

Sissejuhatus
 „Peame jooksma kõikide jõududega, et lihtsalt paigal püsida,
„Peame jooksma kõikide jõududega, et lihtsalt paigal püsida,
ja kuhugi jõudmiseks tuleb joosta vähemalt kahekordselt kiiremini!”
(c) Alice Imedemaal
Mõni aeg tagasi paluti mul pidada loeng analüütikutele meie ettevõttes andmete mudelite kavandamise teemal, sest veedame kaua aega projektides (mõnikord mitu aastat), unustades, mis toimub IT-tehnoloogia maailmas. Meie ettevõttes (kuid nii on läinud) ei kasutata paljudes projektides NoSQL andmebaase (vähemalt seni), seetõttu keskendusin oma loengus veidi rohkem neile HBase näitel ning püüdsin suunata sisu neid, kes ei ole kunagi nendega töötanud. Eelkõige illustreerisin andmete mudeli kavandamise mõningaid omadusi näitega, mida lugesin paar aastat tagasi . Näiteid analüüsides võrdlesin erinevaid lahendusi sama probleemi jaoks, et aidata kuulajatel mõista põhiteemasid.
Hiljuti, "ei tea, mida teha", küsisin endalt, kui hästi teoreetilised järeldused praktikale vastavad (pikad maised puhkepäevad karantiini režiimis toetavad seda eriti). Just seetõttu sündis see artikli idee. Arendaja, kes on NoSQL-iga juba pikka aega tegelenud, ei pruugi siit midagi uut leida (ja seetõttu võib kohe poole artikli poole kerida). Kuid analüütikutele, kes ei ole veel NoSQL-iga süvitsi tegelenud, arvan, et see on kasulik, et saada põhiteadmisi andmemudelite kavandamise eripäradest HBase jaoks.
Näite analüüs
Minu arvates, enne NoSQL andmebaaside kasutamise alustamist tuleks hoolikalt mõelda ja kaaluda plusse ja miinuseid. Sageli on probleemi võimalik lahendada ka traditsiooniliste relationaalsete andmebaasidega. Seega on parem mitte kasutada NoSQL-i ilma tõsise põhjenduseta. Kui siiski on otsustatud kasutada NoSQL andmebaasi, tuleb arvestada, et projekteerimislähenemised on siin veidi erinevad. Eriti võivad mõned neist tunduda harjumatuna neile, kes on varem kasutanud ainult relationaalseid andmebaase (minu tähelepanekute kohaselt). Nii et „relationaalses“ maailmas alustame tavaliselt domeeni modelleerimisest ja vajadusel teeme mudeli denormaliseerimise. Me peame kohe arvestama eeldatavate andmetöötlusstsenaariumidega ja algselt denormaliseerima andmed. Lisaks on veel mitu erinevust, millest räägitakse allpool.
Vaatame järgmise „sünteetilise“ ülesande, millega tegeleme edasi:
Kasutajate sõprade nimekirja salvestamise struktuur tuleb projekteerida mingisuguses abstraktses sotsiaalvõrgustikus. Lihtsuse huvides eeldame, et kõik seosed on suunatud (nagu Instagramis, mitte LinkedInis). Struktuur peab võimaldama tõhusalt:
- Vastata küsimusele, kas kasutaja A loeb kasutaja B sisu (lugemismall)
- Kasutaja A ja kasutaja B vahelisi seoseid lisada/eemaldada juhul, kui kasutaja A tellib/peatutab kasutaja B (andmete muutmise mall)
Lahenduste variandid on loomulikult mitmed. Tavalises relatsioonilises andmebaasis teeksime tõenäoliselt lihtsalt seoste tabeli (võimalik, et tüpiseeritud, kui näiteks on vaja salvestada kasutajagruppi: perekond, töö jne, kuhu kuulub antud „sõber“), ja kiirusoptimeerimise huvides lisaks indekseid/partitsioneerimist. Tõenäoliselt näeks lõpptabel välja umbes nii:
user_id
friend_id
Vladimir
Peti
Vladimir
Olya
siin ja edaspidi, et paremini aru saada, kasutan ID-de asemel nimesid
HBase'i puhul teame, et:
- efektiivne otsing, mis ei põhjusta täielikku tabeli skaneerimist, on võimalik ainult võtme alusel
