


Toodet, mis on arenenud üle kümne aasta, pole üldse üllatav kohata aegunud tehnoloogiaid. Ent mis juhtub, kui kuue kuu pärast peate taluma kümme korda suuremat koormust ja väljaminekud kukuvad sadadel kordadel? Sellisel juhul on teil vajalik kõrge koormuse insener. Kuid kuna ei olnud sellist spetsialisti, usaldati probleem minu kätte. Artikli esimeses osas räägin, kuidas me üleminek Rediselt Redis-klastrile teostasime, ja teises osas jagan näpunäiteid, kuidas klastrit kasutada ja millele tähelepanu pöörata töös.
Tehnoloogia valik
Kas eraldi Redis on nii halb? Kas eraldi Redis (standalone redis) konfiguratsioonis 1 meister ja N orja jaoks? Miks ma pean seda aegunud tehnoloogiaks? (standalone redis) konfiguratsioonis 1 master ja N slave'i? Miks ma nimetan seda vananenud tehnoloogiaks?
Ei, Redis ei ole nii halb... Siiski on teatud puudusi, mida ei tohi ignoreerida.
Esiteks, Redis ei toeta meistrite ebaõnnestumise ajal taastumise mehhanisme. Selle probleemi lahendamiseks kasutasime konfigureerimist, mis automaatselt suunab VIP-e uuele meistrile, muutes ühe orja rolli ja lülitades ülejäänud sisse. See mehhanism töötas, kuid seda ei saanud pidada usaldusväärseks lahenduseks. Esiteks, toimusid valehädasid ja teiseks, see oli ühekordne ning sellele järgnesid käsitsi teostatavad toimingud.
Teiseks, ainult ühe meistri olemasolu tõi kaasa šardinguprobleemi. Oli vajalik luua mitu sõltumatut klastrit "1 meister ja N orja", seejärel jagada andmebaasid nende masinate vahel käsitsi ja loota, et hommikuks ei paisu ükski andmebaas nii, et see tuleb viia eraldi instantsi.
Millised on valikud?
- Kõige kallim ja rikkam lahendus on Redis-Enterprise. See on karbilahendus täie tehnilise toetusega. Kuigi see näeb tehniliselt ideaalne välja, ei sobinud see meile ideoloogilistel põhjustel.
- Redis-cluster. Tugineb oli toeks hädaolukordade ülemineku ja jagamise toetamine. Liides ei erine praktiliselt tavalisest versioonist. See näeb paljutõotav välja, aga räägime hiljem keerukustest.
- Tarantool, Memcache, Aerospike ja teised. Kõik need tööriistad teevad enamasti sama. Kuid igalühel on oma puudused. Otsustasime mitte kõik munad ühte korvi panna. Memcache ja Tarantool on meil muude ülesannete jaoks, ja, et ette öelda, on meie kogemuse järgi nendega olnud rohkem probleeme.
Kasutamisomadused
Vaadakem, milliseid ülesandeid oleme ajalooliselt Redis’iga lahendanud ja millist funktsionaalsust kasutanud:
- Cache enne päringuid kaugteenustele nagu 2GIS | Golang
GET SET MGET MSET "SELECT DB"
- Cache enne MYSQL | PHP
GET SET MGET MSET SCAN "KEY BY PATTERN" "SELECT DB"
- Peamine salvestuskoht seansside haldamiseks ja juhtide koordinaatide jaoks | Golang
GET SET MGET MSET "SELECT DB" "ADD GEO KEY" "GET GEO KEY" SCAN
Nagu näha, pole siin mingit kõrgemat matemaatikat. Kus siis seisneb keerukus? Vaatame iga meetodi eraldi.
Meetod
Kirjeldus
Redis-clusteri eripärad
Lahendus
GET SET
Kirjutada/ette lugeda võti
MGET MSET
Kirjutada/ette lugeda mitu võtit
Võtmed asuvad erinevates sõlmedes. Valmis raamatukogud oskavad teha Multi-operatsioone ainult ühe sõlme piires.
Asenda MGET N GET operatsioonide pipeline'iga.
