

Ettekandes tutvustatakse mõningaid lähenemisviise, mis võimaldavad jälgida SQL-päringute jõudlust, kui neid on miljoneid päevas, ja hallatavaid PostgreSQL servereid on sadu.
Millised tehnilised lahendused võimaldavad meil tõhusalt sellist teabehulka töödelda ja kuidas see lihtsustab tavalise arendaja elu.

Kellele on huvitav konkreetsete probleemide analüüs ning erinevad optimeerimisetehnikad SQL-päringute ja tüüpiliste DBA-ülesannete lahendamine PostgreSQL-is — saate samuti sel teemal.
Minu nimi on Kirill Borovikov, ma esindan . Konkreetsemalt spetsialiseerun ma meie ettevõttes andmebaasidega töötamisele.
Täna räägin teile, kuidas tegeleme päringute optimeerimisega, kui peate mitte "kaevama" ühe päringu tootlikkuse kallal, vaid lahendama probleemi massiliselt. Kui päringute arv on miljonite kaupa ja peate leidma mingid lähenemisviisid selle suure probleemi lahendamiseks. selle suure probleemi.
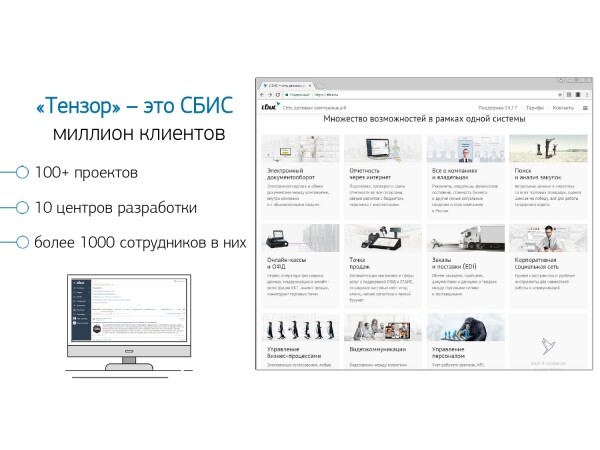
Üldiselt on "Tensor" miljoni meie kliendi jaoks : ettevõtte sotsiaalne võrk, lahendused videokõnede jaoks, sisemise ja välise dokumenteerimise jaoks, raamatupidamise ja laosüsteemide haldamine… See on nagu „megakombain“ äri terviklikuks juhtimiseks, milles on rohkem kui 100 erinevat sisemist projekti.
Selleks, et kõik need sujuksid ja areneksid — meil on 10 arenduskeskust üle kogu riigi, kus on rohkem 1000 arendajat.
PostgreSQL-iga töötame alates 2008. aastast ja oleme kogunud suure hulga andmeid — need on kliendiandmed, statistilised, analüütilised, andmed välistest infosüsteemidest — üle 400TB.Ainult „töös“ on umbes 250 serverit, aga kokku jälgime andmebaasi servereid, neid on umbes 1000.

SQL on deklaratiivne keel. Esiteks kirjeldate, mitte „kuidas“, vaid „mida“ soovite saada. DBMS teadub paremini, kuidas teha JOIN – kuidas ühendada tabelid, millised tingimused kehtestada, mis läheb indeksi kaudu ja mis mitte…
Mõned andmebaasid võtavad vastu vihjeid: „Ei, ühenda need kaks tabelit sellises järjekorras“, kuid PostgreSQL ei oska seda teha. See on teadlik seisukoht juhtivate arendajate poolt: „Eelistame optimeerijat täiustada, kui lubada arendajatel mingite vihjete abil töötada.“
Kuid hoolimata sellest, et PostgreSQL ei luba „väljast“ ennast juhtida, võimaldab see suurepäraselt nähes, mis toimub selle „sises“, kui teete oma päringu ja kus tekivad probleemid.

Tavaliselt, milliste klassikaliste probleemidega tuleb arendaja [DBA] juurde? „Me protsessisime päringu ja meil on kõik aeglane, kõik hangub, midagi toimub… See on kahtlane!“
Põhjused on peaaegu alati samad:
- tõhus algoritm päringule
Arendaja: „Praegu ühendan SQL-is 10 tabelit JOIN-iga…“ – ja ootab, et tema tingimused imekombel efektiivselt „lahendatakse“ ja ta saab kõik kiiresti. Kuid imesid ei juhtu, ja iga süsteem sellise varieerimise puhul (10 tabelit ühe FROM-i sees) annab alati mingi ebatäpsuse.] - vakku statistikat
Moment on väga oluline just PostgreSQL jaoks, kui olete suure andmehulgaga serverisse „sisenenud“, teete päringu — ja see „seksib“ tabelis. Sest eile oli seal 10 kirjet, aga täna 10 miljonit, kuid PostgreSQL ei tea sellest veel, ja meil tuleb talle seda näidata.] - ressursside „ummistus“
Olete pannud suure ja koormatud andmebaasi nõrkadele serveritele, kellel puuduvad ketta, mälude ja protsessori võimekus. Ja kõik... Kusagil on olemas jõudluse lagi, mille ületamiseks te enam ei suuda. - blokaadid
Täpne moment, kuid need on kõige asjakohasemad erinevate muudetud päringute (INSERT, UPDATE, DELETE) jaoks — see on eraldi suur teema.
Kava saamine
… Ja kõigi teiste jaoks me vajame kava! Me peame nägema, mis serveris toimub.

