

Сразу объясню название статьи. Изначально планировалось дать хороший, надежный совет по ускорению использования рефлекшена на простом, но реалистичном примере, однако в ходе бенчмаркинга выяснилось, что рефлексия работает не так медленно, как я думал, LINQ работает медленнее, чем снилось в кошмарах. А в итоге оказалось, что мной еще и была допущена ошибка в замерах… Подробности этой жизненной истории под катом и в комментариях. Так как пример достаточно бытовой и реализованный в принципе как обычно делается в энтерпрайзе, получилось достаточно интересная, как мне кажется, демонстрация жизни: влияния на скорость работы основного предмета статьи было не заметно из-за внешней логики: Moq, Autofac, EF Core и прочей «обвязки».
Начал я работу под впечатлением от этой статьи:
Nähtavasti soovitab autor kasutada kompileeritud delegaatide asemel otse refleksioonitüüpide meetodite juurde pöördumist, mis on suurepärane viis rakenduse töö kiirus axe kiirendamiseks. Seal on loomulikult ka IL emissioon, kuid seda oleks soovitav vältida, kuna see on kõige töömahukam ülesande täitmise viis, mis toob endaga kaasa vigu.
Arvestades, et olen alati sarnase arvamuse jaganud refleksiooni kiirusest, ei kavatsenud ma autori järeldusi eriti kahtluse alla seada.
Ma ei kohtunud harva naiivse refleksiooni kasutamisega ettevõttes. Võetakse tüüp. Võetakse teave omaduse kohta. Kutsutakse välja meetod SetValue ja kõik on rõõmsad. Väärtus jõuab sihtväljakule, kõik on rahul. Inimesed ei ole üldse lollid — vanemad ja tiimijuhid — kirjutavad oma laiendusi objektile, tuginedes sellisele naiivsele teostusele, tehes „universaalseid“ mappereid ühelt tüübilt teisele. Tavaliselt on asi selles: võtame kõik väljad, võtame kõik omadused, iteratsioonime nende üle: kui nimed klapitavad, siis täidame SetValue. Aeg-ajalt saame erandeid seal, kus ei leia mõnda omadust ühelt tüüpidelt, kuid ka siin on lahendus, mis parandab jõudlust. Try/catch.
Olen näinud, kuidas inimesed leiutavad parsereid ja mappereid, olles samas täiesti teadmatud, kuidas varem välja mõeldud rattaid töötab. Olen näinud, kuidas inimesed varjavad oma naiivseid rakendusi strateegiate, liideste ja süstimise taha, justkui see oleks vabandus järgneva kaose jaoks. Sellest tüüpi rakendustest olen ma eemale hoidnud. Tegelikult ei ole ma tõelist jõudluse kadu mõõtnud ja võimalusel vahetasin lihtsalt rakenduse «optimaalsema» vastu, kui selleks aega leidsin. Seega, esimesed mõõtmised, millest allpool juttu, tõid mind tõsiselt segadusse.
Mõtle, et paljud teist, lugedes Richterit või teisi ideolooge, on silmitsi seisnud täitsa õigustatud väitega, et refleksioon koodis on nähtus, mis avaldab äärmiselt negatiivset mõju rakenduse jõudlusele.
Peegli kutsumine sunnib CLR-i kogusid uurima, vajalikud metadata tooma, neid analüüsima jne. Peale selle, peegeldamine järjestuste läbimisel põhjustab suurt mälu kasutust. Mälule kulutades, CLR vabastab GC-ja ja hakkavad tekkima viivitused. See on kindlasti aeglane, uskuge. Kaasaegsete tootmiserverite või pilvemasinate suuremad mäluressursid ei päästa teid kõrgetest töötlemise viivitustest. Tegelikult, mida rohkem mälu, seda suurem on tõenäosus, et te märkate, kuidas GC töötab. Peegeldamine on oma olemuselt liigne punane kalts selle jaoks.
Tõepoolest, me kõik kasutame nii IoC konteinerit kui ka andmete kaardistajaid, mille tööpõhimõtted põhinevad samuti peegeldamisel, kuid nende jõudluse osas ei esine tavaliselt küsimusi. Ei, mitte sellepärast, et sõltuvuste süstimine ja väliste piiratud konteksti mudelitest eristamine oleksid nii olulised asjad, et peaksime jõudluse nimel igal juhul ohverdama. Asi on lihtsam – see tõesti ei mõjuta jõudlust oluliselt.
Tõsiasi on see, et kõige levinumad raamistiku tehnoloogiad, mis põhinevad refleksioonil, kasutavad erinevaid nippide abil, et tagada efektiivsem töö. Üldiselt kasutatakse vahemälu. Tüüpiliselt on need väljendid ja kompressitud väljendite puu delegeeritud funktsioonid. Sama automaapper hoiab konkurentsivõimelist sõnastikku, mis seob tüübid funktsioonidega, mis suudavad üksteisega ümber konverteerida juba ilma refleksiooni kutsumiseta.
