

See artikkel on tõlge minu artiklist Mediumis — , mis osutus üsna populaarseks, ilmselt oma lihtsuse tõttu. Seetõttu otsustasin selle kirjutada eesti keeles ja veidi täiendada, et tavaline inimene, kes ei ole andmeanalüütika spetsialist, saaks aru, mis on andmehoidla (DW) ja mis on andmejärv (Data Lake) ning kuidas nad koos eksisteerivad.
Miks soovisin kirjutada andmejärvest? Olen töötanud andmete ja analüütikaga üle 10 aasta ning hetkel tegelen kindlasti suurandmete kasutamisega Amazon Alexa AI-s Cambridges, mis asub Bostoni lähedal, kuigi elan ise Victoria's Vancouveri saarel ja olen sageli Bostoni, Seattle'i ja Vancouveri vahel, vahel isegi Moskvas konverentsidel esinemas. Samuti kirjutan aeg-ajalt, kuid peamiselt inglise keeles, ja olen juba kirjutanud , samuti on mul vajadus jagada analüütika trende Põhja-Ameerikas, ja vahel kirjutan ka .
Olen alati töötanud andmehoidlate kallal ja alates 2015. aastast olen aktiivselt tegelenud Amazon Web Servicesiga, üldiselt olen suundunud pilveanalüütikale (AWS, Azure, GCP). Olen jälginud analüütikalahenduste arengut alates 2007. aastast ning töötasin isegi andmehoidlate tarnijana Teradata, rakendades seda Sberbankis, kus hakkas esmakordselt leidma kasutust Big Data koos Hadoopiga. Kõik hakkasid rääkima, et andmehoidlate ajastu on möödas ja nüüd on kõik Hadoopis, hiljem hakati rääkima andmejärvest, jälle väideti, et andmehoidlate aeg on tõeliselt lõppenud. Kuid õnneks (võib-olla on see kellegi jaoks ka õnnetus, kes teenis palju raha Hadoopi seadistamisel) andmehoidla ei ole kadunud.
Selles artiklis vaatleme, mis on andmejärv. Artikkel on suunatud inimestele, kellel on andmehoidlate kohta vähene või üldse mitte teadmisi.

Pildil on Bledi järv, see on üks minu lemmikjärvi, kuigi olen seal olnud vaid korra, jäin selle meelde kogu eluks. Kuid räägime teisest järve tüübist — andmejärvest. Võimalik, et paljud teist on seda terminit korduvalt kuulnud, kuid veel üks määratlus ei tee kellelegi paha.
Esiteks, siin on kõige populaarsemad määratlused andmejärvest:
„Kõikide toorandmete failide salvestamine, mis on kergesti kergesti kättesaadavad analüüsimiseks organisatsioonis“ — Martin Fowler.
„Kui arvad, et andmevaade on pudel puhtast veest — puhastatud, pakendatud ja mugavaks tarbimiseks, siis andmejärv on meile tohutu reservuaar veega selle looduslikus vormis. Kasutajad saavad sealt vett võtta, sügavale sukelduda, uurida“ — James Dixon.
Nüüd teame kindlasti, et andmejärv on seotud analüüsi ja see võimaldab meil hoida suuri andmemahtusid nende algses vormis ning meil on vajalik ja mugav juurdepääs andmetele.
Mulle meeldib asju lihtsustada, kui suudan keerulist mõistet lihtsate sõnadega selgitada, siis olen ise aru saanud, kuidas see töötab ja milleks see vajalik on. Ühel hetkel, kui uurisin oma iPhone'i fotoalbumit, sain aru, et see on tõeline andmejärv, ma isegi tegin konverentside jaoks slaidi:
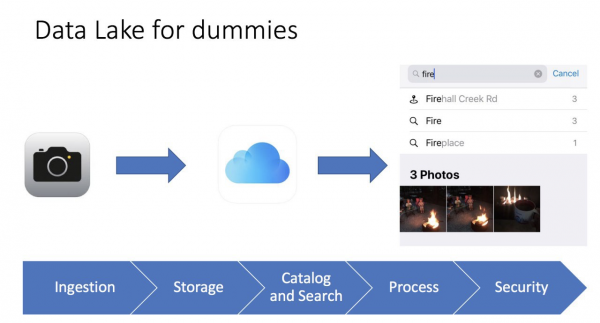
Kõik on väga lihtne. Teeme pildi telefoniga, pilt salvestatakse telefonisse ja seda saab salvestada iCloudi (pilveteenuse hoidla) ka. Samuti kogub telefon pildi metaandmeid: mis on pildil, geosildid, aeg. Tulemusena saame kasutada mugavat iPhone'i liidest, et leida meie pilt, ja näeme isegi näitajaid, näiteks kui otsin pilte sõnaga tuli (fire), leian 3 pilti lõkke pildiga. Minu jaoks on see justkui Business Intelligence tööriist, mis töötab väga kiiresti ja täpselt.
