

Tere Habr!
Tuletame meelde, et järgides raamatut umbes oleme avaldanud sama huvitava teose raamatukogust .

Praegu õpib kogukond selle võimsa tööriista piire tundma. Niisiis, hiljuti ilmus artikkel, mille tõlget tahaksime teile tutvustada. Autor räägib oma kogemusest, kuidas muuta Kafka Streams hajutatud andmesalvestuseks. Nautige lugemist!
Apache raamatukogu kasutatakse kogu maailmas ettevõtetes hajutatud vootöötluseks peale Apache Kafka. Üks selle raamistiku alahinnatud aspekte on see, et see võimaldab salvestada niidi töötlemisel põhinevat kohalikku olekut.
Selles artiklis räägin teile, kuidas meie ettevõttel õnnestus pilverakenduste turvalisuse toote arendamisel seda võimalust kasumlikult kasutada. Kafka Streamsi abil lõime jagatud oleku mikroteenused, millest igaüks toimib tõrketaluvusega ja väga kättesaadava usaldusväärse teabe allikana süsteemis olevate objektide oleku kohta. Meie jaoks on see samm edasi nii töökindluse kui ka toe lihtsuse osas.
Kui olete huvitatud alternatiivsest lähenemisest, mis võimaldab teil kasutada ühtset keskandmebaasi, et toetada oma objektide formaalset seisukorda, lugege seda, see on huvitav...
Miks me arvasime, et on aeg muuta seda, kuidas me jagatud olekuga töötame?
Meil oli vaja säilitada erinevate objektide seisukord agentide aruannete põhjal (näiteks: kas saiti rünnati)? Enne Kafka Streamsile üleminekut kasutasime oleku haldamisel sageli ühte keskandmebaasi (+ teenuse API). Sellel lähenemisviisil on oma puudused: järjepidevuse ja sünkroonimise säilitamine muutub tõeliseks väljakutseks. Andmebaas võib muutuda kitsaskohaks või sattuda sinna ja kannatavad ettearvamatuse käes.
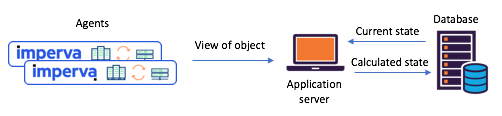
Joonis 1: Tüüpiline jagatud oleku stsenaarium, mida nähti enne üleminekut
Kafka ja Kafka Streams: agendid edastavad oma vaateid API kaudu, värskendatud olek arvutatakse keskandmebaasi kaudu
Tutvuge Kafka Streamsiga, mis muudab jagatud osariigi mikroteenuste loomise lihtsaks
Umbes aasta tagasi otsustasime nende probleemide lahendamiseks oma ühiseid stsenaariume põhjalikult läbi vaadata. Otsustasime kohe proovida Kafka Streamsi – teame, kui skaleeritav, hästi kättesaadav ja tõrketaluvus see on, millised rikkalikud voogedastusfunktsioonid sellel on (teisendused, sealhulgas olekupõhised). Just see, mida vajasime, rääkimata sellest, kui küpseks ja usaldusväärseks on Kafka sõnumisüsteem muutunud.
Kõik meie loodud olekupõhised mikroteenused ehitati üsna lihtsa topoloogiaga Kafka Streamsi eksemplari peale. See koosnes 1) allikast 2) püsiva võtmeväärtuse hoidjaga protsessorist 3) valamust:
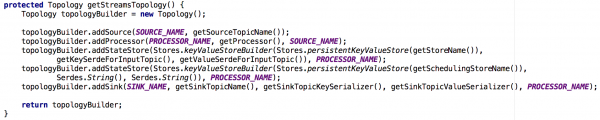
Joonis 2. Meie voogesituse eksemplaride vaiketopoloogia olekupõhiste mikroteenuste jaoks. Pange tähele, et siin on ka hoidla, mis sisaldab planeerimise metaandmeid.
