


2019. aastal ei olnud meil ikka veel standardset lahendust Kuberneteses logide kogumiseks. Selles artiklis tahame jagada oma otsingute tulemusi, kohti, kus kokku puutusime probleemidega, ja nende lahendusi, kasutades tegelikke näiteid.
Kuid kõigepealt tuleb märkida, et erinevad kliendid mõistavad logide kogumist väga erinevalt:
- mõni tahab näha turbe- ja auditilogisid;
- teine soovib kogu infrastruktuuri tsentraliseeritud logimist;
- ja mõnele piisab ainult rakenduse logide kogumisest, jättes välja näiteks tasakaalustajad.
Kuidas me rakendasime erinevaid „soove“ ja millega silmitsi seisisime, — loe edasi.
Teooria: tööriistad logide jaoks
Taust teavitussüsteemi komponentidest
Logimine on läbinud pika tee, mille käigus on välja töötatud logide kogumise ja analüüsi metoodikad, mida me täna rakendame. Juba 1950. aastatel ilmus Fortran'is analoog standardsetest sisend-väljundvoogudest, mis aitasid programmeritel oma programme tõrkeotsingul. Need olid esimesed arvuti logid, mis lihtsustasid selle aja programmerite elu. Tänaseks näeme nendes esimese komponendi logimisüsteemist — logide allikas või "tootja" (producer).
Arvutiteadus ei seisnud paigal: tekkisid arvutivõrgud, esimesed klastrid... Alustati keerukate süsteemide tööd, mis koosnesid mitmest arvutist. Nüüd pidid süsteemiadministraatorid koguma logisid mitmelt masinalt ning erijuhtudel võisid nad lisada ka OS-i tuuma teadete, juhuks kui on vajalik süsteemi rikkumise uurimine. Et kirjeldada tsentraliseeritud logide kogumise süsteeme, ilmus 2000-ndate alguses , mis standardiseerib remote_syslog. Nii tekkis veel üks oluline komponent: logikogujad ja nende ladustamine.
Logide mahu suurenemise ja veebitehnoloogiate laialdase rakendamise tõttu kerkis küsimus, kuidas logisid kasutajatele mugavalt esitada. Lihtsatele käsurea tööriistadele (awk/sed/grep) tuli välja rohkem arenenud logivaatlejad — kolmas komponent.
Logide mahu suurenemise tõttu selgus veel üks asi: logid on vajalikud, kuid mitte kõik. Erinevad logid nõuavad erinevat säilitamise taset: mõned võib kaotada päeva jooksul, teised tuleb aga hoida 5 aastat. Nii lisandus logimisüsteemi komponent voogude andmete filtreerimiseks ja marsruutimiseks — kutsume seda filtriks.
Ahnus on teinud tõsise hüppe: tavalistest failidest oldi liikunud suhetebaasilistele andmebaasidele ja seejärel dokumentidepõhistele salvestustehnoloogiatele (näiteks Elasticsearch). Nii eraldus kollektsioonist salvestus.
Lõppude lõpuks on logi mõisted laienenud mingiks abstraktseks sündmuste vooks, mida soovime ajaloo jaoks salvestada. Täpsemalt — juhul, kui on vaja teha uurimine või koostada analüütiline aruanne...
Lõppkokkuvõttes on suhteliselt lühikese aja jooksul logide kogumine arenenud oluliseks alamsüsteemiks, mida võib õigustatult nimetada üheks Big Data haruks.
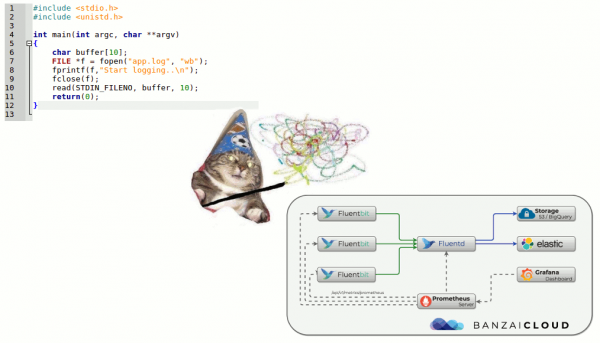
Kui kunagi piisab tavalistest print'idest 'logimisüsteemi' jaoks, siis nüüd on olukord märkimisväärselt muutunud.
