


Apache Cassandra and the need to operate it within a Kubernetes-based infrastructure is something we encounter regularly. In this article, we will share our vision of the necessary steps, criteria, and existing solutions (including an overview of operators) for migrating Cassandra to K8s.
«Who can manage a woman can also manage a state»
So, who is Cassandra? It is a distributed storage system designed to handle large volumes of data while ensuring high availability without a single point of failure. The project hardly needs a lengthy introduction, so I will mention only the main features of Cassandra that will be relevant to this article:
- Cassandra is written in Java.
- The topology of Cassandra includes several levels:
- Node — a single deployed instance of Cassandra;
- Rack — a group of Cassandra instances combined by some criterion, located in the same data center;
- Datacenter — a collection of all groups of Cassandra instances located in a single data center;
- Cluster — a collection of all data centers.
- To identify a node, Cassandra uses an IP address.
- Andmete salvestamise ja lugemise kiirusel hoiab Cassandra osa andmeid operatiivmälu.
Nüüd — Kubernetes'i potentsiaalsele üleviimisele.
Üleviimise kontrollnimekiri
Rääkides Cassandra migratsioonist Kubernetes'i, loodame, et üleviimisega muutub haldamine mugavamaks. Mis on selleks vajalik ja mis aitab?
1. Andmete salvestus
Kuidas juba mainitud, hoiab Cassandra osa andmeid operatiivmälu — Memtable. Kuid on ka teine osa andmeid, mis salvestatakse kettale - formaadis SSTable. Nendele andmetele lisandub üksus Commit Log — kõikide tehingute salvestused, mis samuti salvestatakse kettale.
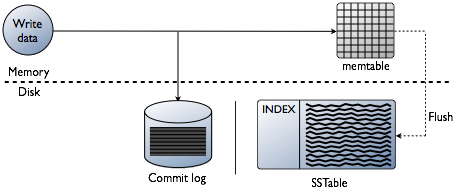
Cassandra andmete salvestamise tehingute skeem
Kubernetesis saame andmete salvestamiseks kasutada PersistentVolume'i. Tänu välja töötatud mehhanismidele muutub andmetega töö tegemine Kubernetes'is iga aastaga üha lihtsamaks.
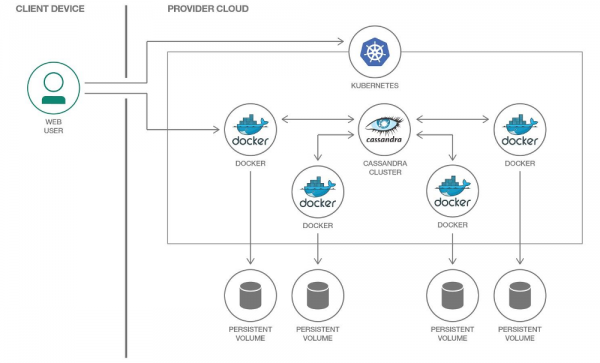
Iga Cassandra pod'i jaoks eraldame oma PersistentVolume'i
Oluline on märkida, et Cassandra impliciteerib andmete replikeerimist, pakkudes selleks sisseehitatud mehhanisme. Seetõttu, kui koostate Cassandra klastri suure hulga sõlmedega, ei ole vaja kasutada andmete salvestamiseks jaotatud süsteeme nagu Ceph või GlusterFS. Sellisel juhul on mõistlik salvestada andmed sõlme kettale, kasutades või mountimist hostPath.
Teine küsimus on, kui soovite iga feature haru jaoks arendajatele eraldi keskkonda luua. Sellisel juhul oleks õige lähenemine tõsta üles üks Cassandra sõlm ja hoida andmed jaotatud salvestuses, st mainitud Ceph ja GlusterFS saavad teie valikuks. Siis on arendajal kindel tunne, et ta ei kaota testandmeid isegi siis, kui üks Kubernetes klastri sõlm kaob.
2. Jälgimine
Peaaegu alternatiivitu valik jälgimise rakendamiseks Kuberneteses on Prometheus (oleme sellest üksikasjalikult rääkinud ). Kuidas on Cassandra olukord metrikate eksportijatega Prometheusele? Ja mis on veelgi olulisem, kuidas on sobivate dashboard'idega Grafanal?
