

On teada, et CTO pädevus kontrollitakse alles teisel korral selle rolli täitmisel. Sest ühe asi on töötada paar aastat ettevõttes, koos sellega areneda ja samas kultuurilises kontekstis järjest rohkem vastutust saada. Ja hoopis teine asi on kohe tehnoloogiajuhi ametisse asumine ettevõttes, kus on pärandid ja hulk probleeme, korrektselt vaiba alla pühitud.
Selles osas on Leon Fire'i kogemus, mida ta jagas , mitte otseselt ainulaadne, kuid koos tema staaži ja erinevate ametikohtade arvuga, mida ta 20 aasta jooksul on kandnud, on see väga kasulik. Allpool on 90 päeva sündmuste kronoloogia ja palju lugusid, mille üle on naerda tore, kui need juhtuvad kellegagi teisega, aga millega ei ole nii lõbus isiklikult silmitsi seista.
Leon räägib vene keeles väga värvikalt, seega, kui teil on 35-40 minutit, siis soovitan videot vaadata. Ajakirjanduse versioon ajasäästmiseks on allpool.

Esimene raporti versioon oli hästi struktureeritud ülevaade inimeste ja protsessidega töötamisest, mis sisaldas kasulikke soovitusi. Kuid see ei edastanud kõiki üllatusi, millega teel kokku puutusin. Seetõttu muutsin vormi ning esitasin probleemid, mis uues ettevõttes mu ees ilmnesid, nagu kurat urnist, ja nende lahendamise meetodid kronoloogilises järjekorras.
Kuu aega enne
Nagu paljud head lood, algas see alkoholiga. Istusime tuttavatega baaris ja nagu IT-ala inimestele kohane, kurtis igaüks oma probleemide üle. Üks neist oli just töökohta vahetanud ja rääkis oma muredest nii tehnoloogiate, inimeste kui ka meeskonnaga. Mida kauem ma kuulasin, seda enam mõistsin, et tal oleks lihtsalt mind palgata vaja, sest just selliseid probleeme olen ma viimased 15 aastat lahendanud. Nii ma talle ka ütlesin, ja järgmisel päeval kohtusime juba töökeskkonnas. Ettevõtte nimi oli Teaching Strategies.
Teaching Strategies on turul lastest liidab väikelaste õppeprogrammide turgu — alates sünnist kuni kolme aastani. Traditsiooniline „paberipõhine” ettevõte on tegutsenud juba 40 aastat, samas kui digitaalne SaaS-versioon platvormist on olnud olemas 10 aastat. Suhteliselt hiljuti algas digitehnoloogia kohandamine ettevõtte standardite juurde. „Uus” versioon käivitus 2017. aastal ja oli pea sama, kuid töötas halvemini.
Huvitaval kombel on selle ettevõtte liiklus väga prognoositav — päevast päeva, aastast aastasse saab täpselt ennustada, kui palju inimesi tuleb ja millal. Näiteks kell 13-15 lähevad kõik lapsed lasteaedades magama, samas kui õpetajad hakkavad andmeid sisestama. Ja see toimub iga päev, välja arvatud nädalavahetustel, kuna nädalavahetustel ei käi peaaegu keegi tööl.
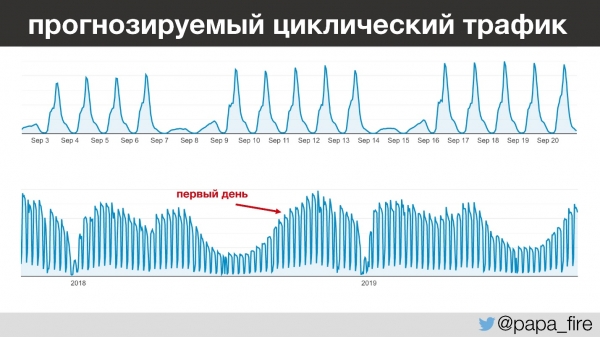
Veidi ettepoole vaadates tahan märkida, et alustasin oma tööd kõige rohkem liiklust omaval aastal, mis on huvitav erinevatel põhjustel.
Platvorm, mis oli oma olemuselt vaid 2 aastat vana, omas omapärast tehnoloogiate kogumit: ColdFusion ja SQL Server 2008. ColdFusion, kui te ei tea, ja tõenäoliselt te ei tea, on selline ettevõtte tasemel PHP, mis ilmus 90ndate keskel, ja sellest peale ei ole ma midagi kuulnud. Seal olid ka: Ruby, MySQL, PostgreSQL, Java, Go, Python. Kuid peamine monoliit töötas ColdFusioni ja SQL Serveriga.