- Seetõttu on tavaliste SQL-päringute kirjutamine sellistele andmebaasidele halb mõte; tehniliselt on muidugi võimalik saata Impala'lt SQL-päring koos Join'ide ja muu loogikaga HBase's, aga kui efektiivne see on…
Seetõttu peame kasutama kasutaja ID-d võtmena. Esimene mõte selle kohta, "kuidas ja kus salvestada sõprade ID-d?", võib olla nende salvestamine veergudesse. See kõige ilmsem ja "naivne" variant näeb välja umbes nii (nimetame seda Variant 1 (default), et viidata hiljem):
RowKey
Veerud
Vladimir
1: Peeter
2: Olya
3: Dasha
Peti
1: Masha
2: Vasya
Igas reas on üks kasutaja sotsiaalvõrgustikes. Veergudel on nimed: 1, 2, … — sõprade arvu järgi, ja veergudes hoitakse sõprade ID-sid. Oluline on märkida, et igas reas on erinev arv veerge. Ülaltoodud joonisel on ühes reas kolm veergu (1, 2 ja 3), teises aga ainult kaks (1 ja 2) — siin kasutasime kahte omadust HBase's, mida ei ole relaationalsetes andmebaasides:
- võimalust dünaamiliselt muuta veergude koosseisu (lisame sõbra -> lisame veeru, eemaldame sõbra -> eemaldame veeru)
- erinevates ridades võivad olla erinevad veergude koosseisud
Kontrollime meie struktuuri ülesande nõuetele vastavust:
- Andmete lugemine: et mõista, kas Vassil on Olya tellitud, peame me välja lugema kogu rida võtme RowKey = «Vassil» järgi ja kontrollima veergude väärtusi, kuni leiame Olya. Või kontrollime kõiki veerge, et «ei kohtaks» Olya ja anname vastuseks vale;
- Andmete muutmine: sõbra lisamine: sellise ülesande jaoks peame samuti välja lugema kogu rida võtme RowKey = «Vassil» järgi, et arvutada tema sõprade koguarv. See koguarv on vajalik, et määrata veeru number, kuhu tuleb salvestada uue sõbra ID.
- Andmete muutmine: sõbra kustutamine:
- Peame välja lugema kogu rida võtme RowKey = «Vassil» järgi ja kontrollima veerge, et leida see, kuhu on salvestatud kustutatav sõber;
- Seejärel peame kustutatud sõbra pärast «tõukama» kõik andmed ühe veeru võrra, et vältida nende numbrite «katkestusi».
Hinnakem nüüd, kui tõhusad on need algoritmid, mida peame «tinglikus rakenduses» rakendama. . Määratleme meie hüpotetiseeritud sotsiaalvõrgustiku suuruseks n. Seega võib ühe kasutaja maksimaalne sõprade arv olla (n-1). Selle (-1) võime edaspidi ignoreerida, kuna O-sümboolika kasutamisel on see ebaoluline.
- Andmete lugemine: on vaja kogu rida välja arvutada ja piiri piires läbi vaadata kõik selle veerud. Seega on ülemine hindamine kulude osas umbes O(n)
- Andmete muutmine: sõbra lisamine: sõprade arvu määramiseks on vaja läbi vaadata kõik veerud, pärast mida tuleb sisestada uus veerg => O(n)
- Andmete muutmine: sõbra kustutamine:
- Sarnaselt lisamisega - on lõppkokkuvõttes vaja läbi vaadata kõik veerud => O(n)
- Veergede eemaldamisel peame need "tõukama". Kui seda "otseselt" teostada, vajame lõpuks veel kuni (n-1) operatsiooni. Kuid siin ja edaspidi rakendame praktilises osas teistsugust lähenemist, mis viib „vale tõukamiseni“ fikseeritud arvu operatsioonidega — see tähendab, et selleks kulub konstantne aeg olenemata n-st. Seda konstantset aega (täpsemalt O(2)) saab võrrelda O(n) ja selle peale võib tähelepanu mitte pöörata. Lähenemine on illustreeritud alloleval joonisel: lihtsalt kopeerime andmed "viimasest" veerust sellesse, kust on vaja andmed eemaldada, seejärel kustutame viimase veeru:


Kokkuvõttes saime kõigis stsenaariumides asymptootilise arvutuskompleksuse O(n).
