

Sissejuhatus
Mõni aeg tagasi sain ülesande luua vigadeta klaster , mis töötab mitmes andmekeskuses, mis on ühendatud kiudoptilise kaabliga ühes linnas, ja suudab taluda ühte andmekeskust puudutavat riket (nt elektrikatkestus). Vigadeta funktsionaalsuse tagamiseks valisin , kuna see on RedHati ametlik lahendus vigadeta klastrite loomiseks. Selle eeliseks on, et RedHat tagab selle toe, ja et see on universaalne (modulaarne) lahendus. Selle abil on võimalik tagada vigadeta mitte ainult PostgreSQL-ile, vaid ka teistele teenustele, kasutades kas standardmooduleid või luues neid konkreetsete vajaduste jaoks.
Selle lahenduse kohta tekkis õigustatud küsimus: kui tõrkekindel on tõrkekindel klaster? Selle uurimiseks koostasin katse seadme, mis simuleerib erinevaid tõrkeid klastrite sõlmedes, ootab taastumist, taastab tõrkena töötanud sõlme ja jätkab testimist tsüklis. Esialgu nimetati seda projekti hapgsql, kuid aja jooksul hakkas mind ärritama nimi, milles on ainult üks vokaal. Seetõttu hakkan tõrkekindlaid andmebaase (ja float IP, mis neile viitavad) nimetama krogan (iseloom arvutimängust, kellel on kõik olulised organid duplitseeritud), ja sõlmed, klastrid ning kogu projekt — tuchanka (planeet, kus kroganid elavad).
Praegu on juhtkond lubanud . README tõlgitakse peagi inglise keelde (sest oodatakse, et põhitarbijad oleksid Pacemakeri ja PostgreSQL arendajad), ja vana venekeelne README otsustasin osaliselt vormistada selle artikli kujul.

Klastrid paigutatakse virtuaalmasinatele . Kokku luuakse 12 virtuaalset masinat (kokku 36GiB), mis moodustavad 4 talitushäiret kestvat klusterit (erinevad variandid). Esimene kaks klastrit koosnevad kahest PostgreSQL serverist, mis asuvad erinevates andmekeskustes, ja ühest serverist witness c quorum device (mis on paigutatud odavale virtuaalmasinale kolmandas andmekeskuses), mis lahendab ebamugavustunde 50%/50%, andes oma hääle ühele osapoolele. Kolmas klaster asub kolmes andmekeskuses: üks peamine, kaks alam, ilma quorum device. Neljas klaster koosneb neljast PostgreSQL serverist, kaks igas andmekeskuses: üks peamine, teised replikad, ja kasutab samuti witness c quorum device. Neljas talub kahe serveri või ühe andmekeskuse riket. See lahendus võib vajadusel ulatuda suuremale arvule replikatele.
Ajavahe teenus on samuti ümber seadistatud talitushäirete vältimiseks, kuid seal kasutatakse meetodit, mille nimi on ntpd (orphan mode). Ühine server witness täidab keskses NTP serveri rolli, jagades oma aega kõigile klastritele, seeläbi sünkroniseerides kõik serverid üksteisega. Kui witness kui see ebaõnnestub või isoleeritakse, hakkab klastris üks serveritest oma aega jagama. Abistav vahemälu HTTP proxy on samuti üles tõstetud witness, mille abil ülejäänud virtuaalmasinad pääsevad juurde Yum-repositooriumidele. Tegelikult, nagu täpne aeg ja proksid, paigutatakse need tõenäoliselt eraldi serveritesse, kuid katsetes nad asuvad witness ainult virtuaalmasinate arvu ja ruumi kokkuhoiu eesmärgil.
Versioonid
v0. Toimib CentOS 7 ja PostgreSQL 11 peal VirtualBox 6.1-s.