Selle uue lähenemisviisi korral koostavad agendid sõnumeid, mis suunatakse lähteteemasse, ja tarbijad – näiteks meiliteatiste teenus – saavad arvutatud jagatud oleku läbi valamu (väljundteema).
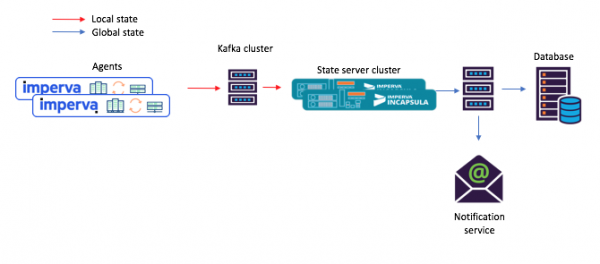
Joonis 3: Uus ülesandevoo näide jagatud mikroteenustega stsenaariumi jaoks: 1) agent genereerib sõnumi, mis jõuab Kafka lähteteema juurde; 2) jagatud olekuga mikroteenus (kasutades Kafka Streams) töötleb seda ja kirjutab arvutatud oleku lõplikku Kafka teemasse; mille järel 3) tarbijad aktsepteerivad uut olekut
Hei, see sisseehitatud võtmeväärtuste pood on tegelikult väga kasulik!
Nagu eespool mainitud, sisaldab meie jagatud oleku topoloogia võtmeväärtuste salvestust. Leidsime selle kasutamiseks mitu võimalust ja kahte neist kirjeldatakse allpool.
Valik nr 1: kasutage arvutusteks võtmeväärtuste salvestust
Meie esimene võtmeväärtuste pood sisaldas arvutusteks vajalikke abiandmeid. Näiteks mõnel juhul määrati jagatud riik "enamuse häälte" põhimõttel. Hoidlas võiks olla kõik viimased agendiaruanded mõne objekti oleku kohta. Seejärel, kui saime ühelt või teiselt agendilt uue aruande, saime selle salvestada, hankida salvestuselt kõigi teiste agentide aruanded sama objekti oleku kohta ja arvutust korrata.
Alloleval joonisel 4 on näidatud, kuidas me avasime võtme/väärtuste hoidla protsessori töötlemismeetodile, et uut sõnumit saaks seejärel töödelda.
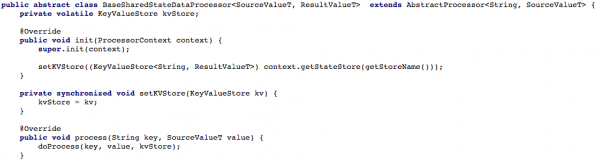
Illustratsioon 4: avame protsessori töötlemismeetodi võtmeväärtuste hoidlale juurdepääsu (pärast seda peab iga jagatud olekuga töötav skript seda meetodit rakendama doProcess)
Valik nr 2: CRUD API loomine Kafka Streamsi peal
Olles loonud oma põhiülesannete voo, hakkasime meie jagatud riigi mikroteenuste jaoks proovima kirjutada RESTful CRUD API-d. Tahtsime, et oleks võimalik hankida mõne või kõigi objektide olekut, samuti määrata või eemaldada objekti olekut (kasulik taustaprogrammi toe jaoks).
Kõigi Get State API-de toetamiseks salvestasime selle pikka aega sisseehitatud võtmeväärtuste salves, kui meil oli vaja olek töötlemise ajal ümber arvutada. Sel juhul muutub sellise API juurutamine ühe Kafka Streamsi eksemplari abil üsna lihtsaks, nagu on näidatud allolevas loendis:
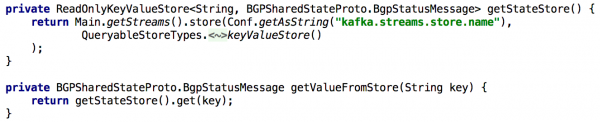
Joonis 5. Sisseehitatud võtmeväärtuste salvestusruumi kasutamine objekti eelarvutatud oleku saamiseks
Samuti on lihtne rakendada objekti oleku värskendamist API kaudu. Põhimõtteliselt pole vaja teha muud, kui luua Kafka produtsent ja kasutada seda uut olekut sisaldava plaadi tegemiseks. See tagab, et kõiki API kaudu genereeritud sõnumeid töödeldakse samamoodi nagu teistelt tootjatelt (nt agentidelt) saadud sõnumeid.