Probleemid
Mida rohkem ma rääkisin ettevõtte töötajatega nende tööst ja probleemidest, millega nad silmitsi seisavad, seda rohkem sain aru, et probleemid on mitte ainult tehnilised. Olgu, tehnoloogia on vana — me oleme töötanud ka vanemate süsteemidega, kuid probleemid olid seotud meeskonna ja protsessidega, ning ettevõte hakkas seda lõpuks mõistma.
Traditsiooniliselt istusid seal tehnikud nurgas ja tegid oma tööd. Kuid üha enam äriprotsesse hakkas liikuma digitaalsesse keskkonda. Seetõttu, aastaga enne mu töö algust, ilmusid ettevõttesse uued positsioonid: juhatus, CTO, CPO ja QA-direktor. See tähendab, et ettevõte hakkas investeerima tehnoloogiasse.
Raske raskus pärand oli tunda mitte ainult süsteemides. Ettevõttes olid legacy-protsessid, legacy-inimesed, legacy-kultuur. Kõike seda tuli muuta. Mõtlesin, et igav ei hakka kindlasti ja otsustasin proovida.
Kaks päeva enne
Kaks päeva enne uue töö algust saabusin kontorisse, täitsin viimased dokumendid, tutvusin meeskonnaga ja avastasin, et meeskond võitleb sel ajal probleemiga. Probleemiks oli see, et keskmine lehe laadimisaeg oli tõusnud 4 sekundini, mis oli kaks korda rohkem.
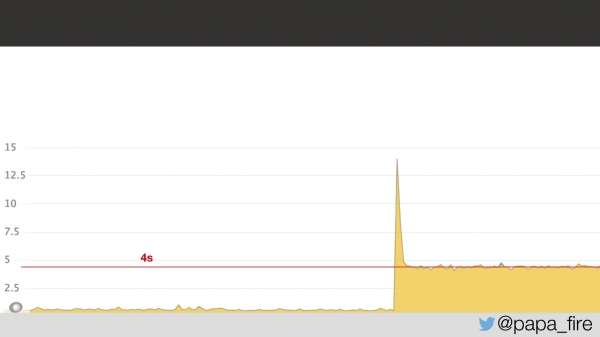
Graafikult vaadates oli selgelt midagi juhtunud, küll aga polnud selge, mis. Selgus, et probleem oli seotud varsaste latentsusega andmekeskuses: 5 ms latentsus andmekeskuses muutus 2 sekundiks kasutajatele. Miks see nii läks, ma ei teadnud, aga igal juhul oli teada, et probleem on andmekeskuses.
Esimene päev
Kaks päeva hiljem, oma esimesel tööpäeval, avastasin, et probleem ei olnud kuskile kadunud.
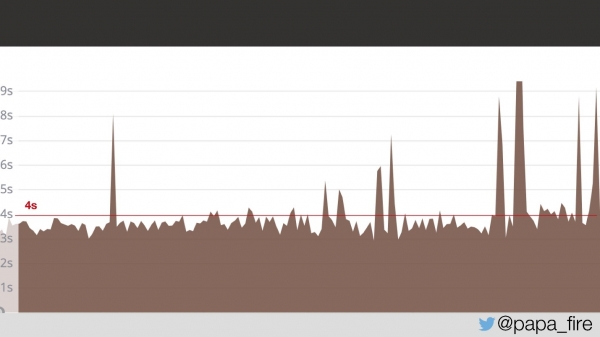
Kaks päeva laadisid lehed kasutajatele keskmiselt 4 sekundiga. Küsisin, kas nad leidsid, milles probleem on.
— Jah, me avasime tiku.
— Ja?
— Noh, nad pole meile veel vastanud.
Siis sain aru, et kõik, millest mulle varem räägiti, on vaid jäämäe väike tipp, millega tuleb võidelda.
On olemas hea tsitaat, mis sobib siia väga hästi:
„Mõnikord on tehnoloogia muutmiseks vaja muuta organisatsiooni.”
Kuna aga hakkasin tööle aasta kõige kiiremal ajal, tuli olukorrale läheneda kahe lahenduse võimaluse kaudu: nii kiirelt kui ka pikaajalises perspektiivis. Tuleb alustada sellest, mis on kriitiline just nüüd.
Kolmas päev
Nii kestis laadimine 4 sekundit ja kell 13-15 olid kõige suuremad tipud.