Te olete ilmselt juba märganud, et me peame peaaegu alati lugema terve rea kogu ulatuses, ja kaks korda kolmest teeme seda ainult selleks, et läbida kõik veerud ja arvutada kokku sõprade arvu. Seetõttu võiks optimeerimise katse raames lisada veeru „count“, kuhu salvestada iga kasutaja sõprade koguarv. Sel juhul ei pea me kogu rida tervikuna lugema, et saada sõprade koguarvu, vaid saame lugeda ainult veeru „count“. Peaasi, et ei unustata „count“ väärtust andmetega manipuleerimisel uuendada. Nii saavutame tõhustamise. Variant 2 (count):
RowKey
Veerud
Vladimir
1: Peeter
2: Olya
3: Dasha
count: 3
Peti
1: Masha
2: Vasya
count: 2
Võrreldes esimesega:
- Andmete lugemine: küsimusele „Kas Vasia loeb Oljat?” ei ole midagi muutunud => O(n)
- Andmete muutmine: sõbra lisamine: Oleme lihtsustanud uue sõbra lisamist, kuna nüüd ei pea me lugema kogu rida ja läbima selle veerge, vaid saame lihtsalt võtta veeru „count” väärtuse ja seega määrata kohe veeru numbri uue sõbra lisamiseks. See vähendab arvutuskompleksust O(1)-ni.
- Andmete muutmine: sõbra kustutamine: Sõbrade eemaldamisel saame kasutada ka seda veergu, et vähendada sisendi ja väljundi operatsioonide arvu andmete „tõukamiseks” ühe lahtri võrra vasakule. Kuid veergude läbivaatamise vajadus eemaldatava leidmiseks jääb siiski alles, seega => O(n)
- Teiselt poolt, nüüd peame andmete uuendamisel iga kord värskendama ka veergu „count”, kuid selleks kulub konstantne aeg, mida O-sümboolide raames võib ignoreerida
Üldiselt tundub variant 2 veidi optimaalsem, kuid see on pigem „evolutsioon, mitte revolutsioon”. Revolutsiooni saavutamiseks vajame Variant 3 (col).
Käinvertame kõik „jalgu üle pea”: määrame veeru nimi kasutaja identifikaatoriks! Mis iganes veerus salvestatakse – ei ole meie jaoks enam oluline, las see olla number 1 (üldiselt, seal saab hoida näiteks rühma „pereliikmed/sõbrad jne”). See lähenemine võib üllatada ettevalmistamata „tavainimest”, kellel pole varem olnud kogemusi NoSQL-andmebaasidega, kuid just see võimaldab HBase potentsiaali selles ülesandes kasutusele võtta palju efektiivsemalt:
RowKey
Veerud
Vladimir
Petr: 1
Ola: 1
Dasha: 1
Peti
Masha: 1
Vasya: 1
Siin saame kohe mitmeid eeliseid. Need mõista, analüüsime uut struktuuri ja hindame arvutuskompleksust:
- Andmete lugemine: et vastata küsimusele, kas Vasja on Olya jälginud, piisab ühe veeru «Olya» lugemisest: kui see on olemas, siis vastus on True, kui seda pole, siis False => O(1)
- Andmete muutmine: sõbra lisamine: Sõbra lisamine: piisab lihtsalt uue veeru «Sõbra ID» lisamisest => O(1)
- Andmete muutmine: sõbra kustutamine: piisab lihtsalt veeru «Sõbra ID» eemaldamisest => O(1)
Kuna näeme, on sellise salvestusmudeli oluline eelis see, et kõigis vajalikus stsenaariumis töötame ainult ühe veeruga, vältides kogu rea lugemist andmebaasist ja veelgi enam, kõigi selle rea veergude läbimist. Sellega võikski piirduda, kuid…
Saame muretseda ja minna veelgi kaugemale jõudluse optimeerimise ja andmebaasi juurdepääsul sisend-väljundite vähenemise teel. Mis siis, kui salvestada kõik ühenduse kohta käivad andmed otse rea võtmes? Ehk tegemist on koostisosavõtmega vormis userID.friendID? Sel juhul ei pea me isegi rea veerge lugema (Variant 4 (rida)):
RowKey
Veerud
Vasja.Petja
Petr: 1
Vasja.Olya
Ola: 1
Vasja.Dasha
Dasha: 1
Petja.Masha
Masha: 1
Petja.Vasja
Vasya: 1
Ilmselt on kõigi andmete manipuleerimise stsenaariumide hindamine sellises struktuuris, nagu ka eelmine variant, O(1). Erinevus variandiga 3 seisneb üldiselt vaid andmebaasis sisend- ja väljundoperatsioonide efektiivsuses.
