

Sisu põhine andmete klassifikatsioon on avatud probleem. Traditsioonilised andmete kaotsimineku ennetamise süsteemid (DLP) lahendavad selle probleemi, võttes sobivatest andmetest sõrmejälgi ja jälgides lõpp-punkte sõrmejälgede võtmise jaoks. Arvestades Facebookis pidevalt muutuvate andmeallikate suurt hulka, ei ole see lähenemine mitte ainult mastaapimatu, vaid ka ebaefektiivne, et tuvastada, kus andmed asuvad. Käesolev artikkel käsitleb lõpp-to-lõpp süsteemi, mis on loodud tundlike semantiliste tüüpide tuvastamiseks Facebookis mastaabis ning automaatseks andmete salvestamise ja juurdepääsu kontrollimise tagamiseks.
Siin kirjeldatud lähenemine on meie esimene integreeritud privaatsussüsteem, mis püüab lahendada seda probleemi, integreerides andmesignaalid, masinõppe ja traditsioonilised sõrmejälgede eemaldamise meetodid, et kuvada ja klassifitseerida kõiki andmeid Facebookis. Kirjeldatud süsteem töötas tootmiskeskkonnas, saavutades mitmesugustes privaatsusklassides keskmise F2 skoori 0,9+ suure andmeressursside mahuga, millel on kümneid ladustamisruume. Tutvustame Facebooki postituse tõlget ArXiv'is, kus käsitletakse andmete skaleeritavat klassifitseerimist masinõppe alusel turvalisuse ja privaatsuse tagamiseks.
Sissejuhatus
Tänapäeval koguvad ja säilitavad organisatsioonid suurtes kogustes andmeid erinevates formaatides ja kohtades [1], seejärel tarbitakse andmeid paljudes kohtades, mõnikord kopeeritakse või vahemällu salvestatakse mitu korda, mille tulemuseks on see, et väärtuslik ja konfidentsiaalne äriteave hajub paljudesse ettevõtte andmehoidlatesse. Kui organisatsioon peab täitma teatud juriidilisi või regulatiivseid nõudeid, näiteks järgima seadusi tsiviilkohtumenetluse raames, tekib vajadus andmete kogumiseks vajalike andmete asukohast. Kui konfidentsiaalsusmääruses öeldakse, et organisatsioon peab maskeerima kõik sotsiaalkindlustuse numbrid (SSN), edastades isiklikku teavet volitamata isikutele, on loomulik esimene samm leida kõik SSN organisatsiooni andmehoidlatest. Sellistes oludes muutub andmete klassifitseerimine äärmiselt tähtsaks [1]. Klassifiseerimissüsteem võimaldab organisatsioonidel automaatselt tagada konfidentsiaalsuse ja turvapoliitika järgimise, näiteks juurdepääsuhalduse ja andmete säilitamise poliitika rakendamise. Facebook esitleb süsteemi, mille me ehitasime Facebookis, mis kasutab mitmeid andmesignaale, skaleeritavat süsteemi arhitektuuri ja masinõpet tundlike semantiliste andmetüüpide tuvastamiseks.
Andmete tuvastamine ja klassifitseerimine tähendab nende leidmist ja märgistamist viisil, millega sobivat teavet saab vajadusel kiiresti ja tõhusalt eraldada. Praegune protsess on enamasti käsitsi ja hõlmab asjakohaste seaduste või regulatsioonide uurimist, tundlike teabe liikide määratlemist ja erinevate tundlikkuse tasemete määramist, millele järgneb klasside ja klassifitseerimise poliitika vastav koostamine [1]. Andmete kaotsimineku kaitse (DLP) süsteemid võtavad andmetest jäljed ja jälgivad allavoolu lõpp-punkte jälgede saamiseks. Suurte varade ja petabaitide andmemahtude korral selline lähenemine lihtsalt ei skaaleeru.
Meie eesmärk on luua andmeklassifitseerimise süsteem, mis on skaleeritav nii stabiilsete kui ka ebastabiilsete kasutajate andmete jaoks, ilma et oleks täiendavaid piiranguid andmete tüübi või formaadi osas. See on julge eesmärk ja loomulikult kaasneb sellega väljakutseid. Mõni andmekirje võib ulatuda tuhandete märkideni.