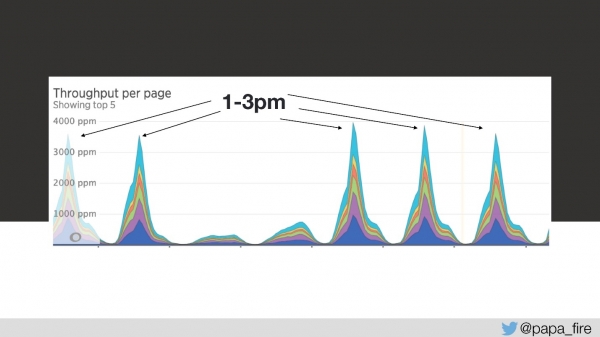
Kolmandal päeval nägi laadimise kiirus sel ajavahemikul välja nii:
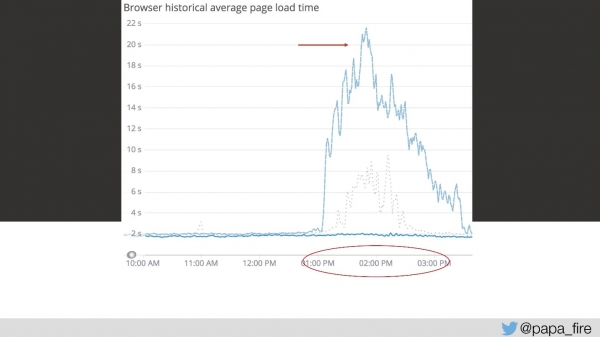
Minu arvates ei töötanud üldse midagi. Kõigi teiste arvates töötas see aga veidi aeglasemalt kui tavaliselt. Kuid lihtsalt nii ei juhtu — see on tõsine probleem.
Proovisin tiimi veenda, kuid nad vastasid, et on lihtsalt vaja rohkem servereid. See on muidugi probleemilahendus, kuid mitte alati ainus ja kõige tõhusam. Küsisin, miks serveritest jääb puudu ja kui suur on liiklusmaht. Ekstrapoleerisin andmed ja sain, et meil on umbes 150 päringut sekundis, mis jääb mõistlikesse piiridesse.
Kuid ei tohi unustada, et enne õige vastuse saamist tuleb esitada õige küsimus. Minu järgmine küsimus oli: kui palju meil on frontend-servereid. Vastus üllatas mind veidi — meil oli 17 frontend-serverit!
— Kardan küsida, 150 jagada 17, tuleks umbes 8? Kas tahate öelda, et iga server käitleb 8 päringut sekundis ja kui homme on 160 päringut sekundis, siis vajame veel 2 serverit?
Muidugi, me ei vajanud täiendavaid servereid. Lahendus oli koodis endas ja see oli väliselt nähtav:
var currentClass = classes.getCurrentClass();
return currentClass; Oli funktsioon getCurrentClass(), sest kogu sait töötab klassi kontekstis — õigesti. Ja selle funktsiooni jaoks iga lehe kohta tuli 200+ päringut.
Seega oli lahendus väga lihtne, ei olnud vaja midagi ümber kirjutada: lihtsalt mitte küsida sama teavet uuesti.
if ( !isDefined("REQUEST.currentClass") ) {
var classes = new api.private.classes.base();
REQUEST.currentClass = classes.getCurrentClass();
}
return REQUEST.currentClass;Olin väga rõõmus, sest arvasin, et kolmandal päeval leidsin peamise probleemi. Kui naiivne ma olin, see oli ainult üks väga paljusid probleeme.
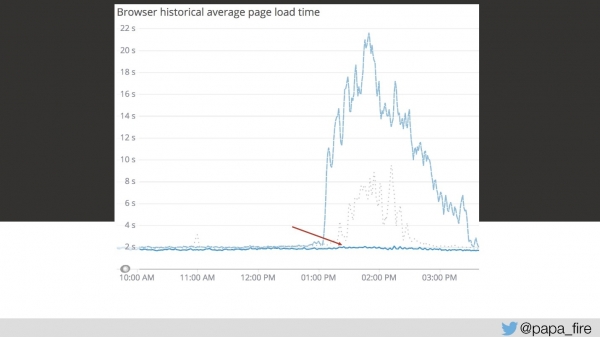
Kuid selle esimese probleemi lahendamine alandas graafikut palju madalamale.
Samas samal ajal tegime ka muid optimeerimisi. Palju asju, mida saab parandada, tuli esile. Näiteks kolmandal päeval avastasin, et süsteemis oli ikkagi puhver (esialgu arvasin, et kõik päringud tulevad otse andmebaasist). Kui ma mõtlen puhversalvestusele, siis kujutan ette standardseid Redis või Memcached. Kuid nii arvasin vaid mina, sest selle süsteemi puhverdamiseks kasutati MongoDB-d ja SQL Serverit — sama, kust just andmed loeti.
Kümnes päev
Esimese nädala jooksul tegelesin probleemidega, mida tuli kohe lahendada. Teisel nädalal osalesin esmakordselt seistes meeskonna koosolekul, et näha, mis toimub ja kuidas kogu protsess sujub.
Taaskord selgus midagi huvitavat. Meeskonda kuulus: 18 arendajat; 8 testijat; 3 juhti; 2 arhitekti. Ja kõik nad osalesid ühistes rituaalides, see tähendab, et enam kui 30 inimest tuli igal hommikul koosolekule ja rääkis, mida nad tegid. Selge on, et kohtumine ei kestnud 5 ega 15 minutit. Keegi ei kuulnud kedagi, sest kõik töötasid erinevates süsteemides. Sellises olukorras 2-3 ülesande käsitlemine ühe tunni jooksul grooming session'il oli juba hea tulemus.
