mida kogume Graphite'i. Töötajate töö lihtsustamiseks on meil infrastruktuuri klastrile mõeldud mõõdikud ja poolautomaatsete tüüpiliste probleemide parandamise skriptid. Pärast järgmise aasta andmete sõlme arvu suurendamist plaanime andmete säilitamise perioodi pikendada 4 päevalt 7 päevani. See on piisav kiireks tööks, kuna püüame alati uurida juhtumeid nii kiiresti kui võimalik, samas kui pikaajaliste uuringute jaoks on meil telemeetriandmed.
2019. aasta oktoobris kasvas cian.ru külastatavus juba 15,3 miljoni unikaalse kasutaja võrra kuus. See oli tõsine proov arhitektuurilise lahenduse logide edastamiseks.
Praegu valmistume ElasticSearchi versiooni 7 uuendamiseks. Tõsi, selleks tuleb uuendada paljude indeksite mapping'ut ElasticSearchis, kuna need on üle kantud versioonist 5.5 ja kuulutatud deklareerimisele versioonis 6 (versioonis 7 neid lihtsalt pole). See tähendab, et uuendamise käigus juhtub kindlasti midagi ootamatut, mis jätab meid ajutiselt logideta. Versioonilt 7 ootame enim Kibana’d koos täiustatud liidese ja uute filtritega.
Oleme saavutanud oma põhieesmärgi: enam ei kaota logisid ja oleme vähendanud infrastruktuuri klastrite seisakuaega 2-3 kokkuvarisemisest nädalas paaritunniseks hooldusperioodiks kuus. Kogu see töö tootmiskeskkonnas on peaaegu märkamatuks jäänud. Nüüd saame aga täpselt määrata, mis meie teenustega toimub, saame seda kiiresti teha rahulikult ning ei pea muretsema, et logid kaovad. Kokkuvõttes oleme rahul, õnnelikud ja valmistume uute saavutuste nimel, millest räägime hiljem.
Allikas: habr.com