Klastri struktuur
Kõik klastrid on mõeldud paiknema mitmes andmekeskuses, ühendatud ühe tasase võrku ja peavad taluma ühe andmekeskuse rikke või võrgu isoleerimist. Seetõttu ei ole võimalik kasutada kaitseks split-brain standardi tehnoloogiat Pacemaker, mis tuntakse STONITH (Shoot The Other Node In The Head) või fencing. Selle sisu seisneb selles, et kui klastris olevad sõlmed hakkavad kahtlema, et mõne sõlmega on midagi valesti, et see ei reageeri või käitub ebaõigesti, siis nad sunnivad selle väliste seadmete, näiteks IPMI juhtimiskaardi või UPS-i kaudu välja lülitama. Kuid see töötab ainult siis, kui üksikserveri rikke korral IPMI või UPS jätkab töötamist. Siin on ette nähtud kaitse palju katastroofilisema rikke eest, kui kogu andmekeskus kaotab, näiteks voolu. Ja sellise rikke korral ei tööta ka stonith-seadmed (IPMI, UPS jne) samuti.
Selle asemel põhineb süsteem kvoorumil. Kõigil sõlmedel on hääl ja töötada saavad ainult need, mis näevad rohkem kui poole kõigist sõlmedest. Seda arvu, mis on "pool+1", nimetatakse kvorum. Kui kvoorumit ei saavutata, siis otsustab sõlm, et ta asub võrguisolatsioonis ja peab välja lülitama oma ressursid, st see on selline kaitse split-brain. Kui see tarkvara, mis vastutab selle käitumise eest, ei toimi, siis peab tööle hakkama watchdog, näiteks IPMI baasil.
Kui sõlmede arv on paaris (kluster kahes andmekeskuses), võib tekkida nn ebamugavus 50%/50% (viiskümmend viiskümmend), kui võrgu isolatsioon jagab kluster täpselt pooleks. Seetõttu lisatakse paarisarvuliste sõlmede jaoks quorum device — madala nõudlikkusega demon, mida saab käivitada odavaimal virtuaalmudelis kolmandas andmekeskuses. Ta annab oma hääle ühele segmentidest (mida ta näeb), lahendades seeläbi 50%/50% ebamugavuse. Serverit, kus quorum seade tööle pannakse, nimetasin ma witness (terminoloogia repmgr-ist, meeldiv).
Ressursid saavad liikuda ühest kohast teise, näiteks rikete tõttu serverite pealt toimivatele või süsteemiadministraatorite käsul. Et kliendid teaksid, kus vajalikud ressursid asuvad (kuhu ühendada?), kasutatakse ujutavaid IP (float IP). Need on IP, mida Pacemaker saab sõlmedel liigutada (kõik asub tasases võrgus). Igaüks neist sümboliseerib ressursi (teenuse) ja on seal, kuhu tuleb ühendada, et sellele teenusele (meie puhul andmebaasile) ligipääs saada.
Tuchanka1 (tihendamise skeem)
Struktuur
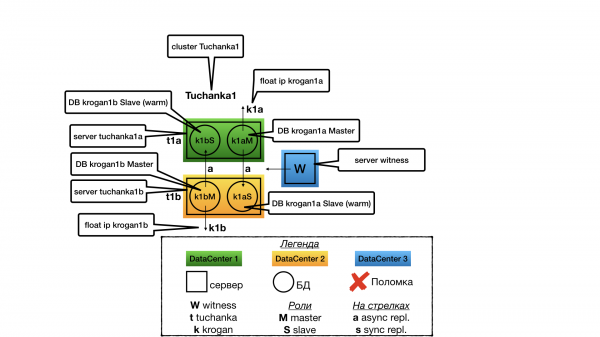
Mõte oli selles, et meil on palju väikseid andmebaase madala koormusega, mille jaoks ei ole kasulik hoida pühendatud slave-serverit kuumvarundusrežiimis ainult lugemisvõimetustega tehingute jaoks (sellise ressursside raiskamise vajadus puudub).
