

Märk. tõlge.: Selles artiklis jagab Banzai Cloud näidet, kuidas kasutada oma spetsiaalseid utiliite, et lihtsustada Kafka haldamist Kuberneteses. Esitatud juhised illustreerivad, kuidas leida optimaalse infrastruktuuri suuruse ja seadistada Kafka nõutava läbilaskevõime saavutamiseks.

Apache Kafka on jaotatud voogedastuse platvorm, mis võimaldab luua usaldusväärseid, skaleeritavaid ja kõrge jõudlusega reaalajas voogesitussüsteeme. Selle muljetavaldavaid võimalusi saab laiendada Kubernetesega. Selleks oleme välja töötanud ja tööriista nimega . Need võimaldavad käivitada Kafka Kuberneteses ja kasutada selle erinevaid funktsioone, nagu häälestamine, automaatne skaleerimine, põhivarade teadlikkus, "pehme" (graceful) uuenduste juurutamine jne.
Proovige Supertubes oma klastris:
curl https://getsupertubes.sh | sh ja supertubes install -a --no-democluster --kubeconfigVõi võtke ühendust . Samuti võib lugeda mõningatest Kafka võimalustest, mille töö on automatiseeritud Supertubes'i ja Kafka operaatori abil. Me oleme neist juba blogis kirjutanud:
- ;
- ;
- ;
- ;
- ;
- ;
- .
Kui otsustate käitada Kafka klastrit Kubernetes'es, seisate tõenäoliselt silmitsi küsimusega, kuidas määrata baas infrastruktuuri optimaalne suurus ja kohandada Kafka konfiguratsiooni vastavalt läbilaskevõime nõudmistele. Iga brokera maksimaalne jõudlus sõltub selle aluseks olevate infrastruktuuri komponentide, nagu mälu, protsessor, ketta kiirus, võrgu läbilaskevõime jne, jõudlusest.
Ideaalis peaks maakleri konfiguratsioon olema selline, et kõik infrastruktuuri elemendid töötavad oma maksimaalses võimekuses. Kuid reaalses elus on sellise seadistuse saavutamine üsna keeruline. Tõenäolisem on, et kasutajad seadistavad maakleri konfiguratsiooni nii, et maksimeerivad ühe või kahe komponendi (ketta, mälu või protsessori) kasutamist. Üldiselt näitab maakler maksimaalset jõudlust, kui tema konfiguratsioon võimaldab kõige aeglasemal komponendil töötada täielikult. Nii saame umbkaudse ettekujutuse koormusest, millega üks maakler toime tulla suudab.
Teoreetiliselt saame samuti hinnata nende maaklerite arvu, mis on vajalik antud koormuse talumiseks. Kuid praktikas on erinevate tasemete seadistamiseks nii palju variante, et mingi konfiguratsiooni potentsiaalset jõudlust on väga keeruline (kui mitte võimatu) hinnata. Teisisõnu, on väga keeruline planeerida konfiguratsiooni, tuginedes mingile kindlale jõudlusele.
Supertubes kasutajatele rakendame tavaliselt järgmist lähenemist: alustame teatud konfiguratsioonist (infrastruktuur + seaded), seejärel mõõdame selle jõudlust, kohandame maakleri seadeid ja korrame protsessi veel kord. See kestab seni, kuni kõige aeglasema infrastruktuuri komponendi potentsiaal on täielikult ära kasutatud.
Nii saame selgema ülevaate sellest, kui palju maaklereid on klastril vaja, et teatud koormusega toime tulla (maaklerite arv sõltub ka teistest teguritest, nagu minimaalne sõnumite replikate arv stabiilsuse tagamiseks, partition-juhtide arv jne). Lisaks saame aimu, millist infrastruktuuri komponenti on soovitatav vertikaalselt skaleerida.
