

Tere.
Otsustasin jagada oma leiutist — mõtete, proovide ja vigade vilju.
Suures plaanis: see pole tegelikult leiutis, muidugi — see peaks olema ammu teada neile, kes tegelevaid rakenduslike andmetöötluse ja süsteemide optimeerimisega, mitte tingimata just andmebaasidega.
Ja: jah, nad teavad, kirjutavad huvitavaid artikleid oma uurimistööde kohta, (UPD.: kommentaarides viidati väga huvitavale projektile: )
Teisest küljest: mul ei tundu, et sarnast lähenemist laialdaselt mainitakse või levitatakse internetis it-spetsialistide, DBA-de seas.
Nii et, asja olemus.
Oletame, et meil on ülesanne: seadistada mingi teenindussüsteem mingiks tööks.
Selle töö kohta on teada: milline see töö on, kuidas kvaliteeti mõõdetakse ja milline on selle kvaliteedi mõõtmise kriteerium.
Samuti oletame, et enam-vähem on teada, kuidas tööd teostatakse (või selle teenindussüsteemiga).
"Üks-kaks" tähendab, et on võimalus valmistada (või kuskilt võtta) tööriist, utiliit või teenus, millega saab süntiseerida ja testida süsteemi testkoormust, mis on piisavalt sarnane sellele, mis tootmises, piisavalt tõhusates tingimustes toimetamiseks.
Ja oletame, et on teada, millised on selle teenussüsteemi kohandamisparameetrite komplektid, millega saab seda süsteemi konfigureerida, selle töö efektiivsuse osas.
Ja milles on probleem — ei ole piisavalt selget arusaama sellest teenussüsteemist, mis võimaldab eksperdil seadistada süsteemi tulevase koormuse jaoks antud platvormil ja saavutada vajalik töö efektiivsus.
Noh. Nii see peaaegu alati on.
Mis siin teha saab.
Esiteks, mis pähe tuleb: vaadata selle süsteemi dokumentatsiooni. Mõista — millised on seal lubatud vahemikud kohandamisparameetrite väärtuste jaoks. Ja näiteks, koordinaatide langemise meetodil, sobitada süsteemi parameetrite väärtusi testides.
St. seada süsteemile mingisugune konfiguratsioon, konkreetse parameetrite väärtuste komplekti kujul.
Esitada testkoormust selle tööriista-utiliidi abil, koormuse generaatoriga.
Ja vaadata suurust — vastust, või süsteemi töö kvaliteedi mõõdikut.
Teise mõttena võib tekkida järeldus, et — see on ju väga pikk protsess.
Nii et: kui seadeparameetreid on palju, kui nende väärtuste ulatus on suur, kui iga eraldi koormustest kestab kaua, siis: jah, see kõik võib võtta vastuvõetamatult palju aega.
Ja siin on, mida saab teada ja meeles pidada.
Võib teada saada seadeparameetrite väärtuste kogum — vektor, nagu mingite väärtuste järjestus.
Iga sellise vektoriga, tingimusel et see vektor ei ole seotud, vastab täiesti määratud mõõdiku väärtus — süsteemi töö kvaliteedi näitaja katsekoormuse all.
St.
Märgime süsteemi konfiguratsiooni vektori kui  , kus
, kus  ; Kus
; Kus  — konfiguratsiooni parameetrite arv, mitu neid parameetreid on.
— konfiguratsiooni parameetrite arv, mitu neid parameetreid on.
Ja mõõdiku väärtus, mis vastab sellele  määrame kui
määrame kui
 , siis saame funktsiooni:
, siis saame funktsiooni: 
Nii et, siis: kõik vähendatakse kohe selle juurde, minu puhul: peaaegu unustatud ülikoolipingilt, funktsiooni ekstreemumi otsimise algoritmid.
Hea, aga siin tekib organisatsiooniline ja praktiline küsimus: millist algoritmi kasutada.
- Mõttes — et ei peaks ise liiga palju käsitsi kodeerima.
- Ja et see töötaks, st leiaks ekstreemi (kui see olemas on), vähemalt kiiremini kui koordinaatide allaminek.
Esimene punkt viitab sellele, et tuleks vaadata mingite keskkondade poole, kus sellised algoritmid on juba realiseeritud ja olemas, mingil kujul, kasutamiseks valmis koodis.
Noh, mulle on teada python ja cran-r
Teine punkt tähendab, et tuleks lugeda tegelikult algoritmide kohta, millised need on, millised on nende nõudmised, tööeripärad.
Ja mida nad pakuvad, võivad olla kasulikud kõrvalmõjud-tulemused, kas otse algoritmist.