Igas andme keskuses on üks server. Igal serveril on kaks PostgreSQL instantsi (PostgreSQL terminoloogias nimetatakse neid klasteriteks, kuid segaduse vältimiseks nimetatakse neid instantsideks (nagu teiste andmebaaside puhul), ja klastreid nimetatakse ainult Pacemakeri klasteriteks). Üks instants töötab meistrina ja ainult tema osutab teenuseid (ainult tema suunas on float IP). Teine instants töötab orjana teise andmekeskuse jaoks ja hakkab teenuseid osutama ainult siis, kui tema meister tõrkub. Kuna enamik aega osutab teenuseid (täidab päringuid) ainult üks kahest instantsist (meister), optimeeritakse serveri kõik ressursid meistrile (mälu eraldatakse shared_buffers jaoks jne), kuid nii, et ka teisele instantsile jagub ressursse (kuigi mitteoptimaalse töö jaoks failisüsteemi cache'i kaudu) ühe andmekeskuse rikke korral. Ori ei osuta teenuseid (ei täida read only-päringuid) klastrite normaalse töö korral, et vältida ressursikonflikte meistriga samas masinas.
Kui tegemist on kahe sõlmega, siis on tõhususe tagamine võimalik ainult asünkroonse replikatsiooni puhul, kuna sünkroonse puhul viib orja rike meistri peatamiseni.
Rikke witness
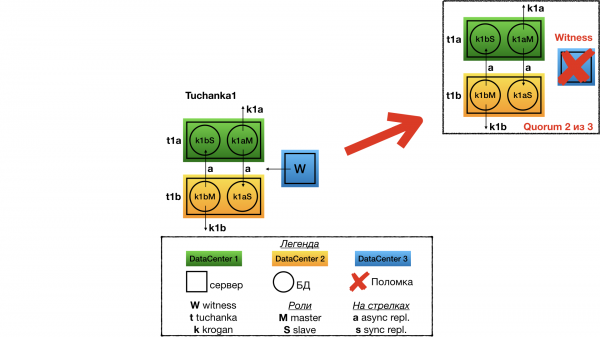
Rikke witness (quorum device) vaatlen ainult Tuchanka1 klastri puhul, kõigi teiste osas on lugu sama. Witness'i rikke korral klastristruktuuris ei muutu midagi, kõik töötab edasi nagu varem. Kuid quorum muutub 2-st 3-st, seega iga järgmine rike on klastrile saatuslik. Igal juhul on kiirelt remontima.
Riik Tuchanka1
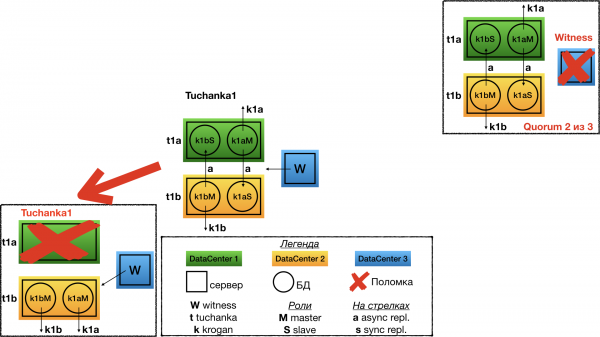
Ühe andmekeskuse rike Tuchanka1 jaoks. Sel juhul witness annab oma hääle teisele sõlmele teises andmekeskuses. Seal muutub endine ori meistriks, mille tulemuseks on see, et ühel serveril töötavad mõlemad meistrid ja suunavad mõlemad oma float IP-d.
Tuchanka2 (klassikaline)
Struktuur
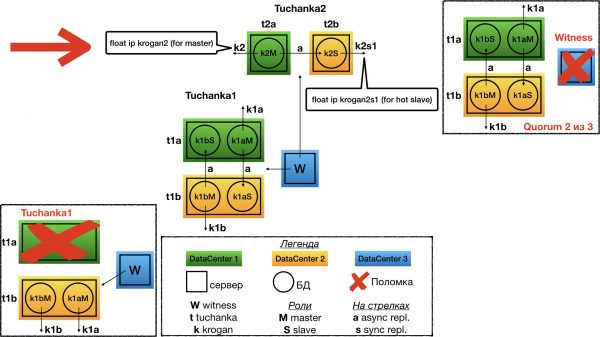
Klassikaline skeem kahest sõlmest. Ühel töötab meister, teisel ori. Mõlemad saavad päringuid teostada (ori ainult read only), seetõttu suunatakse mõlemale float IP: krogan2 — meistrile, krogan2s1 — orjale. Tõhususe tagamine on nii meistril kui orjal.