Päringu täitmise plaan PostgreSQL jaoks on päringu täitmise algoritmi puu tekstivälja kujul. Just see algoritm, mille analüüsis plaanija on tunnistanud kõige efektiivsemaks.
Iga puu sõlm — operatsioon: andmete väljavõtmine tabelist või indeksist, bitikaardi koostamine, kahe tabeli ühendamine, liitmine, ristamine või valikute eristamine. Päringu täitmine — läbimine selle puu sõlmedest.
Küsimuse plaani saamiseks on kõige lihtsam viis kasutada käsku EXPLAIN. Selleks, et saada kõiki reaalseid atribuute, st tegelikult päringut andmebaasis täita — EXPLAIN (ANALYZE, BUFFERS) SELECT ....
Halb koht: kui te seda täidate, toimub see „siin ja praegu”, seega sobib see ainult kohaliku tõrkeotsingu jaoks. Kui aga võtate mõne kõrge koormusega serveri, mis seisab tugeva andmevoo all, ja näete: „Ai! Siin me olime aeglaselt täitnudpäringu.” Pool tundi, tund tagasi — kui te jooksisite ja tõite selle päringu logidest, kandsite selle uuesti serverisse, on kogu teie andmekogum ja statistika muutunud. Te täidate selle tõrkeotsinguks — ja see täitub kiiresti! Ja te ei saa aru, „miks”, miks päringu.» Pool tundi, tund aega tagasi — samal ajal, kui te jooksisite ja tõite selle päringu logidest, toite selle jälle serverisse, oli kogu teie andmestik ja statistika muutunud. Te täidate selle, et siluda — ja see täidetakse kiiresti! Ja te ei saa aru, "miks", miks oli aeglaselt.

Kuna mõista, mis juhtus just sel hetkel, kui päring serveris täidetakse, on tarkade inimeste poolt kirjutatud . See on praktiliselt kõikides levinumates PostgreSQL'i distributsioonides ja seda saab lihtsalt konfig-failis aktiivseks teha.
Kui ta mõistab, et mõni päring kestab kauem, kui olete talle öelnud, siis ta teeb selle päringu 'võtte' plaani ja kirjutab need koos logisse..

Näib, et kõik on nüüd hästi, läheme logisse ja näeme seal… [портянка текста]. Aga me ei saa sellest midagi öelda, peale selle, et see on suurepärane plaan, kuna see kestis 11 ms.
Kohati näib, et kõik on korras — aga ei ole selge, mis tegelikult toimus. Välja arvatud üldine aeg, ei näe me eriti midagi. Sest vaadata sellise 'latuka' plain text'i on üldiselt ebaülevaatlik.
Kuid isegi kui see on ebamugav, on palju tõsisemaid probleeme:
- Sõlmes näidatakse resursside summa kogu alampuu tema all. See tähendab, et lihtsalt ei saa teada, kui palju aega on konkreetselt selles Index Scan'is kulutatud — kui seal all on mingi sisse seatud tingimus. Peame dünaamiliselt vaatama, kas seal on 'lapsed' ja tingimuslikud muutujad, CTE — ja kõik see 'meeles' välja arvutama.
- Teine punkt: sõlmes näidatud aeg on sõlme täitmise aeg. Kui see sõlm täideti näiteks tabeli kirjade tsükli käigus mitu korda, suureneb plaanis loops — selle sõlme tsüklite arv. Kuid aatomite täitmise aeg jääb plaanis endiseks. Seega, et mõista, kui palju see sõlm kokkuvõttes täideti, tuleb ühte teisega korrutada — taas “meeles”.
Sellistes olukordades on «Kes on kõige nõrgem lüli?» mõistmine praktiliselt võimatu. Seetõttu kirjutavad isegi arendajad «manuaalis», et «Plani mõistmine on kunst, mida tuleb õppida, kogemus…».
Aga meil on 1000 arendajat ja ei saa seda kogemust igale pead anda. Mina, sina, tema — teavad, aga see, kes seal, ei pruugi. Võib-olla ta õpib, aga võib-olla ei õpi, kuid talle peab juba praegu tööle minema — kust tal siis see kogemus võtta on.
Plani visualiseerimine
Seetõttu mõistsime — et nende probleemidega tegeleda, on meil vaja head plaani visualiseerimist.
Me läksime kõigepealt «turule» — otsime internetist, mida üldse olemas on.
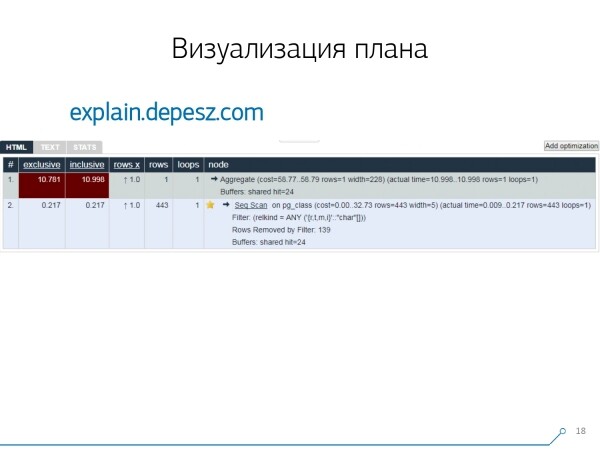
Kuid selgus, et suhteliselt "elavaid" lahendusi, mis enam-vähem arenevad, on väga vähe — sõna otseses mõttes üks: Hubert Lubaczewski poolt. Sisestades tekstilise esitluse plaanist, kuvatakse sulle tabel analüüsitud andmetega:
- sõlme enda tööaeg
- koguaeg kogu allpuu kohta
- salvestuste arv, mis on välja tõmmatud ja mis statistiliselt oodati
- sõlme enda keha
Sellel teenusel on ka võimalus jagada lingiarhiivi. Sa viskad sinna oma plaani ja ütled: „Hei, Vasja, siin on link, seal on midagi valesti.“