Ja viimane 'pael'. On lihtne märkida, et variandis 4 on meie rea võti muutuv pikkus, mis võib mõjutada jõudlust (meenutame, et HBase salvestab andmeid baitide kogumina ja read tabelites on sorteeritud võtme järgi). Lisaks on meil eraldaja, mida teatud stsenaariumites võib olla vaja töödelda. Selle mõju vähendamiseks võime kasutada userID ja friendID hašhe, ning kuna mõlemad hašid on konstantsed pikkused, saame need lihtsalt konkateerida, ilma eraldajata. Siis näevad andmed tabelis välja sellised.Variant 5(hash)):
RowKey
Veerud
dc084ef00e94aef49be885f9b01f51c01918fa783851db0dc1f72f83d33a5994
Petr: 1
dc084ef00e94aef49be885f9b01f51c0f06b7714b5ba522c3cf51328b66fe28a
Ola: 1
dc084ef00e94aef49be885f9b01f51c00d2c2e5d69df6b238754f650d56c896a
Dasha: 1
1918fa783851db0dc1f72f83d33a59949ee3309645bd2c0775899fca14f311e1
Masha: 1
1918fa783851db0dc1f72f83d33a5994dc084ef00e94aef49be885f9b01f51c0
Vasya: 1
On selge, et sellise struktuuri algoritmiline keerukus meie käsitletud stsenaariumide puhul on sama, mis variandil 4 – st O(1).
Kokkuvõtteks koondame kõik meie arvutuste keerukuse hinnangud ühte tabelisse:
Sõbra lisamine
Sõbra kontrollimine
Sõbra eemaldamine
Variant 1 (default)
O(n)
O(n)
O(n)
Variant 2 (count)
O(1)
O(n)
O(n)
Variant 3 (column)
O(1)
O(1)
O(1)
Variant 4 (row)
O(1)
O(1)
O(1)
Variant 5 (hash)
O(1)
O(1)
O(1)
Kuna näha on, näivad variandid 3-5 olema kõige eelistatumad ja teoreetiliselt tagavad kõigi vajalike andmehaldusstsenaariumide täitmise pideva ajaga. Meie ülesande tingimustes pole selget nõuet, et saaksime kasutaja kõigi sõprade loendi, kuid tegelikus projektitöös oleks meil, headel analüütikutel, mõistlik "ette näha", et selline ülesanne võib tekkida ja "kaitsta end". Seetõttu on minu eelistus variandi 3 poole. Kuid on täiesti võimalik, et reaalses projektis on see päring juba lahendatud muude vahenditega, seega on parem vältida lõplikke järeldusi, kui pole üldist arusaama kogu probleemist.