VALI DB
Vali andmebaas, millega töötame.
Ei toeta mitut andmebaasi.
Koguda kõik ühte andmebaasi. Lisada võtmetele prefikseid.
SCAN
Käia läbi kõik võtmed andmebaasis.
Kuna meil on üks andmebaas, on kõigi võtmete mööda käimine klastris liiga kulukas.
Hoidke invariant ühes võtmes ja tehke HSCAN selle võtme järgi. Või loobuge sellest täielikult.
GEO
Operatsioonid geovõtmega.
Geovõti ei jagune.
KEY BY PATTERN
Otsige võtit mustri järgi.
Kuna meil on üks andmebaas, otsime kõigi võtmete kaudu klastris. Liiga kulukas.
Loobuda või hoida invariant, nagu SCAN-i puhul.
Redis vs Redis-cluster
Mida me kaotame ja mida me saame klastrisse üleminekul?
- Puudused: kaotame mitme andmebaasi funktsionaalsuse.
- Kui soovime salvestada ühte klastrisse loogiliselt mitte seotud andmeid, peame tegema tülikad lahendused prefiksite näol.
- Kaotame kõik „andmebaasi“ operatsioonid, nagu SCAN, DBSIZE, CLEAR DB jne.
- Mitme operatsiooni teostamine on oluliselt keerulisem, kuna võib osutuda vajalikuks pöörduda mitme sõlmese poole.
- Eelised:
- Vigu kannatavad süsteemid, mis pakuvad varu juhtimist.
- Shardimine Redis'i külgedel.
- Andmete edastamine sõlmede vahel, atomaarne ja katkestuseta.
- Võimsuse ja koormuse lisamine ja ümberjaotamine katkestuseta.
Jõuaksin järeldusele, et kui teil ei ole vaja kõrget varu tagamise taset, ei ole klastrisse üleminek selle väärt. See võib osutuda keeruliseks ülesandeks. Kuid kui valida eriversiooni ja klastriversiooni vahel, tasub valida klaster, kuna see ei jää mingisuguses osas alla ja vähendab teie muret.
Üleminekuks valmistumine
Alustame üleminekuks vajalike nõudmistega:
- See peab olema sujuv. Täielik teenuse seiskamine 5 minutiks ei sobi.
- See peab olema võimalikult ohutu ja järkjärguline. Soovime omada mingit kontrolli olukorra üle. Me ei soovi kõike korraga kokku panna ja lootma jääda tagasivõtmise nupule.
- Minimaalsed andmekadud üleviimise korral. Me mõistame, et atomaarne üleminek on väga keeruline, seetõttu lubame teatud desünkroniseerimist tavaliselt ja klasterdatud Redis'i andmete vahel.
Klastri hooldus
Enne üleminekut tuleks mõelda, kas me suudame klassit toetada:
- Graafikud. Kasutame täitmiseks Prometheust ja Grafanat, et jälgida protsessorite koormust, mäluhulka, klientide arvu, GET, SET, AUTH ja muude operatsioonide arvu.
- Ekspertiis. Kujutage ette, et homme on teie vastutada suur klaster. Kui see rikki läheb, ei saa keegi, välja arvatud teie, seda parandada. Kui see hakkab pidurduma — jooksevad kõik teie poole. Kui on vaja lisada ressursse või koormust ümber jaotada — taas teie poole. Et vältida halli juuste saamist 25-aastasena, on soovitatav arvestada nende olukordadega ja eelnevalt kontrollida, kuidas tehnoloogia erinevates olukordades käitub. Räägime sellest lähemalt jaotises „Ekspertiis“.
- Monitooringud ja teavitamine. Kui klaster rikki läheb, tahad sellest esimesena teada saada. Siin oleme piirdunud teavitamisega, et kõik sõlmed edastavad sama teavet klooni oleku kohta (jah, juhtub ka teisiti). Teisi probleeme on kiiremini märgata Redis'i klientide teenuste teavituste kaudu.