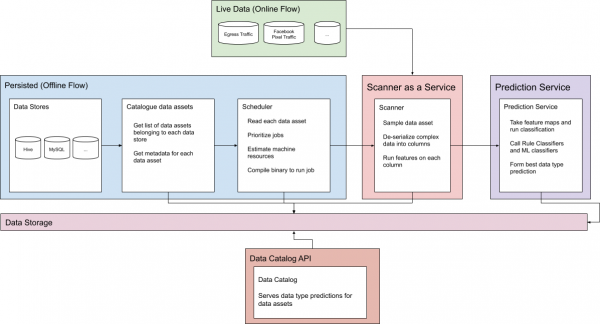
Joon 1. Veebipõhine ja offline prognoosimise voog
Seetõttu peame seda efektiivselt esitama, kasutades ühiseid tunnuseid, mida saab hiljem liita ja hõlpsasti liigutada. Need tunnused peavad tagama mitte ainult täpse klassifikatsiooni, vaid ka paindlikkuse ja laiendatavuse, et uute andmetüüpide lihtne lisamine ja avastamine tulevikus oleks võimalik. Teiseks peame tegelema suurte iseseisvate tabelitega. Püsivad andmed võivad olla salvestatud tabelites, mille suurus ulatub mitme petabaidini. See võib põhjustada skaneerimise kiirusel vähenemist. Kolmandaks peame järgima ranget SLA klassifikatsiooni ebausaldusväärsete andmete osas. See sunnib süsteemi olema kõrge jõudlusega, kiire ja täpne. Lõpuks peame tagama madala latentsusega andmete klassifikatsiooni ebausaldusväärsete andmete jaoks, et reaalajas klassifitseerimine oleks võimalik, samuti interneti kasutamise juhtumite jaoks.
Selles artiklis käsitletakse, kuidas me lahendasime eelnevaid probleeme, ning tutvustatakse kiiret ja skaleeritavat klassifitseerimissüsteemi, mis klassifitseerib andmeelemente igasugustest tüüpidest, formaatidest ja allikatest vastavalt ühisele tunnuste kogumile. Oleme laiendanud süsteemiarhitektuuri ja loonud spetsiaalse masinõppe mudeli andmete kiireks klassifitseerimiseks nii offline kui online. Artikkel on organiseeritud järgmiselt: jaotises 2 esitatakse süsteemi üldine disain. Jaotises 3 arutatakse masinõppesüsteemi komponente. Jaotistes 4 ja 5 räägitakse seotud tööst ning joonistatakse tulevikusuundi.
Arhitektuur
Et lahendada püsivate ja online-andmete probleemid Facebooki mastaabis, sisaldab klassifitseerimissüsteem kahte eraldi voogu, millest arutame üksikasjalikult.
Püsivad andmed
Esialgu peab süsteem saama teadlikuks erinevatest Facebooki teabest. Iga andmelao kohta kogutakse mõned põhiteated, nagu andmekeskus, kus andmed asuvad, süsteem, milles need andmed on, ja varad, mis asuvad konkreetses andmehoidlas. See loob metaandmekatalooge, mis võimaldab süsteemil tõhusalt andmeid извлечь ilma klientide ja teiste inseneride kasutatavate ressursside ülekoormamiseta.
See metaandmekataloog tagab usaldusväärse allika kõigi skannitud varade jaoks ja võimaldab jälgida erinevate varade olekut. Selle teabe abil määratakse planeerimise prioriteet kogutud andmete ja süsteemi siseteabe, näiteks viimase edukalt skannitud vara skaneerimise aja ja selle loomise aja ning eelmised mälunõuded ja protsessorinõuded, kui see vara on varem skannitud. Seejärel käivitatakse igale andmevara jaoks ülesanne, et tegelikult skannida vara, kui ressursid muutuvad saadaval.
Iga ülesanne on kompileeritud binaarfail, mis viib läbi Bernoulli valiku viimasest kergesti kättesaadavast andmest iga vara jaoks. Vara jagatakse eraldi veergudeks, kus iga veeru klassifitseerimise tulemus töödeldakse iseseisvalt. Lisaks skannib süsteem veergude sees olevaid igasuguseid sisendandmeid. JSON, massiivid, kodeeritud struktuurid, URL-id, base64-sorvitud andmed ja palju muud — kõik see skannitakse. See võib oluliselt pikendada skaneerimise aega, kuna üks tabel võib sisaldada tuhandeid pesakolonne suures binaarses objektis. json.
Iga andmematerjali valitud rea puhul ekstraheerib klassifitseerimissüsteem sisaldusest hõljuvad ja tekstilised objektid, sidudes iga objekti tagasi selle veeruga, kust see võeti. Objektide ekstraheerimise etapi tulemus on kaart kõigist objektidest igas leitud andmematerjali veerus.
Milleks on vajalikud omadused?
Mõistete määratlemine on võtmeelement. Selle asemel, et edastada omadusi float ja text, saame edastada tooreid stringinäidiseid, mis on otseselt iga andmeallikast välja võetud. Lisaks võivad masinõppe mudelid õppida otse igast valimist, mitte sadade omaduste kalkulatsioonide põhjal, mis püüavad valimit lähedale tuua. Sellel on mitu põhjust:
- Privaatsus on esikohal: kõige olulisem on see, et mõiste määratlemine võimaldab meil mälus hoida ainult neid näidiseid, mida me ekstraheerime. See tagab, et hoiame näidiseid vaid ühe eesmärgi jaoks ja ei logi neid oma jõupingutustega kunagi. See on eriti oluline ebastabiilsete andmete puhul, kuna teenus peab toetama mingit klassifitseerimise seisundit enne prognosteeringute pakkumist.