Selles artiklis räägitakse sammudest, mida astume, et 'välja pigistada kõik' kõige aeglasematest komponentidest algkonfiguratsioonides ja mõõta Kafka klastrite läbilaskevõimet. Kõrge usaldusväärsusega konfiguratsioon vajab vähemalt kolme töötavat maaklerit (min.insync.replicas=3), kolm erineva kättesaadavuspiirkonna vahel. Kubernetes'i infrastruktuuri konfigureerimiseks, skaleerimiseks ja jälgimiseks kasutame meie enda konteinerihaldusplatvormi hübriidpilvede jaoks — . See toetab on-premise (bare metal, VMware) ja viit erinevat pilve (Alibaba, AWS, Azure, Google, Oracle), samuti nende mis tahes kombinatsioone.
Mõtted infrastruktuuri ja Kafka klastrite konfiguratsiooni kohta
Allpool toodud näidete jaoks oleme valinud AWS pilveteenuse pakkujaks ja EKS-i Kubernetes'i jaotuseks. Sarnast konfiguratsiooni saab rakendada ka — Banzai Cloud'i Kubernetes'i jaotus, mis on CNCF'i sertifitseeritud.
Kett
Amazon pakub erinevaid . Aluseks on gp2 ja io1 SSD-diskid, kuid kõrge läbilaskevõime tagamiseks gp2 kasutab kogutud krediite (I/O krediidid), seetõttu eelistasime tüüpi io1, mis pakub stabiilset kõrget läbilaskevõimet.
Instantsitüübid
Kafka jõudlus sõltub tugevalt operatsioonisüsteemi leheküljekattest, seega vajame instantsse, millel on piisavalt mälu brokera (JVM) ja leheküljekatte jaoks. Instants c5.2xlarge — hea algus, kuna sellel on 16 GB RAM-i ja . Selle miinus on see, et see suudab tagada maksimaalset jõudlust mitte rohkem kui 30 minutit iga 24 tunni jooksul. Kui töökoormus nõuab maksimaalset jõudlust pikema aja jooksul, tasub kaaluda teisi tüüpe instantsse. Just nii me tegime, valides c5.4xlarge. See tagab maksimaalse läbilaskevõime 593,75 MB/s. EBS-i mahuti maksimaalne läbilaskevõime io1 on suurem kui selle instantsi c5.4xlarge, seega tundub, et infrastruktuuri aeglasem komponent on selle tüübi instantsi I/O läbilaskevõime (mida peaksid kinnitama ka meie koormustestide tulemused).
Võrk
Võrgu läbilaskevõime peaks olema piisavalt suur võrreldes VM-i instantsi ja ketta jõudlusega, vastasel juhul muutub võrk kitsaskohaks. Meie juhul toetab võrgu liides c5.4xlarge kiirus kuni 10 Gb/s, mis on oluliselt kõrgem VM-i instantsi I/O läbilaskevõimest.
Brokereid juurutamine
Brokereid tuleb käivitada (planeerida Kuberneteses) pühendatud sõlmedes, et vältida konkurentsi teiste protsesside vahel CPU, mälu, võrgu ja kettaressursside pärast.
Java versioon
Loogiline valik on Java 11, kuna see on Dockeriga ühilduv, tagades, et JVM määrab õigesti protsessorid ja mälu, mis on saadaval konteineris, kus broker töötab. Teades, et protsessorite piirangud on olulised, määrab JVM sisemiselt ja läbipaistvalt GC ja JIT-kompilaatori lõime arvu. Kasutasime Kafka pilti banzaicloud/kafka:2.13-2.4.0, mis sisaldab Kafka versiooni 2.4.0 (Scala 2.13) Java 11 peal.
Kui soovite Java/JVM kohta Kuberneteses rohkem teada saada, vaadake meie järgmisi publikatsioone:
- ;
- .
Brokери mälu seaded
Brokeri mälu seadistamisel on kaks peamist aspekti: JVM-i seadistused ja Kubernetes'i pod'i seadistused. Pod'i jaoks määratud mälu piir olema suurem kui maksimaalne heap size, et JVM-il oleks ruumi Java metaruumi jaoks, mis asub oma mälus, ja operatsioonisüsteemi lehekaatš, mida Kafka aktiivselt kasutab. Meie testides käivitasime Kafka brokereid seadistustega -Xmx4G -Xms2G, samas kui pod'i mälu piir oli 10 Gi. Pidage meeles, et JVM-i mälu seadistusi saab automaatselt hankida, kasutades -XX:MaxRAMPercentage ja -X:MinRAMPercentage, lähtudes pod'i mälu piirist.
