


Linuxis on palju tööriistu tuuma ja rakenduste silumiseks. Enamik neist mõjutab rakenduste jõudlust negatiivselt ja neid ei saa kasutada tootmises.
Mõni aasta tagasi loodi — eBPF. See võimaldab jälgida tuuma ja rakendusi madala üleminekuga ning ilma vajaduseta programme uuesti kompileerida ja kolmandate osapoolte mooduleid tuuma laadida.
Praeguseks on juba mitmeid rakenduslikke utiliite, mis kasutavad eBPF-d, ja selles artiklis vaatame, kuidas kirjutada oma profilleerimise utiliit, kasutades teeki . Artikkel põhineb tõeliselt juhtunud sündmustel. Me läbime teekonna probleemide ilmumisest kuni nende lahendamiseni, et näidata, kuidas olemasolevaid utiliite konkreetses olukorras kasutada.
Ceph on aeglane
Klusterisse Ceph lisati uus host. Pärast osa andmete selle peale migreerimist märkasime, et kirjutamiselt päringute töötlemise kiirus on neil oluliselt madalam kui teistel serveritel.
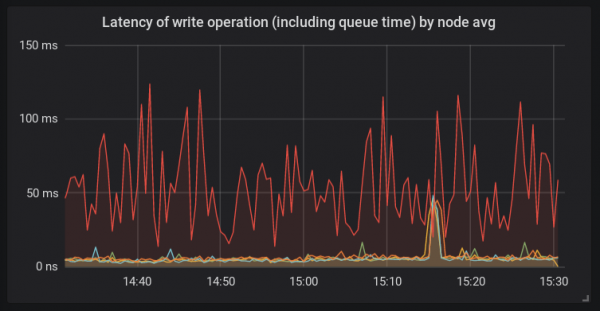
Erinevalt teistest platvormidest kasutati selle hosti puhul bcache'i ja uut linux 4.15 kerneli. Sellist konfiguratsiooni kasutati siin esmakordselt. Ja tol ajal oli selge, et probleemi juurteks võis teoreetiliselt olla mis iganes.
Uurime hosti
Alustame uurimist, vaadates, mis toimub ceph-osd protsessi sees. Selleks kasutame ja (millega saab rohkem tutvuda ):

Pilt näitab meile, et funktsioon fdatasync() kulutas palju aega päringu saatmisele funktsioonis generic_make_request(). See tähendab, et tõenäoliselt on probleemide põhjus kuskil väljaspool osd teenust. See võib olla kas kernel või kettad. Iostat'i väljund näitas bcache-kettaste kõrgeid päringute töötlemise viivitusi.
Hosti kontrollimisel avastasime, et systemd-udevd demon tarbib suurt hulka CPU aega — umbes 20% mitmel tuumal. See on kummaline käitumine, seega on vaja välja selgitada selle põhjus. Kuna Systemd-udevd tegeleb uevent'idega, otsustasime vaadata neid läbi udevadm monitor. Selgub, et süsteemis genereeriti iga plokiseadmise jaoks suur hulk muudatus-sündmusi. See on üsna ebatavaline, seega tuleb vaadata, mis kõik need sündmused genereerib.
BCC tööriistakomplekti kasutamine
Nagu me juba selgitasime, veedab kernel (ja demon ceph süsteemitõkses) palju aega generic_make_request(). Proovime selle funktsiooni töökiirus ära mõõta. Selles on juba suurepärane utiliit — funclatency. Me jälgime deemonit selle PID järgi, tehes teabe väljundite vahel 1-sekundilise intervalli ning väljastame tulemuse millisekundites.