Kuidas seda saavutatakse? Põhimõtteliselt ei erine see loogikast, mida platvorm ise kasutab JIT koodi genereerimiseks. Esimese väljakutse korral kompileeritakse meetod (jah, see protsess ei ole kiire), kuid järgnevate väljakutsetega antakse juhtimine juba kompileeritud meetodile, kus erilisi jõudluse langusi ei toimu.
Meie puhul saame kasutada JIT kompileerimist ja seejärel kasutada kompileeritud käitumist sama jõudlusega nagu AOT analoogid. Expressions tulevad meile selles osas appi.
Lühidalt võib printsiipi, millest jutt, kokku võtta järgmiselt:
Refleksiooni lõpphaldust tuleks vahemälu hoida delegeeritud funktsiooni kujul, mis sisaldab kompileeritud funktsiooni. Kõik vajalikud tüübiinfo objektid tasuks samuti salvestada teie tüübi väli — töötaja.
Selles on mõte. Terve mõistus ütleb meile, et kui midagi saab kompileerida ja vahemällu salvestada, siis tasub seda teha.
Kellestki ette pääsemiseks tuleb öelda, et vahemälu kasutamisel refleksiooniga on oma eelised, isegi kui ei kasuta soovitatud väljendite kompileerimise meetodit. Siinkohal kordaksin lihtsalt artikli autori teese, millele viitan üleval.
Nüüd koodist. Vaatame näidet, mis põhineb minu hiljutisel valul, millega pidin tõsiselt tegelema tõsises krediidiasutuses. Kõik entiteedid on väljamõeldud, et keegi ei rikuks saladust.
On olemas mingisugune entiteet. Olgu see Contact. On kirjad, millel on standardiseeritud sisu, millest parsi ja hudrator loovad need kontaktid. Kiri saabus, loeme selle läbi, jagame võtme-väärtuse paarideks, loome kontakti ja salvestame andmebaasi.
See on elementaarne. Oletame, et kontaktis on omadused Nimi, Vanus ja kontakttelefon. Need andmed edastatakse ka kirjas. Samuti soovib äri, et tugiteenused saaksid kiiresti lisada uusi võtmeid, et kaardistada omadused paarid kirja kehas. Kui keegi tegi šabloonis trüki- või kui enne väljalaskmist on vaja kiiresti algatada uus kaardistus uutelt partneritelt, kohandudes uue formaadiga. Siis saame uue kaardistuse korrelatsiooni lisada odava andmefiksina. See tähendab, et toome näite elust.
Rakendame, loome teste. Toimib.
Koodi ma ei too: koode on saanud liiga palju ja need on saadaval GitHubis, lingi leiate artikli lõpust. Saate neid alla laadida, masendavalt muuta ja mõõta, kuidas see teie puhul mõjuks. Toon välja ainult kahe šabloonimeetodi koodi, mis eristavad kiiret hüdratorit aeglasest hüdratorist.
Loogika on järgmine: mallimeetod saadab paare, mis on moodustatud parsi põhiloogikast. LINQ tase on parser ja hüdreerija põhiloogika, mis küsib andmebaasi kontekstist ja vastab võtmed paaridele parserist (nende funktsioonide jaoks on olemas kood ilma LINQ-ita võrreldes). Seejärel edastatakse paarid peamisse hüdreerimise meetodisse ja väärtused seadistatakse vastavatesse entiteedi omadustesse.
„Kiire” (Prefiks Fast tehingute testides):
protected override Contact GetContact(PropertyToValueCorrelation[] correlations)
{
var contact = new Contact();
foreach (var setterMapItem in _proprtySettersMap)
{
var correlation = correlations.FirstOrDefault(x => x.PropertyName == setterMapItem.Key);
setterMapItem.Value(contact, correlation?.Value);
}
return contact;
}
Nagu me näeme, kasutatakse staatilist kollektsiooni omaduste seadeid - kompileeritud lambdana, mis kutsuvad esile entiteedi seadiseid. Need luuakse järgmise koodiga:
static FastContactHydrator()
{
var type = typeof(Contact);
foreach (var property in type.GetProperties())
{
_proprtySettersMap[property.Name] = GetSetterAction(property);
}
}
private static Action GetSetterAction(PropertyInfo property)
{
var setterInfo = property.GetSetMethod();
var paramValueOriginal = Expression.Parameter(property.PropertyType, "value");
var paramEntity = Expression.Parameter(typeof(Contact), "entity");
var setterExp = Expression.Call(paramEntity, setterInfo, paramValueOriginal).Reduce();
var lambda = (Expression<Action>)Expression.Lambda(setterExp, paramEntity, paramValueOriginal);
return lambda.Compile();
}
Üldiselt on arusaadav. Käime läbi omadused, loome nende põhjal delegaadid, mis kutsuvad esile seadeid, salvestame. Siis kutsume välja, kui on vaja.
