

Kõrge jõudlus on üks peamisi nõudeid suurandmete töötlemisel. Meie, andmete laadimise meeskonnas Sberis, töötleme praktiliselt kõiki tehinguid meie Hadoopi Andmekeskuses, mistõttu puutume kokku tõeliselt suurte informatsiooni voogudega. Loomulikult otsime pidevalt võimalusi jõudluse tõstmiseks ning nüüd tahame rääkida, kuidas suudame parandada HBase RegionServer'i ja HDFS-kliendi, mis võimaldas märkimisväärselt suurendada lugemisoperatsioonide kiirus.
Kuid enne, kui liigume edasiste muudatuste juurde, tuleks rääkida piirangutest, mida on põhimõtteliselt võimatu mööda hiilida, kui kasutada HDD-d.
Miks HDD-d ja kiire Random Access lugemine on ühilduvad
Nagu teada, salvestavad HBase ja paljud muud andmebaasid andmeid plokkidena, mille suurus on mitu kümmet kilobaiti. Vaikimisi on see umbes 64 KB. Kujutame nüüd ette, et peame välja tooma vaid 100 baiti ja palume HBase'il anda meile need andmed mingi võtme alusel. Kuna HFile'ide ploki suurus on 64 KB, siis küsitud andmeid on 640 korda rohkem (väheke!) kui vajalik.
Edasi minnes, kuna päring läheb läbi HDFS-i ja selle metaandmete vahemälu mehhanismi ShortCircuitCache (mis võimaldab faile otseselt juurde pääseda), toob see kaasa 1 MB lugemise kettalt. Siiski saab seda reguleerida parameetriga dfs.client.read.shortcircuit.buffer.size ja paljudel juhtudel on mõistlik seda väärtust vähendada, näiteks 126 KB-ni.
Oletame, et me teeme nii, kuid lisaks, kui hakkame andmeid lugema java API kaudu, kasutades selliseid funktsioone nagu FileChannel.read ja palume operatsioonisüsteemil lugeda määratud maht andmeid, loeb see "igaks juhuks" 2 korda rohkem, st 256 KB meie puhul. See juhtub seetõttu, et javasse pole lihtsat võimalust seada lippu FADV_RANDOM, mis takistaks sellist käitumist.
Kokkuvõttes, et saada meie 100 bait, loetakse taustal 2600 korda rohkem. Tundub, et lahendus on ilmne, vähendame ploki suurust kilobaidi võrra, seadke mainitud lipp ja saavutame suure selguse kiiruskasvu. Kuid probleem on selles, et ploki suuruse kahekordne vähendamine vähendab ka aega, mil me loeme baiti, samuti kaks korda.
Mõningast kasu FADV_RANDOM lippu seadmisest võib saada, kuid ainult suure mitme niidi korral ja ploki suuruse korral alates 128 Kb, kuid see on maksimaalselt paarikümmend protsenti:

Testid viidi läbi 100 failiga, igaüks suurusega 1 Gb ja paigutatud 10 HDD kettale.
Arvutame, milleks me sellise kiirusena üldse loota saame:
Oletame, et me loeme 10 kettalt kiirusel 280 MB/s, st 3 miljonit korda 100 baiti. Kuid nagu me mäletame, vajame me andmeid, mis esinevad 2600 korda vähem kui loetud. Seega jagame 3 miljonit 2600-ga ja saame 1100 kirjet sekundis.
Pettumust tekitav, eks ole? Nii on lood Juhusliku ligipääsuga andmetele HDD-l — olenemata ploki suurusest. See on füüsiline piir juhuslikule juurdepääsule, ega ükski andmebaas ei suuda sellistes tingimustes rohkem välja pigistada.
Kuidas siis andmebaasid saavutavad palju kõrgemat kiirust? Sellele küsimusele vastamiseks vaatame, mis toimub järgmises pildis:
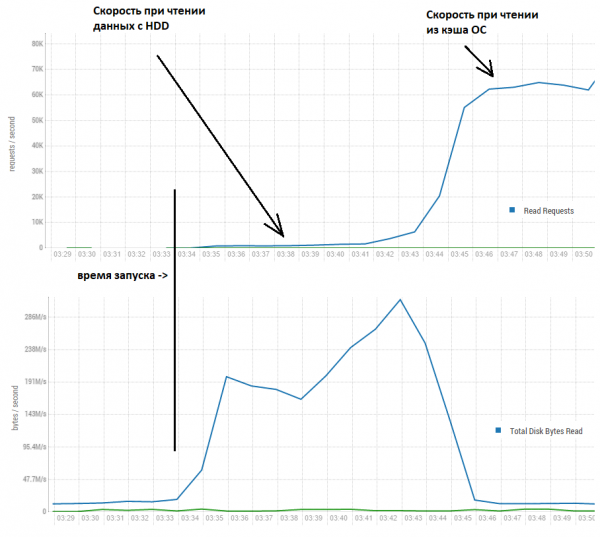
Siin näeme, et esimesed paar minutit saavutatakse tõepoolest kiirus umbes tuhat salvestust sekundis. Siiski, kuna loetakse palju rohkem, kui on küsitud, ladestuvad andmed Linuxi operatsioonisüsteemi buff/cache'i ja kiirus tõuseb vastuvõetavaks 60 tuhande juurde sekundis.
Seega uurime edasi juurdepääsu kiirendamist ainult nendele andmetele, mis on OS-i vahemälus või sarnastes SSD/NVMe salvestites, mille ligipääsukiirus on võrdne.
Meie puhul teostame teste nelja serveriga keskkonnas, kus igaühes on järgmised seadistused:
CPU: Xeon E5-2680 v4 @ 2.40GHz, 64 lõime.
Mälu: 730 GB.
java versioon: 1.8.0_111
Ja siin on tegelikult peamine punkt — andmemaht tabelites, mida tuleb lugeda. Asja on selles, et kui lugeda andmeid tabelist, mis mahub täielikult HBase'i vahemällu, siis ei jõua lugemine isegi OS-i buff/cache'i. Kuna HBase eraldab vaikimisi 40% mälast struktuurile nimega BlockCache. Tegelikult on see ConcurrentHashMap, kus võtme moodustab faili nimi + plokkide offset, ja väärtus on tegelikult andmed selle nihke kohta.