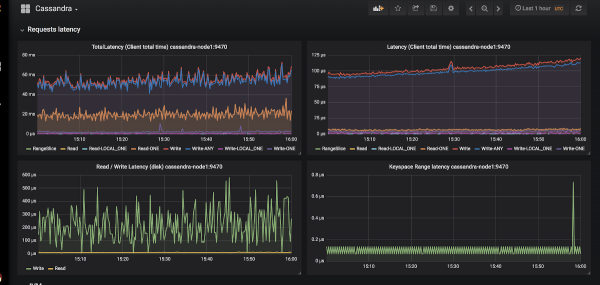
Grafana graafikute välimuse näide Cassandra jaoks
Ekspordereid on kokku kaks: ja .
Valisime esmase, kuna:
- JMX Exporter kasvab ja areneb, samas kui Cassandra Exporter ei suutnud saada piisavat tuge kogukonnalt. Cassandra Exporter ei toeta endiselt enamikku Cassandra versioonidest.
- Seda saab käivitada javaagentina, lisades lipu
-javaagent:/cassandra-exporter.jar=--listen=:9180. - Selle jaoks on olemas , mis ei ühildu Cassandra Exporteriga.
3. Kubernetes primitiivide valik
Vastavalt eeltoodud Cassandra klastri struktuurile proovime tõlkida kõik, mis seal on, Kubernetes terminoloogiaks:
- Cassandra Node → Pod
- Cassandra Rack → StatefulSet
- Cassandra Datacenter → StatefulSet'ide rühm
- Cassandra Cluster → ???
Tundub, et puudub mingi täiendav entiteet, et haldada kogu Cassandra klastrit korraga. Kuid kui midagi on puudu, saame selle luua! Kuberneteses on selleks ette nähtud isiklike ressurside määramise mehhanism — .
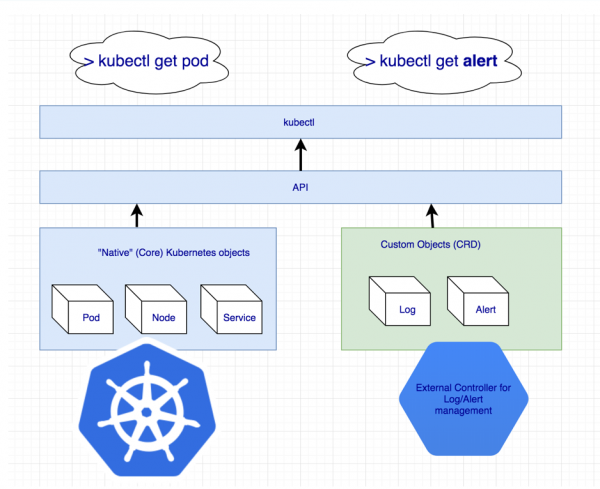
Lisaressursside deklareerimine logide ja teavituste jaoks
Aga iseenesest ei tähenda Custom Resource midagi: selleks on vajalik kontroller. Võib-olla tuleb appi kutsuda …
4. Pod'ide identifitseerimine
Eelmises punktis leppisime kokku, et üks Cassandra sõlm vastab ühele pod'ile Kuberneteses. Kuid pod'ide IP-aadressid erinevad iga kord. Ja Cassandra sõlm on identifitseeritud just IP-aadressi alusel… See tähendab, et iga pod'i kustutamise järel lisab Cassandra klaster endasse uue sõlme.
Väljapääs on olemas, ja isegi rohkem kui üks:
- Saame jälgida hostide identifikaatoreid (UUID-sid, mis üheselt tuvastavad Cassandra instantsid) või IP-aadresse ning salvestada kõik need mingitesse struktuuridesse / tabelitesse. Sellel meetodil on kaks peamist puudust:
- Risk, et kahe sõlme kokkuvarisemise korral tekib võistlusolukord. Pärast taastumist lähevad Cassandra sõlmed korraga IP-aadressi tabelist küsima ja konkureerivad sama ressursi pärast.
- Kui Cassandra sõlm on oma andmed kaotanud, ei saa me seda enam tuvastada.
- Teine lahendus näib olevat väike hack, kuid siiski: saame luua iga Cassandra sõlme jaoks Service'i ClusterIP-ga. Selle rakenduse probleemid:
- Kui Cassandra klastris on väga palju sõlmi, peame looma väga palju Service'e.
- ClusterIP funktsionaalsus on реализован через iptables. See võib muutuda probleemiks, kui Cassandra klastris on palju (1000... või isegi 100?) sõlme. Kuigi suudab selle probleemi lahendada.
