

Märk. tõlge.: See artikkel, mille autor on Galo Navarro, kes töötab peamise tarkvarainsenerina Euroopa ettevõttes Adevinta, on põnev ja õpetlik "uurimus" infrastruktuuri kasutamise valdkonnas. Originaaltitlit on tõlkes veidi muudetud, nagu autor selgitab artikli alguses.
Autorilt märkus: Tundub, et see avaldus palju rohkem tähelepanu kui oodatud. Ma saan siiani vihaseid kommentaare selle kohta, et artikli pealkiri on eksitav ja et mõned lugejad on kurvad. Ma mõistan juhtunust tingitud põhjuseid, seetõttu tahan, vaatamata riskile kogu intriig loomata, kohe rääkida, millest see artikkel räägib. Kui meeskonnad üleviivad Kubernetes'esse, jälgin ma huvitavat asja: iga kord, kui tekib probleem (nt viivituste suurenemine pärast migreerimist), süüdistatakse kohe Kubernetes't, kuid hiljem selgub, et orkestreerija ei ole üldiselt süüdi. See artikkel käsitleb ühte sellist juhtumit. Selle pealkiri kordab ühte meie arendajate hüüdu (hiljem näete, et Kubernetes ei ole siin absoluutselt süüdi). Te ei leia sealt ootamatuid äratundmisi Kubernetes'est, kuid võite oodata paar head õppimist keeruliste süsteemide kohta.
Paari nädala eest töötas minu tiim ühe mikroteenuse migratsiooniga peamine platvorm, mis sisaldab CI/CD-d, Kubernetes-põhist töökeskkonda, mõõdikuid ja muid kasulikke omadusi. Kolimine oli katseperioodil: plaanisime seda kasutada aluseks ja viia lähikuudel üle veel umbes 150 teenust. Kõik need teenused vastutavad mõnede suurimate veebiplatvormide, nagu Infojobs, Fotocasa ja teised, toimimise eest.
Pärast seda, kui rakendus Kubernetesis käivitati ja liiklus sellele suunati, ootas meid murettekitav üllatus. Kuberentes olevate päringute viivitus oli 10 korda kõrgem kui EC2-s. (latency) Kokkuvõttes oli vajalik kas selle probleemi lahenduse leidmine või mikroteenuse migratsioonist loobumine (või võimalusel kogu projekti lõpetamine).
Miks on Kubernetesis viivitus nii palju kõrgem kui EC2-s?
Selle kitsaskoha leidmiseks kogusime mõõdikud kogu päringu teele. Meie arhitektuur on lihtne: API-läbisõitja (Zuul) edastab päringud mikroteenuse eksemplaridele EC2-s või Kubernetesis. Kubernetesis kasutame NGINX Ingress Controllereid ja tagaplaanid on tavalised objektid, millel on JVM-rakendus Springi platvormil.
EC2
+---------------+
| +---------+ |
| | | |
+-------> BACKEND | |
| | | | |
| | +---------+ |
| +---------------+
+------+ |
Public | | |
-------> ZUUL +--+
traffic | | | Kubernetes
+------+ | +-----------------------------+
| | +-------+ +---------+ |
| | | | xx | | |
+-------> NGINX +------> BACKEND | |
| | | xx | | |
| +-------+ +---------+ |
+-----------------------------+Tundus, et probleem oli seotud algfaasi viivitusega backendis (märgin kahtlase koha joonisel kui "xx"). EC2-s võttis rakenduse vastus umbes 20 ms. Kuberneteses suurenes viivitus 100–200 ms-ni.
Küsimuse sealt mitte õnnestunud kahtlusaluste hulgast välistasime kiiresti, mis olid seotud keskkonna muutumisega. JVM-i versioon jäi muutumatuks. Ka konteineriseerimise probleemid ei olnud asjaosalised: rakendus toimis juba EC2-s konteinerites edukalt. Koormus? Kuid isegi 1 päringu sekundis puhul oli meil märkimisväärsed viivitused. Prügikoristuspausidega oli samuti võimalik kõrvale hiilida.