Brokri protsessoriseaded
Üldiselt saab tõhusust suurendada, suurendades paralleelsust, suurendades Kafka kasutatavate lõime arvu. Mida rohkem protsessoreid Kafka jaoks saadaval on, seda parem. Meie testis alustasime 6 protsessori piiranguga ja suurendasime nende arvu järk-järgult (iteratsioonide kaupa) kuni 15. Samuti seadsime num.network.threads=12 brokerite seadetes, et suurendada voogude arvu, mis võtab andmeid võrgust ja saadab need edasi. Kohe pärast avastamist, et järelevalve-brokerid ei suuda piisavalt kiiresti replikate saada, tõsteti num.replica.fetchers kuni 4, et suurendada kiirust, millega järelevalve-brokerid replitseerivad sõnumeid liidritelt.
Koormuse genereerimise tööriist
Peab veenduma, et valitud koormuse generaatori potentsiaal ei lõpe enne, kui Kafka klaster (millele tehakse bänkmärk) saavutab maksimaalse koormuse. Teisisõnu, on oluline eelnevalt hinnata koormuse genereerimise tööriista võimalusi ning valida selleks piisava protsessori ja mälu arvuga instantsid. Sel juhul toodab meie tööriist rohkem koormust, kui Kafka klaster suudab taluda. Pärast mitmeid katseid peatusime kolme instantsi peal, c5.4xlargemilles igas oli käivitatud generaator.
Benkmarkimine
Suuruse mõõtmine on iteratiivne protsess, mis hõlmab järgmisi etappe:
- infrastruktuuri seadistamine (EKS klaster, Kafka klaster, koormuse genereerimise tööriist, samuti Prometheus ja Grafana);
- koormuse genereerimine kindlaksmääratud ajavahemiku jooksul, et filtreerida juhuslikke kõrvalekaldeid kogutud jõudlusnäitajates;
- infrastruktuuri ja vahendite konfigureerimise kohandamine vaatatud jõudlusnäitajate põhjal;
- protsessi kordamine seni, kuni saavutatakse nõutav Kafka klastrite läbivoolu tase. See peab olema stabiilselt reprodutseeritav ja näitama minimaalset variatsiooni läbivoolust.
Järgmises jaos kirjeldatakse samme, mida tehti testklastri bänkmärkimise protsessi käigus.
Tööriistad
Kiireks põhikonfiguratsiooni seadistamiseks, koormuse genereerimiseks ja jõudluse mõõtmiseks kasutati järgmisi tööriistu:
- EKS klastri korraldamiseks Amazonilt c (Kafka ja infrastruktuuri meetrikate kogumiseks) ja (selle meetrikate visualiseerimiseks). Kasutasime integreeritud ühes teenuseid, mis pakuvad föderaalselt jälgimist, keskset logide kogumist, haavatavuste skaneerimist, tõrke taastamist, ettevõtte tasemel turvalisust ja palju muud.
- — tööriist Kafka klasteri koormustestimiseks.
- Grafana paneelid Kafka ja infrastruktuuri metrikate visualiseerimiseks: , .
- Supertubes CLI maksimaalselt lihtsaks Kafka klasteri seadistamiseks Kuberneteses. Zookeeper, Kafka operator, Envoy ja palju muid komponente on installitud ja õigesti konfigureeritud, et käivitada production-ready Kafka klaster Kuberneteses.
- Paigaldamiseks supertubes CLI kasutage juhiseid, mis on toodud .