Ja muidugi ei tohi me unustada turvalisust (autoriseerimist ja autentimist), vastasel juhul võivad meie andmed kergesti avalikku ruumi sattuda. Palju uudiseid suurte ettevõtete ja idufirmade kohta, kelle andmed sattusid avalikku ruumi arendajate hoolimatuse ja lihtsate reeglite järgimise eiramise tõttu.
Isegi selline lihtne pilt aitab meil mõista, mis on and lake, selle erinevused traditsioonilisest andmete hoidlast ja selle põhielemendid:
- Andmete laadimine (Ingestion) — andmete järve peamine koostisosa. Andmed võivad andmehoidlasse jõuda kahel viisil — batch (andmete laadimine intervallide kaupa) või streaming (andmevoog).
- Failihaldus (Storage) — andmejärve põhikomponent. Meie vajaduseks on, et hoidla oleks kergesti skaleeritav, äärmiselt usaldusväärne ja madala hinnaga. Näiteks AWS-is on see S3.
- Kataloog ja Otsing (Catalog and Search) — et vältida andme sohu (mis juhtub, kui kõik andmed visatakse ühte kuhja ja hiljem on nendega keeruline töötada), peab olema loodud metaandmete kiht andmete klassifitseerimiseks, et kasutajad saaksid hõlpsasti leida analüüsiks vajalikke andmeid. Täiendavalt saab kasutada täiendavaid otsingulahendusi, näiteks ElasticSearch. Otsing aitab kasutajal vajalikku teavet mugava liidese kaudu otsida.
- Töötlemine (Process) — see etapp vastutab andmete töötlemise ja transformeermise eest. Saame andmeid ümber töötleda, nende struktuure muuta, puhastada ja palju muud.
- Ohutus (Security) — oluline on investeerida aega turvadesaini. Näiteks andmete krüpteerimine nende säilitamise, töötlemise ja edastamise ajal. Oluline on kasutada autentimise ja autoriseerimise meetodeid. Kokkuvõttes on vajalik auditeerimise tööriist.
Praktilisest vaatenurgast võime andmejärve iseloomustada kolme omadusega:
- Koguge ja salvestage kõike — andmejärv sisaldab kõiki andmeid, alates toores töötlemata andmetest mis tahes ajavahemiku jooksul kuni töödeldud/puhastatud andmeteni.
- Süvaanalüüs — andmejärv võimaldab kasutajatel andmeid uurida ja analüüsida.
- Paindlik ligipääs — andmejärv tagab paindliku ligipääsu erinevatele andmetele ja erinevatele stsenaariumidele.
Nüüd saame rääkida andmehoidla ja andmejärve vahetest. Tavaline küsimus on:
- Ent kuidas jääb andmehoidla?
- Kas asendame andmehoidla andmejärvega või laiendame seda?
- Kas on võimalik ilma andmejärveta hakkama saada?
Lühidalt öeldes pole selget vastust. Kõik sõltub konkreetsest olukorrast, meeskonna oskustest ja eelarvest. Näiteks andmete salvestamise migratsioon Oracle’ist AWS-i ja andmejärve loomine Amazonile kuuluva Woot’i poolt — .
Teisest küljest väidab Snowflake, et te ei pea enam muretsema andmejärve pärast, kuna nende andmeplatvorm (kuni 2020. aastani andmesalvestus) võimaldab teil ühendada nii andmejärve kui ka andmesalvestuse. Ma olen natuke töötanud Snowflake’iga ja see on tõeliselt ainulaadne toode, mis oskab seda teha. Hinna küsimus on aga teine teema.
