


Paljusid kogemusi on seotud Elasticsearchiga. Aga mis juhtub, kui soovid selle abil salvestada „suuri” logisid? Ja veel, kuidas ellu jääda, kui üks mitmest andmekeskusest langeb välja? Milline arhitektuur peaks olema ja milliseid takistusi võivad ette tulla?
Klassikaaslased otsustasime kasutada Elasticsearchi logihalduse küsimuste lahendamiseks ning nüüd jagame kogemusi Habraga: arhitektuuri ja takistuste kohta.
Mina olen Peeter Zaitsev, töötan süsteemiadministraatorina Klassikaaslaste juures. Enne seda töötasin ka administraatorina, tegelesin Manticore Searchi, Sphinx searchi ja Elasticsearchiga. Kui peaks veel mõni ...search välja tulema, tõenäoliselt töötan ka sellega. Osalen ka mitmes avatud lähtekoodiga projektis vabatahtlikuna.
Kui ma Klassikaaslaste juurde tulin, ütlesin arvelt intervjuul, et oskan töötada Elasticsearchiga. Pärast harjumist ja mõned lihtsad ülesanded lahendades sain suure ülesande logihaldusüsteemi reformimiseks, mis oli sel ajal olemas.
Nõuded
Süsteemi nõuded olid sõnastatud järgmiselt:
- Frontendina pidin kasutama Graylogi. Kuna ettevõttes oli juba kogemus selle toote kasutamisega, siis programmilised ja testijad tundsid seda, see oli neile tuttav ja mugav.
- Andme maht: keskmiselt 50-80 tuhat sõnumit sekundis, kuid kui midagi katki läheb, siis liiklust ei piirata, see võib olla 2-3 miljonit rida sekundis.
- Kliendiga arutades töötluse kiirusnõudeid, mõistsime, et sellise süsteemi tüüpiline kasutusmuster on järgmine: inimesed otsivad oma rakenduse logisid viimase kahe päeva jooksul ja ei sooviks oodata vastust rohkem kui sekund.
- Adminnid nõudsid, et süsteem oleks vajadusel kergesti skaaleeritav, ilma et nad peaksid sügavale täielikult sisse minema, kuidas see toimib.
- Ainus hooldusülesanne, mis nendele süsteemidele perioodiliselt vaja oli, oli mingi riistvara vahetamine.
- Lisaks on Odnoklassnikites ilus tehniline traditsioon: iga teenus, mille me käivitame, peab taluma andmekeskuse riket (äkilist, planeerimata ja absoluutselt igal ajal).
Selle projekti viimase nõudmise täitmine nõudis meilt kõige rohkem vaeva, millest räägin lähemalt hiljem.
Keskkond
Me töötame neljas andmekeskuses, kusjuures Elasticsearch'i andmeklastrid võivad asuda vaid kolmes (mitme mitte-tehnilise põhjuse tõttu).
Nendes neljas andmekeskuses asub ligikaudu 18 000 erinevat logiallikat — riistvara, konteinerid, virtuaalmasinad.
Oluline omadus: klastrite käivitamine toimub konteinerites mitte füüsilistel masinatel, vaid . Konteineritele garanteeritakse 2 tuuma, mis on sarnased 2.0Ghz v4-le ning ülejäänud tuumade kasutamine, juhul kui need on seisakusse jäänud.
Teisisõnu:

Topoloogia
Lahenduse üldine visioon paistis mulle alguses järgmine:
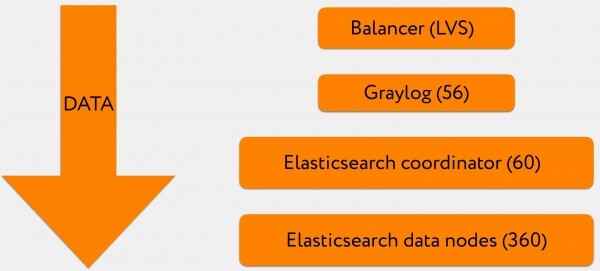
- 3-4 VIP-d seisavad Graylogi domeeni A-kirje taga, sellele aadressile saadetakse logid.
