

Paljuski tunnevad PostgreSQL andmebaasi, ja see on end väikestes paigaldustes suurepäraselt tõestanud. Siiski on üleminek avatud lähtekoodile saanud aina selgemaks suundumuseks, isegi suurte ettevõtete ja ettevõtlusnõuete puhul. Selles artiklis räägime, kuidas integreerida Postgres ettevõtte keskkonda, ning jagame oma kogemusi varundussüsteemi (VKS) loomisel selle andmebaasi jaoks Commvaulti varundussüsteemi näitel.

PostgreSQL on juba tõestanud oma usaldusväärsust — andmebaas töötab suurepäraselt, seda kasutavad trendikad digitaalsed ettevõtted nagu Alibaba ja TripAdvisor, ning litsentsitasude puudumine teeb selle ahvatlevaks alternatiiviks sellistele hiidudele nagu MS SQL või Oracle DB. Kuid niipea, kui hakkame mõtlema PostgreSQL-le ettevõtlusmaastikul, puutume kokku rangete nõudmistega: 'Kuidas on lood konfiguratsiooni talitlushäirete ja katastroofitaluvuse, põhjaliku jälgimise, automatiseeritud varundamise ning lintteekide kasutamisega, nii otse kui ka sekundaarse salvestusena?'
Ühelt poolt ei ole PostgreSQL-il sisseehitatud varundamise vahendeid nagu Oracle DB või SAP Database Backup'i küpsed DBMS-id, nagu RMAN. Teiselt poolt toetavad ettevõtte varundussüsteemide pakkujad (Veeam, Veritas, Commvault) küll PostgreSQL-i, kuid tegelikult töötavad nad vaid kindlate (tavaliselt standalone) konfiguratsioonide ja erinevate piirangute komplektiga.
Spetsiaalselt PostgreSQL-i jaoks loodud varundussüsteemid, nagu Barman, Wal-g, pg_probackup, on äärmiselt populaarsed väikestes PostgreSQL-i andmebaasi paigaldustes või seal, kus ei ole vaja keerulisi varukoopiaid teiste IT-maastiku elementide suhtes. Näiteks võivad infrastruktuuris olla füüsilised ja virtuaalsed serverid, OpenShift, Oracle, MariaDB, Cassandra jne. Kõike seda on soovitatav varundada ühtse tööriistaga. Eraldi lahenduse paigaldamine ainult PostgreSQL-ile on ebaõnnestunud idee: andmed kopeeritakse kuskile kettale ja siis tuleb need lindile viia. Selline kahekordne varundamine pikendab varundamise aega ja mis veelgi kriitilisem — taastamist.
Enterprise lahenduses toimub installatsioonide varundamine teatud arvude eraldi klastrite nodidega. Näiteks Commvault suudab töötada ainult kahe nodiga klastriga, kus Primary ja Secondary on kindlalt seotud kindlate nodidega. Ja varundamine on mõistlik ainult Primary kaudu, sest Secondaryst varundamine toob kaasa omad piirangud. Due to DBMS features, a dump is not created on Secondary, leaving only the option for file backup.
Kuna seisakute riske tuleb vähendada, luuakse vea- ja katkestustaluv süsteem, milles moodustatakse "elav" klastrikonfiguratsioon ja Primary võib järk-järgult migreeruda erinevate serverite vahel. Näiteks käivitab tarkvara Patroni ise Primary uue juhuslikult valitud nodi klastris. SRC-l puuduvad vahendid selle jälgimiseks "kastist välja" ja kui konfiguratsioon muutub, siis protsessid lagunevad. Seega väline juhtimise rakendamine takistab SRK efektiivset tööd, kuna juhtimisserver ei saa lihtsalt aru, kust ja milliseid andmeid on vaja kopeerida.
Veel probleem on PostgreSQL-i varundamine. See on võimalik dump'i kaudu ja väikeste andmebaaside puhul toimib see. Kuid suurte andmebaaside puhul on dumpimine aeganõudev, nõuab palju ressursse ja võib põhjustada andmebaasi eksemplari kokkuvarisemise.
Faili varukoopia parandab olukorda, kuid suurte andmebaaside puhul toimub see aeglaselt, kuna see töötab ühesuunalises režiimis. Lisaks on vendoritel terve rida täiendavaid piiranguid. Mõnikord ei saa üheaegselt kasutada faili ja dump varukoopiates, mõnikord pole deduplikatsioon toetatud. Probleeme on palju ja tihti on lihtsam valida kallim, kuid usaldusväärne andmebaas PostgreSQL-i asemel.
Tagasi pole minna! Moskva arendajad on seljataga!
Kuid hiljuti seisis meie meeskond keerulise väljakutse ees: OSAGO 2.0 AIS-i loomise projektis, kus me töötasime IT-infrastruktuuri, valisid arendajad uue süsteemi jaoks PostgreSQL-i.
