

Soovitan tutvuda Aleksei Lesovski ettekande kokkuvõttega Data Egret'ist "PostgreSQL jälgimise põhitõed".
Selles ettekandes räägib Aleksei Lesovski PostgreSQL statistika põhiaspektidest, nende tähendusest ja sellest, miks need peaksid olema jälgimises; millised diagrammid peaksid olema jälgimises, kuidas neid lisada ja kuidas neid tõlgendada. Ettekanne on kasulik andmebaasiadministraatoritele, süsteemiadministraatoritele ja arendajatele, kes on huvitatunud Postgres'i tõrkeotsingust.


Minu nimi on Aleksei Lesovski, esindan ettevõtet Data Egret.
Natuke sõnu enda kohta. Alustasin kunagi ammu süsteemiadministraatorina.
Haldasin erinevaid Linuxe, tegelesin erinevate Linuxiga seotud asjadega, st virtualiseerimise, jälgimisega, töötasin proksiga jne. Kuid mingil hetkel hakkasin rohkem tegelema andmebaasidega, PostgreSQLiga. See meeldis mulle väga. Ja mingil hetkel hakkasin PostgreSQLile pühendama oma tööajast suurema osa. Nii ma slowly muutusin PostgreSQL DBA-ks.
Ja on olnud minu karjääri vältel pidev huvi statistika, jälgimise ja telemeetriaga seotud teemade üle. Kui olin süsteemiadministraator, tegelesin ma Zabbixiga väga põhjalikult. Kirjutasin ka väikese komplekti skripte, mis . See oli oma ajal üsna populaarne. Seal sai jälgida väga erinevaid olulisi asju, mitte ainult Linuxit, vaid ka muid komponente.
Praegu tegeleme PostgreSQL-iga. Kirjutan juba midagi muud, mis võimaldab töötada PostgreSQL-i statistikaga. Selle nimi on (artikkel Habrisse — ).

Lühike sissejuhatus. Millised on meie tellijate ja klientide olukorrad? Juhtunud on mõni probleem, mis on seotud andmebaasiga. Ja kui andmebaas on juba taastatud, tuleb osakonnajuhataja või arenduse juhataja ja ütleb: «Sõbrad, peaksime andmebaasi jälgima, sest midagi halba juhtus ja tulevikus ei tohi sellist asja juhtuda». Siit algab huvitav protsess jälgimissüsteemi valimise või olemasoleva jälgimissüsteemi kohandamise osas, et saaksime jälgida oma andmebaasi – PostgreSQL, MySQL või mõni muu. Ja kolleegid hakkavad üksteisele soovitama: «Olen kuulnud, et on olemas selline andmebaas. Kasutame seda». Kolleegid hakkavad omavahel vaidlema. Ja lõppkokkuvõttes selgub, et valime mõne andmebaasi, aga PostgreSQL jälgimine on selles üsna nõrk ja peame ikkagi midagi kohandama. Korjame GitHubist mõningaid hoidlaid, kloonime neid, kohandame skripte, seadistame neid veelgi. Ja lõpuks osutub see käsitööks.

Seetõttu püüan selles ettekandes anda mõned teadmised, kuidas valida monitooring mitte ainult PostgreSQL-i, vaid ka teiste andmebaaside jaoks. Samuti pakun teadmisi, mis võimaldavad teil täiustada oma monitooringut, et saada sellest tõeliselt kasu, võimaldades oma andmebaasi jälgida ja ennetada võimalikke avariisid, mis võivad tekkida.
Ja need ideed, mis ettekandes käsitleme, on otse tõlgendatavad igasuguste andmebaaside, olgu need relatsioonilised andmebaasid või noSQL, jaoks. Seetõttu ei käsitle me siin ainult PostgreSQL-i, vaid pakume ka palju retsepte, kuidas seda PostgreSQL-is rakendada. Olemas on päringute näited, näited entiteetidest, mis on PostgreSQL-is monitooringuks olemas. Ja kui teie andmebaasis on sarnaseid komponente, mida saab monitooringusse lisada, saate neid ka kohandada ja see on hea.
 Ettekandes ma ei hakka
Ettekandes ma ei hakka
rääkima sellest, kuidas saata ja salvestada mõõdikuid. Ma ei räägi midagi andmete järel töötlemisest ja nende kasutajale esitamisest. Samuti ei käsitle ma midagi häiresüsteemidest.
Kuna ma räägin, näitan ma erinevaid olemasolevaid jälgimise ekraanipilte ja kritiseerime neid. Siiski püüan ma mitte nimetada brände, et mitte luua reklaame ega vastureklaame nendele toodetele. Seega kõik kokkusattumised on juhuslikud ja jäävad teie fantaasiale.

