

Tere, Habr.org kogukond. Täna alustavad õppetunnid esimese rühma kursusel . Seoses sellega tahame rääkida, kuidas käis avatud veebiseminar selle kursuse kohta.

V rääkisime, milliste väljakutsetega SQL-andmebaasid silmitsi seisavad pilvede ja Kubernetes’i ajastul. Samuti käsitlesime, kuidas SQL-andmebaasid kohanduvad ja muutuvad nende väljakutsete mõjul.
Veebinari viibis , Google Cloud Practice Delivery Manager EPAM Systems’is.
Kui puud olid väikesed…
Alustuseks tuletame meelde, kuidas toimus andmebaasihalduse valik eelmise sajandi lõpus. See ei tohiks olla raske, sest andmebaasi valik tol ajal algas ja lõppes Oracle.

90ndate lõpus ja 2000. aastate alguses polnud valikut, kui rääkida tööstuslikest skaleeritavatest andmebaasidest. Jah, eksisteerisid IBM DB2, Sybase ja veel mõned andmebaasid, mis tekkisid ja kadusid, kuid nad ei olnud Oracle'i taustal kuigi märgatavad. Vastavalt sellele olid siis aegade inseneride oskused rohkem-vähem seotud selle ainsa valikuga, mis olemas oli.
Oracle DBA pidi oskama:
- installima Oracle Server'i jaotist;
- konfigureerima Oracle Server'i:
- init.ora;
- listener.ora;
— looma:
- andmebaasi ruume;
- skeeme;
- kasutajaid;
— tegema varundamist ja taastamist;
— teostama jälgimist;
— tegelema suboptimalsete päringutega.
Samal ajal ei olnud Oracle DBA-lt eriti nõutud:
- oskama valida optimaalse andmebaasi või teisi andmete salvestamise ja töötlemise tehnoloogiaid;
- tagama kõrge kättesaadavuse ja horisontaalse skaleeritavuse (see ei olnud alati DBA mure);
- valdama hästi valdkonda, infrastruktuuri, rakendusarkitektuuri, opsüsteemi;
- teostama andmete laadimist ja laadimist, andmete migreerimist erinevate andmebaaside vahel.
Üldiselt, kui rääkida valikust nendel aegadel, meenutab see valikut Nõukogude poes 80ndate lõpus:

Meie aeg
Sellest ajast on muidugi puudel kasvanud, maailm on muutunud ja olukord on kuidagi selline:

Andmebaaside turg on samuti muutunud, mida näitab hästi Gartneri värske raport:
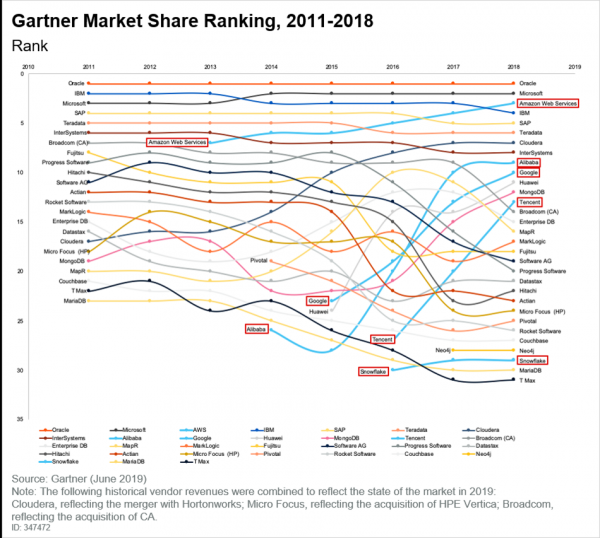
Siinjuures ei saa mainimata jätta, et oma niši on leidnud pilved, mille populaarsus kasvab. Kui lugeda sama Gartneri raportit, näeme järgmisi järeldusi:
- Palju kliente on teel oma rakenduste pilve migreerimise poole.
- Uued tehnoloogiad ilmuvad esmalt pilve ning pole kindel, et need kunagi üleminekut mittepilvisele infrastruktuurile teevad.