Või neid saab saada algoritmi töö tulemustest.
Siin sõltub palju sisetingimustest.
Näiteks, kui mingitel põhjustel, tuleb tulemust kiiremini saada, siis tuleb vaadata gradiente allamäge algoritmide poole, valida mõni nende hulgast.
Või, kui aeg pole nii oluline, võib näiteks kasutada stohhastilise optimeerimise meetodeid, näiteks geneetilist algoritmi.
Pakun kaaluda sellise lähenemise tööd, süsteemi konfiguratsiooni valimiseks geneetilise algoritmi kasutamisega järgmise, ütleme nii: laboritöö käigus.
Algandmed:
- Oletame, et teenindussüsteemiks on:
oracle xe 18c - Oletame, et see teenindab tehingu aktiivsust ja eesmärk on saavutada võimalikult suur subd läbilaskevõime tehingute/s.
- Tehingud võivad olla väga erinevad oma andmete töötlemise ja konteksti poolest.
Lepinguga lepime kokku, et need on tehingud, mis ei töötle suurt hulka tabeli andmeid.
Selles mõttes, et nad ei genereeri undo-andmeid rohkem kui redo ja ei töödelda suuri protsente ridade, suurte tabelite kohta.
Need on tehingud, mis muudavad ühte rida enam-vähem suurtes tabelites, millel on väike arv indekseid selle tabeli kohal.
Sel juhul määrab subd toimetuleku kvaliteet tehingute töötlemisel redo-andmete baasi kvaliteet.
Märkus — kui rääkida just andmebaasi seadistustest.
Sest üldiselt võivad näiteks olla tehingute lukustused, skaneerimise sessioonide vahel, kasutajate töötamise disaini tõttu tabeliandmetega ja/või tabelimudelitega.
Need on kindlasti koormavad tps-mõõdikule ja see on eksogeenne, subd suhtes, tegur: nii on loodud tabelimudel ja töö nende andmetega, et tekivad lukustused.
Seetõttu, eksperimentaalse puhtuse nimel, välistame selle teguri, allpool täpsustan, kuidas täpselt.
- Oletame, et selguse mõttes, et 100% subd-le esitatavatest SQL-käskudest on DML-käskude.
Oletame, et kasutaja töö omadused subd-ga on samad, testides.
Kaasaarvatud: SQL-seansside arv, tabeliandmed, kuidas SQL-seansid nende andmetega töötavad. - Subd töötab järgnevates
FORCE LOGGING,ARCHIVELOGrežiimides. Flashback-andmebaasi režiim on subd tasemel välja lülitatud. - Redo-logid: asuvad eraldi failisüsteemis, eraldi "ketas";
Kogu ülejäänud füüsiline komponent andmebaasis asub teises, eraldi failisüsteemis, eraldi "ketas":
Rohkem teavet labori andmebaasi füüsilise komponendi ülesehituse kohta
SQL> select status||' '||name from v$controlfile;
/db/u14/oradata/XE/control01.ctl
SQL> select GROUP#||' '||MEMBER from v$logfile;
1 /db/u02/oradata/XE/redo01_01.log
2 /db/u02/oradata/XE/redo02_01.log
SQL> select FILE_ID||' '||TABLESPACE_NAME||' '||round(BYTES/1024/1024,2)||' '||FILE_NAME as col from dba_data_files;
4 UNDOTBS1 2208 /db/u14/oradata/XE/undotbs1_01.dbf
2 SLOB 128 /db/u14/oradata/XE/slob01.dbf
7 USERS 5 /db/u14/oradata/XE/users01.dbf
1 SYSTEM 860 /db/u14/oradata/XE/system01.dbf
3 SYSAUX 550 /db/u14/oradata/XE/sysaux01.dbf
5 MONITOR 128 /db/u14/oradata/XE/monitor.dbf
SQL> !cat /proc/mounts | egrep "/db/u[0-2]"
/dev/vda1 /db/u14 ext4 rw,noatime,nodiratime,data=ordered 0 0
/dev/mapper/vgsys-ora_redo /db/u02 xfs rw,noatime,nodiratime,attr2,nobarrier,inode64,logbsize=256k,noquota 0 0Alguses tahtsin nende koormustingimuste korral kasutada SQL-t
Sellel on üks suurepärane omadus, ma tsiteerin autorit:
SLOB-i tuum on 'SLOB meetod'. SLOB meetod on mõeldud platvormide testimiseks
rakenduse konfliktita. Maksimaalset riistvara jõudlust ei saa saavutada
rakendusgraafikus, mis on näiteks piiratud rakenduse lukustamisega või isegi
Oracle Database plokkide jagamisega. Just nii — andmete jagamisel on
plokkides teil on ülejääk! Kuid SLOB — oma vaikimisi kasutuses — on sellsest konfliktist immuunne.