- Kolmas lahendus on kasutada Cassandra sõlmede jaoks sõlmede võrku, mitte eraldi pod'ide võrku, aktiveerides seadistuse
hostNetwork: true. See meetod seab teatud piirangud:- Sõlmede asendamine. Uuel sõlmel peab tingimata olema sama IP-aadress kui eelmisel (pilvteenustes nagu AWS, GCP on see peaaegu võimatu);
- Kas kasutades klastrisõlmede võrgustikku, hakkame konkureerima võrguresursside üle. Seega on ühe Cassandra klastrisõlme peale rohkem kui ühte pod’i paigutamine probleemne.
5. Varukoopiad
Tahame salvestada ühte Cassandra sõlme täielikku andmeversiooni graafikuga. Kubernetes pakub mugavat võimalust , kuid siin takistab meid Cassandra ise.
Kordan, et osa andmeid salvestab Cassandra mällu. Täieliku varukoopia tegemiseks tuleb andmed mälust (Memtables) viia kettale (SSTables). Sel hetkel lakkab Cassandra sõlm vastuvõtmast ühendusi, eemaldudes täielikult klastrist.
Pärast seda tehakse varukoopia (snapshot) ja salvestatakse skeem (keyspace). Siin selgub, et lihtsalt varukoopia ei aita: tuleb salvestada andmete identifikaatorid, mille eest Cassandra sõlm vastutas - need on spetsiaalsed tokenid.
Tokenite jaotamine, et määrata, milliste andmete eest Cassandra sõlmed vastutavad
Näidis Google'i Cassandra varukoopia skriptist Kubernetesis on saadaval aadressil . Ainus moment, mida skript ei arvesse võta, on andmete nullimine sõlmele enne snapshot'i tegemist. See tähendab, et varukoopia ei tehta hetkeolukorra jaoks, vaid natuke varem. Kuid see aitab mitte viia sõlme välja tööst, mis tundub väga loogiline.
set -eu
if [[ -z "$1" ]]; then
info "Palun esitage keyspace"
exit 1
fi
KEYSPACE="$1"
result=$(nodetool snapshot "${KEYSPACE}")
if [[ $? -ne 0 ]]; then
echo "Viga snapshot'i tegemisel"
exit 1
fi
timestamp=$(echo "$result" | awk '/Snapshot directory: / { print $3 }')
mkdir -p /tmp/backup
for path in $(find "/var/lib/cassandra/data/${KEYSPACE}" -name $timestamp); do
table=$(echo "${path}" | awk -F "[/-]" '{print $7}')
mkdir /tmp/backup/$table
mv $path /tmp/backup/$table
done
tar -zcf /tmp/backup.tar.gz -C /tmp/backup .
nodetool clearsnapshot "${KEYSPACE}"Näidis bash-skript varukoopia tegemiseks ühelt Cassandra sõlmelt
Valmis lahendused Cassandra jaoks Kuberneteses
Mida üldse praegu kasutatakse Cassandra käivitamiseks Kuberneteses ja mis neist sobib kõige paremini antud nõuetele?
1. Lahendused StatefulSetide või Helm-chartide põhjal
Kasutada StatefulSetide põhifunktsioone Cassandra klastri käitamiseks on hea valik. Helm-chartide ja Go mallide abil saab kasutajale pakkuda paindlikku liidest Cassandra käivitamiseks.
Tavaliselt töötab see normaalselt... kuni juhtub midagi ootamatut — näiteks sõlme rike. Kubernetes'i põhivahendid ei suuda lihtsalt arvesse võtta kõiki ülaltoodud eripära. Lisaks on see lähenemine väga piiratud, kui tegemist on keerulisemate rakendustega: sõlmede vahetus, varundamine, taastamine, monitooring jne.
Esindajad:
- ;
- .
Mõlemad chart'id on võrdselt head, kuid on siiski ülaltoodud probleemidele vastuvõtlikud.
2. Lahendused Kubernetes Operator'i põhjal
Need rohkem huvitavaid valikuvõimalusi, kuna need pakuvad laialdasi võimalusi klastrite haldamiseks. Cassandra operaatori kujundamine, nagu iga teise andmebaasi puhul, näeb hea mustrina välja nagu Sidecar Controller CRD:
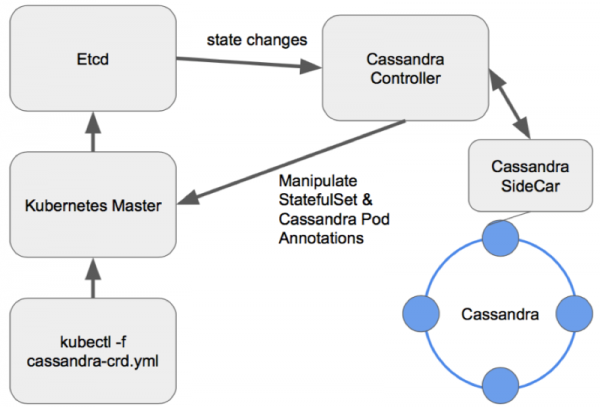
Sõlmede haldamise skeem õigesti projekteeritud Cassandra operaatoris
Vaatame olemasolevaid operaatorite.