Eksperimendi ettevalmistamine
Ülaltoodud teoreetilisi arutlusi on soovitatav praktikas kontrollida - see oligi pika nädalavahetuse mõtte põhjuseks. Selleks on vajalik hinnata meie "tingimusliku rakenduse" töökiirus kõigis kirjeldatud andmebaasi kasutuse stsenaariumides ning samuti selle aja kasvu sotsiaalse võrgu (n) suuruse suurenemisega. Sihtparameeter, mis meid huvitab ja mida me katse käigus mõõdame, on "tingimusliku rakenduse" kulutatud aeg ühe "ettevõtte tehingu" täitmiseks. "Ettevõtte tehing" tähendab ühte järgmistest:
- Ühe uue sõbra lisamine
- Kontrollimine, kas kasutaja A on kasutaja B sõber
- Ühe sõbra kustutamine
Seega, arvestades algses ülesandes esitatud nõudeid, joonistub kinnitamise stsenaarium välja järgmiselt:
- Andmete salvestamine. Genereeri juhuslikult lähtevõrk suurusega n. Suurema lähenemise saavutamiseks "reaalsele maailmale" on iga kasutaja sõprade arv samuti juhuslik väärtus. Määra aeg, mille jooksul meie „tingimuslik rakendus“ salvestab HBase kõik genereeritud andmed. Seejärel jagage saadud aeg lisatud sõprade koguarvuga – nii saame keskmise aja ühe „äritehingu“ kohta.
- Andmete lugemine. Iga kasutaja jaoks koosta nimekiri „isikutest“, kelle kohta tuleb välja selgitada, kas kasutaja jälgib neid või mitte. Nimekirja pikkus = ligikaudu kasutaja sõprade arv, kusjuures poole kontrollitavate sõprade puhul peab vastus olema „Jah“ ja teise poole puhul – „Ei“. Kontrollimine toimub sellises järjekorras, et vastused „Jah“ ja „Ei“ vahelduvad (st igal teisel juhul peame läbi vaatama kõik veerud ridades variantide 1 ja 2 jaoks). Üldine kontrollimise aeg jagatakse seejärel kontrollitavate sõprade arvuga, et saada keskmine kontrollimise aeg ühe subjekti kohta.
- Andmete kustutamine. Eemaldage kasutajalt kõik sõbrad. Eemaldamise järjekord on juhuslik (st „segame” algse loendi, mida kasutati andmete salvestamiseks). Kokku kontrollimise aeg jagatakse siis eemaldatavate sõprade arvuga, et saada keskmine aeg ühe kontrolli kohta.
Skeeme tuleb testida iga 5 andmemudeli variandi jaoks ja erinevate sotsiaalvõrgustike suuruste järgi, et näha, kuidas aeg muutub koos selle kasvuga. Ühe nühikuga peab võrgu sees ja kontrollimiseks kasutatav kasutajate nimekiri loomulikult olema sama kõigi 5 variandi jaoks.
Parema arusaamise saamiseks toome allpool näite genereeritud andmetest n= 5. Kirjutatud „generaator” annab väljundina kolm ID-de sõnastikku:
- esimene – sisestamiseks
- teine – kontrollimiseks
- kolmas – kustutamiseks
{0: [1], 1: [4, 5, 3, 2, 1], 2: [1, 2], 3: [2, 4, 1, 5, 3], 4: [2, 1]} # kokku 15 sõpra
{0: [1, 10800], 1: [5, 10800, 2, 10801, 4, 10802], 2: [1, 10800], 3: [3, 10800, 1, 10801, 5, 10802], 4: [2, 10800]} # kokku 18 kontrollitavat subjekti
{0: [1], 1: [1, 3, 2, 5, 4], 2: [1, 2], 3: [4, 1, 2, 3, 5], 4: [1, 2]} # kokku 15 sõpra
Kuidas märkida, kõik ID-d, mis on suuremad kui 10 000 kontrollimise sõnastikus - need on just need, mis kindlasti annavad vale vastuse. Sõbra lisamine, kontrollimine ja eemaldamine toimub alati sõnastikus näidatud järjekorras.
Eksperiment viidi läbi sülearvutil, millel oli Windows 10, kus ühes Docker'i konteineris töötas HBase andmebaas ja teises - Python koos Jupyter Notebook'iga. Docker'ile on eraldatud 2 CPU tuuma ja 2 GB RAM-i. Kogu loogika, sealhulgas emulatsioon „tinglikust rakendusest“ ja „riistvara“ testandmete genereerimise ning aja mõõtmise jaoks, oli kirjutatud Pythonis. HBase'i jaoks kasutati raamatukogu , MD5 hashide (variant 5) arvutamiseks - hashlib.