Kolimine
Kuidas me kolime:
- Esiteks tuleb ette valmistada raamatukogu klooniga töötamiseks. Gо versiooni aluseks võtsime go-redis'i ja muutsime seda veidi vastavalt enda vajadustele. Realiseerisime Multi-meetodid läbi pipeline'ide ning muutisime ka päringute kordamise reegleid. PHP versiooniga tekkis rohkem probleeme, kuid lõpuks otsustasime php-redis'i kasuks. Hiljuti on nad kasutusele võtnud klastritoe ning meie arvates näeb see hea välja.
- Seejärel tuleb klaster enda üles seada. See toimub sõna otseses mõttes kahe käsuga, lähtudes konfiguratsioonifailist. Räägime seadistamisest lähemalt allpool.
- Aeglase ülemineku jaoks kasutame dry-režiimi. Kuna meil on kaks versiooni teegist, millel on sama liides (üks tavaversioon ja teine klastriversioon), pole midagi keerulist teha mähist, mis töötaks eraldi versiooniga ja samal ajal dubleeriks kõik päringud klastrisse, võrdleks vastuseid ja kirjutaks lahknevused logidesse (meie puhul NewRelic). Nii et isegi kui klastriversioon rikke tõttu avalikustamise ajal puruneb, ei mõjuta see meie tootmist.
- Klastri dry-režiimis väljatoomisega saame rahulikult jälgida vastuste lahknevuste graafikut. Kui vigade osakaal aeglaselt, kuid kindlalt liigub mõne väikese konstantse suunas, siis on kõik hästi. Miks lahknevused ikkagi tekivad? Sest eraldi versioonis toimumine toimub veidi varem kui klastris, ja tänu mikroviivitusele võivad andmed lahkuda. Jäänud on vaid vaadata lahknevuste logisid, ja kui kõik need on seletatavad mitteaatomaarsete kirjutamiste kaudu, siis saab edasi liikuda.
- Nüüd saab dry-mode'i vahetada tagasi. Kirjutame ja loeme klastrist, ning dubleerime eraldi versioonis. Miks? Järgmise nädala jooksul tahame klastrit jälgida. Kui peaks selguma, et koormuse tipul on probleeme või oleme midagi tähelepanuta jätnud, on meil alati võimalus erakorraliseks tagasitulekuks vanale koodile ja värsketele andmetele dry-mode'i kaudu.
- On jäänud dry-mode välja lülitada ja eraldi versioon lahti võtta.
Ekspertülevaade
Alustame lühidalt klastrisseadme kirjeldusest.
Esiteks on Redis key-value salvestus. Võtmetena kasutatakse suvalisi stringe. Väärtusteks võivad olla numbrid, stringid ja terviklikud struktuurid. Viimaseid on palju, kuid üldise ülesehituse mõistmiseks ei ole see oluline.
Järgmine tasand abstraktsiooni võtmete järel on slotid (SLOTS). Iga võti kuulub ühte 16 383 slotist. Iga sloti sees võib olla lõpmatult võtmeid. Seega jagunevad kõik võtmed 16 383 kattumatu hulga vahel.