1. Instaclustri Cassandra operaator
- Valmidus: Alpha
- Litsents: Apache 2.0
- Tehnoloogia: Java
See on tõeliselt paljutõotav ja aktiivselt arenev projekt ettevõttelt, mis pakub hallatavaid Cassandra juurutusi. Nagu eelpool kirjeldatud, kasutavad nad sidecar konteinerit, mis aktsepteerib käske HTTP kaudu. Kirjutanud Java keeles, seega tal puudub mõnikord keerukam funktsionaalsus client-go teegist. Samuti ei toeta operaator erinevaid Rack'e ühe Andmekeskuse jaoks.
Kuid operaatoril on sellised eelised nagu monitooringu tugi, klastrite kõrgema taseme haldamine CRD abil ja isegi varukoopiate tegemise dokumentatsioon.
2. Jetstacki Navigator
- Valmidus: Alpha
- Litsents: Apache 2.0
- Tehnoloogia: Golang
DB-as-a-Service'i kasutamiseks mõeldud operaator. Sellel hetkel toetab see kahte andmebaasi: Elasticsearch ja Cassandra. Sellel on mitmeid huvitavaid lahendusi, nagu andmebaasi juurdepääsukontroll RBAC kaudu (selleks käivitub omaette navigator-apiserver). Huvitav projekt, millele tasub tähelepanu pöörata, kuigi viimane commit tehti poolteist aastat tagasi, mis vähendab selgelt selle potentsiaali.
3. Cassandra-operator vgkowski poolt
- Valmidus: Alpha
- Litsents: Apache 2.0
- Tehnoloogia: Golang
Seda ei hakata tõsiselt võtma, kuna viimane commit repositooriumisse oli üle aasta tagasi. Operaatori arendamine on hüljatud: viimane välja kuulutatud Kubernetes versioon, mida peetakse toetatud, on 1.9.
4. Cassandra-operator Rook'i poolt
- Valmidus: Alpha
- Litsents: Apache 2.0
- Tehnoloogia: Golang
Operaator, mille areng ei käi nii kiiresti, kui sooviks. Sellel on hästi läbi mõeldud CRD struktuur klastri haldamiseks, lahendatakse sõlmede tuvastamise probleem Service'i abil koos ClusterIP'ga (see sama 'hakk') ... aga see on selline hetkeline hetk. Vidinaid ja varukoopiaid ei ole praegu väljakujunenud (muide, vidinate ülevaatamisega tegeleme me ). Huvitav fakt on see, et selle operaatori abil on võimalik käivitada ka ScyllaDB.
NB: Selle operaatori väikeste kohandustega oleme kasutanud ühes meie projektis. Probleeme operaatori tööga ei ole täheldatud kogu kasutusaja (~4 kuud).
5. CassKop Orange'ilt
- Valmidus: Alpha
- Litsents: Apache 2.0
- Tehnoloogia: Golang
Selle nimekirja noorim operaator: esimene kommit tehti 23. mail 2019. Juba praegu on tal arsenalis suur hulk funktsioone meie nimekirjast, millega saab tutvuda projekti repos. Operaator on loodud populaarse operator-sdk baasil. Toetab «karbist väljas» jälgimist. Peamine erinevus teistest operaatoritest on , mis on realiseeritud Pythonis ja mida kasutatakse Cassandra sõlmede vaheliseks suhtlemiseks.
Järeldused
Cassandra edasiviimise lähenemiste ja võimalike variantide arv Kubernetesesse räägib enda eest: teema on nõutud.
Praegusel etapil võib proovida midagi ülaltoodust oma riski ja vastutuse all: ükski arendaja ei garanteeri 100% töökindlust oma lahenduses tootmiskeskkonnas. Kuid juba nüüd näevad paljud tooted välja lubavad, et neid tasub proovida arendusstandardites.
Arvan, et tulevikus tuleb see naine laeva peale õigel ajal!
P.S.
Lugege ka meie blogist:
- «»;
- «»;
- «»;
- «».
Allikas: habr.com
