

Andmesalvesti arendamine on aeganõudev ja tõsine ülesanne.
Palju sõltub projekti elus sellest, kui hästi on alguses välja mõeldud objekti mudel ja andmebaasi struktuur.
Üldiselt on aktsepteeritud lähenemine erinevad kombinatsioonid tähe-skeemidest ja kolmanda normaali vormist. Üldiselt kehtib põhimõte: algandmed — 3NF, vitriinid — täht. See lähenemine, mis on ajaga tõestatud ja toetatud paljude uuringutega, on esimene (mõnikord ka ainus), mis tuleb kogenud DWH spetsialisti mõtteisse, kui arutada, milline võiks välja näha analüüsihäälestus.
Teisest küljest, äri tervikuna ja kliendi nõudmised muutuvad kiiresti, samal ajal kui andmed kasvavad nii "sügavale" kui ka "laiusele". Siin tuleb esile tähe põhiline puudus — piiratud paindlikkus.
Ja kui teie rahulikus ja hubases DWH arendaja elus äkki:
- ilmnes vajalik "teha kiiresti midagi, seejärel vaatame";
- ilmnes kiiresti arenev projekt, kus uute allikate ühendamine ja äri mudeli ümberkujundamine toimub vähemalt kord nädalas;
- ilmnes klient, kes ei oska ette kujutada, milline peaks süsteem välja nägema ja milliseid funktsioone lõpuks täitma, aga on eksperimentideks valmis ja soovib järk-järgult täpsustada soovitud tulemust, liikudes järk-järgult selle suunas;
- projektijuhi rõõmsate uudistega: “Nüüd on meil agiilne lähenemine!”
Või kui teid lihtsalt huvitab, kuidas veel andmehoidlaid üles ehitada — tulge edasi!
Mida tähendab «paindlikkus»
Esiteks lepime kokku, milliseid omadusi peab süsteem omama, et seda saaks nimetada “paindlikuks”.
Tasub märkida, et kirjeldatud omadused peavad kuuluma just süsteemile, mitte arendamise protsessile. Seega, kui soovisite lugeda Agile'ist kui arendusteemast, on parem tutvuda teiste artiklitega. Näiteks, siin samas, Habras, on palju huvitavaid materjale (nii ja , kui ka ).
See ei tähenda, et arendusprotsess ja andmehoidla struktuur ei oleks omavahel seotud. Üldiselt peaks Agile põhimõtete kohaselt paindliku arhitektuuriga andmehoidla loomine olema märgatavalt lihtsam. Siiski on praktikas sagedasemad variandid, kus Agile'i klassikalise DWH-i arendusega Kimballi või DataVaulti meetodites koostatakse pigem veesoola kui õnnelikke kokkusattumusi selle kahe variandi seas ühisel projektil.
Nii et millised on paindliku andmehoidla omadused? Siin saab välja tuua kolm punkti:
- Varajane tarnimine ja kiire täiendamine — see tähendab, et ideaalis peaks esimene ärikastus (näiteks esimesed toimivad aruanded) olema saadud nii kiiresti kui võimalik, st veel enne, kui kogu süsteem on täielikult projekteeritud ja ellu viidud. Samuti peaks iga järgmine täiendamine võtma võimalikult vähe aega.
- Iteratiivne täiendamine — see tähendab, et iga järgmine täiendus ei tohiks ideaaljuhul mõjutada juba töötavat funktsionaalsust. Just see punkt saab sageli olema suurim õudusunenägu suurtes projektides — tarde või hiljem hakkavad eraldi objektid omandama nii palju seoseid, et on lihtsam täielikult kopeerida loogikat kõrvale, kui lisada väli olemasolevasse tabelisse. Ja kui teid üllatab, et täiendusanalüüsi aeg, mis on olemasolevatele objektidele mõjude määramisel, võib võtta rohkem aega kui teie ise täiendus — siis te tõenäoliselt ei ole veel töötanud suurtes andmehaiglas pankade või telekommunikatsiooni sektoris.
- Pidev kohandumine muutuva äri vajadustega — üldine objekti struktuur peaks olema projekteeritud mitte lihtsalt võimaliku laiendamise arvestamiseks, vaid arvestama, et selle järgmise laiendamise suund ei oleks teile isegi kujuteldav projekteerimise etapis.
Ja jah, nendele kõigile nõuetele vastamine ühes süsteemis on võimalik (loomulikult teatavate juhtumite ja mõningate ettevaatlike märkustega).