Alustame sellest, mis on jälgimine. Jälgimine on väga oluline asi, mis peab olema olemas. Seda mõistavad kõik. Kuid samas ei kuulu jälgimine äriproduktsi hulka ega mõjuta otseselt ettevõtte kasumit, mistõttu pööratakse jälgimisele alati tähelepanu alles siis, kui aega jääb. Kui meil on aega, tegeleme jälgimisega, kui aega ei ole, siis OK, paneme selle backlogi ja tuleb kunagi tagasi nende ülesannete juurde.
Seetõttu on meie praktikas, kui me tuleme klientide juurde, jälgimine sageli alahinnatud ja tal puuduvad huvitavad asjad, mis aitaksid meil andmebaasiga paremini töötada. Seepärast tuleb jälgimist alati täiustada.
Andmebaasid on keerulised asjad, mida tuleb ka jälgida, sest andmebaasid on teabehoidlad. Teave on ettevõtte jaoks väga oluline ja seda ei tohi mingil juhul kaotada. Samas on andmebaasid väga keerulised tarkvara tükid, mis koosnevad paljusid komponente. Paljusid neist komponentidest tuleb jälgida.
 Kui räägime konkreetselt PostgreSQL-ist, siis seda võib kujutada nagu skeemi, mis koosneb paljusid komponente, mis omavahel suhtlevad. Samuti on PostgreSQL-is nn Stats Collector allüksus, mis võimaldab koguda statistikat nende allüksuste töö kohta ja pakkuda administraatorile või kasutajale liidest, mille abil nad saavad seda statistikat vaadata.
Kui räägime konkreetselt PostgreSQL-ist, siis seda võib kujutada nagu skeemi, mis koosneb paljusid komponente, mis omavahel suhtlevad. Samuti on PostgreSQL-is nn Stats Collector allüksus, mis võimaldab koguda statistikat nende allüksuste töö kohta ja pakkuda administraatorile või kasutajale liidest, mille abil nad saavad seda statistikat vaadata.
See statistika on esitatud teatud funktsioonide ja vaadete (view) kogumina. Neid võib ka tabeliteks nimetada. See tähendab, et tavapärase psql kliendi kaudu saate ühendust luua andmebaasiga, teha nende funktsioonide ja vaadete suhtes valiku ning saada juba konkreetseid numbreid PostgreSQL allüksuste töö kohta.
Saate need numbrid lisada oma lemmik jälgimissüsteemi, joonistada graafikud, lisada funktsioone ja saada pikaajalist analüüsi.
Kuid sel teema ma ei käsitle kõiki neid funktsioone, sest see võiks võtta terve päeva. Räägin vaid paarist-kolmest-neljast asjast ja sellest, kuidas need aitavad jälgimist paremaks muuta.

Ja kui rääkida andmebaasi jälgimisest, siis mida tuleb jälgida? Esiteks tuleb jälgida kättesaadavust, sest andmebaas on teenus, mis pakkub klientidele juurdepääsu andmetele, ning peame jälgima selle kättesaadavust, samuti mõningaid selle kvaliteedi- ja kvantitatiive omadusi.

Samuti tuleb jälgida kliente, kes meie andmebaasiga ühendust võtavad, sest nad võivad olla nii normaalsed kui ka kahjulikud kliendid, kes võivad andmebaasile kahju teha. Neid tuleb samuti jälgida ja nende tegevust jälgida.

Kui kliendid liituvad andmebaasiga, on selge, et nad hakkavad töötama meie andmete kallal, seega peame jälgima ka seda, kuidas kliendid andmetega töötavad: milliste tabelitega, vähemal määral milliste indeksitega. See tähendab, et me peame hindama koormust, mida meie kliendid tekitavad.

Aga ka koormus koosneb muidugi päringutest. Rakendused ühenduvad andmebaasi, pöördudes andmete poole päringute kaudu, seega on oluline hinnata, millised päringud meil andmebaasis on, jälgida nende adekvaatsust, et need ei oleks halvasti kirjutatud ning et mõned valikud tuleks ümber kirjutada ja muuta nii, et need töötaksid kiiremini ja parema tootlikkusega.

Ja kui me räägime andmebaasist, siis andmebaas – see on alati taustaprotsessid. Taustaprotsessid aitavad hoida andmebaasi jõudlust heas seisundis, seetõttu vajavad nad oma tööks teatud hulga ressursse. Samuti võivad nad kattuda kliendi päringute ressurssidega, seetõttu võib taustaprotsesside ahne töö otseselt mõjutada kliendi päringute jõudlust. Seetõttu tuleb neid samuti jälgida ja jälgida, et taustaprotsesside osas ei tekiks mingisuguseid ebatäpsusi.

Ja kõik see, mis puudutab andmebaasi jälgimist, jääb süsteemse metrikaga seotuks. Kuid arvestades, et suurem osa meie infrastruktuurist liigub pilve, jäävad üksiku hosti süsteemsed metrikad alati teisejärgulisteks. Kuid andmebaasides on need endiselt olulised ja süsteemsete metrikate jälgimine on muidugi samuti vajalik.

Süsteemsete metrikatega on enam-vähem kõik hästi, kõik tänapäeva jälgimisse süsteemid toetavad neid meetrikaid, kuid üldiselt on ikka veel mõningaid komponente puudu ning teatud asju tuleb lisada. Nendest räägin ka, mõned slaidid on nende kohta.

Esimese plaani punkt on kättesaadavus. Mis on kättesaadavus? Kättesaadavus minu mõistes tähendab, et andmebaas suudab teenindada ühendusi, st andmebaas on üles tõstetud ja see aktsepteerib ühendusi klientidelt. Ja seda kättesaadavust saab hinnata mitmete omadustega. Need omadused on väga mugav tuua juhtpaneelidele.

Kõik teavad, mis on juhtpaneelid. See on siis, kui sa heidad ühe pilgu ekraanile, kus on koondatud vajalik teave. Ja sa saad kohe määrata – kas andmebaasis on probleem või mitte.
Seega tuleb andmebaasi kättesaadavus ja teised võtmeomadused alati tuua juhtpaneelidele, et see teave oleks käepärast, alati lähedal. Mõned täiendavad üksikasjad, mis aitavad õnnetuste uurimisel, tuleks juba tuua sekundaarsetele juhtpaneelidele või peita drilldown-linkidesse, mis viivad väliste jälgimisse süsteemidesse.
Üks tuntud seire süsteemide näide. See on tõeliselt vinged seire süsteem. See kogub palju andmeid, kuid minu arvates on sellel kummaline arusaam juhtpaneelidest. Seal on link "loo juhtpaneel". Kuid kui te loote juhtpaneeli, siis loote te teatud loendi, mis koosneb kahest veerust, teatud graafikute loendi. Ja kui peate midagi vaatama, hakkate hiirega klõpsima, kerima, otsima vajalikku graafikut. Sellele kulub aega, st juhtpaneele, nagu selliseid, ei ole. On ainult graafikute loendid.