Suurte tarkvaraarendajate jaoks on palju lihtsam kasutada "moes" avatud lähtekoodiga lahendusi. Facebooki töötajate seas on piisavalt spetsialiste, kes toetavad selle andmebaasi toimimist. Kuid RSC puhul langesid kõik „teise päeva” ülesanded meie õlgadele. Meilt nõuti, et tagame veakindluse, kogume klusteri ja loomulikult korraldame varundamise. Meie tegevuse loogika oli järgmine:
- Õpetada SRK-d tegema varukoopiaid klaseeri Primaarse sõlme kaudu. Selleks peab SRK seda leidma — tähendab, et on vajalik integratsioon PostgresSQL klastrihalduse lahendusega. RSC puhul kasutati selleks tarkvara Patroni.
- Määrata varukoopia tüüp, lähtudes andmete mahust ja taastamise nõuetest. Näiteks kui on vaja taastada lehti granulaarselt, kasutada dumpingut, ja kui andmebaasid on suured ning granulaarselt taastamist ei nõuta — töötada failitasemel.
- Lisada lahendusele võimalus bloki varundamiseks, et luua varukoopiaid mitme lõime režiimis.
Esmalt oleme seadnud eesmärgi luua tõhus ja lihtne süsteem, ilma üleliigsete komponentide monstrinoosse nöörimiseta. Mida vähem püüniseid, seda väiksem on töötajate koormus ja madalam on süsteemi rikke risk. Lähenemised, kus kasutati Veeam'i ja RMAN'i, jätsime kohe välja, sest kahe lahenduse komplekt viitab juba süsteemi usaldamatusele.
Veidi maagilist ettevõtete jaoks
Nii et me pidime tagama usaldusväärse varundamise 10 klastrile, kus igas on 3 sõlme, samal ajal on varundusandmete keskuses peegelduvad samasugused infrastruktuurid. Andmekeskustes töötavad PostgreSQL aktiiv-passiiv põhimõttel. Andmebaaside kogumaht oli 50 TB. Igast selle ülesandega toimetab mistahes taseme ettevõtte varundussüsteem. Kuid nüanss on selles, et algselt ei ole Postgres'is täielik ja süvitsiminev ühilduvus varundussüsteemidega. Seega pidime otsima lahendust, millel on algselt maksimaalne funktsionaalsus koos PostgreSQL'iga, ja süsteemi täiustama.
Vi korraldasime kolm sisemist "hackathon"-i — vaatlesime üle rohkem kui pooled tutvustatud lahendused, testisime neid, tegime muudatusi vastavalt oma hüpoteesidele ja kontrollisime uuesti. Analüüsides kõiki saadaval olevaid võimalusi, valisime Commvaulti. Toode suutis juba "karbist välja" töötada kõige lihtsama PostgreSQL klastrite installatsiooni, ja selle avatud arhitektuur andis lootust (mis osutus õigeks) eduka täiendamise ja integreerimise osas. Commvault suudab ka PostgreSQL logide varundamist teostada. Näiteks suudab Veritas NetBackup PostgreSQL puhul teha vaid täielikke varukoopiaid.
Rohkem arhitektuurist. Commvaulti haldusserverid olid paigaldatud igasse kahte andmekeskusesse CommServ HA konfiguratsioonis. Süsteem on peegeldav, seda haldatakse ühe juhtpaneeli kaudu ja HA vaatepunktist vastab see kõigile ettevõtte nõuetele.
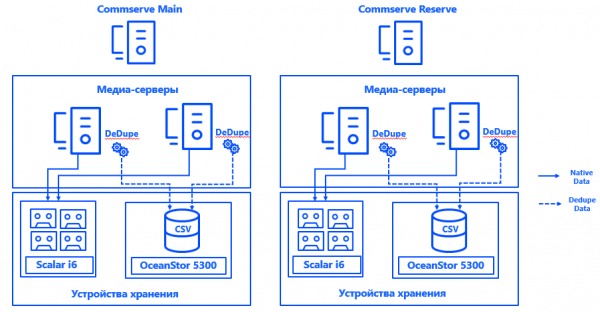
Iga andmesalvestuse keskuses oleme käivitanud kaks füüsilist meediaserverit. Need on ühendatud eraldiseisvate kettamahtudega ja lindiraamatukogudega SAN kaudu Fibre Channeli abil. Venitatud dedupikatsiooni alused tagavad meediaserverite tõrke taluvuse, samas kui iga serveri ühendamine iga CSV-ga võimaldab pidevat tööprotsessi, isegi kui üks komponentidest ebaõnnestub. Süsteem arhitektuur võimaldab jätkata varundamist, isegi kui üks andmesalvestuse keskus ebaõnnestub.
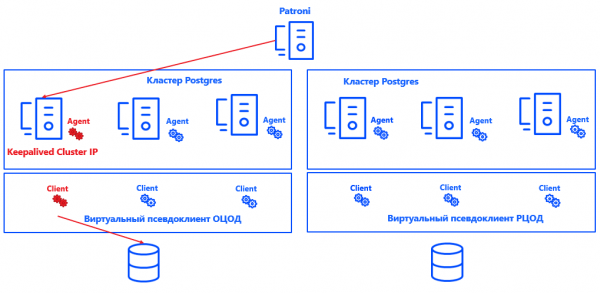
Patroni määrab iga klastri jaoks Primary-sõlme. Selleks võib olla mõni vabast sõlm andmesalvestuse keskuses — kuid ainult peamises. Varukoopias on kõik sõlmed Secondary.