Joonis 6: Kafka tootja abil saate määrata objekti oleku
Väike komplikatsioon: Kafkal on palju vaheseinu
Järgmisena soovisime jagada töötlemiskoormust ja parandada saadavust, pakkudes jagatud oleku mikroteenuste klastri stsenaariumi kohta. Seadistamine oli imelihtne: kui konfigureerisime kõik eksemplarid töötama sama rakenduse ID (ja samade alglaadimisserverite) all, tehti peaaegu kõik muu automaatselt. Samuti täpsustasime, et iga lähteteema koosneb mitmest partitsioonist, nii et iga eksemplari saab määrata selliste partitsioonide alamhulga.
Mainin ka ära, et tavaks on teha osariigipoest varukoopia, et näiteks pärast tõrget taastumise korral see koopia teisele eksemplarile üle kanda. Iga Kafka Streamsi osariigi poe jaoks luuakse paljundatud teema koos muudatuste logiga (mis jälgib kohalikke värskendusi). Seega varustab Kafka pidevalt riigipoodi. Seetõttu saab ühe või teise Kafka Streamsi eksemplari rikke korral olekusalve kiiresti taastada teisel eksemplaril, kuhu vastavad partitsioonid lähevad. Meie testid on näidanud, et seda tehakse mõne sekundiga, isegi kui poes on miljoneid plaate.
Liikudes ühelt jagatud olekuga mikroteenuselt mikroteenuste klastrile, muutub Get State API juurutamine vähem triviaalseks. Uues olukorras sisaldab iga mikroteenuse olekupood ainult osa tervikpildist (need objektid, mille võtmed olid seotud konkreetse partitsiooniga). Pidime kindlaks määrama, milline eksemplar sisaldab vajaliku objekti olekut, ja tegime seda lõime metaandmete põhjal, nagu allpool näidatud:
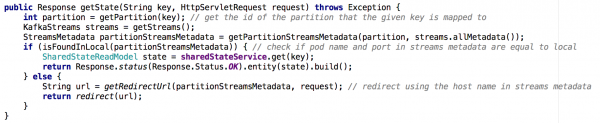
Joonis 7: Voo metaandmete abil määrame, millisest eksemplarist soovitud objekti olekut küsida; sarnast lähenemist kasutati GET ALL API puhul
Peamised järeldused
Kafka Streamsi osariigi kauplused võivad toimida de facto hajutatud andmebaasina,
- pidevalt paljundatud Kafkas
- Sellise süsteemi peale saab hõlpsasti ehitada CRUD API
- Mitme partitsiooni käsitlemine on veidi keerulisem
- Samuti on võimalik lisaandmete salvestamiseks lisada voogedastustopoloogiasse üks või mitu olekusalvesti. Seda valikut saab kasutada:
- Arvutusteks vajalike andmete pikaajaline säilitamine voo töötlemise ajal
- Andmete pikaajaline salvestamine, mis võib olla kasulik voogesituse eksemplari järgmisel korral
- palju rohkem...
Need ja muud eelised muudavad Kafka Streamsi hästi sobivaks globaalse seisundi säilitamiseks meie omaga sarnases hajutatud süsteemis. Kafka Streams on osutunud tootmises väga töökindlaks (meil pole pärast selle kasutuselevõttu praktiliselt ühtegi sõnumit kadunud) ja oleme kindlad, et selle võimalused ei piirdu sellega!
Allikas: www.habr.com