Kubernetes ja logid
Kubernetes'i sissetoomisega süvenes probleem logide kogumisel veelgi. Teatud mõttes muutus see isegi valusamaks: infrastruktuuri platvormi haldamine lihtsustati, ent samas ka keerulisemaks. Paljud vanad teenused hakkasid üle minema mikroteenuste iskele. Logide kontekstis väljendus see logi allikate arvu kasvus, nende eripärases elutsüklis ning vajaduses jälgida süsteemi komponentide omavahelisi seoseid logide kaudu...
Võttes arvesse, et hetkel pole kahjuks olemas standardiseeritud logimise varianti Kubernetes'i jaoks, mis eristuks teistest. Kõige populaarsemad kogukonnas skeemid on järgmised:
- keegi loob stack'i EFK (Elasticsearch, Fluentd, Kibana);
- keegi - proovib hiljuti vabastatud või kasutab ;
- meid (võib-olla mitte ainult meid?...) paljuski rahuldab meid enda arendus - …
Tavaliselt kasutame K8s-klastrites selliseid kombinatsioone (self-hosted lahendustele):
- ;
- .
Kuid ma ei kavatse peatuda nende paigaldamise ja konfigureerimise juhistel. Selle asemel keskendun nende puudustele ja üldistele järeldustele logide olukorra kohta.
Logide praktika K8s-is

"Igapäevased logid", kui palju teid on?..
Suure infrastruktuuri tsentraliseeritud logide kogumine nõuab märkimisväärseid ressursse, mis lähevad logide kogumise, säilitamise ja töötlemise peale. Erinevate projektide käigus oleme silmitsi seisnud erinevate nõudmiste ja nende tõttu tekkivate probleemidega.
Proovime ClickHouse'i
Vaadakem tsentraliseeritud ladustamist projektis, mille rakendus genereerib üsna aktiivselt logisid: rohkem kui 5000 rida sekundis. Alustame tööga, kogudes neid ClickHouse'i.
Niipea kui on vaja maksimaalset reaalajas käitlemist, on 4-tuumaline server ClickHouse'iga juba liialdatud diskial süsteemiga:
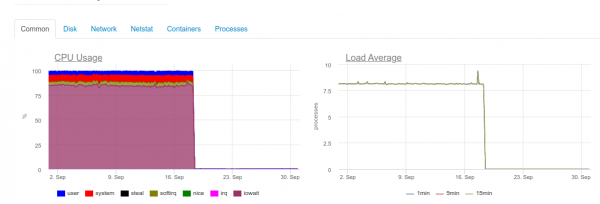
Selline laadimine on seotud sellega, et me üritame kirjutada ClickHouse'i nii kiiresti kui võimalik. Andmebaas reageerib sellele suurenenud ketaskoormusega, mistõttu võib see anda selliseid vigu:
DB::Exception: Liiga palju osi (300). Ühendused töötlevad oluliselt aeglasemalt kui sisendid.
Asi on selles, et ClickHouse'is (kus hoitakse logi andmeid) esinevad kirjutamisel oma raskused. Nendesse sisestatud andmed genereerivad ajutise partitsiooni, mis pärast ühendatakse põhitaabliga. Selle tulemusena on kirjutamine väga ketasnõudlik ja sellele kehtib piirang, mille teavituse saime ülal: mitte rohkem kui 300 sub-partitsiooni (tegelikult 300 insert'i sekundis) võivad valmistuda ühe sekundi jooksul.
Sellise käitumise vältimiseks nii suurte tükkide kaupa kui võimalik ja mitte sagedamini kui 1 kord 2 sekundi jooksul. Ent suurte vahedega kirjutamine eeldab, et peame harvemini kirjutama ClickHouse'i. See omakorda võib põhjustada puhverdamise ületäitumise ja logide kaotuse. Lahendus on suurendada Fluentd puhvrit, kuid siis suureneb ka mälutarve.