- Mälu: mõned proovid võivad olla pikkusega tuhanded tähemärgid. Selliste andmete salvestamine ja edastamine süsteemi osadele ilma vajaduseta tarbib palju lisabaite. Aja jooksul võivad kaks tegurit kokku liituda, arvestades, et andmeallikaid on palju ja nendel on tuhandeid veerge.
- Omaduste kogumine: omaduste kaudu esitatakse skannimiste tulemused selgelt, mis võimaldab süsteemil mugavalt ühendama sama andmeallika eelnevate skannimiste tulemusi. See võib olla kasulik, et koguda sama andmeallika skannimise tulemusi mitmete käivituste jooksul.
Seejärel saadetakse omadused prognoosimise teenusele, kus me kasutame reeglite põhist klassifitseerimist ja masinõpet iga veeru andmete siltide prognoosimiseks. Teenus tugineb nii reeglite klassifikaatoritele kui ka masinõppele, valides iga prognoosimise objekti poolt antud parima prognoosi.
Reeglite klassifikaatorid on käsitsi heuristika, mis kasutab arvutusi ja koefitsiente objekti normaliseerimiseks vahemikus 0 kuni 100. Kui selline algne punkt genereeritakse iga andmetüübi ja sellele andmetüübile seotud veeru nime jaoks, mis ei kuulu ühtegi "keelatud nimekirja", valib reeglite klassifikaator kõige kõrgema normaliseeritud punkti kõigi andmetüüpide seas.
Klassifitseerimise keerukuse tõttu toob ainult käsitsi heuristiku kasutamine kaasa madala klassifitseerimise täpsuse, eriti struktuurita andmete puhul. Selle tõttu oleme välja töötanud masinõppe süsteemi, et tegeleda struktuurita andmete klassifitseerimisega, nagu kasutajate sisu ja aadress. Masinõpe on võimaldanud liikuda eemale käsitsi heuristikast ja rakendada täiendavaid andmesignaale (näiteks veergude nimed, andmete allikad), mis tõstab oluliselt tuvastamise täpsust. Me uurime masinõppe arhitektuuri süvitsi hiljem.
Prognoosimisteenus salvestab kõigi veergude tulemused koos metaandmete, mis puudutavad skaneerimise aega ja olekut. Kõik need, kes sõltuvad nendest andmetest, saavad neid lugeda igapäevaselt avaldatavast andmehulgast. See kogum koondab kõigi nende skaneerimise ülesannete tulemusi või reaalajas andmekatalooge API. Avaldatud prognoosid on põhi automaatse privaatsuspoliitika ja turvalisuse rakendamise jaoks.
Lõpuks, pärast seda, kui prognoositeenus on kõik andmed salvestanud ja kõik prognoosid on salvestatud, saab meie andmekatalooge API tagastada kõik andmetaustade prognoosid reaalses ajas. Igal päeval avaldab süsteem andmestiku, mis sisaldab kõiki viimaseid prognoose iga varade kohta.
Ebastabiilsed andmed
Kuigi ülaltoodud protsess on loodud salvestatud varade jaoks, loetakse salvestamata liiklus samuti organisatsiooni andmete osaks ja see võib olla oluline. Seetõttu pakub süsteem reaalajas klassifitseerimise prognooside genereerimiseks online-API-d igasuguse ebastabiilse liikluse jaoks. Reaalaja prognoosimise süsteemi kasutatakse laialdaselt väljamineva ja sissetuleva liikluse klassifitseerimiseks masinõppe mudelites ja reklaamija andmetes.
Siin API võtab vastu kaks peamist argumenti: grupeerimise võti ja toores andmestik, mida tuleb prognoosida. Teenus täidab sama objekti ekstraheerimise, nagu eespool kirjeldatud, ja grupeerib objektid koos sama võtmega. Need omadused säilitatakse ka salvestatavas vahemälus taastamiseks tõrke korral. Iga grupeerimisvõti tagab, et enne prognoosimisteenuse kutsumist on teenus näinud piisavalt proove vastavalt eespool kirjeldatud protsessile.
Optimeerimine
Mõnede salvestiste skaneerimiseks kasutame kuumi salvestuskohti lugemise optimeerimise raamatukogusid ja meetodeid [2] ning tagame, et teiste kasutajate juurdepääs samale salvestusele ei põhjusta tõrkeid.