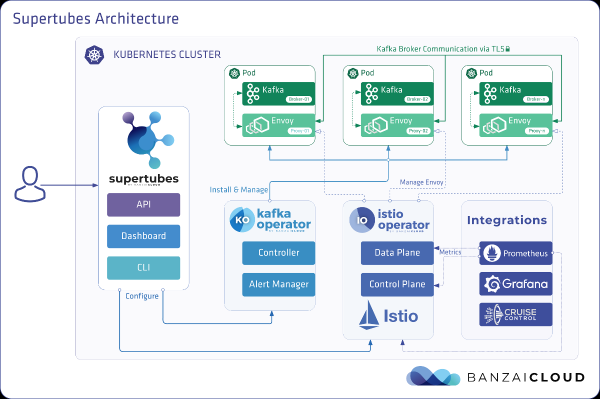
EKS klaster
Valmistage EKS klaster, kus on eraldatud töövõlurid c5.4xlarge erinevates kättesaadavustsoonides Kafka brokergarede pod'ide jaoks, samuti eraldatud sõlmed koormuse genereerijale ja jälgimisinfrastruktuurile.
banzai cluster create -f https://raw.githubusercontent.com/banzaicloud/kafka-operator/master/docs/benchmarks/infrastructure/cluster_eks_202001.jsonKui EKS klaster on üles pandud, aktiveerige selle sisseehitatud — see paigaldab Prometheuse ja Grafana klastrisse.
Kafka süsteemikomponendid
Installige Kafka süsteemikomponendid (Zookeeper, kafka-operator) EKS-is supertubes CLI abil:
supertubes install -a --no-democluster --kubeconfigKafka klaster
EKS kasutab vaikimisi EBS tüüpi mahuteid gp2, seetõttu tuleb luua eraldi salvestusklass mahtude põhjal io1 Kafka klastri jaoks:
kubectl create -f - <<EOF
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: fast-ssd
provisioner: kubernetes.io/aws-ebs
parameters:
type: io1
iopsPerGB: "50"
fsType: ext4
volumeBindingMode: WaitForFirstConsumer
EOF Seadke brokerite jaoks parameeter min.insync.replicas=3 ja juurutage brokeri pod'id kolmes erinevas kättesaadavuspiirkonnas:
supertubes cluster create -n kafka --kubeconfig -f https://raw.githubusercontent.com/banzaicloud/kafka-operator/master/docs/benchmarks/infrastructure/kafka_202001_3brokers.yaml --wait --timeout 600Teemad
Käitasime samaaegselt kolme koormusgeneraatori eksemplari. Igaüks neist kirjutab oma teemasse, st meil on kokku vaja kolme teemat:
supertubes cluster topic create -n kafka --kubeconfig -f -<<EOF
apiVersion: kafka.banzaicloud.io/v1alpha1
kind: KafkaTopic
metadata:
name: perftest1
spec:
name: perftest1
partitions: 12
replicationFactor: 3
retention.ms: '28800000'
cleanup.policy: delete
EOF
supertubes cluster topic create -n kafka --kubeconfig -f -<<EOF
apiVersion: kafka.banzaicloud.io/v1alpha1
kind: KafkaTopic
metadata:
name: perftest2
spec:
name: perftest2
partitions: 12
replicationFactor: 3
retention.ms: '28800000'
cleanup.policy: delete
EOF
supertubes cluster topic create -n kafka --kubeconfig -f -<<EOF
apiVersion: kafka.banzaicloud.io/v1alpha1
kind: KafkaTopic
metadata:
name: perftest3
spec:
name: perftest3
partitions: 12
replicationFactor: 3
retention.ms: '28800000'
cleanup.policy: delete
EOFIga teema replikatsioonifaktor on 3 — minimaalne soovitatav väärtus kõrge kättesaadavuse tootmissüsteemide jaoks.
Koormuse genereerimise tööriist
Meie jooksime kolm koormuse genereerimise eksemplari (igal ühel oli eraldi teema). Koormuse genereerimise pod'ide jaoks on vajalik määrata node affinity, et need planeeritaks ainult neile määratud sõlmedele:
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
labels:
app: loadtest
name: perf-load1
namespace: kafka
spec:
progressDeadlineSeconds: 600
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
app: loadtest
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
creationTimestamp: null
labels:
app: loadtest
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: nodepool.banzaicloud.io/name
operator: In
values:
- loadgen
containers:
- args:
- -brokers=kafka-0:29092,kafka-1:29092,kafka-2:29092,kafka-3:29092
- -topic=perftest1
- -required-acks=all
- -message-size=512
- -workers=20
image: banzaicloud/perfload:0.1.0-blog
imagePullPolicy: Always
name: sangrenel
resources:
limits:
cpu: 2
memory: 1Gi
requests:
cpu: 2
memory: 1Gi
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
terminationGracePeriodSeconds: 30Mõned punktid, millele tähelepanu pöörata:
- Koormuse genereerija genereerib 512-baidiseid sõnumeid ja avaldab need Kafka-s 500-sõnumiliste gruppidena.