Arvestades konkreetse sülearvuti arvutusvõimsust, valiti eksperimentaalselt käivitamine n = 10, 30, …. 170 - kui kogu tsükli testimise (kõik stsenaariumid kõigi variantide jaoks igas n-s) koguaeg oli veel enam-vähem mõistlik ja mahtus ühe teejoomise aega (keskmiselt 15 minutit).
Siin on oluline märkida, et antud eksperimendis hindame esmalt mitte absoluutseid jõudlusnumbreid. Isegi erinevate kahe variandi suhteline võrdlemine ei pruugi kindlasti olla täiesti korrektne. Meid huvitab praegu eelkõige aja muutumise iseloom n sõltuvalt, kuna arvesse võttes eespool mainitud 'testimise seade' konfiguratsiooni on ajahinnangute saamine, mis on 'puhastatud' juhuslike ja teiste tegurite mõjust, väga keeruline (ja sellist ülesannet ei olnudki esitatud).
Eksperimendi tulemus
Esimene test – kuidas muutub aeg, mis kulub sõprade nimekirja täitmiseks. Tulemus – alloleval graafikul.
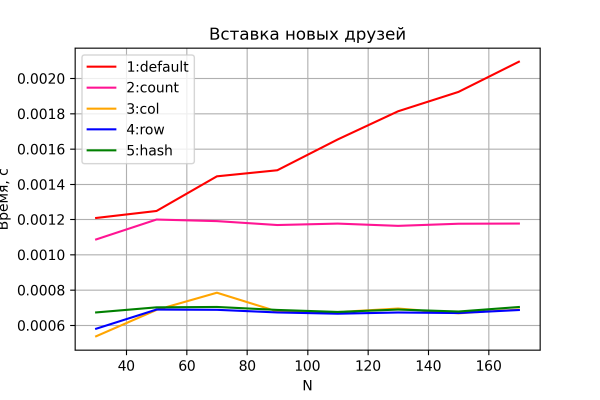
Variandid 3-5 näitavad ootuspäraselt praktiliselt konstantset 'äritegevuse' aega, mis ei sõltu võrgu suuruse kasvamisest ja nähtamatust jõudlusvahedest.
Variant 2 shows a constant but slightly worse performance, being nearly 2 times lower compared to variants 3-5. This is encouraging as it aligns with theory — in this variant, the number of input/output operations to/from HBase is exactly twice as high. This could serve as indirect evidence that our test setup provides decent accuracy.
Variant 1 is, as expected, the slowest one and demonstrates a linear increase in time taken for adding one another, proportional to the size of the network.
Now let's look at the results of the second test.
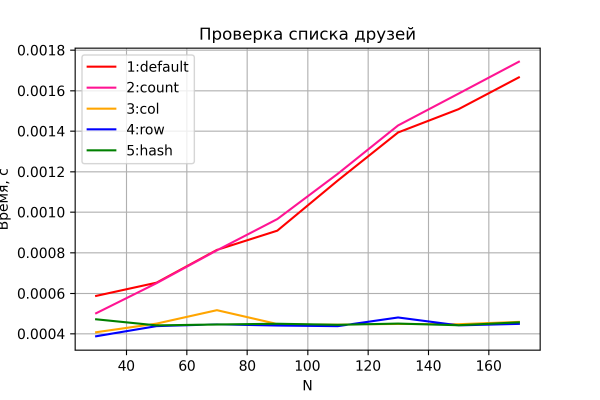
Valikud 3-5 käituvad taas ootuspäraselt – konstantne aeg, mis ei sõltu võrgu suurusest. Valikud 1 ja 2 näitavad lineaarset ajakasvu võrgu suuruse suurenedes ja sarnast jõudlust. Tuleb märkida, et variant 2 osutub veidi aeglasemaks – tõenäoliselt seetõttu, et tuleb lugeda ja töödelda täiendavat „count” veergu, mis suuruse n kasvades muutub märgatavamaks. Kuid ma ei tee siiski järeldusi, kuna selle võrdluse täpsus on suhteliselt madal. Lisaks muutuvad need suhted (milline valik, 1 või 2, on kiirem) käivitamiselt käivitamisele (samal ajal säilitades sõltuvuse loomuse ja "minnes ninapidi koos").