Esimene asi, mida me tegime, oli jagada meeskond mitmeks tooteliiniks. Erinevate sektsioonide ja süsteemide jaoks moodustasime eraldi meeskonnad, kuhu kuulusid arendajad, testijad, tootemanajerid ja ärianalüütikud.
Tulemuseks saime:
- Standupide ja koosolekute lühendamine.
- Tootealane teadmistebaas.
- Omanditunne. Kui varem inimesed pidevalt rotatsioonis olid, siis nad teadsid, et nende vigadega peavad tõenäoliselt tegelema keegi teine, mitte nemad ise.
- Koostöö rühmade vahel. Pole vaja öelda, et QA ja arendajate omavahelised suhted ei olnud ennenägematult head, tootemaad korraldasid oma tegevust jne. Nüüd on neil ühine vastutuspunkt.
Peamiselt keskendusime efektiivsusele, tootlikkusele ja kvaliteedile — just neid probleeme püüdsime meeskonna transformatsiooniga lahendada.
Kaks üksteist päeva
Meeskonna struktuuri muutmise protsessis avastasin, kuidas arvestatakse LuguPunkti. 1 SP oli võrdne ühe päevaga, ja iga pilet sisaldas SP-d nii arenduseks kui ka QA-ks, seega vähemalt 2 SP-d.
Kuidas ma selle avastasin?
Leiti vea: ühes aruandes, kus sisestatakse perioodi algus- ja lõppkuupäev, ei arvestata viimast päeva. See tähendab, et kuskil päringus oli mitte <=, vaid lihtsalt <. Öeldi, et see on kolm Story Points, st 3 päeva.
Pärast seda me:
- Uuendasime Story Pointide hindamis süsteemi. Nüüd jõuavad väikeste vigade parandused, mida saab süsteemist kiiresti läbi lasta, kiiremini kasutajani.
- Alustasime seotud piletite ühendamist arendamiseks ja testimiseks. Varasemalt oli iga pilet, iga viga eraldiseisev ökosüsteem, mis ei olnud seotud ühegi teisega. Kolme nupu muutmine ühel lehel võis olla kolm erinevat piletit koos kolme erineva QA-protsessiga, mitte ühe automaatse testimisega lehel.
- Algatasime arendajatega koostöö tööjõukulusid hindava lähenemise osas. Kolm päeva ühe nupu muutmiseks — see ei ole naljakas.
Kakskümmend päeva
Umbes kuu esimese kuu keskpaiku stabiliseerus olukord veidi, sain aru, mis peamiselt toimub, ja hakkasin juba vaatama tulevikku ning mõtlema pikaajalistele lahendustele.
Pikaajalised eesmärgid:
- Haldusega platvorm. Iga lehe sisu hulk päringuid — see ei ole tõsiseltvõetav.
- Ettearvatavad trendid. Mõnikord toimusid liikluspõhjused, mis esialgu ei korreleerinud teiste mõõdikutega — tuli aru saada, miks see juhtub ja õppida, kuidas seda ennustada.
- Platvormi laienemine. Äri kasvab pidevalt, üha rohkem kasutajaid tuleb, liiklus suureneb.
Varem öeldi sageli: "Laseme kõik ümber kirjutada [keel/raamistik], kõik hakkab paremini töötama!"
Enamasti see ei toimi, on hea, kui ümber kirjutatud üldse tööle hakkab. Seega pidime looma tegevuskava — selge strateegia, mis illustreerib samm-sammult, kuidas äri eesmärke saavutame (mida me teeme ja miks), mis:
- peegeldab projekti missiooni ja eesmärke;
- prioriseerib peamised eesmärgid;
- sisaldab ajakava nende saavutamiseks.
Eelnevalt ei ole keegi meeskonnaga rääkinud, millise eesmärgiga tehakse muudatusi. Selleks on vaja õigeid edule viivaid näitajaid. Esmakordselt ettevõtte ajaloos seadsime tehnilise meeskonna jaoks KPI-d, sidudes need organisatsiooniliste eesmärkidega.
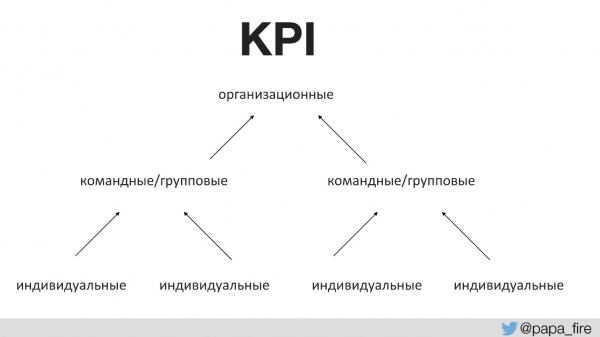
See, organizational KPIs are supported by teams, while team KPIs are supported individually. Otherwise, if technological KPIs do not align with organizational ones, everyone pulls the blanket towards themselves.