Üks meie Kubernetes'i administraatoritest küsis, kas rakendusel on väliseid sõltuvusi, kuna minevikus on DNS-i päringud põhjustanud sarnaseid probleeme.
Hüpotees 1: DNS-i nimede lahendamine
Iga päringu korral pöördub meie rakendus AWS Elasticsearch'i eksemplari poole kuni kolm korda domeenis, mis näeb välja nagu elastic.spain.adevinta.com. Konteinerite sees on meil , seega saame kontrollida, kas domeeni otsingu ajal tõepoolest kulub palju aega.
DNS-i päringud konteinerist:
[root@be-851c76f696-alf8z \]# while true; do dig "elastic.spain.adevinta.com" | grep time; sleep 2; done
;; Küsi aeg: 22 msec
;; Küsi aeg: 22 msec
;; Küsi aeg: 29 msec
;; Küsi aeg: 21 msec
;; Küsi aeg: 28 msec
;; Küsi aeg: 43 msec
;; Küsi aeg: 39 msecSarnased päringud ühest EC2 eksemplarist, kus rakendus töötab:
bash-4.4# while true; do dig "elastic.spain.adevinta.com" | grep time; sleep 2; done
;; Küsi aeg: 77 msec
;; Küsi aeg: 0 msec
;; Küsi aeg: 0 msec
;; Küsi aeg: 0 msec
;; Küsi aeg: 0 msecArvestades, et otsing võtab aega umbes 30 ms, sai selgeks, et DNS-i lahendus Elasticsearch'iga suhtlemisel tõepoolest panustab latentsuse suurenemisse.
Kuid see oli kummaline kahel põhjusel:
- Meil on juba palju rakendusi Kuberneteses, mis suhtlevad AWSi ressurssidega, kuid ei kannata suure latentsuse all. Mis iganes põhjus see ka poleks, on see konkreetselt seotud antud juhtumiga.
- Teame, et JVM teostab DNS-i in-memory vahemälu. Meie piltides on TTL väärtus määratud
$JAVA_HOME/jre/lib/security/java.securityja see on seatud 10 sekundiks:networkaddress.cache.ttl = 10. Teisisõnu, JVM peab vahemälu kõik DNS-i päringud 10 sekundi jooksul.
Esimese hüpoteesi kinnitamiseks otsustasime ajutiselt loobuda DNS-i päringutest ja vaadata, kas probleem kaob. Esmalt otsustasime kohandada rakendust, et see suhtleks Elasticsearchiga otse IP-aadressi kaudu, mitte domeeninime kaudu. See oleks nõudnud koodi muutmist ja uut juurutamist, seega sidusime domeeni selle IP-aadressiga /etc/hosts:
34.55.5.111 elastic.spain.adevinta.comNüüd sai konteiner IP-aadressi peaaegu koheselt. See tõi kaasa teatava paranemise, kuid me lähenesime vaid veidi oodatud latentsuse tasemele. Kuigi DNS-i lahendamine võttis aega, varjas tõeline põhjus endiselt meie nägemise alt.
Diagnostika võrgu abil
Otsustasime analüüsida konteinerist tulevat liiklust tcpdump, et jälgida, mis täpselt toimub võrgus:
[root@be-851c76f696-alf8z /]# tcpdump -leni any -w capture.pcap Seejärel saatsime välja mõned päringud ja allalaadisin nende salvestuse (kubectl cp my-service:/capture.pcap capture.pcap) edasiseks analüüsiks .
DNS-päringutes ei olnud midagi kahtlast (välja arvatud üks väikeste asja, millest räägin hiljem). Kuid meie teenuse käsitlemisel igas päringus ilmnesid teatud kummalised asjad. Allpool on captura ekraanipilt, mis näitab päringu vastuvõtmist enne vastuse algust:
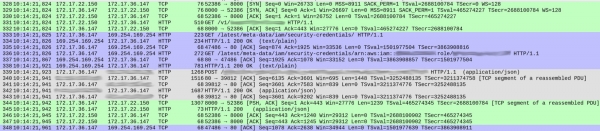
Pakettide numbrid on toodud esimeses veerus. Selguse huvides olen erinevad TCP-vood värvidega eristanud.
