

Soovin jagada oma esimest edukaid kogemusi Postgressi andmebaasi täisfunktsionaalsuse taastamisel. Olen PostgreSQL-iga tutvunud pool aastat tagasi, enne seda polnud mul mingit andmebaaside haldamise kogemust.

Töötan osaliselt DevOps insenerina suurtes IT-ettevõtetes. Meie ettevõte tegeleb tarkvara arendamisega suure koormusega teenuste jaoks, mina vastutan töökindluse, hoolduse ja juurutamise eest. Minu ülesanne oli ajakohastada rakendust ühel serveril. Rakendus on kirjutatud Django raamistikus; ajakohastamise käigus viiakse läbi migreerimised (andmebaasi struktuuri muutmine), ja enne seda protsessi teeme täieliku andmebaasi varukoopia standardprogrammi pg_dump abil igaks juhuks.
Varukoopia tegemise ajal tekkis ettenägematu viga (Postgresi versioon – 9.5):
pg_dump: Tabeli "ws_log_smevlog" sisu väljund ebaõnnestus: PQgetResult() ebaõnnestus.
pg_dump: Serveri veateade: VIGA: vigane leht plokis 4123007 suheline baas/16490/21396989
pg_dump: Komandiks oli: COPY public.ws_log_smevlog [...]
pg_dump: [paralleelne arendamine] töötaja protsess lõpetas ootamatult. Viga "vigane leht plokis" kõneleb failisüsteemi taseme probleemidest, mis ei ole hea. Erinevates foorumites on soovitatud teha TÄIELIK VACUUM valikuga zero_damaged_pages selle probleemi lahendamiseks. Noh, proovime ...
Taastumise ettevalmistamine
TÄHELEPANU! Veenduge, et teete enne andmebaasi taastamise katset kindlasti Postgresi varukoopia. Kui teil on virtuaalmasin, peatage andmebaas ja tehke hetkekuvand. Kui hetkekuvandi tegemine pole võimalik, peatage andmebaas ja kopeerige Postgresi katalooge (sealhulgas wal-failid) usaldusväärsesse kohta. Peamine asi on mitte halvemaks teha. Loe .
Kuna minu andmebaas töötas üldiselt, piirdusin tavapärase andmebaasi dumpimisega, kuid jätsin välja tabeli, kus olid kahjustatud andmed (valik -T, —exclude-table=TABLE pg_dump-is).
Server oli füüsiline, hetkekuvandi tegemine oli võimatu. Varukoopia on tehtud, liigume edasi.
Failisüsteemi kontrollimine
Enne andmebaasi taastamise katset tuleb veenduda, et meie failisüsteem on korras. Vigu tuleb parandada, sest vastasel juhul võib asjad veelgi hullemaks minna.
Minu puhul oli failisüsteem andmebaasiga liidetud «/srv» ja tüüp oli ext4.
Peatame andmebaasi: systemctl stop postgresql@9.5-main.service ja kontrollime, et failisüsteemi ei kasutata ja et selle saab lahti monteerida käsuga lsof:
lsof +D /srv
Pidin veel peatama redis andmebaasi, kuna see kasutas samuti «/srv». Edasi monteerisin lahti /srv (umount).
Failisüsteemi kontroll tehti utiliidiga e2fsck lippudega -f (Sundkontroll isegi kui failisüsteem on märgitud puhtaks):
Edasi utiliidiga dumpe2fs (sudo dumpe2fs /dev/mapper/gu2—sys-srv | grep checked) saab veenduda, et kontroll tõepoolest viidi läbi:

e2fsck ütleb, et ext4 failisüsteemi tasemel probleeme ei leitud, mis tähendab, et saab jätkata katseid andmebaasi taastada, täpsemalt naasta vacuum full (loomulikult tuleb failisüsteem tagasi monteerida ja andmebaasi käivitada).
Kui teil on füüsiline server, siis kontrollige kindlasti ketaste seisukorda (kasutades smartctl -a /dev/XXX) või RAID-kontroller, et veenduda, et probleem ei ole riistvaras. Minu puhul osutus RAID „nähtavaks”, seega palusin kohalikul administraatoril kontrollida RAID-i seisukorda (server oli minust mitmekümne kilomeetri kaugusel). Ta ütles, et vigu pole, mis tähendab, et saame kindlasti alustada taastamist.