Kokkuvõttes arvan, et me vajame endiselt andmehoidlat peamiseks andmeallikaks meie aruandluses, ja kõik, mis ei mahu sisse, salvestame andmejärve. Analüüsi roll on anda ettevõttele mugav juurdepääs otsuste tegemiseks. Ükskõik kuidas vaadata, tegevus kasvajad töötavad andmehoidla mudeliga efektiivsemalt kui andmejärvega. Näiteks Amazonis on olemas Redshift (analüütiline andmehoidla) ja Redshift Spectrum/Athena (SQL liides andmejärvele S3-s, mis põhineb Hive/Presto). Sama kehtib ka teiste kaasaegsete analüütiliste andmehoidlate kohta.
Vaatame tüüpilist andmehoidla arhitektuuri:
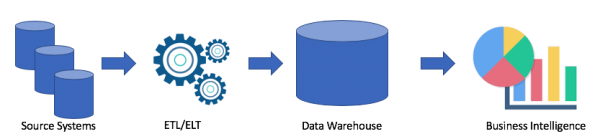
See on klassikaline lahendus. Meil on allika süsteemid, mille abil ETL/ELT protsesside kaudu kopeerime andmed analüütilisse andmehoidlasse ja ühendame need Business Intelligence lahendusega (minu lemmik on Tableau, aga mis on sinu?).
Sellisel lahendusel on järgmised puudused:
- ETL/ELT operatsioonid nõuavad aega ja ressursse.
- Reeglina on andmete salvestamiseks analüütilises andmehoidlas vajalik mälu kallis (näiteks Redshift, BigQuery, Teradata), kuna peame ostma täis klastrit.
- Ärikasutajad saavad juurdepääsu puhastatud ja sageli kokku kogutud andmetele, kuid neil ei ole võimalust saada toorandmeid.
Muidugi sõltub see teie juhtumist. Kui teil ei ole probleeme oma andmehoidla kasutamisega, siis ei ole teil üldse vaja andmejärve. Kuid kui hakkavad ilmnema ruumi, jõudluse või hinna probleemid, siis võib andmejärve kaalumine olla mõistlik. Just seetõttu on andmejärv väga populaarne. Siin on näide andmejärve arhitektuurist:
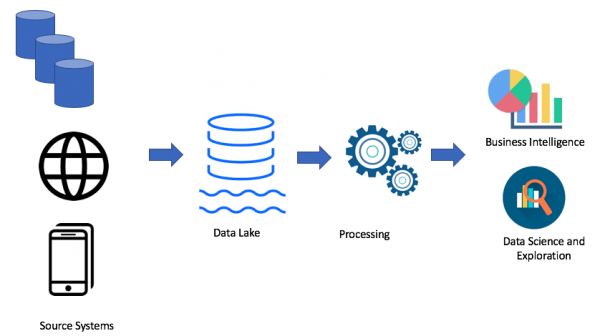
Andmejärve lähenemist kasutades laadime toorandmed oma andmejärve (kas partiina või voogu), seejärel töötleme andmeid vastavalt vajadusele. Andmejärv võimaldab ärikasutajatel luua oma andmete muudatusi (ETL/ELT) või analüüsida andmeid ärintellekti lahendustes (kui on olemas vajalik draiver).
Iga analüüsilahenduse eesmärk on teenida ärikasutajaid. Seetõttu peame alati töötama äri nõuetest lähtudes. (Amazonis on see üks põhimõtteid — tagasi töötamine).
Töötades nii andmehoidla kui ka andmejärvega, saame võrrelda mõlemat lahendust:
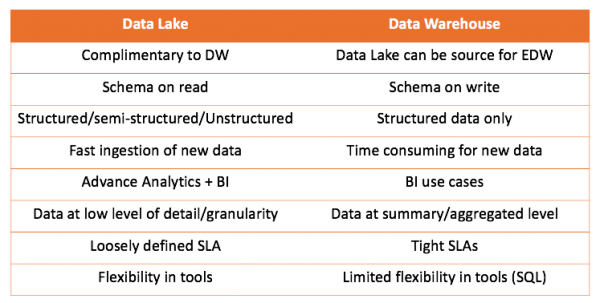
Peamine järeldus, mida teha, on see, et andmesalvestus ei konkureeri andmejärvega, vaid pigem täiendab seda. Kuid otsus, mis teie olukorrale sobib, on teie. Alati on huvitav proovida ise ja teha õigeid järeldusi.