- iga VIP on LVS tasakaalustaja.
- Pärast seda jõuavad logid Graylogi süsteemi, osa andmetest läheb GELF-formaadis, osa syslog-formaadis.
- Edasi kirjutatakse see kõik suurte partiidena Elasticsearch'i koordinaatorite süsteemi.
- Need omakorda saadavad kirjutamis- ja lugemisemandid asjakohastele andmenoodidele.
Terminoloogia
Mõned võivad terminoloogias mitte kõigega põhjalikult tuttavad olla, seetõttu tasub sellel peatumiseks natuke aega võtta.
Elasticsearchis on mitu tüüpi sõlme — master, koordinaator, andmesõlm. On veel kaks muud tüüpi, mis on mõeldud erinevate logide töötlemiseks ja erinevate klastrite omavaheliseks suhtlemiseks, kuid me oleme kasutanud vaid nimetatud tüüpe.
Master
Kontrollib kõiki klastris olevaid sõlmesid, toetab ajakohast klastrikaarti ja levitab seda sõlmede vahel, töötleb sündmuste loogikat ning tegeleb erineva tüüpi klastrisiseste toimingutega.
Koordinaator
Teeb ühte ainsat ülesannet: võtab vastu kliendilt päringud lugemiseks või kirjutamiseks ja suunab selle liikluse. Kui tegu on kirjutamispäringuga, küsib ta suure tõenäosusega masterilt, millisesse shardi vastavat indeksi seda panna, ja suunab päringu edasi.
Andmesõlm
Hoidab andmeid, täidab väljast tulevaid otsingupäringuid ja tehingute toiminguid, mis on seotud sellel asuvate shardidega.
Graylog
See on midagi sarnast Kibana ja Logstashi sulandumisega ELK-virnas. Graylog ühendab endas nii kasutajaliidese kui ka logide töötlemise torujuhtme. Graylogi taga töötavad Kafka ja Zookeeper, mis tagavad Graylogi sidususe klastrina. Graylog suudab vahemällu salvestada logisid (Kafka) juhtudel, kui Elasticsearch ei ole kergesti ligipääsetav, ja kordab ebaõnnestunud lugemis- ja kirjutamisülesandeid, rühmitades ja sildistades logisid vastavalt määratud reeglitele. Nagu Logstash, omab Graylog ka funktsionaalsust stringide muutmiseks enne Elasticsearch'i salvestamist.
Lisaks on Graylogis sisseehitatud teenuse avastamine, mis võimaldab ühe kergesti ligipääsetava Elasticsearch'i sõlme põhjal saada kogu klastri kaardi ja filtreerida seda konkreetse sildi alusel, mis võimaldab suunata päringud teatud konteineritele.
Visuaalselt näeb see umbes välja nii:

See on ekraanipilt konkreetsest instantsist. Siin ehitame otsingupäringu põhjal histogrammi ning kuvame asjakohaseid ridu.
Indeksid
Tagasi süsteemi arhitektuuri juurde, tahaksin detailselt peatuda sellel, kuidas me index mudelit ehitasime, et kõik see õigesti toimiks.
Küljendatud skeemil on see alumine tase: Elasticsearchi andmesõlmed.
Indeks on suur virtuaalne entiteet, mis koosneb Elasticsearch'i shard'idest. Iga shard iseenesest on vaid Lucene indeks. Iga Lucene indeks koosneb omakorda ühest või enamast segmendist.