Katse 1: zero_damaged_pages
Ühendame andmebaasiga psql kaudu, kasutades superkasutaja õigusi. Meile on vajalik just superkasutaja, kuna valikut zero_damaged_pages saab muuta vaid tema. Minu puhul on see postgres:
psql -h 127.0.0.1 -U postgres -s [database_name]
Valik zero_damaged_pages on vajalik lugemisvigade ignoreerimiseks (PostgresPro veebisaidilt):
Kui leitud on kahjustatud lehepealkiri, teatab Postgres Pro tavaliselt veast ja lõpetab praeguse tehingu. Kui zero_damaged_pages valik on lubatud, väljastab süsteem selle asemel hoiatuse, nullib kahjustatud lehe mälu ja jätkab töötlemist. See käitumine rikub andmeid, nimelt kõiki ridu kahjustatud lehel.
Lülitame valiku sisse ja proovime tabeli üle täielikult vakuumeerida:
VACUUM FULL VERBOSE 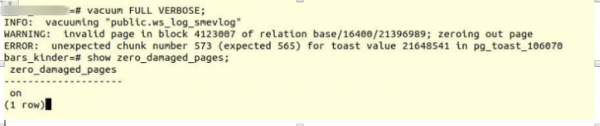
Kahjuks, ebaõnnestumine.
Kohtasime sarnast viga:
INFO: vakuumine "public.ws_log_smevlog"
HOIATUS: vigane leht plokis 4123007 seoses suhetega base/16400/21396989; nullid leht
VIGA: ootamatu tükil number 573 (oodatud 565) toster väärtuse 21648541 jaoks pg_toast_106070– mehhanism "pika andmete" salvestamiseks Postgres'is, kui need ei mahdu ühele lehte (vaikimisi 8KB).
Katse 2: reindekseerimine
Esimene soovitus Google'ist ei aidanud. Pärast mitut minutit otsimist leidsin teise soovituse – teha reindekseerimine kahjustatud tabelist. Seda soovitust olin näinud paljudes kohtades, kuid see ei inspireerinud usaldust. Teeme reindekseerimise:
reindekseerimine tabelit ws_log_smevlog 
reindekseerimine lõppes probleemideta.
Kuid see ei aidanud, VACUUM FULL kuk knowledge ebaõnnestus sarnase veaga. Kuna olin harjunud läbikukkumistega, otsisin edasi Internetist nõu ja sattusin üsna huvitavale .
Katse 3: SELECT, LIMIT, OFFSET
Eelpooltoodud artiklis soovitati vaadata tabelit rida-realt ja eemaldada probleemsed andmed. Esiteks oli vaja vaadata läbi kõik read:
for ((i=0; i/dev/null || echo $i; doneMinu puhul sisaldas tabel 1 628 991 rida! Tegelikult oleks pidanud hoolitsema , kuid see on eraldi arutlemise teema. Oli laupäev, käivitusin selle käsu tmuxis ja läksin magama:
for ((i=0; i/dev/null || echo $i; doneHommikuks otsustasin vaadata, kuidas asjalood olid. Olin üllatunud, et 20 tunni jooksul oli skaneeritud vaid 2% andmetest! Ma ei tahtnud 50 päeva oodata. Jälle täielik ebaõnnestumine.
Aga ma ei andnud alla. Mind hakkas huvitama, miks skaneerimine nii kaua aega võttis. Dokumentatsioonist (taas postgrespro-lt) õppisin, et:
OFFSET näitab, kui palju ridu tuleb vahele jätta, enne kui hakatakse ridu tagasi andma.
Kui nii OFFSET kui LIMIT on määratud, siis kõigepealt jätab süsteem vahele OFFSET read ja alustab seejärel ridade arvestamist LIMIT-i jaoks.LIMIT-i rakendamisel on oluline kasutada ka ORDER BY-lause, et tulemuste read esitataks kindlas järjekorras. Vastasel juhul tagastatakse ettearvamatud read.