Mida tuleks nendele juhtpaneelidele lisada? Võib alustada sellisest omadusest nagu reageerimisaeg. PostgreSQL-is on vaade pg_stat_statements. Vaikimisi on see keelatud, kuid see on üks tähtsamaid süsteemivaateid, mida tuleb alati lubada ja kasutada. See salvestab teavet kõikide toimingus olevate päringute kohta, mis andmebaasis on täidetud.
Seega saame alustada sellest, et võime võtta kõigi päringute täitmise koguaega ja jagada selle päringute arvuga, kasutades eeltoodud väljade andmeid. Kuid see on vaid keskmine temperatuur haiglas. Saame lähtuda ka muudest väljadest – minimaalne, maksimaalne ja mediaan päringute täitmise aeg. Oleme võimelised looma isegi persentiile, PostgreSQL-is on selleks vastavad funktsioonid. Saame hankida mingid numbrid, mis iseloomustavad meie andmebaasi vastamise aega juba tehtud päringute põhjal, st me ei tee vale päringut 'select 1' ja ei vaata vastusaega, vaid analüüsime vastuste aegu juba tehtud päringute järgi ning esitleme neid kas individuaalse numbrina või joonistame nende põhjal graafiku.
Samuti on oluline jälgida süsteemi genereeritavate vigade arvu hetkel. Selleks saab kasutada pg_stat_database vaadet. Me jälgime xact_rollback välja. See väli näitab mitte ainult tagasivõtmiste arvu, mis andmebaasis toimub, vaid arvestab ka vigade arvu. Ütleme, et saame selle numbri meie juhtpaneelile kuvada ja jälgida, kui palju vigu meil hetkel on. Kui vigu on palju, on see juba hea põhjus vaadata logisid ja uurida, millised need vead on ja miks need esinevad, ning seejärel juba uurida ja lahendada need.

Saame lisada sellise asja nagu tahhograaf. See on tehingute arv sekundis ja päringute arv sekundis. Ütleme nii, et saate neid numbreid kasutada oma andmebaasi praeguse jõudluse jälgimiseks ja vaadata, kas on päringute, tehingute tippe, või vastupidi, andmebaas on alakoormatud, kuna mõni taustaprogramm on väljas. Seda numbrit on oluline pidevalt jälgida ja meeles pidada, et meie projekti jaoks on selline jõudlus normaalne, samas kui kõrgemad ja madalamad väärtused on probleemsed ja arusaamatud, seega tuleb vaadata, miks sellised numbrid.
Kuna me peame hindama tehingute arvu, saame taas pöörduda pg_stat_database vaate poole. Saame liita commit arvu ja rollback arvu ning saada tehingute arvu sekundis.
Kõik mõistavad, et ühte tehingusse võib mahtuda mitmeid päringuid? Seetõttu on TPS ja QPS veidi erinevad.
Päringute arvu sekundis saab hankida pg_stat_statements'i kaudu ja lihtsalt arvutada kõigi tehtud päringute summa. On selge, et me võrdleme praegust väärtust eelmisega, lahutame, saame delfi ja saame arvu.

Soovides on võimalik lisada ka täiendavaid mõõdikuid, mis aitavad hinnata meie andmebaasi kättesaadavust ja jälgida, kas on olnud mõningaid seisu aegu.
Üks selline mõõdik on kättesaadavus (uptime). Kuid PostgreSQL-i kättesaadavus on veidi petlik. Selgitan, miks. Kui PostgreSQL käivitatakse, algab kättesaadavuse arvestamine. Kuid kui näiteks öösel toimub mingi protsess ja OOM-killer lõpetab PostgreSQL-i alamprotsessi, siis PostgreSQL katkestab kõigi klientide ühendused, nullib jagatud mälu ja alustab taastamist viimase kontrollpunkti põhjal. Ja kuni see taastamine kestab, ei aktsepteeri andmebaas uusi ühendusi, nii et seda olukorda saab hinnata kui seisu aega. Kuid kättesaadavuse arvestus ei nulli, sest see arvestab postmasteri käivitamisest alates esimesest hetkest. Seetõttu võib selliseid olukordi üle vaadata.
Samuti tuleks jälgida tühjendajate (vacuum) arvu. Kas kõik teavad, mis on autovacuum PostgreSQL-is? See on huvitav alamsüsteem PostgreSQL-is. Selle kohta on kirjutatud palju artikleid, palju on tehtud ettekandeid. Tühjendamise kohta on palju arutelusid, kuidas see peaks töötama. Paljud peavad seda vältimatuks kurjuseks. Kuid see on tõsi. See on mingis mõttes prügikorjamise analoog, mis puhastab aegunud rea versioonid, mis ei ole enam ühegi tehingu jaoks vajalikud, ja vabastab ruumi tabelites, indeksites uute ridade jaoks.
Miks on vaja seda jälgida? Sest tühjendamine võib mõnikord teha suure kahju. See sööb palju ressursse ja kliendi päringud kannatavad selle tõttu.
Ja seda tuleks jälgida pg_stat_activity vaate kaudu, millest ma räägin järgmises osas. See vaade näitab praegust aktiivsust andmebaasis. Selle aktiivsuse kaudu saame jälgida, kui palju tühjendusi on praegu töös. Me saame jälgida tühjendusi ja näha, et kui meie limiit on ületatud, siis see on põhjus, miks uurida PostgreSQL seadeid ja proovida tühjendamise tööd optimeerida.
Teine PostgreSQL-i omadus on see, et PostgreSQL kannatab pikaajaliste tehingute all. Eriti tehingute, mis kauem püsivad ja midagi ei tee. Need on nn stat idle-in-transaction. Selline tehing hoiab kinni lukud, takistab vakuumi tööd. Ja tagajärjena - tabelid paisuvad, nende suurus suureneneb. Ja päringud, mis töötavad nende tabelitega, hakkavad aeglasemalt töötama, sest tuleb igasuguseid vanu rea versioone mälust kettale ja tagasi eksponeerida. Seetõttu tuleb jälgida ka kõige pikemaid tehingute ja vakuumi päringute aega. Ja kui me näeme mõningaid protsesse, mis on juba väga kaua töötanud, rohkem kui 10-20-30 minutit OLTP koormuse korral, siis tuleks neile tähelepanu pöörata ja nad sundida lõpetama või optimeerida rakendust, et neid ei kutsutaks esile ja nad ei ripuks nii kaua. Analüütilise koormuse puhul on 10-20-30 minutit normaalne, seal on mõnikord isegi pikemaid.