Aga väiksed probleemid on ka.
Esiteks, tohutu hulk „kopeerimist ja kleepimist“. Sa võtad logsakti ja paned selle sinna, ja jälle, ja jälle.
Teiseks, andmete lugemise arvu analüüsi puudumine — just need buffers, mida ta välja toob EXPLAIN (ANALYZE, BUFFERS), siin me ei näe. Ta lihtsalt ei oska neid analüüsida, neid mõista ja nendega töötada. Kui loed palju andmeid ja mõistad, et võid kettale ja mälu vahemälusse vale jaotuse teha, on see teave väga oluline.
Kolmas negatiivne punkt on väga nõrk selle projekti areng. Commit'id on väga väiksed, hästi kui kord poole aasta jooksul, ja kood on Perl'is.
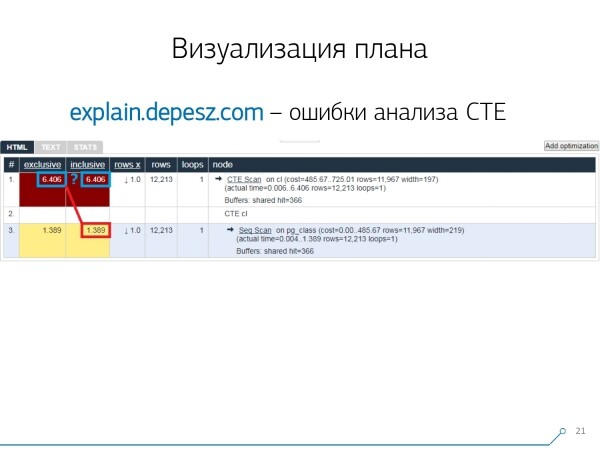
Aga see on kõik 'lüürika', sellega oleks võimalik kuidagi elada, kuid on üks asi, mis meid sellest teenusest tugevasti eemale tõukab. Need on Common Table Expression (CTE) ja erinevate dünaamiliste sõlmede, nagu InitPlan/SubPlan, analüsi vead.
Kui uskuda seda pilti, siis on iga eraldi sõlme täitmise koguaeg suurem kui kogu päringu täitmise aeg. Kõik on lihtne — CTE Scan'i sõlmest ei ole maha arvestatud selle CTE genereerimise aega.. Seega ei tea me enam õiget vastust, kui kaua kestis CTE skaneerimine.