On ilmne, et ülaltoodud käsk oli vale: kõigepealt puudus order by, seetõttu võis tulemus olla vale. Teiseks pidi Postgres kõigepealt skaneerima ja vahele jätma OFFSET-read ning kui see suureneb OFFSET tõhusus oleks veelgi madalam.
Katse 4: tõmmake dump tekstivormingus
Siis tuli mulle pähe näiliselt geniaalne mõte: võtta dump tekstivormingus ja analüüsida viimast salvestatud rida.
Aga kõigepealt tutvume tabeli struktuuriga ws_log_smevlog:
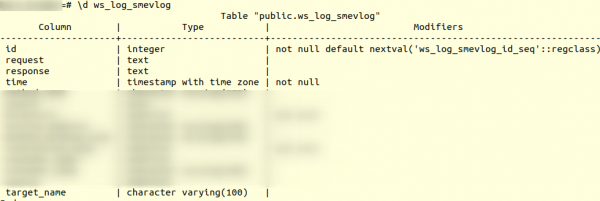
Meie korral on meil veerg «id», mis sisaldas unikaalset identifikaatorit (loendur) rida. Plaan oli järgmine:
- Alustame dumpi tegemist tekstivormingus (sql-käskude kujul)
- Mõnel hetkel katkestataks dumpi võtmine vea tõttu, kuid tekstifail salvestataks silti siiski kettale.
- Vaata tekstifaili lõppu, niinimetatud leidme identifikaatori (id) viimase rea, mis õnnestus.
Alustasin dumpi võtmist tekstivormingus:
pg_dump -U my_user -d my_database -F p -t ws_log_smevlog -f ./my_dump.dumpDumpi tegemine, nagu oodatud, katkestati sama vea tõttu:
pg_dump: Serveri veateade: ERROR: invalid page in block 4123007 of relation base/16490/21396989 Seejärel läbi tail vaatasin dumpi lõppu (tail -5 ./my_dump.dump) leidsin, et dump katkestati id real 186 525. „Seega on probleem id 186 526 real, see on rikutud, see tuleb eemaldada!” – mõtlesin ma. Kuid tehes päring andmebaasi:
«valige * from ws_log_smevlog where id=186529» selgus, et selle reaga on kõik korras… Ridadel, mille indeksid on 186 530 — 186 540, töötasid ka probleemideta. Jälle üks "geniaalne idee" ebaõnnestus. Hiljem sain aru, miks see juhtus: tabelist andmete kustutamisel või muutmisel ei kustutata neid füüsiliselt, vaid need märgitakse kui "surmatud ridadeks"; seejärel tuleb autovacuum ja märgib need read kustutatuks ning lubab neid ridasid uuesti kasutada. Arvestades, et kui tabelis andmed muutuvad ja autovacuum on sisse lülitatud, siis ei hoita neid järjestikustes asukohtades.
Katse 5: SELECT, FROM, WHERE id=
Ebaõnnestumised teevad meid tugevamaks. Kunagi ei tohi alla anda, tuleb minna lõpuni ja uskuda endasse ja oma võimetesse. Seega otsustasin proovida veel üht varianti: lihtsalt vaadata kõik andmed andmebaasis ükshaaval. Teades minu tabeli struktuuri (vt ülal), on meil id väli, mis on ainulaadne (esmane võti). Tabelis on meil 1 628 991 rida ja id need on järjestikuses järjekorras, mis tähendab, et saame need lihtsalt ükshaaval läbi käia:
for ((i=1; i<1628991; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; doneKui keegi ei saa aru, siis käib käsklus nii: ta vaatab rida-realt tabelit ja saadab stdout-i /dev/null, kuid kui SELECT käsk kukub läbi, siis kuvatakse veateksti (stderr saadetakse konsooli) ja välja prinditakse rida, mis sisaldab viga (tänu ||, mis tähendab, et select käsku esines probleem, tagastuskood ei ole 0).
Mul oli õnne, mul oli välja töötatud indeksid välja suhtes id:

See tähendab, et vajaliku id-ga rea leidmine ei tohiks võtta palju aega. Teoorias peaks see toimima. Noh, käivitage käsk tmux ja läheme magama.