See deklaratsioon: vastab, nii see on.
Mugav on reguleerida SQL-seansside paralleelsuse taset, see on võtmes -t SLOB utiliidi runit.sh osades
Reguleeritakse DML-käskude protsent, selles hulk SQL-e, mida saadetakse DB-le, iga SQL-seanss, parameeter UPDATE_PCT
Erakordselt ja väga mugavalt: SLOB ise, koormuse seansi eel ja järel — valmistab ette statspakke või AWR-snapshote (kuidas on ette nähtud).
Kuid selgus, et SLOB ei toeta SKL-seansside töötlust, kui nende kestus on vähem kui 30 sekundit.
Seetõttu kodeerisin alguses oma, töölisklassi variandi koormajast ja see jäi tööle.
Selgitan koormaja kohta — mida ja kuidas ta teeb, et selgem oleks.
Põhimõtteliselt näeb koormaja välja selline:
Töölise kood
function dotx()
{
local v_period="$2"
[ -z "v_period" ] && v_period="0"
source "/home/oracle/testingredotracе/config.conf"
$ORACLE_HOME/bin/sqlplus -S system/${v_system_pwd} << __EOF__
whenever sqlerror exit failure
set verify off
set echo off
set feedback off
define wnum="$1"
define period="$v_period"
set appinfo worker_&&wnum
declare
v_upto number;
v_key number;
v_tots number;
v_cts number;
begin
select max(col1) into v_upto from system.testtab_&&wnum;
SELECT (( SYSDATE - DATE '1970-01-01' ) * 86400 ) into v_cts FROM DUAL;
v_tots := &&period + v_cts;
while v_cts <= v_tots
loop
v_key:=abs(mod(dbms_random.random,v_upto));
if v_key=0 then
v_key:=1;
end if;
update system.testtab_&&wnum t
set t.object_name=translate(dbms_random.string('a', 120), 'abcXYZ', '158249')
where t.col1=v_key
;
commit;
SELECT (( SYSDATE - DATE '1970-01-01' ) * 86400 ) into v_cts FROM DUAL;
end loop;
end;
/
exit
__EOF__
}
export -f dotxTöölisi käivitakse järgmiselt:
Tööliste käivitamine
echo "testi alustamine, kestus: ${TEST_DURATION}" >> "$v_logfile"
for((i=1;i> "$v_logfile"
dotx "$i" "${TEST_DURATION}" &
done
echo "ootamine..." >> "$v_logfile"
waitJa töötajate tabelid valmistatakse nii:
Tabelite loomine
function createtable() {
source "/home/oracle/testingredotracе/config.conf"
$ORACLE_HOME/bin/sqlplus -S system/${v_system_pwd} << __EOF__
whenever sqlerror continue
set verify off
set echo off
set feedback off
define wnum="$1"
define ts_name="slob"
begin
execute immediate 'drop table system.testtab_&&wnum';
exception when others then null;
end;
/
create table system.testtab_&&wnum tablespace &&ts_name as
select rownum as col1, t.*
from sys.dba_objects t
where rownum> "$v_logfile"K.a. iga töötaja jaoks (praktiliselt: eraldi SQL-seanss andmebaasis) luuakse eraldi tabel, millega töötaja töötab.
Sellega saavutatakse, et andmebaasi seansside vahel ei esine tehingulisi lukustusi.
Iga töötaja: teeb sama, oma tabeliga, kõik tabelid on samad.
Töötajad kõik — teevad tööd sama palju aega.
Ja see tähendas, et näiteks võttis aega, et täpselt juhtuda, ja see ei olnud ainus kord, kui logivahetus toimus.
Sellega seoses tekkisid kõnealused kulud ja mõjud.
Minu puhul - töötajate töö kestus kujunes 8 minutiks.
Statspaki aruande lõik, millel on kirjeldus andmebaasi töö kohta koormuse all.