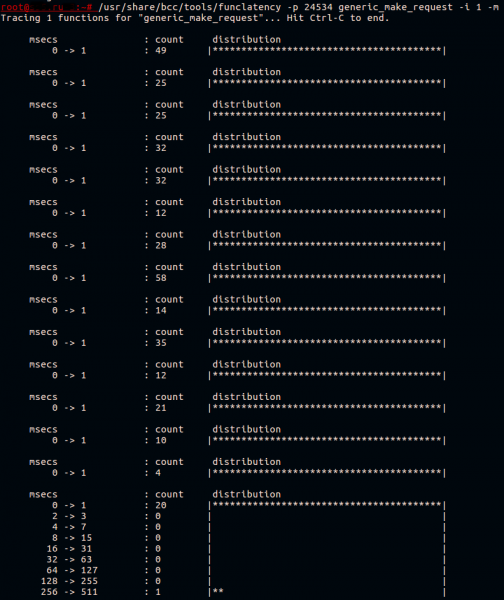
Tavaliselt töötab see funktsioon kiiresti. Kõik, mida ta teeb — edastab päringu seadme draiveri järjekorda.
Bcache on keeruline seade, mis tegelikult koosneb kolmest kettast:
- backing device (sisemine ketas), antud juhul aeglane HDD;
- caching device (vahemälu ketas), siin on see üks NVMe seadme partitsioon;
- virtuaalne seade bcache, millega rakendus töötab.
Teame, et päringu edastamine on aeglane, aga millise nende seadmete puhul? Selle selgitame välja hiljem.
Praegu teame, et uevent'id võivad põhjustada probleeme. Leida, mis täpselt nende genereerimist põhjustab, pole lihtne. Eeldame, et see on mingi perioodiliselt käivitatav tarkvara. Vaadakem, mis tarkvara töötab süsteemis skripti abil execsnoop samast . Käivitame selle ja suuname väljundi faili.
Näiteks niimoodi:
/usr/share/bcc/tools/execsnoop | tee ./execdump
Ei too siinkohal välja execsnoop'i täielikku väljundit, kuid üks meid huvitav rida nägi välja nii:
sh 1764905 5802 0 sudo arcconf getconfig 1 AD | grep Temperature | awk -F '[:\/]' '{print $2}' | sed 's\/^ ([0-9]*) C.*\/1\/'
Kolmas veerg on protsessi PPID (vanem PID). Protsess, millel on PID 5802, osutus üheks meie süsteemi jälgimisvoogudest. Jälgimisseadme konfiguratsiooni kontrollimisel leiti vale seadistusega parameetrid. HBA-adapteri temperatuuri loeti iga 30 sekundi tagant, mis on palju sagedamini, kui vajalik. Pärast kontrollintervalli pikendamist avastasime, et päringute töötlemise viivitus sellel hostil ei eristu enam teiste hostide seas.
Kuid siiani ei ole selge, miks bcache-seade nii aeglaselt töötas. Valmistame ette testplatvormi identse konfiguratsiooniga ja proovime probleemi kopeerida, käivitades fio bcache'il, perioodiliselt käivitades udevadm trigger'i ürituste genereerimiseks.
BCC-põhiste tööriistade kirjutamine
Proovime kirjutada lihtsat utiliiti, et jälgida ja ekraanile välja printida kõige aeglasemaid väljakutseid generic_make_request(). Meid huvitab ka ketta nimi, mille jaoks see funktsioon kutsuti.
Plaani eesmärk:
- Registreerime kprobe järgnevaga generic_make_request():
- Salvestame mällu ketta nime, mis on saadaval funktsiooni argumendi kaudu;
- Salvestame ajatempli.
- Registreerime kretprobe tagasipöördumine generic_make_request():
- Saame praeguse ajatempli;
- Otsime salvestatud ajatempli ja võrdleme praegusega;
- Kui tulemus on suurem määratud, leiame salvestatud ketta nime ja väljastame terminalile.