For instance, one organizational KPI is to increase market share through new products.
What can support the goal of having more new products?
- Firstly, we want to spend more time developing new products instead of fixing defects. This is a logical decision that can be easily measured.
- Secondly, we want to support an increase in transaction volume because the larger the market share, the more users there are, and correspondingly, the more traffic.
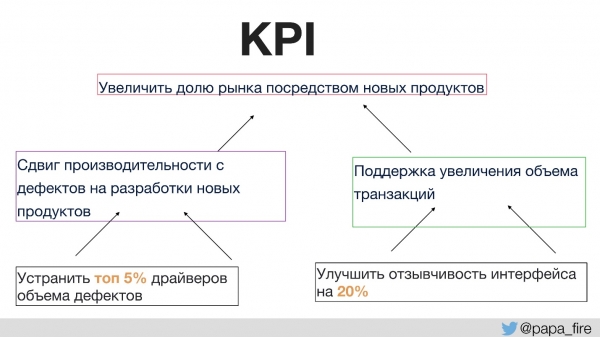
Then, individual KPIs that can be executed within the group could be, for example, those related to places where the main defects come from. If we focus on this section specifically, we can significantly reduce defects, which would increase the time available for developing new products and again support the organizational KPIs.
Seega peab iga lahendus, sealhulgas koodi ümberkirjutamine, toetama konkreetseid eesmärke, mis on ettevõtte ees seatud (organisatsiooni kasv, uued funktsioonid, meeskonna komplekteerimine).
Selle protsessi käigus ilmnes huvitav asi, mis ei olnud uudiseks mitte ainult tehnilistele inimestele, vaid kogu ettevõttele: kõik piletid peavad olema suunatud vähemalt ühele KPI-le. See tähendab, et kui tootearendaja ütleb, et soovib luua uut funktsiooni, siis peaks esimene küsimus olema: „Millist KPI-d see funktsioon toetab?“ Kui ei ühtegi, siis vabandust — tundub, et see on tarbetu funktsioon.
Kolmekümnes päev
Kuu lõpus avastasin veel ühe nüansi, et keegi minu ops meeskonnast pole kunagi näinud lepinguid, mida me klientidega sõlmime. Võite küsida, miks lepingud peaksid olema nähtavad.
- Esiteks, kuna lepingutes on määratud SLA-d.
- Teiseks, SLA-d on kõik erinevad. Iga klient tuli oma nõudmistega ning müügiosakond allkirjastas need ilma vaatamata.
Veel üks huvitav nüanss — ühe meie suurima kliendi lepingus on kirjas, et kõik platvormi toetatavad tarkvaraversioonid peavad olema n-1, seega mitte viimane versioon, vaid eelviimane.
Selge, kui kaugel me n-1-st olime, kui platvorm oli ColdFusion ja SQL Server 2008, mida lõpetati täielikult toetamast juulis.
Kümmnes päev
Kusagil teise kuu keskel vabastasin piisavalt aega, et istuda maha ja teha valuestreammapping täielikult kogu protsessi. Need on vajalikud sammud, mis tuleb astuda alates toote loomise hetkest kuni selle tarbijani toimetamiseni, ja neid tuleb võimalikult detailselt kirjeldada.
Jagad protsessi väikesteks osadeks ja vaatad, mis võtab liiga kaua aega, mida saab optimeerida, parandada jne. Näiteks, kui kaua võtab aega toote päring, minna läbi grooming, kuni see jõuab piletini, mille arendaja saab võtta, QA jne. Niivõrd detailselt vaatad iga üksik samm ja mõtled, mida saab optimeerida.
Kui ma seda tegin, paistsid silma kaks asja:
- kõrge piletite tagastamise protsent QA-st tagasi arendajatele;
- pull request'i ülevaatus võttis liiga kaua aega.
Probleem oli selles, et need olid järeldused, mis näisid: tundub, et võtab palju aega, kuid me ei ole kindlad, kui palju täpselt.
«Midagi ei saa parandada, mida ei saa mõõta.»
Kuidas põhjendada, kui tõsine probleem on? Kas selle tõttu kulutatakse päevi või tunde?
Selleks, et seda mõõta, lisasime Jira protsessile paar sammu: „valmis arendamiseks“ ja „valmis QA-ks“, et mõõta, kui kaua iga pilet ootab ja mitu korda see teatud sammu tagasi tuleb.