Äärmiselt suurte tabelite (50+ petabaiti) puhul, hoolimata kõikidest optimeerimisest ja mälu efektiivsusest, töötab süsteem skannimise ja arvutamise nimel kõike, enne kui mälu saab otsa. Lõppkokkuvõttes arvutatakse skannimine täielikult mällu ja ei salvestata skannimise ajal. Kui suured tabelid sisaldavad tuhandeid veerge kahemõtteliste andmekogumitega, võib ülesanne ebaõnnestuda mäluressursside puudumise tõttu, kui prognoositakse kogu tabeli jaoks. See viib katvuse vähenemiseni. Selle vastu võitlemiseks oleme optimeerinud süsteemi, et kasutada skannimiskiirust vahendajana, et näha, kui hästi süsteem suudab praeguse koormusega toime tulla. Kasutame kiirusest prognoosimehhanismi, et tuvastada mäluprobleeme ja ennetavat objektiinventuuri arvutamist. Selle käigus kasutame vähem andmeid kui tavaliselt.
Andmesignaalid
Klassifitseerimissüsteem on hea nii kaugele, kui head on andmesignaalid. Siin vaatleme kõiki signaale, mida klassifitseerimissüsteem kasutab.
- Sisu põhjal: kõigepealt ja kõige tähtsam on sisu. Iga andmevara jaoks, mille me skanneerime ja millelt me funktsioone ekstrakteerime, toimub Bernoulli valimine. Paljusid funktsioone määravad andmete sisu. Võib esineda arvukalt ujuvaid objekte, mis esindavad arvutusi, kui sageli on kindlat tüüpi mustreid täheldatud. Näiteks võivad meil olla loendiaugud saadud e-kirjade arvu kohta valimis või näitad, mitu emotikoni on valimis märgatud. Need funktsioonide arvutused saab normaliseerida ja aggregaatida erinevate skaneerimiste kohaselt.
- Andmete päritolu: oluline signaal, mis võib aidata, kui sisu on muutunud vanemast tabelist. Levinud näide on räsitud andmed. Kui andmed alamtabelis räsitakse, tulenevad nad tihti vanemast tabelist, kus nad jäävad avatud kujul. Andmete päritolu aitab klassifitseerida teatud tüüpi andmeid, kui need pole selgelt loetavad või on muudetud ülemise tabeli kaudu.
- Annotatsioonid: veel üks kvaliteetne signaal, mis aitab tuvastada struktureerimata andmeid. Tegelikult saavad annotatsioonid ja päritoluteave koos töötada, et jagada atribuute erinevate andmevarade vahel. Annotatsioonid aitavad tuvastada struktureerimata andmete allika, samas kui päritoluteave võib aidata neil andmetel voolata läbi salvesti.
- Andmeinteraktsioon on meetod, kus tuntud allikatesse viiakse teadlikult sisse erilised, loetamatud sümbolid tuntud andmetüüpidega. Seejärel, iga kord, kui skaneerime sisu sama loetamatut sümbolite jada, saab järeldada, et sisu pärineb sellest tuntud andmetüübist. See on veel üks kvaliteetne andmesignaal, sarnane annotatsioonidele. Erinevus on see, et sisule põhinev tuvastamine aitab avastada sisestatud andmeid.
Mõõdikute mõõtmine
Oluline komponent – ranget meetodoloogiat mõõdikute mõõtmiseks. Peamised mõõdikud klassifitseerimise täiustamise iteratsioonis on iga märke täpsus ja tagasiside, kusjuures F2 hindamine on kõige olulisem.
Nende näitajate arvutamiseks on vajalik sõltumatu andmete märgistamise metoodika, mis ei sõltu süsteemist endast, kuid mida saab kasutada otse selle võrdlemiseks. Allpool kirjeldame, kuidas me kogume Facebookist põhilist tõde ja kasutame seda oma klassifitseerimissüsteemi koolitamiseks.
Usaldusväärsete andmete kogumine
Kogume usaldusväärseid andmeid igast allikast, mis on loetletud allpool, oma tabelisse. Iga tabel vastutab selle konkreetse allika viimaste vaadatavate väärtuste kogumise eest. Igal allikal on andmekvaliteedi kontroll, et tagada, et vaadatavad väärtused on kõrge kvaliteediga ja sisaldavad uusimaid andmetüüpide silte.
- Logimise platvormi konfiguratsioonid: mesila tabelites täidetakse teatud väljad andmetega, mis kuuluvad kindlasse tüüpi. Nende andmete kasutamine ja levitamine on usaldusväärsete andmete kindel allikas.
- Käsitsi märgistamine: süsteemi toetavad arendajad ja välist märgistajad on koolitatud veergude märgistamiseks. See töötab tavaliselt hästi kõigi andmete tüüpide puhul salvestuses ning võib olla teatud struktureerimata andmete, nagu sõnumite või kasutajasisu andmete, usaldusväärsuse peamine allikas.
- Vanematel tabelitel olevad veerud võivad olla märgistatud või annotatsioonidega nagu teatud andmeid sisaldavad, ja me saame neid andmeid jälgida alluvates tabelites.
- Täidesaatvate voogude valimine: Facebooki täidesaatvad vood kannavad teatud tüüpi andmeid. Kasutades meie skannerit teenuse arhitektuurina, saame valida vooge, millel on tuntud andmetüübid, ja saata need süsteemi. Süsteem lubab mitte neid andmeid salvestada.