Siit mõistsime, et on aeg kirjutada oma lahendus — hurraa! Iga arendaja ütleb: 'Nüüd me kirjutame oma, super lihtne on!'
Võtsime veebiteenustele tüüpilise tehnoloogia: süda Node.js + Express, Bootstrap ja ilusate diagrammide jaoks — D3.js. Ja meie ootused said põhjalikult täidetud — saime esimese prototüübi kahe nädalaga:
- oma plaani parser
See tähendab, et nüüd suudame analüüsida igasuguseid plaane, mida PostgreSQL genereerib. - korrektne dünaamiliste sõlmede analüüs — CTE Scan, InitPlan, SubPlan
- buffersi jaotuse analüüs — kus andmelehed loetakse mälust, kus kohalikust vahemälust, kus kettalt
- oleme saanud selguse
Kuna ei pea kõike seda logis "kaevama", vaid nägema "nõrgimat lüli" kohe pildilt.
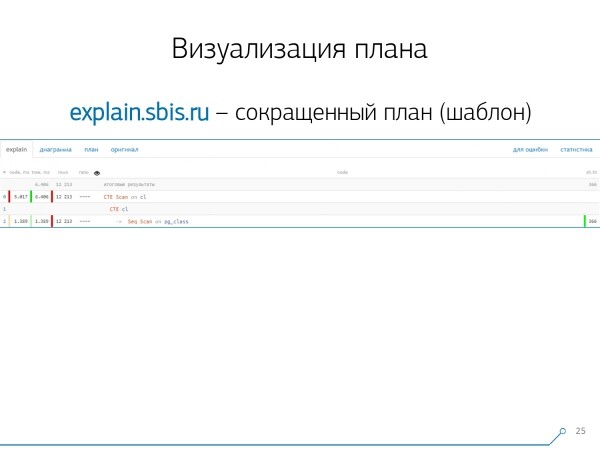
Oleme saanud umbes sellise pildi — kohe süntaksihighlighting'iga. Kuid tavaliselt töötavad meie arendajad juba mitte täieliku plaaniga, vaid millegagi lühemaga. Kõik numbrid oleme juba parsitud ja ühte või teise suunda visatud, alles on ainult esimene rida, mis see sõlm on: CTE Scan, CTE loomine või Seq Scan mõne tabeli järgi.
Seda lühendatud esitust nimetameme plaanimalliks.
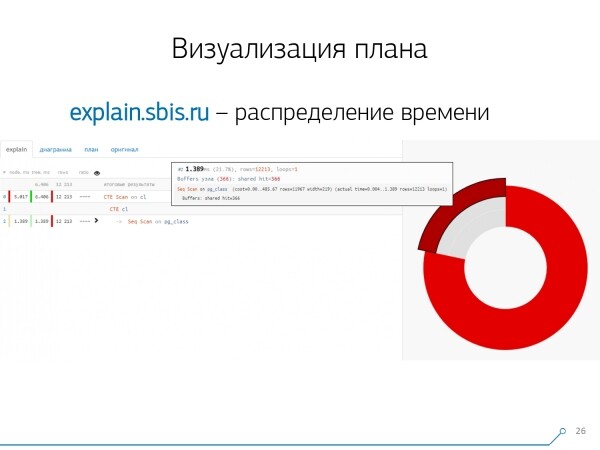
Mis veel oleks mugav? Mugav oleks näha, kui suur osa aega millisele sõlmele jaguneb — ja lihtsalt "kleepisime" küljele küpsisetabel.
Suuname sõlmele ja näeme — äratus! Seq Scan võttis kogu ajast vähem kui veerandi, aga ülejäänud 3/4 võttis CTE Scan. Kohutav! See on väike märk "kiirusest" CTE Scan'i puhul, kui kasutate neid aktiivselt oma päringutes. Nad ei ole väga kiired — nad kaotavad isegi tavapärase tabeli skaneerimisele.
Kuid tavaliselt on sellised diagrammid huvitavamad ja keerukamad, kui suuname kohe segmendile ja näeme näiteks, et üle poole kogu ajast on läinud mõne Seq Scan 'förstinud'. Ning seal sees oli mingisugune Filter, mille tõttu visati palju kirjeid kõrvale... Selle pildi saab otse arendajale saata ja öelda: 'Vassil, sul on siin tõeliselt kehvasti! Lahenda see üles, vaata — midagi on valesti!'

Muidugi ei käinud see ilma 'kombeideta'.
Esimene probleem, millele 'astepidi' astusime, oli ümardamise probleem. Iga eraldi sõlme aeg plaanis on näidatud täpsusega kuni 1µs. Ja kui sõlme tsüklite arv ületab näiteks 1000 — pärast PostgreSQL'i täitmist jagas 'täpsusega', siis tagasi arvutades saame kokkuaja 'kusagil 0,95ms ja 1,05ms vahel'. Kui arvestus käib mikrosekundite lõikes, on see veel talutav, aga kui juba [miljoni] sekundite osas — tuleb sõlmede plaanis 'kes kui palju tarbis' neid andmeid arvesse võtta.

Teine, keerulisem aspekt on ressursside (neid samu puhvrid) jaotamine dünaamiliste sõlmede vahel. See maksis meile prototüübi esimese kahe nädala kõrval veel neli nädalat.
Selline probleem on üsna kerge tekkima — loome CTE ja seal näiliselt midagi loeme. Tegelikult on PostgreSQL „nutikas” ja ei loe seal otse midagi. Siis võtame sellest esimesest kirjest, ja sellele — sadandeist samast CTE-st.
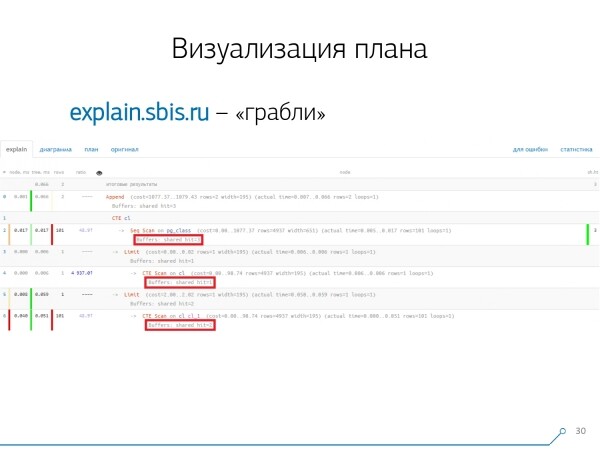
Vaadates plaani, saame aru — kummaline, meil oli 3 bufferit (andmelehti), mis olid „tarbitud” Seq Scan'is, veel 1 CTE Scan'is ja veel 2 teises CTE Scan'is. Kui kõik kokku liita, saada 6, aga tabelist lugesime ainult 3! CTE Scan ei loe mitte kuskilt, vaid töötab otse protsessi mäluga. Siin on selgelt midagi valesti!
Tegelikult selgub, et need 3 andmelehte, mida küsiti Seq Scan'ilt, küsis esmalt 1. CTE Scan ja seejärel 2., mis luges juurde veel 2. Seega loeti kokku 3 andmelehte, mitte 6.
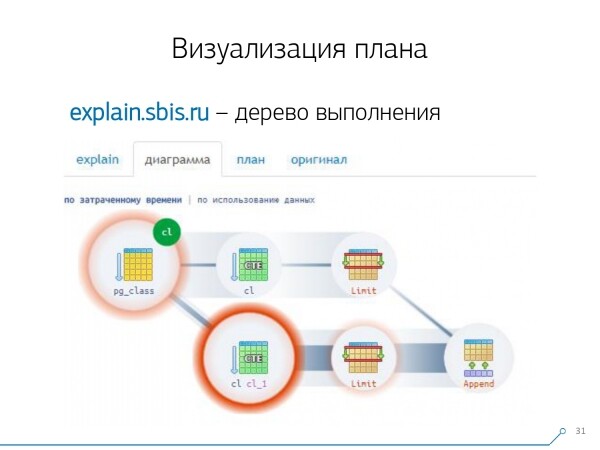
Ja see pilt viis meid arusaamisele, et plaani täitmine ei ole enam puu, vaid lihtsalt mingi suuline graaf. Ja meil on tekkinud umbes selline diagramm, et mõista, "mida-kusagilt üldse tuli". See tähendab, et siin me lõime CTE pg_class'ist ja palusime seda kaks korda ning praktiliselt kogu meie aeg kulus teisel korral, kui me seda küsisime. On selge, et 101. kirje lugemine on oluliselt kallim kui lihtsalt 1. tabelist.

