

Need päevad on möödas, mil ei olnud vaja andmebaaside jõudluse optimeerimise pärast muretseda. Aeg ei seisa paigal. Iga uus tehnoloogiaettevõtja soovib luua järgmist Facebooki, püüdledes samas koguda kõiki andmeid, mis on nende käeulatuses. Need andmed on ettevõtetele vajalikud, et paremini koolitada mudeleid, mis aitavad raha teenida. Sellistes tingimustes peavad arendajad looma selliseid API-sid, mis võimaldavad kiiresti ja usaldusväärselt töötada tohutute andmemahtudega.
Kui olete mõnda aega tegelenud rakenduste või andmebaaside serveripoolsete osade projekteerimisega, siis olete tõenäoliselt kirjutanud koodi lehe jagamise päringute täitmiseks. Näiteks — sellise:
SELECT * FROM table_name LIMIT 10 OFFSET 40
Kas see on tõsi?
Kuid kui te olete lehe jagamist teinud just nii, pean kahetsema, et olete seda teinud kaugel kõige tõhusamal viisil.
Kas soovite mulle vastu vaielda? . , ja kasutavad juba tehnikaid, millest ma täna rääkida tahan.
Nimetage vähemalt üks tagapoolt arendaja, kes pole kunagi kasutanud OFFSET ja LIMIT lehtede jagamise päringute täitmiseks. MVP-s (Minimum Viable Product, minimaalne elujõuline toode) ja projektides, kus kasutatakse väikeseid andmemahtusid, on see lähenemine täiesti rakendatav. See, nii öelda, "lihtsalt töötab".
Aga kui on vaja nullist luua usaldusväärseid ja tõhusaid süsteeme, tuleks ette mõelda andmebaaside päringute täitmise efektiivsusele, mida sellistes süsteemides kasutatakse.
Täna räägime probleemidest, mis kaasnevad laialdaselt kasutatavate (kahjuks) lehtede jagamise päringute täitmise mehhanismide rakendustega, ja sellest, kuidas saavutada kõrge jõudlus selliste päringute täitmisel.
Mis on valesti OFFSET-i ja LIMIT-iga?
Nagu juba mainitud, OFFSET ja LIMIT näitavad nad end suurepäraselt projektides, kus ei pea töötama suurte andmemahtudega.
Probleem tekib siis, kui andmebaas kasvab nii suureks, et ei mahu enam serveri mällu. Samas tuleb selle andmebaasiga töötades kasutada leheküljepõhiseid päringuid.
Selle probleemi ilmnemiseks peab tekkima olukord, kus andmebaasi haldussüsteem peab iga leheküljepõhise päringu täitmisel pöörduma ebaefektiivse täistabeli skaneerimise (Full Table Scan) poole (samal ajal võivad toimuda andmete lisamine ja kustutamine, ja vanad andmed ei ole meile vajalikud!).
Mis on "täielik tabeli skaneerimine" (või "järjekorraga tabeli vaatamine", Sequential Scan)? See on toiming, mille käigus andmebaasiserver loeb järjestikuuliselt läbi iga tabeli rea, st andmed, mis seal sisaldub, ning kontrollib neid määratud tingimuse järgi. On teada, et see skaneerimistüüp on aeglaseim. Probleem on selles, et selle teostamise käigus tehakse palju sisendi/väljundi operatsioone, mis hõlmavad serveri ketasüsteemi. Situatsiooni halvendavad viivitused, mis kaasnevad kettal salvestatud andmetega töötamisel, ning see, et andmete edastamine kettalt mälu on ressursimahukas toiming.
Näiteks, teil on kirjed 100000000 kasutajast ja teete päringu konstruktsiooniga OFFSET 50000000. See tähendab, et andmebaasiserver peab laadima kõik need kirjed (ja need pole ju meile isegi vajalikud!), paigutama need mälu ning seejärel võtma, ütleme, 20 tulemust, millest on teatatud LIMIT.
Oletagem, et see võib välja näha nii: "vali read 50000 kuni 50020 100000-st". See tähendab, et süsteem peab päringu täitmiseks esmalt laadima 50000 rida. Kas näete, kui palju tarbetut tööd tal tuleb teha?
Kui te ei usu, vaadake näidet, mille ma lõin võimaluste abil .