- Valikulaud: suured mesitarude tabelid, mis on tuntud selle poolest, et need sisaldavad kogu andmehulka, saab kasutada ka treeningandmetena ja edastada skanneri kaudu teenusena. Need sobivad ideaalselt tabelitele, kus on täielik andmetüüpide valik, nii et veeru juhuslik valimine on võrreldav kogu selle andmetüübi kogumi valimisega.
- Sünteetilised andmed: saame kasutada isegi teeke, mis genereerivad andmeid reaalajas. See töötab hästi lihtsate, avalike andmetüüpide, näiteks aadressi või GPS-i jaoks.
- Andmete hooldajad: privaatsusprogrammid kasutavad tavaliselt andmete hooldajaid poliitikate käsitsi kinnitamiseks andmete osadele. See teenib väga täpset usaldusväärsuse allikat.
Kogume kõik olulised usaldusväärsete andmeallikate allikad ühte kogusse, kus kõik need andmed on. Usaldusväärsuse suurim probleem on veenduda, et see on esinduslik andmehoidlas. Vastasel juhul võivad klassifitseerimismootorid ülepakkuda. Selle vastu võitlemiseks kasutatakse kõik ülaltoodud allikad, et tagada tasakaal mudelite koolitamisel või mõõdikute arvutamisel. Lisaks valivad inimkoodijad erinevaid veerge andmehoidlast ja märgistavad andmed vastavalt, et tõhusate väärtuste kogumine jääks objektiivseks.
Jätkuv integreerimine
Kiire iteratsiooni ja täiustamise tagamiseks on oluline alati mõõta süsteemi jõudlust reaalajas. Saame mõõta iga klassifitseerimise täiustamist võrreldes tänase süsteemiga, et suunata taktikaline lähenemine edasistele täiustustele. Siin vaatame, kuidas süsteem lõpetab tagasiside tsükli, mida toetavad usaldusväärsed andmed.
Kui planeerimissüsteem seisab silmitsi varaga, millel on usaldusväärsest allikast saadud sildid, plaanime kaks ülesannet. Esimene kasutab meie tootmisst scanner'i ja seega meie tootmisvõimekust. Teine ülesanne kasutab viimase koostamise scanner'it koos uusimate tunnustega. Iga ülesanne kirjutab oma väljundi oma tabelisse, märkides versioonid koos klassifitseerimise tulemustega.
Nii võrreldame väljalaskekandidaadi ja tootemudeli klassifitseerimise tulemusi reaalajas.
Samal ajal, kui andmekogud võrreldavad RC ja PROD tunnuseid, registreeritakse mitmeid variatsioone ML klassifitseerimisengine'i teenusest prognoosimiseks. Kõige viimane valminud masinõppe mudel, praegune tootemudel ja kõik katsetavad mudelid. Sama lähenemine võimaldab meil "lõigata" erinevaid mudelite versioone (meie reeglite klassifitseerijate agnostik) ja võrrelda näitajaid reaalajas. Nii on lihtne määrata, millal ML katse on valmis tootmisse rakendamiseks.
Igal öösel saadetakse selle päeva RC-märgid ML-õppimise konveieri juurde, kus mudel õpib viimaste RC-märkide põhjal ja hindab oma tulemuslikkust usaldusväärse andmekogumi suhtes.
Igal hommikul lõpetab mudel õppimise ja avaldatakse automaatselt katsetamisena. See lisatakse automaatselt katsetamisloendisse.
Mõned tulemused
Tuvastatakse üle 100 erineva andmetüübi kõrge täpsusega. Hästi struktureeritud tüübid, nagu e-post ja telefoninumbrid, klassifitseeritakse f2 hindega üle 0,95. Vaba andmetüüp, nagu kasutajasisu ja nimi, töötab samuti väga hästi, f2 hindega üle 0,85.
Igal päeval klassifitseeritakse suur hulk individuaalseid stabiilsete ja ebastabiilsete andmete veerge kõigis andmehoidlates. Igal päeval skannitakse rohkem kui 500 terabaiti rohkem kui 10 andmehoidis. Enamikus hoidlates on katvus üle 98%.
Aja jooksul on klassifitseerimine muutunud väga tõhusaks, kuna klassifitseerimise ülesannete täitmine salvestatud autonoomses voos võtab keskmiselt 35 sekundit skaneeritud objekti prognooside arvutamiseni iga veeru jaoks.
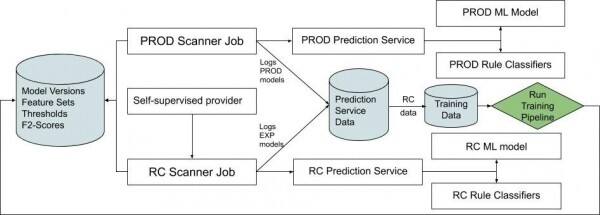
Joonis 2. Diagramm, mis kirjeldab pidevat integreerimisvoogu, et mõista, kuidas RC-objektid genereeritakse ja saadetakse mudelisse.