Kahe sõlme puhul on soovitatav kasutada asünkroonset replikatsiooni, sest sünkrone replikatsiooni korral toob üksiku orja rike kaasa pea seadme töö seiskumise.
Rike Tuchanka2
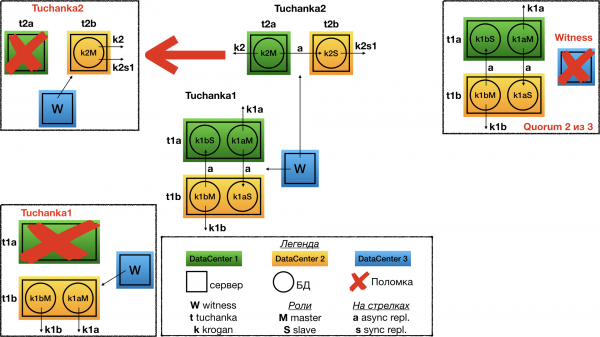
Ühe andmekeskuse rikke korral witness hääletab teise poolt. Ainult töötavas andmekeskuses tõstetakse pea seade ja mõlemad float IP: pea ja orja IP viivad sinna. Loomulikult peab instants olema seadistatud nii, et tal on piisavalt ressursse (ühenduse piirangud jne), et üheaegselt vastu võtta kõik ühendused ja päringud pea- ja orja float IP-lt. See tähendab, et normaalses töös peab tal olema piisav varu piirangutest.
Tuchanka4 (palju orje)
Struktuur
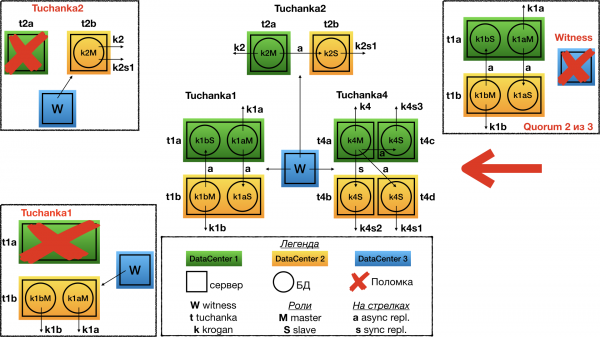
See on juba teine äärmus. On andmebaase, kuhu saadetakse väga palju lugemisettepanekuid (tüüpiline olukord kõrge koormusega veebisaidi puhul). Tuchanka4 on olukord, kus orje võib olla kolm või rohkem selliste päringute töötlemiseks, kuid mitte siiski liiga palju. Kui orje on väga palju, peab välja mõtlema hierarhilise replikatsioonisüsteemi. Minimaalses juhtumis (pildil) on igas kahes andmekeskuses kaks serverit, millel on igaühel instants PostgreSQL.
Teise olulise omaduse puhul on see, et siin on juba võimalik korraldada ühtset sünkroonimist. See on seadistatud nii, et vajadusel replikeerida teise andmeti keskusesse, mitte sama andmeti keskuse kopeerimisele. Peamine ja iga orja prindib float IP. Tõepoolest, orjade vahel tuleks teha päringute tasakaalustamine millegi kaudu. sql proxy, näiteks kliendi pool. erinevatel tüüpidel klientidel võib vaja minna erinevat tüüpi sql proxy, ning ainult klientide arendajad teavad, kellele milline on vajalik. See funktsionaalsus võib olla rakendatud nii välise deemoni kui ka klientide teegi (connection pool) kaudu jne. Kõik see jääb andmebaasi usaldusväärse kihi teemade sisse (usaldusväärsus SQL proxy saab rakendada eraldi koos kliendi usaldusväärsusega).