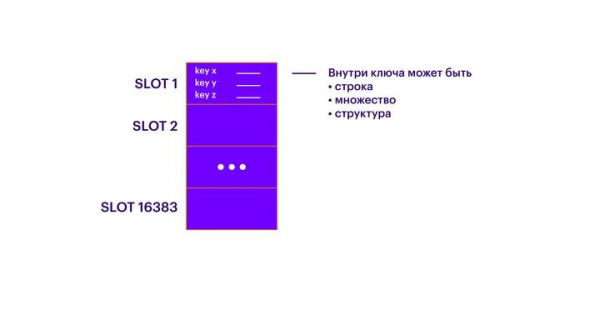
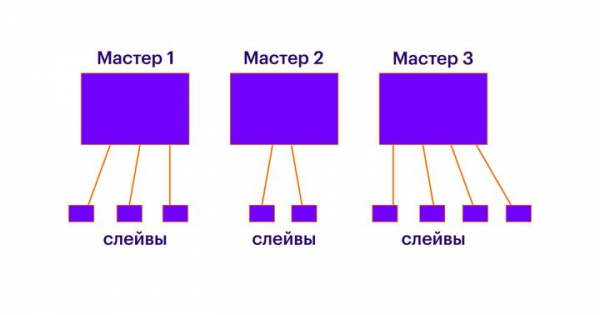
Seejärel peab klastris olema N master-sõlme. Iga sõlm on nagu eraldi Redis-juhtum, mis teab kõike teistest sõlmedest klastris. Iga master-sõlm sisaldab teatud arvu sadamaid. Iga sadam kuulub ainult ühele master-sõlmele. Kõiki sadamaid tuleb jaotada sõlmede vahel. Kui mõni sadam jääb jaotamata, siis pole nende sisu kätte saadav. Iga master-sõlme on mõistlik käivitada eraldi loogilisel või füüsilisel masinal. Samuti tuleb meeles pidada, et iga sõlm töötab ainult ühel tuumal ja kui soovite käivitada mitu Redis-juhtumit ühel loogilisel masinal, veenduge, et need töötaksid erinevatel tuumadel (me ei ole seda proovinud, kuid teoorias peaks kõik toimima). Fondamendis tagavad master-sõlmed tavalise šardimise ning suurem master-sõlmede arv võimaldab skaleerida kirjutamis- ja lugemispäringuid.
Kui kõik võtmed on jaotatud slotide vahel ja slotid on jaotatud peanoodide vahel, saab igale peanoodile lisada suvalise arvu orjanoodid. Igas sellises „meistri-orja“ ühenduses töötab tavapärane replikatsioon. Orjad on vajalikud lugemislehtede taotluste skaleerimiseks ja hädaolukordades peanoodi rikke korral.
Nüüd räägime toimingutest, mida oleks hea osata teha.
Me pöördume süsteemi poole Redis-CLI kaudu. Kuna Redis'il ei ole ühte sisenemispunkti, saab järgmisi toiminguid sooritada ükskõik millisel noodil. Igas punktis toon eraldi välja võimaluse sooritada toiming koormuse all.
- Esimene ja kõige olulisem, mida vajame: toiming cluster nodes. See tagastab klastrite oleku, näitab loetelu nootidest, nende rolle, slotide jaotust jne. Täiendavat teavet saab cluster info ja cluster slots abil.
- Oluline on osata sõlme lisada ja eemaldada. Selleks on operatsioonid cluster meet ja cluster forget. Pange tähele, et cluster forget tuleb rakendada IGAS sõlmes, nii master-sõlmedes kui ka replikates. Cluster meet tuleb kutsuda välja vaid ühes sõlmes. See erinevus võib olla häiriv, seega on parem sellest enne klasteri kasutusele võtmist teada saada. Sõlme lisamine toimub ohutult ja ei mõjuta klasteri tööd (mis on mõistetav). Kui kavatsete eemaldada sõlme klastrist, peate veenduma, et seal ei ole enam slote (vastasel juhul riskite kaotada ligipääsu kõigile võtmetele sellele sõlmele). Samuti ärge eemaldage masterit, kellel on släbivad sõlmed, muidu käivitub ebavajalik hääletus uue masteri valimiseks. Kui sõlmedes ei ole enam slote, siis see on väike probleem, kuid miks peaksime valima lisaks, kui saame kõigepealt eemaldada släbivad sõlmed.
- Kui peate sundima master'i ja slave'i vahetama, sobib käsk cluster failover. Seda käivitades tuleb arvestada, et operatsiooni ajal on master kättesaamatu. Tavaline vahetus toimub vähem kui sekundiga, kuid see ei ole aatomaarne. Võite eeldada, et osa päringutest masterile sellel ajal ebaõnnestub.