Me hingasime hetkeks kergendatult. Ütlesime: "Nüüd, Neo, sa tead kung fu! Nüüd on meie kogemus otse sinu ekraanil. Nüüd saad seda kasutada."
Logide konsolideerimine
Meie 1000 arendajat hingasid kergendatult. Aga me mõistsime, et meil on vaid sadu "laevade" servereid ja see "kopeerimine-kleepimine" arendajatelt on vägagi ebamugav. Saime aru, et peame selle ise kokku koguma.

Tegelikult on olemas ametlik moodul, mis oskab statistikat koguda, aga seda tuleb samuti konfigureerida — see on . Kuid see ei sobinud meile.
Esiteks määrab ta sama päringu erinevatele skeemidele ühe ja sama andmebaasi raames erinevad QueryId. See tähendab, et kõigepealt tehes SETEERIGE otsingutee = '01'; VALIGE * KASUTAJAST PIIR 1;, ja siis SETEERIGE otsingutee = '02'; ja sama päringuga on selle mooduli statistikas erinevad kirjed ning ma ei suuda koguda üldist statistikat just selle päringu profiili lõikes, arvestamata skeemi.
Teine aspekt, mis takistas meil selle kasutamist — plaanside puudumine. See tähendab, et plaani ei ole, on ainult päring ise. Me näeme, mis takistas, kuid ei saa aru, miks. Ja siin tuleme tagasi kiiresti muutuva andmestiku probleemile.
Ja viimane punkt — puudumine «faktidest». See tähendab, et ei saa viidata konkreetsele päringu täitmise instantsile — seda ei ole, on ainult agregaatstatistika. Sellega on võimalik töötada, kuid see on väga keeruline.
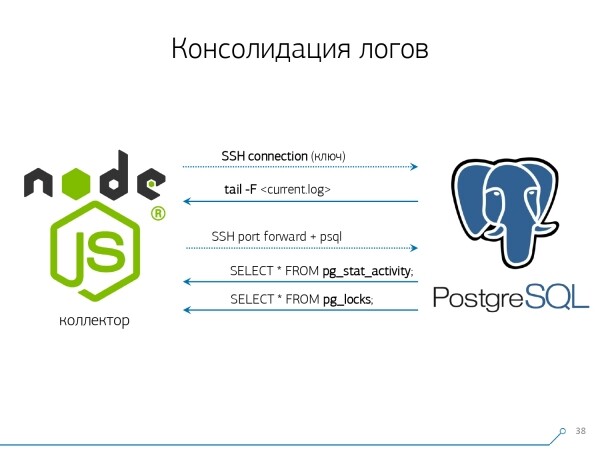
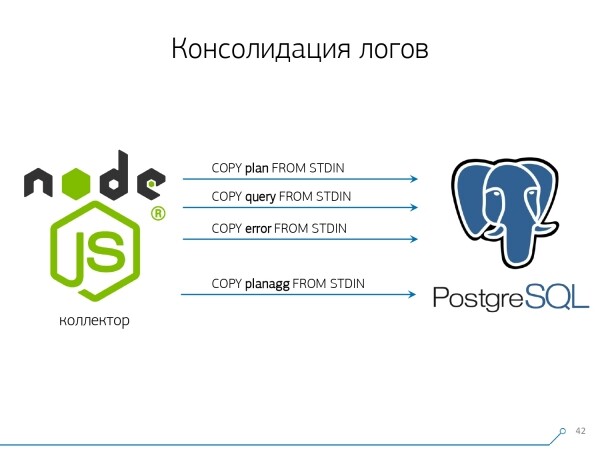
Seetõttu otsustasime «kopeerimise ja kleepimisega» võidelda ja hakkasime kirjutama kollektor.
Kollektor ühendub SSH kaudu, loob turvalise ühenduse sertifikaadiga andmebaasiserveriga ja tail -F ühendub sellega logifailiga. Sel moel saame kogu logifaili täieliku «peegelpildi», mille genereerib server. Serveri koormus on selle juures minimaalne, sest me ei parsi seal midagi, lihtsalt peegeldame liiklust.
Kuna me oleme juba alustanud liidese loomist Node.js-is, siis jätkasime kollektorit arendamist samuti seal. See tehnoloogia on end õigustanud, kuna halvasti vormindatud tekstiliste andmete, nagu logide, töötlemiseks on JavaScripti kasutamine väga mugav. Ja Node.jsi infrastruktuur tagab, et on lihtne ja mugav töötada võrguühenduste ja igasuguste andmevoogudega.
Seega „venitame” kaks ühendust: esimene, et „kuulata” logi ja selle enda juurde korjata, ning teine — et perioodiliselt andmebaasilt küsida. „Logis tuli teade, et tabel oid-iga 123 on blokeeritud”, kuid see ei ütle arendajale midagi, seega oleks hea küsida andmebaasilt: „Mis asi on OID = 123?” Nii me siis perioodiliselt küsime andmebaasilt neid asju, mida me veel ei tea.