- Pay-as-you-go hinnakujundusmudel on muutunud põhimõtteliseks tavaks. Kõik soovivad maksta ainult selle eest, mida nad kasutavad, ja see pole enam ainult trend, vaid tõsiasi.
Mis nüüd?
Täna oleme kõik pilves. Meie küsimused puudutavad valikuid, ja need valikud on tohutud, isegi kui vaatleme ainult On-premises andmebaasitehnoloogiate valikut. Samuti on meil olemas hallatud teenused ja SaaS. Seega muutub valik igal aastal ainult keerulisemaks.
Valikute kõrval tegutsevad ka piiravad tegurid:
- hind. Paljud tehnoloogiad on endiselt tasulised;
- oskused. Kui räägime avatud lähtekoodiga tarkvarast, tekib oskuste küsimus, kuna tasuta tarkvara nõuab selle kasutajalt ja haldajalt piisavat kompetentsi;
- funktsionaalsus. Kõik teenused, mis on saadaval pilves ja on loodud näiteks Postgresi alusel, ei oma tingimata samu funktsioone kui Postgres On-premises. See on oluline tegur, mida tuleb teada ja mõista. Veelgi enam, see tegur muutub tähtsamaks kui teadmised mõnest varjatud võimalusest teatud andmebaasihalduse süsteemis.
Mida oodatakse DA/DE-lt:
- head arusaamist teema valdkonnast ja rakendusarhitektuurist;
- oskus õigesti valida sobiv andmebaasitehnoloogia arvestades seatud ülesannet;
- oskus valida optimaalse rakendamise meetod valitud tehnoloogia jaoks olemasolevate piirangute kontekstis;
- oskus teostada andmete üleviimist ja migreerimist;
- oskus rakendada ja hallata valitud lahendusi.
Alljärgnev näide GCP-lt näitab, kuidas tehnoloogia valik andmete töötlemiseks sõltub nende struktuurist:
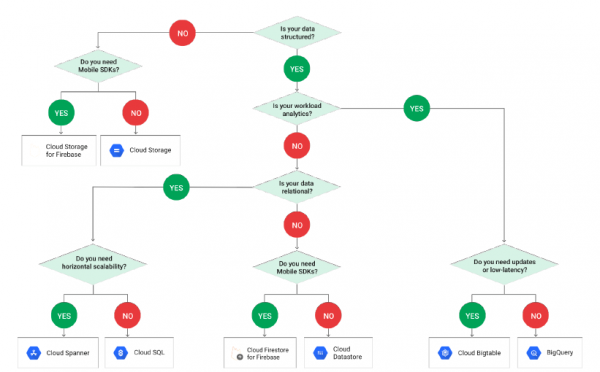
Pange tähele, et skeemist puudub PostgreSQL, sest see peitub terminoloogias Cloud SQL. Ja kui me satume Cloud SQL-i, peame jälle valiku tegema:
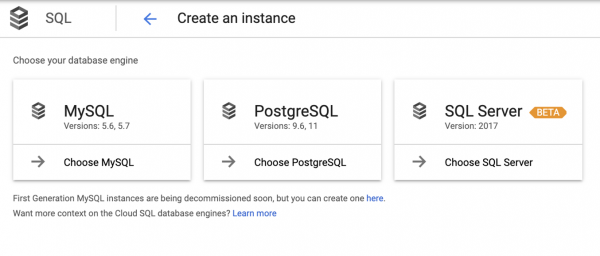
Tuleb märkida, et see valik ei ole alati arusaadav, seetõttu juhinduvad rakenduse arendajad sageli intuitsioonist.
Kokku:
- Mida kaugemale, seda aktuaalsemaks muutub küsimus valikust. Ja isegi kui vaadata ainult GCP-d, siis managed teenused ja SaaS, siis mõni mainimine RDBMS-ist ilmub alles 4. etapis (ja seal on kõrval Spanner). Pluss, PostgreSQL-i valik ilmub üldse alles 5. etapis, ja seal on veel MySQL ja SQL Server, seega kõike on palju, aga valida tuleb.
- Ei saa unustada ka piiranguid kiusatuste taustal. Peamiselt tahavad kõik Spannerit, aga see on kallis. Lõpuks on tüüpiline päring umbes selline: „Palun tehke meile Spanner, aga Cloud SQL-i hinnaga, te ju olete professionaalid!“

Aga mida siis teha?
