


Kliendid küsivad üha enam: „Tahame nagu Amazon RDS, aga odavamalt“; „Tahame nagu RDS, kuid igas infrastruktuuris“. Et luua sarnane hallatav lahendus Kuberneteses, vaatasime populaarseimate PostgreSQL operaatorite (Stolon, Crunchy Data ja Zalando operaatorid) praegust seisu ja tegime oma valiku.
See artikkel on meie saadud kogemus nii teoreetilisest (lahenduste ülevaade) kui ka praktilisest (mis valiti ning mis sellest sai) vaatenurgast. Kuid kõigepealt selgitame välja, millised nõudmised esitatakse potentsiaalsele RDS asendusele...
Mis on RDS?
Kui inimesed räägivad RDS-ist, siis meie kogemuse kohaselt, nad mõistavad hallatavat (managed) andmebaasiteenust, mis:
- on kergesti seadistatav;
- omab võimalust töötada snapshots'itega ja taastuda neist (eelmisel juhul — toega );
- kurbab luua master-slave topoloogiaid;
- omab ulatuslikku laiendite nimekirja;
- pakub kasutajate/auditite ja juurdepääsude haldamist.
Üldiselt võivad lähenemised seatud ülesande täitmiseks olla üsna erinevad, kuid tingimuslik Ansible on meile võõras. (Sarnasele järeldusele jõudsid ka 2GIS-i kolleegid oma katses Omandatud operaatorid on üldtunnustatud lähenemine sarnaste probleemide lahendamiseks Kubernetes’e ökosüsteemis. Rohkem teavet nende kohta, mida kasutada Kubernetes'e sees töötavates andmebaasides, jagas juba Flanta tehniline direktor
oma esitlustes: , in .
NB. Kasutades seda, on võimalik seda teha ilma teadmata Go keelt, kasutades rohkem süsteemiadministraatoritele tuttavaid viise: Bash, Python jne. PostgreSQL-i jaoks on olemas mitu populaarset K8s-ooperatoori:
Stolon;
- Crunchy Data PostgreSQL Operator;
- Zalando Postgres Operator.
- Vaatame neid lähemalt.
Operaatori valik
Peale nende oluliste võimaluste, mida oli juba eespool mainitud, ootasime – kui Kubernetes'i infrastruktuuri insenerid – operaatoritelt ka järgmist:
Gitist paigaldamine ja
- Kohandatud ressursid ;
- поддержку pod anti-affinity;
- node affinity või node selector seadistamine;
- toleratsioonide seadistamine;
- tuning-võimaluste olemasolu;
- arusaadavad tehnoloogiad ja isegi käsud.
Ilma igasse punkti detailidesse laskumata (küsige kommentaarides, kui tekivad küsimused pärast artikli lugemist), märkida, et need parameetrid on vajalikud klastrite sõlmede spetsialiseerumise täpsemaks kirjeldamiseks, et tellida neid konkreetsete rakenduste jaoks. Nii saame saavutada optimaalse tasakaalu jõudluse ja hinna vahel.
Nüüd — PostgreSQL operaatorite juurde.
1. Stolon
Itaalia ettevõtte Sorint.lab poolt peeti mingisuguseks etaloniks andmebaasi operaatorite seas. See on üsna vana projekt: esimene avalik väljaanne toimus juba 2015. aasta novembris(!), ja GitHubi repole on kogunenud peaaegu 3000 tähte ning 40+ panustajat.
Ja tõepoolest, Stolon on suurepärane näide läbi mõeldud arhitektuurist:
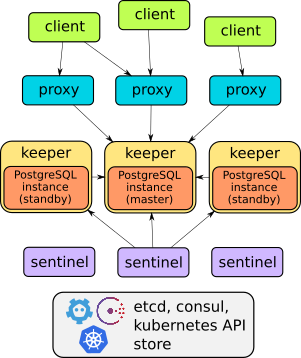
Selle operaatori seadistuse üksikasjadega saab tutvuda ettekandes või . Üldiselt võib öelda, et see suudab kõike kirjeldatut: failover, klientide läbipaistva juurdepääsu proxid, varukoopiad… Lisaks pakuvad proxid juurdepääsu läbi ühe teenuse lõpp-punkti — erinevalt kahest järgnevast lahendusest (neil on kaks teenust andmebaasi juurdepääsuks).
Kuid Stolonil , mistõttu ei saa seda lihtsalt ja kiiresti nagu „kuuma pirukaga” DB eksemplare Kubernetesesse luua. Halduse teostab utiliit stolonctl, deploy on läbi Helm-charti, ja kasutaja määratleb need ConfigMap’is.