Seega, kui lugemine toimub ainult sellest struktuurist, siis me , nagu miljonit päringut sekundis. Ent kujutame ette, et me ei saa anda sadu gigabaiti mälu ainult andmebaasi vajadustele, kuna nende serverite peal töötab veel palju muud kasulikku.
Näiteks meie puhul on BlockCache ühe RS-i maht umbes 12 GB. Oleme istutanud kaks RS-i ühele node’ile, st BlockCache’i jaoks on eraldatud kokku 96 GB kõigis node'ides. Andmeid on aga selles osas palju rohkem, oletame, et meil on 4 tabelit, 130 regioonis, kus failide suurused on 800 MB, kokkusurutud FAST_DIFF, st kokku 410 GB (need on puhtad andmed, st ilma replikatsiooni tegurita).
Seega moodustab BlockCache vaid umbes 23% andmete kogumahtust ja see on palju lähemal tegelikele tingimustele, mida nimetatakse BigData-ks. Ja siin hakkab asi huvitavaks minema — kuna on selge, et mida vähem on pääseda vahemällu, seda halvem on jõudlus. Kui juhtub möödalask, tuleb teha palju tööd — st alla minna süsteemifunktsioonide kutsumiseni. Kuid seda ei saa vältida, seega vaatame hoopis teist aspekti — mis juhtub andmetega vahemälus?
Lihtsustame olukorda ja eeldame, et meil on vahemälu, kuhu saab paigutada ainult 1 objekti. Siin on näide sellest, mis juhtub, kui proovi töödelda andmeid, mis on 3 korda suuremad kui vahemälu, peame me:
1. Paigutame ploki 1 vahemällu
2. Eemaldame ploki 1 vahemälust
3. Paigutame ploki 2 vahemällu
4. Eemaldame ploki 2 vahemälust
5. Paigutame ploki 3 vahemällu
Oleme teinud 5 toimingut! Kuid selle olukorra nimetamist normaalseks ei saa, tegelikult sundime HBase'i tegema palju täiesti mõttetut tööd. Ta pidevalt loeb andmeid OS vahemälust, paigutab selle BlockCache'i, et peaaegu kohe see välja visata, kuna saabub uus andmepartii. Postituse alguses olev animatsioon näitab probleemi olemust — prügikogujate koormus ületab piire, atmosfäär soojeneb, väike Greta kauges ja kuumas Rootsis tunneb muret. Ja meie, IT-inimesed, ei meeldi, kui lapsed on kurvad, seega hakkame mõtlema, mida selle olukorraga teha.
Mis siis, kui paigutame vahemällu mitte kõik plokid, vaid ainult teatud protsendi neist, nii et vahemälu ei täituks? Alustame lihtsalt lisades mõned koodirida BlockCache'i andmete paigutamise funktsiooni algusesse:
public void cacheBlock(BlockCacheKey cacheKey, Cacheable buf, boolean inMemory) {
if (cacheDataBlockPercent != 100 && buf.getBlockType().isData()) {
if (cacheKey.getOffset() % 100 >= cacheDataBlockPercent) {
return;
}
}
...
Siin on mõte järgmine: offset on ploki asukoht failis ja viimased numbrid jaotuvad juhuslikult ja ühtlaselt vahemikus 00 kuni 99. Seetõttu jätame vahele ainult need, mis jäävad meie soovitud vahemikku.
Näiteks seadistame cacheDataBlockPercent = 20 ja vaatame, mis juhtub:
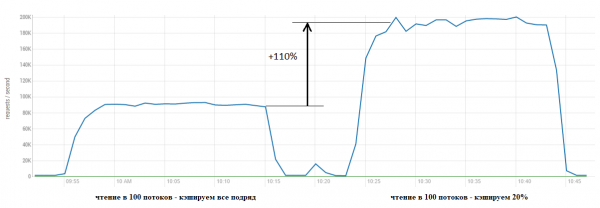
Tulemus on ilmne. Allpool toodud diagrammid näitavad, kuidas see kiirus saavutati — me säästame tohutult GC ressursse, vältides sisefilosoofilist tööd andmete paigutamisel vahemällu, et neid kohe tõugata marslaste koertele jalge alla:
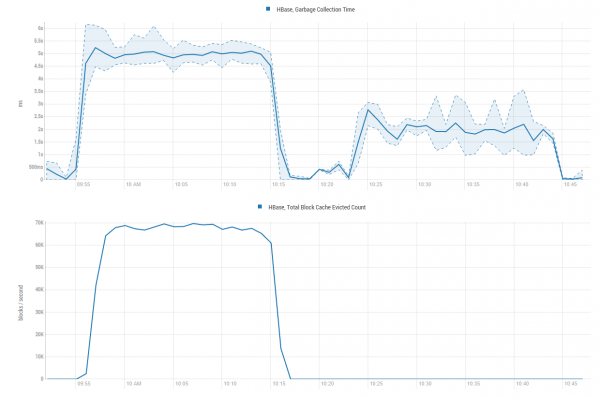
CPU kasutamine suureneb, kuid siiski mitte oluliselt rohkem kui tulemuslikkus:
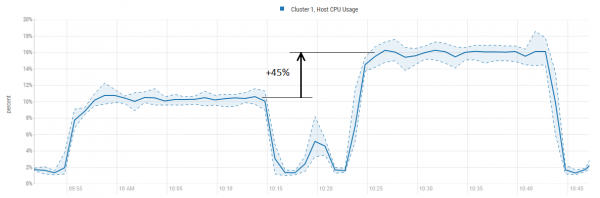
Samuti tasub mainida, et BlockCache'is hoitavad plokid võivad olla erinevad. Suur osa, umbes 95%, on tegelikud andmed. Ülejäänud on metaandmed, nagu näiteks Bloom filtrid või LEAF_INDEX ja . Need to ensure that the data is well-tested and useful, as before directly accessing the data, HBase checks the meta to understand if it should search further, and if so, where the required block is located.
Therefore, in the code, we see the condition check. buf.getBlockType().isData() and thanks to this meta, we will keep it in the cache anyway.