Kprobid ja kretprobid kasutavad peatumispunktide mehhanismi funktsioonide koodi reaalajas muutmiseks. Võite lugeda ja artiklit selle teema kohta. Kui vaadata erinevate utiliitide koodi , siis võib märgata, et neil on identne struktuur. Seega jätame käesolevas artiklis skripti argumentide parsimise vahele ja liigume otse BPF programmi juurde.
eBPF tekst Python-skripti sees näeb välja järgmiselt:
bpf_text = ''""" # Siia tuleb bpf programmi kood ''"""
Andmete vahetamiseks funktsioonide vahel kasutavad eBPF programmid . Nii teeme meiegi. Võtame võtmena protsessi PID ja väärtuseks määrame struktuuri:
struct data_t {
u64 pid;
u64 ts;
char comm[TASK_COMM_LEN];
u64 lat;
char disk[DISK_NAME_LEN];
};
BPF_HASH(p, u64, struct data_t);
BPF_PERF_OUTPUT(events);
Siin registreerime hüvitaabeli, mille nimi on p, võtme tüübiga u64 ja väärtuse tüübiga struct data_t. Tabel on kergesti kasutatav meie BPF-programmi kontekstis. Makro BPF_PERF_OUTPUT registreerib teise tabeli, mida nimetatakse events, mida kasutatakse kasutajaruumi.
Kuidas mõõta viivitusi funktsiooni kutsumise ja selle tagasiviimise vahel või erinevate funktsioonide kutsumiste vahel, tuleb arvesse võtta, et saadud andmed peavad kuuluma samasse konteksti. Teisisõnu, tuleb meeles pidada võimalikke funktsioonide üheaegseid käivitusi. Meil on võimalus mõõta viivitust funktsiooni kutsumise vahel ühe protsessi kontekstis ja selle funktsiooni tagasiviimist teise protsessi kontekstis, kuid see on tõenäoliselt kasutu. Hea näide siinkohal on , kus võtmena kasutatakse hash-tabeli puhul viidet struct request, mis kajastab ühe kettasaidi päringut.
Edasi peame kirjutama koodi, mis käivitatakse uuritava funktsiooni kutsumise korral:
void start(struct pt_regs *ctx, struct bio *bio) {
u64 pid = bpf_get_current_pid_tgid();
struct data_t data = {};
u64 ts = bpf_ktime_get_ns();
data.pid = pid;
data.ts = ts;
bpf_probe_read_str(&data.disk, sizeof(data.disk), (void*)bio->bi_disk->disk_name);
p.update(&pid, &data);
}
Siin pannakse teise argumendina paika kutsutud funktsiooni esimene argument . Pärast seda saame protsessi PID, mille kontekstis töötame, ja praeguse ajatempli nanosekundites. Salvestame kõik värskelt eraldatud. struct data_t data. Kõvakettanimi saadakse struktuurist bio, mis edastatakse kutse ajal generic_make_request(), ja salvestatakse samasse struktuuri data. Viimase sammuna lisame eelnevalt mainitud hash-tabelisse kirje.
Järgmine funktsioon kutsutakse välja tagastamisel generic_make_request():
void stop(struct pt_regs *ctx) {
u64 pid = bpf_get_current_pid_tgid();
u64 ts = bpf_ktime_get_ns();
struct data_t* data = p.lookup(&pid);
if (data != 0 && data->ts > 0) {
bpf_get_current_comm(&data->comm, sizeof(data->comm));
data->lat = (ts - data->ts) / 1000;
if (data->lat > MIN_US) {
FACTOR
data->pid >>= 32;
events.perf_submit(ctx, data, sizeof(struct data_t));
}
p.delete(&pid);
}
}
See funktsioon sarnaneb eelnevale: saame protsessi PID ja ajamärgi, kuid ei eralda mälu uue data struktuuri jaoks. Selle asemel otsime hash-tabelist juba olemasolevat struktuuri võtme järgi, mis vastab praegusele PID-le. Kui struktuur leiti, siis saame teada käimasoleva protsessi nime ja lisame selle sinna.
Siin kasutatav binaarne nihutamine on vajalik, et saada thread GID, st peamise protsessi PID, mis käivitas niidi, milles me töötame. Meie kutse tagastab nii niidi GID kui ka tema PID ühes 64-bitises väärtuses.
Väljunditerminali puhul ei huvita meid praegu voog, vaid peamine protsess. Pärast saadud viivituse võrdlemist määratud lävega edastame meie struktuuri data kasutaja ruumi kaudu tabelisse events, seejärel eemaldame kirje p.