Allpool käsitlen kahte populaarseimat tellimisprotsessi metoodikat — Anchor model ja Data Vault. Kaalust jäävad sellised kaunid lähenemised nagu näiteks EAV, 6NF (puhtal kujul) ja kõik, mis on seotud NoSQL lahendustega — mitte sellepärast, et need oleks halvemad, ega ka seetõttu, et see artikkel oleks siis ähvardanud omada keskmise väitekirja mahtu. Lihtsalt kõik see kuulub veidi teistsuguste lahenduste klassi — kas lähenemistele, mida võite rakendada spetsiifilistes olukordades, sõltumata teie projekti üldisest arhitektuurist (nagu EAV), või globaalselt erinevatele teabele salvestamise paradigmadele (nagu näiteks graafandmebaasid ja muud NoSQL variandid).
Klassikalise lähenemise probleemid ja nende lahendused paindlikes metodologia
Klassikalise lähenemise all mõistan vana head tähte (sõltumata spetsiifilisest rakendamisest aluseks olevates kihtides, andku Kimballi, Inmanni ja CDM austajad mulle andeks).
1. Rangelt suhted kardinaalsus
Selle mudeli peamiseks aluseks on andmete selge jaotus mõõtmed (Dimension) ja faktid (Fact). Ja see on, kurat võtaks, loogiline — kuna andmeanalüüs enamikul juhtudel keskendub just teatud numbriliste näitajate (faktide) analüüsile teatud lõikes (mõõtmetes).
Samas seosed objektide vahel luuakse seostena tabelite vahel välisvõtme kaudu. See näeb välja täiesti loogiline, kuid viib kohe esimese paindlikkuse piiranguni — rangelt määratletud seoste kardinaalsus..
See tähendab, et tabelite projekteerimise etapis peate täpselt määratlema, kas iga kahe omavahel seotud objekti vahel võivad nad olla paljude-kaupa paljude või ainult 1-kaupa paljude, ja "millises suunas". Sellest sõltub otseselt, millises tabelis on peamine võti ja millises — välisvõti. Selle suhte muutmine uute nõudmiste saamisel toob tõenäoliselt kaasa andmebaasi ümbertöötluse.
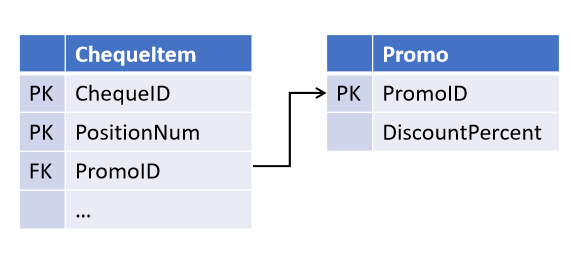
Näiteks projekteerides objekti "kassaarve", tuginedes müügiosakonna vandetõotustele, olete loonud võimaluse ühe soodustuse kehtimist mitme arve positsiooni suhtes (kuid mitte vastupidi):
Ja mõne aja pärast tutvustasid kolleegid uut turundusstrateegiat, kus sama positsiooni jaoks võivad kehtida mitmed kampaaniad samal ajal. Ja nüüd peate täiendama tabeleid, tuues seose välja eraldi objekti.
(Kõik tuletatud objektid, kus toimub kampaaniate ühendumine, vajavad nüüd samuti täiendamist).
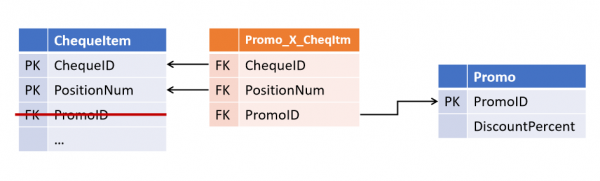
Seosed Data Vault'is ja Anchor Model'is
Sellise olukorra vältimine osutus üsna lihtsaks: ei tohi müügiosakonnale uskuda, selleks piisab, et kõik seosed hoiustatakse alguses eraldi tabelites ja töödeldakse nagu paljusid-mitmeid.
Selline lähenemine pakuti välja Dan Linstedt'i poolt osana paradigmast Data Vault ja täielikult toetatud Lars Rönnbäck'i poolt ühes Ankurmudel (Anchor Model).
Lõppkokkuvõttes saame esimese eristava tunnuse paindlikest metoodikatest:
Objektide vahelisi seoseid ei hoita vanemate entiteetide atribuutides, vaid need kujutavad endast eraldi objektitüüpi.