Andmebaas DB Id Instants Inst Num Käivitamise aeg Väljalase RAC
~~~~~~~~ ----------- ------------ -------- --------------- ----------- ---
2929910313 XE 1 07-sep-20 23:12 18.0.0.0.0 EI
Hosti nimi Platvorm CPUd Südamikud Pesad Mälu (G)
~~~~ ---------------- ---------------------- ----- ----- ------- ------------
billing.izhevsk1 Linux x86 64-bit 2 2 1 15.6
Snapshoot Snap Id Snap Aeg Sessioonid Curs/Sess Kommentaar
~~~~~~~~ ---------- ------------------ -------- --------- ------------------
Algus Snap: 1630 07-sep-20 23:12:27 55 .7
Lõpp Snap: 1631 07-sep-20 23:20:29 62 .6
Möödunud: 8.03 (min) Keskmine aktiivne sess: 8.4
DB aeg: 67.31 (min) DB CPU: 15.01 (min)
Vahemälu suurused Algus Lõpp
~~~~~~~~~~~ ---------- ----------
Puhversüžee: 1,392M Std ploki suurus: 8K
Jagatud bassein: 288M Logi vahemälu: 103,424K
Koormusprofiil Sekundi kohta Tehingu kohta Üksuse kohta Kõne kohta
~~~~~~~~~~~~ ------------------ ----------------- ----------- -----------
DB aeg(s): 8.4 0.0 0.00 0.20
DB CPU(s): 1.9 0.0 0.00 0.04
Uuendamise suurus: 7,685,765.6 978.4
Loogilised lugemised: 60,447.0 7.7
Bloki muutused: 47,167.3 6.0
Füüsilised lugemised: 8.3 0.0
Füüsilised kirjutised: 253.4 0.0
Kasutajakutsed: 42.6 0.0
Töötlemised: 23.2 0.0
Tõsised töötlemised: 1.2 0.0
W/A MB töödeldud: 1.0 0.0
Logimine: 0.5 0.0
Täitmine: 15,756.5 2.0
Tagasitõmbamised: 0.0 0.0
Tehingud: 7,855.1Tagasi laboratoorsete tööde seadmise juurde.
Vaatame, võrdselt teistega, kuidas varieeruda labori andmebaasi parameetrite väärtustes:
- Logigrupi suurus. väärtuste vahemik: [32, 1024] MB;
- Logigruppide arv. väärtuste vahemik: [2,32];
log_archive_max_processesväärtuste vahemik: [1,8];commit_logginglubatakse kahte väärtust:batch|immediate;commit_waitlubatakse kahte väärtust:wait|nowait;log_bufferväärtuste vahemik: [2,128] MB.log_checkpoint_timeoutväärtuste vahemik: [60,1200] sekunditdb_writer_processesväärtuste vahemik: [1,4]undo_retentionväärtuste vahemik: [30;300] sekundittransactions_per_rollback_segmentväärtuste vahemik: [1,8]disk_asynch_iolubatakse kahte väärtust:true|false;filesystemio_optionslubatakse järgmisi väärtusi:none|setall|directIO|asynch;db_block_checkinglubatakse järgmisi väärtusi:OFF|LOW|MEDIUM|FULL;db_block_checksumlubatakse järgmisi väärtusi:OFF|TYPICAL|FULL;
Inimene, kellel on kogemusi oracle andmebaaside hooldamisel, võib kindlasti juba öelda, milliseid ja milliseid väärtusi tuleks määrata, et saavutada suurem tootlikkus andmebaasis, selle andmetöötluse jaoks, mida esindab siin ülalmainitud rakenduskood.
Aga.
Laboratoorse töö eesmärk on näidata, et optimeerimisalgoritm täpsustab meid kiiresti.
Meile jääb vaid vaadata dokumenti, mille kohta saab kohandatud süsteemi seadistada nii palju, kui vaja, et selgitada välja, milliseid parameetreid ja millistes vahemikes muuta.
Samuti tuleb kirjutada kood, millega rakendatakse valitud optimeerimisalgoritmi kohandatud süsteemiga töötamine.
Nii et nüüd koodist.
Ülalpool rääkisin cran-r, st: kõik kohandatud süsteemiga seotud toimingud orkestreeritakse R-skripti kujul.
Tegelik ülesanne, analüüs, mõõdikute väärtuste ja süsteemi oleku vektorite valik: see on pakett GA ()
Pakett ei sobi siinkohal eriti hästi, kuna see ootab vektorite (hromosoomide, kui kasutada paketi termineid) määratlemiseks reaalses arvude komaga esitlemist.
Kuid minu vektor, seadistamisparameetrite väärtustest, on 14 suurust – täisarvud ja stringiväärtused.
Probleemi saab muidugi kergesti vältida, määrates stringiväärtustele mõningad kindlad nummer.