Now let's increase the load and also slightly enhance the feature. In the first test, we set the trimming percentage to 20, and BlockCache was slightly underloaded. Now we'll set it to 23% and add 100 threads every 5 minutes to see when saturation occurs:
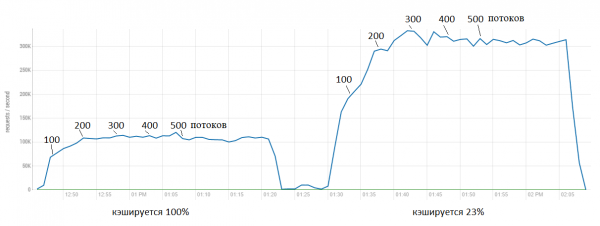
Here we see that the original version hits a ceiling almost immediately at around 100,000 requests per second. Meanwhile, the patch provides a speedup to 300,000. It's clear that further acceleration is not as 'free,' and CPU utilization also rises.
Kuid see pole kuigi elegantne lahendus, kuna me ei tea ette, kui suur protsent plokkidest tuleb vahemälus hoida; see sõltub koormusprofiilist. Seetõttu on rakendatud mehhanism, mis kohandab automaatselt seda parameetrit vastavalt lugemistegevuse aktiivsusele.
Selle haldamiseks on lisatud kolm parameetrit:
hbase.lru.cache.heavy.eviction.count.limit — määrab, kui mitu korda peab toimuma andmete eemaldamise protsess vahemälust, enne kui hakkame kasutama optimeerimist (st plokkide vahelejätmist). Vaikimisi on see MAX_INT = 2147483647, mis tegelikult tähendab, et funktsioon ei hakka kunagi tööle, kui see väärtus jääb selliseks. Kuna andmete eemaldamise protsess toimub iga 5-10 sekundi järel (sõltuvalt koormusest) ja 2147483647 * 10 / 60 / 60 / 24 / 365 = 680 aastat. Kuid me saame seada selle parameetri nulliks ja sundida funktsiooni tööle kohe pärast käivitamist.
Kuid selle parameetri puhul on ka kasulikku koormust. Kui meie koormuse iseloom on selline, et lühiajaliselt vahelduvad pidevalt lugemised (öelda päevasel ajal) ja pikaajalised (öösel), siis saame teha nii, et funktsioon käivitub ainult siis, kui toimuvad pikaajalised lugemistegevused.
Näiteks teame, et lühiajalised lugemised kestavad tavaliselt umbes 1 minuti. Siiski ei tohi hakata blokke eemaldama, sest vahemälu ei jõua aeguda ja seetõttu saame seadistada selle parameetri näiteks 10-ks. See tähendab, et optimeerimine hakkab töötama alles siis, kui on alanud pikaajaline aktiivne lugemine, st 100 sekundi pärast. Seega, kui meil on lühiajaline lugemine, siis kõik blokid jäävad vahemällu ja on kergesti kättesaadavad (välja arvatud need, mis kõrvaldavad tavalise algoritmiga). Ja kui teeme pikaajalisi lugemisi, siis funktsioon aktiveeritakse ja saavutame palju kõrgema jõudluse.
hbase.lru.cache.heavy.eviction.mb.size.limit — määrab, kui palju megabaite soovime 10 sekundi jooksul vahemällu panna (ja loomulikult vabastada). Funktsioon üritab saavutada seda väärtust ja hoida seda. Asi on selles, et kui paneme vahemällu gigabaitide kaupa, siis tuleb ka gigabaitide kaupa vabastada, mis, nagu me ülal nägime, on üsna kulukas. Siiski pole mõtet proovida seada seda väärtust liiga madalaks, kuna see toob kaasa varajase väljumise plokkskeemide vahelejätmise režiimist. Võimsate serverite (umbes 20–40 füüsilist südamikku) jaoks on optimaalne seada umbes 300–400 MB. Keskmise klassi (umbes 10 südamikku) jaoks 200–300 MB. Nõrkade süsteemide (2–5 südamikku) puhul võiks olla normaalseks 50–100 MB (sellistel ei ole testitud).
Vaatame, kuidas see töötab: oletame, et oleme seadnud hbase.lru.cache.heavy.eviction.mb.size.limit = 500, toimub mingi koormus (lugemine) ja siis iga ~10 sekundi järel arvutame, kui palju baite on vabastatud järgmise valemi järgi:
Overhead = Vabastatud baitide summa (MB) * 100 / Limite (MB) — 100;
Kui tegelikult on vabastatud 2000 MB, siis Overhead on järgmine:
2000 * 100 / 500 — 100 = 300%
Algrithmid püüavad säilitada mitte rohkem kui paarikümne protsendi ulatuses, seega vähendab see omadus vahemälu blokke, rakendades sellega automaatse häälestamise mehhanismi.
Kuid kui koormus on langenud, näiteks kui vabanes vaid 200 MB ja Overhead muutus negatiivseks (nii-öelda overshooting):
200 * 100 / 500 — 100 = -60%
Siis see omadus vastupidi suurendab vahemälu blokke kuni Overhead ei muutu positiivseks.
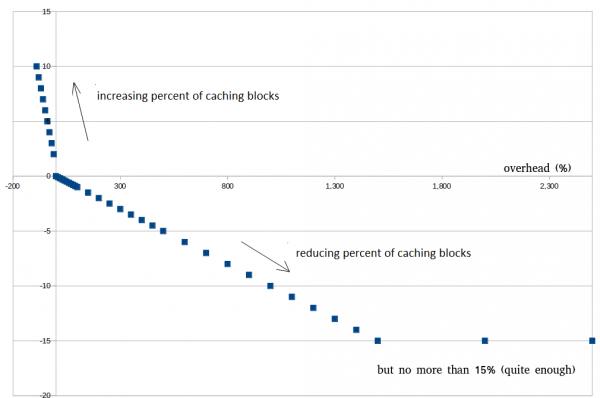
Allpool on näide sellest, kuidas see välja näeb reaalsetel andmetel. Ärge proovige saavutada 0%, see on võimatu. Aastakümne jooksul 30–100% on juba väga hea, kuna see aitab vältida enneaegset väljumist optimeerimise režiimist lühiajaliste tõusude tõttu.
hbase.lru.cache.heavy.eviction.overhead.coefficient — määrab, kui kiiresti me tahame tulemusi saada. Kui me teame kindlalt, et meie lugemised on enamasti pikad ja me ei taha oodata, võime seda koefitsienti suurendada ja saavutada kõrge jõudluse kiiremini.