«Sa ainult ühte asja ei arvutanud, on olemas elevandilaadseid mesilasi!..» Me alustasime selle süsteemi väljatöötamist, kui soovisime jälgida 10 serverit. Need olid meie arvates kõige kritilisemad, kus esines probleeme, millega oli keeruline tegeleda. Kuid juba esimese kvartali jooksul saime jälgimise alla sada — sest süsteem «sisenes», kõik soovisid, kõigile oli mugav.
Kogu see info tuleb kokku panna, andmevoog on suur ja aktiivne. Tegelikult jälgime seda, milles oskame toime tulla — seda ka kasutame. Kasutame andmete laona ka PostgreSQL-i. Ja ei ole mingit kiiremat viisi, et sinna andmeid «pudendada», kui operaator. COPY pole veel.
Aga lihtsalt andmete «pudendamine» — see ei ole päris meie tehnoloogia. Sest kui teil on sajale serverile kokku umbes 50k päringut sekundis, genereerib see teile 100-150GB logisid päevas. Seetõttu pidime andmebaasi ettevaatlikult «lõikama».
Esiteks tegime jaotamise päevade kaupa, sest põhimõtteliselt ei huvitunud kedagi ööpäevade vahelisest korrelatsioonist. Mis vahet seal on, mis sul eile oli, kui sa täna öösel uue rakenduse versiooni väljalaskmine — ja juba on mingi uus statistika.
Teiseks, me õppisime (olime sunnitud) väga-väga kiiresti kirjutama kasutades COPY. See tähendab, et mitte lihtsalt COPY, kuna see on kiirem kui INSERT, aga veel kiiremini.

Kolmas punkt — pidime loobuma triggereist ning samuti Foreign Key'dest. See tähendab, et meil puudub täiesti viidatud terviklikkus. Sest kui teil on tabel, millel on paar FK-d, ja te ütlete andmebaasi struktuuris, et "siin on logis olemas viide näiteks grupile kirjeid", siis kui te selle sisestate, ei jää PostgreSQL-l midagi muud üle, kui lihtsalt täita SELECT 1 FROM master_fk1_table WHERE ... selle identifikaatoriga, mida te püüate sisestada — lihtsalt selleks, et kontrollida, et see kirje seal olemas on, et te ei "purusta" oma sisestusega seda Foreign Key'd.
Saame sihtotstarbelisse tabelisse ühe kirje asemel ja selle indeksid, lisaks lugemist kõigilt tabelitelt, millele see viitab. Ja me ei vaja seda üldse — meie ülesanne on kirjutada nii palju kui võimalik ja nii kiiresti kui võimalik väiksema koormusega. Nii et FK — välja!
Järgmine punkt on agregatsioon ja häsheering. Alguses rakendasime neid andmebaasis — see on mugav, kui igasugune kirje saabub, teha midagi mõnes tabelis. "pluss üks" otse triggeris.. Hästi, mugav, aga halb samas — teete ühe kirje lisamise, aga peate lugema ja kirjutama veel midagi teisest tabelist. Ja mis veel hullem, tuleb lugeda ja kirjutada iga kord.
Ja nüüd kujutage ette, et teil on tabel, kus te lihtsalt loete konkreetse hosti kaudu läbitud päringute arvu: +1, +1, +1, ..., +1. Ja see pole teile tegelikult vajalik — kõik võib mälu summaarse koguse järgi kollektoris ja saata andmebaasi korraga. +10.
Jah, teil võib tekkida „purunemine“ loogilises terviklikkuses, kuid see on praktiliselt reaalne juhtum — sest teil on normaalne server, sellel on patarei kontrolleris, teil on tehingute ajalugu, ajakiri failisüsteemis... Ühesõnaga, see ei ole seda väärt. Kaotatud jõudluse hind ei ole õigustatud, mida te saate triggerite/FK-de tõttu, need kulud, mida te sellega kaasnevalt kannate.
Sama kehtib ka hõlmitud rämpspostide kohta. Teile tuleb mingi päring, millest arvutate andmebaasis mingi identifikaatori, kirjutate selle andmebaasi ja räägite kõigile sellest. Kõik on hästi, kuni salvestamise hetkel ei tule teise soovi salvestada sama — ja teil tekib lukustus, mis on juba halb. Seega, kui saate teatud ID-de genereerimise kliendisse viia (andmebaasi suhtes), on parem see teha.
Meile sobis suurepäraselt kasutada teksti MD5 — päringu, plaane, mallide jne. Me arvutame selle kogujapoolsel küljel ja „töötame” andmebaasi juba valmistatud ID-ks. MD5 pikkus ja päevaste osade muutmine võimaldavad meil mitte muretseda võimalike kokkulangevuste pärast.
Kuid et seda kõike kiiresti salvestada, pidime modifitseerima salvestamisprotseduuri.
Kuidas andmeid tavaliselt kirjutatakse? Meil on mingi andmestik, jaotame selle mitmeks tabeliks ning siis COPY — kõigepealt esimesse, siis teise, kolmandasse… Ebamugav, sest näiliselt kirjutame ühe andmevoo kolmes etapis järjestikku. Ebameeldiv. Kas seda saab kiiremini teha? Saab!
Selleks piisab, kui panna need voolud üksteise kõrval параллелne. Tulemusena lendavad meil eraldi voogudes vead, päringud, mallid, lukustused,… — ja me kirjutame seda kõike paralleelselt. Selleks piisab, hoida pidevalt avatud COPY-kanalit iga eraldi sihtmatsi jaoks..