Seega näeb R-skripti peamine osa välja nii:
Kutse GA::ga
cat( "", file=v_logfile, sep="n", append=F)
pSize = 10
elitism_value=1
pmutation_coef=0.8
pcrossover_coef=0.1
iterations=50
gam=GA::ga(type="real-valued", fitness=evaluate,
lower=c(32,2, 1,1,1,2,60,1,30,1,0,0, 0,0), upper=c(1024,32, 8,10,10,128,800,4,300,8,10,40, 40,30),
popSize=pSize,
pcrossover = pcrossover_coef,
pmutation = pmutation_coef,
maxiter=iterations,
run=4,
keepBest=T)
cat( "GA-session is done" , file=v_logfile, sep="n", append=T)
gam@solutionSiin, kasutades madalam ja ülemine alamprogrammi atribuute ga määratakse, põhimõtteliselt, otsingu ruum, mille sees toimub sellise vektori (või vektorite) otsing, mille jaoks saadakse maksimaalne väärtus sobivusfunktsioonist.
ga-alamprogramm otsib, maksimeerides sobivusfunktsiooni.
Nii et, sel juhul, peab sobivusfunktsioon, mõistes vektorit kui parameetrite väärtuste komplekti andmebaasi jaoks, saama mõõdiku andmebaasilt.
See tähendab: kui antud andmebaasi seadistusega ja antud koormusega töötleb andmebaas tehingute arvu sekundis.
Seega, arendades, on vajalik, et sobivusfunktsiooni sees toimuks selline mitmeastmeline käik:
- Sisendi numbri vektori töötlemine — selle muutmine väärtusteks andmebaasi parameetritele.
- Püüd luua määratud arvu redo-rühmi, määratud suurusega. See on siiski katse: see võib osutuda ebaõnnestunuks.
Juba olemasolevad andmebaasi ajakirjerühmad, mingis koguses ja mingis suuruses, tuleb katse puhtuse huvides eemaldada. - Kui eelmine punkt õnnestub: seadistada konfiguratsiooni parameetrite väärtuste põhja (taas: võib esineda tõrkeid).
- Kui eelmine punkt õnnestub: peatada andmebaas, käivitada andmebaas, et uuesti määratud parameetrite väärtused saaksid kehtima. (taas: võib esineda tõrkeid).
- Kui eelmine punkt õnnestub: teostada koormustest, et saada mõõdik andmebaasilt.
- Tagasi tuua andmebaas algsesse seisundisse, st eemaldada täiendavad ajakirjerühmad ja taastada andmebaasi algne konfiguratsioon.
Füüsika-funktsiooni kood
evaluate=function(p_par) {
v_module="evaluate"
v_metric=0
opn=NULL
opn$rg_size=round(p_par[1],digit=0)
opn$rg_count=round(p_par[2],digit=0)
opn$log_archive_max_processes=round(p_par[3],digit=0)
opn$commit_logging="BATCH"
if ( round(p_par[4],digit=0) > 5 ) {
opn$commit_logging="IMMEDIATE"
}
opn$commit_logging=paste("'", opn$commit_logging, "'",sep="")
opn$commit_wait="WAIT"
if ( round(p_par[5],digit=0) > 5 ) {
opn$commit_wait="NOWAIT"
}
opn$commit_wait=paste("'", opn$commit_wait, "'",sep="")
opn$log_buffer=paste(round(p_par[6],digit=0),"m",sep="")
opn$log_checkpoint_timeout=round(p_par[7],digit=0)
opn$db_writer_processes=round(p_par[8],digit=0)
opn$undo_retention=round(p_par[9],digit=0)
opn$transactions_per_rollback_segment=round(p_par[10],digit=0)
opn$disk_asynch_io="true"
if ( round(p_par[11],digit=0) > 5 ) {
opn$disk_asynch_io="false"
}
opn$filesystemio_options="none"
if ( round(p_par[12],digit=0) > 10 && round(p_par[12],digit=0) 20 && round(p_par[12],digit=0) 30 ) {
opn$filesystemio_options="asynch"
}
opn$db_block_checking="OFF"
if ( round(p_par[13],digit=0) > 10 && round(p_par[13],digit=0) 20 && round(p_par[13],digit=0) 30 ) {
opn$db_block_checking="FULL"
}
opn$db_block_checksum="OFF"
if ( round(p_par[14],digit=0) > 10 && round(p_par[14],digit=0) 20 ) {
opn$db_block_checksum="FULL"
}
v_vector=paste(round(p_par[1],digit=0),round(p_par[2],digit=0),round(p_par[3],digit=0),round(p_par[4],digit=0),round(p_par[5],digit=0),round(p_par[6],digit=0),round(p_par[7],digit=0),round(p_par[8],digit=0),round(p_par[9],digit=0),round(p_par[10],digit=0),round(p_par[11],digit=0),round(p_par[12],digit=0),round(p_par[13],digit=0),round(p_par[14],digit=0),sep=";")