Näiteks seadsime selle koefitsiendi = 0,01. See tähendab, et üleminek (vt üle) korrutatakse selle arvuga saadud tulemuste nimel ning väheneb määratud vaheoste protsent. Oletame, et üleminek = 300% ja koefitsient = 0,01, siis vaheoste protsent väheneb 3%.
Sarnane „tagasivoolu“ loogika on rakendatud ka negatiivsete ülemise väärtuste (üleslaundmine) jaoks. Kuna lühiajalised kõikumised lugemiste-volatiilsuse osas on alati võimalikud, võimaldab see mehhanism vältida enneaegset väljumist optimeerimisseisundist. Tagasivoolu loogika on vastupidine: mida tugevam on ülelaundmine, seda rohkem on vaheoste salvestatud.
Rakenduskood
LruBlockCache cache = this.cache.get();
if (cache == null) {
break;
}
freedSumMb += cache.evict() / 1024 / 1024;
/*
* Mõnikord loeme me rohkem andmeid, kui BlockCache'i mahub
* ja see põhjustab kõrget evakueerimise määra.
* See omakorda viib intensiivse prügikoguja tööni.
* Nii et palju plokke pannakse BlockCache'i, kuid neid ei loeta,
* kuid nad kulutavad palju CPU ressursse.
* Siin analüüsime, kui palju baitide vabastamine toimus ja otsustame,
* kas on aeg vähendada vahemälu plokkide arvu.
* See aitab vältida liiga paljude plokkide lisamist BlockCache'i,
* kui evict() töötab väga aktiivselt ja säästab CPU-d teiste tööde jaoks.
* Rohkem üksikasju: https://issues.apache.org/jira/browse/HBASE-23887
*/
// Enne kõike peame kontrollima, kui palju aega
// on möödunud eelmise evict() käivitamisest
// See peaks olema peaaegu sama aeg (+/- 10s)
// kuna saame sarnaseid vabastatud baitide mahtusid iga kord.
// 10s, sest see on vaikimisi periood evict() käivitamiseks (vt ülalpool this.wait)
long stopTime = System.currentTimeMillis();
if ((stopTime - startTime) > 1000 * 10 - 1) {
// Siin peame arvutama, milline olukord meil on.
// Meil on piir "hbase.lru.cache.heavy.eviction.bytes.size.limit"
// ja saame selle üleliigse arvutada.
// Kasutame seda teavet otsustamiseks,
// kuidas muuta vahemälu plokkide protsenti.
freedDataOverheadPercent =
(int) (freedSumMb * 100 / cache.heavyEvictionMbSizeLimit) - 100;
if (freedSumMb > cache.heavyEvictionMbSizeLimit) {
// Nüüd oleme olukorras, kus oleme üle piiri
// Aga võib-olla ignoreerime seda, sest see lõpeb üsna pea
heavyEvictionCount++;
if (heavyEvictionCount > cache.heavyEvictionCountLimit) {
// See kestab kaua ja me peame nüüd vähendama vahemälu
// plokkide arvu. Arvutame siin, kui palju plokke tahame vahele jätta.
// See sõltub:
// 1. Üleliigsest - kui üleliigne on suur, saame olla agressiivsemad
// vahemälu plokkide arvu vähendamisel.
// 2. Kui kiiresti soovime tulemust saada. Kui teame, et meie
// intensiivne lugemine kestab kaua, ei soovi me oodata ja saame
// suurendada koefitsienti ja saada head jõudlust üsna kiiresti.
// Kuid kui me ei ole kindel, saame seda aeglaselt teha ja see võib
// takistada enneaegset väljumist sellest režiimist. Nii et kui koefitsient on
// kõrgem, saame paremat jõudlust, kui intensiivne lugemine on stabiilne.
// Kuid kui lugemine muutub, saame sellele kohanduda ja seada
// koefitsienti madalamale väärtusele.
int change =
(int) (freedDataOverheadPercent * cache.heavyEvictionOverheadCoefficient);
// Kuid praktika näitab, et 15% vähendamine on täiesti piisav.
// Me ei ole ahned (see võib viia enneaegse väljumiseni).
change = Math.min(15, change);
change = Math.max(0, change); // Ma arvan, et see ei juhtu kunagi, kuid kontrolli siiski
// Niisiis on see peamine punkt, siin vähendame vahemälu plokkide %
cache.cacheDataBlockPercent -= change;
// Kui me läheme liiga madalale, peame siin peatuma, 1% peaks igal juhul olema.
cache.cacheDataBlockPercent = Math.max(1, cache.cacheDataBlockPercent);
}
} else {
// Noh, me oleme ületanud.
// Võib-olla on see lihtsalt lühiajaline kõikumine ja saame selles režiimis jääda.
// See aitab vältida enneaegset väljumist lühiajalise kõikumise ajal.
// Kui ületamine on alla 90%, proovime tõsta vahemälu
// plokkide protsenti ja loodame, et seda on piisavalt.
if (freedSumMb >= cache.heavyEvictionMbSizeLimit * 0.1) {
// Lihtne loogika: rohkem ületamist - rohkem vahemälu plokke (tagasisurve)
int change = (int) (-freedDataOverheadPercent * 0.1 + 1);
cache.cacheDataBlockPercent += change;
// Kuid see ei saa olla rohkem kui 100%, nii et kontrollime seda.
cache.cacheDataBlockPercent = Math.min(100, cache.cacheDataBlockPercent);
} else {
// Tundub, et intensiivne lugemine on läbi.
// Lihtsalt lahkume sellest režiimist.
heavyEvictionCount = 0;
cache.cacheDataBlockPercent = 100;
}
}
LOG.info("BlockCache evicted (MB): {}, overhead (%): {}, " +
"heavy eviction counter: {}, " +
"current caching DataBlock (%): {}",
freedSumMb, freedDataOverheadPercent,
heavyEvictionCount, cache.cacheDataBlockPercent);
freedSumMb = 0;
startTime = stopTime;
}
Vaatame nüüd seda kõike reaalse näite pealt. Meil on järgmine teststsenaarium:
- Alustame skaneerimise tegemisega (25 lõime, partii = 100)
- Viie minuti pärast lisame multi-get'id (25 lõime, partii = 100)
- Viie minuti pärast lülitame multi-get'id välja (jätkame jälle ainult skaneerimisega)
Teeme kaks läbimist, esmalt hbase.lru.cache.heavy.eviction.count.limit = 10000 (mis tegelikult lülitab funktsiooni välja), seejärel seadistame limiidi = 0 (lülitab sisse).