V Data Vault selliseid seostetabeleid nimetatakse Link, ja seejärel määratleme selle, takistades seeläbi kasutajal selgelt selle väljaid muuta. See on üks andmete peitmise mustritest Ankurmudelis — Tie. Esmapärane, kuigi nende nimed ei ole ainus erinevus (mille üle arutame allpool). Mõlemas arhitektuuris võivad sidetabelid siduda igal ajal hulga entiteete (mitte tingimata 2).
See esmapilgul näiv ülemäärasus pakub olulist paindlikkust edasiste kohanduste tegemisel. Selline struktuur muutub tolerantseks mitte ainult olemasolevate seoste kardinaalsuse muutustele, vaid ka uute lisamisele — kui tšekipositsioonile lisandub viide selle registrile, siis sellise sideme loomine on lihtsalt olemasolevate tabelite pealsetuseks ilma, et see mõjutaks olemuslikult olemasolevaid objekte ja protsesse.
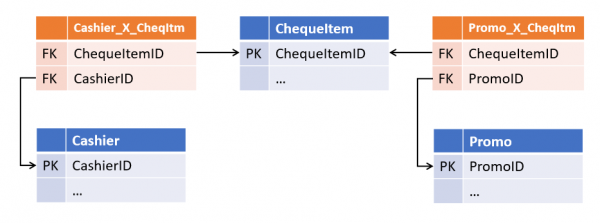
2. Andmete dubleerimine
Teine probleem, mida paindlikud arhitektuurid lahendavad, on vähem ilmselge ja omane eelkõige SCD2 tüüpi mõõtmistele (aeglased muutuvad mõõtmised teise tüübi), kuigi mitte ainult neile.
Klassikalises andmehoidlas on mõõde tavaliselt tabel, mis sisaldab asendusvõtit (PK-na) ning ka ärivõtmeid ja atribuute eraldi veergudes.

Kui mõõt võimaldab versioonimist, lisatakse standardse väljade kogumisse versiooni kehtivuse ajapiirangud, ja ühes allikas ilmub mitu versiooni salvestusse (iga versiooni atribuutide muudatuse kohta üks).
Kui mõõdul on vähemalt üks tihti muudetav versiooni atribuut, on selle mõõdu versioonide arv märkimisväärne (isegi kui ülejäänud atribuudid ei ole versioonilised või ei muutu kunagi), ja kui neid atribuute on mitu, võib versioonide arv kasvada geomeetrilises progressioonis nende arvu järgi. Selline mõõt võib võtta märkimisväärse ketta ruumi, kuigi suur osa selles salvestatud andmetest on lihtsalt teiste ridade muutumatute atribuutide väärtuste dubleerimised.
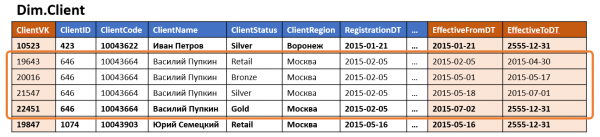
Selle puhul kasutatakse väga tihti ka denormaliseerimist — osa atribuute hoitakse teadlikult väärtusena, mitte viitena registrile või muule mõõdule. See lähenemine kiirendab andmetele juurdepääsu, vähendades mõõdu juurde juurdepääsul jõudes tehtavate join'ide arvu.
Üldiselt viib see selleni, et Sama teave salvestatakse korraga mitmes kohas.Näiteks võib elukoha ja kliendikategooria kuuluvuse kohta käiv teave korraga olla salvestatud mõõtmistes 'Klient' ning faktides 'Ost', 'Kohaletoimetamine' ja 'Klienditeenindusega kontakt', samuti tabelis 'Klient — Kliendihaldur'.
Üldiselt kehtib eespool toodud ka tavaliste (mitte-versiooniliste) mõõtmiste kohta, kuid versioonilistel võib olla teine mastaap: uue objekti versiooni ilmumine (eriti tagantjärele) ei too kaasa lihtsalt kõigi seotud tabelite värskendamist, vaid uute versioonide kaskaadi väljanägemise seotud objektide puhul — kui Tabel 1 kasutatakse Tabel 2 koostamisel ja Tabel 2 Tabel 3 koostamisel jne. Isegi kui ühtegi Tabeli 1 atribuuti ei osaldu Tabeli 3 koostamisel (ja osalduvad teised Tabeli 2 atribuute, mis on saadud muudest allikatest), toob selle konstruktsiooni versioonivärskendus vähemalt kaasa lisakulud ja maksimaalselt — täiendavad versioonid Tabelis 3, mis siin 'ei puutu asjasse', ning sealt edasi ahelas.