Märkus: Teine probleemne aspekt meie lahendusest ClickHouse'ile seondus asjaoluga, et partitsioneering meie puhul (loghouse) on rakendatud väliste tabelite kaudu, mis on seotud . See toob, et suurte ajavahemike valimise korral on vajalik liiga palju mäluruumi, kuna meta tabel käib läbi kõik osakonnad — isegi need, mis kindlasti ei sisalda vajalikke andmeid. Hetkel võib aga sellist lähenemist julgelt pidada aegunuks aktuaalsete ClickHouse versioonide jaoks (c ).
Kokkuvõttes on selge, et ClickHouse’i reaalajas logide kogumiseks ei piisa kaugeltki iga projekti ressurssidest (täpsemalt, nende jaotamine ei ole mõistlik). Samuti tuleb kasutada aku, mille juurde me veel kord tagasi tuleme. Ülaltoodud juhtum on reaalne. Ja sel ajal ei suutnud me pakkuda usaldusväärset ja stabiilset lahendust, mis rahuldaks tellijat ja võimaldaks logisid koguda minimaalse viivitusega…
Aga Elasticsearch?
On teada, et Elasticsearch talub suuri koormusi. Proovime seda samas projektis. Nüüd näeb koormus välja järgmiselt:
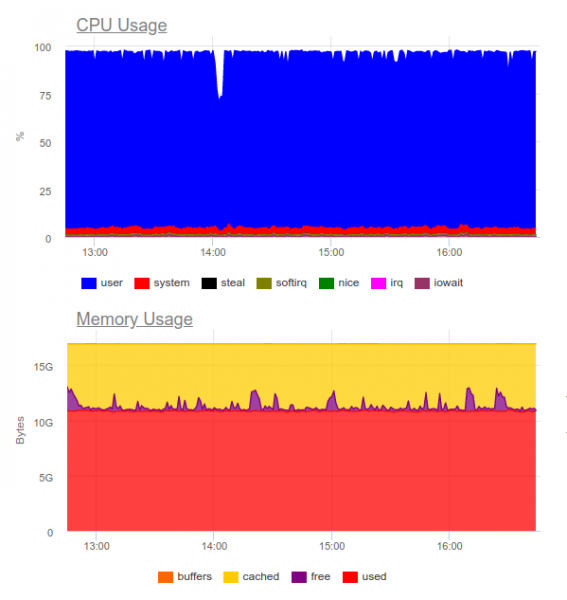
Elasticsearch suudab andmepublishingu voogude töötlemisega hakkama saada, kuid selliste mahtude salvestamine kulutab palju CPU ressursse. Seda nimetatakse klastriks korraldamiseks. Puhtalt tehniliselt ei ole see probleem, kuid juhtub, et logide kogumise süsteemi toimimiseks kasutame juba umbes 8 tuuma ja meil on süsteemis veel üks kõrge koormusega komponent...
Kokkuvõttes: selline variant võib olla põhjendatud, kuid ainult juhul, kui projekt on suur ja selle juhtkond on valmis kulutama märkimisväärseid ressursse tsentraliseeritud logimise süsteemile.
Siis tekib loogiline küsimus:
Millised logid on tõeliselt vajalikud?
 Proovime lähenemist muuta: logid peaksid olema samas informatiivsed ja mitte katma iga süsteemis toimuvat sündmust.
Proovime lähenemist muuta: logid peaksid olema samas informatiivsed ja mitte katma iga süsteemis toimuvat sündmust.
Oletame, et meil on edukaid internetipoode. Millised logid on olulised? Maksimaalse teabe kogumine, näiteks makseportaalist — suurepärane idee. Kuid tooteloendi piltide lõikamise teenusest ei ole kõik logid meie jaoks kriitilised: piisab vaid vigadest ja laiendatud jälgimisest (näiteks 500. vigade protsendi põhjal, mida see komponent genereerib).
Nii oleme jõudnud sinnani, et Keskendatud logimine ei ole alati õigustatud. Très souvent, le client souhaite rassembler tous les journaux au même endroit, alors qu'en réalité, seuls environ 5 % des messages du journal sont critiques pour l'entreprise :
- Mõnikord piisab sellest, kui seadistada näiteks ainult konteineri logi suurus ja viga koguv tööriist (nt Sentry).