Edasi liigume variandi juurde, kus on ühendatud kliendid. Kui oleme juba koostanud juhtpaneeli ja avaldanud seal olulised kättesaadavuse meetrid, võime sinna lisada ka täiendavat teavet ühendatud klientide kohta.
Teave ühendatud klientide kohta on oluline, kuna PostgreSQLi vaatepunktist on kliendid erinevad. On head kliente ja on ka halbu kliente.
Lihtne näide. Klienti mõistan rakendusena. Rakendus on ühendatud andmebaasiga ja hakkab kohe saatma sinna oma päringuid, andmebaas töötleb neid ja täidab, tulemused saadetakse kliendile tagasi. Need on head ja õiged kliendid.
On olukordi, kus klient on ühendatud, hoiab ühendust, kuid ei tee samas midagi. Ta on idle olekus.
Kuid on ka halbu kliente. Näiteks, sama klient ühendas end, avas tehingu, tegi andmebaasis midagi ja seejärel läks koodi, et pöörduda välise allika poole või andmete töötlemiseks. Kuid ta ei sulgenud tehingut. Ja tehing jääb andmebaasi ja hoiab rida lukus. See on halb olukord. Ja kui äkki rakendus kuskil oma sees katkeb erandi (Exception) tõttu, võib tehing jääda avatuks väga pikaks ajaks. Ja see mõjutab otseselt PostgreSQL-i jõudlust. PostgreSQL töötab aeglasemalt. Seetõttu on selliseid kliente oluline õigeaegselt jälgida ja sundida nende töö lõpetamist. Samuti tuleb optimeerida oma rakendusest, et selliseid olukordi ei tekiks.
Teised halvad kliendid on ootejärjekorras olevad kliendid. Kuid nad muutuvad halbadeks olukordade tõttu. Näiteks lihtsalt seisev tehing: võib avada tehingu, lukustada mõned read ja siis kuskil koodi sees see katkeb, jättes rippuma tehingu. Tuleb teine klient, kes küsib samu andmeid, kuid ta peab silmitsi seisma lukustusega, sest see rippuv tehing hoiab juba lukustusi mõnes vajalikus reaas. Ja teine tehing jääb ootele, kuni esimene tehing lõpetatakse või selle administraator sunnib seda sulgema. Nii võivad ootavad tehingud koguneda ja ületada andmebaasi ühenduste limiiti. Ja kui limiit ületatakse, siis rakendus ei saa enam andmebaasiga töötada. See on juba kriitiline olukord projekti jaoks. Seetõttu on halbu kliente vaja jälgida ja nendele õigeaegselt reageerida.
Teine näide jälgimisest. Siin on juba korralik armatuurlaud. Ülal on teavet ühenduste kohta. DB-ühendused – 8 tükki. Ja see on kõik. Meil pole teavet selle kohta, millised kliendid on aktiivsed, millised kliendid lihtsalt ootavad, mitte midagi ei tee. Pole teavet ummistunud tehingute ja ooteühenduste kohta, st see näit on lihtsalt numbrina, mis näitab ühenduste arvu ja see on kõik. Edasi mõelge ise.

Seetõttu, et seda teavet jälgimisele lisada, tuleb pöörduda süsteemi vaate pg_stat_activity poole. Kui veedate palju aega PostgreSQL-is, siis see vaade on tõeliselt väärtuslik ning see peaks muutuma teie sõbraks, kuna see näitab praegust aktiivsust PostgreSQL-is, st mis seal toimub. Iga protsessi kohta on eraldi rida, mis näitab teavet selle protsessi kohta: milliselt hostilt ühendus on loodud, millise kasutaja all, millise nimega, millal tehing käivitati, milline on praegu käivitatav päring ja milline päring oli eelmine. Seega saame kliendi olekut hinnata stat välja järgi. Teisisõnu, saame selle välja alusel grupeerida ja saada need statsid, mis praegu andmebaasis on ning ühenduste arvu, mis on sellega statsiga andmebaasis. Ja juba saadud numbrid saame saata meie jälgimisele ja nende põhjal graafikuid joonistada.
Samuti on oluline hinnata tehingu kestust. Olen juba rääkinud, et on tähtis hinnata vaakumite kestust, kuid tehingud on samuti täpselt nii hinnatavad. On väljad xact_start ja query_start. Need näitavad, ütleme nii, tehingu algus- ja päringu algusaega. Me võtame funktsiooni now(), mis näitab praegust ajamärki ja lahutame sellest tehingu ja päringu ajatempli. Ja saame tehingu kestuse, päringu kestuse.
Kui näeme pikki tehinguid, peame need juba lõpetama. OLTP-koormuse jaoks peetakse pikki tehinguid selliseks, mis kestab üle 1-2-3 minuti.. OLAP-koormuse puhul on pikad tehingud normaalsed, kuid kui need kestavad rohkem kui kaks tundi, siis on see samuti märk sellest, et kuskil on meil tasakaaluhäire.