Roheline voog, mis algab 328. paketist, näitab, kuidas klient (172.17.22.150) lõi TCP-seose konteineriga (172.17.36.147). Pärast esmast käepigistust (328-330) tõi pakett 331 HTTP GET /v1/.. — sisenemise päring meie teenusele. Kogu protsess võttis aega 1 ms.
Hall voog (paketist 339) näitab, et meie teenus saatis HTTP-päringu Elasticsearchi eksemplarile (TCP-käepigistus puudub, kuna kasutatakse juba olemasolevat ühendust). Selleks kulus 18 ms.
Praegu on kõik korras ja ajad vastavad enam-vähem oodatud viivitustele (20–30 ms kliendi mõõtmiste põhjal).
Kuid sinine sektsioon võtab 86 ms. Mis seal toimub? Paketi 333 korral saatis meie teenus HTTP GET-päringu aadressile /latest/meta-data/iam/security-credentials, ja kohe pärast seda, sama TCP-ühenduse kaudu, veel üks GET-päring aadressile /latest/meta-data/iam/security-credentials/arn:...
Oleme tuvastanud, et see kordub iga päringu puhul kogu jälgimises. DNS-i lahendamine on tõepoolest meie konteinerites veidi aeglasem (selle fenomeni seletus on väga huvitav, kuid ma hoian selle eraldi artikli jaoks). Selgus, et suurte viivituste põhjuseks on AWS Instance Metadata teenusele tehtavad päringud iga päringu puhul.
Hüpotees 2: liigsed päringud AWS-ile
Mõlemad lõpp-punktid kuuluvad . Meie mikroteenus kasutab seda teenust Elasticsearchiga töötamisel. Mõlemad kutsed on osa põhivolituste protsessist. Esimese päringu korral toimub pöördumine lõpp-punkti, mis väljastab instantsiga seotud IAM-rolli.
/ # curl http://169.254.169.254/latest/meta-data/iam/security-credentials/
arn:aws:iam::<account_id>:role/some_roleTeine päring pöördub teise lõpp-punkti poole, et saada ajutisi volitusi antud instantsi jaoks:
/ # curl http://169.254.169.254/latest/meta-data/iam/security-credentials/arn:aws:iam::<account_id>:role/some_role`
{
"Code" : "Success",
"LastUpdated" : "2012-04-26T16:39:16Z",
"Type" : "AWS-HMAC",
"AccessKeyId" : "ASIAIOSFODNN7EXAMPLE",
"SecretAccessKey" : "wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY",
"Token" : "token",
"Expiration" : "2017-05-17T15:09:54Z"
} Kliendil on võimalus neid kasutada lühikese aja jooksul ja ta peab aeg-ajalt saama uusi sertifikaate (kuni nende Aegumine). Mudel on lihtne: AWS korraldab turvakaalutlustel sagedast ajutiste võtmete vahetust, kuid kliendid saavad neid mitu minutit vahemällu talletada, tasakaalustades uute sertifikaatide saamisega seotud jõudluse langust.
AWS Java SDK peab selle protsessi korraldamise endale võtma, kuid mingil põhjusel seda ei juhtu.
Otsides GitHub'i probleemide seast, sattusime probleemile . See aitas meil määratleda suuna, kuhu edasi "kaevata".
AWS SDK värskendab sertifikaate, kui toimub üks järgmistest tingimustest:
- Nende kehtivusaja lõpp (
Aegumine) satubEXPIRATION_THRESHOLD, mis on koodis rangelt seadistatud 15 minutiks. - Olenemata viimasest katsest sertifikaate värskendada, on möödunud rohkem aega kui
REFRESH_THRESHOLD, mis on 'hardcode' vahel 60 minuti jooksul.