Kuna Commvault mõistab, milline klastri sõlm on Primary, oleme integreerinud süsteemi (tänu lahenduse avatud arhitektuurile) Postgresiga. Selleks loodi skript, mis teavitab haldurit Primary-sõlme praegusest asukohast. serverile Commvault.
Üldiselt näeb protsess välja nii:
Patroni valib Primary → Keepalived aktiveerib IP-klastri ja käivitab skripti → Commvaulti agent valitud klastri sõlmes saab teate, et see on Primary → Commvault konfigureerib automaatselt varukoopia pseudokliendi raames.
Selle lähenemise eelised seisnevad selles, et lahendus ei mõjuta logide järjepidevust, täpsust ega Postgres'i instantsi taastamist. Samuti on see kergesti skaleeritav, kuna Commvault'i esmase ja sekundaarse sõlme fikseerimine ei ole enam vajalik. Piisab, kui süsteem mõistab, kus asub esmase sõlme, ja sõlmede arv võib olla suurendatav praktiliselt ükskõik kui suureks.
Lahendus ei pretendeeri ideaalile ning sellel on omad nüansid. Commvault suudab varundada ainult kogu instantsi, mitte eraldi andmebaase. Seetõttu on iga andmebaasi jaoks loodud eraldi instants. Reaalsed kliendid on ühendatud virtuaalseteks pseudokliendiks. Iga Commvault’i pseudoklient kujutab endast UNIX klastrit. Sellesse lisatakse need klastrisõlmed, kus on paigaldatud Commvault'i agent Postgres'i jaoks. Selle tulemusena varundatakse kõik pseudokliendi virtuaalsed sõlmed kui üks instants.
Iga tehisklient sisaldab aktiivset klastrinode. Just seda määratleb meie integreerimislahendus Commvaultile. Selle tööpõhimõte on üsna lihtne: kui nodis tõuseb klastripäring, seab skript Commvaulti agendi binaarsesse parameetrisse "aktiivne nodi" — sisuliselt seab skript "1" vajalikku mälukohta. Agent edastab need andmed CommServe'ile ja Commvault teeb varukoopia õigelt sõlmelt. Lisaks kontrollib skript konfiguratsiooni õigsust, aidates vältida varundamise käivitamisel vigu.
Selle käigus kopeeritakse suured andmebaasid plokkidena mitme voolu kaudu, vastates RPO ja varukoopiaakna nõudmistele. Süsteemile avaldatav koormus on väike: täiskoopiad ei toimu sageli, teistel päevadel kogutakse ainult logisid, samuti madala koormuse perioodidel.
Muide, oleme rakendanud eraldi poliitikaid PostgreSQL arhiivide logide varundamiseks — need säilitavad teistsuguste reeglite järgi, neid kopeeritakse teise ajakava alusel ja deduplikatsioon ei kehti nende kohta, kuna need logid sisaldavad unikaalseid andmeid.
IT-infrastruktuuri järjepidevuse tagamiseks on Commvaulti eraldiseisvad failiklientide installatsioonid igas klastris. Need välistavad varukoopiatest Postgresi failid ja on mõeldud ainult operatsioonisüsteemi ja rakenduste taasteks. Selle andmeosa jaoks on kehtestatud oma poliitika ning säilitustähtaeg.

Praegu ei mõjuta SRK tootmisservise, kuid kui olukord muutub, saab Commvaultis aktiveerida koormuse piiramisüsteemi.
Sobib? Sobib!
Nii et saime mitte lihtsalt toimiva, vaid ka täielikult automatiseeritud varukoopia PostgreSQL klastripaigaldamiseks, mis vastab kõigile ettevõtete vajadustele.
RPO ja RTO parameetrid 1 tunni ja 2 tunni kohta on reserveeritud, seega vastavad need isegi andmemahtude olulisel kasvamisel. Paljude kahtluste kiuste on PostgreSQL ja ettevõtte keskkond täiesti ühilduvad. Nüüd teame kogemuse põhjal, et selliste andmebaaside varundamine on võimalik kõige erinevates konfiguratsioonides.
Muidugi, selle tee jooksul pidime me kulutama seitse paari raudvarbreid, ületama mitmeid raskusi, astuma mõnedel haavlitele ja parandama hulga vigu. Kuid nüüd on lähenemine testitud ja seda saab rakendada avatud lähtekoodiga lahenduste integreerimiseks asemel patenteeritud andmebaasidele äärmuslikes ettevõtte tingimustes.
Kas olete proovinud töötada PostgreSQL-iga ettevõtte keskkonnas?
Autorid:
Oleg Lavrenovi, andmesalvestussüsteemide projekteerimistarkvara insener „Infosisüsteemid Jet“
Dmitri Jerõkin, arvutite komplexide projekteerimistarkvara insener „Infosisüsteemid Jet“
Allikas: habr.com