- Sündmuste uurimiseks piisab tihti veateatest ja suurest kohalikust logidest.
- Meil on olnud projekte, kus piirduti puhtalt funktsionaalsete testide ja veakogumise süsteemidega. Arendajale ei olnud logid vajalikud — nad nägid kõike veateadete jälgimise kaudu.
Illustratsioon elust
Heaks näiteks võib olla teine lugu. Meile tuli päring ühe kliendi turvameeskonnalt, kellel oli juba kasutusel kommertslahendus, mis oli välja töötatud kaua enne Kubernetes'e rakendamist.
Tuli vajadus „sümbioosida“ tsentraliseeritud logide kogumise süsteemi ettevõtte probleemi avastamise sensoriga — QRadariga. See süsteem suudab vastu võtta logisid syslog protokolli kaudu ja FTP-st üles laadida. Siiski ei õnnestunud selle integreerimine remote_syslog pluginaga fluentd kohe. (kui selgus, ). QRadara seadistamise probleemid tulid kliendi tur teams poolelt.
Kuna tulemusena laaditi osa äri jaoks kriitilisi logisid FTP-le QRadarisse, suunati teine osa otse sõlmedelt remote syslog kaudu. Selleks kirjutatud — võib-olla aitab see kellelgi sarnast ülesannet lahendada... Tänu saadud skeemile sai klient kriitilisi logisid analüüsida (oma lemmiktööriistadega), samal ajal kui suudame vähendada logimise süsteemi kulusid, säilitades vaid viimase kuu.
Veel üks näide on üsna näitlik, kuidas asju ei tohiks teha. Üks meie klientidest töötles peamise domeeni kohta loendis. kasutajalt saabuvaid sündmusi, tehes mitmerealist strukturimata väljundit. logides olevate andmete lugemine ja säilitamine oli äärmiselt ebamugav.
Logide kriteeriumid
Sarnased näited viivad järeldusele, et peale logide kogumise süsteemi valimise tuleb projekti veel ka logid ise! Millised on siinsed nõuded?
- Logid peavad olema masinloetavas formaadis (nt JSON).
- Logid peavad olema kompaktsed ja võimaldama logimise taset muuta, et lahendada võimalikke probleeme. Samas tuleks tootmiskeskkondades käivitada süsteemid logimise tasemega nagu Hoiatus või Error.
- Logid peavad olema normaliseeritud, see tähendab, et logi objekte sisaldavad kõik stringid peavad olema sama tüüpi väljadega.
Struktureerimata logid võivad põhjustada probleeme logide laadimisel salvestusse ja nende töötlemise täieliku seiskumise. Näiteks, 400 vea näide, millega paljud on kindlasti fluentd logides kokku puutunud:
2019-10-29 13:10:43 +0000 [warn]: dump an error event: error_class=Fluent::Plugin::ElasticsearchErrorHandler::ElasticsearchError error="400 - Rejected by Elasticsearch"
Viga tähendab, et saadate indeksi, millel on valmis mapping, välja, mille tüüp on ebastabiilne. Lihtsaim näide on nginx logi väli, kus on muutuja $upstream_status. Seda võib olla kas number või string. Näiteks:
{ "ip": "1.2.3.4", "http_user": "-", "request_id": "17ee8a579e833b5ab9843a0aca10b941", "time": "29/Oct/2019:16:18:57 +0300", "method": "GET", "uri": "/staffs/265.png", "protocol": "HTTP/1.1", "status": "200", "body_size": "906", "referrer": "https://example.com/staff", "user_agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36", "request_time": "0.001", "cache_status": "-", "upstream_response_time": "0.001, 0.007", "upstream_addr": "127.0.0.1:9000", "upstream_status": "200", "upstream_response_length": "906", "location": "staff"}
{ "ip": "1.2.3.4", "http_user": "-", "request_id": "47fe42807f2a7d8d5467511d7d553a1b", "time": "29/Oct/2019:16:18:57 +0300", "method": "GET", "uri": "/staff", "protocol": "HTTP/1.1", "status": "200", "body_size": "2984", "referrer": "-", "user_agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36", "request_time": "0.010", "cache_status": "-", "upstream_response_time": "0.001, 0.007", "upstream_addr": "10.100.0.10:9000, 10.100.0.11:9000", "upstream_status": "404, 200", "upstream_response_length": "0, 2984", "location": "staff"}
Logides on näha, et server 10.100.0.10 vastas 404-iga ja päring suunati teise sisuhoidlasse. Tulemusena muutus logis väärtus selliseks:
"upstream_response_time": "0.001, 0.007"
See olukord on nii levinud, et on saanud eraldi .