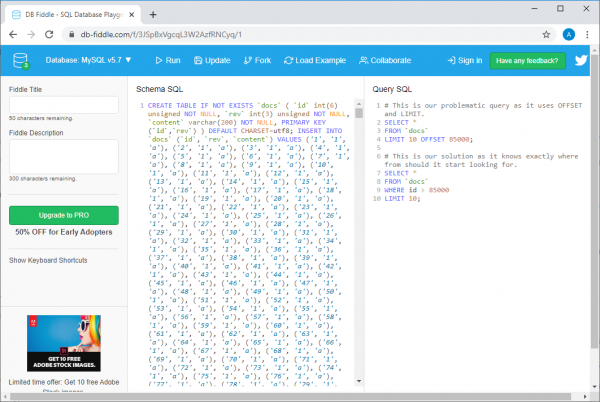
Näide db-fiddle.com lehelt
Vasakul, väljadel Schema SQL, on kood, mis sisestab andmebaasi 100000 rida, ja paremal, väljadel Query SQL, on esitatud kaks päringut. Esimene, aeglane, näeb välja selline:
SELECT *
FROM `docs`
LIMIT 10 OFFSET 85000;
Teine, mis on tõhus lahendus sama ülesande jaoks, on selline:
SELECT *
FROM `docs`
WHERE id > 85000
LIMIT 10;
Nende päringute täitmiseks piisab, kui vajutada nuppu Run lehe ülaosas. Pärast seda võrrelgem päringute täitmise aega. Selgub, et ebaefektiivse päringu täitmiseks kulub vähemalt 30 korda rohkem aega kui teise täitmiseks (iga käivitamise korral võib see aeg varieeruda, näiteks süsteem võib teatada, et esimese päringu täitmiseks kulus 37 ms, teine aga 1 ms).
Ja kui andmeid on rohkem, halveneb see veelgi (kui soovite selles veenduda, vaadake minu 10 miljoni realise andmestiku näidet).
See, mida me just arutasime, peaks andma teile mingisuguse arusaama sellest, kuidas andmebaasi päringud tegelikult töötavad.
Pidage meeles, et mida suurem on väärtus OFFSET — seda kauem võtab päringu täitmine aega.
Mida kasutada kombinatsiooni OFFSET ja LIMIT asemel?
Kombinatsiooni asemel OFFSET ja LIMIT on mõistlik kasutada järgnevat struktuuri:
SELECT * FROM table_name WHERE id > 10 LIMIT 20
See on lehekestamine, mis põhineb kursori kasutamisel.
Selle asemel, et säilitada praeguseid OFFSET ja LIMIT ja edastada neid iga päringuga, tuleb salvestada viimane saadud põhivõti (tavaliselt see on ID) ja LIMIT, mille tulemusena saadakse päringud, mis meenutavad ülaltoodud.
Miks? Asja on selles, et kui te märkite selgelt viimase loetud rea identifikaatori, siis te annate oma andmebaasi haldustarkvarale teada, kust alustada vajalike andmete otsimist. Otsing toimub tõhusalt tänu võtme kasutamisele, süsteem ei pea häirima, et otsida ridu, mis jäävad väljapoole näidatud vahemikku.
Vaadakem järgmisi erinevate päringute jõudluse võrdlusi. Siin on ebaefektiivne päring.
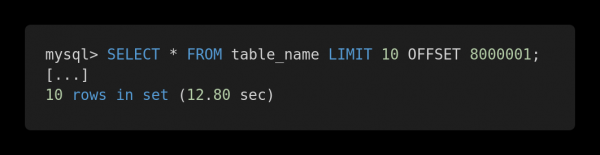
Aeglane päring
Ja siin on selle päringu optimeeritud versioon.
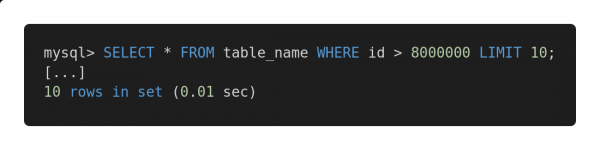
Kiire päring
Mõlemad päringud tagastavad täpselt sama andmehulga. Kuid esimese täitmiseks kulub 12,80 sekundit, teise jaoks aga 0,01 sekundit. Tunnete erinevust?
Võimalikud probleemid
Effektiivse päringute täitmise meetodi tagamiseks peab tabelis olema veerg (või veerud), mis sisaldavad unikaalseid ja järjestatud indekseid, nagu täisarvuline identifikaator. Mõningatel spetsiifilistel juhtudel võib see määrata, kas selliseid päringuid on võimalik kasutada andmebaasi töö kiirusel parandamiseks.
Loomulikult, päringute koostamisel tuleb arvesse võtta tabelite arhitektuuri eripära ning valida mehhanismid, mis näitavad end olemasolevates tabelites parimat. artiklit.
Kui seisame silmitsi primaarvõtme puudumise probleemiga, näiteks kui meil on tabel, kus on "palju-palju", siis traditsiooniline lähenemine, mis eeldab rakendamist OFFSET ja LIMIT, sobib meile kindlasti. Kuid selle rakendamine võib tuua kaasa potentsiaalselt aeglaste päringute täitmise. Sellisel juhul soovitaksin kasutada automaatselt suurenemist toetavat primaarvõtit, isegi kui see on vajalik ainult leheküljel tehtavate päringute täitmiseks.
Kui teema huvitab — , ja — mõned kasulikud materjalid.
Kokkuvõte
Peamine järeldus, mille me teha saame, on see, et olenemata andmebaasi suurusest tuleb alati analüüsida päringute täitmise kiirus. Tänapäeval on lahenduste skaleeritavus äärmiselt oluline, ja kui alustada süsteemi projekteerimist õigesti, võib see tulevikus vabastada arendaja paljusid probleemidest.
Kuidas te analüüsite ja optimeerite andmebaaside päringuid?
Allikas: habr.com