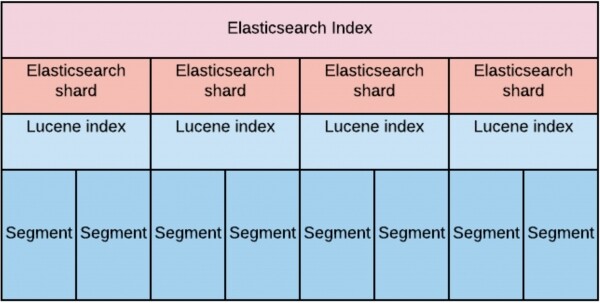
Disaini käigus arvestasime, et suurte andmemahtude lugemiskiirusnõuete täitmiseks on vajalik andmad ühtlaselt "jaotada" andmed andmepunktide vahel.
See tõi meid järeldusele, et indeksi shard'ide arv (koos replikatega) peab olema rangelt võrdne andmepunktide arvuga. Esiteks, et tagada replikeerimise faktor, mis on kaks (st võime kaotada poole klastrist). Teiseks, et lugemis- ja kirjutamispeab töötlema vähemalt poole klastrist.
Käivitusaja määrasime esmalt 30 päeva.
Shard'ide jaotus võib olla visuaalselt esitatud järgmiselt:

Kogu tumehall ristkülik on indeks. Vasak punane ruut selles on põhishard, indeksis esimene. Ja sinine ruut on kopeeritud shard. Need asuvad erinevates andmekeskustes.
Kui me lisame veel ühe shard'i, jõuab see kolmandasse andmekeskusesse. Ja lõpuks saame me sellise struktuuri, mis võimaldab andmekeskuse kadumist ilma, et andmete järjepidevus kannataks:

Indeksite rotatsiooni, st uue indeksi loomise ja kõige vanema indeksi kustutamise, oleme seadnud 48 tunniks (indeksi kasutuse patterni kohaselt: viimase 48 tunni jooksul otsitakse enim).
Selline indeksi rotatsiooni intervall on seotud järgmiste põhjustega:
Kui konkreetne andmevahe nodi saab otsingupäringu, on jõudluse seisukohalt kasulikum, kui küsitakse ainult ühte shard'i, kui selle suurus on võrreldav nodi mälupanga suurusega. See võimaldab hoida indeksi "kuuma" osa mälupangas ja kiiresti sellele juurde pääseda. Kui "kuumi osi" on palju, siis indeksi otsingukiirus halveneb.
Kui sõlm hakkab täitma otsingupäringut ühes shardis, eraldab ta füüsilise masina hüperthreading tuumadele vastava arvu lõime. Kui otsingupäring hõlmab suurt hulka shard'e, kasvab lõimede arv proportsionaalselt. See mõjutab negatiivselt otsingu kiirus ja avaldab halba mõju uute andmete indekseerimisele.
Otsingulävede tagamiseks otsustasime kasutada SSD-sid. Kiireks päringute töötlemiseks peavad masinad, millel need konteinerid asuvad, omama vähemalt 56 tuuma. Arv 56 on valitud kui tingimisi piisav väärtus, mis määrab lõimede arvu, mida Elasticsearch töös genereerib. Elasticsearchis sõltuvad paljud thread pool'i parameetrid otseselt saadaval olevate tuumade arvust, mis omakorda mõjutab vajalike nodede arvu klastris põhimõttega "vähem tuumi — rohkem node".
Kokkuvõttes selgus, et keskmiselt kaalub shard umbes 20 gigabaidi ning ühe indeksi kohta on 360 shard'i. Seetõttu, kui me neid roteerime iga 48 tunni järel, on neid kokku 15. Iga indeks mahutab andmeid kahe päeva jooksul.
Andmete salvestamise ja lugemise skeemid
Vaatame, kuidas selles süsteemis andmeid salvestatakse.
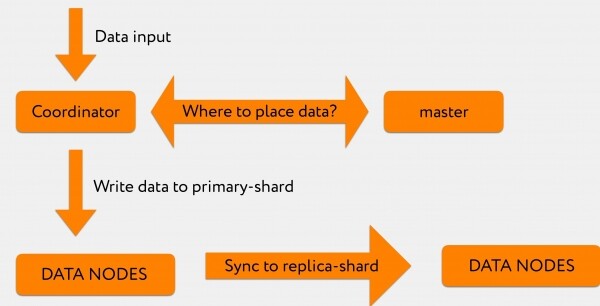
Oletame, et Graylogist tuleb koordinaatorisse mingi päring. Näiteks soovime indekseerida 2-3 tuhat rida.