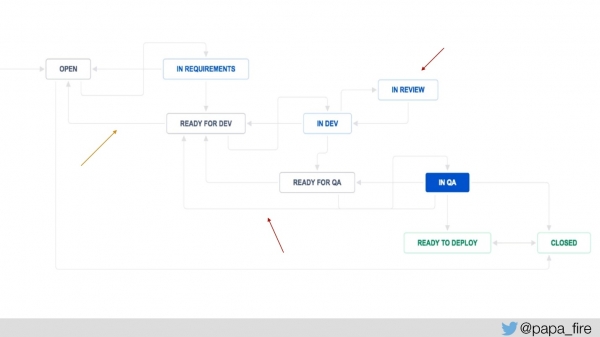
Samuti lisasime „ülevaatuses“, et teada, kui kaua keskmiselt piletid ülevaatuses viibivad, ja selle põhjal edasi liikuda. Meil olid süsteemilised mõõdikud olemas, nüüd lisasime uusi mõõdikuid ja hakkasime mõõtma:
- Protsessi efektiivsus: tootlikkus ja kavandatud/teostatud.
- Protsessi kvaliteet: defektide arv, QA-st tulenevad defektid.
See aitab tõeliselt mõista, mis läheb hästi ja mis halvasti.
Viiekümnes päev
See kõik on loomulikult hea ja huvitav, kuid teise kuu lõpus juhtus see, mis oli tõenäoliselt ette ennustatav, kuigi ma ei oodanud sellist ulatust. Inimesed hakkasid lahkuma, sest juhtkond muutus. Uued inimesed tulid juhtima ja algasid muudatused, vanad aga lahkusid. Ja tavaliselt on ettevõttes, mis on juba mitu aastat eksisteerinud, kõik sõbrad ja kõik tunnevad teineteist.
See oli oodatud, kuid üllatav oli vallandamiste ulatus. Näiteks esitasid kahe meeskonna juhi samal nädalal lahkumisavalduse. Seetõttu pidin mitte niivõrd unustama muid probleeme, vaid keskenduma meeskonna loomisele. See on pikk ja keeruline probleem, kuid sellega pidime tegelema, sest soovisime hoida inimesi, kes jäi (või enamiku neist). Pidi kuidagi reageerima sellele, et inimesed lahkusid, et toetada meeskonna moraali.
Teoreetiliselt on see hea: tuleb uus inimene, kellel on täielik vabadus hinnata meeskonna oskusi ja asendada töötajaid. Tegelikult ei saa lihtsalt uusi inimesi tuua paljusid põhjuseid arvesse võttes. Alati on vajalik tasakaal.
- Vana ja uus. Tuleb hoida vanu inimesi, kes saavad muutuda ja toetada missiooni. Kuid samas on vaja tuua ka uut verd, millest räägime natuke hiljem.
- Kogemus. Olen palju rääkinud headest noortest, kes olid entusiasmi täis ja soovisid meie juurde tööle tulla. Aga ma ei saanud neid võtta, kuna ei olnud piisavalt vanemaid, kes noori toetaksid ja nende mentoriteks oleksid. Kõigepealt tuli tööle võtta tipptegijad ja alles siis noored.
- Mikro- ja makrohaldus.
Mul ei ole head vastust küsimusele, milline tasakaal on õige, kuidas seda hoida, kui palju inimesi jätta ja kui palju survet avaldada. See on puhtalt individuaalne protsess.
Viiskümmend esimest päeva
Olen hakanud meeskonda vaatama, et aru saada, kes mul on, ja uuesti meelde tuletasin:
«Enamik probleeme on seotud inimestega».
Olen avastanud, et meeskonnas, olgu need siis arendajad või Ops, on kolm suurt probleemi:
- Rahulolu praeguse olukorraga.
- Vastutuse puudumine — sest keegi pole kunagi seostanud töö tulemusi äri mõjutamisega.
- Muutuste kartmine.

Muudatused viivad alati meid mugavustsoonist välja, ja mida nooremad inimesed on, seda vähem nad muudatusi armastavad, sest nad ei mõista, miks ja ei mõista, kuidas. Kõige sagedasem vastus, mida olen kuulnud: „Me pole kunagi nii teinud“. Tegi absurdu, et väikesedki muutused ei möödunud ilma, et keegi ei oleks protestinud. Oluline ei ole, kui palju muudatused nende tööga seotud olid, inimesed ütlesid: „Ei, miks? See ei toimi."
Aga paremaks saab ainult muutusi tegemata jäädes.
Mul oli täiesti absurdne vestlus töötajaga, rääkisin talle oma ideedest optimeerimise osas, millele ta vastas:
— Aaa, sa ei ole näinud, mis meil eelmisel aastal oli!
— No ja mis siis?
— Nüüd on palju parem kui oli.
— Nii et ei saa veel paremaks minna?
— Aga miks?