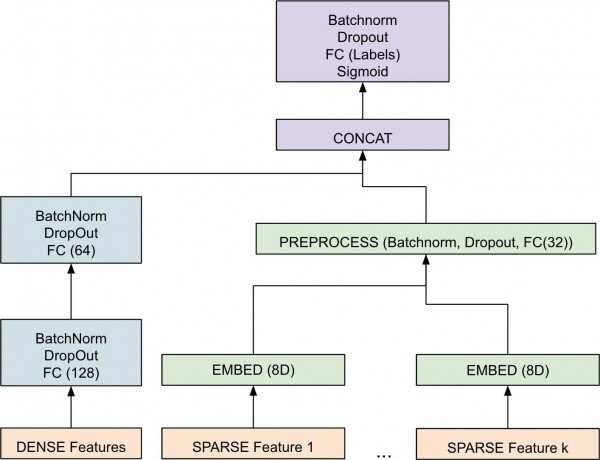
Joonis 3. Ülevaatlik diagramm masinõppe komponendist.
Masinõppe süsteemi komponent.
Eelmises jaotises viisime süvitsi kogu süsteemi arhitektuuri, tuues esile skaalat, optimeerimist ja andmevooge nii autonoomses kui ka võrgurežiimis. Selles jaotises käsitleme prognoositeenust ja kirjeldame masinõppesüsteemi, mis tagab prognoositeenuse töö.
Üle 100 andmetüübi ja teatud struktureerimata sisuga, nagu sõnumite ja kasutajate sisu, toob ainult käsitsi heuristikaga töötamine kaasa alamparameetrilise klassifitseerimise täpsuse, eriti struktureerimata andmete puhul. Just seetõttu oleme välja töötanud ka masinõppesüsteemi, et tegeleda struktureerimata andmete keerukustega. Masinõppe kasutamine võimaldab meil liikuda kaugemale käsitsi heuristikast ja töötada tunnuste ning andmete täiendavate signaalidega (nt veergude nimed, andmete päritolu), et suurendada täpsust.
Rakendatud mudel uurib tihedaid ja hõredaid objekte eraldi vekt esitusena [3]. Seejärel ühendatakse nad, et moodustada vektor, mis läbib rida partii normaliseerimise etappe [4] ja mitte-lineaarsust lõpliku tulemuse saavutamiseks. Lõplik tulemus on ujukomaga number vahemikus [0-1] iga sildi jaoks, mis näitab tõenäosust, et näide kuulub antud tundlikkuse tüübisse. PyTorchi kasutamine mudelis võimaldas meil liikuda kiiremini, andes meeskonna välistele arendajatele võimaluse kiiresti muudatusi teha ja neid testida.
Arhitektuuri projekteerimisel oli oluline mudeldada hõredaid (nt teksti) ja tihedaid (nt numbreid) objekte eraldi их внутреннего различия tõttu. Lõpliku arhitektuuri jaoks oli oluline ka parameetrite tühi välja töötamine, et leida optimaalsed õppimiskiirus, partii suurus ja muud hüperparameetrid. Optimeerija valik oli samuti oluline hüperparameeter. Me leidsime, et populaarne optimeerija Adamtoob sageli kaasa üleõppimise, samas kui mudeliga SGD stabiilsem. Oli täiendavaid nüansse, mida pidime otse mudelisse kaasama. Näiteks staatilised reeglid, mis tagasid, et mudel teeb määratletud väärtuse korral.deterministlikke prognoose. Need staatilised reeglid on meie kliendi määratletud. Avastasime, et nende otse mudelisse kaasamine viis iseseisvama ja usaldusväärsema arhitektuuri, erinevalt post-protsessimise etapi rakendamisest nende eriliste äärmuslike juhtumite käsitlemiseks. Samuti tasub märkida, et treeningu ajal need reeglid on välja lülitatud, et mitte takistada gradientide langemise treeningprotsessi.
Probleemid
Ühe probleemina oli kõrgekvaliteediliste usaldusväärsete andmete kogumine. Mudel vajab iga klassi usaldusväärsust, et see saaks õppida objektide ja siltide vahelisi seoseid. Eelnevas osas rääkisime andmete kogumise meetoditest nii süsteemi mõõtmiseks kui ka mudelite õpetamiseks. Analüüs näitas, et meie hoidlas ei ole sellised andmeklassid nagu krediitkaartide ja pankade kontode numbrid väga levinud. See raskendab usaldusväärsete andmete kogumist mudelite õpetamiseks. Selle probleemi lahendamiseks oleme välja töötanud protsessid sünteetiliste usaldusväärsete andmete saamiseks nende klasside jaoks. Generoome selliseid andmeid tundlike tüüpide jaoks, sealhulgas SSN, krediitkaartide numbrid ja IBAN-numbrid, mille jaoks mudel ei osanud varem prognoosida. See lähenemine võimaldab töödelda konfidentsiaalseid andmeid ilma privaatsusriskita, mis on seotud tegelike konfidentsiaalsete andmete varjamisega.
