

Klassikaline küsimus, millega arendaja pöördub oma DBA või äriomaniku poole — PostgreSQL konsultandi poole, kõlab peaaegu alati ühtemoodi: „Miks päringud töötlevad andmebaasis nii kaua?“
Traditsiooniline põhjuste kogum:
- efektiivne algoritm
kui otsustasite teha JOIN mitu CTE paarikümne tuhande kirje kohta - vakku statistikat
kui tegelik andmete jaotumine tabelis erineb juba oluliselt viimasest ANALYZE’ist - ressursside „ummistus“
ja juba ei piisa eraldatud arvutusvõimsusest CPU, pidevalt tõuseb gigabaite mälu või kett ei jõua kõikide andmebaasi „soovide“ täitmisega - blokaadid konkureerivatest protsessidest
Ja kui lukustused on piisavalt keerulised tabamiseks ja analüüsimiseks, siis kõigi teiste jaoks piisab meile päringute plaanist, mille saab hankida (muidugi on parem kohe EXPLAIN (ANALYZE, BUFFERS) ...) või .
Kuid nagu öeldud sama dokumentatsioonis,
„Plani mõistmine on kunst, ja selle omandamiseks on vajalik teatud kogemus…“
Aga selleta ei ole tarvis, kui kasutada õigustatud tööriistu!
Kuidas näeb tavaliselt välja päringu plaan? Nii:
Index Scan using pg_class_relname_nsp_index on pg_class (actual time=0.049..0.050 rows=1 loops=1)
Index Cond: (relname = $1)
Filter: (oid = $0)
Buffers: shared hit=4
InitPlan 1 (returns $0,$1)
-> Limit (actual time=0.019..0.020 rows=1 loops=1)
Buffers: shared hit=1
-> Seq Scan on pg_class pg_class_1 (actual time=0.015..0.015 rows=1 loops=1)
Filter: (relkind = 'r'::"char")
Rows Removed by Filter: 5
Buffers: shared hit=1või nii:
"Append (cost=868.60..878.95 rows=2 width=233) (actual time=0.024..0.144 rows=2 loops=1)"
" Buffers: shared hit=3"
" CTE cl"
" -> Seq Scan on pg_class (cost=0.00..868.60 rows=9972 width=537) (actual time=0.016..0.042 rows=101 loops=1)"
" Buffers: shared hit=3"
" -> Limit (cost=0.00..0.10 rows=1 width=233) (actual time=0.023..0.024 rows=1 loops=1)"
" Buffers: shared hit=1"
" -> CTE Scan on cl (cost=0.00..997.20 rows=9972 width=233) (actual time=0.021..0.021 rows=1 loops=1)"
" Buffers: shared hit=1"
" -> Limit (cost=10.00..10.10 rows=1 width=233) (actual time=0.117..0.118 rows=1 loops=1)"
" Buffers: shared hit=2"
" -> CTE Scan on cl cl_1 (cost=0.00..997.20 rows=9972 width=233) (actual time=0.001..0.104 rows=101 loops=1)"
" Buffers: shared hit=2"
"Planning Time: 0.634 ms"
"Execution Time: 0.248 ms"Aga lugeda plaani tekstina „paberilt” — on väga keeruline ja raskesti mõistetav:
- sõlmes kuvatakse alamsõlmede ressursside summa
ehk et mõista, kui palju aega kulus konkreetse sõlme täitmiseks või kui palju just see tabelist lugemine andmeid kettalt tõi — tuleb kuidagi üks teisest välja arvutada - sõlme aeg on vajalik korrutada loops
jah, lahutamine ei ole veel kõige keerulisem tehe, mida tuleb «meeles» teha — sest täitmise aeg määratakse keskmisena ühe sõlme täitmiseks, ja neid võib olla sadu - noh, ja kõik see kokku takistab vastamast peamisele küsimusele — nii kes on siis «nõrk lüli»?
Kui me püüdsime seda selgitada mitmele sajale meie arendajale, siis mõistsime, et väljastpoolt näeb see välja umbes nii:

Ah, nii et meil on vaja…
Tööriista
Sellesse oleme püüdnud koguda kõik võtme mehhanismid, mis aitavad plaani ja päringu kaudu mõista, «kes on süüdi ja mida teha». Noh, ja jagada osa oma kogemustest kogukonnaga.
Tere tulemast ja kasutage —
Plaanide selgus
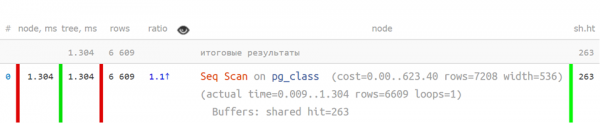
Kas on lihtne mõista plaani, kui see välja näeb nii?
Seq Scan on pg_class (reaalne aeg=0.009..1.304 read=6609 loops=1)
Buffers: jagatud hit=263
Planeerimise aeg: 0.108 ms
Täitev aeg: 1.800 ms
Ei ole eriti.
Aga nii, lühendatud kujul, kui peamised näitajad on eraldatud — on juba palju selgem:
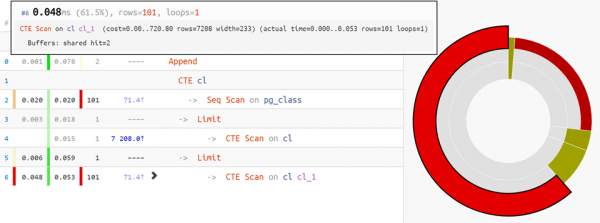
Aga kui plaan on veidi keerulisem — tuleb appi aegade jaotuse piechart sõlmede järgi:
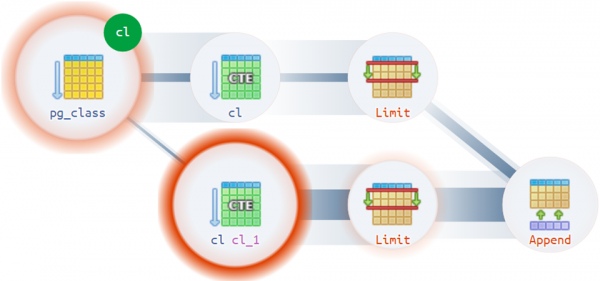
Noh, ja kõige keerulisemate variantide puhul kiirustab appi täitmise diagramm:
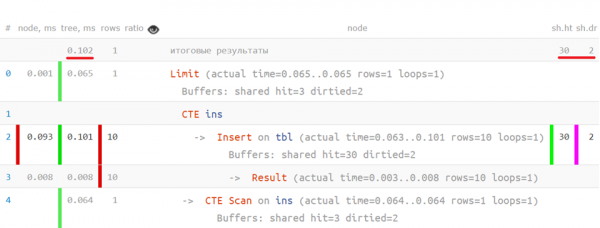
Näiteks võivad olla piisavalt keerulised olukorrad, kus plaanil võib olla rohkem kui üks tegelik juur:
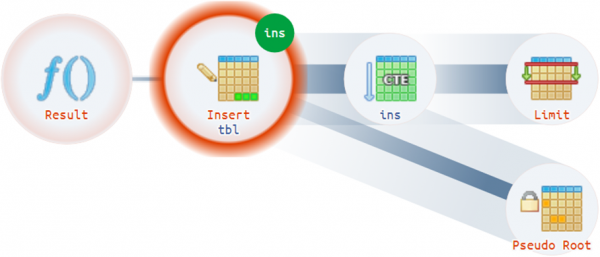
Struktuursed vihjed
Noh, ja kui kogu plaani struktuur ja selle nõrgad kohad on juba välja pandud ja nähtavad — miks mitte tuua need arendajale esile ja selgitada "venekeeles"?
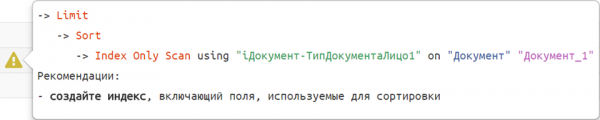 Selliseid soovitusmalle oleme kokku kogunud juba paar tosinat.
Selliseid soovitusmalle oleme kokku kogunud juba paar tosinat.
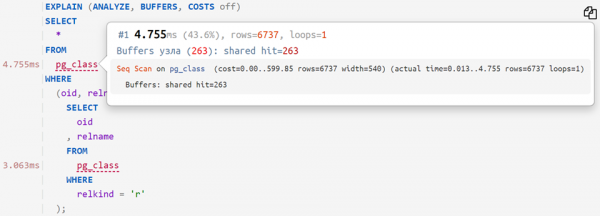
Reakutsiooni reaalajas profiiler
Nüüd, kui analüüsitavale plaanile lisada algpärane päring, siis on võimalik näha, kui palju aega kulus iga konkreetse operaatori jaoks — umbes nii:
… või isegi nii:

Parameetrite asendamine päringus
Kui olete "ühendanud" plaaniga mitte ainult päringu, vaid ka selle parameetrid DETAIL-reast logis, siis saate kopeerida selle ka ühes variantidest:
- väärtuste asendamisega päringus
otse oma andmebaasis täitmiseks ja edasiseks profiilimiseksSELECT 'const', 'param'::text; - väärtuste asendamisega läbi PREPARE/EXECUTE
ajendaja töö emuleerimiseks, kui parameetriline osa võib olla tähelepanuta jäetud — näiteks partitsioneeritud tabelite töötamiselDEALLOCATE ALL; PREPARE q(text) AS SELECT 'const', $1::text; EXECUTE q('param'::text);
Plaanide arhiiv
Sisestage, analüüsige, jagage kolleegidega! Plaanid jäävad arhiivi ja saate hiljem nende juurde tagasi pöörduda:
Aga kui te ei soovi, et teie plaani teised näeksid, ärge unustage märkida välja „ärge avaldage arhiivis”.
Järgmistes artiklites räägin keerukustest ja lahendustest, mis tekivad plaani analüüsimisel.
Allikas: habr.com