Hea küsimus — miks? Justkui, kui nüüd on parem, kui oli, siis on kõik piisavalt hea. See viib vastutuse puudumiseni, mis on põhimõtteliselt täiesti normaalne. Nagu ma ütlesin, oli tehniline meeskond veidi kõrvale tõrjutud. Ettevõttes arvati, et nad peavad olema, aga keegi ei ole kunagi standardeid kehtestanud.. Tugiteenuses ei ole SLA-d kunagi nähtud, seega tundus grupile see täiesti «vastuvõetav» (ja see üllatas mind kõige rohkem):
- 12 sekundit laadimisaja;
- 5-10 minutit seisakut iga väljalaske korral;
- kriitiliste probleemide lahendamine võtab päevi ja nädalad;
- öise valve puudumine 24/7 / hädaolukordadel.
Keegi ei ole kunagi proovinud küsida, miks me seda paremini ei teeks, ja keegi ei ole kunagi aru saanud, et asjad ei tohiks nii olla.
Lisaks oli veel üks probleem: kogemuse puudumine. Vanemad lahkusid ning jäänud noorem meeskond kasvas endises režiimis ja oli nende halvatusest mürgitatud.
Kogu selle taustal kartsid inimesed veel ka ebaõnnestuda ja tunduda saamatu. See väljendub selles, et nad, esiteks, ei küsi mingil juhul abi. Kui palju kordi oleme grupis ja individuaalselt rääkinud ning ma olen öelnud: «Küsi küsimus, kui sa ei tea, kuidas midagi teha». Ma olen endas kindel ja tean, et suudan lahendada iga probleemi, kuid see võtab aega. Seetõttu, kui saab küsida kedagi, kes teab, kuidas seda 10 minutiga lahendada, küsin. Mida vähem sul on kogemust, seda rohkem sa kardad küsida, kuna arvad, et sind peetakse saamatu.
Seda kartmine küsimise ees avaldub huvitavates vormides. Näiteks küsid: „Kuidas selle ülesandega lood on?“ — „Jään paariks tunniks, peagi valmib.“ Järgmine päeva küsid taas ja saad vastuseks, et kõik on hästi, kuid tekkis üks probleem, päeva lõpuks kindlasti valmis ei jõua. Mulle tundub, et seni kuni kedagi seinaga kokku suruda, ja teda koos kellegagi rääkima sundida, nii see kõik jätkub. Inimesele meeldib probleem ise lahendada, ta arvab, et kui ta seda ise ei tee, on see suur ebaõnnestumine.
Just seetõttu arendajad hindasid üle. See oli päris anekdoot, kui arutasime kindlat ülesannet, kui mulle anti number, mis mind väga üllatas. Selle peale öeldi, et hinnangutes arvestab arendaja ka aega, mille pilet QA-st tagasi tuleb, sest nad leiavad sealt vigu, ja aega, mis kulub PR-ile, ning aega, mille jooksul inimesed, kes peaksid seda vaatama, on hõivatud — ehk kõike, mis üldiselt võimalik on.
Teiseks, inimesed, kes kardavad tühi mulje jätta, liialt analüüsivad. Kui ütled, mida täpselt teha, algab see: „Ei, aga mis siis, kui me siin mõtleme?” Selles osas ei ole meie ettevõte ainulaadne, see on noorpõlve standardproblem.
Vastuseks esitasin järgmised põhimõtted:
- 30-minuti reegel. Kui poole tunni jooksul ei õnnestu probleemi lahendada, paluge kellelgi abi. See toimib varieeruva eduga, kuna inimesed ei küsi niikuinii abi, aga vähemalt on protsess alanud.
- Välistage kõik, välja arvatud tuum, ülesande teostamise ajahinnangus, st arvestage ainult seda, kui palju aega kulub koodi kirjutamiseks.
- Pidev õppimine neile, kes analüüsivad üle. See on lihtsalt pidev töö inimestega.
Kuuendal päeval
Kui ma sellega kõik tegeleda, tuli aeg eelarvega tegeleda. Muidugi leidsin palju huvitavat, kuhu me raha kulutasime. Näiteks oli meil kogu riiul eraldi andmekeskuses, kus seisis üks FTP-server, mida kasutas üks klient. Selgus, et „... me kolisime ja see jäi nii, me ei vahetanud seda.” See oli 2 aastat tagasi.
Erilised huvi tekitas pilveteenuste arve. Olen kindel, et peamine põhjus suurele pilveteenuste arvele on arendajad, kellel on esmakordselt elus piiramatu juurdepääs serveritele. Neil ei ole vaja küsida: „Palun andke mulle testiserver”, — nad saavad selle ise võtta. Lisaks sellele tahavad arendajad alati luua nii ägeda süsteemi, et Facebook ja Netflix kadestaksid.
Aga arendajatel pole serverite ostmise kogemust ega oskust määrata serverite vajalikku suurust, kuna nad ei ole seda varem vajanud. Ja tavaliselt ei mõista nad piisavalt erinevust skaleeritavuse ja jõudluse vahel.