Lisaks usaldusväärsete andmete probleemidele on meil avatud arhitektuurilised probleemid, mille kallal töötame, nagu muudatuste isoleerimine ja enneaegne peatamine. Muudatuste isoleerimine on oluline, et erinevatesse võrgupiirkondadesse tehtud muudatuste mõju ei oleks laialdane, vaid isoleeritud teatud klasside vahel, et vältida nende laialdast mõju prognoosi üldisele jõudlusele. Varajase peatamise kriteeriumide täiustamine on samuti ülioluline, et saaksime treeningprotsessi lõpetada stabiilses punktis kõigi klasside jaoks, mitte punktis, kus mõned klassid üleõppivad ja teised ei.
Märgi olulisus
Kui mudelisse lisatakse uus märk, soovime teada selle üldist mõju mudelile. Samuti tahame veenduda, et prognoosid on inimesetõlgendatavad, et saaksime täpselt mõista, milliseid märke kasutatakse iga andmetüübi puhul. Selleks oleme töötanud välja ja rakendanud klassipõhine PyTorchi mudeli tunnuste tähtsus. Pange tähele, et see erineb üldise tunnuse tähtsusest, mis tavaliselt toetub, kuna see ei ütle meile, millised tunnused on olulised konkreetse klassi jaoks. Hindame objektide tähtsust, arvutades prognoosiviga suurenemist objekti segamise järel. Tunnus on «oluline», kui väärtuste segamine suurendab mudeli viga, kuna sellisel juhul sõltus mudel prognoosimisel tunnusest. Tunnus on «ebatähtis», kui selle väärtuste segamine jätab mudeli vea muutumatuks, kuna mudel ignoreeris seda [5].
Iga klassi tunnuse tähtsus võimaldab mudelit tõlgendada, et näha, millele mudel prognoosimisel tähelepanu pöörab. Näiteks kui analüüsime ADDR, tagame, et aadressiga seotud tunnus, nagu AddressLinesCount, on iga klassi tunnuste tähtsusloendis kõrgel kohal, et meie inimlik intuitsioon klappiks hästi sellega, mida mudel õppis.
Hinne
Oluline on määratleda ühtne edutehnika. Oleme valinud F2 — tasakaal tagasiside ja täpsuse vahel (tagasiside kaal on veidi suurem). Privaatsuse kasutusjuhtumite puhul on tagasiside olulisem kui täpsus, kuna meeskonna jaoks on ülioluline mitte jätta tähelepanuta mingeid konfidentsiaalseid andmeid (tagades samas mõistliku täpsuse). Meie mudeli F2 jõudluse tegelikud hinnangud jäävad selle artikli raames väljapoole. Siiski, hoolika häälestamise korral suudame saavutada kõrge (0,9+) F2 skoori kõige olulisemate tundlike klasside jaoks.
Seotud töö
On olemas palju automatiseeritud klassifitseerimise algoritme struktureerimata dokumentide jaoks, kasutades erinevaid meetodeid, nagu mustrite sobitamine, dokumentide sarnasuse otsimine ja erinevad masinõppe meetodid (baayeeritud, otsuste puud, k-lähedased naabrid ja paljud teised) [6]. Igaüht neist saab kasutada klassifitseerimise osana. Probleem seisneb aga skaleeritavuses. Artiklis käsitletud klassifitseerimisviis on suunatud paindlikkusele ja jõudlusele. See võimaldab meil tulevikus tosupport uusi klasse ja säilitada madala viivitusega.
Andmeid on võimalik jälgida ka erinevate meetoditega. Näiteks autorid [7] kirjeldavad lahendust, mis keskendub konfidentsiaalsete andmete lekete tuvastamise probleemile. Peamine eeldus on andmete jäljendamine, et siduda see tuntud konfidentsiaalsete andmete kogumiga. Autorid [8] kirjeldavad sarnast privaatsuspüüdete probleemi, kuid nende lahendus põhineb konkreetse Androidi arhitektuuri kasutamisel ning klassifitseeritakse vaid siis, kui kasutaja tegevused toimetavad isiklikku teavet või kui põhirakenduses lekib kasutajaandmeid. Siin on olukord veidi erinev, kuna kasutajaandmed võivad olla tugevalt struktureerimata. Seetõttu on meil vaja keerukamat meetodit jäljendamise asemel.