„Aeglane” (eelseisvas Slow märk jaotustes):
protected override Contact GetContact(PropertyToValueCorrelation[] correlations)
{
var contact = new Contact();
foreach (var property in _properties)
{
var correlation = correlations.FirstOrDefault(x => x.PropertyName == property.Name);
if (correlation?.Value == null)
continue;
property.SetValue(contact, correlation.Value);
}
return contact;
}
Siin käime kohe läbi omadused ja kutsume otse välja SetValue.
Selguse huvides ja võrdluseks rakendasin lihtsat meetodit, mis kirjutab paaride korrelatsiooni väärtused otse entiteetide väljadele. Eesliide – Manual.
Võtame nüüd BenchmarkDotNet'i ja uurime jõudlust. Ja järsku… (spoiler — see ei ole õige tulemus, üksikasjad — allpool)
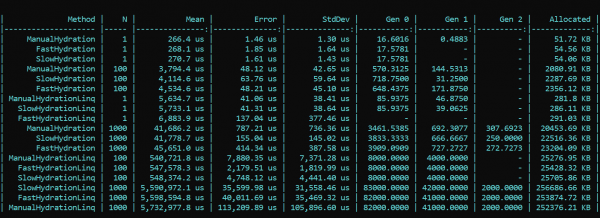
Mida me siin näeme? Meetodid, kes uhkelt kannavad eesliidet Fast, on peaaegu kõigil läbimistel aeglasemad kui meetodid, mille eesliide on Slow. See kehtib nii allokatsiooni kui ka töökiirusena. Teisalt, kena ja elegantne rakendus, mis kasutab kõikjal, kus võimalik, selleks mõeldud LINQ meetodeid, sööb vastupidiselt jõudlust tohutult. Erinevused on tohutud. Suundumus ei muutu erineva läbimise arvu korral. Erinevus on vaid mõõtkavas. LINQ puhul on 4 — 200 korda aeglasem, prügi on samuti umbes samas ulatuses rohkem.
UPDATEeritud
Ma ei saanud oma silmi uskuda, aga mis veelgi olulisem, meie kolleeg ei uskunud mitte ainult minu silmi, vaid ka minu koodi — . Kontrollides oma lahendust, tuvastas ta suurepäraselt vea, mille ma mitmete muudatuste tõttu algversioonist lõppversioonini unustasin. Pärast Moqi seadistuses leitud vea parandamist, olid kõik tulemused oma kohtadel. Uuesti testimise tulemused näitavad, et peamine suundumus ei muutu — LINQ mõjutab jõudlust endiselt tugevamini kui refleksioon. Küll aga on hea kuulda, et avalduste kompileerimise töö ei lähe raisku, ja tulemused on nähtavad nii allokaatoris kui ka käitusaegades. Esimene käivitamine, mil statilised väljad initsialiseeritakse, on loogiliselt aeglasem 'kiire' meetodi puhul, kuid edaspidi olukord muutub.
Siin on uuesti testimise tulemus:
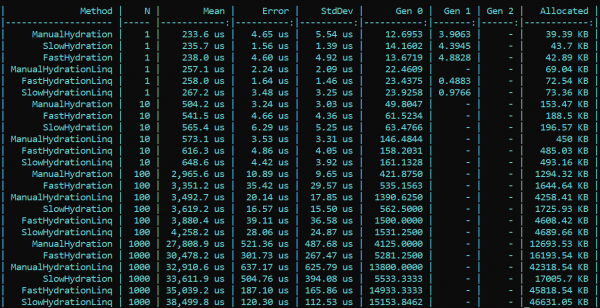
Järeldus: ettevõttes refleksiooni kasutamisel pole erilisi trikke vaja — LINQ vähendab jõudlust rohkem. Siiski, kõrge koormusega meetodites, mis vajavad optimeerimist, võib refleksiooni säilitada initsialiseerijate ja delegaatide kompilaatorite kujul, mis tagavad hiljem 'kiire' loogika. Nii saate säilitada nii refleksiooni paindlikkuse kui ka rakenduse töö kiirus.
Benchmarki kood on saadaval siin. Kõik huvilised saavad mu sõnu üle kontrollida:
PS: kooditestides kasutatakse IoC-d, samas kui benchmarkides on kasutusel selge konstruktsioon. Lõpplahenduses jätsin välja kõik tegurid, mis võiksid mõjutada jõudlust ja tulemusi häirida.
PPS: Aitäh kasutajale minu Moq seadistuse vea avastamise eest, mis mõjutas esimesi mõõtmisi. Kui kellegil lugejatest on piisavalt karmaaktsiooni, palun andke talle like. Inimene tegi peatuse, luges süvenenult, kontrollis üle ja osutas veale. Arvan, et see väärib lugupidamist ja simpatiat.
PPPS: aitäh sellele põhjalikule lugejale, kes uuris stiili ja vormindust. Olen ühtsuse ja mugavuse poolt. Esituse diplomaatilisus võiks olla parem, aga ma arvestasin kriitikaga. Palun, olge valmis.
Allikas: habr.com