Koordinaator, saades Graylogist päringu, küsib meistrilt: „Indekseerimise päringus on konkreetne indeks, kuid millisesse shard'i see kirjutada — seda pole täpsustatud“.
Meister vastab: „Salvesta see teave shard'i numbriga 71“, pärast mida saadetakse see otse asjakohasesse andme-sõlme, kus asub primary-shard numbriga 71.
Pärast seda replikatakse tehingute logi replica-shard'i, mis asub juba teises andmekeskuses.
Graylogist tuleb koordinaatorisse otsingupäring. Koordinaator suunab selle indeksi põhjal, samas Elasticsearch jaotab päringud round-robin meetodil primary-shard'i ja replica-shard'i vahel.
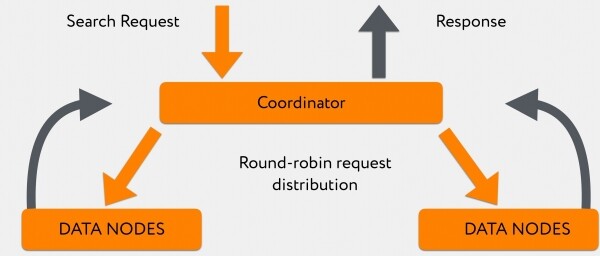
180 sõlme vastavad ebavõrdselt ja seni, kuni nad vastavad, kogub koordinaator teavet, mille juba kiiremad andme-sõlmed temasse „välja sülitasid“. Pärast seda, kui kas kogu teave on saabunud või päringu jaoks on saavutatud ajavahemik, edastab ta kõik otse kliendile.
Selle süsteemi keskmine vastamisaeg otsingupäringutele viimase 48 tunni jooksul on 300–400 ms, välja arvatud päringud, mis sisaldavad leading wildcard'it.
Elasticsearchi "Lilledega": Java seadistamine

Kuna soovime, et kõik see töötaks nii nagu algselt plaanisime, veetsime me väga palju aega erinevate asjade klastris häälestamisele.
Esimene leitud probleem oli seotud sellega, kuidas Elasticsearch on vaikimisi Java jaoks eelseadistatud.
Probleem number üks
Oli palju teateid, et meil on Lucene tasemel, kui taustatöödel on käivitatud, Lucene segmentide ühendamised ebaõnnestunud. Samuti oli logides näha, et see on OutOfMemoryError-iga seotud. Telemeetria kohaselt nägime, et heap on vabanev ja ei olnud selge, miks see operatsioon ebaõnnestub.
Selgus, et Lucene indeksite ühendamised toimuvad väljaspool heap'i. Ja konteinerid on üsna rangelt piiratud kasutatavate ressurssidega. Nendesse ressurssidesse mahtus ainult heap (heap.size väärtus oli ligikaudu võrdne RAM-iga) ja mõned off-heap operatsioonid kukkusid välja mälu jagamise veaga, kui mingil põhjusel ei mahtunud nad neid umbes 500 MB, mis olid limiidile lähedal.
Probleem oli üsna lihtne: konteinerile antud RAM-i mahtu suurendati, pärast mida unustasime, et sellised probleemid üldse eksisteerisid.
Teine probleem
Umbes 4–5 päeva pärast klastrite käivitamist märkisime, et andmenoodid hakkavad perioodiliselt klastrist välja langema ja tagasi tulema 10–20 sekundi pärast.