Viimane diagramm – kustutamise testimise tulemus.
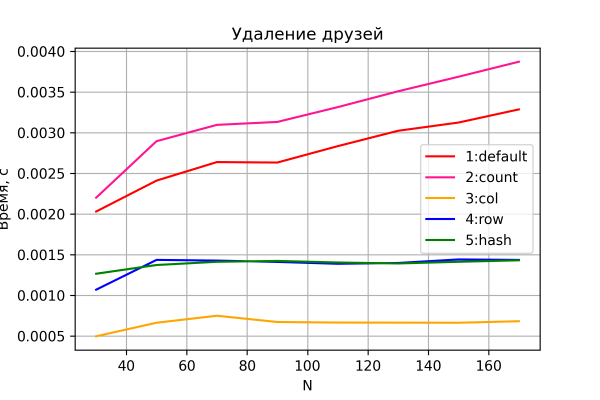
Siin pole samuti üllatusi. Valikud 3-5 teostavad kustutamise konstantse ajaga.
Mis on huvitav, variantide 4 ja 5, erinevalt eelnevatest stsenaariumitest, näitavad veidi kehvemat jõudlust kui variant 3. Tõenäoliselt on rea kustutamine kulukam kui veeru kustutamine, mis on üldiselt loogiline.
Valikud 1 ja 2 näitavad oodatult lineaarset ajakasvu. Sellegipoolest on valik 2 pidevalt aeglasem kui valik 1 - tänu täiendavatele sisendi-välendi operatsioonidele 'kolonni count' hooldamiseks.
Kokkuvõtted katse tulemustest:
- Valikud 3-5 näitavad suuremaid tõhususe näitajaid, kuna nad kasutavad HBase'i eeliseid; sellegipoolest erineb nende tootlikkus omavahel konstantse väärtuse ulatuses ja ei sõltu võrgu suurusest.
- Erinevust variantide 4 ja 5 vahel ei registreeritud. Kuid see ei tähenda, et variant 5 ei oleks kasutamiseks sobiv. On täiesti võimalik, et katse stsenaarium, arvestades testimise seinale m3ompid, ei võimaldanud seda avastada.
- Ajakasvu iseloom, mis on vajalik 'äritegevustega' andmetega töötamiseks, on üldiselt kinnitanud varem saadud teoreetilisi järeldusi kõikide variantide osas.
Epilog
Tehtud katseid ei tohiks tõlgendada absoluutsena. On palju tegureid, mida ei arvestatud ja mis moonutasid tulemusi (eriti selgelt on need kõikumised nähtavad graafikutes väikese võrgu suuruse korral). Näiteks thrift'i töö kiirus, mida kasutatakse happybase'is, loogika rakendamine, mille ma olin kirjutanud Pythonis (ei julge öelda, et kood oli kirjutatud optimaalselt ja tõhusalt kasutas kõiki komponente), võib-olla HBase'i salvestamise eripära, Windows 10 taustategevus minu sülearvutis jne. Üldiselt võib öelda, et kõik teoreetilised järeldused on katsetega osutunud kehtivaks. Või vähemalt ei õnnestunud neid sellise „ersameelne vastu” ümber lükata.
Kokkuvõtteks – soovitused neile, kes alles hakkavad andmemudeleid HBase'is projekteerima: abstraktsioneerige oma eelmist kogemust relatsiooniliste andmebaasidega ja pidage meeles „käsky”:
- Projekteerimisel lähme ülesandest ja andmete manipuleerimise mallidest, mitte objektide mudelist.
- Tõhus juurdepääs (ilma full table scanita) – ainult võtme kaudu.
- Denormaliseerimine
- Erinevad read võivad sisaldada erinevaid veerge
- Veergude dünaamiline koostis
Allikas: habr.com