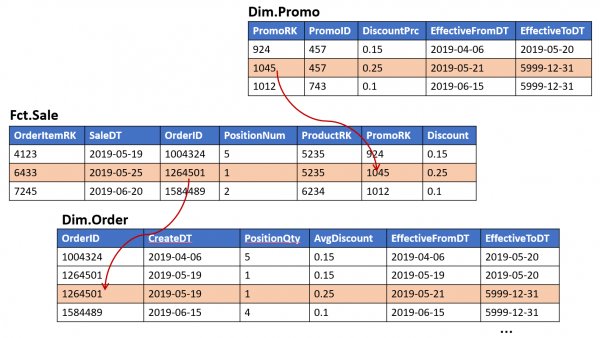
3. Mitte-lineaarne keerukus täiustamisel
Iga uus vitriin, mis luuakse teise põhjal, suurendab kohti, kus andmed võivad ETL-i muudatuste tegemisel "lahkuda". See toob endaga kaasa iga järgmise täiustuse keerukuse (ja kestuse) suurenemise.
Kui eeltoodud kehtib süsteemide kohta, mille ETL-protsessid harva muutuvad, siis sellises paradigma elamine on võimalik — piisab, kui jälgida, et uued täiustused kantaks korrektselt kõikidesse seotud objektidesse. Kui aga täiustused toimuvad tihti, tõuseb tõenäosus, et mõned seosed jäetakse kogemata vahele.
Kuna "versiooniline" ETL on oluliselt keerukam kui "mitteversiooniline", siis on keeruline vältida vigu, kui kogu seda süsteemi sageli täiustatakse.
Objektide ja atribuutide hoidmine Data Vaultis ja Anchor mudelis
Paigutus, mida paindlike arhitektuuride autorid pakuvad, võiks formuleerida järgmiselt:
On vajalik eristada, mis muutub ja mis jääb muutumatuks. Seega, hoida võtmed eraldi atribuutidest.
Siiski ei tohiks segi ajada mitteversiooniline atribuut koos muutumatuga: esimene ei hoia oma muudatusi ajalugu, kuid võib muutuda (näiteks sisestamisvea parandamise või uute andmete saamise korral) teine — ei muutu kunagi.
Arvamused selle kohta, mida täpselt võib Data Vaultis ja Anchor mudelis pidada muutumatuks, erinevad.
Arhitektuuri vaatenurgast Data Vault, muutumatuks võib pidada kõiki võtmekomplekte — looduslikud (organisatsiooni KMKR, toote kood allikasüsteemis jne) ja asendavad. Samal ajal saab ülejäänud atribuute jagada rühmade kaupa allika ja / või muudatuste sageduse põhjal ja iga rühma jaoks tuleb pidada eraldi tabelit iseseisva versioonide komplekti jaoks.
Küll aga Anchor Model peetakse muutumatuks ainult asendusvõtme üksuse. Kõik muu (sealhulgas looduslikud võtmed) — on lihtsalt tema atribuutide erijuht. Samuti kõik atribuudid on vaikimisi üksteisest sõltumatud, seega peab iga atribuut olema eraldi tabelid.
V Data Vault tabelid, mis sisaldavad üksuste võti, nimetatakse Hubideks (Hub). Hubid sisaldavad alati fikseeritud väljade komplekti:
- Looduslikud võtmed üksuse
- Asendav võti
- Viide allikale
- Salvestamise aeg
Salvestused Hubides ei muutu kunagi ja ei oma versioone. Välimuselt sarnanevad hubid väga ID-kaardiga tabelitele, mida kasutatakse mõnedes süsteemides asendustena, kuid Data Vaultis soovitatakse asendustena kasutada mitte täisarvulist järjestust, vaid häält ettevõtte võtmete kogumist. See lähenemine lihtsustab suhete ja atribuutide laadimist allikatest (ei ole vaja hubiga liituda asenduse saamiseks, piisab lihtsalt ettevõtte võtme hääle arvutamisest), kuid võib põhjustada muid probleeme (seotud näiteks kollisioonide, suurustundlikkuse ja trükkimata sümbolitega stringivõtmetes jne), mistõttu see ei ole üldiselt aktsepteeritud.