Python skriptis, mis laadib antud koodi, peame asendama MIN_US ja FACTOR viivituse lävenditega ja ajainetega, mille me edastame argumentide kaudu:
bpf_text = bpf_text.replace('MIN_US',str(min_usec))
if args.milliseconds:
bpf_text = bpf_text.replace('FACTOR','data->lat /= 1000;')
label = "msec"
else:
bpf_text = bpf_text.replace('FACTOR','')
label = "usec"
Nüüd peame ette valmistama BPF programmi läbi ja registreerima proovide:
b = BPF(text=bpf_text)
b.attach_kprobe(event="generic_make_request",fn_name="start")
b.attach_kretprobe(event="generic_make_request",fn_name="stop")
Samuti peame määratlema struct data_t meie skriptis, vastasel juhul ei saa me midagi lugeda:
TASK_COMM_LEN = 16 # linux/sched.h
DISK_NAME_LEN = 32 # linux/genhd.h
class Data(ct.Structure):
_fields_ = [("pid", ct.c_ulonglong),
("ts", ct.c_ulonglong),
("comm", ct.c_char * TASK_COMM_LEN),
("lat", ct.c_ulonglong),
("disk",ct.c_char * DISK_NAME_LEN)]
Viimane samm — andmete väljund terminali:
def print_event(cpu, data, size):
global start
event = ct.cast(data, ct.POINTER(Data)).contents
if start == 0:
start = event.ts
time_s = (float(event.ts - start)) / 1000000000
print("%-18.9f %-16s %-6d %-1s %s %s" % (time_s, event.comm, event.pid, event.lat, label, event.disk))
b["events"].open_perf_buffer(print_event)
# format output
start = 0
while 1:
try:
b.perf_buffer_poll()
except KeyboardInterrupt:
exit()
Kood on saadaval . Proovime käivitada selle testplatvormil, kus fio kirjutab bcache'ile ja kutsume esile udevadm monitor:
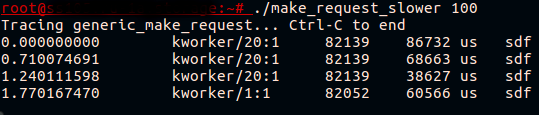
Lõfinally! Nüüd näeme, et see, mis näis peatavat bcache-seadet, on tegelikult peatumine generic_make_request() vahemälustatud ketta jaoks.
Kaevake südamikku
Mis täpselt peatab päringu esitamist? Näeme, et viivitus tekib isegi enne, kui päringu arvestamine algab, st konkreetse päringu arvestamine edasise statistika kuvamiseks (/proc/diskstats või iostat) ei ole veel alanud. Seda on lihtne kontrollida, käivitades iostat probleemide kordamisel, või , mis põhineb päringute arvestamise alguses ja lõpus. Ükski neist utiliidist ei näita vahemälustatud kettale tehtud päringute probleeme.
Kui vaatame funktsiooni generic_make_request(), siis näeme, et enne päringu konto loomist kutsutakse välja veel kaks funktsiooni. Esimene — generic_make_request_checks(), teeb päringu legitiimsuse kontrolle seoses ketta seadistustega. Teine — , kus on huvitav kõne :
ret = wait_event_interruptible(q->mq_freeze_wq,
(atomic_read(&q->mq_freeze_depth) == 0 &&
(preempt || !blk_queue_preempt_only(q))) ||
blk_queue_dying(q));
Selles tuum ootab järjekorra sulgemist. Mõõdame viivituse blk_queue_enter():
~# /usr/share/bcc/tools/funclatency blk_queue_enter -i 1 -m
Funktsioonide jälgimine "blk_queue_enter"... Vajutage Ctrl-C, et lõpetada.
msecs : count distribution
0 -> 1 : 341 |****************************************|
msecs : count distribution
0 -> 1 : 316 |****************************************|
msecs : count distribution
0 -> 1 : 255 |****************************************|
2 -> 3 : 0 | |
4 -> 7 : 0 | |
8 -> 15 : 1 | |
Tundub, et oleme lähedal lahendusele. Funktsioonid, mida kasutatakse järjekorra "külmutamiseks/sulatamiseks" — need on ja . Neid kasutatakse, kui on vajalik muuta järjekorra seadistusi, mis võivad olla potentsiaalselt ohtlikud sellele järjekorras olevatele päringutele. Kui kutsutakse blk_mq_freeze_queue() funktsiooni kalkulaatori väärtus suureneb q->mq_freeze_depth. Pärast seda ootab tuum, kuni järjekord on tühi .