Tuchanka4 tõrge
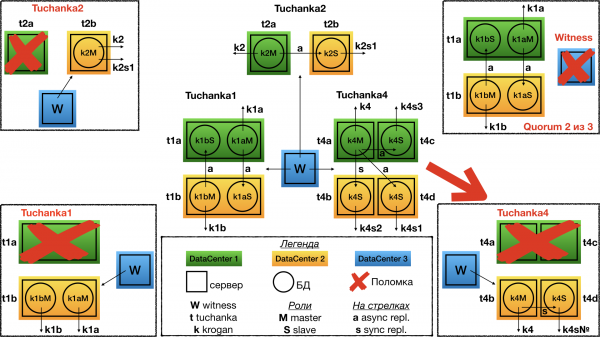
Kui üks andmekeskus (st kaks serverit) ebaõnnestub, hääletab witness teise poolt. Tulemuseks on see, et teises andmekeskuses töötavad kaks serverit: ühes töötab meisters server ja sellele viitab meistriserveri float IP (read-write päringute vastuvõtmiseks); teises serveris töötab slave, millel on sünkroonreplikatsioon, ja sellele viitab üks slave float IP (read-only päringute jaoks).
Esimene asi, mida tuleb märkida: töötavad slave float IP-d ei ole kõik, vaid ainult üks. Ja selle korrektselt toimimiseks tuleb, et sql proxy suunaks kõik päringud ainukesele allesjäänud float IP-le; ja kui sql proxy ei, siis võib loetleda kõik slave float IP-d komaga eraldatult URL-is ühenduse loomiseks. Sellisel juhul on libpq ühendamine esimese töötava IP-ga, nagu on tehtud automaattestimise süsteemis. Võimalik, et teistes raamatukogudes, näiteks JDBC-s, ei pruugi see nii töötada ja vajalik on sql proxy. Nii on tehtud, sest slave float IP-de puhul on keelatud samaaegselt sama serveris töötamine, et need jaotuksid ühtlaselt slave serverite vahel, kui neid töötab mitu.
Teiseks: isegi andmekeskuse rikke korral säilib sünkroonne kopeerimine. Isegi kui juhtub teine rike, kui ühes allesjäänud andmekeskuses ebaõnnestub üks kahest serverist, lõpetab klaster küll teenuste osutamise, kuid salvestab siiski teavet kõigi kinnitatud tehingute kohta, millele ta on andnud kinnituse (teise rikke korral ei tohi info kaduma minna).
Tuchanka3 (3 andmekeskust)
Struktuur
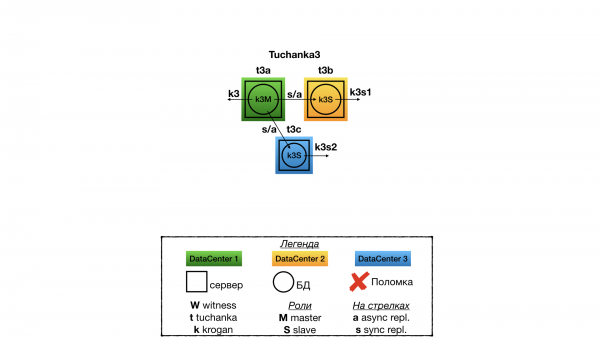
See klaster on mõeldud olukorraks, kus on kolm täielikult töötavat andmekeskust, milles igas on täielikult toimiv andmebaasi server. Sel juhul quorum device ei ole vajalik. Ühes andmekeskuses töötab master, kahes teises - orjad. Replikatsioon on sünkroonne, tüüpi ANY (slave1, slave2), st kliendile saadakse kinnituskiri kommitud tehingute kohta, kui üks orjadest esimesena vastab, et ta on kommitud vastu võtnud. Ressursside jaoks on määratud üks float IP masterile ja kaks orjadele. Erinevalt Tuchanka4-st on kõik kolm float IP-d tõrke jooksul vastupidavad. Read-only SQL-päringute tasakaalustamiseks saab kasutada sql proxy (eraldiseisva rikkevastupidavusega), või määrata poolele klientidele ühe orja float IP ning teisele poolele teise.