Kui kliendid on andmebaasi sisse loginud, hakkavad nad meie andmetega tööd tegema. Nad pöörduvad tabelite poole, nad pöörduvad indeksite poole, et saada andmeid tabelist. Oluline on hinnata, kuidas kliendid nende andmetega töötavad.
See on vajalik, et hinnata meie töökoormust ja umbkaudu mõista, millised tabelid on meie jaoks kõige «kuumemad». Näiteks vajame seda olukordades, kus soovime «kuumad» tabelid paigutada kiiresti SSD-salvestusse. Näiteks võime arhiivi tabelid, mida me juba ammu ei kasuta, viia «külma» arhiivi SATA-kettale ja lasta neil seal elada, nendele pääsemine toimub vastavalt vajadusele.
Samuti on see kasulik anomaaliate avastamiseks erinevate väljaandmiste ja juurutamiste järel. Oletame, et projekt käivitas uue funktsiooni. Näiteks lisati uus funktsionaalsus andmebaasi haldamiseks. Ja kui me joonistame välja tabelite kasutamise graafikud, saame nendel graafikutel kergesti avastada neid anomaaliaid. Näiteks uuenduste või kustutuste äkilised tõusud. See on väga hästi nähtav.
Samuti on võimalik avastada "sulgunud" statistika anomaaliaid. Mida see tähendab? PostgreSQL-l on väga tugev ja hea päringute planeerija. Arendajad kulutavad palju aega selle arendamisele. Kuidas see töötab? Heade plaanide koostamiseks kogub PostgreSQL teatud ajavahemike järel statistikat tabelites andmete jaotumise kohta. Need on kõige sagedasemad väärtused: ainulaadsete väärtuste arv, teave NULL-e kohta tabelis, palju teavet.
Selle statistika põhjal koostab planeerija mitu päringut, valib kõige optimaalsema ja kasutab seda päringu plaani päringu täitmiseks ja andmete tagastamiseks.
Kord, kui statistika "ujub". Andmete kvaliteet ja hulk on mingil moel tabelis muutunud, kuid statistika ei kogunenud. Ja loodud plaanid võivad osutuda mitteoptimaalseteks. Kui meie plaanid osutuvad kogutud jälgimise ja tabelite järgi mitteoptimaalseteks, saame neid anomaaliaid näha. Näiteks, kui andmed on kvaliteetselt muutunud ja koondindeks hakkas kasutama järjestikust läbitöötamist tabelis, st kui päringul on vaja tagastada vaid 100 rida (piirang on limit 100), siis selle päringu jaoks tehakse täiuslik läbimine. Ja see avaldab alati väga halba mõju jõudlusele.
Ja me saame seda näha jälgimises. Võime juba vaadata seda päringut, sooritada explain, koguda statistikat, ehitada uus täiendav indeks. Ja juba reageerida sellele probleemile. Seetõttu on see oluline.
Teine näide jälgimisest. Ma arvan, et paljud on selle ära tundnud, kuna see on väga populaarne. Kes kasutab seda oma projektides ? А кто использует этот продукт совместно с Prometheus? Дело в том, что в стандартном репозитории этого мониторинга есть дашборд для работы с PostgreSQL – Prometheus. Kuid siin on üks halb detail.
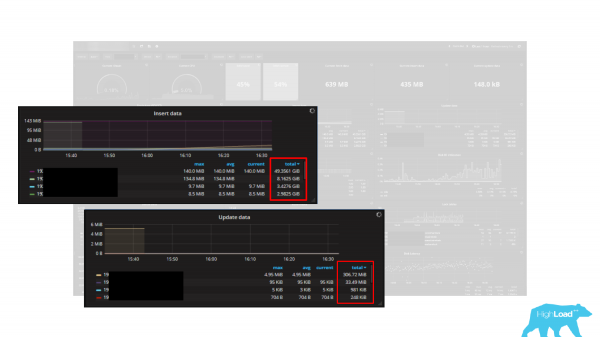
On mitmeid graafikuid. Ühtsuse mõõtmena on näidatud baidid, st seal on 5 graafikut: Insert data, Update data, Delete data, Fetch data ja Return data. Kuid mõõtühikute puhul on näidatud baidid. Probleem seisneb aga selles, et PostgreSQL statsitikast tagastavad andmed tuple'itena (rea kujul). Seega on need graafikud väga hea viis teie töökoormuse vähendamiseks mitme korra võrra, kümnete kordade võrra, kuna tuple ei ole bait, tuple on rida, see on palju baite ja see on alati muutuva pikkusega. Seega, koormuse arvutamine baidides kasutades tuple'e on pea võimatu ülesanne või väga keeruline. Seetõttu on alati oluline mõista, et kui kasutate armatuurlauda või sisseehitatud jälgimist, teeb see seda õigesti ja tagastab teile õigesti hinnatud andmed.

Kuidas saada statistikat nende tabelite kohta? Selleks on PostgreSQL-s olemas teatud hulk vaateid. Ja peamine vaade on . User_tables – see tähendab, et tabelid, mis on loodud kasutaja nimel. Vastupidiselt on süsteemi vaated, mida PostgreSQL ise kasutab. Ja on kokkuvõtte tabel Alltables, mis sisaldab nii süsteemi- kui ka kasutajate tabeleid. Saate tugineda ükskõik kummale, mis teile rohkem meeldib.
Ülaltoodud väljade põhjal on võimalik hinnata sisestuste, värskenduste ja kustutuste arvu. See paneel, mida ma kasutasin, kasutab neid välju töökoormuse omaduste hindamiseks. Seetõttu saame samuti neile tugineda. Kuid tasub meeles pidada, et need on tuples, mitte baitid, seega ei saa me lihtsalt võtta ja muuta neid baitideks.
Nende andmete põhjal saame koostada nn TopN-tabeleid. Näiteks Top-5, Top-10. Ja on võimalik jälgida neid kuumi tabeleid, mida kasutatakse rohkem kui teisi. Näiteks 5 «kuuma» tabelit sisestamise osas. Ja nende TopN-tabelite põhjal hindame meie töökoormust ning saame jälgida töökoormuse piike pärast igasuguseid avalikustamisi, värskendusi ja juurdepääse.
Samuti on oluline hinnata tabeli suurusi, kuna mõnikord arendajad lisavad uut funktsiooni ja meie tabelid hakkavad suurendama oma suuri mõõtmeid, kuna otsustatakse lisada täiendav andmemaht, kuid ei prognoosita, kuidas see mõjutab andmebaasi suurust. Sellised juhud võivad samuti olla meie jaoks üllatuseks.