Hommikuks avastasin, et oli vaadatud umbes 90 000 kirjet, mis teeb natuke üle 5%. Suurepärane tulemus, kui võrrelda varasema meetodiga (2%)! Kuid oodata 20 päeva ei soovinud…
Katse 6: SELECT, FROM, WHERE id >= and id <
Kliendi andmebaasi jaoks oli eraldatud suurepärane server: kahetuumaline Intel Xeon E5-2697 v2, meie asukohas oli koguni 48 lõime! Serveri koormus oli keskmine, me saime probleemideta võtta umbes 20 lõime. Ka RAM-i oli piisavalt: koguni 384 gigabaiti!
Seetõttu tuli käsklus paralléliseerida:
for ((i=1; i<1628991; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; doneSiin oleks võinud kirjutada kauni ja elegantse skripti, kuid ma valisin kõige kiiremalt samaaegselt töötamise viisi: jagasin vahemiku 0-1628991 käsitsi 100 000 kirje kaupa intervallideks ja käivitasin eraldi 16 käsku:
for ((i=N; i/dev/null || echo $i; doneAga see ei ole kõik. Tegelikult võtab andmebaasi ühendamine samuti aega ja süsteemi resursse. Ühendamine 1 628 991-ga ei olnud just väga mõistlik, nõustute? Seetõttu tõmmake ühe ühenduse põhjal 1000 rida, mitte ühte. Lõpptulemusena muutus käsk selliseks:
for ((i=N; i=$i and id/dev/null || echo $i; doneAvame tmux sessioonis 16 akent ja käivitame käsud:
1) for ((i=0; i=$i and id/dev/null || echo $i; done 2) for ((i=100000; i=$i and id/dev/null || echo $i; done … 15) for ((i=1400000; i=$i and id/dev/null || echo $i; done 16) for ((i=1500000; i=$i and id/dev/null || echo $i; done
Päeva pärast sain esimesed tulemused! Nimelt (väärtused XXX ja ZZZ ei ole enam salvestatud):
ERROR: puuduv tükk number 0 toast väärtuse 37837571 puhul pg_toast_106070
829000
ERROR: puuduv tükk number 0 toast väärtuse XXX puhul pg_toast_106070
829000
ERROR: puuduv tükk number 0 toast väärtuse ZZZ puhul pg_toast_106070
146000See tähendab, et meil on kolm rida, mis sisaldavad viga. Esimese ja teise probleemi kirje id asus vahemikus 829 000 ja 830 000, kolmanda id aga vahemikus 146 000 ja 147 000. Edasi pidime lihtsalt leidma probleemsete kirje id täpsed väärtused. Selleks vaatame meie probleemsete kirje vahemikku samm-sammult ja tuvastame id:
for ((i=829000; i/dev/null || echo $i; done 829417 ERROR: unexpected chunk number 2 (expected 0) for toast value 37837843 in pg_toast_106070 829449 for ((i=146000; i/dev/null || echo $i; done 829417 ERROR: unexpected chunk number ZZZ (expected 0) for toast value XXX in pg_toast_106070 146911
Õnnelik lõpp
Me leidsime probleemsed read. Logime psql'i kaudu andmebaasi ja proovime need kustutada:
my_database=# delete from ws_log_smevlog where id=829417;
DELETE 1
my_database=# delete from ws_log_smevlog where id=829449;
DELETE 1
my_database=# delete from ws_log_smevlog where id=146911;
DELETE 1Minu üllatuseks, kanded kanti probleemideta välja isegi ilma valikuta zero_damaged_pages.
Siis ühendasin end andmebaasi, tegin VACUUM FULL (arvan, et tegin seda ei olnud vaja), ja lõpuks õnnestus mul luua varukoopia pg_dump. Varukoopia loodi ilma vigadeta! Probleem õnnestus lahendada sedasi. Rõõmu ei olnud piire pärast nii palju ebaõnnestumisi, lõpuks leiti lahendus!
Tänusõnad ja kokkuvõte
Nii et see oli minu esimene kogemus PostgreSQL andmebaasi taastamisel. Selle kogemuse mäletan pikalt.
Ja lõpetuseks tahaksin tänada PostgresPro't tõlgitud dokumentatsiooni eest vene keeles ja , mis aitasid väga palju probleemi analüüsimisel.
Allikas: habr.com