Lõpuks, et tegeleda andmete puudumisega teatud tüüpi konfidentsiaalsete andmete puhul, oleme tutvustanud sünteetilisi andmeid. Andmete täiendamise kohta on palju kirjandust, näiteks on autorid [9] uurinud müra süstimise rolli koolituse ajal ja on jälginud positiivseid tulemusi kontrollitud õppes. Meie lähenemine privaatsusele on erinev, kuna müra sisaldavate andmete kasutuselevõtt võib olla vastutustundetu, ning keskendume hoopis kvaliteetsetele sünteetilistele andmetele.
Kokkuvõte
Selles artiklis tutvustasime süsteemi, mis suudab andmefragmenti klassifitseerida. See võimaldab meil luua privaatsuse ja turvaseoste poliitikate järgimise süsteeme. Oleme näidanud, et skaleeritav infrastruktuur, pidev integreerimine, masinõpe ja kvaliteetsed andmeautentsuse andmed mängivad paljude meie privaatsuse algatuste edus olulist rolli.
Tulevikus on palju võimalusi tööks. See võib hõlmata struktureerimata andmete (failide) toetamist, mitte ainult andmeühe tüübi, vaid ka tundlikkuse taseme klassifitseerimist ning iseõppimise kasutamist õppimise ajal, genereerides täpseid sünteetilisi näiteid. Need omakorda aitavad mudelil vähendada kaotuseni suurimat mahtu. Tuleviku töö võib keskenduda ka uurimisprotsessile, kus ületame tuvastamise ja pakume erinevate privaatsusrikkumiste põhjusanalüüsi. See aitab näiteks tundlikkuse analüüsis (nt kas andme tüübi privaatsuse tundlikkus on kõrge (nt kasutaja IP) või madala (nt Facebooki sisemine IP)).
Bibliograafia
- David Ben-David, Tamar Domany ja Abigail Tarem. Ettevõtte andmete klassifitseerimine semantiliste veebitehnoloogiate abil. Redigeeritud Peter F.Ï Patel-Schneider, Yue Pan, Pascal Hitzler, Peter Mika, Lei Zhang, Jeff Z. Pan, Ian Horrocks ja Birte Glimm. Semantiline veeb – ISWC 2010, lk 66–81, Berliin, Heidelberg, 2010. Springer Berlin Heidelberg.
- Subramanian Muralidhar, Wyatt Lloyd, Sabyasachi Roy, Cory Hill, Ernest Lin, Weiwen Liu, Satadru Pan, Shiva Shankar, Viswanath Sivakumar, Linpeng Tang ja Sanjeev Kumar. f4: Facebooki soe BLOB-i salvestussüsteem. Sissejuhatus 11. USENIXi kasutajaliidese ja rakenduste disaini sümpoosion (OSDI 14), leheküljed 383–398, Broomfield, CO, oktoober 2014. USENIX Association.
- Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S Corrado ja Jeff Dean. Sõnade ja fraaside jaotatud representatsioonid ja nende kompositsioonilisus. C. J. C. Burgesi, L. Bottou, M. Wellingi, Z. Ghahramani ja K. Q. Weinbergeri toimetamisel, Neuraalsete infoprotsesside süsteemide 26. aastakäik, leheküljed 3111–3119. Curran Associates, Inc., 2013.
- Sergey Ioffe ja Christian Szegedy. Partiide normaliseerimine: sügavate võrkude treeningu kiirendamine sisemise varieerumise vähendamise kaudu. Francis Bachi ja David Blei toimetamisel, 32. rahvusvahelise masinõppe konverentsi toimetised, köide 37 Masinõppe teadustöö toimetised, leheküljed 448–456, Lille, Prantsusmaa, 07–09 juuli 2015. PMLR.
- Leo Breiman. Juhuslikud metsad. Masin. Õppimine., 45(1):5–32, oktoober 2001.
- Thair Nu Phyu. Klassifikatsioonitehnikate ülevaade andmete kaevandamises.
- X. Shu, D. Yao ja E. Bertino. Kõrvalekalde avastamine tundlike andmete avalikustamisel. IEEE Tehingud teabe forensika ja turvalisuse alal, 10(5):1092–1103, 2015.
- Zhemin Yang, Min Yang, Yuan Zhang, Guofei Gu, Peng Ning ja Xiaoyang Wang. Appintent: tundlike andmete edastamise analüüs androidis privaatsete lekkete tuvastamiseks. leheküljed 1043–1054, 11 2013.
- Qizhe Xie, Zihang Dai, Eduard H. Hovy, Minh-Thang Luong ja Quoc V. Le. Juhuslik andmete suurendamine.
Tutvuge üksikasjadega, kuidas alustada nõutud ametit või täiustada oma oskusi ja palka, osaledes SkillFactory veebikursustel:
- (12 kuud)
- (12 nädalat)
- (20 nädalat)
- (20 nädalat)
Rohkem kursusi
- (9 kuud)
- (8 kuud)
- (9 kuud)
- (12 kuud)
- (18 kuud)
- (12 kuud)
- (9 kuud)
- (7 kuud)

Allikas: habr.com