Ja nüüd väike küsimus teile. Milline küsimus tekib, kui märkate andmebaasi serveris koormust? Milline on järgmine küsimus, mis teil tekib?

Kuid tegelikult tekib järgmine küsimus. Milliseid päringuid koormus kutsub esile? St ei ole huvitav vaadata protsesse, mis koormust põhjustavad. On selge, et kui host on andmebaas, siis seal töötab andmebaas ja on selge, et ainult andmebaasid seal ka töötavad. Kui avame Topi, näeme seal PostgreSQL protsesside nimekirja, mis midagi teevad. Topist ei selgu, mida nad teevad.

Seega on vaja tuvastada need päringud, mis põhjustavad suurima koormuse, sest päringute häälestamine toob tavaliselt rohkem kasu kui PostgreSQL või operatsioonisüsteemi häälestamine või isegi riistvara häälestamine. Minu hinnangul on see umbes 80-85-90%. Ja seda tehakse palju kiiremini. Päringu parandamine võtab vähem aega kui konfiguratsiooni korrigeerimine, taaskäivitamise planeerimine, eriti juhul, kui andmebaasi ei saa taaskäivitada või riistvara lisada. Lihtsam on kuskil päringut ümber kirjutada või lisada indeks, et saada juba paremat tulemust sellest päringust.
Seega tuleb jälgida päringute sisu ja nende adekvaatsust. Vaatame teisi jälgimise näiteid. Siin on samuti näiliselt suurepärane jälgimine. On teavet replikatsiooni, läbilaskevõime, lukustuste ja ressursside kasutamise kohta. Kõik on suurepärane, kuid puudub teave päringute kohta. Pole selge, millised päringud meie andmebaasis käivitatakse, kui kaua need kestavad ja kui palju neid on. Me peame jälgimisel alati seda teavet omama.

Ja selle teabe saamiseks saame kasutada pg_stat_statements moodulit. Selle alusel saab koostada erinevaid diagramme. Näiteks saame saada teavet kõige sagedamini esitatavate päringute kohta, s.t. nende päringute kohta, mis täidetakse kõige rohkem. Jah, ka pärast väljatõmmete tegemist on väga kasulik sellele pilk heita ja mõista, kas päringute arv on suurenenud.
Saame jälgida kõige aeglasemaid päringuid, s.t. neid päringuid, mis täidetakse kõige kauem. Need kasutavad protsessorit, nad tarbivad sisendi-väljundi ressursse. Saame seda hinnata ka total_time, mean_time, blk_write_time ja blk_read_time väljade kaudu.
Saame hinnata ja jälgida kõige ressursimahukamaid päringuid, neid, mis loevad kettalt, töötavad mäluga või vastupidi, genereerivad kirjutamiskoormust.
Saame hinnata kõige arvukamaid päringuid. Need on päringud, mis tagastavad suure hulga ridu. Näiteks võib see olla päring, kus unustati limiit panna. Ja see tagastab lihtsalt kogu tabeli sisu või midagi, mis on nõutud tabelite kohta.
Saame ka jälgida päringuid, mis kasutavad ajutisi faile või ajutisi tabeleid.

Meil on ka taustaprosessid. Taustaprosessid on eelkõige kontrollpunktid, mida nimetatakse ka kontrollpunktideks, autovacuum ja replikatsioon.
Teine näide jälgimisest. Vasakul on vahekaart Maintenance, liikuge sinna ja loodame näha midagi kasulikku. Kuid siin on ainult vakumite ja statistika kogumise tööaeg, rohkem mitte midagi. See on väga napp teave, seetõttu on alati oluline teada, kuidas meie andmebaasis taustaprosessid töötavad ja kas nende tegevusest on probleeme.

Kontrollpunkte käsitledes tasub meeles pidada, et kontrollpunktid kustutavad 'räpaseid' lehti sharded mälu piirkonnast kõvakettale, seejärel luuakse kontrollpunkt. See kontrollpunkt võib hiljem olla kasutatav taastamise kohana, kui PostgreSQL peaks äkki kokku kukkuma.
Seega, et kõik "räpased" lehed kettale lähtestada, tuleb teha teatud kogus kirjutamist. Ja tavaliselt on süsteemides, kus on palju mälu, seda väga palju. Ja kui meil on kontrollpunkte väga sageli lühikese aja jooksul, siis kettasüsteemi jõudlus kannatab tõsiselt. Kliendi päringud kannatavad ressursside puuduse all. Nad võitlevad ressursside pärast ning neil jääb jõudlusest puudu.
Seega, pg_stat_bgwriter kaudu võivad antud väljade järgi jälgida kontrollpunktide arvu. Ja kui mingis ajavahemikus (näiteks 10-15-20 minuti, pool tunni jooksul) on kontrollpunkte väga palju, näiteks 3-4-5, siis see võib juba olla probleem. Ja tuleb vaadata andmebaasi, vaadata konfiguratsiooni, mis sellist kontrollpunktide rohkust põhjustab. Võib-olla toimub mingi suur kirjutamine. Workload'i põhjal saame juba hinnata, kuna meil on töökoormuse graafikud juba lisatud. Saame kohandada kontrollpunktide parameetreid nii, et need ei mõjuta päringute jõudlust.