Ühelt poolt tundub, et operaator ei ole väga operaator (sest ta ei kasuta CRD-d). Teiselt poolt on see paindlik süsteem, mis võimaldab seadistada ressursse K8s just nii, nagu soovite.
Kokkuvõttes ei tundunud meile optimaalne tee luua iga DB jaoks eraldi chart. Seetõttu hakkasime otsima alternatiive.
2. Crunchy Data PostgreSQL Operaatор
, noore Ameerika idufirma näib olevat loogiline alternatiiv. Selle avalik ajalugu algab esimesest versioonist märtsis 2017, mille järel on GitHubi repo saanud veidi vähem kui 1300 tähte ja 50+ kaastöötajat. Viimane väljaanne septembris on testitud koos Kubernetes 1.15—1.18, OpenShift 3.11+ ja 4.4+, GKE ning VMware Enterprise PKS 1.3+.
Crunchy Data PostgreSQL operaatori arhitektuur vastab samuti deklareeritud nõuetele:
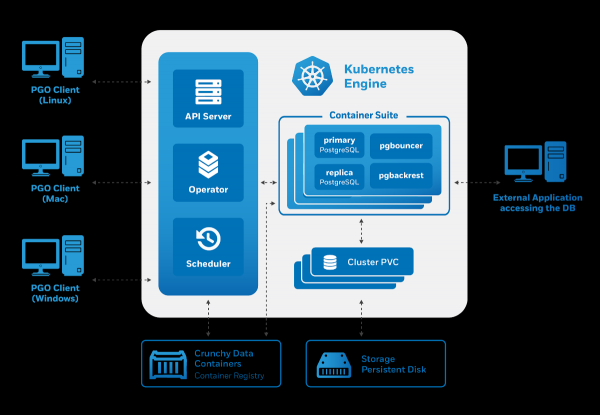
Halduse tegemine toimub utiliidi kaudu pgo, kuid see genereerib omakorda Custom Resources Kubernetes'ele. Seega rõõmustas operaator meid, kui potentsiaalseid kasutajaid:
- on haldus läbi CRD;
- mugav kasutajate haldus (samuti läbi CRD);
- integreerimine teiste komponentidega — spetsialiseeritud konteinerite piltide kogum PostgreSQL-i ja selle kasutamiseks mõeldud utiliitide (sealhulgas pgBackRest, pgAudit, laiendused contrib-st jne) jaoks.
Siiski tõi Crunchy Data operaatorit kasutama asudes esile mitmeid probleeme:
- Toleratsioonide võimalust ei olnud — oli ette nähtud ainult nodeSelector.
- Loodud pod’id olid osa Deployment’ist, kuigi me jagasime stateful-rakendust. Erinevalt StatefulSet’ist ei oska Deployment’id luua kettaid.
Viimane puudus toob kaasa lõbusaid hetki: testkeskkonnas õnnestus käivitada 3 koopiat ühe ketta abil kohalik salvestus, mistõttu operaator teatas, et 3 koopiat töötab (kuigi see polnud tõsi).
Veel üks selle operaatori omadus on selle valmis integreerimine erinevate abisüsteemidega. Näiteks on lihtne paigaldada pgAdmin ja pgBounce, samas kaalutakse eelkonfigureeritud Grafana ja Prometheus. Hiljutises märgitakse eraldi paranenud integreerimist projektiga , mille tõttu operaator pakub PgSQL mõõdikute selget visualiseerimist „karbist välja”.
Siiski viis kummaline valik genereeritud Kubernetes’i resursse meid vajaduseni leida muu lahendus.
3. Zalando Postgres Operator
Zalando tooted on meile ammu tuntud: meil on kogemusi Zaleniumi kasutamisega ja kindlasti oleme proovinud — nende populaarset HA-lahendust PostgreSQL jaoks. Ettevõtte lähenemisest rääkis üks selle autoritest — Aleksei Klyukin — saates , ja see meeldis meile.
See on noorim lahendus artiklis arutletud: esimene versioon ilmus augustis 2018. aastal. Siiski, hoolimata vähesest ametlikust väljalaskmisest, on projekt teinud suure sammu edasi, ületades juba populaarsuses Crunchy Data lahendust, millel on üle 1300 tähe GitHubis ja maksimaalne kontriibutajate arv (üle 70).
Selle operaatori „all“ kasutatakse ajaga proovile pandud lahendusi:
- Patroni ja halduseks,
- — varukoopiate jaoks,
- — ühenduste basena.