See tähendab, et kollektsionäril on alati voog, kuhu ma saan kirjutada vajalikud andmed. Kuid et baas need andmed näeks, ja keegi ei jääks lukustusse ootes, kuni need andmed kirjutatakse, COPY tuleb katkestada teatud regulaarsusega. Meie jaoks tõestuslikult efektiivne aeg oli umbes 100 ms — sulgeme ja avame kohe uuesti sama tabeli. Ja kui meil ei piisa mingist voogust teatud haripunktides, siis teeme tõmbamise kindla piiri ulatuses.
Lisaks oleme välja selgitanud, et sellise koormusprofiili puhul on iga agregatsioon, kui kirjed kogutakse paketti — see on kuri. Klassikaline kuri on INSERT ... VALUES ja edasi 1000 kirjet. Sest sel hetkel tekkib teil salvestamisel tipptunne, ja kõik teised, kes üritavad midagi kettale kirjutada, peavad ootama.
Ette vältimiseks sellistest anomaaliatest, ärge aggregeerige midagi, ärge bufferdage üldse. Ja kui siiski tekib kirjutamise vahemälu (õnneks võimaldab Node.js Stream API seda tuvastada) — lükake see ühendus edasi. Just siis, kui saate teate, et see on jälle vaba — kirjutage sinna akumuleeritud järjekorrast. Kui see on hõivatud — võtke basseinist järgmine vaba ja kirjutage sinna.
Enne sellise andmete salvestamise lähenemise kasutuselevõttu oli meil umbes 4K kirjutamisoperatsiooni, kuid sellise lähenemisega vähendasime koormust neljakordselt. Nüüd on see kasvanud veel kuus korda tänu uutele jälgitavatele andmebaasidele — kuni 100MB/s. Ja nüüd hoiame viimase kolme kuu logisid koguses umbes 10-15TB, lootes, et kolme kuu jooksul suudab iga arendaja mistahes probleemiga tegeleda.
Me mõistame probleeme
Aga lihtsalt nende andmete kogumine — see on hea, kasulik, asjakohane, kuid liiga vähe — neid tuleb mõista. Sest see on miljoneid erinevaid plaane päevas.