Logides allpool näeme, kuidas funktsioon aktiveerub, vähendades overshooting'i 14-71%ni. Aeg-ajalt koormus väheneb, mis aktiveerib backpressure'i ja HBase salvestab jälle rohkem plokke.
RegionServeri logi
evicted (MB): 0, suhe 0.0, ülejääk (%): -100, raske väljaheitmise loendur: 0, praegune salvestamine DataBlock (%): 100
evicted (MB): 0, suhe 0.0, ülejääk (%): -100, raske väljaheitmise loendur: 0, praegune salvestamine DataBlock (%): 100
evicted (MB): 2170, suhe 1.09, ülejääk (%): 985, raske väljaheitmise loendur: 1, praegune salvestamine DataBlock (%): 91 < start
evicted (MB): 3763, suhe 1.08, ülejääk (%): 1781, raske väljaheitmise loendur: 2, praegune salvestamine DataBlock (%): 76
evicted (MB): 3306, suhe 1.07, ülejääk (%): 1553, raske väljaheitmise loendur: 3, praegune salvestamine DataBlock (%): 61
evicted (MB): 2508, suhe 1.06, ülejääk (%): 1154, raske väljaheitmise loendur: 4, praegune salvestamine DataBlock (%): 50
evicted (MB): 1824, suhe 1.04, ülejääk (%): 812, raske väljaheitmise loendur: 5, praegune salvestamine DataBlock (%): 42
evicted (MB): 1482, suhe 1.03, ülejääk (%): 641, raske väljaheitmise loendur: 6, praegune salvestamine DataBlock (%): 36
evicted (MB): 1140, suhe 1.01, ülejääk (%): 470, raske väljaheitmise loendur: 7, praegune salvestamine DataBlock (%): 32
evicted (MB): 913, suhe 1.0, ülejääk (%): 356, raske väljaheitmise loendur: 8, praegune salvestamine DataBlock (%): 29
välja visatud (MB): 912, suhe 0.89, ülejääk (%): 356, raske välja viskamise konto: 9, praegune caching DataBlock (%): 26
välja visatud (MB): 684, suhe 0.76, ülejääk (%): 242, raske välja viskamise konto: 10, praegune caching DataBlock (%): 24
välja visatud (MB): 684, suhe 0.61, ülejääk (%): 242, raske välja viskamise konto: 11, praegune caching DataBlock (%): 22
välja visatud (MB): 456, suhe 0.51, ülejääk (%): 128, raske välja viskamise konto: 12, praegune caching DataBlock (%): 21
välja visatud (MB): 456, suhe 0.42, ülejääk (%): 128, raske välja viskamise konto: 13, praegune caching DataBlock (%): 20
välja visatud (MB): 456, suhe 0.33, ülejääk (%): 128, raske välja viskamise konto: 14, praegune caching DataBlock (%): 19
välja visatud (MB): 342, suhe 0.33, ülejääk (%): 71, raske välja viskamise konto: 15, praegune caching DataBlock (%): 19
välja visatud (MB): 342, suhe 0.32, ülejääk (%): 71, raske välja viskamise konto: 16, praegune caching DataBlock (%): 19
välja visatud (MB): 342, suhe 0.31, ülejääk (%): 71, raske välja viskamise konto: 17, praegune caching DataBlock (%): 19
välja visatud (MB): 228, suhe 0.3, ülejääk (%): 14, raske välja viskamise konto: 18, praegune caching DataBlock (%): 19
välja visatud (MB): 228, suhe 0.29, ülejääk (%): 14, raske välja viskamise konto: 19, praegune caching DataBlock (%): 19
välja visatud (MB): 228, suhe 0.27, ülejääk (%): 14, raske välja viskamise konto: 20, praegune caching DataBlock (%): 19
välja visatud (MB): 228, suhe 0.25, ülejääk (%): 14, raske välja viskamise konto: 21, praegune caching DataBlock (%): 19
välja visatud (MB): 228, suhe 0.24, ülejääk (%): 14, raske välja viskamise konto: 22, praegune caching DataBlock (%): 19
välja visatud (MB): 228, suhe 0.22, ülejääk (%): 14, raske välja viskamise konto: 23, praegune caching DataBlock (%): 19
välja visatud (MB): 228, suhe 0.21, ülejääk (%): 14, raske välja viskamise konto: 24, praegune caching DataBlock (%): 19
välja visatud (MB): 228, suhe 0.2, ülejääk (%): 14, raske välja viskamise konto: 25, praegune caching DataBlock (%): 19
evikt (MB): 228, suhe 0.17, ülejääk (%): 14, raske evakuatsioonikonto: 26, praegune vahemälu DataBlock (%): 19
evikt (MB): 456, suhe 0.17, ülejääk (%): 128, raske evakuatsioonikonto: 27, praegune vahemälu DataBlock (%): 18 < lisatud saadud (aga tabel sama)
evikt (MB): 456, suhe 0.15, ülejääk (%): 128, raske evakuatsioonikonto: 28, praegune vahemälu DataBlock (%): 17
evikt (MB): 342, suhe 0.13, ülejääk (%): 71, raske evakuatsioonikonto: 29, praegune vahemälu DataBlock (%): 17
evikt (MB): 342, suhe 0.11, ülejääk (%): 71, raske evakuatsioonikonto: 30, praegune vahemälu DataBlock (%): 17
evikt (MB): 342, suhe 0.09, ülejääk (%): 71, raske evakuatsioonikonto: 31, praegune vahemälu DataBlock (%): 17
evikt (MB): 228, suhe 0.08, ülejääk (%): 14, raske evakuatsioonikonto: 32, praegune vahemälu DataBlock (%): 17
evikt (MB): 228, suhe 0.07, ülejääk (%): 14, raske evakuatsioonikonto: 33, praegune vahemälu DataBlock (%): 17