Aga kuidas on usaldusväärsusega?
On juhtumeid, kus kõik logid on hädavajalikud ilma eranditeta. Tüüpilistel K8s logide kogumise skeemidel, nagu ülalpool arutatud, on sellega siiski probleeme.
Näiteks ei saa fluentd koguda logisid lühiajalistest konteineritest. Ühes meie projektis elas andmebaasi migratsiooniga konteiner vähem kui 4 sekundit ning kustutati seejärel — vastavalt vastavale annotatsioonile:
"helm.sh/hook-delete-policy": hook-succeeded
Selle tõttu ei jõudnud migratsiooni täitmise logi hoidlasse. Antud juhul võib aidata before-hook-creation poliitika.
Teine näide on Dockeri logide rotatsioon. Oletame, et on rakendus, mis kirjutab aktiivselt logidesse. Tavalistes tingimustes suudame kõik logid õigel ajal töödelda, kuid kui probleem tekkib — näiteks nagu ülalpool kirjeldatud vale formaadi tõttu — peatused töötlemine ja Docker rotatsioonib faili. Tulemuseks on see, et kriitilised logid võivad kaduda.
Just seetõttu Oluline on eristada logivoo, integreerides kõige väärtuslikumate edastamise otse rakendusse, et tagada nende säilimine. Samuti ei tee paha luua mingisugust „logide akumulaatorit“, mis suudab üleelada lühiajalise salvestusruumi kadu, säilitades samas kriitilised sõnumid.
Lõpuks ärge unustage, et iga alam süsteemi on oluline kvaliteetselt monitoorida. Vastasel juhul on lihtne sattuda olukorda, kus fluentd on seisundis CrashLoopBackOff ja ei edasta midagi, mis võib tähendada olulise teabe kaotamist.
Järeldused
Käesolevas artiklis ei käsitle me SaaS-lahendusi nagu Datadog. Palju sellest töötlusest on juba lahendatud kaubanduslike ettevõtete poolt, mis on spetsialiseerunud logide kogumisele, kuid mitte kõik ei saa erinevatel põhjustel SaaS-i kasutada. (peamised — need on 152-FZ täitmine ja maksumus).
Keskne logide kogumine näib esialgu lihtsa ülesandena, kuid see pole sugugi nii. Oluline on meeles pidada, et:
- Detailne logimine on vajalik vaid kriitiliste komponentide jaoks, samas kui teiste süsteemide jaoks saab seadistada jälgimise ja vigade kogumise.
- Productions logid peaksid olema võimalikult minimaalsed, et vältida liigset koormust.
- Logid peavad olema masinloetavad, normaliseeritud ja järgima ranget formaati.
- Tõeliselt kriitilised logid tuleks edastada eraldi voos, mis on eraldatud peamistest.
- Oluline on planeerida logide akumulaator, mis võib päästa kõrge koormuse puhangute eest ja tasandada salvestust koormust.

Need lihtsad reeglid, kui neid rakendada igal pool, võimaldaksid töötada ja ülaltoodud skeemide kaudu — isegi hoolimata sellest, et neil puuduvad olulised komponendid (akumulaator). Kui aga neid põhimõtteid ei järgita, võib ülesanne viia teid ja infrastruktuuri veel ühe kõrge koormusega (ja samas madala efektiivsusega) süsteemi komponendini.
P.S.
Lugege ka meie blogist:
- «»;
- «»;
- «».
Allikas: habr.com