Kuna näha sertifikaatide tegelikku kehtivusaega, sooritasime ülaltoodud cURL-käsud konteinerist ja EC2 instantsist. Konteinerist saadud sertifikaadi kehtivusaeg oli palju lühem: täpselt 15 minutit.
Nüüd on kõik selge: esimese päringu puhul sai meie teenus ajutisi sertifikaate. Kuna nende kehtivusaeg ei ületanud 15 minutit, otsustas AWS SDK järgmisel päringul need uuendada. Ja see juhtus iga päringu puhul.
Miks sertifikaatide kehtivusaeg lühenes?
AWS Instance Metadata teenus on mõeldud EC2 instantside jaoks, mitte Kubernetes’ega. Teisest küljest ei tahtnud me rakenduste liidese muutmist. Selleks kasutasime — tööriista, mis kasutab agentide abil igal Kubernetes’i sõlmes võimaldab kasutajatel (inseneridel, kes rakendusi klastris deployivad) määrata IAM-rolle konteineritele pod’ides justkui need oleksid EC2 instantsid. KIAM püüab kinni kutsed AWS Instance Metadata teenusele ja töötleb neid oma vahemälust, saades need eelnevalt AWS-ilt. Rakenduse vaatenurgast ei muutu midagi.
KIAM pakub lühiajalisi sertifikaate pod'idele. See on mõistlik, arvestades, et pod'i keskmine eluiga on lühem kui EC2 instantsi oma. Vaikimisi on sertifikaatide kehtivusaeg .
. Kui need kaks vaikimisi väärtust üksteise peale kanda, tekib probleem. Iga rakendusele antud sertifikaat aegub 15 minuti pärast. Samal ajal sunnib AWS Java SDK igat sertifikaati värskendama, kui selle kehtivusest on jäänud vähem kui 15 minutit.
Seetõttu värskendatakse ajutist sertifikaati iga päringu korral, mis toob kaasa paar API kõnet AWS-ile ja suurendab märkimisväärselt viivitust. AWS Java SDK-s avastasime , kus mainitakse sarnast probleemi.
Lahendus osutus lihtsaks. Lihtsalt seadistasime KIAM-i nii, et see küsib sertifikaate pikema kehtivusajaga. Pärast seda möödusid päringud ilma AWS Metadata teenuse osaluseta ja viivitus langes isegi madalamale tasemele kui EC2-s.
Järeldused
Meie migratsioonikogemuse põhjal on öeldav, et üks sagedasemaid probleemide allikaid ei ole vigu Kuberneteses ega muudes platvormi elementides. Samuti ei ole see seotud mikroteenuste põhjalike puudustega, mida me üle kanname. Probleemid tekivad sageli lihtsalt seetõttu, et ühendame omavahel erinevaid komponente.
Segame kokku keerulisi süsteeme, mis pole kunagi varem omavahel suhelnud, oodates, et koos nad moodustavad ühe suurema süsteemi. Kahjuks, mida rohkem komponente, seda rohkem on ruumi vigade tekkeks ja seda suurem on entropia.
Meie puhul ei olnud kõrge latentsus põhjustatud vigadest ega halbadest lahendustest Kuberneteses, KIAMis, AWS Java SDK-s ega meie mikroteenuses. See tulenes kahest sõltumatust vaikimisi parameetrist: ühest KIAMis, teisest AWS Java SDK-s. Üksikult on mõlemad parameetrid mõistlikud: nii aktiivne sertifikaatide uuendamise poliitika AWS Java SDK-s kui ka lühikese kehtivusajaga sertifikaadid KIAM-is. Kuid kui need kokku panna, muutuvad tulemused ettearvamatuks. Kaks sõltumatut ja loogilist lahendust ei pruugi kokkuvõttes mõistlikud olla.
P.S. tõlkija märkused
AWS IAM integreerimise KIAM utiliidi arhitektuuri kohta saate lähemalt lugeda selle loojatelt.
Ja meie blogist lugege ka:
- «»;
- «»;
- «»;
- «».
Allikas: habr.com