Aga miljonid — see on juhitav, enne tuleb teha seda 'vähem'. Ja eelkõige tuleb otsustada, kuidas seda 'vähem' organiseerida.
Oleme välja toonud endale kolm peamist punkti:
- kes selle päringu saadab
See, from which application it "arrived": web interface, backend, payment system, or something else. - kus this happened
On which specific server. Because if you have several servers behind one application, and suddenly one "lags" (because the "disk failed", "memory leaked", or some other issue), you need to address it specifically to the server. - kuidas the problem manifested in one way or another
To understand "who" sent us the request, we use a standard tool — setting a session variable: SET application_name = '{bl-host}:{bl-method}'; — we set the name of the business logic host from which the request comes, and the name of the method or application that initiated it.
After we have passed the "host" of the request, it needs to be logged — for this, we configure the variable log_line_prefix = ' %m [%p:%v] [%d] %r %a'. For those interested, it may , what it all means. It turns out, we see in the log:
- aega
- process and transaction identifiers
- database name
- IP of the one who sent this request
- and the name of the method
Pealegi mõistsime, et pole liiga huvitav vaadata ühe päringu korrelatsiooni erinevate serverite vahel. Harva juhtub, et teil on üks rakendus, mis samamoodi "laguneb" siin ja seal. Kuid isegi kui see on sama — vaadake mõnda neist serveritest.
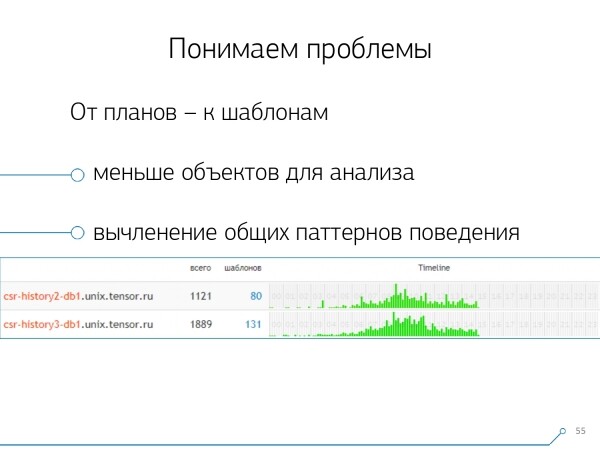
Nii et lõikepinda "üks server — üks päev" olid meile igasuguseks analüüsiks piisavad.
Esimene analüütiline lõige — see on see "mall" — lühendatud vorm plaani esitamiseks, puhastatud kõigist arvulistest näitajatest. Teine lõikepind — rakendus või meetod, ja kolmas — see konkreetne plaanipunkt, mis tõi meile probleeme.
Kui me ühel määratletud korralt mallidele üle läksime, saime kohe kaks eelist:
- märgatav arv objekti analüüsi vähendamine
Selle asemel, et probleemiga tegeleda tuhandete päringute või plaanide kaudu, vaatame nüüd vaid kümneid malle. - aegjoon
Kokkuvõttes, kui teatud lõigust "fakte" kokku võtta, saab nende ilmumist päeva jooksul visualiseerida. Siinkohal võite aru saada, et kui teil on mõni muster, mis toimub näiteks kord tunnis, aga peaks olema kord päevas, tasub mõelda, mis valesti läks — kes ja miks selle esitas, võib-olla ei peaks seda siin olema. See on veel üks mittearvuline, puhtalt visuaalne analüüsimeetod.

Teised meetodid põhinevad näitajatel, mida me plaanist välja töötame: kui mitu korda on selline muster aset leidnud, koguaeg ja keskmine aeg, kui palju andmeid on ketast lugenud ja kui palju mälust...
Näiteks, kui te tulete hosti analüüsilehe juurde, näete — mingil põhjusel on ketas hakanud liiga palju lugema. Serveri ketas ei suuda hakkama saada — kes seda lugemist teostab?
Võite sorteerida igasuguste veergude järgi ja otsustada, millega te hetkel tegelema hakkate — protsessori või ketase koormuse, või üldise päringute arvu... Sortisite, vaatasite "tipud" üle, parandasite need — tõukate välja uue versiooni rakendusest.
Ja kohe saate näha erinevaid rakendusi, mis töötavad sama šablooni alusel vastavalt päringu tüübile SELECT * FROM users WHERE login = 'Vasya'. Eesmine, tagumine, töötlemine… Ja te mõtlete, miks töötlemine peaks lugema kasutajat, kui ta ei suhtle sellega.
Tagasi liikudes - rakenduse kaudu näha kohe, mida see teeb. Näiteks, eesmine - see, see, see ja veel see korra tunnis (just nagu ajakava aitab). Ja kohe tekib küsimus - tundub, et eesmine ei peaks tegema midagi korra tunnis…

Mõne aja pärast saime aru, et meil on puudu koondatud statistika plaani sõlmede lõikes. Me eraldasime plaanidest ainult need sõlmed, mis tegelevad andmete endi tabelitega (kas loevad/kirjutavad neid indeksi kaudu või mitte). Igatahes, eelneva pildi suhtes lisandub vaid üks aspekt - kui palju kirjeid see sõlm meile tõi, ja kui palju see kõrvale heitis (Rows Removed by Filter).
Teie tabelis ei ole sobivat indeksit, teete sellele päringu, see lendab mööda indeksit, langeb Seq Scan… kõik kirjed, välja arvatud üks, olete filtreerinud. Aga miks teil on ööpäevas 100M filtreeritud kirjeid, kas ei oleks parem indeksi kasutusele võtta?

Kõiki sõlmpunkte puudutavaid plaane analüüsides mõistsime, et teatud tüüpilised struktuurid plaanides näevad väga tõenäoliselt kahtlased välja. Arendajale oleks hea öelda: „Sõber, siin loed sa alguses indeksi järgi, siis sorteeri ja lõpuks lõika” — tavaliselt on seal üks rida.
Kõik, kes on selliste patroonidega päringuid teinud, on kindlasti kokku puutunud: „Anna mulle Viime viimane tellimus, selle kuupäev.” Ja kui sul ei ole kuupäeva indeksit või kasutatud indeksis ei ole kuupäeva, astud sa just sellistele „harjastele.”
Aga me ju teame, et need on „harjad” — miks mitte kohe arendajale öelda, mida tal peaks tegema. Seega, kui ta nüüd plaani avab, näeb meie arendaja kohe ilusat pilti vihjetega, kus talle öeldakse: „Sul on siin ja siin probleemid ning need lahenevad nii ja naa.”
Tulemusena on probleemi lahendamiseks vajalik kogemus varasemaga võrreldes kahanenud mitmeid kordi. Selline tööriist meil nüüd on.

Allikas: habr.com