Tõrge Tuchanka3
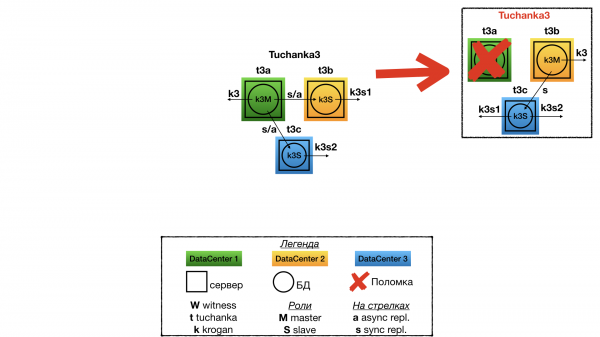
Kui üks andmete keskus ebaõnnestub, jäävad alles kaks. Ühes on master ja float IP masterist, teises on töö ja mõlemad töö float IP-d (instantsil peab olema kahekordne ressursside varu, et vastu võtta kõik ühendused mõlemalt töö float IP-lt). Masterite ja töö vahel toimub sünkroonne replikatsioon. Samuti säilitab klaster teavet kinnitatud ja kinnitatud tehingute kohta (mingeid andmeid ei kao) juhul, kui kaks andmete keskust hävivad (kui need ei hävi samal ajal).
Otsustasin mitte lisada üksikasjalikku kirjeldust failistruktuurist ja juurutamisest. Kes soovib mängida, võite selle kõik lugeda README-s. Toodan ainult automaatse testimise kirjelduse.
Automaatse testimise süsteem
Klientide vastupidavuse testimiseks, simuleerides erinevaid tõrkeid, on loodud automaatse testimise süsteem. See käivitatakse skripti test/failure. Skript võib võtta parameetritena klastrite numbrid, mida soovite testida. Näiteks see käsk:
test/failure 2 3testib ainult teist ja kolmandat klastrit. Kui parameetreid ei ole määratud, testitakse kõiki klasse. Kõiki klasse testitakse paralleelselt ja tulemused kuvatakse tmuxi paneelil. Tmux kasutab pühendatud tmux serverit, seega saab skripti käivitada ka vaikimisi tmuxist, mille tulemuseks on sisemine tmux. Soovitan kasutada terminali suure akna ja väikese fontiga. Enne testimise alustamist taastatakse kõik virtuaalmasinad rääkima hetkel, mil skript lõppes. setup.
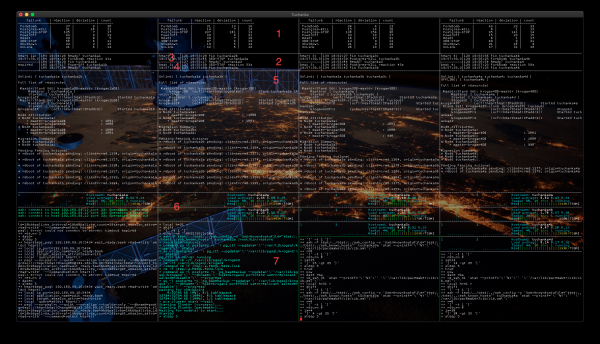
Terminal on jagatud veergudeks, mis vastavad testitavatele klastritele, vaikimisi on neid neli (nagu ekraanipildil). Veergude sisu kirjeldan Tuchanka2 näitel. Paneelid ekraanipildil on numeeritud:
- Siin kuvatakse testide statistika. Veerud:
- failure — testi nimi (skripti funktsioon), mis simuleerib rikete esinemist.