Ma tulen jälle autovacuum’i juurde, sest see on asi, mis nagu juba mainisin, võib kergesti mõjutada nii kettahaarde kui ka päringute jõudlust, seetõttu on alati oluline hinnata autovacuum’i määra.
Autovacuum’i tööde arv andmebaasis on piiratud. Vaikimisi on neid kolm, seega kui meil on pidevalt töötamas kolm töölist, tähendab see, et meie autovacuum on alakonfigureeritud, tuleb tõsta limite, üle vaadata autovacuum’i seaded ja minna juba konfiguratsiooni.
On oluline hinnata, millised autovacuum’i töölised meil töötavad. Kas see on kasutaja käivitatud, DBA on tulnud ja käsitsi käivitanud mingi vacuum’i, ning see on tekitanud koormuse. Meil on tekkinud mingi probleem. Või on see autovacuum’ide arv, mis arvestavad tehingute arvutust. Mõnedes PostgreSQL versioonides on need väga koormavad vacuum’id. Need võivad kergesti mõjutada jõudlust, sest need loevad kogu tabelit täiesti läbi, skaneerides kõik plokid selles tabelis.
Ja muidugi, ka vaakumi kestus. Kui meil on pikad vaakumid, mis töötavad väga pikka aega, siis see tähendab, et peaksime taas tähelepanu pöörama vaakumi konfiguratsioonile ja võib-olla kaaluma selle seadete ülevaatamist. Sest võib tekkida olukord, kus vaakum töötab tabelis kaua (3-4 tundi), kuid selle töötamise ajal on tabelis jälle kogunenud suur hulk surnud ridu. Ja nii pea, kui vaakum lõppeb, peab see tabelit uuesti vaakumeerima. Nii jõuame olukorda – lõputu vaakum. Ja sellisel juhul ei tule vaakum oma tööga toime ning tabelid hakkavad järk-järgult suurendama oma mahtu, kuigi selles olevate kasulike andmete hulk jääb endiseks. Seetõttu vaatame alati pikal vaakumite ajal konfiguratsiooni ja püüame seda optimeerida, kuid samas, et klientide päringute jõudlus ei kannataks.

Praegu ei leidu praktiliselt ühtegi PostgreSQL-i installatsiooni, kus ei oleks voogedastust. Replikatsioon on andmete edastamise protsess peamehelt kopeerimisprotsessile.
PostgreSQL-is replikatsioon toimub tehingu logi kaudu. Master genereerib tehingu logi. Tehingu logi saadetakse replikale üle võrgus ja seal see taastatakse. Kõik on lihtne.
Seetõttu kasutatakse replikatsiooni viivituse jälgimiseks vaadet pg_stat_replication. Kuid sellega ei ole kõik lihtne. Versioonis 10 on vaates toimunud mitmeid muudatusi. Esiteks, mõned väljad on ümber nimetatud. Ja mõned väljad on lisatud. Versioonis 10 lisandusid väljad, mis võimaldavad hinnata replikatsiooni viivitust sekundites. See on väga mugav. Enne versiooni 10 oli võimalik hinnata replikatsiooni viivitust baitides. See võimalus jääb alles ka versioonis 10, st saate valida, kumba teile sobib – hinnata viivitust baitides või sekundites. Paljud teevad mõlemat.
Kuid siiski, et hinnata replikatsiooni viivitust, tuleb teada tehingu logi positsiooni. Need tehingu logi positsioonid ongi pg_stat_replication vaates. Ütleme nii, et saame funktsiooni pg_xlog_location_diff() abil võtta kaks punkti tehingu logis. Arvutada nende vahelise erinevuse ja saada replikatsiooni viivitus baitides. See on väga mugav ja lihtne.
10. versioonis nimetati see funktsioon ümber pg_wal_lsn_diff(). Üldiselt, kõikides funktsioonides, vaadetes, utiliitides, kus ilmus sõna "xlog", asendati see sõnaga "wal". See kehtib nii vaadete kui ka funktsioonide kohta. See on selline uuendus.
Pluss, 10. versioonis lisandusid read, mis näitavad konkreetselt viivitust. Need on write lag, flush lag ja replay lag. St neid asju on oluline jälgida. Kui näeme, et meil on replikatsiooni viivitus, tuleb uurida, miks see tekkis, kust see tuli ning probleeme lahendada.

Süsteemsete mõõdikute osas on peaaegu kõik korras. Kui iga monitoringu loomine algab süsteemsetest mõõdikutest. Need on protsessorite, mälu, vahetuse, võrgu ja ketta kasutamine. Kuid paljusid parameetreid ei ole seal vaikimisi olemas.
Kui protsessi utilizeerimisega on kõik korras, siis ketta utilizeerimisega on probleeme. Tüüpiliselt lisavad jälgimisriistade arendajad teavet läbilaskevõime kohta. See võib olla iops või baitides. Kuid nad unustavad latentsuse ja kettaseadmete utilizeerimise. Need on olulisemad parameetrid, mis aitavad hinnata, kui koormatud meie kettad on ja kui palju nad peavad pidurdama. Kui meil on kõrge latentsus, siis tähendab see, et kettastega on mingid probleemid. Kui meil on kõrge utilizeerimine, siis tähendab see, et kettad ei tule toime. Need on kvaliteetsemad omadused kui läbilaskevõime.
Kuigi neid statistilisi andmeid saab ka failisüsteemist /proc, nagu tehakse protsessorite utilizeerimise puhul. Miks seda teavet jälgimistesse ei lisata, ei tea ma. Kuid sellegipoolest on oluline, et see oleks teie jälgimises.
Sama kehtib ka võrguliideste kohta. Võrgu läbilaskevõime kohta on teavet pakettide, baitide kaupa, kuid siiski puudub teave latentsuse ja utilizeerimise kohta, kuigi see oleks samuti kasulik teave.