Kui hakkasime uurima, selgus, et see off-heap mälu Elasticsearchis ei ole praktiliselt üldse kontrollitud. Kui andsime konteinerile rohkem mälu, saime võimaluse täita otsepuud (direct buffer pools) erinevate andmetega, ning need puhastusid ainult pärast seda, kui Elasticsearch käivitas explicit GC.
Mõnel juhul toimus see operatsioon üsna pika aja jooksul, ja selle aja jooksul suutis klaster märgistada selle noodiga juba välja langenud. See probleem on hästi kirjeldatud. .
Lahendus oli järgmine: piirasime Java võimet kasutada peamise osa mälu väljaspool heapsit nende operatsioonide jaoks. Piirasime selle 16 gigabaidini (-XX:MaxDirectMemorySize=16g), saavutades, et explicit GC kutsuti oluliselt sagedamini ja toimus oluliselt kiiremini, lõpetades seeläbi klastrit destabiliseerimise.
Kolmas probleem
Kui arvasite, et probleemid "sõlmedega, mis lahkuvad klastrist kõige ettearvamatumatel hetkedel" on nüüdseks läbi, eksite.
Indeksite töö seadistamisel valisime mmapfs, et värskete shardide puhul suure segmentatsiooniga. See oli üsna suurem viga, sest mmapfs-i kasutamisel kaardistatakse fail peamällu ning seejärel töötame juba mapped-failiga. Seetõttu tekib olukord, kus üritades viimaseid niite peatada, läheme me safepointi poole väga kaua, ja teel sinna lakkab rakendus reageerimast meistrilt küsimistele, kas see on ikka veel aktiivne. Seetõttu arvab master, et sõlm ei ole enam klastris. Pärast seda, umbes 5–10 sekundi pärast, töötab prügikoristus, sõlm taastub, siseneb taas klastrisse ja alustab shardide initsialiseerimist. Kõik see meenutas tugevalt “toodet, mida me väärime” ja ei sobinud tõsisemaks kasutamiseks.
Selle käitumise lõpetamiseks võtsime kõigepealt kasutusele standardse niofs'i ning seejärel, kui oleme Elastic'i viiendast versioonist kuuesse migrate'nud, proovime hybridfs'i, kus see probleem ei esinenud. Tüüpide kohta saab rohkem lugeda storage'st. .
Neljas probleem
Siis oli veel üks väga huvitav probleem, mida lahendasime rekordiliselt kaua. Me püüdsime seda 2-3 kuud, kuna selle muster oli täiesti arusaamatu.
Mõnikord läksid meie koordinaatorid Full GC'sse, tavaliselt pärast lõunat, ja sealt nad enam ei naasnud. Samas, kui logisime GC viivitusi, nägi see välja selline: kõik sujus hästi, hästi, hästi, ja siis järsku — kõik läks äkki halvaks.
Alguses arvasime, et meil on kuri kasutaja, kes käivitab mingisuguse päringu, mis lööb koordinaatori töökeskkonnast välja. Logisime päringuid väga kaua, püüdes aru saada, mis toimub.
Lõpuks selgus, et hetkel, kui mõni kasutaja käivitab väga suurepäringu ja see jõuab konkreetsele Elasticsearchi koordinaatorile, vastavad mõned noodid kauem kui teised.
Kuni sel hetkel, mil koordinaator ootab kõigi nodide vastust, kogub ta endasse tulemusi, mis on saadetud juba vastanud nodidelt. GC jaoks tähendab see, et meie hüpoteekide kasutusmuster muutub väga kiiresti. Ja see GC, mida me kasutasime, ei suutnud selle ülesandega toime tulla.
Ainus lahendus, mille me leidsime, et muuta klastrite käitumist sellises olukorras, on migreerimine JDK13-le ja prügikoguja Shenandoah kasutamine. See lahendas probleemi, koordinaatorid ei kukkunud enam alla.
Sellega lõppesid Java probleemid ja algasid ribalaiuse probleemid.