- reaction — keskmine ajavahemik sekundites, mille jooksul klaster taastab oma töökorrasoleku. Mitu korda mõõdetakse alates skripti käivitamisest, mis simuleerib riket, kuni hetkeni, mil klaster taastab oma töökorrasoleku ja suudab jätkata teenuste osutamist. Kui aeg on väga väike, näiteks kuus sekundit (nagu tuvastatakse mitme orja (Tuchanka3 ja Tuchanka4) korral), tähendab see, et rike toimus asünkroonse orja peal ja ei mõjutanud töökorrasolekut, klastris ei toimunud olekumuutusi.
- deviatsioon — näitab väärtuse hajuvust (täpsust) reaction meetodi "standardne deviatsioon" abil.
- arv — mitu korda on see test läbi viidud.
- Lühiajalugu võimaldab hinnata, millega klaster praegu tegeleb. Kuvatakse iteratsiooni (testi) number, ajatempli ja operatsiooni nimi. Liigne kestus (> 5 minutit) näitab võimalikke probleeme.
- süda (süda) — praegune aeg. Visuaalseks hindamiseks töökorrasolekut meistri tema tabelisse kirjutatakse pidevalt praegune aeg, kasutades meistri float IP-d. Edu korral kuvatakse tulemus selles paneelis.
- löök (puls) — "praegune aeg", mis varem oli skriptiga salvestatud süda masterisse, nüüd loetakse orjast tema float IP kaudu. See võimaldab visuaalselt hinnata orja ja replikeerimise töökindlust. Tuchanka1-s ei ole orje, kellel on float IP (ei ole orje, kes teenust osutavad), kuid seal on kaks instantsi (DB), seega näidatakse siin mitte löök, ja süda teise instantsi.
- Klastri oleku jälgimine utiliidi
pcs mon. Näitab struktuuri, ressursside jaotust sõlmedes ja muud kasulikku teavet. - Siin kuvatakse süsteemi jälgimine iga virtuaalmasina kohta klastris. Neid paneele võib olla rohkem — sama palju kui klastris on virtuaalmasinaid. Kaks diagrammi CPU koormus (virtuaalmasinatel on kaks protsessorit), virtuaalmasina nimi, Süsteemi koormus (tuntud kui Load Average, kuna see on keskmine 5, 10 ja 15 minuti jooksul), andmed protsesside kohta ja mälu jaotus.
- Skripti jälgimine, mis teostab testimist. Viga korral — ootamatu katkestamine või lõputu ooteaeg — siin on võimalik näha selle käitumise põhjust.
Testimine toimub kahes etapis. Esiteks käib skript läbi kõik testide variandid, valides juhuslikult virtuaalmasina, kus seda testi rakendada. Seejärel toimub lõputu testimisring, kus virtuaalmasinad ja tõrked valitakse iga kord juhuslikult. Skripti äkiline lõpetamine (alumine riba) või lõputu ootamisring millegi jaoks (> 5 minutit ühe operatsiooni sooritamiseks, mida on näha jälgimises) viitab sellele, et mõni test selle klastris on ebaõnnestunud.
Iga test koosneb järgmistest toimingutest:
- Funktsiooni käivitamine, mis simuleerib tõrget.
- Valmis? — ootamine, kuni klaster taastub (kui kõik teenused on saadaval).
- Klastri taastumise ooteaeg on näidatud (reaction).
- Paranda — klaster "parandatakse". Pärast seda peab see naasma täielikult tööolekusse ja olema valmis järgmiseks tõrkeks.
Siin on testide nimekiri koos kirjeldustega, mida need teevad:
- ForkBomb: loob "Mälu on otsa saanud" fork-bombiga.
- OutOfSpace: täidab kõvaketta. Kuid test on pigem sümboolne, arvestades vähest koormust, mis testimise käigus tekib. Kõvaketta täitumisel PostgreSQL tavaliselt ei crash'i.