Kõik muud atribuudid salvestatakse spetsiaalsetes tabelites, mida nimetatakse satelliitideks (Satellite). Ühel hubil võib olla mitu satelliiti, mis salvestavad erinevaid atribuutide kogumeid.
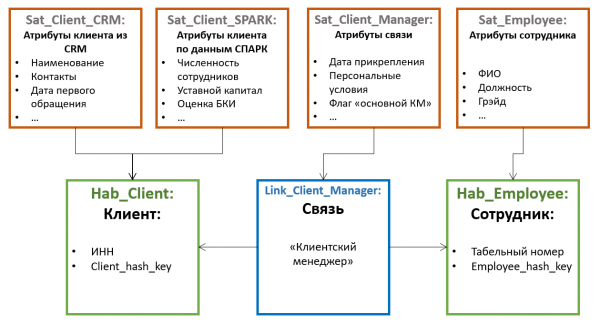
Atribuutide jaotamine satelliitide vahel toimub koosmuutmise printsiibi järgi — ühes satelliidis võivad olla salvestamata atribuudid (näiteks sünnikuupäev ja isikukood füüsilise isiku jaoks), teises — harva muudetavad versioonilised atribuudid (näiteks perekonnanimi ja passi number), kolmandas — sageli muudetavad (näiteks kohaletoimetamise aadress, kategooria, viimane tellimise kuupäev jne). Versioonide haldamine toimub üksikute satelliitide tasandil, mitte tervikobjekti ulatuses, seetõttu on otstarbekas jaotada atribuudid nii, et ühe satelliidi siseversioonide ühisosa oleks minimaalne (mida vähem muudab salvestatavate versioonide kogus).
Samuti, andmete laadimisprotsessi optimeerimiseks, viidatakse sageli eraldi satelliitidesse atribuudid, mis saadakse erinevatest allikatest.
Satelliidid on ühendatud Hubiga välise võtme kaudu (mis vastab 1-ühele mitmele koodile). See tähendab, et atribuutide mitmed väärtused (näiteks mitu telefoninumbrit ühe kliendi kohta) toetab selline arhitektuur „vaikimisi“.
V Ankurmudel (Anchor Model) tabelid, mis salvestavad võtmeid, nimetatakse Ankuriteks (Anchor). Nad salvestavad:
- Ainult surrogaatvõtmed
- Viide allikale
- Salvestamise aeg
Looduslikke võtmeid Ankur Mudeli kontekstis peetakse tavapärasteks atribuutideks. See variant võib tunduda keerulisem mõista, kuid see annab palju rohkem ruumi objekti tuvastamiseks.
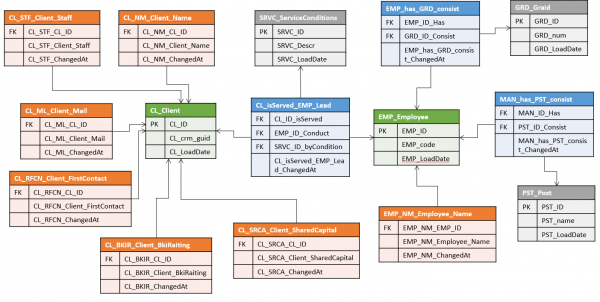
Näiteks kui sama entiteedi kohta andmed pärinevad erinevatest süsteemidest, kus igas kasutatakse oma loodusteaduslikku võtit. Data Vaultis võib see viia väga kohmakate struktuurideni, kus on mitu sõlme (igaühele üks allikas + ühendav meistriversioon), Ankur mudelis aga iga allika loodusteaduslik võti läheb oma atribuudisse ja seda saab laadimisel kasutada sõltumatult teistest.
Aga siin peitub üks salakaval asi: kui üks entiteet ühendab atribuute erinevatest süsteemidest, siis tõenäoliselt eksisteerivad mõned “liimimise”reeglid,
V Data Vault mille järgi peab süsteem mõistma, et eri allikatest pärinevad kirjed vastavad ühele entiteedi eksemplarile. need reeglid tõenäoliselt määravad “asendusnõlva” meistertüübi loomise ja ei mõjuta Hube, mis salvestavad allika algsed võtmed ja omadused. Kui mingil hetkel andmepaigutuse reeglid muutuvad (või saabub atribuuttäiendamine, mille alusel see toimub), piisab, kui sissejuhatused ümber vormistada.