Siin on esitatud Zalando operaatori arhitektuur:
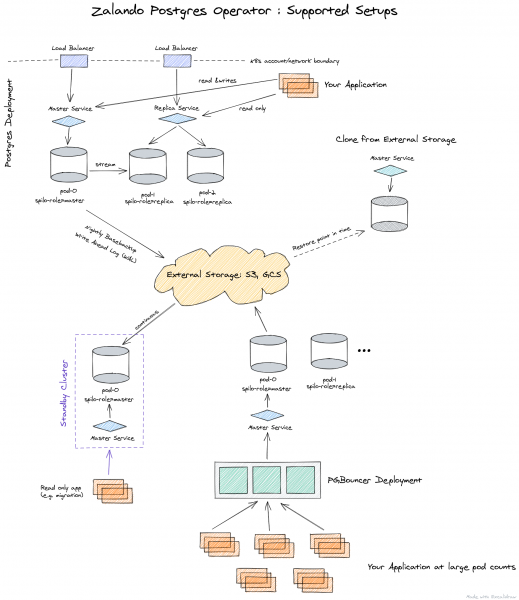
Operaatorit saab täielikult hallata Custom Resources kaudu, see loob automaatselt StatefulSet'i konteineritest, mida saab seejärel kohandada, lisades pod’i erinevaid sidecar’e. Kõik see on suur pluss võrreldes Crunchy Data operaatoriga.
Kuna me valisime Zalando lahenduse kolme arutletud variandi seast, esitatakse allpool edasi selle võimaluste kirjeldus koos rakenduse praktikaga.
Zalando Postgres Operaatori praktika
Operaatori juurutamine toimub väga lihtsalt: piisab, kui laadida alla uusim väljaanne GitHubist ja rakendada YAML-failid kaustast. . Samuti võib kasutada .
Pärast installimist tuleks muretseda See toimub läbi ConfigMap postgres-operator nimetuses, kuhu olete operaatori paigaldanud. Kui hoidlad on seadistatud, saab käitada esimese PostgreSQL klastrit.
Näiteks meie standardne paigaldus näeb välja järgmine:
apiVersion: acid.zalan.do/v1
kind: postgresql
metadata:
name: staging-db
spec:
numberOfInstances: 3
patroni:
synchronous_mode: true
postgresql:
version: "12"
resources:
limits:
cpu: 100m
memory: 1Gi
requests:
cpu: 100m
memory: 1Gi
sidecars:
- env:
- name: DATA_SOURCE_URI
value: 127.0.0.1:5432
- name: DATA_SOURCE_PASS
valueFrom:
secretKeyRef:
key: password
name: postgres.staging-db.credentials
- name: DATA_SOURCE_USER
value: postgres
image: wrouesnel/postgres_exporter
name: prometheus-exporter
resources:
limits:
cpu: 500m
memory: 100Mi
requests:
cpu: 100m
memory: 100Mi
teamId: staging
volume:
size: 2Gi
Antud manifest paigaldab klastrit, kus on 3 eksemplari koos sidecar'iga , millest võtame rakenduse mõõdikud. Nagu näete, on kõik väga lihtne ja soovi korral saab luua sõna otseses mõttes piiramatu arvu klastreid.
Tasub tähelepanu pöörata ka veebipaneelile haldamiseks — . See toob koos operaatoriga, mis võimaldab luua ja kustutada klustreid ning töötada operaatori poolt loodud varukoopiatena.
PostgreSQL klastrite nimekiri
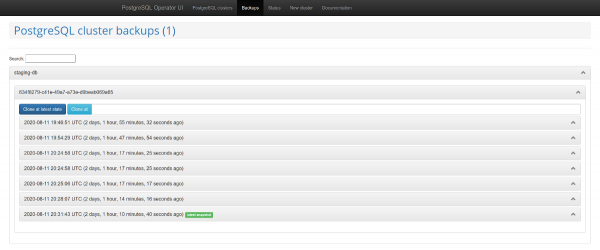
Varukoopiate haldamine
Teine huvitav omadus on toimetamine . Antud mehhanism genereerib automaatselt rolle PostgreSQLis, lähtuvalt saadud kasutajanime nimekirjast. Pärast seda võimaldab API tagastada nimekirja kasutajatest, kellele loodakse automaatselt rollid.
Probleemid ja nende lahendamine
Kuid operaatori kasutamine tõi peagi esile mitmeid olulisi puudusi:
- nodeSelector'i toe puudumine;
- varukoopiate keelamise võimaluse puudumine;
- andmebaaside loomise funktsiooni kasutamine ei anna vaikimisi privileege;
- mõnikord ei piisa dokumentatsioonist või on see aegunud.
Õnneks saavad paljusid neist lahendada. Alustame lõpust — probleemide osas dokumentatsiooniga.