evikt (MB): 228, suhe 0.06, ülejääk (%): 14, raske evakuatsioonikonto: 34, praegune vahemälu DataBlock (%): 17
evikt (MB): 228, suhe 0.05, ülejääk (%): 14, raske evakuatsioonikonto: 35, praegune vahemälu DataBlock (%): 17
evikt (MB): 228, suhe 0.05, ülejääk (%): 14, raske evakuatsioonikonto: 36, praegune vahemälu DataBlock (%): 17
evikt (MB): 228, suhe 0.04, ülejääk (%): 14, raske evakuatsioonikonto: 37, praegune vahemälu DataBlock (%): 17
evikt (MB): 109, suhe 0.04, ülejääk (%): -46, raske evakuatsioonikonto: 37, praegune vahemälu DataBlock (%): 22 < tagasitõukerõhk
evikt (MB): 798, suhe 0.24, ülejääk (%): 299, raske evakuatsioonikonto: 38, praegune vahemälu DataBlock (%): 20
evikt (MB): 798, suhe 0.29, ülejääk (%): 299, raske evakuatsioonikonto: 39, praegune vahemälu DataBlock (%): 18
evikt (MB): 570, suhe 0.27, ülejääk (%): 185, raske evakuatsioonikonto: 40, praegune vahemälu DataBlock (%): 17
evikt (MB): 456, suhe 0.22, ülejääk (%): 128, raske evakuatsioonikonto: 41, praegune vahemälu DataBlock (%): 16
evicted (MB): 342, ratio 0.16, overhead (%): 71, heavy eviction counter: 42, current caching DataBlock (%): 16
evicted (MB): 342, ratio 0.11, overhead (%): 71, heavy eviction counter: 43, current caching DataBlock (%): 16
evicted (MB): 228, ratio 0.09, overhead (%): 14, heavy eviction counter: 44, current caching DataBlock (%): 16
evicted (MB): 228, ratio 0.07, overhead (%): 14, heavy eviction counter: 45, current caching DataBlock (%): 16
evicted (MB): 228, ratio 0.05, overhead (%): 14, heavy eviction counter: 46, current caching DataBlock (%): 16
evicted (MB): 222, ratio 0.04, overhead (%): 11, heavy eviction counter: 47, current caching DataBlock (%): 16
evicted (MB): 104, ratio 0.03, overhead (%): -48, heavy eviction counter: 47, current caching DataBlock (%): 21 < interrupt gets
evicted (MB): 684, ratio 0.2, overhead (%): 242, heavy eviction counter: 48, current caching DataBlock (%): 19
evicted (MB): 570, ratio 0.23, overhead (%): 185, heavy eviction counter: 49, current caching DataBlock (%): 18
evicted (MB): 342, ratio 0.22, overhead (%): 71, heavy eviction counter: 50, current caching DataBlock (%): 18
evicted (MB): 228, ratio 0.21, overhead (%): 14, heavy eviction counter: 51, current caching DataBlock (%): 18
evicted (MB): 228, ratio 0.2, overhead (%): 14, heavy eviction counter: 52, current caching DataBlock (%): 18
evicted (MB): 228, ratio 0.18, overhead (%): 14, heavy eviction counter: 53, current caching DataBlock (%): 18
evicted (MB): 228, ratio 0.16, overhead (%): 14, heavy eviction counter: 54, current caching DataBlock (%): 18
evicted (MB): 228, ratio 0.14, overhead (%): 14, heavy eviction counter: 55, current caching DataBlock (%): 18
evicted (MB): 112, ratio 0.14, overhead (%): -44, heavy eviction counter: 55, current caching DataBlock (%): 23 < back pressure
evicted (MB): 456, ratio 0.26, overhead (%): 128, heavy eviction counter: 56, current caching DataBlock (%): 22
välja aetud (MB): 342, suhe 0.31, ülejääk (%): 71, suur väljaheitmise number: 57, praegune vahemälu DataBlock (%): 22
välja aetud (MB): 342, suhe 0.33, ülejääk (%): 71, suur väljaheitmise number: 58, praegune vahemälu DataBlock (%): 22
välja aetud (MB): 342, suhe 0.33, ülejääk (%): 71, suur väljaheitmise number: 59, praegune vahemälu DataBlock (%): 22
välja aetud (MB): 342, suhe 0.33, ülejääk (%): 71, suur väljaheitmise number: 60, praegune vahemälu DataBlock (%): 22
välja aetud (MB): 342, suhe 0.33, ülejääk (%): 71, suur väljaheitmise number: 61, praegune vahemälu DataBlock (%): 22
välja aetud (MB): 342, suhe 0.33, ülejääk (%): 71, suur väljaheitmise number: 62, praegune vahemälu DataBlock (%): 22
välja aetud (MB): 342, suhe 0.33, ülejääk (%): 71, suur väljaheitmise number: 63, praegune vahemälu DataBlock (%): 22
välja aetud (MB): 342, suhe 0.32, ülejääk (%): 71, suur väljaheitmise number: 64, praegune vahemälu DataBlock (%): 22
välja aetud (MB): 342, suhe 0.33, ülejääk (%): 71, suur väljaheitmise number: 65, praegune vahemälu DataBlock (%): 22
välja aetud (MB): 342, suhe 0.33, ülejääk (%): 71, suur väljaheitmise number: 66, praegune vahemälu DataBlock (%): 22
välja aetud (MB): 342, suhe 0.32, ülejääk (%): 71, suur väljaheitmise number: 67, praegune vahemälu DataBlock (%): 22
välja aetud (MB): 342, suhe 0.33, ülejääk (%): 71, suur väljaheitmise number: 68, praegune vahemälu DataBlock (%): 22