Selle järjekorra tühjendamise ooteaeg on võrdne kettaseadmest tingitud viivitusega, kuna tuum ootab, kuni kõik järjekorda pandud toimingud on lõpetatud. Kui järjekord on tühi, rakendatakse seade muudatused. Seejärel kutsutakse välja , vähendades freeze_depth.
Nüüd teame piisavalt, et olukorda parandada. Käsk udevadm trigger viib lõpuks seadete rakendamiseni plokkseadmest. Need seaded on kirjeldatud udev reeglites. Saame välja selgitada, millised seaded „külmutavad” järjekorra, proovides neid muuta läbi sysfs või vaadates tuuma allika koodi. Samuti saame proovida BCC , mis kuvab terminalis tuuma ja kasutaja ruumi kuhjade jälgimise iga kõne jaoks blk_freeze_queue, näiteks:
~# /usr/share/bcc/tools/trace blk_freeze_queue -K -U
PID TID COMM FUNC
3809642 3809642 systemd-udevd blk_freeze_queue
blk_freeze_queue+0x1 [kernel]
elevator_switch+0x29 [kernel]
elv_iosched_store+0x197 [kernel]
queue_attr_store+0x5c [kernel]
sysfs_kf_write+0x3c [kernel]
kernfs_fop_write+0x125 [kernel]
__vfs_write+0x1b [kernel]
vfs_write+0xb8 [kernel]
sys_write+0x55 [kernel]
do_syscall_64+0x73 [kernel]
entry_SYSCALL_64_after_hwframe+0x3d [kernel]
__write_nocancel+0x7 [libc-2.23.so]
[unknown]
3809631 3809631 systemd-udevd blk_freeze_queue
blk_freeze_queue+0x1 [kernel]
queue_requests_store+0xb6 [kernel]
queue_attr_store+0x5c [kernel]
sysfs_kf_write+0x3c [kernel]
kernfs_fop_write+0x125 [kernel]
__vfs_write+0x1b [kernel]
vfs_write+0xb8 [kernel]
sys_write+0x55 [kernel]
do_syscall_64+0x73 [kernel]
entry_SYSCALL_64_after_hwframe+0x3d [kernel]
__write_nocancel+0x7 [libc-2.23.so]
[unknown]
Udev reeglid muutuvad harva ja tavaliselt toimub see kontrollitud viisil. Nii näeme, et isegi määratud väärtuste rakendamine põhjustab hilinemise suurenemist rakenduse ja ketta vaheliste päringute edastamisel. Loomulikult ei ole hea praktika genereerida udev-sündmusi, kui ketaste konfiguratsioonis pole mingeid muutusi (näiteks seade ei ühenda ega lahku). Siiski saame aidata tuumal mitte teha jõhkrat tööd ega "külmutada" päringute järjekorda, kui selleks pole mingit vajadust. lahendab olukorra.
Kokkuvõte
eBPF on väga paindlik ja võimas tööriist. Artiklis vaatasime ühte praktilist juhtumit ja näitasime väikeses osas, mida on võimalik teha. Kui teid huvitab BCC-utility arendamine, siis tasub tutvuda , mis kirjeldab hästi töö aluseid.
On ka teisi huvitavaid tööriistu, mis põhinevad eBPF-il, üks neist on , mis võimaldab kirjutada võimsaid ühelauseprogramme ja väikeseid skripte awk-sarnases keeles. Teine on , mis võimaldab koguda madala taseme kõrge eraldusvõimega metrikat otse teie prometheus serverisse, võimaldades hiljem saada kaunist visualiseerimist ja isegi hoiatusi.
Allikas: habr.com