V Ankurmudel selline entiteet tõenäoliselt salvestatakse ainult ühte ankurdamisse. See tähendab, et kõik omadused, sõltumata sellest, kust nad on saadud, seotakse sama sissejuhatusega. Valeühendatud kirjeid eristada ja jälgida andmeluuna ajakohasust sellises süsteemis võib olla oluliselt keerulisem, eriti kui reeglid on piisavalt keerulised ja sageli muutuvad, ja sama omadus võib olla saadud erinevatest allikatest (kuigi see on täielikult võimalik, kuna iga versiooni omadus säilitab oma allika lingi).
Igal juhul, kui teie süsteemis on planeeritud funktsionaalsus kaksikväljade de-dupliceerimine, kirje ühinemine ja MDM-i teiste elementide funktsioonid, on oluline tutvuda looduslike võtmete salvestamise aspektidega paindlikes meetodites. Tõenäoliselt osutub mahukam Data Vault konstruktsioon ootamatult tõhusamaks, et vältida liitumisvigu.
Kinnitusmudel näeb ette ka täiendava objekti tüübi, mida nimetatakse Sõlmeks (Knot) mille olemuselt on see eriline degeneratsioonivorm ankru, mis võib sisaldada vaid ühte atribuuti. Sõlmi on ette nähtud kasutamiseks tasapinnaliste kataloogide salvestamiseks (nt sugu, peresuhe, klienditeeninduse kategooria jne). Erinevalt ankrist, Sõlm ei oma seotud atribuutide tabeleid, ja selle ainus atribuut (nimi) on alati salvestatud ühte tabelisse koos võtmega. Sõlmed seotakse ankrute vahelise seose tabelite kaudu (Tie) samamoodi nagu ankruid omavahel.
Sõlmede kasutamise osas puudub ühemõtteline arvamus. Näiteks, , kes edendab aktiivselt Kinnitusmudeli kasutamist Venemaal, usub (ilma alusetult), et mitte ühegi katalooge ei saa täpselt kinnitada, et see alati on staat staatiline ja ühe taseme, seega on kõigi objektide jaoks parem kohe kasutada täis funktsionaalset Ankur.
Veel üks oluline erinevus Data Vaulti ja Ankurmudeli vahel on olemasolu atribuutide seostes.:
V Data Vault Seosed on sama täisväärtuslikud objektid nagu Hublid ja võivad omada oma atribuute.. Dokumendihalduses Ankurmudel Seoseid kasutatakse ainult Ankurite ühendamiseks ja oma atribuute omada ei saa.. See erinevus toob oluliselt erinevad lähenemisviisid mudeldamiseks faktide kohta, millest räägitakse hiljem.
Faktide säilitamine
Varem rääkisime peamiselt mõõtmete modelleerimisest. Faktide suhtes on olukord natuke vähem ühemõtteline.
V Data Vault tüüpiline objekt faktide hoidmiseks on Seos (Link), mille Satellitides kogutakse materiaalsed näitajad.
Selline lähenemine tundub intuitiivselt mõistetav. See pakub lihtsat juurdepääsu analüüsitavatele näitajatele ja sarnaneb üldiselt traditsioonilise faktide tabeliga (ainult näitajad ei asu tabelis endas, vaid "naaber" tabelis). Kuid on ka varjatud ohte: üks tüüpiline mudeli täiendus — fakti võtme laiendamine — toob kaasa vajaduse uue välist võtme lisamiseks Linkile.. Ja see omakorda „murendab“ moodulsust ja võib potentsiaalselt tekitada vajaduse teiste objektide kohandamiseks.
V Ankurmudel Seos ei saa omada oma atribuute, seega selline lähenemine ei toimi — kõik atribuudid ja näitajad peavad olema seotud ühe konkreetse ankruga. Järeldus on lihtne — iga fakti jaoks on samuti vajalik oma ankru. Osa sellest, mida me oleme harjunud faktideks pidama, võib tunduda loomulik — näiteks ostufakt seondub objekti „tellimus“ või „kviitungiga“, veebisaidi külastamine — sessiooniga jne. Kuid on ka fakte, mille jaoks sellise loodusliku „kandjate objektiga“ seondumine ei ole nii lihtne — näiteks kaupade jääkide arv laos päeva alguses.
Seega ei esine ankrumudelis faktivõti laiendades moodulsuse probleeme (piisab lihtsalt uue seose lisamisest vastava ankruga), kuid mudeli projekteerimine faktide esitamiseks on vähem üheselt mõistetav, võivad tekkida „kunstlikud“ ankrud, mis ei peegelda ärimudelit selgelt.