- Argumenti kasutades
-required-acks=allpublikatsioon loetakse edukaks, kui kõik sünkroniseeritud sõnumi koopiad on saadud ja Kafka brokerid on need kinnitanud. See tähendab, et meie mõõtmises hindasime mitte ainult liidri kiirusest, kes sõnumeid vastu võtab, vaid ka nende järgijate kiirusest, kes sõnumeid replitseerivad. Selle testi eesmärk ei ole hinnata tarbijate (consumers) kiiruset, kes loevad uusimaid sõnumeid, mis jäävad veel operatsioonisüsteemi lehekausta ja võrrelda seda sõnumite lugemise kiirusest, mis on salvestatud kettale. (consumers) Hiljuti vastuvõetud sõnumeid, mis jäävad veel operatsioonisüsteemi lehekausta, ja selle võrreldavust sõnumite lugemise kiirusest, mis on salvestatud kettale. - Koormuse generaator käivitab paralleelselt 20 töötlusprotsessi (
-workers=20). Iga töötlusprotsess sisaldab 5 tootjat, kes jagavad oma ühendust töötlusprotsessiga Kafka klastri. Kokku on igas koormuse generaatoris 100 tootjat, kes kõik saadavad sõnumeid Kafka klastri.
Klastri oleku jälgimine
Koormustestimise ajal jälgisime ka Kafka klastri tervist, et veenduda pod'ide taaskäivitamise, sünkroniseerimata koopiate ja maksimaalse läbilaskevõime puudumises minimaalsete kõikumistega:
- Koormuse generaator annab standardstatistikat avaldatud sõnumite arvu ja vigade taseme kohta. Vigade protsent peaks jääma väärtusele
0,00%. - , mida haldab kafka-operator, pakub jälgimisliidest, kus saame samuti jälgida klastrite seisundit. Selle liidese vaatamiseks käivita:
supertubes cluster cruisecontrol show -n kafka --kubeconfig - ISR tase (in-sync replikate arv) shrink ja expansion on 0.
Mõõtmis tulemused
3 brokerit, sõnumite suurus — 512 baiti
Partitsioonidega, mis on võrdselt jagatud kolme brokera vahel, suutsime saavutada tootlikkuse ~500 MB/s (umbes 990 tuhat sõnumit sekundis):



JVM-i virtuaalmasina mälu kasutamine ei ületanud 2 GB:



Ketta läbilaskevõime saavutas igal kolmel instantsil maksimaalse I/O läbilaskevõime, kus brookerid töötasid:
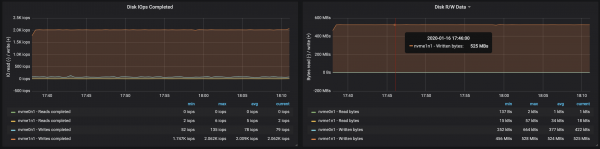
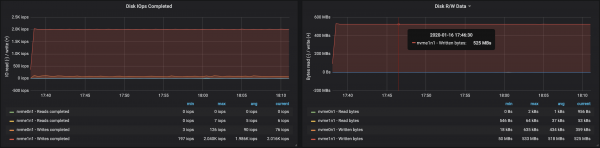
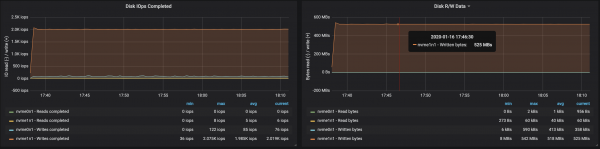
Sõlmede mälukasutuse andmetest selgub, et süsteemne puhversalvestus ja vahemälu olid ~10-15 GB:



3 brokerit, sõnumite suurus — 100 baiti
Sõnumite suuruse vähenemisega langeb läbilaskevõime umbes 15-20%: see mõjutab iga sõnumi töötlemiseks kuluvat aega. Samuti on protsessori koormus peaaegu kahekordistunud.