Tahaksin rääkida ühest juhtumist, kui hakkasin rakendama andmejärve lähenemist. Kõik on üsna tavaline, proovisin kasutada ELT-tööriista (meil oli Matillion ETL) ja Amazon Redshift'i; minu lahendus töötas, kuid ei vastanud nõuetele.
Mul oli vaja võtta veebilogid, neid ümber töötleda ja koguda, et esitada andmeid kahe juhtumi jaoks:
- Turundusmeeskond soovis analüüsida robotite tegevust SEO jaoks
- IT tahtis vaadata veebilehtede töö statistikat
Väga lihtsad, väga lihtsad logid. Siin on näide:
https 2018-07-02T22:23:00.186641Z app/my-loadbalancer/50dc6c495c0c9188
192.168.131.39:2817 10.0.0.1:80 0.086 0.048 0.037 200 200 0 57
"GET https://www.example.com:443/ HTTP/1.1" "curl/7.46.0" ECDHE-RSA-AES128-GCM-SHA256 TLSv1.2
arn:aws:elasticloadbalancing:us-east-2:123456789012:targetgroup/my-targets/73e2d6bc24d8a067
"Root=1-58337281-1d84f3d73c47ec4e58577259" "www.example.com" "arn:aws:acm:us-east-2:123456789012:certificate/12345678-1234-1234-1234-123456789012"
1 2018-07-02T22:22:48.364000Z "authenticate,forward" "-" "-"Üks fail kaalus 1-4 megabaiti.
Kuid oli üks probleem. Meil oli 7 domeeni üle maailma ja ühe päeva jooksul loodi 7000 faili. See pole kuigi suur maht, kokku 50 gigabaiti. Kuid ka meie Redshifti klaster oli väikene (4 sõlme). Ühe faili traditsiooniline üleslaadimine kestis umbes minuti. Seega ei olnud ülesanne nii lihtne. Ja see oli hetk, mil otsustasin kasutada andmejärve lähenemist. Lahendus nägi välja umbes selline:
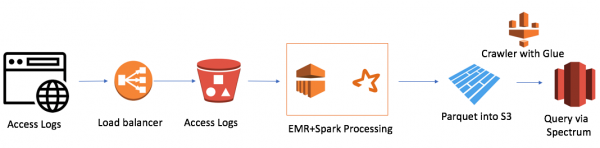
See on piisavalt lihtne (tahan märkida, et pilvetöö eelis on lihtsus). Kasutasin:
- AWS Elastic Map Reduce (Hadoop) arvutusvõimsusena
- AWS S3 failide salvestamiseks, kus on andmete krüptimise ja juurdepääsu piiramisvõimalus
- Spark mälus arvutusvõimsusena ja PySpark andmete loogika ja transformatsioonide jaoks
- Parquet Spark'i töö tulemuseks
- AWS Glue Crawler uute andmete ja partitsioonide metaandmete kogujana
- Redshift Spectrum SQL liidesena andmejärvele olemasolevatele Redshifti kasutajatele
Kõige väiksem EMR+Spark klaster töötles terve hulga faile 30 minutiga. AWS-l on ka teisi juhtumeid, eriti palju, mis on seotud Alexaga, kus andmete maht on väga suur.
Hiljuti sain teada ühe andmejärve puuduse — see on GDPR. Probleem on selles, et kui klient palub andmed kustutada ja need on ühes failis, ei saa me kasutada andmete töötlemise keelt ja DELETE käsku nagu andmebaasis.
Loodan, et see artikkel selgitas erinevust andmesalvestuse ja andmejärve vahel. Kui see huvitas, siis võin tõlkida veel oma artikleid või professionaalide artikleid, keda loen. Samuti võin rääkida lahendustest, millega töötan, ja nende arhitektuurist.
Allikas: habr.com