- Enne sõlme eemaldamist klastrist ei tohi seal olla ühtegi sloti. Parim on nende üleandmine käsklusega cluster reshard. Slotid kantakse ühe meistri juurest teise. Kogu operatsioon võib võtta mitu minutit, sõltuvalt edastatavate andmete mahust, kuid ülekanne on ohutu ja ei mõjuta klastrite töö. Nii on kõik andmed võimalik ühelt sõlmelt teisele üle kanda ka koormuse all, kartmata nende kättesaadavust. Siiski on mõned nüansid. Esiteks on andmete edastamine seotud teatud koormusega nii saatja- kui ka vastuvõtva sõlme jaoks. Kui vastuvõttev sõlm on juba protsessori poolest tugevalt koormatud, siis ei tasu seda veel uute andmete vastuvõtmisega üle koormata. Teiseks, niipea kui saatva meistri stint jääb tühjaks, lähevad kõik tema släivid kohe meesterile, kuhu need slotid on kantud. Probleem on selles, et kõik need släivid tahavad korraga andmeid sünkroniseerida. Ja teil on vedanud, kui see on osaline, mitte täielik sünkroniseerimine. Arvestage sellega ja kombineerige slotide edastamise ja slave'ide väljajätmise/ülekanne operatsioone. Või lootke, et teil on piisavalt paindlikkust.
- Mida teha, kui märkate, et transportimise käigus on mõni slot kaduma läinud? Loodan, et selle probleemiga te ei puutu, kuid igaks juhuks on olemas operatsioon cluster fix. See jaotab slotid node'ide vahel juhuslikus järjekorras. Soovitan kontrollida selle toimimist, eemaldades eelnevalt klastrist node, kus slotid on jagatud. Kuna jagamata slotid ei ole nagunii kergesti kättesaadavad, on hilja muretseda nende kättesaadavuse probleemide pärast. Omakorda ei mõjuta see jagatud slote.
- Veel üks kasulik operatsioon on monitor. See võimaldab reaalajas näha kogu nimekirja päringutest, mis suunatakse node'ile. Veelgi enam, selle abil saab kasutada grep'i, et teada saada, kas vajalik liiklus on kohal.
Samuti on oluline mainida meistrinoodi hädaolukorra vahetamise protseduuri. Lühiülevaates, see on olemas ja minu arvates töötab see suurepäraselt. Kuid ärge arvestage, et kui tõmbate juhi pistikust välja, vahetab Redis kohe ning kliendid ei märka katkestust. Minu praktikas toimub vahetamine mitme sekundi jooksul. Selle aja jooksul on osa andmeid kättesaamatud: meistri kättesaamatuse tuvastamine, nodide hääletamine uue määramiseks, slave'id vahetuvad ja andmed sünkroonitakse. Parim viis enda veendumiseks, et süsteem töötab, on läbi viia kohalikud harjutused. Seadke klaster üles oma sülearvutis, andke sellele minimaalne koormus, simuleerige kokkuvarisemist (näiteks blokeerides pordid) ja hinnake vahetamise kiirus. Minu arvates, alles pärast paaripäevast katsetamist on võimalik kindel olla tehnoloogia toimimises. Või loodate, et tarkvara, mida kasutab pool internetist, töötab kindlasti.
Konfiguratsioon
Tihti on konfiguratsioon see, millega alustamiseks kõigepealt tegelema peab. Kui kõik töötab, ei taha enam konfiguratsiooniga ega selle seadistustega tegeleda. On vajalik, et ennast sundida tagasi seadete juurde naasma ja need hoolikalt üle vaatama. Minu mälestustes on olnud vähemalt kaks tõsist viga, mis tulenesid konfiguratsioonile tähelepanu mitte pööramisest. Pöörake erilist tähelepanu järgmistele punktidele:
- timeout 0
Aeg, mille jooksul suletakse mitteaktiivsed ühendused (sekundites). 0 — ei sulgeda.
Meie iga teek ei osanud õigesti ühendusi sulgeda. Selle seadistuse väljalülitamisega riskime, et jõuame kliendilimiidini. Teisest küljest, kui selline probleem esineb, siis kaotatud ühenduste automaatne katkestamine maskeerib selle ja me ei pruugi seda märgata. Samuti ei peaks seda seadistust lubama, kui kasutate püsivaid ühendusi. - Save x y & appendonly yes
RDB-snapshooti salvestamine.