Inventuuri tulemused:
- Väljusime ühest andmekeskusest.
- Lõpetasime lepingu 3 logiteenusega. Sest neid oli meil 5 — iga arendaja, kes hakkas millegiga eksperimenteerima, võttis uue.
- Käivitame 7 AWS-süsteemi. Jällegi, surnud projekte keegi ei peatunud, need jätkasid töötamist.
- Vähendasime tarkvara kulusid 6 korda.
Seitsmekümnes viies päev
Aeg möödus ja kahe ja poole kuu pärast pidi ma kohtuma juhatusega. Meie juhtkond ei ole parem ega halvem kui teised; nagu kõik juhatused, tahavad nad kõik teada. Inimesed investeerivad raha ja tahavad mõista, kui hästi see, mida me teeme, vastab seatud KPI-dele.
Juhatus saab igal kuul palju teavet: kasutajate arv, nende kasv, milliseid teenuseid nad kasutavad ja kuidas, tootlikkus ja efektiivsus ning lõpuks keskmine lehe laadimisaeg.
Probleem on ainult selles, et ma arvan, et keskmine näitaja on puhas kurjus. Kuid juhatusele on seda väga raske selgitada. Nad on harjunud tööle aggregaatnumbritega, mitte näiteks laadimisaegade hajumisega sekundites.
Seoses sellega olid huvitavad hetked. Näiteks ütlesin, et tuleb jagada liiklus individuaalsete veebiserverite vahel sõltuvalt sisu tüübist.

See tähendab, et ColdFusion läbib Jetty ja nginxi ning käivitas lehti. Ja pildid, JS ja CSS lähevad läbi eraldi nginxi oma konfiguratsioonidega. See on üsna tavaline praktika, millest ma veel paar aastat tagasi. Seetõttu laadivad pildid palju kiiremini ja … keskmine laadimiskiirus tõusis 200 ms.
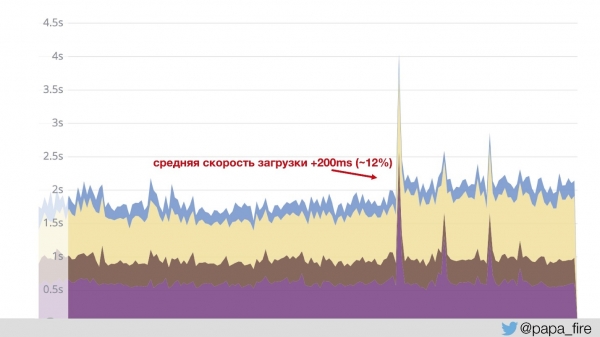
See juhtus seetõttu, et graafik koostati andmete põhjal, mis tulid Jettylt. See tähendab, et kiire sisu ei arvestata — keskmine väärtus tõusis. Meile oli see arusaadav, me naersime, kuid kuidas selgitada juhatusele, miks me midagi tegime ja tulemuseks oli 12% halvenemine?
Kaheksakümne viies päev
Kolmanda kuu lõpus mõistsin, et on üks asi, millega ma absoluutselt ei arvestanud — see on aeg. Kõik, millest ma rääkisin, vajab aega.

See on minu tõeline nädalakalender — lihtsalt töönädal, mitte kuigi koormav. Aeg on kõigest puudu. Seega on jälle vaja inimesi palgata, kes aitavad probleemidega toime tulla.
Kokkuvõte
See pole veel kõik. Selles loos ei ole ma veel jõudnud sinuni, kuidas me tootega töötasime ja proovisime end ühise laine peale saada, või kuidas me integreerisime tehnilise toe, või kuidas me lahendasime muid tehnilisi probleeme. Näiteks, ma täiesti juhuslikult avastasin, et meie suurimatel tabelitel andmebaasis me ei kasuta SEKVENTS. Meil on enda kirjutatud funktsioon nextID, ja seda ei kasutata tehingus.
Oli veel miljon sarnast asja, millest võiks rääkida pikalt. Kuid kõige olulisem, millest tasub rääkida, on kultuur.

Just kultuur või selle puudumine viib kõikide teiste probleemideni. Me püüame luua kultuuri, kus inimesed:
- ei karda ebaõnnestumisi;
- õpivad vigadest;
- teevad koostööd teiste meeskondadega;
- näitavad üles initsiatiivi;
- võtavad vastutust;
- tervitavad tulemust kui eesmärki;
- peavad edu tähistamist.
Seda kõike järgneb.
Leon Fire , ja .
Legacy’ga on kaks strateegiat: vältida sellega töötamist kui suudetakse, või julgelt ületada kaasnevaid raskusi. Me valime teise tee, muutes protsesse ja lähenemisi. Liitu meiega , ja , ja paneme koos DevOps kultuuri ellu.
Allikas: habr.com