välja aetud (MB): 342, suhe 0.32, ülejääk (%): 71, suur väljaheitmise number: 69, praegune vahemälu DataBlock (%): 22
välja aetud (MB): 342, suhe 0.32, ülejääk (%): 71, suur väljaheitmise number: 70, praegune vahemälu DataBlock (%): 22
välja aetud (MB): 342, suhe 0.33, ülejääk (%): 71, suur väljaheitmise number: 71, praegune vahemälu DataBlock (%): 22
välja aetud (MB): 342, suhe 0.33, ülejääk (%): 71, suur väljaheitmise number: 72, praegune vahemälu DataBlock (%): 22
välja aetud (MB): 342, suhe 0.33, ülejääk (%): 71, suur väljaheitmise number: 73, praegune vahemälu DataBlock (%): 22
välja tõstetud (MB): 342, suhe 0.33, ülejääk (%): 71, suur väljajätmist loendur: 74, praegune puhverdatud DataBlock (%): 22
välja tõstetud (MB): 342, suhe 0.33, ülejääk (%): 71, suur väljajätmist loendur: 75, praegune puhverdatud DataBlock (%): 22
välja tõstetud (MB): 342, suhe 0.33, ülejääk (%): 71, suur väljajätmist loendur: 76, praegune puhverdatud DataBlock (%): 22
välja tõstetud (MB): 21, suhe 0.33, ülejääk (%): -90, suur väljajätmist loendur: 76, praegune puhverdatud DataBlock (%): 32
evicted (MB): 0, suhe 0.0, ülejääk (%): -100, raske väljaheitmise loendur: 0, praegune salvestamine DataBlock (%): 100
evicted (MB): 0, suhe 0.0, ülejääk (%): -100, raske väljaheitmise loendur: 0, praegune salvestamine DataBlock (%): 100
Skaalide eesmärk oli näidata sama protsessi graafiku kujul, kajastades suhet kahe puhvri eraldise vahel — single (kuhu jõuavad plokid, mida keegi kunagi ei ole küsinud) ja multi (siin hoitakse andmeid, mis on vähemalt kord nõudmisest tulnud):
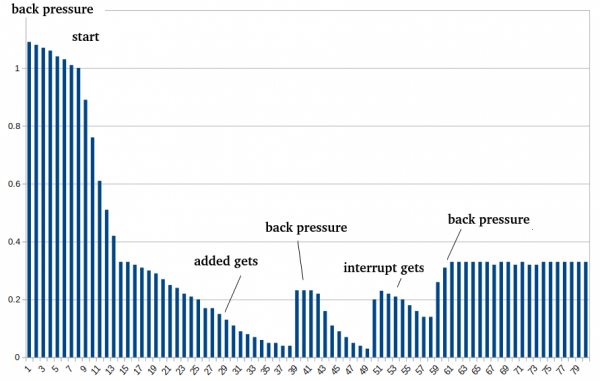
Ja lõpuks, kuidas näevad välja parameetrite töö graafiku kujul. Võrdluseks, puhver oli alguses täielikult välja lülitatud, seejärel käivitati HBase puhverdamisega ja optimiseerimise alustamise viivitus 5 minuti võrra (30 välja tõstmist tsüklit).
Täieliku koodi leiate Pull Request'ist githubis.
Kuid 300 tuhat lugemist sekundis ei ole kõik, mida selle riistvara kohta antud tingimustes saavutada on võimalik. Asi on selles, et andmete küsi puhul HDFS-i kaudu kasutatakse ShortCircuitCache (edaspidi SSC) mehhanismi, mis võimaldab andmetele otse juurde pääseda, vältides võrgu interaktsioone.
Profiliseerimine näitas, et see mehhanism, kuigi toob suurt kasu, muutub mingil hetkel kitsaskohaks, kuna praktiliselt kõik rasked operatsioonid toimuvad lock'i sees, mis viib suure osa ajast ummikseisudeni.

Seda mõistdes, saime aru, et probleemi saab vältida, luues sõltumatute SSC massiivi:
private final ShortCircuitCache[] shortCircuitCache;
...
shortCircuitCache = new ShortCircuitCache[this.clientShortCircuitNum];
for (int i = 0; i < this.clientShortCircuitNum; i++)
this.shortCircuitCache[i] = new ShortCircuitCache(…);
Ja seejärel töödelda neid, välistades üksteisega kattumise viimasest digiti offset'i järgi:
public ShortCircuitCache getShortCircuitCache(long idx) {
return shortCircuitCache[(int) (idx % clientShortCircuitNum)];
}
Nüüd on võimalik alustada katsetega. Selleks loeme HDFS-ist faile lihtsa mitme lõimega rakendusega. Seadistame parameetrid:
conf.set("dfs.client.read.shortcircuit", "true");
conf.set("dfs.client.read.shortcircuit.buffer.size", "65536"); // vaikimisi = 1 MB ja see aeglustab lugemist oluliselt, seega on parem kohandada vastavalt tegelikele vajadustele
conf.set("dfs.client.short.circuit.num", num); // vahemikus 1 kuni 10
Ja lihtsalt loeme faile:
FSDataInputStream in = fileSystem.open(path);
for (int i = 0; i 900000000)
position = 0L;
int res = in.read(position, byteBuffer, 0, 65536);
}
See kood käib eraldi lõimedena ja me suurendame samal ajal loetavate failide arvu (10 kuni 200 — horisontaalne telg) ja vahemälude arvu (1 kuni 10 — graafikud). Vertikaalne telg näitab kiiruskasvu, mis tuleneb SSC arvu suurendamisest võrreldes olukorraga, kus vahemälu on ainult üks.
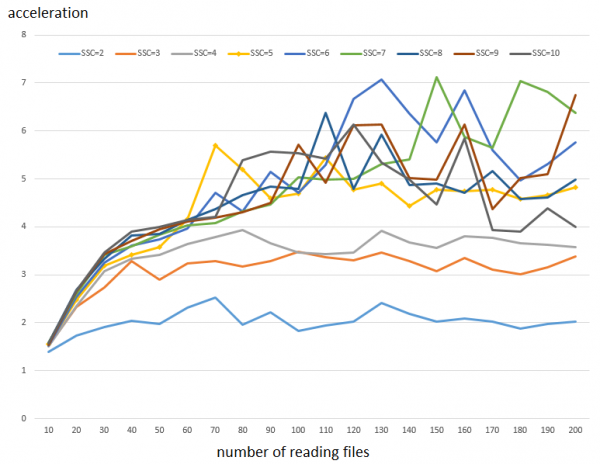
Kuidas graafikut lugeda: 100 000 lugemise täitmine 64 KB plokkidena ühe vahemäluga võtab aega 78 sekundit. Samas, viie vahemäluga täitmine võtab aega 16 sekundit. See tähendab, et kiirus kasvab umbes 5 korda. Grafi kust on näha, et väikse arvu paralleelsete lugemiste korral ei ole mõju väga märgatav, see muutub olulise tegurina, kui lugemiste arv ületab 50. Samuti on märgatav, et SSC arvu suurendamine 6-st ja rohkemast annab oluliselt vähem jõudluse kasvu.