cat( paste(v_module," try to evaluate vector: ", v_vector,sep="") , file=v_logfile, sep="n", append=T)
rc=make_additional_rgroups(opn)
if ( rc!=0 ) {
cat( paste(v_module,"make_additional_rgroups failed",sep="") , file=v_logfile, sep="n", append=T)
return (0)
}
v_rc=0
rc=set_db_parameter("log_archive_max_processes", opn$log_archive_max_processes)
if ( rc != 0 ) { v_rc=1 }
rc=set_db_parameter("commit_logging", opn$commit_logging )
if ( rc != 0 ) { v_rc=1 }
rc=set_db_parameter("commit_wait", opn$commit_wait )
if ( rc != 0 ) { v_rc=1 }
rc=set_db_parameter("log_buffer", opn$log_buffer )
if ( rc != 0 ) { v_rc=1 }
rc=set_db_parameter("log_checkpoint_timeout", opn$log_checkpoint_timeout )
if ( rc != 0 ) { v_rc=1 }
rc=set_db_parameter("db_writer_processes", opn$db_writer_processes )
if ( rc != 0 ) { v_rc=1 }
rc=set_db_parameter("undo_retention", opn$undo_retention )
if ( rc != 0 ) { v_rc=1 }
rc=set_db_parameter("transactions_per_rollback_segment", opn$transactions_per_rollback_segment )
if ( rc != 0 ) { v_rc=1 }
rc=set_db_parameter("disk_asynch_io", opn$disk_asynch_io )
if ( rc != 0 ) { v_rc=1 }
rc=set_db_parameter("filesystemio_options", opn$filesystemio_options )
if ( rc != 0 ) { v_rc=1 }
rc=set_db_parameter("db_block_checking", opn$db_block_checking )
if ( rc != 0 ) { v_rc=1 }
rc=set_db_parameter("db_block_checksum", opn$db_block_checksum )
if ( rc != 0 ) { v_rc=1 }
if ( rc!=0 ) {
cat( paste(v_module," can not startup db with that vector of settings",sep="") , file=v_logfile, sep="n", append=T)
rc=stop_db("immediate")
rc=create_spfile()
rc=start_db("")
rc=remove_additional_rgroups(opn)
return (0)
}
rc=stop_db("immediate")
rc=start_db("")
if ( rc!=0 ) {
cat( paste(v_module," can not startup db with that vector of settings",sep="") , file=v_logfile, sep="n", append=T)
rc=stop_db("abort")
rc=create_spfile()
rc=start_db("")
rc=remove_additional_rgroups(opn)
return (0)
}
rc=run_test()
v_metric=getmetric()
rc=stop_db("immediate")
rc=create_spfile()
rc=start_db("")
rc=remove_additional_rgroups(opn)
cat( paste("result: ",v_metric," ",v_vector,sep="") , file=v_logfile, sep="n", append=T)
return (v_metric)
}Nii on, kogu töö: toimub sobivuse funktsioonis.
ga-algoritm, teostab vektorite töötlemist, või õigemini öelda — kromosoome.
Kus on meie jaoks kõige olulisem: kromosoomide selektsioon selliste geenidega, mille puhul sobivuse funktsioon annab suuremaid väärtusi.
See on sisuliselt protsess, mille käigus otsitakse optimaalse kromosoomide komplekti vektoriga N-mõõtmelises otsinguruumis.
Äärmiselt arusaadav, üksikasjalik , koos R-koodi näidete ja geneetilise algoritmi tööga.
Eriliselt märkida kaks tehnilist momenti.
Abikutsed, funktsioonist evaluate, näiteks peatamine-käivitamine, andmete määramine alamandmebaasi väärtuseks, teostatakse cran-r funktsiooni system2
Mille kaudu: kutsub välja mingi skripti või käsu.
Näiteks:
set_db_parameter
set_db_parameter=function(p1, p2) {
v_module="set_db_parameter"
v_cmd="/home/oracle/testingredotracе/set_db_parameter.sh"
v_args=paste(p1," ",p2,sep="")
x=system2(v_cmd, args=v_args, stdout=T, stderr=T, wait=T)
if ( length(attributes(x)) > 0 ) {
cat(paste(v_module," failed with: ",attributes(x)$status," ",v_cmd," ",v_args,sep=""), file=v_logfile, sep="n", append=T)
return (attributes(x)$status)
}
else {
cat(paste(v_module," ok: ",v_cmd," ",v_args,sep=""), file=v_logfile, sep="n", append=T)
return (0)
}
}Teine moment — string, evaluate funktsioonid, säilitades mõõtme konkreetse väärtuse ja vastava seadistuse suuna logifailis:
cat( paste("tulemus: ",v_metric," ",v_vector,sep="") , file=v_logfile, sep="n", append=T)See on oluline, sest sellest andmehulgast saab lisainfot selle kohta, milline seadistuse suuna komponent rohkem või vähem mõjutab mõõtme väärtust.