Kuidas saavutatakse paindlikkus
Saadud struktuur sisaldab mõlemal juhul oluliselt rohkem tabeleid, kui traditsiooniline mõõtmine. Kuid see võib võtta oluliselt vähem kettaruumi sama versioonide atribuutide kogumi juures nagu traditsiooniline mõõtmine. Loomulikult ei ole siin mingit maagilist — kõik on normaliseerimises. Jaotades atribuute Satellitides (Data Vaultis) või eraldi tabelites (Anchor Model), vähendame (või välistame täielikult) ühtede ja sama atribuutide väärtuste dubleerimist teiste muutumisel.
Kuna Data Vault kasu sõltub atribuutide jaotumisest Satellitides, ja Ankurmudel — praktiliselt otseproportsionaalne keskmise versioonide arvu osakaalu mõõtmisel.
Siiski on ruumikasutuse kasu oluline, kuid mitte peamine eelis atribuutide eraldi salvestamisel. Koos suhete eraldi salvestamisega muudab see hoidla modulaarseks struktuuriks. See tähendab, et eraldi atribuutide ja tervete uute valdkondade lisamine sellesse mudelisse näeb välja nagu lisakiht olemasoleva objektide kogumi üle ilma neid muutmata. Ja see ongi see, mis muudab kirjeldatud metoodikad paindlikeks.
See on samuti nagu üleminek üksikutelt toodetelt masstootmisele — kui traditsioonilises lähenemises on iga mudeli tabel ainulaadne ja vajab eraldi tähelepanu, siis agiilses metoodikas on see juba komplekt tüüpilisi "detailide". Ühest küljest, tabelite arv suureneb, andmete laadimise ja valimise protsessid peavad nägema keerukamad välja. Teisest küljest — need muutuvad tüüpiliseks. Seega, need saavad olla automaatsetes ja hallatavad metaandmete kaudu. Küsimus “kuidas me paneme?” — millele vastamine võis võtta olulise osa projekteerimistööst, ei ole nüüd lihtsalt aktuaalne (nagu ka küsimus mudeli muutmise mõju kohta toimivatele protsessidele).
See ei tähenda, et analüütikud sellises süsteemis üldse ei ole vajalikud — keegi peab siiski töötama välja objektide kogumi koos atribuutidega ja aru saama, kust ja kuidas kõike seda laadida. Kuid töömaht ning ka vigade tõenäosus ja hind vähenevad oluliselt. Nii analüüsietapis kui ka ETL-i arendamisel, mis suures osas võib olla suunatud metaandmete redigeerimisele.
Tumeda külg
Kõik eespool kirjeldatud teeb mõlemad lähenemisviisid tõeliselt paindlikeks, tehnoloogilisteks ja sobivateks iteratiivseks arendamiseks. Loomulikult on olemas ka "tõrvaämber", millest te juba ilmselt aimate.
Andmete dekompositsioon, mis on paindlike arhitektuuride moodulsuse alus, toob kaasa tabelite arvu suurenemise ja vastavalt sellele, ülekande kulud ühenduste tegemisel otsingutes. Kõik mõõtme atribuudid hankimiseks piisab klassikalises andmehoidlas ühest valikust, kuid paindlik arhitektuur nõuab mitmeid ühendusi. Samas, kui raportite jaoks saab kõik need ühendused ette kirjutada, siis SQL-i käsitsi kirjutamisega harjunud analüütikud kannatavad kahekordselt.
On mitmeid fakte, mis hõlbustavad sellist olukorda:
Suurte mõõtmete korral ei kasutata harva kõiki selle atribuute samaaegselt. See tähendab, et ühendusi võib olla vähem, kui esmapilgul mudelit vaadates näib. Data Vaultis saab arvesse võtta ka eeldatavat jagamise sagedust, kui atribuudid jaotatakse satelliitide vahel. Samuti on Hübriidid või Ankrud vajalikud peamiselt surrogaatide genereerimiseks ja kaardistamiseks laadimisfaasis ning neid kasutatakse harva päringutes (eriti see kehtib Ankrute kohta).
Kõik ühendused — võtme kaudu. Lisaks vähendab andmete “kokkusurutud” viis salvestamise kulusid tabelite skaneerimise puhul seal, kus see on vajalik (näiteks atribuudiväärtuse järgi filtreerimise ajal). See võib viia selleni, et normaliseeritud andmebaas, kus on palju ühendusi, võib olla isegi kiirem kui ühe suure mõõtme skaneerimine, millel on palju versioone reas.