„Marjad” Elasticsearchiga: ribalaius

Ribalaiuse probleemid tähendavad, et meie klaster töötab stabiilselt, kuid dokumentide indekseerimise tipppunktide ajal ja manööverdushetkedel on jõudlus ebapiisav.
Esimene märgatav sümptom: mõningate „plahvatuste” korral tootmises, kui genereeritakse äkki väga suur hulk logisid, hakkab Graylogis sageli ilmuma indekseermise viga es_rejected_execution.
See toimus seetõttu, et thread_pool.write.queue ühes andmega nodis suudab enne Elasticsearchi indekseerimistaotluse töötlemist ja teabe jagusse kirjutamist vaikimisi vahemälus hoida vaid 200 taotlust. Ja käsitletakse seda parameetrit väga vähe. Mainitakse vaid lõpp-arvu teemasid ja vaikimisi suurust.
Muidugi hakkasime seda väärtust kohandama ning selgus järgmist: meie seadistuses vahemälustatakse üsna hästi kuni 300 taotlust, samas kui suurem väärtus toob meid tagasi Full GC-i.
Lisaks, kuna need on ühes taotluses saabuvad sõnumipakid, pidi Graylogi seadistama nii, et see kirjutaks mitte liiga sageli ja väikeste pakettidega, vaid suurte pakettidega või iga kolme sekundi järel, kui pakett pole veel täielik. Sellisel juhul tundub, et teave, mida me Elasticsearchi kirjutame, on kättesaadav mitte kahe sekundi jooksul, vaid viie sekundi jooksul (mis sobib meile täiesti), kuid väheneb retrai arv, mis tuleb suure teabe paketi edastamiseks teha.
See on eriti oluline siis, kui meil on midagi kukkunud ja see teatatakse meeleheitlikult, et vältida täielikku spämmimist Elasticis, ja mõne aja pärast — mittetoimivad Graylogi noodid ummistunud puhvrite tõttu.
Lisaks, kui meil olid need plahvatused tootmises, saime kaebusi programmeerijatelt ja testijatelt: hetkel, kui nad neid logisid tõeliselt vajavad, tullakse neid välja väga aeglaselt.
Hakkasime uurima. Ühest küljest oli selge, et nii otsingupäringud kui ka indekseerimispäringud töötavad põhimõtteliselt ühel ja samal füüsilisel masinal, seega mingil määral on teatud langused vältimatud.
Kuid seda sai osaliselt vältida, kasutades šesti versioonides Elasticsearchi ilmunud algoritmi, mis võimaldab suunata päringud asjakohastele andmepunktide vahel mitte juhuslikult round-robin põhimõttel (konteiner, mis tegeleb indekseerimisega ja hoiab primary-shard'i, võib olla väga hõivatud, seal ei ole kiire vastuse võimalust), vaid suunata see päring vähem koormatud konteinerisse, millel on replica-shard, mis vastab oluliselt kiiremini. Teisisõnu, jõudsime use_adaptive_replica_selection: true juurde.
Lugemise pilt hakkab välja nägema selline:
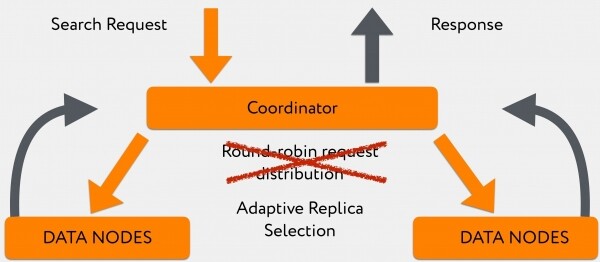
Selle algoritmile üleminek aitas oluliselt parandada päringu aega olukordades, kus meil oli suur logide kirjutamise voog.
Lõppkokkuvõttes seisnes peamine probleem sujuvas andmekeskuse väljavõtmises.
Mida me ootasime klastrilt kohe pärast ühenduse kaotamist ühe DC-ga:
- Kui meil on kadunud andmekeskuses praegune master, siis valitakse see ümber ja liigub rollina teisele sõlmele teises DC-s.