Teisisõnu: saab läbi viia atribuudi olulisuse analüüsi.
Nii et, mis võiks välja tulla.
Diagrammina, kui järjestada testid mõõtme kasvamise järgi, on pilt järgmine:
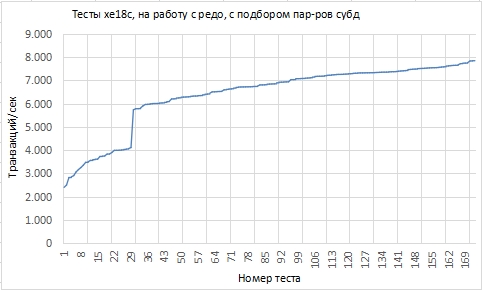
Mõned andmed, mis vastavad mõõtme äärmuslikele väärtustele:

Siin, tulemuste ekraanipildil, täpsustan: seadistuse suuna väärtused on esitatud funktsioonide koodi mõistetena, mitte parametriliste väärtuste nimekirjana või vahemike järgi, nagu ma tekstis eespool formuleerisin.
Noh, see, kas see on palju või vähe, ~8 tuhat tps: on eraldi küsimus.
Laboratoorse töö raames ei ole see number oluline, oluline on dünaamika, kuidas see väärtus muutub.
Dünaamika siin on hea.
On ilmne, et vähemalt üks tegur, mis oluliselt mõjutab mõõtme väärtust, ga-algoritm, ei suutnud kromosoomivektoreid läbi töötledes ebaõnnestuda.
Arvestades kõverate väärtuste üsna elavat dünaamikat, on veel vähemalt üks tegur, mis, kuigi märksa väiksem, mõjutab.
Siin on vajalik attribute-importance analüüs, et mõista: millised atribuudid (selles kontekstis — seadistusvektor komponentide) ja kui palju nad mõjutavad mõõdiku väärtust.
Ja sellest infost: mõista — millised tegurid mõjutavad oluliste atribuutide muutusi.
Tehtud attribute-importance seda saab teha erinevatele viisidele.
Mulle, nende eesmärkide jaoks, meeldib algoritm randomForest sama nimega R-paketist (mida ma mõistan, kuidas see suures plaanis töötab ja selle lähenemine atribuutide tähtsuse hindamisele, loob mingi mudeli sõltuvuse vastusmuutujast atribuutidest.)
randomForest, как я понимаю его работу вообще и его подход к оценке важности атрибутов в частности, строит некую модель зависимости переменной-отклика, от атрибутов.
Meie juhul on vastusmuutuja — mõõdik, mida saadakse andmebaasidest koormustestide käigus: tps;
Ja atribuudid on — seadistusvektori komponendid.
Nii et randomForest hindab iga mudeli atribuudi tähtsust kahe numbriga: %IncMSE — kuidas selle atribuutide olemasolu/puudumine mudelis muudab selle mudeli MSE kvaliteeti (Mean Squared Error);
IncNodePurity on number, which indicates how well a dataset of observations can be divided based on the values of this attribute, so that one part contains data with one specific value of the explained metric, while the other part contains another value of the metric.
So, i.e.: how much of a classification attribute this is (the most clear explanation related to random forests I’ve seen in Russian). ).
Working-peasant R code for processing a dataset with load test results:
x=NULL
v_data_file=paste('/tmp/data1.dat',sep="")
x=read.table(v_data_file, header = TRUE, sep = ";", dec=",", quote = ""'", stringsAsFactors=FALSE)
colnames(x)=c('metric','rgsize','rgcount','lamp','cmtl','cmtw','lgbffr','lct','dbwrp','undo_retention','tprs','disk_async_io','filesystemio_options','db_block_checking','db_block_checksum')
idxTrain=sample(nrow(x),as.integer(nrow(x)*0.7))
idxNotTrain=which(! 1:nrow(x) %in% idxTrain )
TrainDS=x[idxTrain,]
ValidateDS=x[idxNotTrain,]
library(randomForest)
#mtry=as.integer( sqrt(dim(x)[2]-1) )
rf=randomForest(metric ~ ., data=TrainDS, ntree=40, mtry=3, replace=T, nodesize=2, importance=T, do.trace=10, localImp=F)
ValidateDS$predicted=predict(rf, newdata=ValidateDS[,colnames(ValidateDS)!="metric"], type="response")
sum((ValidateDS$metric-ValidateDS$predicted)^2)
rf$importanceYou can manually adjust the hyperparameters of the algorithm and, based on the model quality, select a model that performs better predictions on the validation dataset.