Tõenäoliselt kohtate olukordi, kus pole alati selge, kuidas varukoopia määrata ja kuidas ühendada varukoopia anum Operaatori kasutajaliidesega. Sellega seoses räägitakse dokumentatsioonis ainult üle, aga reaalne kirjeldus on :
- peate looma salajase;
- edastama selle operaatorile parameetrina
pod_environment_secret_nameCRD-s kujunduse seadetes või ConfigMapis (sõltub sellest, kuidas otsustasite operaatori installida).
Kuid nagu selgus, on see hetkel võimatu. Täpselt sellepärast oleme kogunud mõningate lisaväliste arendustegevustega. Rohkem sellest — vaadake allpool.
Kui edastada operaatorile varukoopiate parameetrid, nimelt — wal_s3_bucket ja juurdepääsuvõtmed AWS S3-s, siis teeb ta varukoopiaid kõigest: mitte ainult tootmisandmebaasidest, vaid ka staging'ist. See ei rahuldanud meid.
Spilo parameetrite kirjelduses, mis on põhine Docker-i kattes PgSQL töö kasutamisel operaatori kaudu, selgus, et saab edastada parameetri WAL_S3_BUCKET tühjana, seeläbi varukoopiaid keelates. Lisaks, suureks rõõmuks leidsime ka , mille me koheselt oma forki võtsime. Nüüd piisab lihtsalt enableWALArchiving: false PostgreSQL klastrite ressursile lisamisest.
Jah, oli võimalus teisi teed minna, käivitades 2 operaatorit: üks staging'i jaoks (ilma varukoopiateta) ja teine tootmise jaoks. Kuid nii suutsime hakkama saada ühega.
Okei, me õppisime edastama andmebaasides juurdepääsu S3-le ja varukoopiad hakkasid laokogusse jõudma. Kuidas saame tööle panna varukoopiate lehed Operator UI-s?

Operator UI-s tuleb lisada 3 muutuja:
-
SPILO_S3_BACKUP_BUCKET -
AWS_ACCESS_KEY_ID -
AWS_SECRET_ACCESS_KEY
Pärast seda muutub varundamise haldamine võimalikuks, mis meie puhul lihtsustab tööprotsesse stagingus, võimaldades tõsta sinna tootmisandmeid ilma täiendavate skriptideta.
Veel ühe plussina toodi välja töö Teams API-ga ja laiad võimalused andmebaaside ja rollide loomisel operaatori vahenditega. Kuid loodud rollid ei sisaldanud vaikimisi õigusi.Seetõttu ei teadnud lugemisõigustega kasutaja uusi tabeleid lugeda.
Miks nii? Kuigi koodis on vajalikud GRANT, ei rakendata neid alati. On kaks meetodit: syncPreparedDatabases ja syncDatabases. Dokumendihalduses syncPreparedDatabases — ehkki sektsioonis preparedDatabases on tingimus defaultRoles ja defaultUsers rollide loomise jaoks, ei rakendata vaikimisi õigusi. Oleme valmis töötama patšiga, et need õigused rakenduksid automaatselt.
Ja viimane punkt meie praegustes täiustustes — , lisades Node Affinity loodud StatefulSet'i. Meie kliendid eelistavad sageli kulusid vähendada, kasutades spot-instantse, kuid neid ei tohiks kasutada DBA teenuste jaoks. Selle küsimuse saaks lahendada ka toleratsioonidega, kuid Node Affinity olemasolu annab suurema kindluse.
Mis saime?
Nende probleemide lahendamise tulemuste põhjal forkasime Postgres Operatori Zalando'lt , kus see koguneb nii kasulike patchidega. Mugavuse huvides oleme kokku kogunud ka .
PR-de nimekiri, mis on forkis vastu võetud:
- ;
- ;
- ;
- .
Oleks tore, kui kogukond toetaks neid PR-e, et need jõuaksid järgmise operaatori versiooniga (1.6) upstream'i.
Boonus! Edulugu productioni migratsioonist
Kui kasutate Patronit, saate operaatoreid migratsiooni kaudu elava productioniga minimaalse seisaku kestuse.
Spilo võimaldab luua standby klastreid läbi S3 salvestuste , kus PgSQL binaarlog kõigepealt salvestatakse S3-sse ja seejärel laaditakse välja koopiana. Aga mis siis, kui teil on ei kasutatakse Wal-E vanas infrastruktuuris? Selle probleemi lahendus on juba Habr's.
Siin tuleb appi PostgreSQL loogiline replikaat. Kuid me ei hakka detailidesse laskuma, kuidas väljaandeid ja tellimusi luua, sest... meie plaan ebaõnnestus.