Märkus 1: kuna testimisresultsid on üsna volatiilsed (vt allpool), tehti 3 käivitust ja saadud väärtused keskmistati.
Märkus 2: Jõudluse kasv juhusliku juurdepääsu optimeerimise tõttu on sama, kuigi juurdepääs ise on veidi aeglasem.
Siiski tuleb märkida, et erinevalt HBase'ist ei ole see kiirusetõus alati tasuta. Siin pigem 'vabastame' CPU võimalusi, et töö tegemiseks, mitte et see jääb lukku.
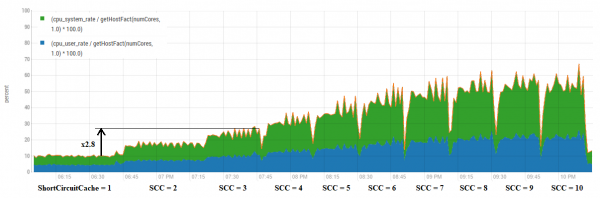
Siin võib näha, et üldiselt toob vahemälu arvu suurendamine kaasa umbes proportsionaalse kasvu CPU kasutuses. Siiski on mõned paremad kombinatsioonid.
Vaatame näiteks hoolikamalt seadistust SSC = 3. Tootlikkuse kasv vahemikus on umbes 3,3 korda. Allpool on tulemused kõikide kolme eraldi käivituse kohta.
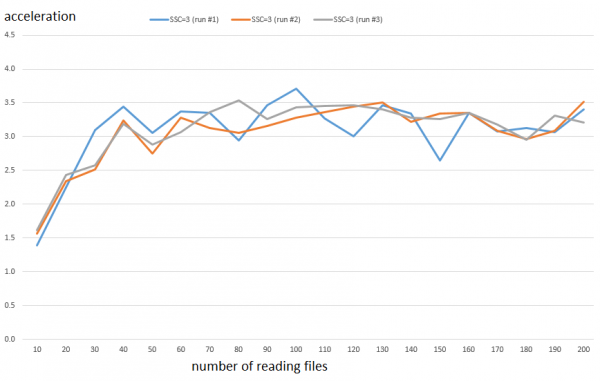
Samas CPU tarbimine kasvab umbes 2,8 korda. Erinevus ei ole eriti suur, kuid väikese Greta jaoks on see juba rõõm ja võib-olla tekib aega kooli ja tundide külastamiseks.
Seega peaksite see olema positiivne mõju igale tööriistale, mis kasutab massi pääsu HDFS-ile (näiteks Spark jne), tingimusel, et rakenduskood on kerge (st ummistus on just HDFS kliendi poolel) ja CPU-l on vabade ressursside varu. Testimiseks vaatame, milline mõju on BlockCache'i optimeerimise ja SSC häälestamise ühisrakendamisel HBase'ist lugemisel.
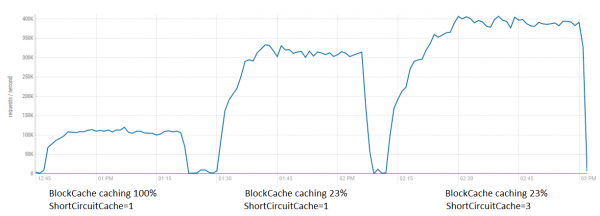
Siit nähtub, et sellistes tingimustes pole efekt nii suur kui rafineeritud testides (lugemine ilma igasuguse töötlemiseta), kuid siit on täiesti võimalik teha lisaks 80K. Üheskoos annavad mõlemad optimeerimised kuni 4 korda kiirusetõusu.
Selle optimeerimise jaoks tehti ka PR , mis liideti ning see funktsionaalsus on saadaval järgmistes väljaannetes.
Ja lõpuks oli huvitav võrrelda sarnaste wide-column andmebaaside Cassandra ja HBase lugemisvõimet.
Selleks käivitasime YCSB koormustestimise standardkasutust kakselt hostilt (kokku 800 niiti). Serveripooles oli igal poole 4 RegionServeri ja Cassandra eksemplari 4 hostil (mitte nendel, kus kliendid töötavad, et vältida nende mõju). Lugemised toimusid tabelitest, mille suurus oli:
HBase — 300 GB HDFS-is (100 GB puhaste andmete jaoks)
Cassandra — 250 GB (replikatsiooni faktor = 3)
T. e. maht oli enam-vähem sama (HBase-is veidi rohkem).
HBase parameetrid:
dfs.client.short.circuit.num = 5 (HDFS kliendi optimeerimine)
hbase.lru.cache.heavy.eviction.count.limit = 30 — see tähendab, et patch hakkab läbi töötama 30 väljatõukamise järel (~5 minutit)
hbase.lru.cache.heavy.eviction.mb.size.limit = 300 — sihtkogus vahemälu ja väljatõukamine
YCSB logid on töödeldud ja koondatud Exceli graafikuteks:
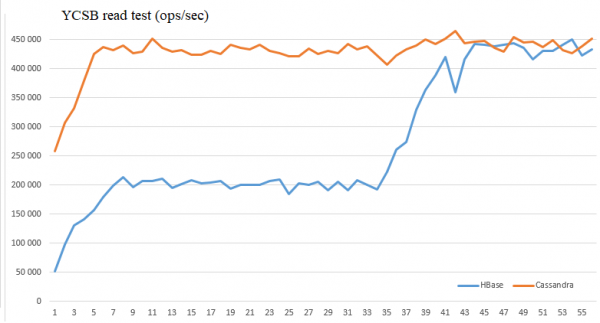
Nagu näha, võimaldab optimeerimise andmed nende andmebaaside jõudluse võrdsustada nendes tingimustes ja saavutada 450 tuhat lugemist sekundis.
Loodame, et see teave on kedagi kasulik meie põnevas võitluses jõudluse nimel.
Allikas: habr.com