RDB/AOF probleemidest räägime allpool üksikasjalikult. - stop-writes-on-bgsave-error no & slave-serve-stale-data yes
Kui see on sisse lülitatud, lõpetab master RDB-snapshoti rikke korral muudatuste vastuvõtmise. Kui masteriga ühendus katkevad, võib slave siiski vastata päringutele (jah). Või lõpetab see vastamise (ei).
Me ei ole rahul olukorraga, kus Redis muutub kõrvitsaks. - repl-ping-slave-period 5
Selle aja jooksul hakkame muretsema, et master on katkenud ja on aeg failover-protseduur läbi viia.
Peame käsitsi leidma tasakaalu valehäirete ja failover’i käivitamise vahel. Meie praktika kohaselt on see 5 sekundit. - repl-backlog-size 1024mb & epl-backlog-ttl 0
Just nii palju andmeid saame säilitada katkise repliika puhvrisse. Kui puhver lõppeb, siis peab täielikult sünkroonima.
Praktika näitab, et parem on seada suurem väärtus. Põhjuseid, miks repliik võib maha jääda, on küllaga. Kui see jääb maha, siis on tõenäoliselt teie masteril juba raskusi, ja täiendav sünkroonimine on viimane tilk. - maxclients 10000
Maksimaalne samaaegsete klientide arv.
Meie kogemuse põhjal on parem seada väärtus suuremaks. Redis suudab suurepäraselt hakkama saada 10 000 ühendusega. Lihtsalt veenduge, et süsteemis on piisavalt sokette. - maxmemory-policy volatile-ttl
Reegel, mille kohaselt kustutatakse võtmed, kui saadaval oleva mälu piirmäär on täidetud.
Siin on oluline mitte ainult reegel, vaid ka arusaam, kuidas see toimub. Redisit võib kiita selle eest, et see suudab piiratud mälu ulatuses tõhusalt töötada.
RDB ja AOF probleemid
Kuigi Redis hoiab kogu teabe mälus, on olemas ka andmete salvestamise mehhanism. Täpsemalt: kolm mehhanismi:
- RDB-snapshots — täielik koopia kõigist andmetest. Seatakse konfigureerimisega SAVE X Y ja seda loetakse kui "Salvesta kõigi andmete täiskope igal X sekundil, kui vähemalt Y võtme on muudetud".
- Append-only fail — tehingute loend nende täitmise järjekorras. Lisab uusi saabunud tehinguid faili iga X sekundi või iga Y tehingu järel.
- RDB ja AOF — kahe eelmise kombinatsioon.
Kõigil meetoditel on oma eelised ja puudused, ma ei hakka neid kõiki loetlema, vaid juhin tähelepanu ainult mulle tunduvatele vähem ilmsetele hetkedele.
Esiteks, RDB-snapshoti säilitamiseks on vajalik kutsuda FORK välja. Kui andmeid on palju, võib see kogu Redis'e mõne millisekundi kuni ühe sekundi jooksul riputada. Lisaks vajab süsteem sellise snapshoti jaoks mälu eraldamist, mis toob endaga kaasa vajaduse hoida loogilisel masinal kahekordne mälureserv: kui Redis'ele on eraldatud 8 GB, siis peaks virtuaalmasinal olema saadaval 16 GB.
Teiseks, osalise sünkroniseerimisega on probleeme. AOF-režiimis, kui slave'i uuesti ühendatakse, võib osalise sünkroniseerimise asemel toimuda täielik. Miks see nii juhtub, ei suutnud ma aru saada. Kuid sellest tasub siiski meeles pidada.
Need to consider whether we really need this data on disk, especially since it is already duplicated by the slaves. Data can only be lost if all slaves fail, which is a problem of 'fire in the data center' level. As a compromise, we could suggest saving data only on the slaves, but in this case, we need to ensure that these slaves never become masters during a disaster recovery (there's a priority setting for slaves in their configuration). We evaluate the necessity of saving data on disk on a case-by-case basis, and most often conclude 'no.'
Kokkuvõte
In conclusion, I hope I was able to provide a general understanding of how redis-cluster works for those who have never heard of it, and also pointed out some less obvious aspects for those who have been using it for a while.
Thank you for your time, and as usual, comments on the topic are welcome.
Allikas: habr.com