Asi on selles, et andmebaasis oli mitu koormatud tabelit, milles oli miljoneid ridu, mis pidevalt täienesid ja kustutati. koos copy_data, kui uus replika kopeerib kogu sisu originaalist, lihtsalt ei jõudnud originaali järgi. Sisu kopeerimine töötas nädal aega, kuid ei jõudnud kunagi originaali järele. Lõpuks aitas probleemi lahendada kolleegid Avitost: andmeid saab üle kanda, kasutades pg_dump. Kirjeldan meie (veidi kohandatud) versiooni sellest algoritmist.
Idee on see, et saab teha välja lülitatud tellimuse, mis on seotud konkreetse replikatsiooni ajavahemikuga, ja seejärel parandada tehingu numbrit. Oli olemas replikaad, et töödelda tootmisprotsessi. See on oluline, sest replika aitab luua järjekindlat dump'i ja jätkata muudatuste saamist originaalist.
Järgnevatel käskudel, mis kirjeldavad migreerimisprotsessi, kasutatakse hostide tähistamiseks järgmisi märke:
- master — algne server;
- replica1 — voogesitusreplikatsioon vanas production-is;
- replica2 — uus loogiline replikatsioon.
Migratsiooniplaan
1. Loome masteris tellimuse kõigi tabelite jaoks skeemis public andmebaasi dbname:
psql -h master -d dbname -c "CREATE PUBLICATION dbname FOR ALL TABLES;"
2. Loome replikaatsiooni slot'i masteris:
psql -h master -c "select pg_create_logical_replication_slot('repl', 'pgoutput');"
3. Peatame replikaatsiooni vanas replikas:
psql -h replica1 -c "select pg_wal_replay_pause();"
4. Saame masterist tehingu numbri:
psql -h master -c "select replay_lsn from pg_stat_replication where client_addr = 'replica1';"
5. Teeme vana replikast dump'i. Teeme seda mitmes voos, et kiirendada protsessi:
pg_dump -h replica1 --no-publications --no-subscriptions -O -C -F d -j 8 -f dump/ dbname
6. Laeme dump'i uuele serverile:
pg_restore -h replica2 -F d -j 8 -d dbname dump/
7. Pärast dump'i laadimist saab voogreplikatsiooni käivitada voogesitusreplikas:
psql -h replica1 -c "select pg_wal_replay_resume();"
7. Loome tellimuse uuel loogilisel replikal:
psql -h replica2 -c "create subscription oldprod connection 'host=replica1 port=5432 user=postgres password=secret dbname=dbname' publication dbname with (enabled = false, create_slot = false, copy_data = false, slot_name='repl');"
8. Saame oid tellimuse:
psql -h replica2 -d dbname -c "select oid, * from pg_subscription;"
9. Oletame, et oleme saanud oid=1000. Rakendame tehingu numbri tellimusele:
psql -h replica2 -d dbname -c "select pg_replication_origin_advance('pg_1000', 'AA/AAAAAAAA');"
10. Käivitame replikeerimise:
psql -h replica2 -d dbname -c "alter subscription oldprod enable;"
11. Kontrollime tellimuse olekut, replikeerimine peab töötama:
psql -h replica2 -d dbname -c "select * from pg_replication_origin_status;"
psql -h master -d dbname -c "select slot_name, restart_lsn, confirmed_flush_lsn from pg_replication_slots;"
12. Pärast replikeerimise käivitamist ja andmebaaside sünkroniseerimist saab teostada vahetuse.
13. Pärast replikeerimise katkestamist on vaja parandada järjestused. Selle kohta on hea ülevaade .
Tänu sellisele plaanile läks vahetus läbi võimalikult väikeste viivitustega.
Kokkuvõte
Kubernetes'i operaatorid lihtsustavad erinevaid toiminguid, muutes need K8s-resursside loomiseks. Kuid pärast hämmastava automatiseerimise saavutamist tuleks meeles pidada, et see võib tuua kaasa ka mitmeid ootamatuid nüansse, seega valige operaatorid teadlikult.
Vaadates kolme populaarseimat Kubernetes- operaatorit PostgreSQL-ile, otsustasime Zalando projekti kasuks. Sellest hoolimata tuli ületada teatavad raskused, kuid tulemus oli tõeliselt rõõmustav, seega plaanime seda kogemust laiendada ka mõnedele muudele PgSQL-installeerimistele. Kui teil on kogemusi sarnaste lahendustega, oleksime tänulikud, kui jagaksite üksikasju kommentaarides!
P.S.
Lugege ka meie blogist:
- «»;
- «»;
- «».
Allikas: habr.com