Kuna brokeri sõlmedes on endiselt kasutamata tuumasid, saab jõudlust parandada Kafka konfiguratsiooni muutmisega. See pole lihtne ülesanne, seetõttu on parem töötada suuremate sõnumitega, et suurendada läbilaskevõimet.
4 brok silent, sõnumi suurus — 512 baiti
Kafka klastrite jõudlust on lihtne suurendada, lisades lihtsalt uusi brokereid ja säilitades partition'ide tasakaalu (see tagab koormuse ühtlase jaotumise brokerite vahel). Meie puhul suurenes klastrite läbilaskevõime pärast brok silent'i lisamist ~580 Mb/s (~1,1 miljonit sõnumit sekundis). Kasv osutus oodatust väiksemaks: peamiselt on selle põhjuseks partition'ide tasakaalu puudumine (kõik brokerid ei tööta maksimaalsel võimekusel).




JVM-i masina mälu tarbimine jäi alla 2 Gb:




Partition'ide tasakaalu puudumine mõjutas brokerite tööd:
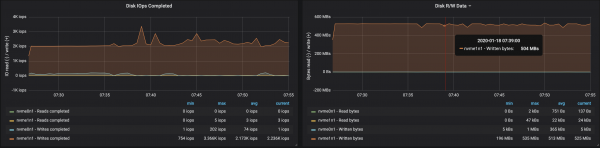
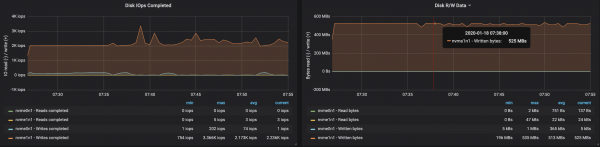
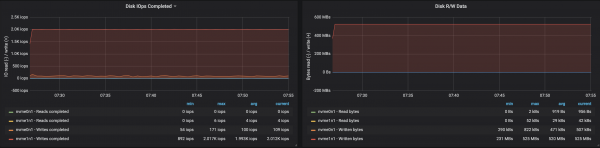
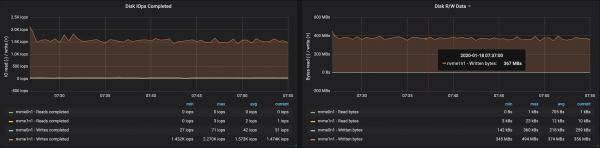
Järeldused
Ülaltoodud ettearvutuslik lähenemisviis võib laieneda keerukamate stsenaariumide jaoks, mis hõlmavad sadu tarbijate, ümberjaotust, uute uuenduste juurutamist, pod’ide taaskäivitamist jne. See kõik võimaldab meil hinnata Kafka klastrite võimeid erinevates tingimustes, tuvastada kitsaskohti ning leida viise probleemide lahendamiseks.
Oleme loonud Supertubes kiireks ja lihtsaks klastrite juurutamiseks, konfigureerimiseks, maaklerite ja teema lisamiseks/eemaldamiseks, hoiatustele reageerimiseks ja Kafka nõuetekohase toimimise tagamiseks Kuberneteses laiemalt. Meie eesmärk on aidata keskenduda põhitegevusele ("toota" ja "tarbida" Kafka sõnumeid), samas kui kogu raske töö jääb Supertubes’i ja Kafka operaatori õlule.
Kui olete huvitatud tehnikast ja Banzai Cloudi avatud lähtekoodiga projektidest, jälgige ettevõtet , või .
P.S. tõlkija märkused
Lugege ka meie blogist:
- «»;
- «»;
- «».
Allikas: habr.com