Iga monitooringul on omad puudused. Ükskõik millist monitooringut te valite, see ei vasta alati teatud kriteeriumidele. Siiski nad arenevad, lisanduvad uued funktsioonid ja asjad, seega valige midagi ja viige see lõpule.
Ja et edendada, on oluline alati mõista, mida edastatud statistika tähendab ning kuidas seda saab probleemide lahendamiseks kasutada.
Ja mõned peamised punktid:
- Alati on vajalik jälgida kättesaadavust, omada armatuurlaudu, et saaksite kiiresti hinnata, kas andmebaas on korras.
- Alati on oluline teada, millised kliendid töötavad teie andmebaasiga, et saaks halbade kliendi seitsime kõrvaldada.
- Oluline on hinnata, kuidas need kliendid andmetega töötavad. Tuleb olla teadlik oma töökoormusest.
- Oluline on hinnata, kuidas see töökoormus luuakse, milliste päringute kaudu. Te saate hinnata päringuid, optimeerida neid, refaktoreerida, ehitada neile indekseid. See on väga oluline.
- Taustprotsessid võivad negatiivselt mõjutada kliendipäringute töötlemist, seega on oluline jälgida, et nad ei kasutaks liiga palju ressursse.
- Süsteemimetriikide abil saate koostada plaanid skaleerimiseks ja oma serverite mahutavuse suurendamiseks, seetõttu on oluline neid jälgida ja hinnata.

Kui see teema teid huvitab, siis võite tutvuda nende linkidega.
— see on ametlik dokumentatsioon statistika kogumise jaoks. Seal on kirjeldatud kõiki statistilisi vaateid ja kõiki välju. Saate neid lugeda, mõista ja analüüsida. Ja juba nende põhjal koostada oma graafikud ning lisada oma jälgimistesse.
Näidiskeerud:
See on meie ettevõtte repos ja minu isiklik. Seal on näidiskeerud. Seal ei ole keerud, mis algavad fraasiga select* from midagi. Need on juba valminud keerud koos ühendumistega, kasutades huvitavaid funktsioone, mis võimaldavad tooreid numbreid muuta loetavateks ja mugavateks väärtusteks, st need on baitide ja aja näitajad. Saate neid uurida, vaadata, analüüsida, lisada oma jälgimistesse ning koostada nende põhjal oma jälgimised.
Küsimused
Küsimus: Te ütlesite, et te ei reklaami brände, aga minul on siiski huvi - milliseid armatuurlaudu te oma projektides kasutate?
Vastus: Erinevalt. On juhtumeid, kus külastame klienti ja tal on juba oma monitorimine. Me anname kliendile nõu, mida tema monitorimisse lisada. Halvem on olukord Zabbiхiga. Sest tal pole võimalust koostada TopN-graafikuid. Meie kasutame , sest me konsulteerisime nende poistega monitorimise osas. Nad tegid PostgreSQL monitorimist meie täpsustatud nõuete põhjal. Ma kirjutan oma pet-projekti, mis kogub andmeid läbi Prometheuse ja joonistab neid . Mul on eesmärk teha Prometheuses oma eksportija ja seejärel joonistada kõik Grafanas.
Küsimus: Kas on olemas AWR-aruannete või ... agregatsioonide analooge? Kas te olete millegi taolisega kursis?
Vastus: Jah, ma tean, mis on AWR, see on äge asi. Praegu on olemas väga erinevaid lahendusi, mis rakendavad umbes järgmist mudelit. Teatud ajaintervali järel kirjutatakse mõningaid aluseid PostgreSQL-i või eraldi andmehoidlasse. Neid saab internetis otsida, need on olemas. Üks sellise lahenduse arendaja istub sql.ru foorumis PostgreSQLi teemas. Teda saab sealt kinni püüda. Jah, selliseid asju on olemas, neid saab kasutada. Pluss enda Ma kirjutangi asja, mis võimaldab teha sama.
P.S.1 Kui kasutate postgres_exporter'i, siis millist juhtpaneeli te kasutate? Seal on mitu. Need on juba aegunud. Kas võib-olla loob kogukond uuendatud mall?
P.S.2 Eemaldasime pganalyze, kuna tegemist on pruugitava SaaS-pakkumisega, mis keskendub sooritusanalüüsile ja automatiseeritud häälestusettepanekutele.
Ainult registreeritud kasutajad saavad küsitluses osaleda. , palun.
Milline self-hosted PostgreSQL monitooring (juhtpaneeliga) on teie arvates parim?
30,0%Zabbix + Alexei Lesovskyi lisandused või zabbix 4.4 või libzbxpgsql + zabbix libzbxpgsql + zabbix3
0,0%https://github.com/lesovsky/pgcenter0
0,0%https://github.com/pg-monz/pg_monz0
20,0%https://github.com/cybertec-postgresql/pgwatch22
20,0%https://github.com/postgrespro/mamonsu2
0,0%https://www.percona.com/doc/percona-monitoring-and-management/conf-postgres.html0
10,0%pganalyze on pruugitav SaaS — ei saa eemaldada1
10,0%https://github.com/powa-team/powa1
0,0%https://github.com/darold/pgbadger0
0,0%https://github.com/darold/pgcluu0
0,0%https://github.com/zalando/PGObserver0
10,0%https://github.com/spotify/postgresql-metrics1
Hääletas 10 kasutajat. 26 kasutajat hoidusid.
Allikas: habr.com