Ilma lõpliku tõe pretensioonita, ütleme järgmist:
Tuleb muutma lähenemist koolitusele:
- ei ole mõtet õpetada, nagu varem DBA-sid õpetati;
- ühe toote teadmised ei ole enam piisavad;
- ja tundma kümneid ühel tasemel ei ole võimalik.
Tuleb teada mitte ainult ja mitte ainult toodet, vaid:
- kasutuse juhtumit;
- erinevaid rakenduse meetodeid;
- iga meetodi eeliseid ja puudusi;
- sarnased ja alternatiivsed tooted, et teha teadlik ja optimaalne valik, mitte alati tuttava toote kasuks.
Lisaks on oluline osata andmeid migreerida ja mõista ETL-iga integreerimise põhialuseid.
Tegeliku juhtumi näide
Hiljuti tuli mul luua mobiilirakenduse taustsüsteem. Projekti alguseks oli taustsüsteem juba välja töötatud ja kasutuselevõtmiseks valmis, ning arendajate meeskond kulutas sellele projektile umbes kaks aastat. Seetõttu seati eesmärgiks:
- luua CI/CD;
- teha arhitektuuri ülevaatus;
- kõik see käivitada.
Rakendus ise oli mikroteenuste arhitektuuri põhjal ja kood Python/Django keeles kirjutatud nullist ning koheselt GCP-sse. Sihtgrupi osas eeldati, et sihitud on kaks piirkonda — USA ja Euroopa, ning liiklus jaotati Global Load Balancer'i kaudu. Kõik töökoormused ja arvutuslik koormus töötasid Google Kubernetes Engine'is.
Andmete osas olid kolm struktuuri:
- Cloud Storage;
- Datastore;
- Cloud SQL (PostgreSQL).
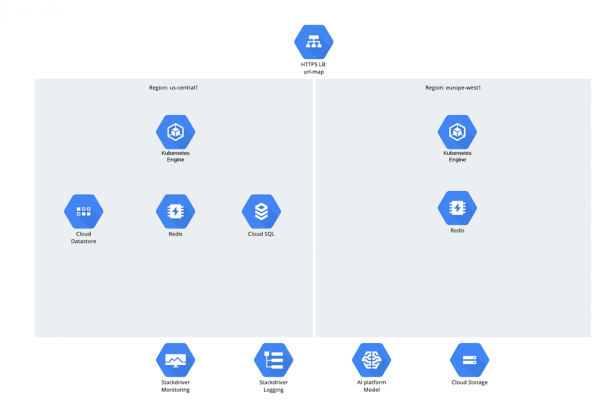
Võib esitada küsimus, miks valiti Cloud SQL? Tõtt-öelda tekitab selline küsimus viimastel aastatel veidi ebamugavust — tundub, et inimesed on hakanud relatsiooniliste andmebaaside suhtes häbenema, kuid sellegipoolest kasutavad nad neid aktiivselt ;-).
Mis puutub meie juhtumisse, siis valiti Cloud SQL järgmiste põhjuste tõttu:
- Nagu mainitud, arendati rakendust Django abil, milles on mudel SQL-andmebaasist püsivate andmete esitamiseks Pythonis (Django ORM).
- Raamistik toetas piisavalt lõplikku nimekirja andmebaasi haldamise süsteemidest:
- PostgreSQL;
- MariaDB;
- MySQL;
- Oracle;
- SQLite.
Seega valiti PostgreSQL sellest loendist pigem intuitsioonist (ega ju Oracle'i valima).
Mida oli puudu:
- rakendus oli juurutatud vaid kahes piirkonnas, kuid plaanis oli kolmas (Aasia);
- Andmebaas asus Põhja-Ameerika piirkonnas (Iowa);
- klient oli mures võimalike ligipääsu viivituste kohta Euroopast ja Aasiast ning teenusekatkestuste riski andmebaasi seiskamise korral.