- Master eemaldab kiiresti klastrist kõik kättesaamatud sõlmed.
- Jäänud põhjal mõistab ta: kadunud andmekeskuses olid meil sellised peamised shardid, kiiresti promootib ta täiendavad replica-shardid jäänud andmekeskustes ja meil jätkub andmete indekseerimine.
- Selle tulemusena hakkab meie klastrite kirjutamis- ja lugemisvõime järk-järgult langema, kuid üldiselt töötab kõik aeglaselt, kuid stabiilselt.
Kuidas selgus, soovisime midagi sellist:

Aga saime järgmist:

Kuidas see juhtus?
Andmekeskuse kokkuvarisemise hetkel oli meie kitsaskohaks master.
Miks?
Asja on selles, et masteris on TaskBatcher, mis vastutab teatud ülesannete ja sündmuste levitamise eest klastris. Iga nodi väljalülitamine, iga shardi edasiviimine replica-st primary-sse, igasugune shardi loomise ülesanne — kõik see läheb esmalt TaskBatcherisse, kus see töödeldakse järjestikku ja ühes voos.
Ühe andmekeskuse väljaviimise hetkel juhtus, et kõik elujõulised andmenoodid elujõulistes andmekeskustes pidid teatama masterile, et "meil on kadunud sellised shardid ja sellised andmenoodid".
Samal ajal saatsid elujõulised andmenoodid kogu selle teabe praegusele masterile ja proovsid oodata kinnitust, et ta on selle vastu võtnud. Nad ei oodanud seda, sest master sai ülesandeid kiiremini, kui ta oskas vastata. Noodid kordasid päringuid ajavahemiku lõppedes, samal ajal kui master ei püüdnud enam neile vastata, vaid oli täielikult pühendunud päringute sorteerimisele prioriteedi järgi.
Terminali vaates nägi välja nii, et data-nodes saatis masterile nii palju, et ta läks full GC. Pärast seda kolis meie master järgmisse nodde, kus toimus sama asi, ja lõpuks lagunes klaster täielikult.
Me tegime mõõtmisi ja enne versiooni 6.4.0, kus see probleem fikseeriti, piisab, kui eemaldada korraga vaid 10 data-node’it 360-st, et klaster täielikult maas oleks.
See nägi välja umbes nii:

Pärast versiooni 6.4.0, kus see kohutav bugi parandati, lõpetasid data-nodes masteri tapmise. Kuid see ei teinud teda „nutikamaks“. Nimelt: kui me eemaldame 2, 3 või 10 (mille iganes arv, mis ei ole 1) data-node'it, saab master mingi esialgse sõnumi, mis ütleb, et node A on kadunud, ja püüab sellest rääkimiseks teavitada node B, node C, node D.
Praegu saab sellega võidelda ainult seadistades aega, mille jooksul proovitakse kellelegi midagi selgitada, umbes 20-30 sekundit, ja seeläbi kontrollida data-center’i eemaldamise kiirus klastrist.
Põhimõtteliselt vastab see algselt projekti lõppprodukti jaoks esitatud nõuetele, kuid puhta teaduse seisukohalt on see tõrge. Mis, muide, on arendajate poolt versioonis 7.2 edukalt parandatud.
Kuid kui mingi andme-node kukkus, selgus, et teavet selle kukkumise kohta on olulisem levitada kui kogu klastrile rääkida, et sellel olid sellised esmased osad (et reklaamida replica-shard teises andmekeskuses esmaseks, kuhu saaks andmeid kirjutada).
Seetõttu, kui kõik "rahutused" on möödas, ei märgistata väljatootud andme-nodesid kohe vananenuks. Seega peame ootama, kuni kõik pinged väljatoodud andme-nodedele aeguvad, ja alles siis hakkab meie klaster rääkima, et seal-seal-seal tuleb andmete salvestamine jätkata. Täpsemat teavet saab lugeda siit. .