Saab kirjutada mingi funktsioon selle töö jaoks (muide — jälle, mingil optimeerimisalgoritmil).
Saab kasutada R-paketti caret, ei ole oluline.
Kokkuvõtteks, antud juhul on tulemuseks järgmine, et hinnata atribuutide olulisuse astet:
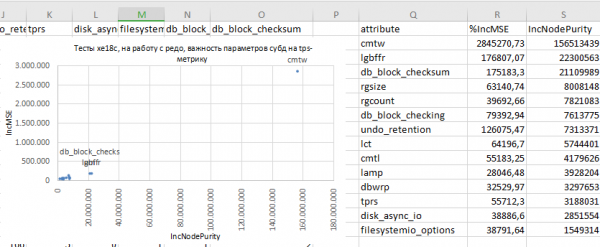
Nii et, saab alustada globaalsete mõtlemisega:
- Tuleb välja, et kõige olulisem, antud testimisolukordades, on parameeter
commit_wait
Tehniliselt määrab see io-operatsiooni kirjutamisrežiimi redo-andmete logibufrisse, current-logigruppi: sünkroonne või asünkroonne.
Väärtusnowaitmille puhul on peaaegu vertikaalne, korduv väärtuse tps-mõõdikute tõus: see on io asünkroonsuse sisselülitamine redo-gruppides.
Erinev küsimus — kas peaks nii tegema tootmisandmebaasis või mitte. Siin piirduksin ainult konstateerimisega: see on oluline tegur. - On loogiline, et log-bufri suurus on andmebaasi jaoks tähtsate tegurite hulgas.
Mida väiksem on log-bufri suurus, seda vähem on selle puhverdamisvõime, seda sagedamini juhtuvad selle ülevoolud ja/või ei ole võimalik eraldada seal vaba ala uute redo-andmete partii jaoks.
Seega: logi-buffer'i ruumi määramine ja/või redo-andmete talletamine redo-gruppidesse seotud viivitused.
Need viivitused peaksid loomulikult mõjutama ja mõjutavad andmebaasi tehingute läbilaskevõimet. - Parameeter
db_block_checksum: noh, see on ka üldiselt arusaadav — tehingute töötlemine toob kaasa darit-blokkide tekkimise andmebaasi vahemälus.
Need, kui andmeblokkide kontrollsumma kontrollimine on sisse lülitatud, peab andmebaas töötlema — arvutama neid kontrollsummasid andmebloki sisust ja võrreldes neid, mis on kirjas andmeploki päises: kas need kattuvad/ei kattu.
Selline töö ei saa jällegi mitte venitada andmete töötlemist ja vastavalt sellele on parameeter ja mehhanism, mida see parameeter määrab, olulised.
Seetõttu pakub tootja selle parameetri dokumentatsioonis erinevaid väärtusi ja märgib, et - jah, mõju on olemas, kuid, noh, erinevad väärtused, sealhulgas "välja lülitatud" ja erinev mõju, saate valida.
Noh ja globaalne järeldus.
Lähteviis näib üldiselt töötavat.
See on täiesti piisav, et varases etapis koormustestimise mingisuguse teenusesüsteemi jaoks oleks võimalik valida selle süsteemi jaoks optimaalse konfiguratsiooni koormuse all, süvenemata eriti süsteemi konfiguratsiooni üksikasjadesse.
Kuid see ei välista täielikult — vähemalt tasemel arusaamise: "reguleerimisnuppudest" ja lubatud pöördevahemikest nende nuppude jaoks peab süsteem olema teadlik.
Edasi liikudes suudab lähenemine suhteliselt kiiresti leida süsteemi optimaalse konfiguratsiooni.
Ja testimise tulemuste põhjal on võimalik saada teavet süsteemi töö kvaliteedi mõõdikute ja süsteemi seadistamise parameetrite seoste kohta.
See peaks muidugi soodustama sügava arusaamise tekkimist süsteemist, selle toimimisest, vähemalt antud koormuse korral.
Praktiliselt tähendab see: kulude jaotamine süvenemise ning süsteemi seadistamise testimise ettevalmistamise vahel.
Erakordselt on oluline selles lähenemises süsteemi testimise adekvaatsuse aste tingimustele, milles see töötab oma tootmisüksteemis.
Aitäh teie tähelepanu ja aja eest.
Allikas: habr.com