Kuigi Django suudab samal ajal töötada mitme andmebaasiga ning jagada neid lugemise ja kirjutamise vahel, ei olnud rakenduses andmete hulk kuigi suur (üle 90% on lugemine). Üldiselt, kui oleks võimalik teha read-replika peamisest andmebaasist Euroopas ja Aasias,, oleks see kompromisslahendus. Mis siin siis nii keeruline on?
Keerus seisnes selles, et klient ei soovinud loobuda hallatavate teenuste ja Cloud SQL-i kasutamisest. Praegusel hetkel on Cloud SQL-i võimalused piiratud. Cloud SQL toetab kõrget saadavust (HA) ja lugemisreplikat (RR), kuid sama RR-i toetatakse ainult ühes regioonis. Ameerika regioonis andmebaasi luues ei saa Cloud SQL-i abil teha lugemisreplikat Euroopa regioonis, kuigi PostgreSQL ise seda ei takista. Suhtlemine Google'i töötajatega ei viisnud kuhugi ja lõppes lubadustega stiilis „teame probleemi ja töötame selle kallal, kunagi küsimus lahendatakse."
Kui loetleda Cloud SQL-i võimalusi punktide kaupa, siis need näeksid välja umbes nii:
1. Kõrge saadavus (HA):
- ühe piirkonna raames;
- diskireplikatsiooni abil;
- PostgreSQL mehhanisme ei kasutata;
- võib olla automaatne ja käsitsi haldus — failover/failback;
- andmebaas on ülemineku ajal mitu minutit maas.
2. Loe Replica (RR):
- ühe piirkonna raames;
- kuum standby;
- PostgreSQL voogedastuse replikatsioon.
Lisaks, nagu tavaks, seisab tehnoloogia valimisel silmitsi igasuguste piirangutega.:
- tellija ei soovinud luua uusi objekte ja kasutada IaaS-i, välja arvatud GKE kaudu;
- tellija ei tahaks kasutusele võtta iseteenindust PostgreSQL/MySQL jaoks;
- ja üldiselt sobiks Google Spanner hästi, kui mitte tema hind, tõsi, Django ORM ei saa sellega töötada, aga muidu on see hea asi.
Arvestades olukorda, esitas tellija järgneva küsimuse: „Kas saate midagi sarnast teha, et see oleks nagu Google Spanner, aga töötaks ka Django ORM-iga?“
Lahenduse variant nr 0
Esimene mõte, mis pähe tuli:
- jääda CloudSQL-i piiresse;
- ehitatud replikatsiooni piirkondade vahel ei tule mingisugusel kujul;
- üritada lisada replikat olemasolevale Cloud SQL by PostgreSQL-ile;
- kusagil ja kuidagi käivitada PostgreSQL-i instants, kuid vähemalt masterit mitte puudutada.
Kahjuks selgus, et seda ei saa teha, kuna juurdepääs hostile puudub (see on üldse teises projektis) — pg_hba jne, ja veel puudub juurdepääs superuser'ina.
Lahenduse variant nr 1
Pärast järjekordseid mõtteid ja varasemaid asjaolusid on mõtlemine pisut muutunud:
- püüame endiselt jääda CloudSQL piiresse, kuid liigume üle MySQL-le, kuna Cloud SQL by MySQL-l on välismaja, mis:
— on proxy välisele MySQL-le;
— näeb välja nagu MySQL instants;
— on loodud andmete migreerimiseks teistest pilvedest või kohalike serverite pealt.
Kuna MySQL replikatsiooni seadistamine ei nõua juurdepääsu hostile, töötas see põhimõtteliselt, kuid väga ebastabiilselt ja ebamugavalt. Ja kui edasi liikuda, siis muutus see tõeliselt hirmutavaks, kuna kogu struktuur oli välja arendatud terraformiga, ja äkki selgus, et välismaja ei ole terraformiga toetatud. Jah, Google'il on CLI, kuid millegipärast töötas ka siin kõik vahelduva eduga — siis loobub, siis ei loobu. Võib-olla sellepärast, et CLI on mõeldud andmete migreerimiseks väljastpoolt, mitte replikatsioonideks.
Sellega sai selgeks, et Cloud SQL ei sobi üldse. Nagu öeldakse, oleme teinud kõik, mis suudame.