- Postgres-KILL: tapab PostgreSQL käsuga
killall -KILL postgres. - Postgres-STOP: peatab PostgreSQL käsuga
killall -STOP postgres. - PowerOff: „lülitab välja“ virtuaalmasina käsuga
VBoxManage controlvm "virtuaarmasin" poweroff. - Reset: taaskäivitab virtuaalmasina käsuga
VBoxManage controlvm "virtuaarmasin" reset. - SBD-STOP: peatab SBD daemoni käsuga
killall -STOP sbd. - ShutDown: saadab SSH kaudu virtuaalmasinale käsu
systemctl poweroff, süsteem lõpetab töö korrektsetelt. - UnLink: võrgus eraldamine, käsk
VBoxManage controlvm "virtuaarmasin" setlinkstate1 off.
Testimise lõpetamine kas standardse käsu tmux "kill-window" abil Ctrl-b &, või käsu "detach-client" abil Ctrl-b d: sel juhul testimine lõpetatakse, tmux suletakse, virtuaalmasinad välja lülitatakse.
Testimise käigus tuvastatud probleemid
Praegu tuleb valida kas heli või suspend/resume. Ootame, kuni mooduli autor funktsionaalsuse lõpetab. watchdog daemon sbd töötleb jälgitavate daemonite peatamist, kuid mitte nende hangumist. Ja seetõttu ei toimu vigade korrektselt töötlemine, mis viib hangumisele vaid Corosync ja Pacemakeri, kuid mitte peatades sbd. Kontrollimiseks Corosync juba olemas. , vastu võetud haruks master. Lubati (PR#83) lubati, et ka Pacemaker jaoks on midagi sarnast tulemas, loodan, et RedHat 8 teevad. Kuid sellised „vead“ on teoreetilised, neid on lihtne kunstlikult järele teha, näiteks
killall -STOP corosync, kuid neid ei esine kunagi reaalses elus.U Pacemakeri versioonis CentOS 7 vale seadistus sync_timeout on quorum device, mille tulemusena , kuhu eelnevalt peaksime liikuma. See lahendati suurendamisega sync_timeout on quorum device paigaldamise ajal (skriptis
setup/setup1). See parandamine ei olnud arendajate poolt vastu võetud Pacemakeri, selle asemel lubasid nad ümber kujundada infrastruktuuri selliselt (mingil määral ebamugaval tulevikus), et see ajutine seade arvutatakse automaatselt.Kui andmebaasi seadistamisel on märgitud, et
LC_MESSAGES(teksti sõnumid) võivad kasutada Unicode'i, näiteksru_RU.UTF-8, siis kui see käivitatakse postgres keskkonnas, kus locale ei ole UTF-8, näiteks tühjas keskkonnas (siin pacemaker+pgsqlms(paf) käivitab postgres), siis . PostgreSQL arendajad ei suutnud kokku leppida, mida sel juhul teha. Seda saab mööduda, tuleb seadaLC_MESSAGES=en_US.UTF-8andmebaasi (DB) konfiguratsiooni (loomise) ajal.Kui on seadistatud wal_receiver_timeout (vaikimisi 60 s), siis PostgreSQL-STOP testi käigus klastrites tuchanka3 ja tuchanka4 Replikatsioon on seal süntaktiline, seega peatub mitte ainult töötaja, vaid ka uus meister. See lahendatakse, seadistades wal_receiver_timeout=0 PostgreSQL-i seadistamisel.
Harva on täheldatud PostgreSQL-i replikatsiooni seiskumist ForkBomb testis (mäluprobleemide tõttu). Sellist olukorda olen kohanud ainult klastrites tuchanka3 ja tuchanka4, kus süntaktiline replikatsioon põhjustas meistri seiskumise. Probleem lahendub ise aega mööda (umbes kahe tunni pärast). Vajalik on täiendav uurimine, et see lahendada. Sümptomid sarnanevad varasema probleemiga, mis on põhjustatud muust põhjusest, kuid sama tagajärjega.
Krogani pilt on saadud autori loal:
Allikas: habr.com