Näiteks, siin artiklis on üksikasjalik võrdlev test Ankrumudeli jõudlusest, kasutades ühte tabelit.
Palju sõltub mootorist. Paljudel kaasaegsetel platvormidel on sisemised mehhanismid join'ide optimeerimiseks. Näiteks oskavad MS SQL ja Oracle "vahel" välja jätta join'id tabelitele, kui nende andmeid ei kasutata kusagil mujal, välja arvatud teistes join'ides, ja need ei mõjuta lõppvalikut (table/join elimination), samas kui MPP Vertica on , tõestanud end suurepärase mootorina Ankur mudeli jaoks, arvestades teatavat käsitsi optimeerimist päringu plaanis. Teiselt poolt tundub Ankur mudeli hoidmine näiteks Click House'is, mis on joinide osas piiratud toetusega, hetkel mitte kõige parem idee.
Lisaks on mõlema arhitektuuri jaoks olemas spetsiaalsed tehnikad, mis lihtsustavad andmete juurde pääsemist (nii päringute sooritusvõime kui ka lõppkasutajate jaoks). Näiteks Point-In-Time tabelid Data Vault'is või spetsiaalsed tabelifunktsioonid Ankur mudelis.
Kokku
Käsitletud paindlike arhitektuuride peamine olemus seisneb nende „konstruktsiooni” moodulsuses.
Just see omadus võimaldab:
- Pärast teatud esialgset ettevalmistust, mis on seotud metaandmete juurutamise ja põhisiseste ETL algoritmide kirjutamisega, kiiresti esitada kliendile esimene tulemus. paaride raportite kujul, mis sisaldavad andmeid vaid mõne objekti allika kohta. Üksikasjaliku (isegi kõrgtaseme) objekti mudeli täielik läbimõtlemine pole sel eesmärgil vajalik.
- Andmemudel võib alustada töötamist (ja tooma kasu) vaid 2-3 objektiga ning seejärel aeglaselt laieneda (seoses humoristliku mudeliga, mida Nikolai kaunis võrdlus seenetüvesega).
- Enamik täiendusi, sealhulgas temaatika laiendamine ja uute allikate lisamine ei mõjuta olemasolevat funktsionaalsust ega tähenda ohtu olemasoleva töö katkestamiseks..
- Standardsed elemendid dekomponeerimise tõttu muudavad ETL-protsessid sellistes süsteemides ühtseks, nende kirjutamine on algoritmisele alluv ja lõpuks automaatimisele.
Sellise paindlikkuse hind on toime. See ei tähenda, et selliste mudelite puhul ei saa saavutada vastuvõetavat tulemuslikkust. Enamasti võib teil lihtsalt olla vaja rohkem pingutusi ja tähelepanu detailidele, et saavutada vajalikke mõõdikuid.
Rakendused
Entiteedi tüübid Data Vault
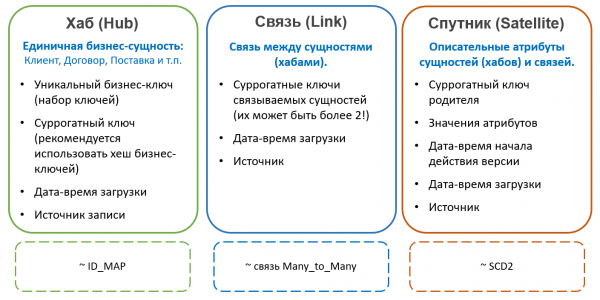
Rohkem teavet Data Vaulti kohta:
Entiteedi tüübid Anchor Model
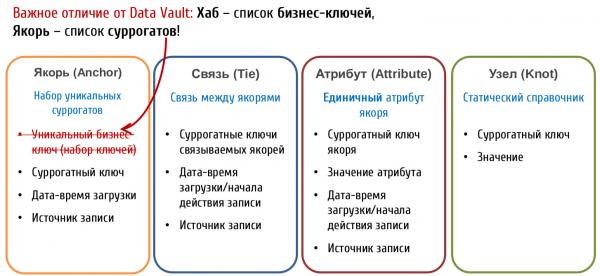
Lisainfo Anchor Modelist:
Kokkuvõtte tabel uuritud lähenemisviiside sarnasuste ja erinevuste kohta:

Allikas: habr.com