Lahenduse variant nr 2
Kuna Cloud SQL piires ei õnnestunud jääda, püüdsime sõnastada nõudmised kompromisslahendusele. Nõudmised osutusid järgmisteks:
- töö Kuberneteses, maksimaalne ressursside ja Kubernetes (DCS, …) ning GCP (LB, …) võimaluste kasutamine;
- ülekaalu puudumine mitmete tarbetute asjade osas pilves nagu HA proxy;
- võimalus käivitada peamises piirkonnas HA PostgreSQL või MySQL; teistes piirkondades — HA põhipiirkonna RR pluss selle koopia (usaldusväärsuse tagamiseks);
- multi master (kui sellega ühendust võtta ei olnud soovitav, aga see ei olnud väga põhimõtteline)
.
Nende nõuete tulemusel on lõpuks silmadele ilmunud sobivadandmebaasi ja raamistiku valikud:
- MySQL Galera;
- CockroachDB;
- PostgreSQL tööriistad
:
— pgpool-II;
— Patroni.
MySQL Galera
MySQL Galera tehnoloogia on välja töötatud ettevõttes Codership ja see on plugin InnoDB jaoks. Omadused:
- multi master;
- sünkrone replikatsioon;
- lugemine igast sõlmest;
- kirjutamine igasse sõlme;
- sisseehitatud HA mehhanism;
- Bitnami poolt on saadaval Helm chart.
CockroachDB
Kirjelduse järgi on see asi täiesti fantastiline ja tegu on open source projektiga, mis on kirjutatud Go keeles. Peamine osaleja on Cockroach Labs (loodud Google'ist pärit inimeste poolt). See relatsiooniline andmebaasi haldur on algselt loodud olema jaotatud (horisontaalse skaleeritavusega „karbist välja”) ja vigadekindel. Selle autorid on seadnud sihiks „ühendada SQL-i funktsionaalsuse rikkus horisontaalse kättesaadavusega, mis on iseloomulik NoSQL lahendustele”.
Mugav boonus on PostgreSQL-i ühendusprotokolli tugi.
Pgpool
See on PostgreSQL-i peal olev lisand, mis tegelikult on uus entiteet, mis võtab enda alla kõik ühendused ja töötleb need. Sellel on oma koormuse tasakaalustaja ja parsi, seda litsentseeritakse BSD litsentsi alusel. Pakub laia valikut võimalusi, kuid tundub veidi hirmutav, sest uue entiteedi olemasolu võiks olla mõningate lisaseikluste allikaks.
Patroni
See oli viimane asi, millele ma pilku heitsin, ja osutus, et see ei olnud asjata. Patroni on avatud lähtekoodiga utiliit, mis põhimõtteliselt esindab Pythonil põhinevat deemonit, mis võimaldab automaatselt hallata PostgreSQL klastreid erinevate replikatsioonitüüpide ja automaatsete rollide üleminekuga. See oli väga huvitav leid, kuna see integreerub hästi Kubernetesega ja ei too kaasa uusi entiteete.
Mida lõpuks valisime
Valik ei tulnud kergelt:
- CockroachDB — tõeline, aga veidi hirmutav;
- MySQL Galera — ka üsna hea, kasutatakse laialdaselt, aga MySQL;
- Pgpool — liiga palju üleliigseid entiteete, integreerub halvemini pilve ja K8s-iga;
- Patroni — suurepärane integreerimine K8s-iga, ei ole üleliigseid entiteete, integreerub hästi GCP LB-ga.
Seega langetati valik Patroni kasuks.
Järeldused
On aeg teha lühikokkuvõtteid. Jah, IT-infrastruktuuri maailm on märkimisväärselt muutunud ja see on alles algus. Ja kui varem olid pilved lihtsalt teistsugune infrastruktuuri tüüp, siis nüüd on kõik teisiti. Veelgi enam, pilvede uuendused ilmuvad pidevalt, neid tulevad ja võib-olla ilmuvad need ainult pilvedes ning hiljem, alustades idufirmade poolt, viiakse need kohalikele süsteemidele.
Mis on SQL, SQL jääb ellu. See tähendab, et PostgreSQL ja MySQL tuleb teada ning osata nendega töötada, aga veelgi olulisem on osata neid õigesti rakendada.
Allikas: habr.com