Kokkuvõttes võtab andmeruumi väljutamine meil täna tipptunnil aega umbes 5 minutit. Sellise suure ja kohmakas masina jaoks on see üsna hea tulemus.
Kokkuvõttes jõudsime järgmise lahenduseni:
- Meil on 360 andme-node'i, millel on 700 gigabaidi kõvakettad.
- 60 koordinaatorit liikluse suunamiseks nende samade andmepunktide kaudu.
- 40 meistrit, kes on jäänud meile kui mingi pärand versioonidest enne 6.4.0 - et ellu jääda andmekeskuse sulgemisest, olime moraalselt valmis kaotama mõned masinad, et tagada isegi halvimates stsenaariumides ustavus meistrite seas.
- Iga katse rollide ühendamiseks ühes konteineris jooksis meie puhul kokku sellega, et varem või hiljem node purunes koormuse all.
- Kogu klastris kasutatakse heap.size-d, mis on 31 gigabaiti: kõik katsed suurust vähendada tõid kaasa, et raskete otsingupäringute puhul, millel oli leading wildcard, kas tapeti mõned node'id või tabas circuit breaker ise Elasticsearchis.
- Lisaks pingutasime otsingutulemuste tagamiseks hoidma klastris objektide arvu minimaalsena, et töödelda võimalikult vähe sündmusi kitsas kohas, mis meil meistris õnnestus.
Viimaseks jälgimisest
Kuna kõik see töötaks nii, nagu oli planeeritud, jälgime järgmist:
- Iga andme taga sõlmib meie pilve, et see on olemas ja sellel on sellised shard’id. Kui kustutame kuskil midagi, teatab klaster 2–3 sekundi jooksul, et keskuses A oleme kustutanud sõlmed 2, 3 ja 4 — see tähendab, et teistes andmekeskustes ei saa me mingil juhul kustutada neid sõlmi, kus on jäänud shard'id ainsuses.
- Teades meistri käitumist, jälgime väga tähelepanelikult pending-ülesannete arvu. Sest isegi üks jääk ülesanne, kui seda õigel ajal ei taandata, võib teoreetiliselt kriitilises olukorras olla põhjus, miks meil ei toimi näiteks replica-shardi edastus primary'sse, mis peatab indekseerimise.
- Samuti jälgime väga hoolikalt garbage collectori viivitusi, kuna meil on selle probleemiga juba olnud suuri raskusi optimeerimise käigus.
- Thread’ite tagasilükked, et mõista ette, kus asub 'pudelikael'.
- Ja ka standardsed näitajad, nagu heap, RAM ja I/O.
Monitooringu loomisel tuleb kindlasti arvesse võtta Elasticsearchi Thread Pooli omadusi. kirjeldab seadistamise võimalusi ja vaikeväärtusi otsimiseks, indekseerimiseks, kuid jätab täiesti tähelepanuta thread_pool.management. Need niidid töötlevad eelkõige päringuid tüüpi _cat/shards ja muid sarnaseid, mida on mugav kasutada jälgimise kirjutamisel. Mida suurem klaster, seda rohkem selliseid päringuid tehakse ajaühikus ning eelmainitud thread_pool.management on lisaks sellele, et seda ei ole ametlikus dokumentatsioonis esitatud, vaikimisi piiratud 5 niidiga, mis saab kiiresti ammendatud, pärast mida jälgimine lakkab korrektselt töötamast.
Lõpetuseks tahaks öelda: meil õnnestus! Oleme suutnud anda meie programmeerijatele ja arendajatele tööriista, mis on praktiliselt igas olukorras võimeline kiiresti ja usaldusväärselt andma teavet sellest, mis toimub tootmises.
Jah, see osutus üsna keeruliseks, aga sellegipoolest suutsime meie soovid mahutada juba olemasolevatesse toodetesse, mida ei pidanud enda jaoks parandama ja ümber kirjutama.

Allikas: habr.com
